
Python is an excellent choice when it comes to data science. With a wide selection of libraries and built-in analytics tools, you can crunch data with ease, analyze even the most complex datasets, and visualize your results in beautiful charts and graphs.
Supabase is backend-as-a-service built on top of PostgreSQL. It's an excellent choice for building modern data-intensive apps and tooling.
Thanks to our incredible community, Supabase now has a powerful and open source Python SDK. With Supabase and Python, you can automate tasks such as CRUD operations with only a few lines of code. This guide will first create a simple schema in Supabase, then we'll use the Supabase Python SDK to show how you can load sample data.
Prerequisites
Before we dive in, let's look at some prerequisites you'll need:
- Python version > 3.7
- The SDK only supports version > 3.7. You can download a supported Python version from here.
- Python virtual environment
- This is optional, but it will avoid issues of package dependencies and version conflicts. You can find the steps to create a virtual environment here. We will be using PyCharm to harness its venv creation capabilities.
- Faker python package
- We will be using the faker-commerce package from the Faker library in Python to generate realistic sample data.
Loading data into Supabase using Python
Supabase is built for developers, and you can get started for free using your existing Github account. Once your Supabase account is set up, you will access the Supabase dashboard. From here, go to All Project > New Project.

Give your project a name and set the database password. You can also choose the region and adjust the pricing plan based on the requirements of your project.
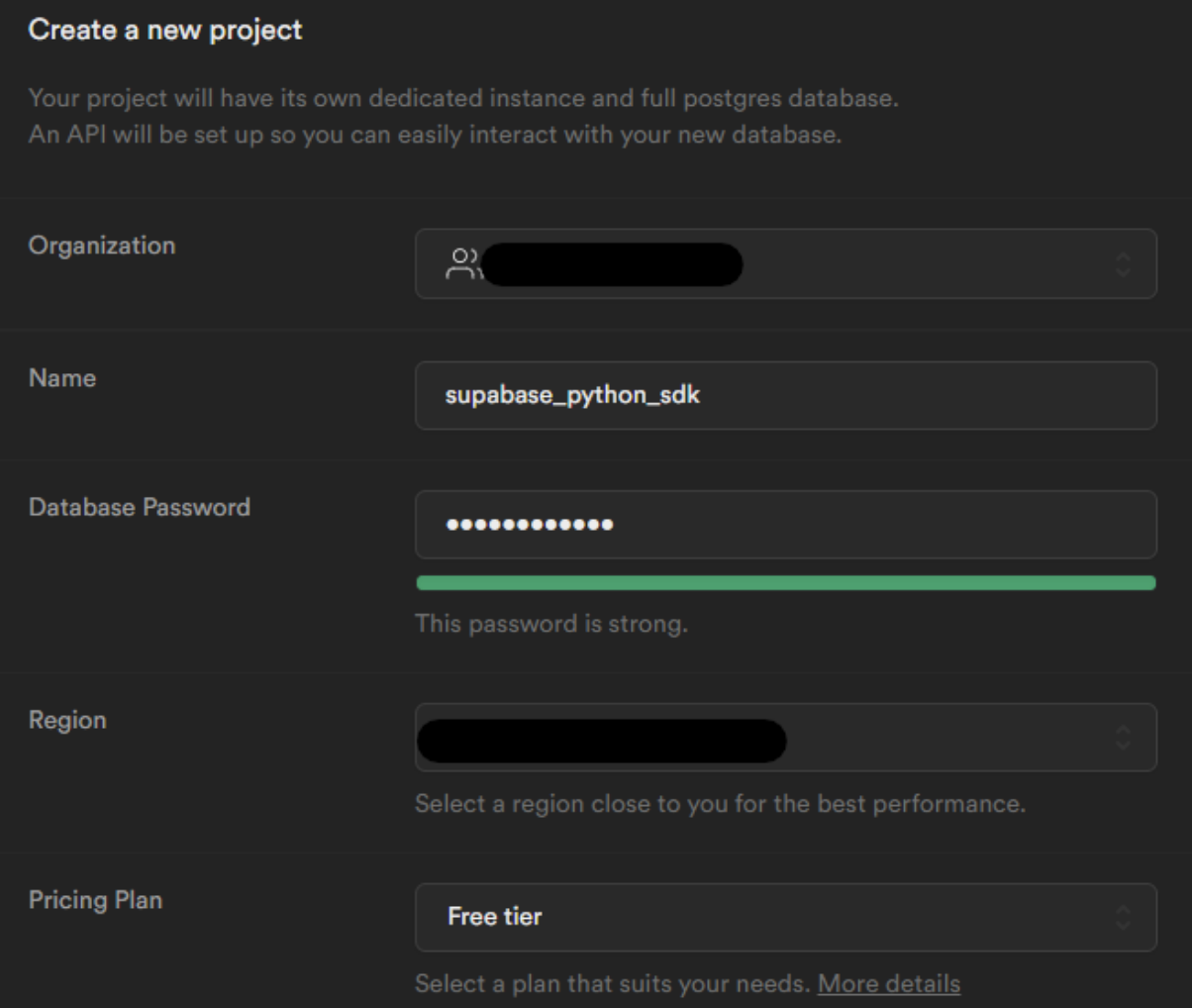
Your project will spin up within 2 minutes.
Creating tables in Supabase
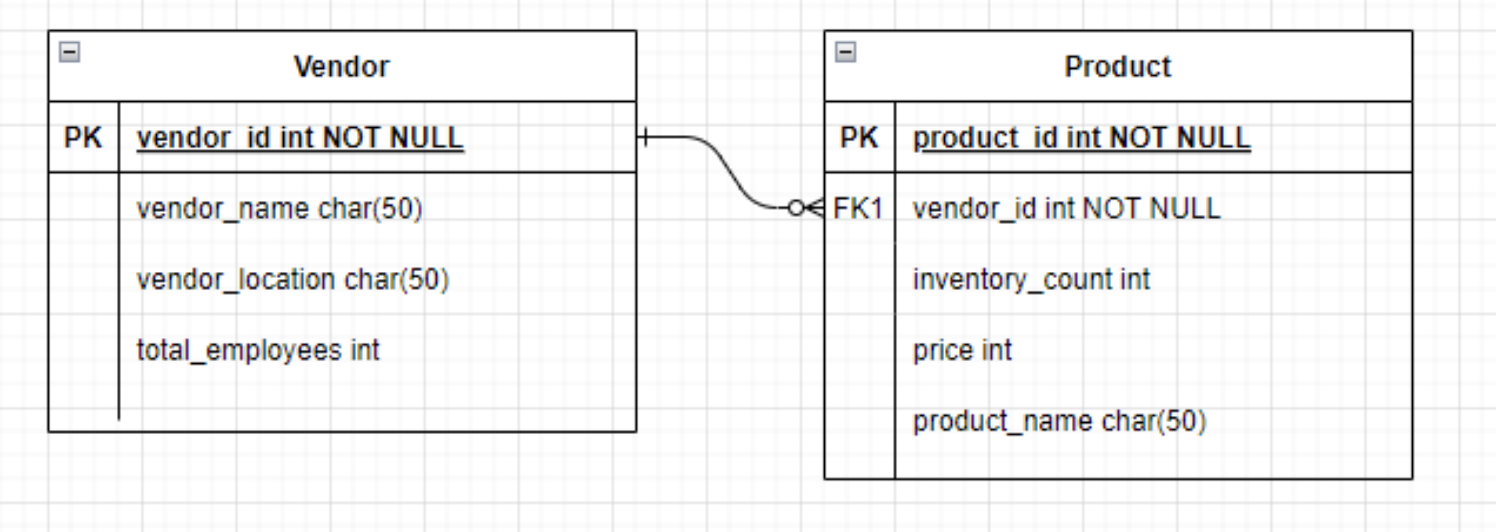
In this example, we'll be creating 2 tables in Supabase:
- Vendor (fields are vendor_name, vendor_location, and total_employees)
- Product (vendor_id as FK, product_name, price, and total orders)
The database schema will look like the following:
Let us now begin creating the tables. Once you create a project, you will need to go to Table Editor > New Table
Now, you can create a table according to the defined schema.
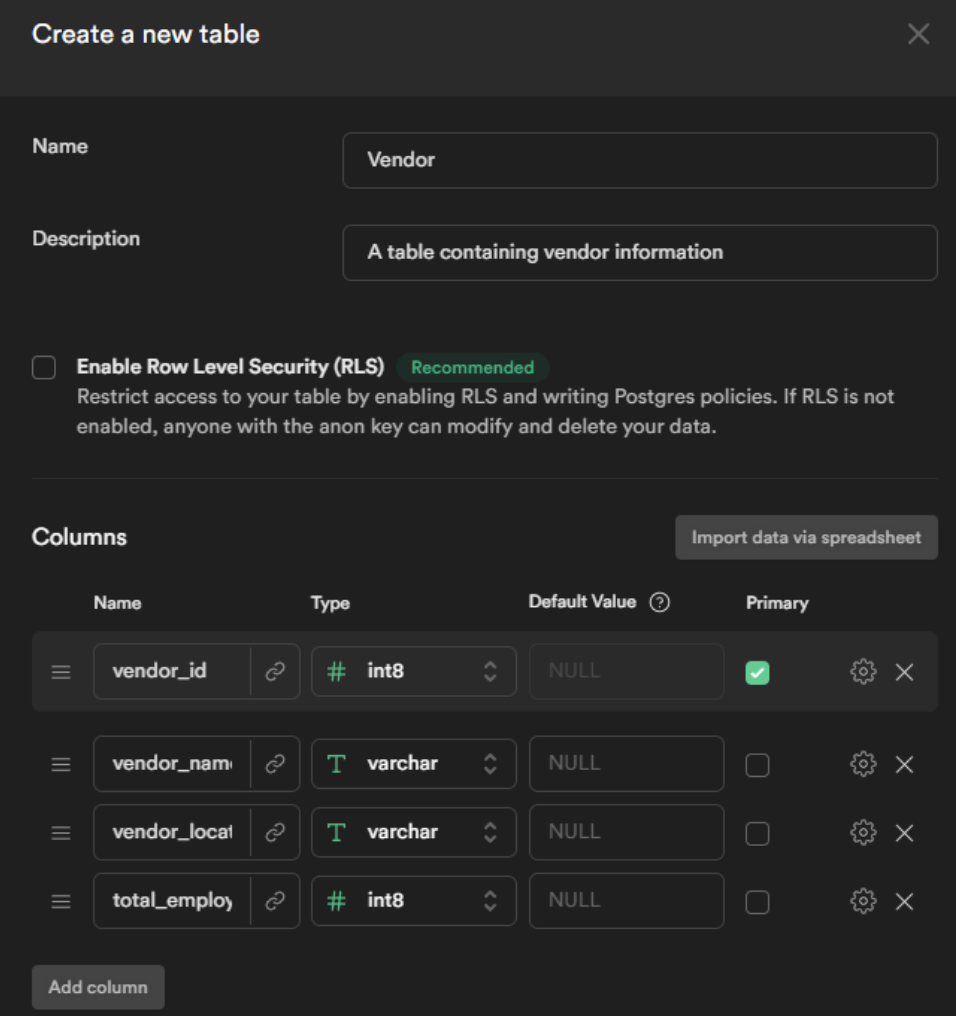 Click on Save to create your vendor table. Similarly, create the product table.
Click on Save to create your vendor table. Similarly, create the product table.
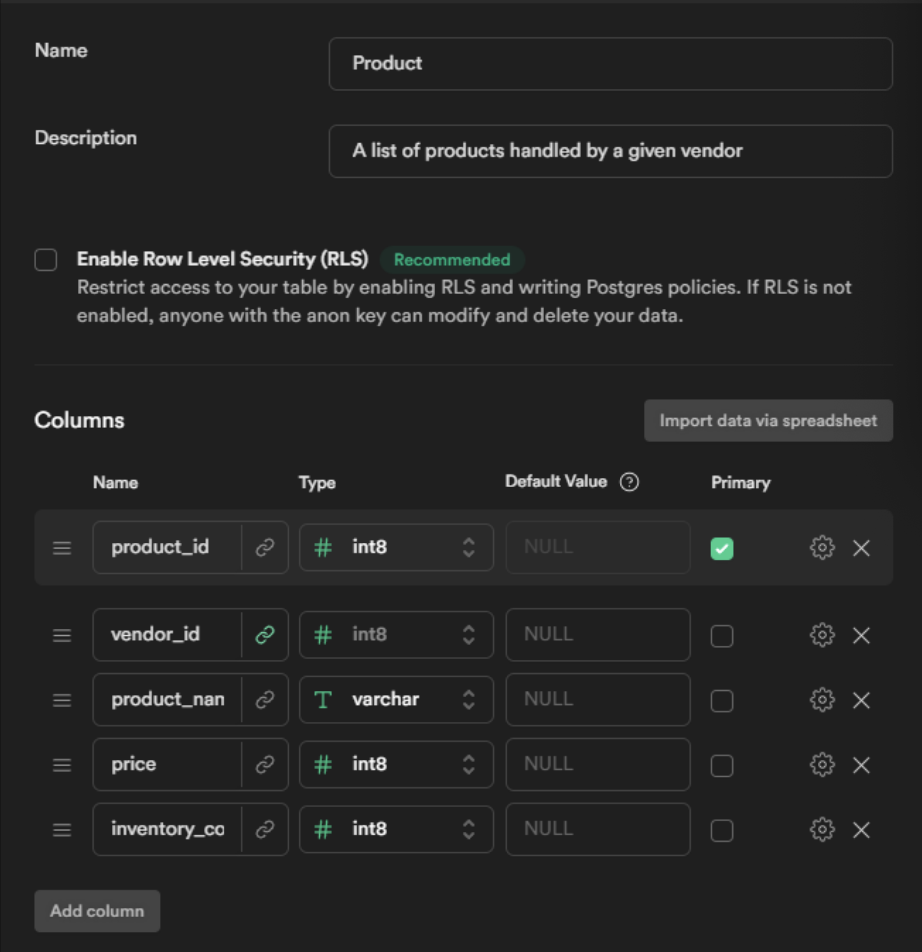
Before you click Save, you need to set up the foreign key relationship between the Product and Vendor table. To do this, select the button next to “vendor_id”
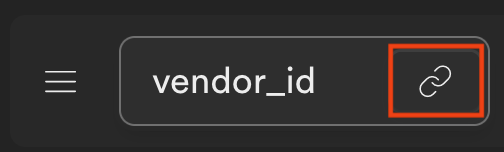 Select the vendor_id primary key from the “Vendor” table.
Select the vendor_id primary key from the “Vendor” table.
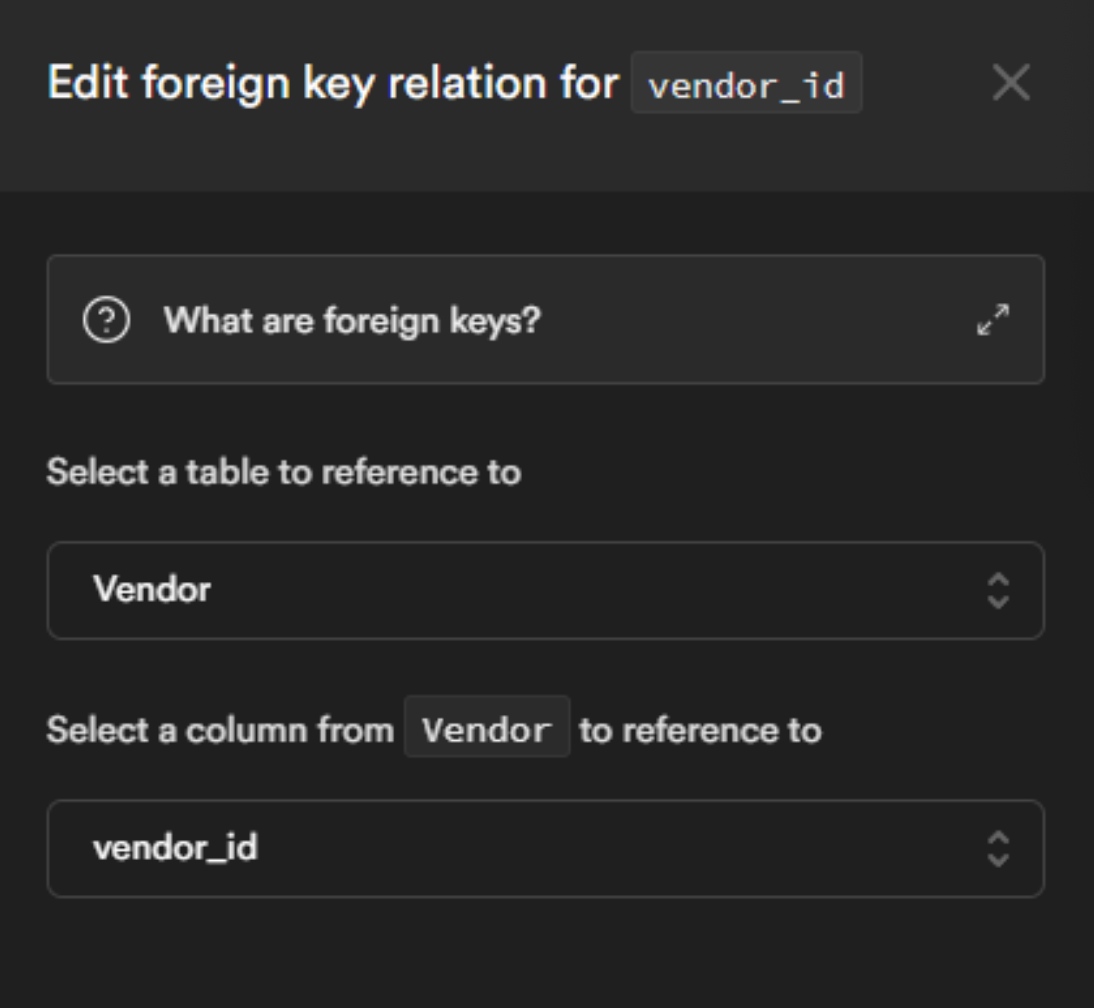
Click on Save and you are good to go. You should now see the 2 tables under Table Editor.
Installing the Python SDK
Once you have set up the tables and installed the prerequisites, you can now start playing around with the Python SDK. To install the SDK, run the following command:
pip3 install supabase
Ensure that you are running this inside your python virtual environment. This will take a few minutes to complete.
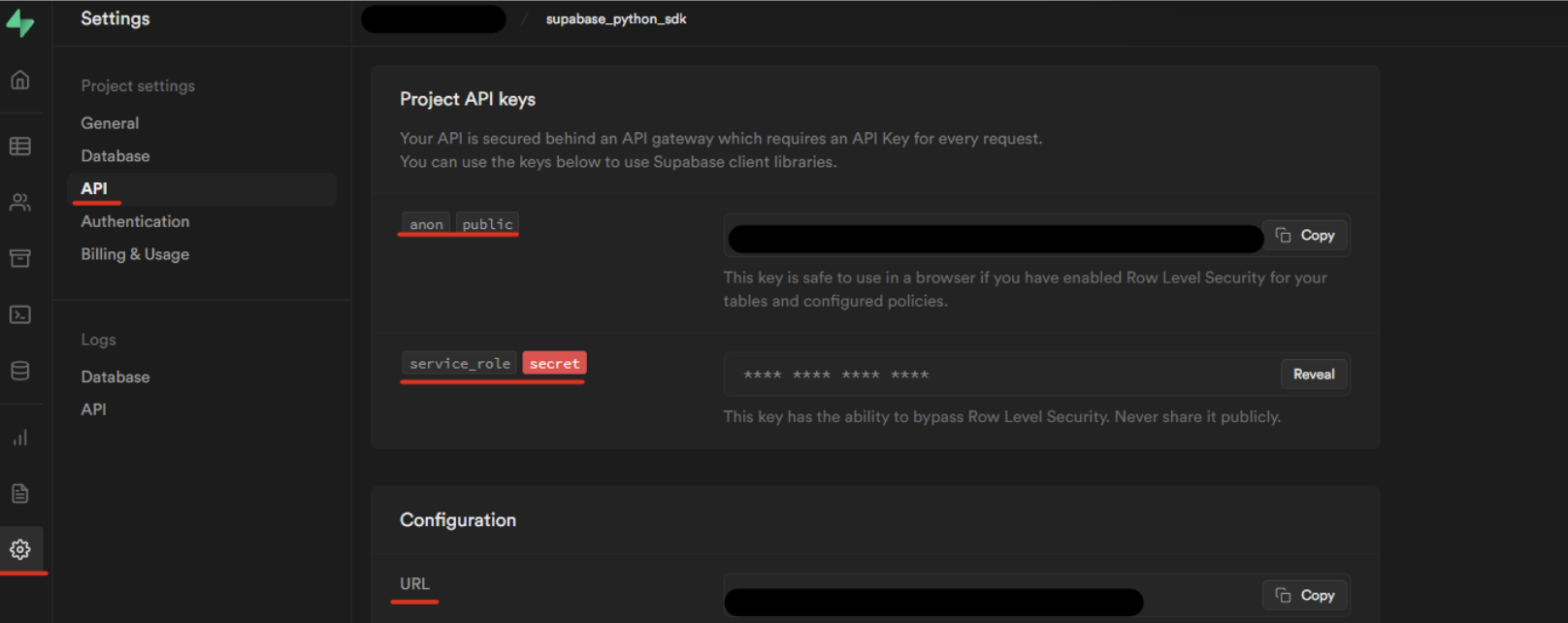
Using Supabase API keys
The SDK authentication uses API keys pointing to a project URL. To find out your project URL and APIs, go to Settings > API.
Setting up the environment variables
API credentials and project URL can be stored in environment variables. Setting the environment variables in bash/zsh is very simple. All we need to do is run:
_10export <variable_name>=<variable_value>
So for our example we will set them up like this:
_10export SUPABASE_URL=<<the value under config > URL>>_10export SUPABASE_KEY=<<the value present in Project API keys > anon public>>_10export SUPABASE_SECRET_KEY=<<the value present in Project API keys > service_role secret>>
Inserting data into Supabase
Here is a snippet of the code we will be using to insert random data into our tables:
_50import os_50import json_50from dotenv import load_dotenv_50from supabase import create_client, Client_50from faker import Faker_50import faker_commerce_50_50_50def add_entries_to_vendor_table(supabase, vendor_count):_50 fake = Faker()_50 foreign_key_list = []_50 fake.add_provider(faker_commerce.Provider)_50 main_list = []_50 for i in range(vendor_count):_50 value = {'vendor_name': fake.company(), 'total_employees': fake.random_int(40, 169),_50 'vendor_location': fake.country()}_50_50 main_list.append(value)_50 data = supabase.table('Vendor').insert(main_list).execute()_50 data_json = json.loads(data.json())_50 data_entries = data_json['data']_50 for i in range(len(data_entries)):_50 foreign_key_list.append(int(data_entries[i]['vendor_id']))_50 return foreign_key_list_50_50_50def add_entries_to_product_table(supabase, vendor_id):_50 fake = Faker()_50 fake.add_provider(faker_commerce.Provider)_50 main_list = []_50 iterator = fake.random_int(1, 15)_50 for i in range(iterator):_50 value = {'vendor_id': vendor_id, 'product_name': fake.ecommerce_name(),_50 'inventory_count': fake.random_int(1, 100), 'price': fake.random_int(45, 100)}_50 main_list.append(value)_50 data = supabase.table('Product').insert(main_list).execute()_50_50_50def main():_50 vendor_count = 10_50 load_dotenv()_50 url: str = os.environ.get("SUPABASE_URL")_50 key: str = os.environ.get("SUPABASE_KEY")_50 supabase: Client = create_client(url, key)_50 fk_list = add_entries_to_vendor_table(supabase, vendor_count)_50 for i in range(len(fk_list)):_50 add_entries_to_product_table(supabase, fk_list[i])_50_50_50main()
To summarize what we have done using this code snippet:
- We have inserted 10 random vendors to the table.
- For each of the 10 vendors, we have inserted a number of different products
Reading the data stored in Supabase
Data can also be viewed directly from the Supabase dashboard. To do this, go to Table Editor > All tables
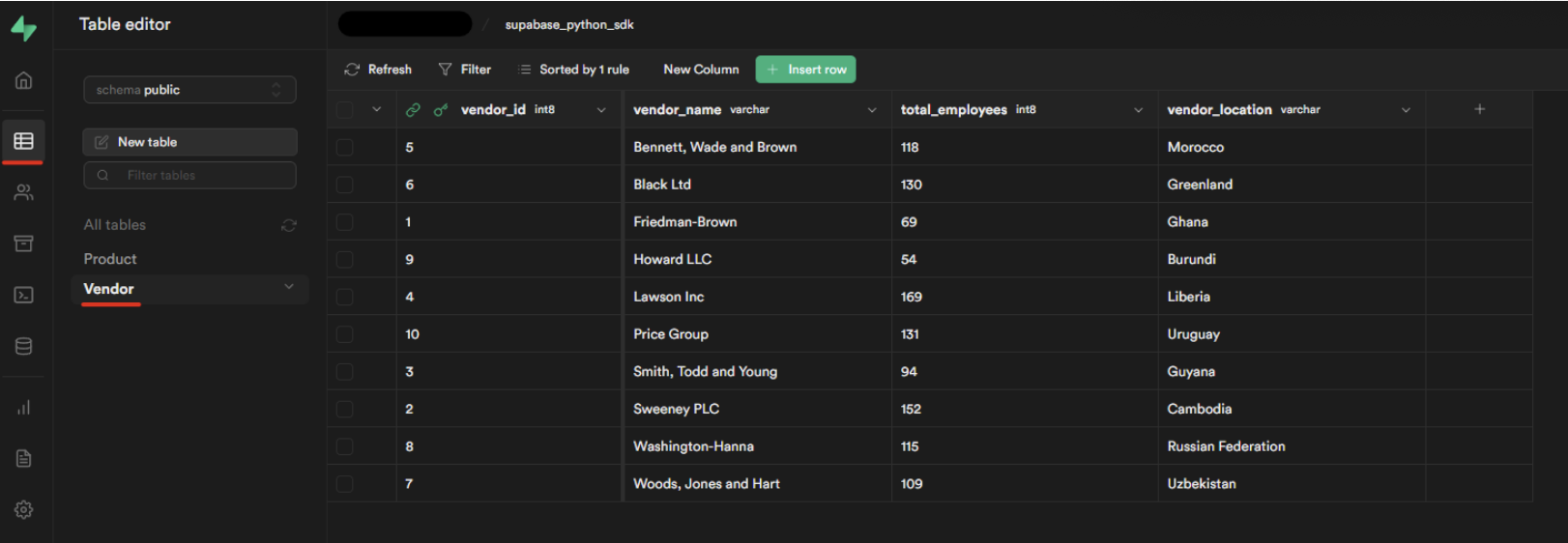
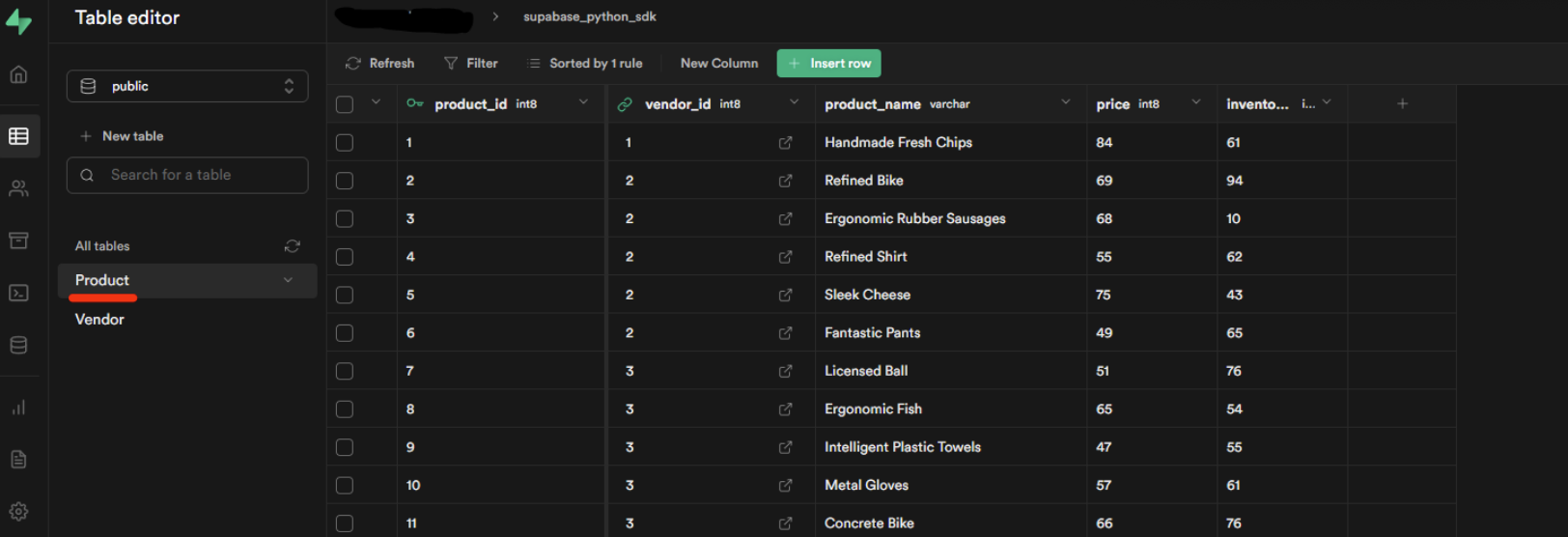 Note: In case you cannot see any of the data, you should hit the Refresh button.
Note: In case you cannot see any of the data, you should hit the Refresh button.
Conclusion
With Python, data loading into Supabase is easy. It just takes a few easy steps to get started with the Python SDK and Supabase. In the next part of this blog series, we will learn how to visualize the data that we just loaded into Supabase using Metabase. Stay tuned!
If you have any questions please reach out via Twitter or join our Discord.