.supabase.co/rest/v1/`.
The REST interface is automatically reflected from your database's schema and is:
* **Instant and auto-generated:** As you update your database the changes are immediately accessible through your API.
* **Self documenting:** Supabase generates documentation in the Dashboard which updates as you make database changes.
* **Secure:** The API is configured to work with Postgres's Row Level Security, provisioned behind an API gateway with key-auth enabled.
* **Fast:** Our benchmarks for basic reads are more than 300% faster than Firebase. The API is a very thin layer on top of Postgres, which does most of the heavy lifting.
* **Scalable:** The API can serve thousands of simultaneous requests, and works well for Serverless workloads.
The reflected API is designed to retain as much of Postgres' capability as possible including:
* Basic CRUD operations (Create/Read/Update/Delete)
* Arbitrarily deep relationships among tables/views, functions that return table types can also nest related tables/views.
* Works with Postgres Views, Materialized Views and Foreign Tables
* Works with Postgres Functions
* User defined computed columns and computed relationships
* The Postgres security model - including Row Level Security, Roles, and Grants.
The REST API resolves all requests to a single SQL statement leading to fast response times and high throughput.
# Auth
Use Supabase to authenticate and authorize your users.
Supabase Auth makes it easy to implement authentication and authorization in your app. We provide client SDKs and API endpoints to help you create and manage users.
Your users can use many popular Auth methods, including password, magic link, one-time password (OTP), social login, and single sign-on (SSO).
## About authentication and authorization
Authentication and authorization are the core responsibilities of any Auth system.
* **Authentication** means checking that a user is who they say they are.
* **Authorization** means checking what resources a user is allowed to access.
Supabase Auth uses [JSON Web Tokens (JWTs)](/docs/guides/auth/jwts) for authentication. For a complete reference of all JWT fields, see the [JWT Fields Reference](/docs/guides/auth/jwt-fields). Auth integrates with Supabase's database features, making it easy to use [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for authorization.
## The Supabase ecosystem
You can use Supabase Auth as a standalone product, but it's also built to integrate with the Supabase ecosystem.
Auth uses your project's Postgres database under the hood, storing user data and other Auth information in a special schema. You can connect this data to your own tables using triggers and foreign key references.
Auth also enables access control to your database's automatically generated [REST API](/docs/guides/api). When using Supabase SDKs, your data requests are automatically sent with the user's Auth Token. The Auth Token scopes database access on a row-by-row level when used along with [RLS policies](/docs/guides/database/postgres/row-level-security).
## Providers
Supabase Auth works with many popular Auth methods, including Social and Phone Auth using third-party providers. See the following sections for a list of supported third-party providers.
### Social Auth
You can also add any OAuth2 or OIDC-compatible identity provider using [Custom OAuth/OIDC Providers](/docs/guides/auth/custom-oauth-providers).
### Phone Auth
## Pricing
Charges apply to Monthly Active Users (MAU), Monthly Active Third-Party Users (Third-Party MAU), and Monthly Active SSO Users (SSO MAU) and Advanced MFA Add-ons. For a detailed breakdown of how these charges are calculated, refer to the following pages:
* [Pricing MAU](/docs/guides/platform/manage-your-usage/monthly-active-users)
* [Pricing Third-Party MAU](/docs/guides/platform/manage-your-usage/monthly-active-users-third-party)
* [Pricing SSO MAU](/docs/guides/platform/manage-your-usage/monthly-active-users-sso)
* [Advanced MFA - Phone](/docs/guides/platform/manage-your-usage/advanced-mfa-phone)
# Local Dev with CLI
Developing locally using the Supabase CLI.
You can use the Supabase CLI to run the entire Supabase stack locally on your machine, by running `supabase init` and then `supabase start`. To install the CLI, see the [installation guide](/docs/guides/cli/getting-started#installing-the-supabase-cli).
The Supabase CLI provides tools to develop your project locally, deploy to the Supabase Platform, handle database migrations, and generate types directly from your database schema.
## Resources
{[
{
name: 'Supabase CLI',
description:
'The Supabase CLI provides tools to develop manage your Supabase projects from your local machine.',
href: 'https://github.com/supabase/cli',
},
{
name: 'GitHub Action',
description: ' A GitHub action for interacting with your Supabase projects using the CLI.',
href: 'https://github.com/supabase/setup-cli',
},
].map((x) => (
{x.description}
))}
{[
{
name: 'With supabase-js',
description: 'Use the Supabase client inside your Edge Function.',
href: '/guides/functions/auth',
},
{
name: 'Type-Safe SQL with Kysely',
description:
'Combining Kysely with Deno Postgres gives you a convenient developer experience for interacting directly with your Postgres database.',
href: '/guides/functions/kysely-postgres',
},
{
name: 'Monitoring with Sentry',
description: 'Monitor Edge Functions with the Sentry Deno SDK.',
href: '/guides/functions/examples/sentry-monitoring',
},
{
name: 'With CORS headers',
description: 'Send CORS headers for invoking from the browser.',
href: '/guides/functions/cors',
},
{
name: 'React Native with Stripe',
description: 'Full example for using Supabase and Stripe, with Expo.',
href: 'https://github.com/supabase-community/expo-stripe-payments-with-supabase-functions',
},
{
name: 'Flutter with Stripe',
description: 'Full example for using Supabase and Stripe, with Flutter.',
href: 'https://github.com/supabase-community/flutter-stripe-payments-with-supabase-functions',
},
{
name: 'Building a RESTful Service API',
description:
'Learn how to use HTTP methods and paths to build a RESTful service for managing tasks.',
href: 'https://github.com/supabase/supabase/blob/master/examples/edge-functions/supabase/functions/restful-tasks/index.ts',
},
{
name: 'Working with Supabase Storage',
description: 'An example on reading a file from Supabase Storage.',
href: 'https://github.com/supabase/supabase/blob/master/examples/edge-functions/supabase/functions/read-storage/index.ts',
},
{
name: 'Open Graph Image Generation',
description: 'Generate Open Graph images with Deno and Supabase Edge Functions.',
href: '/guides/functions/examples/og-image',
},
{
name: 'OG Image Generation & Storage CDN Caching',
description: 'Cache generated images with Supabase Storage CDN.',
href: 'https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/og-image-with-storage-cdn',
},
{
name: 'Get User Location',
description: `Get user location data from user's IP address.`,
href: 'https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/location',
},
{
name: 'Cloudflare Turnstile',
description: `Protecting Forms with Cloudflare Turnstile.`,
href: '/guides/functions/examples/cloudflare-turnstile',
},
{
name: 'Connect to Postgres',
description: `Connecting to Postgres from Edge Functions.`,
href: '/guides/functions/connect-to-postgres',
},
{
name: 'GitHub Actions',
description: `Deploying Edge Functions with GitHub Actions.`,
href: '/guides/functions/examples/github-actions',
},
{
name: 'Oak Server Middleware',
description: `Request Routing with Oak server middleware.`,
href: 'https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/oak-server',
},
{
name: 'Hugging Face',
description: `Access 100,000+ Machine Learning models.`,
href: '/guides/ai/examples/huggingface-image-captioning',
},
{
name: 'Amazon Bedrock',
description: `Amazon Bedrock Image Generator`,
href: '/guides/functions/examples/amazon-bedrock-image-generator',
},
{
name: 'OpenAI',
description: `Using OpenAI in Edge Functions.`,
href: '/guides/ai/examples/openai',
},
{
name: 'Stripe Webhooks',
description: `Handling signed Stripe Webhooks with Edge Functions.`,
href: '/guides/functions/examples/stripe-webhooks',
},
{
name: 'Send emails',
description: `Send emails in Edge Functions with Resend.`,
href: '/guides/functions/examples/send-emails',
},
{
name: 'Web Stream',
description: `Server-Sent Events in Edge Functions.`,
href: 'https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/streams',
},
{
name: 'Puppeteer',
description: `Generate screenshots with Puppeteer.`,
href: '/guides/functions/examples/screenshots',
},
{
name: 'Discord Bot',
description: `Building a Slash Command Discord Bot with Edge Functions.`,
href: '/guides/functions/examples/discord-bot',
},
{
name: 'Telegram Bot',
description: `Building a Telegram Bot with Edge Functions.`,
href: '/guides/functions/examples/telegram-bot',
},
{
name: 'Upload File',
description: `Process multipart/form-data.`,
href: 'https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/file-upload-storage',
},
{
name: 'Upstash Redis',
description: `Build an Edge Functions Counter with Upstash Redis.`,
href: '/guides/functions/examples/upstash-redis',
},
{
name: 'Rate Limiting',
description: `Rate Limiting Edge Functions with Upstash Redis.`,
href: '/guides/functions/examples/rate-limiting',
},
{
name: 'Slack Bot Mention Edge Function',
description: `Slack Bot handling Slack mentions in Edge Function`,
href: '/guides/functions/examples/slack-bot-mention',
},
].map((x) => (
{x.description}
))}
{[
{
title: 'Build with AI tools',
description: 'Develop with Supabase AI-first using plugins, MCP, and skills.',
hasLightIcon: true,
href: '/guides/ai',
},
{
title: 'API Keys',
hasLightIcon: true,
href: '/guides/getting-started/api-keys',
description: 'Learn about the different API keys in Supabase and how to use them.',
},
{
title: 'Local Development',
hasLightIcon: true,
href: '/guides/cli/getting-started',
description: 'Use the Supabase CLI to develop locally and collaborate between teams.',
}
].map((resource) => {
return (
{resource.description}
)
})}
### Use cases
{[
{
title: 'AI, Vectors, and embeddings',
href: '/guides/ai#examples',
description: `Build AI-enabled applications using our Vector toolkit.`,
icon: '/docs/img/icons/openai_logo',
hasLightIcon: true,
},
{
title: 'Subscription Payments (SaaS)',
href: 'https://github.com/vercel/nextjs-subscription-payments#nextjs-subscription-payments-starter',
description: `Clone, deploy, and fully customize a SaaS subscription application with Next.js.`,
icon: '/docs/img/icons/nextjs-icon',
},
{
title: 'Partner Gallery',
href: 'https://github.com/supabase-community/partner-gallery-example#supabase-partner-gallery-example',
description: `Postgres full-text search, image storage, and more.`,
icon: '/docs/img/icons/nextjs-icon',
},
].map((item) => {
return (
{item.description}
)
})}
### Framework quickstarts
{[
{
title: 'React',
href: '/guides/getting-started/quickstarts/reactjs',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a React app.',
icon: '/docs/img/icons/react-icon',
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'Next.js',
href: '/guides/getting-started/quickstarts/nextjs',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a Next.js app.',
icon: '/docs/img/icons/nextjs-icon',
hasLightIcon: true,
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'Nuxt',
href: '/guides/getting-started/quickstarts/nuxtjs',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a Nuxt app.',
icon: '/docs/img/icons/nuxt-icon',
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'Hono',
href: '/guides/getting-started/quickstarts/hono',
description:
'Learn how to create a Supabase project, add some sample data to your database, secure it with auth, and query the data from a Hono app.',
icon: '/docs/img/icons/hono-icon',
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'RedwoodJS',
href: '/guides/getting-started/quickstarts/redwoodjs',
description:
'Learn how to create a Supabase project, add some sample data to your database using Prisma migration and seeds, and query the data from a RedwoodJS app.',
icon: '/docs/img/icons/redwood-icon',
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'Flutter',
href: '/guides/getting-started/quickstarts/flutter',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a Flutter app.',
icon: '/docs/img/icons/flutter-icon',
enabled: isFeatureEnabled('sdk:dart'),
},
{
title: 'iOS SwiftUI',
href: '/guides/getting-started/quickstarts/ios-swiftui',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from an iOS app.',
icon: '/docs/img/icons/swift-icon',
enabled: isFeatureEnabled('sdk:swift'),
},
{
title: 'Android Kotlin',
href: '/guides/getting-started/quickstarts/kotlin',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from an Android Kotlin app.',
icon: '/docs/img/icons/kotlin-icon',
enabled: isFeatureEnabled('sdk:kotlin'),
},
{
title: 'SvelteKit',
href: '/guides/getting-started/quickstarts/sveltekit',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a SvelteKit app.',
icon: '/docs/img/icons/svelte-icon',
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'SolidJS',
href: '/guides/getting-started/quickstarts/solidjs',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a SolidJS app.',
icon: '/docs/img/icons/solidjs-icon',
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'Vue',
href: '/guides/getting-started/quickstarts/vue',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a Vue app.',
icon: '/docs/img/icons/vuejs-icon',
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'TanStack Start',
href: '/guides/getting-started/quickstarts/tanstack',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a TanStack Start app.',
icon: '/docs/img/icons/tanstack-icon',
hasLightIcon: true,
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
{
title: 'Refine',
href: '/guides/getting-started/quickstarts/refine',
description:
'Learn how to create a Supabase project, add some sample data to your database, and query the data from a Refine app.',
icon: '/docs/img/icons/refine-icon',
enabled: isFeatureEnabled('docs:framework_quickstarts'),
},
]
.filter((item) => item.enabled !== false)
.map((item) => {
return (
{item.description}
)
})}
### Web app demos
{
[
{
title: 'Next.js',
href: '/guides/getting-started/tutorials/with-nextjs',
description:
'Learn how to build a user management app with Next.js and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/nextjs-icon',
hasLightIcon: true,
},
{
title: 'React',
href: '/guides/getting-started/tutorials/with-react',
description:
'Learn how to build a user management app with React and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/react-icon',
},
{
title: 'Vue 3',
href: '/guides/getting-started/tutorials/with-vue-3',
description:
'Learn how to build a user management app with Vue 3 and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/vuejs-icon',
},
{
title: 'Nuxt 3',
href: '/guides/getting-started/tutorials/with-nuxt-3',
description:
'Learn how to build a user management app with Nuxt 3 and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/nuxt-icon',
},
{
title: 'Angular',
href: '/guides/getting-started/tutorials/with-angular',
description:
'Learn how to build a user management app with Angular and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/angular-icon',
},
{
title: 'RedwoodJS',
href: '/guides/getting-started/tutorials/with-redwoodjs',
description:
'Learn how to build a user management app with RedwoodJS and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/redwood-icon',
},
{
title: 'Svelte',
href: '/guides/getting-started/tutorials/with-svelte',
description:
'Learn how to build a user management app with Svelte and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/svelte-icon',
},
{
title: 'SvelteKit',
href: '/guides/getting-started/tutorials/with-sveltekit',
description:
'Learn how to build a user management app with SvelteKit and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/svelte-icon',
},
{
title: 'Refine',
href: '/guides/getting-started/tutorials/with-refine',
description:
'Learn how to build a user management app with Refine and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/refine-icon',
}
]
.map((item) => {
return (
{item.description}
)
})}
### Mobile tutorials
{[
{
title: 'Flutter',
href: '/guides/getting-started/tutorials/with-flutter',
description:
'Learn how to build a user management app with Flutter and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/flutter-icon',
enabled: isFeatureEnabled('sdk:dart')
},
{
title: 'Expo React Native',
href: '/guides/getting-started/tutorials/with-expo-react-native',
description:
'Learn how to build a user management app with Expo React Native and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/expo-icon',
hasLightIcon: true,
enabled: true
},
{
title: 'Expo React Native Social Auth',
href: '/guides/getting-started/tutorials/with-expo-react-native-social-auth',
description:
'Learn how to implement social authentication in an app with Expo React Native and Supabase Database and Auth functionality.',
icon: '/docs/img/icons/expo-icon',
hasLightIcon: true
},
{
title: 'Android Kotlin',
href: '/guides/getting-started/tutorials/with-kotlin',
description:
'Learn how to build a product management app with Android and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/kotlin-icon',
enabled: isFeatureEnabled('sdk:kotlin')
},
{
title: 'iOS Swift',
href: '/guides/getting-started/tutorials/with-swift',
description:
'Learn how to build a user management app with iOS and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/swift-icon',
enabled: isFeatureEnabled('sdk:swift')
},
{
title: 'Ionic React',
href: '/guides/getting-started/tutorials/with-ionic-react',
description:
'Learn how to build a user management app with Ionic React and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/ionic-icon',
enabled: true
},
{
title: 'Ionic Vue',
href: '/guides/getting-started/tutorials/with-ionic-vue',
description:
'Learn how to build a user management app with Ionic Vue and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/ionic-icon',
enabled: true
},
{
title: 'Ionic Angular',
href: '/guides/getting-started/tutorials/with-ionic-angular',
description:
'Learn how to build a user management app with Ionic Angular and Supabase Database, Auth, and Storage functionality.',
icon: '/docs/img/icons/ionic-icon',
enabled: true
}
]
.filter((item) => item.enabled !== false)
.map((item) => {
return (
{item.description}
)
})}
# Integrations
Supabase integrates with many of your favorite third-party services.
## Vercel Marketplace
Create and manage your Supabase projects directly through Vercel. [Get started with Vercel](/docs/guides/integrations/vercel-marketplace).
## Supabase Marketplace
Browse tools for extending your Supabase project. [Browse the Supabase Marketplace](/partners/integrations).
# Local Development & CLI
Learn how to develop locally and use the Supabase CLI
Develop locally while running the Supabase stack on your machine.
As a prerequisite, you must install a container runtime compatible with Docker APIs.
* [Docker Desktop](https://docs.docker.com/desktop/) (macOS, Windows, Linux)
* [Rancher Desktop](https://rancherdesktop.io/) (macOS, Windows, Linux)
* [Podman](https://podman.io/) (macOS, Windows, Linux)
* [OrbStack](https://orbstack.dev/) (macOS)
## Quickstart
1. Install the Supabase CLI:
```sh
npm install supabase --save-dev
```
```sh
NODE_OPTIONS=--no-experimental-fetch yarn add supabase --dev
```
```sh
pnpm add supabase --save-dev --allow-build=supabase
```
The `--allow-build=supabase` flag is required on pnpm version 10 or higher. If you're using an older version of pnpm, omit this flag.
```sh
brew install supabase/tap/supabase
```
2. In your repo, initialize the Supabase project:
```sh
npx supabase init
```
```sh
yarn supabase init
```
```sh
pnpx supabase init
```
```sh
supabase init
```
3. Start the Supabase stack:
```sh
npx supabase start
```
```sh
yarn supabase start
```
```sh
pnpx supabase start
```
```sh
supabase start
```
4. View your local Supabase instance at [http://localhost:54323](http://localhost:54323).
If your local development machine is connected to an untrusted public network, you should create a separate Docker network and bind to 127.0.0.1 before starting the local development stack. This restricts network access to only your localhost machine.
```sh
docker network create -o 'com.docker.network.bridge.host_binding_ipv4=127.0.0.1' local-network
npx supabase start --network-id local-network
```
You should never expose your local development stack publicly.
## Local development
Local development with Supabase allows you to work on your projects in a self-contained environment on your local machine. Working locally has several advantages:
1. Faster development: You can make changes and see results instantly without waiting for remote deployments.
2. Offline work: You can continue development even without an internet connection.
3. Cost-effective: Local development is free and doesn't consume your project's quota.
4. Enhanced privacy: Sensitive data remains on your local machine during development.
5. Easy testing: You can experiment with different configurations and features without affecting your production environment.
To get started with local development, you'll need to install the [Supabase CLI](#cli) and Docker. The Supabase CLI allows you to start and manage your local Supabase stack, while Docker is used to run the necessary services.
Once set up, you can initialize a new Supabase project, start the local stack, and begin developing your application using local Supabase services. This includes access to a local Postgres database, Auth, Storage, and other Supabase features.
## CLI
The Supabase CLI is a powerful tool that enables developers to manage their Supabase projects directly from the terminal. It provides a suite of commands for various tasks, including:
* Setting up and managing local development environments
* Generating TypeScript types for your database schema
* Handling database migrations
* Managing environment variables and secrets
* Deploying your project to the Supabase platform
With the CLI, you can streamline your development workflow, automate repetitive tasks, and maintain consistency across different environments. It's an essential tool for both local development and CI/CD pipelines.
See the [CLI Getting Started guide](/docs/guides/local-development/cli/getting-started) for more information.
# Supabase Platform
Supabase is a hosted platform which makes it very simple to get started without needing to manage any infrastructure.
Visit [supabase.com/dashboard](/dashboard) and sign in to start creating projects.
## Projects
Each project on Supabase comes with:
* A dedicated [Postgres database](/docs/guides/database)
* [Auto-generated APIs](/docs/guides/database/api)
* [Auth and user management](/docs/guides/auth)
* [Edge Functions](/docs/guides/functions)
* [Realtime API](/docs/guides/realtime)
* [Storage](/docs/guides/storage)
## Organizations
Organizations are a way to group your projects. Each organization can be configured with different team members and billing settings.
Refer to [access control](/docs/guides/platform/access-control) for more information on how to manage team members within an organization.
## Platform status
If Supabase experiences outages, we keep you as informed as possible, as early as possible. We provide the following feedback channels:
* Status page: [status.supabase.com](https://status.supabase.com/)
* RSS Feed: [status.supabase.com/history.rss](https://status.supabase.com/history.rss)
* Atom Feed: [status.supabase.com/history.atom](https://status.supabase.com/history.atom)
* Slack Alerts: You can receive updates via the RSS feed, using Slack's [built-in RSS functionality](https://slack.com/help/articles/218688467-Add-RSS-feeds-to-Slack)
`/feed subscribe https://status.supabase.com/history.atom`
Make sure to review our [SLA](/docs/company/sla) for details on our commitment to Platform Stability.
# Supabase Queues
Durable Message Queues with Guaranteed Delivery in Postgres
Supabase Queues is a Postgres-native durable Message Queue system with guaranteed delivery built on the [pgmq database extension](https://github.com/tembo-io/pgmq). It offers developers a seamless way to persist and process Messages in the background while improving the resiliency and scalability of their applications and services.
Queues couples the reliability of Postgres with the simplicity Supabase's platform and developer experience, enabling developers to manage Background Tasks with zero configuration.
## Features
* **Postgres Native**
Built on top of the `pgmq` database extension, create and manage Queues with any Postgres tooling.
* **Guaranteed Message Delivery**
Messages added to Queues are guaranteed to be delivered to your consumers.
* **Exactly Once Message Delivery**
A Message is delivered exactly once to a consumer within a customizable visibility window.
* **Message Durability and Archival**
Messages are stored in Postgres and you can choose to archive them for analytical or auditing
purposes.
* **Granular Authorization**
Control client-side consumer access to Queues with API permissions and Row Level Security (RLS)
policies.
* **Queue Management and Monitoring**
Create, manage, and monitor Queues and Messages in the Supabase Dashboard.
## Resources
* [Quickstart](/docs/guides/queues/quickstart)
* [API Reference](/docs/guides/queues/api)
* [`pgmq` GitHub Repository](https://github.com/tembo-io/pgmq)
# Realtime
Send and receive messages to connected clients.
Supabase provides a globally distributed [Realtime](https://github.com/supabase/realtime) service with the following features:
* [Broadcast](/docs/guides/realtime/broadcast): Send low-latency messages between clients. Perfect for real-time messaging, database changes, cursor tracking, game events, and custom notifications.
* [Presence](/docs/guides/realtime/presence): Track and synchronize user state across clients. Ideal for showing who's online, or active participants.
* [Postgres Changes](/docs/guides/realtime/postgres-changes): Listen to database changes in real-time.
## What can you build?
* **Chat applications** - Real-time messaging with typing indicators and online presence
* **Collaborative tools** - Document editing, whiteboards, and shared workspaces
* **Live dashboards** - Real-time data visualization and monitoring
* **Multiplayer games** - Synchronized game state and player interactions
* **Social features** - Live notifications, reactions, and user activity feeds
Check the [Getting Started](/docs/guides/realtime/getting_started) guide to get started.
## Examples
{[
{
name: 'Multiplayer.dev',
description: 'Showcase application displaying cursor movements and chat messages using Broadcast.',
href: 'https://multiplayer.dev',
},
{
name: 'Chat',
description: 'Supabase UI chat component using Broadcast to send message between users.',
href: 'https://supabase.com/ui/docs/nextjs/realtime-chat'
},
{
name: 'Avatar Stack',
description: 'Supabase UI avatar stack component using Presence to track connected users.',
href: 'https://supabase.com/ui/docs/nextjs/realtime-avatar-stack'
},
{
name: 'Realtime Cursor',
description: "Supabase UI realtime cursor component using Broadcast to share users' cursors to build collaborative applications.",
href: 'https://supabase.com/ui/docs/nextjs/realtime-cursor'
}
].map((x) => (
{x.description}
))}
{[
{
name: 'Supabase Realtime',
description: 'View the source code.',
href: 'https://github.com/supabase/realtime',
},
{
name: 'Realtime: Multiplayer Edition',
description: 'Read more about Supabase Realtime.',
href: 'https://supabase.com/blog/supabase-realtime-multiplayer-general-availability',
},
].map((x) => (
{x.description}
))}
{
[
{
title: 'Examples',
hasLightIcon: true,
href: '/guides/resources/examples',
description: 'Official GitHub examples, curated content from the community, and more.',
},
{
title: 'Glossary',
hasLightIcon: true,
href: '/guides/resources/glossary',
description: 'Definitions for terminology and acronyms used in the Supabase documentation.',
}
]
.map((resource) => {
return (
{resource.description}
)
})}
### Migrate to Supabase
{
[
{
title: 'Auth0',
icon: '/docs/img/icons/auth0-icon',
href: '/guides/resources/migrating-to-supabase/auth0',
description: 'Move your auth users from Auth0 to a Supabase project.',
hasLightIcon: true,
},
{
title: 'Firebase Auth',
icon: '/docs/img/icons/firebase-icon',
href: '/guides/resources/migrating-to-supabase/firebase-auth',
description: 'Move your auth users from a Firebase project to a Supabase project.',
},
{
title: 'Firestore Data',
icon: '/docs/img/icons/firebase-icon',
href: '/guides/resources/migrating-to-supabase/firestore-data',
description: 'Migrate the contents of a Firestore collection to a single Postgres table.',
},
{
title: 'Firebase Storage',
icon: '/docs/img/icons/firebase-icon',
href: '/guides/resources/migrating-to-supabase/firebase-storage',
description: 'Convert your Firebase Storage files to Supabase Storage.'
},
{
title: 'Heroku',
icon: '/docs/img/icons/heroku-icon',
href: '/guides/resources/migrating-to-supabase/heroku',
description: 'Migrate your Heroku Postgres database to Supabase.'
},
{
title: 'Render',
icon: '/docs/img/icons/render-icon',
href: '/guides/resources/migrating-to-supabase/render',
description: 'Migrate your Render Postgres database to Supabase.'
},
{
title: 'Amazon RDS',
icon: '/docs/img/icons/aws-rds-icon',
href: '/guides/resources/migrating-to-supabase/amazon-rds',
description: 'Migrate your Amazon RDS database to Supabase.'
},
{
title: 'Postgres',
icon: '/docs/img/icons/postgres-icon',
href: '/guides/resources/migrating-to-supabase/postgres',
description: 'Migrate your Postgres database to Supabase.'
},
{
title: 'MySQL',
icon: '/docs/img/icons/mysql-icon',
href: '/guides/resources/migrating-to-supabase/mysql',
description: 'Migrate your MySQL database to Supabase.'
},
{
title: 'Microsoft SQL Server',
icon: '/docs/img/icons/mssql-icon',
href: '/guides/resources/migrating-to-supabase/mssql',
description: 'Migrate your Microsoft SQL Server database to Supabase.'
}
]
.map((product) => {
return (
{product.description}
)
})}
### Postgres resources
{
[
{
title: 'Managing Indexes',
hasLightIcon: true,
href: '/guides/database/postgres/indexes',
description: 'Improve query performance using various index types in Postgres.'
},
{
title: 'Cascade Deletes',
hasLightIcon: true,
href: '/guides/database/postgres/cascade-deletes',
description: 'Understand the types of foreign key constraint deletes.'
},
{
title: 'Drop all tables in schema',
hasLightIcon: true,
href: '/guides/database/postgres/dropping-all-tables-in-schema',
description: 'Delete all tables in a given schema.'
},
{
title: 'Select first row per group',
hasLightIcon: true,
href: '/guides/database/postgres/first-row-in-group',
description: 'Retrieve the first row in each distinct group.'
},
{
title: 'Print Postgres version',
hasLightIcon: true,
href: '/guides/database/postgres/which-version-of-postgres',
description: 'Find out which version of Postgres you are running.'
}
]
.map((resource) => {
return (
{resource.description}
)
})}
{/* end of container */}
# Supabase Security
Supabase is a hosted platform which makes it very simple to get started without needing to manage any infrastructure. The hosted platform comes with many security and compliance controls managed by Supabase.
# Compliance
Supabase is SOC 2 Type 2 compliant and regularly audited. All projects at Supabase are governed by the same set of compliance controls.
The [SOC 2 Compliance Guide](/docs/guides/security/soc-2-compliance) explains Supabase's SOC 2 responsibilities and controls in more detail.
The [HIPAA Compliance Guide](/docs/guides/security/hipaa-compliance) explains Supabase's HIPAA responsibilities. Additional [security and compliance controls](/docs/guides/deployment/shared-responsibility-model#managing-healthcare-data) for projects that deal with electronic Protected Health Information (ePHI) and require HIPAA compliance are available through the HIPAA add-on.
# Platform configuration
As a hosted platform, Supabase provides additional security controls to further enhance the security posture depending on organizations' own requirements or obligations.
These can be found under the [dedicated security page](/dashboard/org/_/security) under organization settings. And are described in greater detail [here](/docs/guides/security/platform-security).
# Product configuration
Each product offered by Supabase comes with customizable security controls and these security controls help ensure that applications built on Supabase are secure, compliant, and resilient against various threats.
The [security configuration guides](/docs/guides/security/product-security) provide detailed information for configuring individual products.
# Self-Hosting
Install and run your own Supabase on your computer, server, or cloud infrastructure.
## Get started
The fastest and recommended way to self-host Supabase is to use Docker.
Docker
Official
}
showIconBg={true}
>
Deploy Supabase within your own infrastructure using Docker Compose.
## Community-driven projects
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
There are several other options to deploy Supabase. If you're interested in helping these projects, visit our [Community](/contribute) page.
{selfHostingCommunity.map((x) => (
{x.name}
}
>
{x.description}
))}
{storageExamples.map((x) => (
{x.description}
))}
{[
{
name: 'Supabase Storage API',
description: 'View the source code.',
href: 'https://github.com/supabase/storage-api',
},
{
name: 'OpenAPI Spec',
description: 'See the Swagger Documentation for Supabase Storage.',
href: 'https://supabase.github.io/storage/',
},
].map((x) => (
{x.description}
))}
HTTP Version
Gzip
Headers |
| Datadog | HTTP | API Key
Region |
| Loki | HTTP | URL
Headers |
| Sentry | HTTP | DSN |
| Amazon S3 | AWS SDK | S3 Bucket
Region
Access Key ID
Secret Access Key
Batch Timeout |
| OTLP | HTTP | Endpoint
Protocol
Gzip
Headers |
HTTP requests are batched with a max of 250 logs or 1 second intervals, whichever happens first. Logs are compressed via Gzip if the destination supports it.
## Generic HTTP endpoint
Logs are sent as a POST request with a JSON body. Both HTTP/1 and HTTP/2 protocols are supported.
Custom headers can optionally be configured for all requests.
Note that requests are **unsigned**.
Unsigned requests to HTTP endpoints are temporary and all requests will signed in the near future.
1. Create and deploy the edge function
Generate a new edge function template and update it to log out the received JSON payload. For simplicity, we will accept any request with a Publishable Key.
```bash
supabase functions new hello-world
```
You can use this example snippet as an illustration of how the received request will be like.
```ts
import 'npm:@supabase/functions-js/edge-runtime.d.ts'
Deno.serve(async (req) => {
const data = await req.json()
console.log(`Received ${data.length} logs, first log:\n ${JSON.stringify(data[0])}`)
return new Response(JSON.stringify({ message: 'ok' }), {
headers: { 'Content-Type': 'application/json' },
})
})
```
And then deploy it with:
```bash
supabase functions deploy hello-world --project-ref [PROJECT REF]
```
This will create an infinite loop, as we are generating an additional log event that will eventually trigger a new request to this edge function. However, due to the batching nature of how Log Drain events are dispatched, the rate of edge function triggers will not increase greatly and will have an upper bound.
2. Configure the HTTP Drain
Create an HTTP drain under the [Project Settings > Log Drains](/dashboard/project/_/settings/log-drains).
* Disable the Gzip, as we want to receive the payload without compression.
* Under URL, set it to your edge function URL `https://[PROJECT REF].supabase.co/functions/v1/hello-world`
* Under Headers, set the `Authorization: Bearer [PUBLISHABLE KEY]`
Gzip payloads can be decompressed using native in-built APIs. Refer to the Edge Function [compression guide](/docs/guides/functions/compression)
```ts
import { gunzipSync } from 'node:zlib'
Deno.serve(async (req) => {
try {
// Check if the request body is gzip compressed
const contentEncoding = req.headers.get('content-encoding')
if (contentEncoding !== 'gzip') {
return new Response('Request body is not gzip compressed', {
status: 400,
})
}
// Read the compressed body
const compressedBody = await req.arrayBuffer()
// Decompress the body
const decompressedBody = gunzipSync(new Uint8Array(compressedBody))
// Convert the decompressed body to a string
const decompressedString = new TextDecoder().decode(decompressedBody)
const data = JSON.parse(decompressedString)
// Process the decompressed body as needed
console.log(`Received: ${data.length} logs.`)
return new Response('ok', {
headers: { 'Content-Type': 'text/plain' },
})
} catch (error) {
console.error('Error:', error)
return new Response('Error processing request', { status: 500 })
}
})
```
## Datadog logs
Logs sent to Datadog have the name of the log source set on the `service` field of the event and the source set to `Supabase`. Logs are gzipped before they are sent to Datadog.
The payload message is a JSON string of the raw log event, prefixed with the event timestamp.
To setup Datadog log drain, generate a Datadog API key [here](https://app.datadoghq.com/organization-settings/api-keys) and the location of your Datadog site.
1. Generate API Key in [Datadog dashboard](https://app.datadoghq.com/organization-settings/api-keys)
2. Create log drain in [Supabase dashboard](/dashboard/project/_/settings/log-drains)
3. Watch for events in the [Datadog Logs page](https://app.datadoghq.com/logs)
[Grok parser](https://docs.datadoghq.com/service_management/events/pipelines_and_processors/grok_parser?tab=matchers) matcher for extracting the timestamp to a `date` field
```
%{date("yyyy-MM-dd'T'HH:mm:ss.SSSSSSZZ"):date}
```
[Grok parser](https://docs.datadoghq.com/service_management/events/pipelines_and_processors/grok_parser?tab=matchers) matcher for converting stringified JSON to structured JSON on the `json` field.
```
%{data::json}
```
[Remapper](https://docs.datadoghq.com/service_management/events/pipelines_and_processors/remapper) for setting the log level.
```
metadata.parsed.error_severity, metadata.level
```
If you are interested in other log drains, upvote them [here](https://github.com/orgs/supabase/discussions/28324)
## Loki
Logs sent to the Loki HTTP API are specifically formatted according to the HTTP API requirements. See the official Loki HTTP API documentation for [more details](https://grafana.com/docs/loki/latest/reference/loki-http-api/#ingest-logs).
Events are batched with a maximum of 250 events per request.
The log source and product name will be used as stream labels.
The `event_message` and `timestamp` fields will be dropped from the events to avoid duplicate data.
Loki must be configured to accept **structured metadata**, and it is advised to increase the default maximum number of structured metadata fields to at least 500 to accommodate large log event payloads of different products.
## Sentry
Logs are sent to Sentry as part of [Sentry's Logging Product](https://docs.sentry.io/product/explore/logs/). Ingesting Supabase logs as Sentry errors is currently not supported.
To setup the Sentry log drain, you need to do the following:
1. Grab your DSN from your [Sentry project settings](https://docs.sentry.io/concepts/key-terms/dsn-explainer/). It should be of the format `{PROTOCOL}://{PUBLIC_KEY}:{SECRET_KEY}@{HOST}{PATH}/{PROJECT_ID}`.
2. Create log drain in [Supabase dashboard](/dashboard/project/_/settings/log-drains)
3. Watch for events in the [Sentry Logs page](https://sentry.io/explore/logs/)
All fields from the log event are attached as attributes to the Sentry log, which can be used for filtering and grouping in the Sentry UI. There are no limits to cardinality or the number of attributes that can be attached to a log.
If you are self-hosting Sentry, Sentry Logs are only supported in self-hosted version [25.9.0](https://github.com/getsentry/self-hosted/releases/tag/25.9.0) and later.
## Axiom
Logs sent to a specified Axiom's dataset as JSON of a raw log event,
with timestamp modified to be parsed by ingestion endpoint.
To set up the Axiom log drain, you have to:
1. Create a dataset for ingestion in Axiom Console -> Datasets
2. Generate an Axiom API Token with permission to ingest into the created dataset (see [Axiom docs](https://axiom.co/docs/reference/tokens#create-basic-api-token))
3. Create log drain in [Supabase dashboard](/dashboard/project/_/settings/log-drains), providing:
* Name of the dataset
* API token
4. Watch for events in the Stream panel of Axiom Console
## Amazon S3
Logs are written to an existing S3 bucket that you own.
Required configuration when creating an S3 Log Drain:
* S3 Bucket: the name of an existing S3 bucket.
* Region: the AWS region where the bucket is located.
* Access Key ID: used for authentication.
* Secret Access Key: used for authentication.
* Batch Timeout (ms): maximum time to wait before flushing a batch. Recommended 2000-5000ms.
Ensure the AWS account tied to the Access Key ID has permissions to write to the specified S3 bucket.
## OpenTelemetry protocol (OTLP)
Logs are sent to any OTLP-compatible endpoint using the OpenTelemetry Protocol over HTTP with Protocol Buffers encoding.
OTLP is an open-standard protocol for telemetry data, making it compatible with many observability platforms including:
- OpenTelemetry Collector
- Grafana Cloud
- New Relic
- Honeycomb
- Datadog (OTLP ingestion)
- Elastic
- And many more
Required configuration when creating an OTLP Log Drain:
- Endpoint: The full URL of your OTLP HTTP endpoint (typically ending in `/v1/logs`)
- Protocol: Currently only `http/protobuf` is supported
- Gzip: Enable compression to reduce bandwidth (recommended: enabled)
- Headers: Optional authentication headers (e.g., `Authorization`, `X-API-Key`)
Logs are sent as OTLP log record messages using Protocol Buffers encoding, following the [OpenTelemetry Logs specification](https://opentelemetry.io/docs/specs/otel/logs/).
Ensure your OTLP endpoint is configured to accept logs at the `/v1/logs` path with `application/x-protobuf` content type.
To receive Supabase logs with the OpenTelemetry Collector, configure an OTLP HTTP receiver:
```yaml
receivers:
otlp:
protocols:
http:
endpoint: 0.0.0.0:4318
processors:
batch:
exporters:
logging:
loglevel: debug
service:
pipelines:
logs:
receivers: [otlp]
processors: [batch]
exporters: [logging]
```
Then create a log drain in [Supabase dashboard](/dashboard/project/_/settings/log-drains) with:
- Endpoint: `https://your-collector:4318/v1/logs`
- Add authentication headers as needed for your setup
Different OTLP platforms use different authentication methods. Add headers accordingly:
**API Key Authentication:**
```
X-API-Key: your-api-key
```
**Bearer Token:**
```
Authorization: Bearer your-token
```
**Basic Authentication:**
```
Authorization: Basic base64(username:password)
```
Refer to your observability platform's documentation for specific authentication requirements.
## Pricing
For a detailed breakdown of how charges are calculated, refer to [Manage Log Drain usage](/docs/guides/platform/manage-your-usage/log-drains).
# Logging
The Supabase Platform includes a Logs Explorer that allows log tracing and debugging. Log retention is based on your [project's pricing plan](/pricing).
## Product logs
Supabase provides a logging interface specific to each product. You can use simple regular expressions for keywords and patterns to search log event messages. You can also export and download the log events matching your query as a spreadsheet.
{/* */}
[API logs](/dashboard/project/_/logs/edge-logs) show all network requests and response for the REST and GraphQL [APIs](../../guides/database/api). If [Read Replicas](/docs/guides/platform/read-replicas) are enabled, logs are automatically filtered between databases as well as the [API Load Balancer](/docs/guides/platform/read-replicas#api-load-balancer) endpoint. Logs for a specific endpoint can be toggled with the `Source` button on the upper-right section of the dashboard.
When viewing logs originating from the API Load Balancer endpoint, the upstream database or the one that eventually handles the request can be found under the `Redirect Identifier` field. This is equivalent to `metadata.load_balancer_redirect_identifier` when querying the underlying logs.
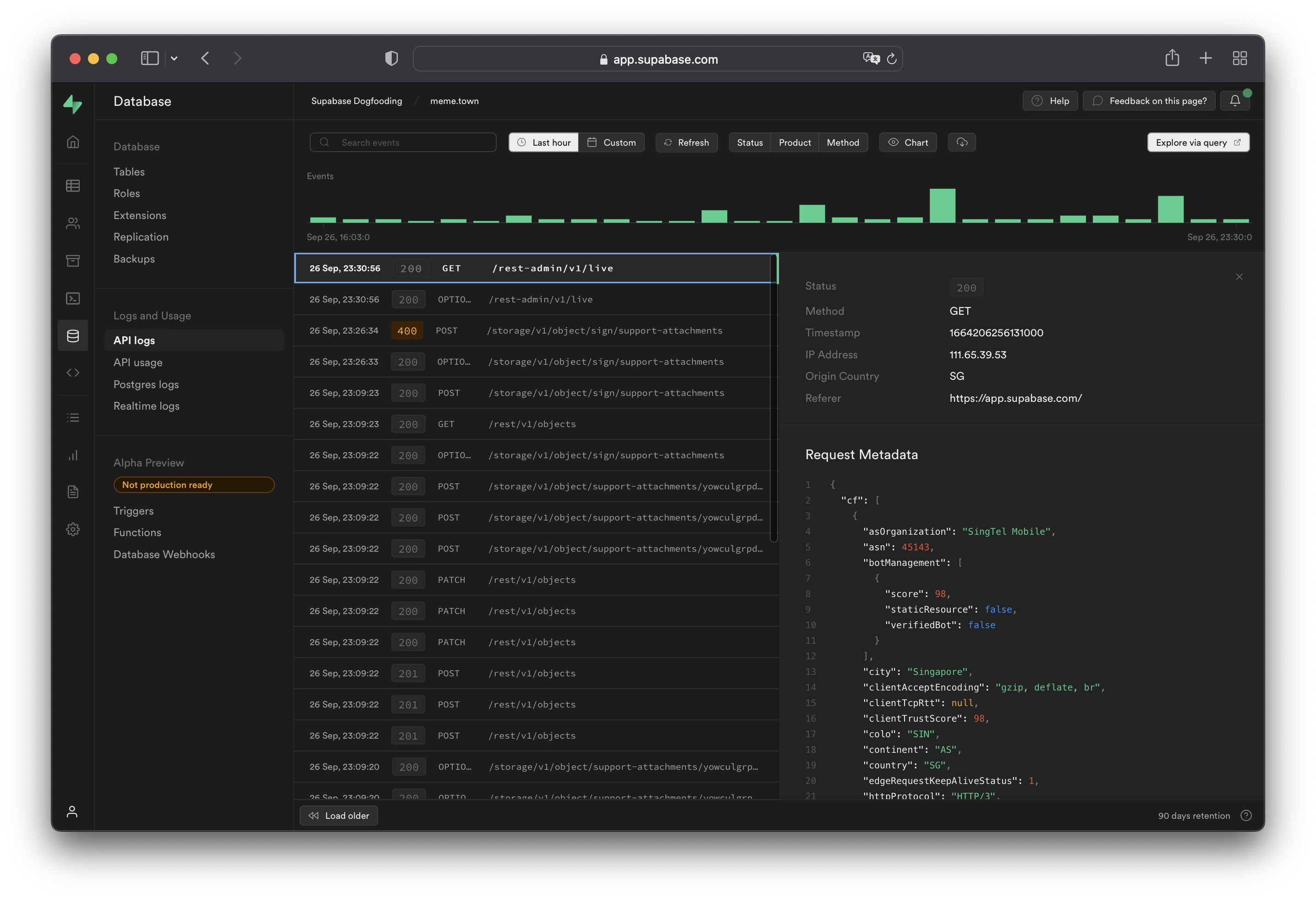
[Postgres logs](/dashboard/project/_/logs/postgres-logs) show queries and activity for your [database](../../guides/database). If [Read Replicas](/docs/guides/platform/read-replicas) are enabled, logs are automatically filtered between databases. Logs for a specific database can be toggled with the `Source` button on the upper-right section of the dashboard.
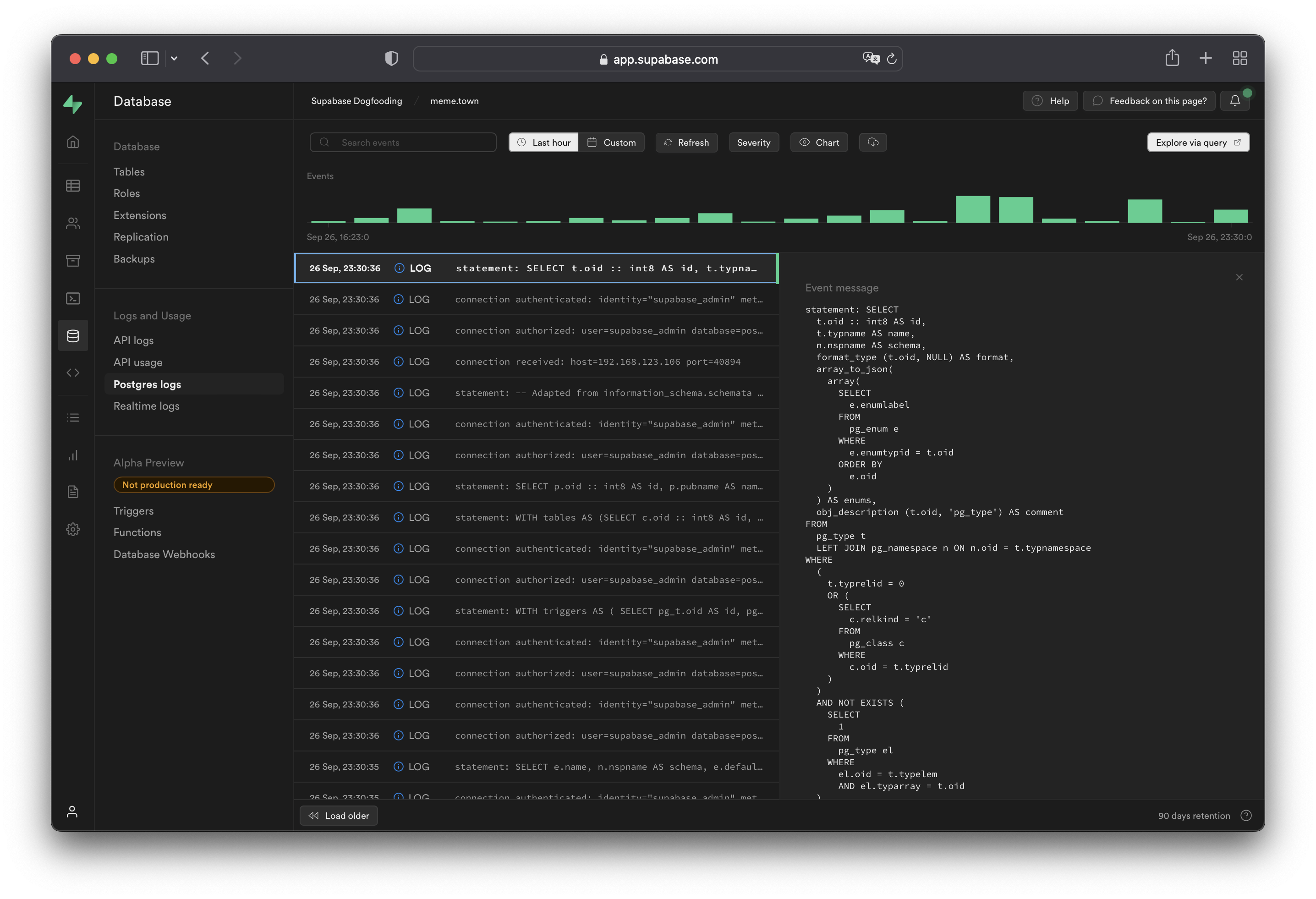
[Auth logs](/dashboard/project/_/logs/auth-logs) show all server logs for your [Auth usage](../../guides/auth).
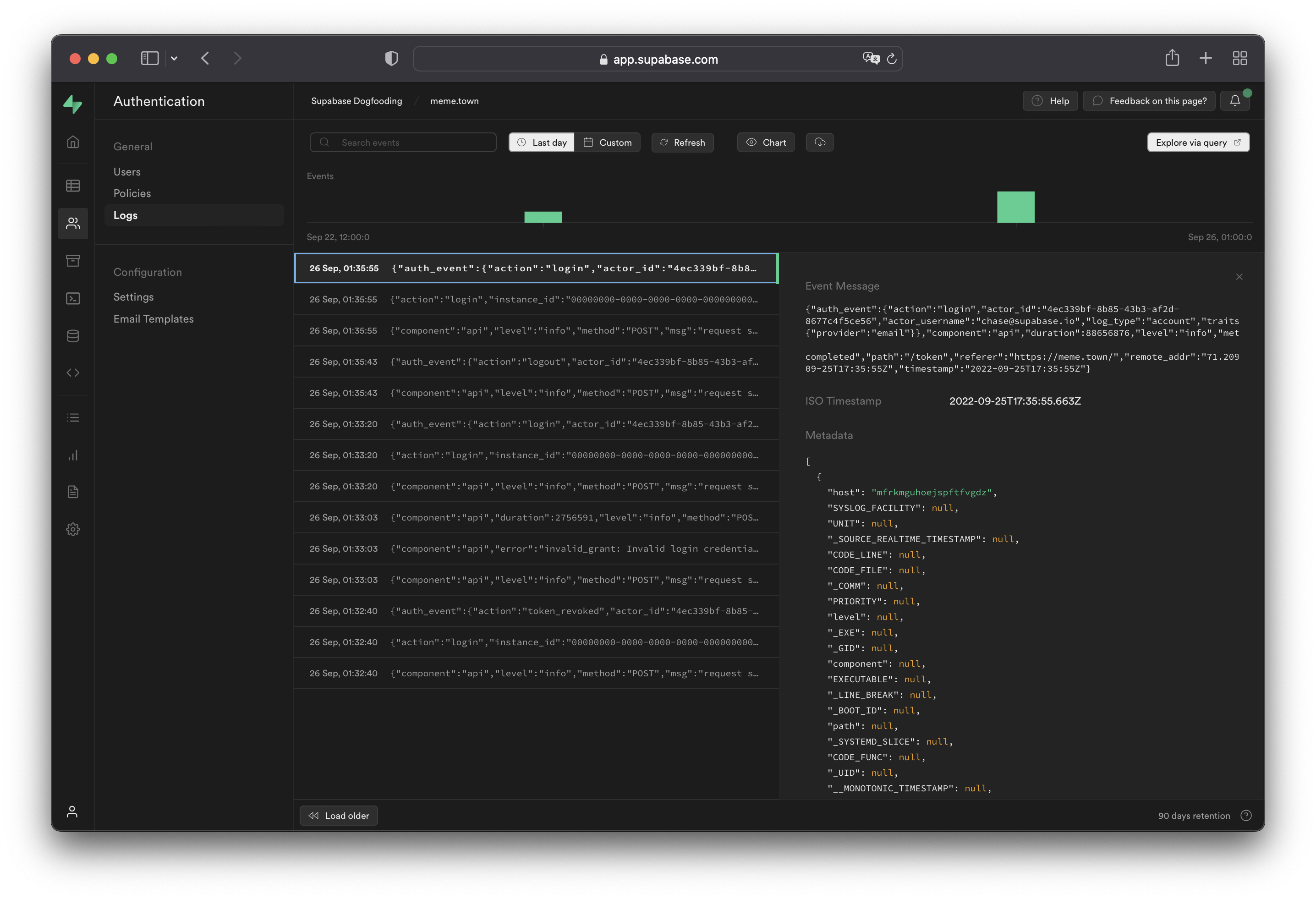
[Storage logs](/dashboard/project/_/logs/storage-logs) shows all server logs for your [Storage API](../../guides/storage).
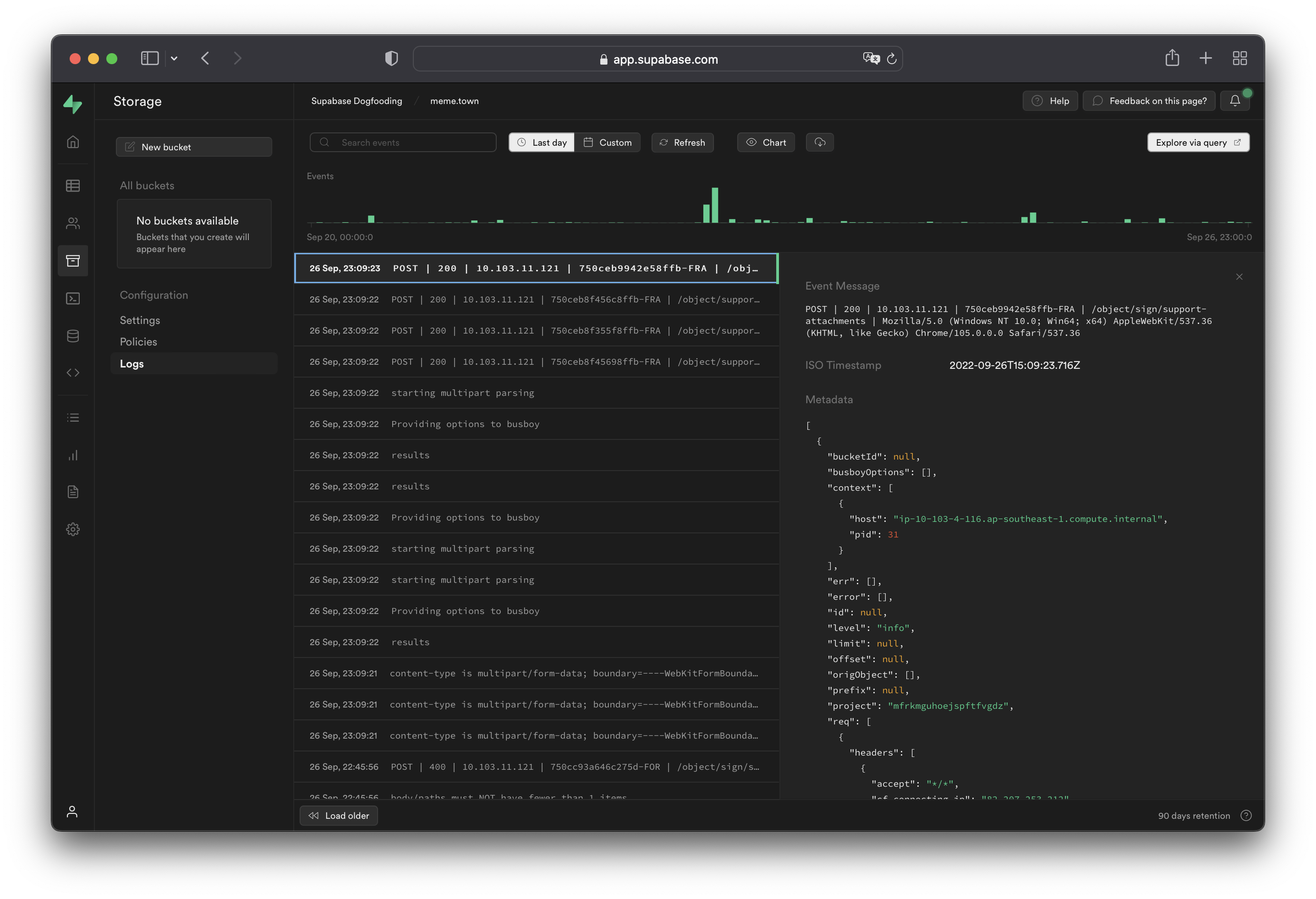
[Realtime logs](/dashboard/project/_/logs/realtime-logs) show all server logs for your [Realtime API usage](../../guides/realtime).
Realtime connections are not logged by default. Turn on [Realtime connection logs per client](#logging-realtime-connections) with the `log_level` parameter.
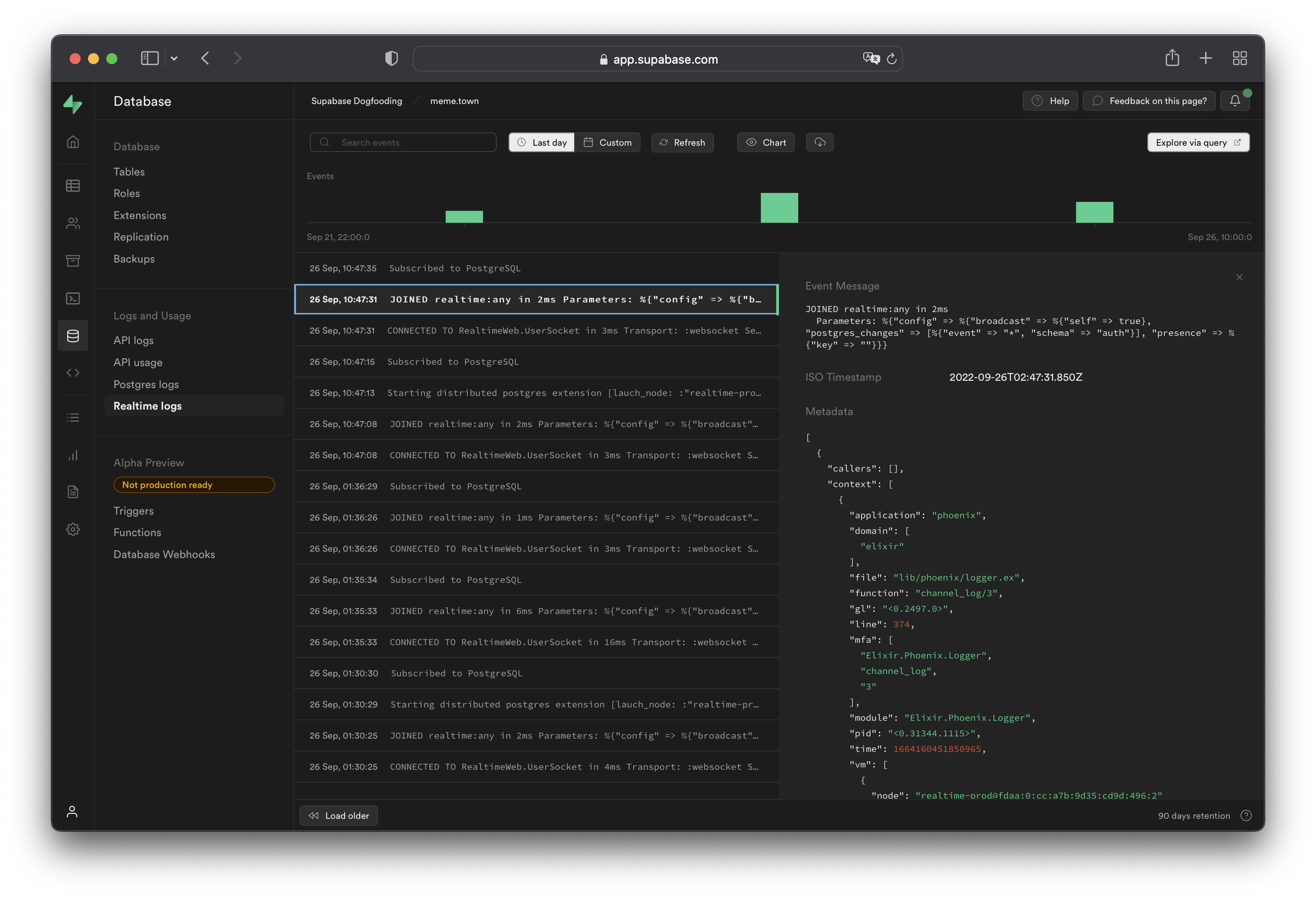
For each [Edge Function](/dashboard/project/_/functions), logs are available under the following tabs:
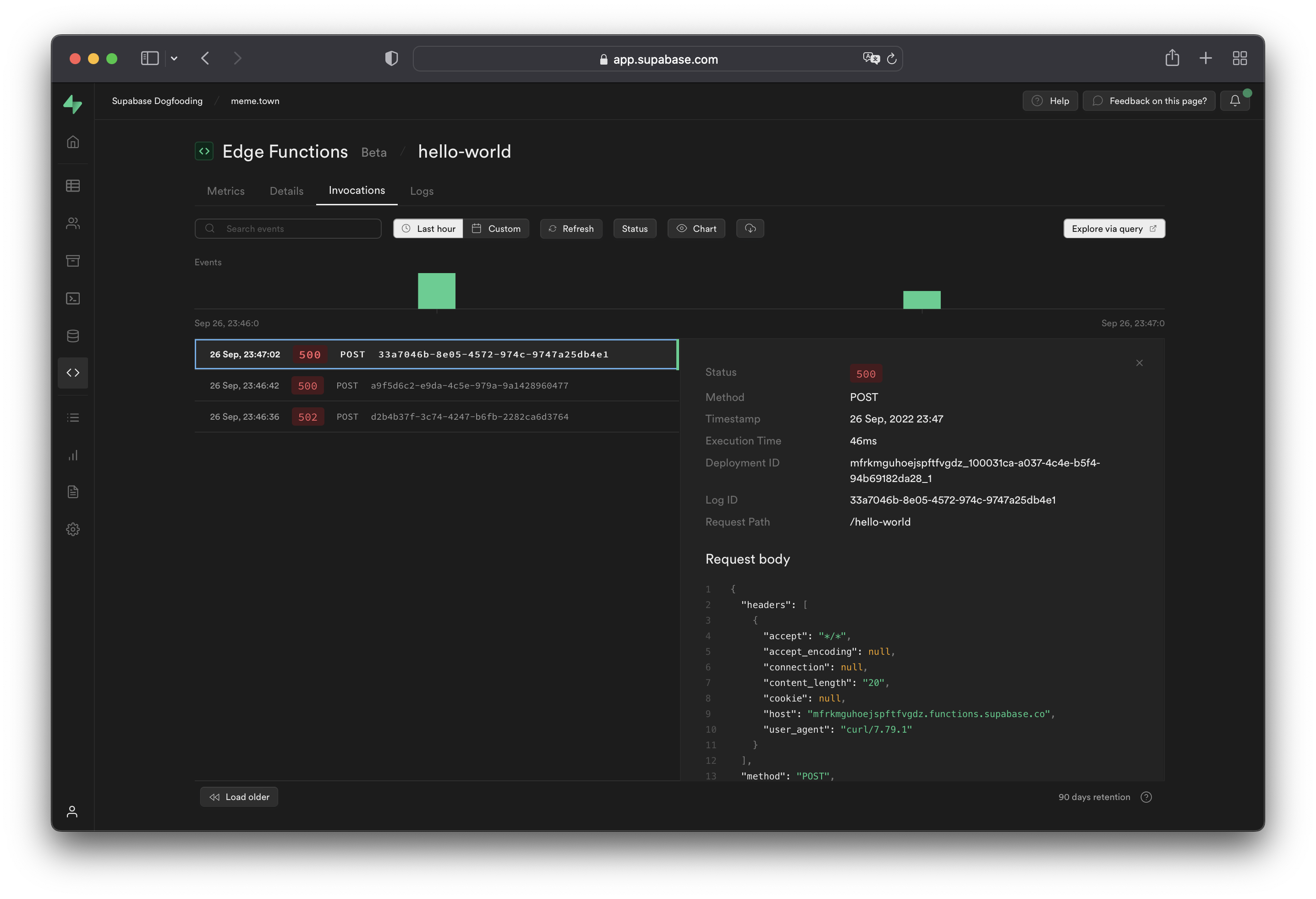
**Invocations**
The Invocations tab displays the edge logs of function calls.
**Logs**
The Logs tab displays logs emitted during function execution.
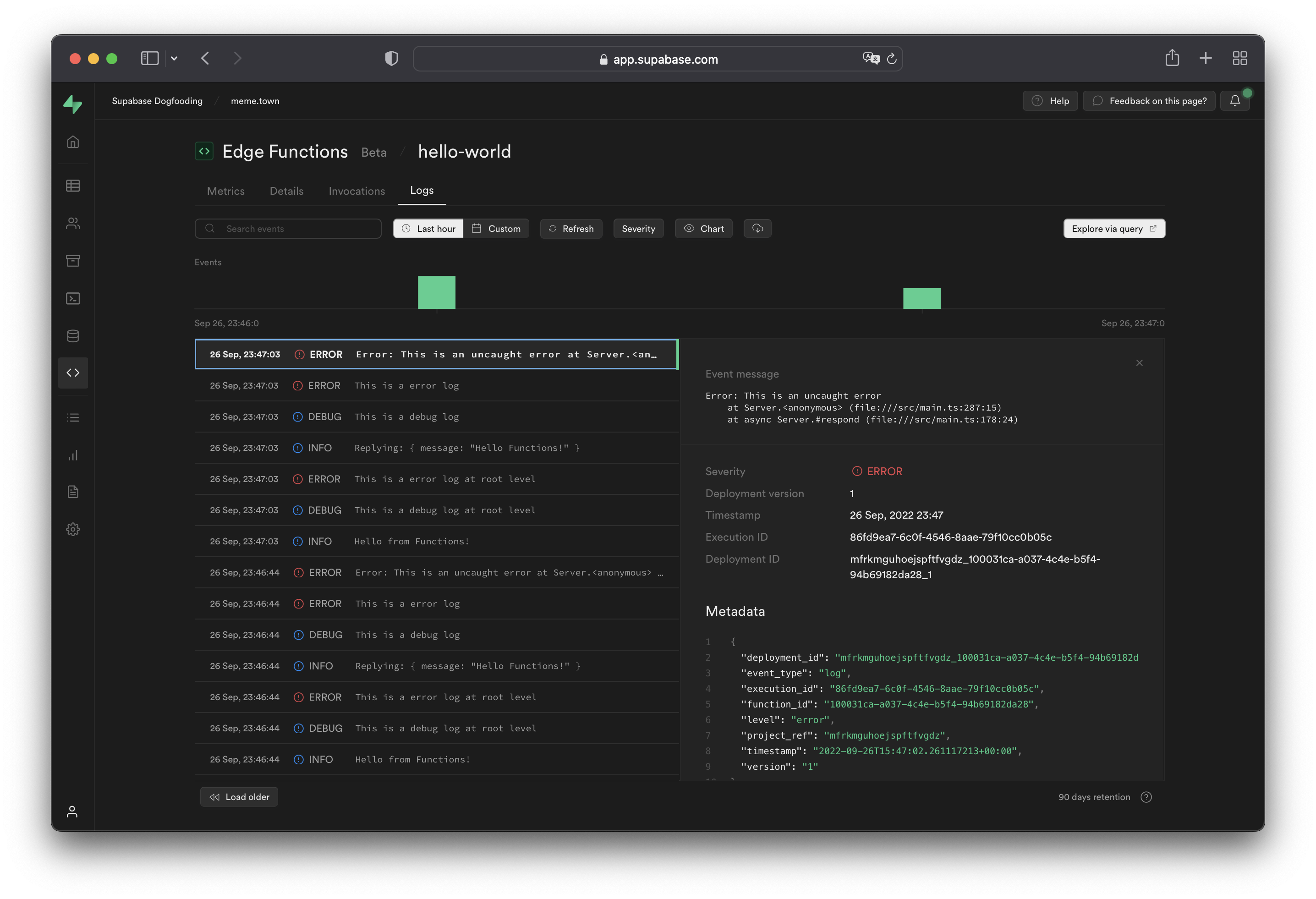
**Log Message Length**
Edge Function log messages have a max length of 10,000 characters. If you try to log a message longer than that it will be truncated.
***
## Working with API logs
[API logs](/dashboard/project/_/logs/edge-logs) run through the Cloudflare edge servers and will have attached Cloudflare metadata under the `metadata.request.cf.*` fields.
### Allowed headers
A strict list of request and response headers are permitted in the API logs. Request and response headers will still be received by the server(s) and client(s), but will not be attached to the API logs generated.
Request headers:
* `accept`
* `cf-connecting-ip`
* `cf-ipcountry`
* `host`
* `user-agent`
* `x-forwarded-proto`
* `referer`
* `content-length`
* `x-real-ip`
* `x-client-info`
* `x-forwarded-user-agent`
* `range`
* `prefer`
Response headers:
* `cf-cache-status`
* `cf-ray`
* `content-location`
* `content-range`
* `content-type`
* `content-length`
* `date`
* `transfer-encoding`
* `x-kong-proxy-latency`
* `x-kong-upstream-latency`
* `sb-gateway-mode`
* `sb-gateway-version`
### Additional request metadata
To attach additional metadata to a request, it is recommended to use the `User-Agent` header for purposes such as device or version identification.
For example:
```
node MyApp/1.2.3 (device-id:abc123)
Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0 MyApp/1.2.3 (Foo v1.3.2; Bar v2.2.2)
```
Do not log Personal Identifiable Information (PII) within the `User-Agent` header, to avoid infringing data protection privacy laws. Overly fine-grained and detailed user agents may allow fingerprinting and identification of the end user through PII.
## Logging Postgres queries
To enable query logs for other categories of statements:
1. [Enable the pgAudit extension](/dashboard/project/_/database/extensions).
2. Configure `pgaudit.log` (see below). Perform a fast reboot if needed.
3. View your query logs under [Logs > Postgres Logs](/dashboard/project/_/logs/postgres-logs).
### Configuring `pgaudit.log`
The stored value under `pgaudit.log` determines the classes of statements that are logged by [pgAudit extension](https://www.pgaudit.org/). Refer to the pgAudit documentation for the [full list of values](https://github.com/pgaudit/pgaudit/blob/master/README.md#pgauditlog).
To enable logging for function calls/do blocks, writes, and DDL statements for a single session, execute the following within the session:
```sql
-- temporary single-session config update
set pgaudit.log = 'function, write, ddl';
```
To *permanently* set a logging configuration (beyond a single session), execute the following, then perform a fast reboot:
```sql
-- equivalent permanent config update.
alter role postgres set pgaudit.log to 'function, write, ddl';
```
To help with debugging, we recommend adjusting the log scope to only relevant statements as having too wide of a scope would result in a lot of noise in your Postgres logs.
Note that in the above example, the role is set to `postgres`. To log user-traffic flowing through the [HTTP APIs](../../guides/database/api#rest-api-overview) powered by PostgREST, set your configuration values for the `authenticator`.
```sql
-- for API-related logs
alter role authenticator set pgaudit.log to 'write';
```
By default, the log level will be set to `log`. To view other levels, run the following:
```sql
-- adjust log level
alter role postgres set pgaudit.log_level to 'info';
alter role postgres set pgaudit.log_level to 'debug5';
```
Note that as per the pgAudit [log\_level documentation](https://github.com/pgaudit/pgaudit/blob/master/README.md#pgauditlog_level), `error`, `fatal`, and `panic` are not allowed.
To reset system-wide settings, execute the following, then perform a fast reboot:
```sql
-- resets stored config.
alter role postgres reset pgaudit.log
```
If any permission errors are encountered when executing `alter role postgres ...`, it is likely that your project has yet to receive the patch to the latest version of [supautils](https://github.com/supabase/supautils), which is currently being rolled out.
### `RAISE`d log messages in Postgres
Messages that are manually logged via `RAISE INFO`, `RAISE NOTICE`, `RAISE WARNING`, and `RAISE LOG` are shown in Postgres Logs. Note that only messages at or above your logging level are shown. Syncing of messages to Postgres Logs may take a few minutes.
If your logs aren't showing, check your logging level by running:
```sql
show log_min_messages;
```
Note that `LOG` is a higher level than `WARNING` and `ERROR`, so if your level is set to `LOG`, you will not see `WARNING` and `ERROR` messages.
### Limits and caveats
* Postgres log events on the Supabase Platform are limited to 100,000 characters. If a log event exceeds this limit, it will be truncated. This does not apply to self-hosting.
* Internal connection logs to Postgres within the Supabase Platform by internal services are not logged. This does not apply to self-hosting.
## Logging realtime connections
Realtime doesn't log new WebSocket connections or Channel joins by default. Enable connection logging per client by including an `info` `log_level` parameter when instantiating the Supabase client.
```javascript
import { createClient } from '@supabase/supabase-js'
const options = {
realtime: {
params: {
log_level: 'info',
},
},
}
const supabase = createClient('https://xyzcompany.supabase.co', 'sb_publishable_...', options)
```
## Logs Explorer
The [Logs Explorer](/dashboard/project/_/logs-explorer) exposes logs from each part of the Supabase stack as a separate table that can be queried and joined using SQL.
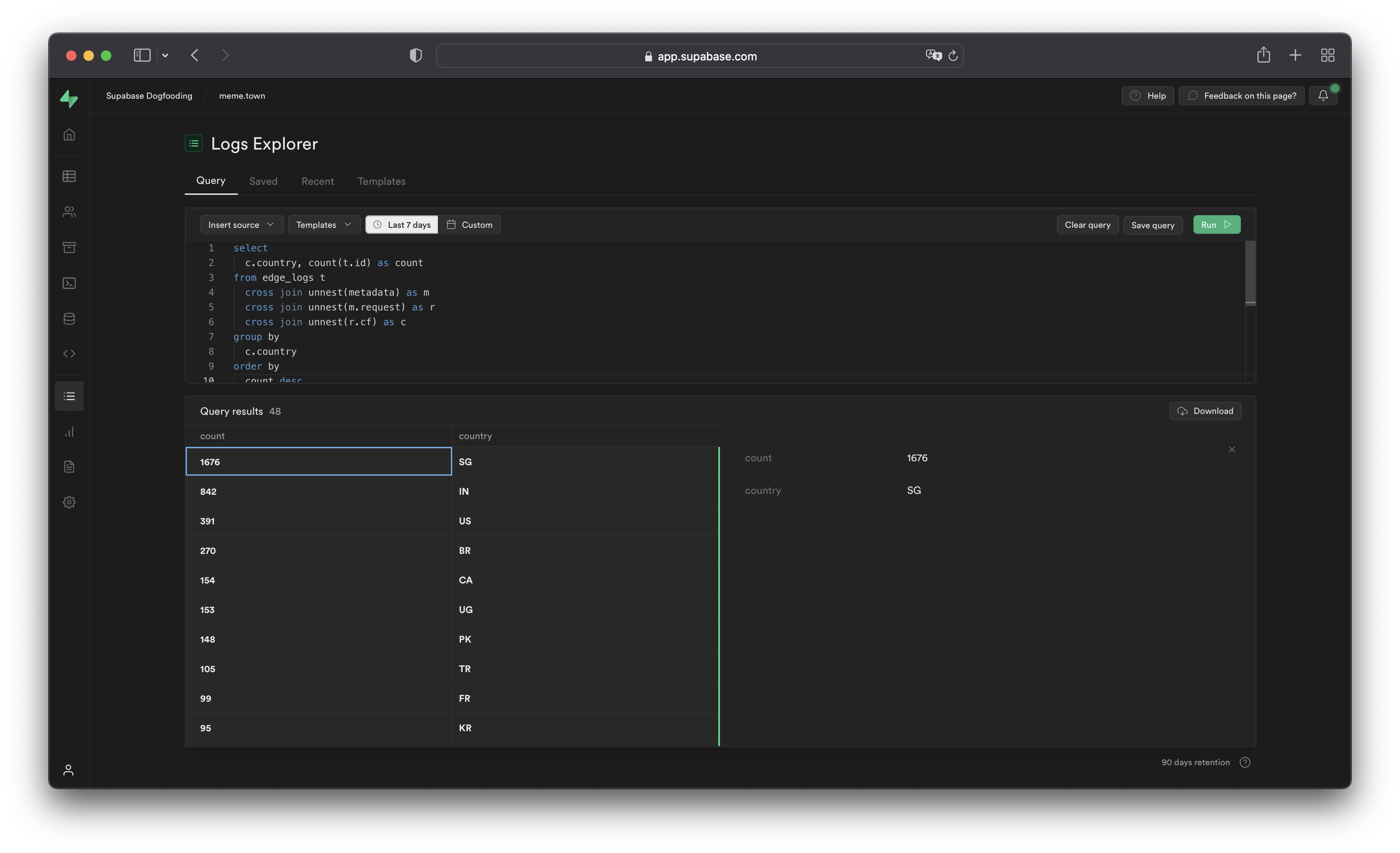
You can access the following logs from the **Sources** drop-down:
* `auth_logs`: GoTrue server logs, containing authentication/authorization activity.
* `edge_logs`: Edge network logs, containing request and response metadata retrieved from Cloudflare.
* `function_edge_logs`: Edge network logs for only edge functions, containing network requests and response metadata for each execution.
* `function_logs`: Function internal logs, containing any `console` logging from within the edge function.
* `postgres_logs`: Postgres database logs, containing statements executed by connected applications.
* `realtime_logs`: Realtime server logs, containing client connection information.
* `storage_logs`: Storage server logs, containing object upload and retrieval information.
## Querying with the Logs Explorer
The Logs Explorer uses BigQuery and supports all [available SQL functions and operators](https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators).
### Timestamp display and behavior
Each log entry is stored with a `timestamp` as a `TIMESTAMP` data type. Use the appropriate [timestamp function](https://cloud.google.com/bigquery/docs/reference/standard-sql/timestamp_functions#timestamp) to utilize the `timestamp` field in a query.
Raw top-level timestamp values are rendered as unix microsecond. To render the timestamps in a human-readable format, use the `DATETIME()` function to convert the unix timestamp display into an ISO-8601 timestamp.
```sql
-- timestamp column without datetime()
select timestamp from ....
-- 1664270180000
-- timestamp column with datetime()
select datetime(timestamp) from ....
-- 2022-09-27T09:17:10.439Z
```
### Unnesting arrays
Each log event stores metadata an array of objects with multiple levels, and can be seen by selecting single log events in the Logs Explorer. To query arrays, use `unnest()` on each array field and add it to the query as a join. This allows you to reference the nested objects with an alias and select their individual fields.
For example, to query the edge logs without any joins:
```sql
select timestamp, metadata from edge_logs as t;
```
The resulting `metadata` key is rendered as an array of objects in the Logs Explorer. In the following diagram, each box represents a nested array of objects:
{/* */}

Perform a `cross join unnest()` to work with the keys nested in the `metadata` key.
To query for a nested value, add a join for each array level:
```sql
select timestamp, request.method, header.cf_ipcountry
from
edge_logs as t
cross join unnest(t.metadata) as metadata
cross join unnest(metadata.request) as request
cross join unnest(request.headers) as header;
```
This surfaces the following columns available for selection:
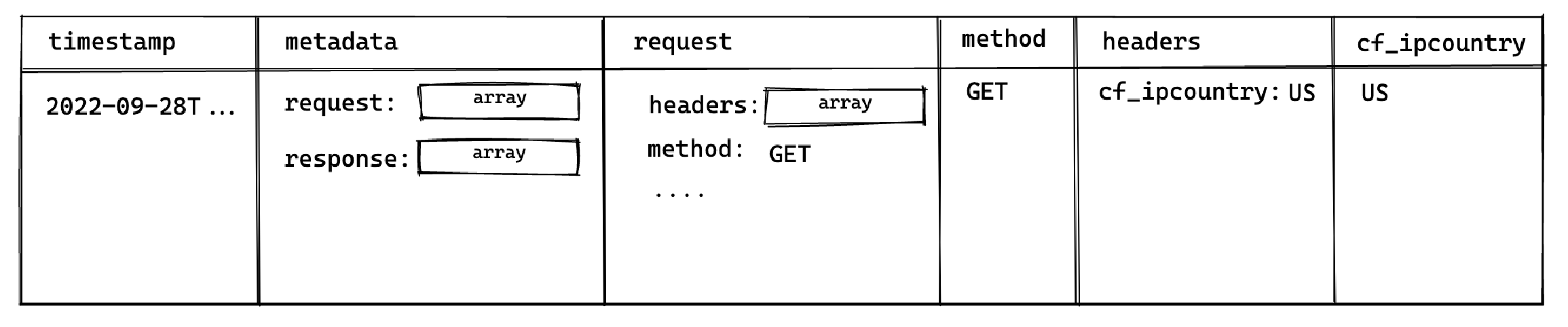
This allows you to select the `method` and `cf_ipcountry` columns. In JS dot notation, the full paths for each selected column are:
* `metadata[].request[].method`
* `metadata[].request[].headers[].cf_ipcountry`
### LIMIT and result row limitations
The Logs Explorer has a maximum of 1000 rows per run. Use `LIMIT` to optimize your queries by reducing the number of rows returned further.
### Best practices
1. Include a filter over **timestamp**
Querying your entire log history might seem appealing. For **Enterprise** customers that have a large retention range, you run the risk of timeouts due additional time required to scan the larger dataset.
2. Avoid selecting large nested objects. Select individual values instead.
When querying large objects, the columnar storage engine selects each column associated with each nested key, resulting in a large number of columns being selected. This inadvertently impacts the query speed and may result in timeouts or memory errors, especially for projects with a lot of logs.
Instead, select only the values required.
```sql
-- ❌ Avoid doing this
select
datetime(timestamp),
m as metadata -- <- metadata contains many nested keys
from
edge_logs as t
cross join unnest(t.metadata) as m;
-- ✅ Do this
select
datetime(timestamp),
r.method -- <- select only the required values
from
edge_logs as t
cross join unnest(t.metadata) as m
cross join unnest(m.request) as r;
```
### Examples and templates
The Logs Explorer includes **Templates** (available in the Templates tab or the dropdown in the Query tab) to help you get started.
For example, you can enter the following query in the SQL Editor to retrieve each user's IP address:
```sql
select datetime(timestamp), h.x_real_ip
from
edge_logs
cross join unnest(metadata) as m
cross join unnest(m.request) as r
cross join unnest(r.headers) as h
where h.x_real_ip is not null and r.method = "GET";
```
### Logs field reference
Refer to the full field reference for each available source below. Do note that in order to access each nested key, you would need to perform the [necessary unnesting joins](#unnesting-arrays)
{(logConstants) => (
{logConstants.schemas.map((schema) => (
| Path |
Type |
{schema.fields
.sort((a, b) => a.path - b.path)
.map((field) => (
| {field.path} |
{field.type} |
))}
))}
)}
# Metrics API
Every Supabase project exposes a [Prometheus](https://prometheus.io/)-compatible **Metrics API** endpoint that surfaces ~200 Postgres performance and health series. You can scrape it into any observability stack to power custom dashboards, alerting rules, or long-term retention that goes beyond what Supabase Studio provides out of the box.
The Metrics API is currently in beta. Metric names and labels might evolve as we expand the dataset, and the feature is not available in self-hosted Supabase instances.
## What you can do with the Metrics API
* Stream database CPU, IO, WAL, connection, and query stats into Prometheus-compatible systems.
* Combine Supabase metrics with application signals in Grafana, Datadog, or any other observability vendor.
* Reuse our [supabase-grafana dashboard JSON](https://github.com/supabase/supabase-grafana) to bootstrap over 200 ready-made charts.
* Build your own alerting policies (right-sizing, saturation detection, index regression, and more).
What you can do with the Metrics API} id="how-do-i-check-when-a-user-went-through-mfa" className="border-0 px-2 py-4">
Every Supabase project exposes a metrics feed at `https://.supabase.co/customer/v1/privileged/metrics`. Replace `` with the identifier from your project URL or from the dashboard sidebar.
1. Copy your project reference and confirm the base URL using the helper below.
2. Configure your collector to scrape once per minute. The endpoint already emits the full set of metrics on each request.
3. Authenticate with HTTP Basic Auth:
* **Username**: `service_role`
* **Password**: a **Secret API key** (`sb_secret_...`). You can create/copy it in [**Project Settings → API Keys**](/dashboard/project/_/settings/api-keys). For more context, see [Understanding API keys](/docs/guides/getting-started/api-keys).
Testing locally is as simple as running `curl` with your Secret API key:
```bash
curl /customer/v1/privileged/metrics \
--user 'service_role:sb_secret_...'
```
You can provision long-lived automation tokens in two ways:
* Create an account access token once at [**Account Settings > Access Tokens**](/dashboard/account/tokens) and reuse it wherever you configure observability tooling.
* **Optional**: programmatically exchange an access token for project API keys via the [Management API](/docs/reference/api/management-projects-api-keys-retrieve).
```bash
# (Optional) Exchange an account access token for project API keys
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
"https://api.supabase.com/v1/projects/$PROJECT_REF/api-keys?reveal=true"
```
## Choose your monitoring stack
Pick the workflow that best matches your tooling. Cards link to Supabase-authored guides or vendor integration docs, and some include a “Community” pill when there’s an accompanying vendor reference.
 ## Additional resources
* [Supabase Grafana repository](https://github.com/supabase/supabase-grafana) for dashboard JSON and alert examples.
* [Grafana Cloud’s Supabase integration doc](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/) (community-maintained, built on this Metrics API).
* [Datadog’s Supabase integration doc](https://docs.datadoghq.com/integrations/supabase/) (community-maintained, built on this Metrics API).
* [Log Drains ](/docs/guides/telemetry/log-drains) for exporting event-based telemetry alongside metrics.
* [Query Performance report](/dashboard/project/_/observability/query-performance) for built-in visualizations based on the same underlying metrics.
# Reports
{/* last LW we added that same report to every report page (pre-filtered) so, API Gateway report filtered by Auth will show the same data as going to Auth Report in the API Gateway section */}
Supabase Reports provide comprehensive observability for your project through dedicated monitoring dashboards for servers:
* Database
* Auth
* Storage
* Realtime
* API systems
Each report offers self-debugging tools to gain actionable insights for optimizing performance and troubleshooting issues.
Reports are only available for projects hosted on the Supabase Cloud platform and are not available for self-hosted instances.
## Using reports
You can filter reports by time range to focus on a specific period. Higher-tier plans provide access to longer time ranges.
| Time Range | Free | Pro | Team | Enterprise |
| --------------- | ---- | --- | ---- | ---------- |
| Last 10 minutes | ✅ | ✅ | ✅ | ✅ |
| Last 30 minutes | ✅ | ✅ | ✅ | ✅ |
| Last 60 minutes | ✅ | ✅ | ✅ | ✅ |
| Last 3 hours | ✅ | ✅ | ✅ | ✅ |
| Last 24 hours | ✅ | ✅ | ✅ | ✅ |
| Last 7 days | ❌ | ✅ | ✅ | ✅ |
| Last 14 days | ❌ | ❌ | ✅ | ✅ |
| Last 28 days | ❌ | ❌ | ✅ | ✅ |
***
## API gateway
The API Gateway report analyzes performance and traffic patterns managed by your project's API layer.
| Chart | Description | Key Insights |
| --------------- | ----------------------------------------- | ---------------------------------------------------------------------- |
| Total Requests | Overall API request volume | Traffic patterns and growth trends, including top routes |
| Response Errors | Error rates with 4XX and 5XX status codes | API reliability and user experience issues, including top routes |
| Response Speed | Average API response times | Performance bottlenecks and optimization targets, including top routes |
| Network Traffic | Request and response egress usage | Data transfer patterns and cost implications |
## Auth
The Auth reports focus on user authentication patterns and behaviors within your Supabase project.
| Chart | Description | Key Insights |
| ------------------------ | --------------------------------------------- | ----------------------------------------------- |
| Active Users | Count of unique users performing auth actions | User engagement and retention patterns |
| Sign In Attempts by Type | Breakdown of authentication methods used | Password vs OAuth vs magic link preferences |
| Sign Ups | Total new user registrations | Growth trends and onboarding funnel performance |
| API Gateway Auth Errors | Error rates grouped by status code | Authentication friction and security issues |
| Password Reset Requests | Volume of password recovery attempts | User experience pain points |
### Auth API Gateway
The Auth API Gateway reports focus on API requests related to authentication and user management.
| Chart | Description | Key Insights |
| --------------- | --------------------------------------------- | ---------------------------------------------------------------------------- |
| Total Requests | Count of unique users performing auth actions | User engagement and retention patterns, including top routes |
| Response Errors | Error rates with 4XX and 5XX status codes | API reliability and user experience issues, including top routes |
| Response speed | Average response time for auth requests | Performance bottlenecks and optimization opportunities, including top routes |
| Network Traffic | Ingress and egress usage | Data transfer costs and CDN effectiveness |
## Database
The Database report provides a comprehensive view into your Postgres instance's health and performance characteristics. These charts help you identify performance bottlenecks and resource constraints at a glance.
The following charts are available for Free and Pro plans:
| Chart | Available Plans | Description | Key Insights |
| ---------------------------- | --------------- | -------------------------------------------- | -------------------------------------------------------------- |
| Memory usage | Free, Pro | RAM usage percentage by the database | Memory pressure and resource utilization |
| CPU usage | Free, Pro | Average CPU usage percentage | CPU-intensive query identification |
| Disk IOPS | Free, Pro | Read/write operations per second with limits | IO bottleneck detection and workload analysis |
| Database connections | Free, Pro | Number of pooler connections to the database | Connection pool monitoring |
| Dedicated Pooler connections | All | Client connections to PgBouncer | Dedicated pooler connection monitoring |
| Shared Pooler connections | All | Client connections to the shared pooler | Shared pooler usage patterns |
| Shared Pooler connections | All | Client connections to the shared pooler | Shared pooler usage patterns |
| Disk usage | Free, Pro | Disk space consumption breakdown | Storage capacity planning |
| Database size | Free, Pro | Total database size and growth trends | Space consumption monitoring, including list of largest tables |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Advanced Telemetry
{/* TODO: This is confusing and feels contradictory */}
The following charts provide a more advanced and detailed view of your database performance and are available only for Team, Enterprise, and Platform plans.
### Memory usage
| Component | Description |
| ------------------- | ------------------------------------------------------ |
| **Used** | RAM actively used by Postgres and the operating system |
| **Cache + buffers** | Memory used for page cache and OS buffers |
| **Free** | Available unallocated memory |
How it helps debug issues:
| Issue | Description |
| ------------------------------ | ------------------------------------------------ |
| Memory pressure detection | Identify when free memory is consistently low |
| Cache effectiveness monitoring | Monitor cache performance for query optimization |
| Memory leak detection | Detect inefficient memory usage patterns |
Actions you can take:
| Action | Description |
| --------------------------------------------------------------------------- | ---------------------------------------------- |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk#compute-size) | Increase available memory resources |
| [Optimize queries](/docs/content/guides/database/query-optimization) | Reduce memory consumption of expensive queries |
| [Tune Postgres configuration](https://pgtune.leopard.in.ua) | Improve memory management settings |
| Implement application caching | Add query result caching to reduce memory load |
### CPU usage
| Category | Description |
| ---------- | ------------------------------------------------ |
| **System** | CPU time for kernel operations |
| **User** | CPU time for database queries and user processes |
| **IOWait** | CPU time waiting for disk/network IO |
| **IRQs** | CPU time handling interrupts |
| **Other** | CPU time for miscellaneous tasks |
How it helps debug issues:
| Issue | Description |
| ---------------------------------- | -------------------------------------------------- |
| CPU-intensive query identification | Identify expensive queries when User CPU is high |
| IO bottleneck detection | Detect disk/network issues when IOWait is elevated |
| System overhead monitoring | Monitor resource contention and kernel overhead |
Actions you can take:
| Action | Description |
| ---------------------------------------------------------------------------------- | ----------------------------------------------- |
| [Optimize CPU-intensive queries](/docs/content/guides/database/query-optimization) | Target queries causing high User CPU usage |
| Address IO bottlenecks | Resolve disk/network issues when IOWait is high |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk) | Increase available CPU capacity |
| [Implement proper indexing](/docs/guides/database/postgres/indexes) | Use query optimization techniques |
### Disk input/output operations per second (IOPS)
This chart displays read and write IOPS with a reference line showing your compute size's maximum IOPS capacity.
How it helps debug issues:
| Issue | Description |
| --------------------------------- | ---------------------------------------------------------------- |
| Disk IO bottleneck identification | Identify when disk IO becomes a performance constraint |
| Workload pattern analysis | Distinguish between read-heavy vs write-heavy operations |
| Performance correlation | Spot disk activity spikes that correlate with performance issues |
Actions you can take:
| Action | Description |
| -------------------------------------------------------------- | --------------------------------------------------------- |
| [Optimize indexing](/docs/guides/database/postgres/indexes) | Reduce high read IOPS through better query indexing |
| Consider [read replicas](/docs/guides/platform/read-replicas) | Distribute read-heavy workloads across multiple instances |
| Batch write operations | Reduce write IOPS by grouping database writes |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk) | Increase IOPS limits with larger compute instances |
### Disk throughput
Available on Team and Enterprise plans.
This chart displays read and write throughput (bytes per second) with a reference line showing your compute size's maximum disk throughput.
How it helps debug issues:
| Issue | Description |
| ------------------------------------ | ------------------------------------------------------- |
| Throughput bottleneck identification | Spot when disk bandwidth is saturated |
| Workload pattern analysis | Differentiate read-heavy vs write-heavy bandwidth usage |
| Performance correlation | Correlate spikes with query performance changes |
Actions you can take:
| Action | Description |
| ------------------------------------------------------------------------------------ | ------------------------------------------------------------- |
| [Optimize disk-intensive queries](/docs/content/guides/database/query-optimization) | Reduce queries that perform excessive reads/writes |
| Tune caching and batching | Minimize repeated disk access and improve throughput headroom |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk) | Increase throughput limits for sustained workloads |
| Review database design | Optimize schema and query patterns for efficiency |
| [Add strategic indexes](http://localhost:3001/docs/guides/database/postgres/indexes) | Reduce sequential scans with appropriate indexing |
### Disk size
| Component | Description |
| ------------ | --------------------------------------------------------- |
| **Database** | Space used by your actual database data (tables, indexes) |
| **WAL** | Space used by Write-Ahead Logging |
| **System** | Reserved space for system operations |
How it helps debug issues:
| Issue | Description |
| ----------------------------- | ------------------------------------------- |
| Space consumption monitoring | Track disk usage trends over time |
| Growth pattern identification | Identify rapid growth requiring attention |
| Capacity planning | Plan upgrades before hitting storage limits |
Actions you can take:
| Action | Description |
| -------------------------------------------------------------------------------- | -------------------------------------------------------------------- |
| Run [VACUUM](https://www.postgresql.org/docs/current/sql-vacuum.html) operations | Reclaim dead tuple space and optimize storage |
| Analyze large tables | Use CLI commands like `table-sizes` to identify optimization targets |
| Implement data archival | Archive historical data to reduce active storage needs |
| [Upgrade disk size](/docs/guides/platform/database-size) | Increase storage capacity when approaching limits |
### Query Performance
Links to the [Query Performance Advisory page](/docs/guides/platform/performance#examine-query-performance) in the dashboard, which provides a detailed analysis of slow database queries
### Database connections
| Connection Type | Description |
| --------------- | ------------------------------------------------ |
| **Postgres** | Direct connections from your application |
| **PostgREST** | Connections from the PostgREST API layer |
| **Reserved** | Administrative connections for Supabase services |
| **Auth** | Connections from Supabase Auth service |
| **Storage** | Connections from Supabase Storage service |
| **Other roles** | Miscellaneous database connections |
How it helps debug issues:
| Issue | Description |
| ------------------------------- | ----------------------------------------------------------- |
| Connection pool exhaustion | Identify when approaching maximum connection limits |
| Connection leak detection | Spot applications not properly closing connections |
| Service distribution monitoring | Monitor connection usage across different Supabase services |
Actions you can take:
| Action | Description |
| ------------------------------------------------------------------------------------------ | --------------------------------------------------------------- |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk#compute-size) | Increase maximum connection limits |
| Implement [connection pooling](/docs/guides/database/connecting-to-postgres#shared-pooler) | Optimize connection management for high direct connection usage |
| Review application code | Ensure proper connection handling and cleanup |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Dedicated Pooler (PgBouncer) Client Connections
Available on Team and Enterprise plans.
This chart displays the number of PgBouncer connections over time.
How it helps debug issues:
| Issue | Description |
| ------------------------------- | ----------------------------------------------------------- |
| Connection pool exhaustion | Identify when approaching maximum connection limits |
| Connection leak detection | Spot applications not properly closing connections |
| Service distribution monitoring | Monitor connection usage across different Supabase services |
Actions you can take:
| Action | Description |
| ------------------------------------------------------------------------------------------ | --------------------------------------------------------------- |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk#compute-size) | Increase maximum connection limits |
| Implement [connection pooling](/docs/guides/database/connecting-to-postgres#shared-pooler) | Optimize connection management for high direct connection usage |
| Review application code | Ensure proper connection handling and cleanup |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Shared Pooler (Supavisor) Client Connections
Available on Team and Enterprise plans.
This chart displays the number of Supavisor connections over time.
How it helps debug issues:
| Issue | Description |
| ------------------------------- | ----------------------------------------------------------- |
| Connection pool exhaustion | Identify when approaching maximum connection limits |
| Connection leak detection | Spot applications not properly closing connections |
| Service distribution monitoring | Monitor connection usage across different Supabase services |
Actions you can take:
| Action | Description |
| ------------------------------------------------------------------------------------------ | --------------------------------------------------------------- |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk#compute-size) | Increase maximum connection limits |
| Implement [connection pooling](/docs/guides/database/connecting-to-postgres#shared-pooler) | Optimize connection management for high direct connection usage |
| Review application code | Ensure proper connection handling and cleanup |
### Disk Usage
### Database size
| Component | Description |
| ------------ | --------------------------------------------------------- |
| **Database** | Space used by your actual database data (tables, indexes) |
| **WAL** | Space used by Write-Ahead Logging |
| **System** | Reserved space for system operations |
How it helps debug issues:
| Issue | Description |
| ----------------------------- | ------------------------------------------- |
| Space consumption monitoring | Track disk usage trends over time |
| Growth pattern identification | Identify rapid growth requiring attention |
| Capacity planning | Plan upgrades before hitting storage limits |
Actions you can take:
| Action | Description |
| -------------------------------------------------------------------------------- | -------------------------------------------------------------------- |
| Run [VACUUM](https://www.postgresql.org/docs/current/sql-vacuum.html) operations | Reclaim dead tuple space and optimize storage |
| Analyze large tables | Use CLI commands like `table-sizes` to identify optimization targets |
| Implement data archival | Archive historical data to reduce active storage needs |
| [Upgrade disk size](/docs/guides/platform/database-size) | Increase storage capacity when approaching limits |
## Edge Functions
The Edge Functions report provides insights into serverless function performance, execution patterns, and regional distribution across Supabase's global edge network.
| Chart | Description | Key Insights |
| ------------------------------------ | ----------------------------------------- | ---------------------------------------------- |
| Total Edge Function Invocations | Function response codes and error rates | Function reliability and error patterns |
| Edge Function Execution Status Codes | Function response codes and error rates | Function reliability and error patterns |
| Edge Function Execution Time | Average function duration and performance | Performance optimization opportunities |
| Edge Function Invocations by Region | Geographic distribution of function calls | Global usage patterns and latency optimization |
## PostgREST
The PostgREST report provides insights into RESTful API performance, request patterns, and response characteristics.
| Chart | Description | Key Insights |
| --------------- | -------------------------------------------- | ---------------------------------------------------------------------------- |
| Total Requests | HTTP requests to PostgREST endpoints | API usage alongside WebSocket activity |
| Response Errors | Error rates with 4XX and 5XX status codes | API reliability and user experience issues, including top routes |
| Response Speed | Average response time for PostgREST requests | Performance bottlenecks and optimization opportunities, including top routes |
| Network Traffic | Ingress and egress usage | Data transfer costs and CDN effectiveness |
## Realtime
The Realtime report tracks WebSocket connections, channel activity, and real-time event patterns in your Supabase project.
| Chart | Description | Key Insights |
| ---------------------------------------------------------- | --------------------------------------------------------------------------------------- | ------------------------------------------------- |
| Connected Clients | Active WebSocket connections over time | Concurrent user activity and connection stability |
| Broadcast Events | Broadcast events over time | Real-time feature usage patterns |
| Presence Events | Presence events over time | Real-time feature usage patterns |
| Postgres Changes Events | Postgres Changes events over time | Real-time feature usage patterns |
| Rate of Channel Joins | Frequency of new channel subscriptions | User engagement with real-time features |
| Message Payload Size | Median size of message payloads sent | Payload size that is being transmitted |
| Broadcast From Database Replication Lag | Median latency between database commit and broadcast when using broadcast from database | Latency to Broadcast from the database |
| Read/Write Private Channel Subscription RLS Execution Time | Median time to authorize private channels | `realtime.messages` RLS policies performance |
| Total Requests | HTTP requests to Realtime endpoints | API usage alongside WebSocket activity |
| Response Speed | Performance of Realtime API endpoints | Infrastructure optimization opportunities |
### Realtime API Gateway
The Realtime API Gateway reports focus on API requests related to Realtime functionality.
| Chart | Description | Key Insights |
| --------------- | ------------------------------------- | --------------------------------------------------------------- |
| Total Requests | HTTP requests to Realtime endpoints | API usage alongside WebSocket activity, including top routes |
| Response Errors | HTTP requests to Realtime endpoints | API usage alongside WebSocket activity, including top routes |
| Response Speed | Performance of Realtime API endpoints | Infrastructure optimization opportunities, including top routes |
## Storage
The Storage report provides visibility into how your Supabase Storage is being utilized, including request patterns, performance characteristics, and caching effectiveness.
| Chart | Description | Key Insights |
| --------------- | ------------------------------------------ | ---------------------------------------------------------------------------- |
| Total Requests | Overall request volume to Storage | Traffic patterns and usage trends, including top routes |
| Response Speed | Average response time for storage requests | Performance bottlenecks and optimization opportunities, including top routes |
| Network Traffic | Ingress and egress usage | Data transfer costs and CDN effectiveness |
| Request Caching | Cache hit rates and miss patterns | CDN performance and cost optimization, including top routes |
# Sentry integration
Integrate Sentry to monitor errors from a Supabase client
You can use [Sentry](https://sentry.io/welcome/) to monitor errors thrown from a Supabase JavaScript client. Install the [Supabase Sentry integration](https://github.com/supabase-community/sentry-integration-js) to get started.
The Sentry integration supports browser, Node, and edge environments.
## Installation
Install the Sentry integration using your package manager:
```sh
npm install @supabase/sentry-js-integration
```
```sh
yarn add @supabase/sentry-js-integration
```
```sh
pnpm add @supabase/sentry-js-integration
```
## Use
If you are using Sentry JavaScript SDK v7, reference [`supabase-community/sentry-integration-js` repository](https://github.com/supabase-community/sentry-integration-js/blob/master/README-v7.md) instead.
To use the Supabase Sentry integration, add it to your `integrations` list when initializing your Sentry client.
You can supply either the Supabase Client constructor or an already-initiated instance of a Supabase Client.
```ts
import * as Sentry from '@sentry/browser'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
],
})
```
```ts
import * as Sentry from '@sentry/browser'
import { createClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
const supabaseClient = createClient(SUPABASE_URL, SUPABASE_KEY)
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(supabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
],
})
```
All available configuration options are available in our [`supabase-community/sentry-integration-js` repository](https://github.com/supabase-community/sentry-integration-js/blob/master/README.md#options).
## Deduplicating spans
If you're already monitoring HTTP errors in Sentry, for example with the HTTP, Fetch, or Undici integrations, you will get duplicate spans for Supabase calls. You can deduplicate the spans by skipping them in your other integration:
```ts
import * as Sentry from '@sentry/browser'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
// @sentry/browser
Sentry.browserTracingIntegration({
shouldCreateSpanForRequest: (url) => {
return !url.startsWith(`${SUPABASE_URL}/rest`)
},
}),
// or @sentry/node
Sentry.httpIntegration({
tracing: {
ignoreOutgoingRequests: (url) => {
return url.startsWith(`${SUPABASE_URL}/rest`)
},
},
}),
// or @sentry/node with Fetch support
Sentry.nativeNodeFetchIntegration({
ignoreOutgoingRequests: (url) => {
return url.startsWith(`${SUPABASE_URL}/rest`)
},
}),
// or @sentry/WinterCGFetch for Next.js Proxy & Edge Functions
Sentry.winterCGFetchIntegration({
breadcrumbs: true,
shouldCreateSpanForRequest: (url) => {
return !url.startsWith(`${SUPABASE_URL}/rest`)
},
}),
],
})
```
## Example Next.js configuration
See this example for a setup with Next.js to cover browser, server, and edge environments. First, run through the [Sentry Next.js wizard](https://docs.sentry.io/platforms/javascript/guides/nextjs/#install) to generate the base Next.js configuration. Then add the Supabase Sentry Integration to all your `Sentry.init` calls with the appropriate filters.
```ts sentry.client.config.ts
import * as Sentry from '@sentry/nextjs'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
Sentry.browserTracingIntegration({
shouldCreateSpanForRequest: (url) => {
return !url.startsWith(`${process.env.NEXT_PUBLIC_SUPABASE_URL}/rest`)
},
}),
],
// Adjust this value in production, or use tracesSampler for greater control
tracesSampleRate: 1,
// Setting this option to true will print useful information to the console while you're setting up Sentry.
debug: true,
})
```
```ts sentry.server.config.ts
import * as Sentry from '@sentry/nextjs'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
Sentry.nativeNodeFetchIntegration({
breadcrumbs: true,
ignoreOutgoingRequests: (url) => {
return url.startsWith(`${process.env.NEXT_PUBLIC_SUPABASE_URL}/rest`)
},
}),
],
// Adjust this value in production, or use tracesSampler for greater control
tracesSampleRate: 1,
// Setting this option to true will print useful information to the console while you're setting up Sentry.
debug: true,
})
```
```js sentry.edge.config.ts
import * as Sentry from '@sentry/nextjs'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
Sentry.winterCGFetchIntegration({
breadcrumbs: true,
shouldCreateSpanForRequest: (url) => {
return !url.startsWith(`${process.env.NEXT_PUBLIC_SUPABASE_URL}/rest`)
},
}),
],
// Adjust this value in production, or use tracesSampler for greater control
tracesSampleRate: 1,
// Setting this option to true will print useful information to the console while you're setting up Sentry.
debug: true,
})
```
```js instrumentation.ts
// https://nextjs.org/docs/app/building-your-application/optimizing/instrumentation
export async function register() {
if (process.env.NEXT_RUNTIME === 'nodejs') {
await import('./sentry.server.config')
}
if (process.env.NEXT_RUNTIME === 'edge') {
await import('./sentry.edge.config')
}
}
```
Afterwards, build your application (`npm run build`) and start it locally (`npm run start`). You will now see the transactions being logged in the terminal when making supabase-js requests.
# Metrics API with Grafana Cloud
Grafana Cloud gives you a fully managed Prometheus endpoint plus hosted Grafana dashboards, which makes it the fastest way to explore the Supabase Metrics API without operating your own infrastructure.
Grafana maintains a [Supabase integration guide](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/) for Grafana Cloud. It runs on the same Metrics API documented here, but is community-maintained by Grafana, so feature coverage might differ from what Supabase officially supports.
## Prerequisites
* A Supabase project with access to the Metrics API (Secret API key `sb_secret_...`).
* A Grafana Cloud account with Prometheus metrics enabled (Free or Pro tier).
* A Grafana API token with the `metrics:write` and `metrics:read` scopes if you plan to push data manually.
What you can do with the Metrics API} id="how-do-i-check-when-a-user-went-through-mfa" className="border-0 px-2 py-4">
Every Supabase project exposes a metrics feed at `https://.supabase.co/customer/v1/privileged/metrics`. Replace `` with the identifier from your project URL or from the dashboard sidebar.
1. Copy your project reference and confirm the base URL using the helper below.
2. Configure your collector to scrape once per minute. The endpoint already emits the full set of metrics on each request.
3. Authenticate with HTTP Basic Auth:
* **Username**: `service_role`
* **Password**: a **Secret API key** (`sb_secret_...`). You can create/copy it in [**Project Settings → API Keys**](/dashboard/project/_/settings/api-keys). For more context, see [Understanding API keys](/docs/guides/getting-started/api-keys).
Testing locally is as simple as running `curl` with your Secret API key:
```bash
curl /customer/v1/privileged/metrics \
--user 'service_role:sb_secret_...'
```
You can provision long-lived automation tokens in two ways:
* Create an account access token once at [**Account Settings > Access Tokens**](/dashboard/account/tokens) and reuse it wherever you configure observability tooling.
* **Optional**: programmatically exchange an access token for project API keys via the [Management API](/docs/reference/api/management-projects-api-keys-retrieve).
```bash
# (Optional) Exchange an account access token for project API keys
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
"https://api.supabase.com/v1/projects/$PROJECT_REF/api-keys?reveal=true"
```
## 1. Create a Grafana Cloud stack
1. Sign in to [Grafana Cloud](https://grafana.com/auth/sign-in).
2. Create (or select) a stack that has **Prometheus Metrics** enabled (Free and Pro tiers both work for this guide).
## 2. Configure the Supabase integration
1. Navigate to **Connections → Add new connection → Supabase** inside Grafana Cloud.
2. Provide:
* Your Supabase project ref (e.g. `abcd1234`).
* The Metrics API endpoint: `https://.supabase.co/customer/v1/privileged/metrics`.
* HTTP Basic Auth credentials (`sb_secret_...`).
3. Choose the scrape interval (1 minute recommended) and test the connection. Grafana Cloud will deploy an agent in the background that scrapes the Metrics API and forwards the data to Prometheus.
If you prefer to reuse an existing Grafana Agent deployment, configure an [integration pipeline](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/) with the same URL and credentials.
## 3. Import the Supabase dashboard
1. Open your Grafana Cloud dashboard list and click **New → Import**.
2. Paste the raw contents of [`supabase-grafana/dashboard.json`](https://raw.githubusercontent.com/supabase/supabase-grafana/refs/heads/main/grafana/dashboard.json).
3. When prompted for the datasource, choose the Prometheus instance that receives the Supabase metrics.
This dashboard includes 200+ charts grouped by CPU, IO, connections, replication, WAL, and bloat indicators.
## 4. Configure alerts (optional)
The [`docs/example-alerts.md`](https://github.com/supabase/supabase-grafana/blob/main/docs/example-alerts.md) file contains suggested alert rules (disk saturation, long-running queries, replication lag, etc.). Import the alert rules into Grafana Cloud’s Alerting UI or translate them into Grafana Cloud’s managed alert rule format.
## 5. Troubleshooting
* Metrics missing? Ensure the Grafana Cloud agent can reach `https://.supabase.co` and that the selected Secret API key is still valid.
* 401 errors? Create/rotate a Secret API key in [Project Settings → API Keys](/dashboard/project/_/settings/api-keys) and update the Grafana Cloud credentials.
* Long scrape durations? Reduce label cardinality in your Grafana queries or lower the time range to focus on recent data.
# Metrics API with Prometheus & Grafana (self-hosted)
Self-hosting [Prometheus](https://prometheus.io/docs/prometheus/latest/installation/) and Grafana gives you full control over retention, alert routing, and dashboards. The Supabase Metrics API slots into any standard Prometheus scrape job, so you can run everything locally, on a VM, or inside Kubernetes.
What you can do with the Metrics API} id="how-do-i-check-when-a-user-went-through-mfa" className="border-0 px-2 py-4">
Every Supabase project exposes a metrics feed at `https://.supabase.co/customer/v1/privileged/metrics`. Replace `` with the identifier from your project URL or from the dashboard sidebar.
1. Copy your project reference and confirm the base URL using the helper below.
2. Configure your collector to scrape once per minute. The endpoint already emits the full set of metrics on each request.
3. Authenticate with HTTP Basic Auth:
* **Username**: `service_role`
* **Password**: a **Secret API key** (`sb_secret_...`). You can create/copy it in [**Project Settings → API Keys**](/dashboard/project/_/settings/api-keys). For more context, see [Understanding API keys](/docs/guides/getting-started/api-keys).
Testing locally is as simple as running `curl` with your Secret API key:
```bash
curl /customer/v1/privileged/metrics \
--user 'service_role:sb_secret_...'
```
You can provision long-lived automation tokens in two ways:
* Create an account access token once at [**Account Settings > Access Tokens**](/dashboard/account/tokens) and reuse it wherever you configure observability tooling.
* **Optional**: programmatically exchange an access token for project API keys via the [Management API](/docs/reference/api/management-projects-api-keys-retrieve).
```bash
# (Optional) Exchange an account access token for project API keys
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
"https://api.supabase.com/v1/projects/$PROJECT_REF/api-keys?reveal=true"
```
Grafana also documents a [Supabase integration reference](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/). While it targets Grafana Cloud, the scrape and agent settings apply equally to self-hosted clusters and offer a community-maintained companion to this guide.
## Architecture
1. **Prometheus** scrapes `https://.supabase.co/customer/v1/privileged/metrics` every minute using HTTP Basic Auth.
2. **Grafana** reads from Prometheus and renders dashboards/alerts.
3. (Optional) **Alertmanager** or your preferred system sends notifications when Prometheus rules fire.
## 1. Deploy Prometheus
Install [Prometheus](https://prometheus.io/docs/prometheus/latest/installation/) using your preferred method (Docker, Helm, binaries). Then add a Supabase-specific job to `prometheus.yml`:
```yaml
scrape_configs:
- job_name: 'supabase'
scrape_interval: 60s
metrics_path: /customer/v1/privileged/metrics
scheme: https
basic_auth:
username: username
password: ''
static_configs:
- targets:
- '.supabase.co:443'
labels:
project: ''
```
* Keep the scrape interval at 60 seconds to match Supabase’s refresh cadence.
* If you run Prometheus behind a proxy, make sure it can establish outbound HTTPS connections to `*.supabase.co`.
* Store secrets (Secret API key) with your secret manager or inject them via environment variables.
## 2. Deploy Grafana
Install Grafana (Docker image, Helm chart, or packages) and connect it to Prometheus:
1. In Grafana, go to **Connections → Data sources → Add data source**.
2. Choose **Prometheus**, set the URL to your Prometheus endpoint (for example `http://prometheus:9090`), and click **Save & test**.
## 3. Import Supabase dashboards
1. Go to **Dashboards → New → Import**.
2. Paste the contents of [`supabase-grafana/dashboard.json`](https://raw.githubusercontent.com/supabase/supabase-grafana/refs/heads/main/grafana/dashboard.json).
3. Select your Prometheus datasource when prompted.
You now have over 200 production-ready panels covering CPU, IO, WAL, replication, index bloat, and query throughput.
## 4. Configure alerting
* Import the sample rules from [`docs/example-alerts.md`](https://github.com/supabase/supabase-grafana/blob/main/docs/example-alerts.md) into Prometheus or Grafana Alerting.
* Tailor thresholds (for example, disk utilization, long-running transactions, connection saturation) to your project’s size.
* Route notifications via Alertmanager, Grafana OnCall, PagerDuty, or any other supported destination.
## 5. Operating tips
* **Multiple projects:** add one scrape job per project ref so you can separate metrics and labels cleanly.
* **Right-sizing guidance:** pair the dashboards with Supabase’s [Query Performance report](/dashboard/project/_/observability/query-performance) and [Advisors](/dashboard/project/_/observability/database) to decide when to optimize vs upgrade.
* **Security:** rotate Secret API keys on a regular cadence and update the Prometheus config accordingly.
# Vendor-agnostic Metrics API setup
The Supabase Metrics API is intentionally vendor-agnostic. Any collector that can scrape a Prometheus text endpoint over HTTPS can ingest the data. This guide explains the moving pieces so you can adapt them to AWS Managed Prometheus, Grafana Mimir, VictoriaMetrics, Thanos, or any other system.
What you can do with the Metrics API} id="how-do-i-check-when-a-user-went-through-mfa" className="border-0 px-2 py-4">
Every Supabase project exposes a metrics feed at `https://.supabase.co/customer/v1/privileged/metrics`. Replace `` with the identifier from your project URL or from the dashboard sidebar.
1. Copy your project reference and confirm the base URL using the helper below.
2. Configure your collector to scrape once per minute. The endpoint already emits the full set of metrics on each request.
3. Authenticate with HTTP Basic Auth:
* **Username**: `service_role`
* **Password**: a **Secret API key** (`sb_secret_...`). You can create/copy it in [**Project Settings → API Keys**](/dashboard/project/_/settings/api-keys). For more context, see [Understanding API keys](/docs/guides/getting-started/api-keys).
Testing locally is as simple as running `curl` with your Secret API key:
```bash
curl /customer/v1/privileged/metrics \
--user 'service_role:sb_secret_...'
```
You can provision long-lived automation tokens in two ways:
* Create an account access token once at [**Account Settings > Access Tokens**](/dashboard/account/tokens) and reuse it wherever you configure observability tooling.
* **Optional**: programmatically exchange an access token for project API keys via the [Management API](/docs/reference/api/management-projects-api-keys-retrieve).
```bash
# (Optional) Exchange an account access token for project API keys
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
"https://api.supabase.com/v1/projects/$PROJECT_REF/api-keys?reveal=true"
```
## Components
* **Collector** – Prometheus, Grafana Agent, VictoriaMetrics agent, Mimir scraper, etc.
* **Long-term store (optional)** – Managed Prometheus, Thanos, Mimir, VictoriaMetrics.
* **Visualization/alerting** – Grafana, Datadog, New Relic, custom code.
## 1. Define the scrape job
No matter which collector you use, you need to hit the Metrics API once per minute with HTTP Basic Auth:
```yaml
- job_name: supabase
scrape_interval: 60s
metrics_path: /customer/v1/privileged/metrics
scheme: https
basic_auth:
username: username
password: ''
static_configs:
- targets:
- '.supabase.co:443'
labels:
project: ''
```
### Collector-specific notes
* **Grafana Agent / Alloy:** use the [`prometheus.scrape` component](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/#manual-configuration) with the same parameters.
* **AWS Managed Prometheus (AMP):** deploy the Grafana Agent or AWS Distro for OpenTelemetry (ADOT) in your VPC, then remote-write the scraped metrics into AMP.
* **VictoriaMetrics / Mimir:** reuse the same scrape block; configure remote-write or retention rules as needed.
## 2. Secure the credentials
* Store the Secret API key in your secret manager (AWS Secrets Manager, GCP Secret Manager, Vault, etc.).
* Rotate the key periodically via [Project Settings → API Keys](/dashboard/project/_/settings/api-keys) and update your collector.
* If you need to give observability vendors access without exposing a broadly-scoped key, create a dedicated Secret API key for metrics-only automation.
## 3. Downstream dashboards
* Import the [Supabase Grafana dashboard](https://github.com/supabase/supabase-grafana) regardless of where Grafana is hosted.
* For other tools, group metrics by categories (CPU, IO, WAL, replication, connections) and recreate the visualizations that matter most to your team.
* Tag or relabel series with `project`, `env`, or `team` labels to make multi-project views easier.
## 4. Alerts and automation
* Start with the [example alert rules](https://github.com/supabase/supabase-grafana/blob/main/docs/example-alerts.md) and adapt thresholds for your workload sizes.
* Pipe alerts into PagerDuty, Slack, Opsgenie, or any other compatible target.
* Combine Metrics API data with log drains, Query Performance, and Advisors to build right-sizing playbooks.
## 5. Multi-project setups
* Create one scrape job per project ref so you can control sampling individually.
* If you run many projects, consider templating the scrape jobs via Helm, Terraform, or the Grafana Agent Operator.
* Use label joins (`project`, `instance_class`, `org`) to aggregate across tenants or environments.
# Pricing
You are charged for the total size of all assets in your buckets.
per GB-Hr ( per GB per month). You are only
charged for usage exceeding your subscription plan's quota.
| Plan | Quota in GB | Over-Usage per GB | Quota in GB-Hrs | Over-Usage per GB-Hr |
| ---------- | ----------- | ----------------------- | --------------- | ---------------------------- |
| Free | 1 | - | 744 | - |
| Pro | 100 | | 74,400 | |
| Team | 100 | | 74,400 | |
| Enterprise | Custom | Custom | Custom | Custom |
For a detailed explanation of how charges are calculated, refer to [Manage Storage size usage](/docs/guides/platform/manage-your-usage/storage-size).
If you use [Storage Image Transformations](/docs/guides/storage/serving/image-transformations), additional charges apply.
# Storage Quickstart
Learn how to use Supabase to store and serve files.
This guide shows the basic functionality of Supabase Storage. Find a full [example application on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/nextjs-user-management).
## Concepts
Supabase Storage consists of Files, Folders, and Buckets.
### Files
Files can be any sort of media file. This includes images, GIFs, and videos. It is best practice to store files outside of your database because of their sizes. For security, HTML files are returned as plain text.
### Folders
Folders are a way to organize your files (just like on your computer). There is no right or wrong way to organize your files. You can store them in whichever folder structure suits your project.
### Buckets
Buckets are distinct containers for files and folders. You can think of them like "super folders". Generally you would create distinct buckets for different Security and Access Rules. For example, you might keep all video files in a "video" bucket, and profile pictures in an "avatar" bucket.
File, Folder, and Bucket names **must follow** [AWS object key naming guidelines](https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-keys.html) and avoid use of any other characters.
## Create a bucket
You can create a bucket using the Supabase Dashboard. Since the storage is interoperable with your Postgres database, you can also use SQL or our client libraries. Here we create a bucket called "avatars":
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Click **New Bucket** and enter a name for the bucket.
3. Click **Create Bucket**.
```sql
-- Use Postgres to create a bucket.
insert into storage.buckets
(id, name)
values
('avatars', 'avatars');
```
```js
// Use the JS library to create a bucket.
const { data, error } = await supabase.storage.createBucket('avatars')
```
[Reference.](/docs/reference/javascript/storage-createbucket)
```dart
void main() async {
final supabase = SupabaseClient('supabaseUrl', 'supabaseKey');
final storageResponse = await supabase
.storage
.createBucket('avatars');
}
```
[Reference.](https://pub.dev/documentation/storage_client/latest/storage_client/SupabaseStorageClient/createBucket.html)
```swift
try await supabase.storage.createBucket("avatars")
```
[Reference.](/docs/reference/swift/storage-createbucket)
```python
response = supabase.storage.create_bucket('avatars')
```
[Reference.](/docs/reference/python/storage-createbucket)
## Upload a file
You can upload a file from the Dashboard, or within a browser using our JS libraries.
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Select the bucket you want to upload the file to.
3. Click **Upload File**.
4. Select the file you want to upload.
```js
const avatarFile = event.target.files[0]
const { data, error } = await supabase.storage
.from('avatars')
.upload('public/avatar1.png', avatarFile)
```
[Reference.](/docs/reference/javascript/storage-from-upload)
```dart
void main() async {
final supabase = SupabaseClient('supabaseUrl', 'supabaseKey');
// Create file `example.txt` and upload it in `public` bucket
final file = File('example.txt');
file.writeAsStringSync('File content');
final storageResponse = await supabase
.storage
.from('public')
.upload('example.txt', file);
}
```
[Reference.](https://pub.dev/documentation/storage_client/latest/storage_client/SupabaseStorageClient/createBucket.html)
## Download a file
You can download a file from the Dashboard, or within a browser using our JS libraries.
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Select the bucket that contains the file.
3. Select the file that you want to download.
4. Click **Download**.
```js
// Use the JS library to download a file.
const { data, error } = await supabase.storage.from('avatars').download('public/avatar1.png')
```
[Reference.](/docs/reference/javascript/storage-from-download)
```dart
void main() async {
final supabase = SupabaseClient('supabaseUrl', 'supabaseKey');
final storageResponse = await supabase
.storage
.from('public')
.download('example.txt');
}
```
[Reference.](/docs/reference/dart/storage-from-download)
```swift
let response = try await supabase.storage.from("avatars").download(path: "public/avatar1.png")
```
[Reference.](/docs/reference/swift/storage-from-download)
```python
response = supabase.storage.from_('avatars').download('public/avatar1.png')
```
[Reference.](/docs/reference/python/storage-from-download)
## Add security rules
To restrict access to your files you can use either the Dashboard or SQL.
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Click **Policies** in the sidebar.
3. Click **Add Policies** in the `OBJECTS` table to add policies for Files. You can also create policies for Buckets.
4. Choose whether you want the policy to apply to downloads (SELECT), uploads (INSERT), updates (UPDATE), or deletes (DELETE).
5. Give your policy a unique name.
6. Write the policy using SQL.
```sql
-- Use SQL to create a policy.
create policy "Public Access"
on storage.objects for select
using ( bucket_id = 'public' );
```
***
{/* Finish with a video. This also appears in the Sidebar via the "tocVideo" metadata */}
## Additional resources
* [Supabase Grafana repository](https://github.com/supabase/supabase-grafana) for dashboard JSON and alert examples.
* [Grafana Cloud’s Supabase integration doc](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/) (community-maintained, built on this Metrics API).
* [Datadog’s Supabase integration doc](https://docs.datadoghq.com/integrations/supabase/) (community-maintained, built on this Metrics API).
* [Log Drains ](/docs/guides/telemetry/log-drains) for exporting event-based telemetry alongside metrics.
* [Query Performance report](/dashboard/project/_/observability/query-performance) for built-in visualizations based on the same underlying metrics.
# Reports
{/* last LW we added that same report to every report page (pre-filtered) so, API Gateway report filtered by Auth will show the same data as going to Auth Report in the API Gateway section */}
Supabase Reports provide comprehensive observability for your project through dedicated monitoring dashboards for servers:
* Database
* Auth
* Storage
* Realtime
* API systems
Each report offers self-debugging tools to gain actionable insights for optimizing performance and troubleshooting issues.
Reports are only available for projects hosted on the Supabase Cloud platform and are not available for self-hosted instances.
## Using reports
You can filter reports by time range to focus on a specific period. Higher-tier plans provide access to longer time ranges.
| Time Range | Free | Pro | Team | Enterprise |
| --------------- | ---- | --- | ---- | ---------- |
| Last 10 minutes | ✅ | ✅ | ✅ | ✅ |
| Last 30 minutes | ✅ | ✅ | ✅ | ✅ |
| Last 60 minutes | ✅ | ✅ | ✅ | ✅ |
| Last 3 hours | ✅ | ✅ | ✅ | ✅ |
| Last 24 hours | ✅ | ✅ | ✅ | ✅ |
| Last 7 days | ❌ | ✅ | ✅ | ✅ |
| Last 14 days | ❌ | ❌ | ✅ | ✅ |
| Last 28 days | ❌ | ❌ | ✅ | ✅ |
***
## API gateway
The API Gateway report analyzes performance and traffic patterns managed by your project's API layer.
| Chart | Description | Key Insights |
| --------------- | ----------------------------------------- | ---------------------------------------------------------------------- |
| Total Requests | Overall API request volume | Traffic patterns and growth trends, including top routes |
| Response Errors | Error rates with 4XX and 5XX status codes | API reliability and user experience issues, including top routes |
| Response Speed | Average API response times | Performance bottlenecks and optimization targets, including top routes |
| Network Traffic | Request and response egress usage | Data transfer patterns and cost implications |
## Auth
The Auth reports focus on user authentication patterns and behaviors within your Supabase project.
| Chart | Description | Key Insights |
| ------------------------ | --------------------------------------------- | ----------------------------------------------- |
| Active Users | Count of unique users performing auth actions | User engagement and retention patterns |
| Sign In Attempts by Type | Breakdown of authentication methods used | Password vs OAuth vs magic link preferences |
| Sign Ups | Total new user registrations | Growth trends and onboarding funnel performance |
| API Gateway Auth Errors | Error rates grouped by status code | Authentication friction and security issues |
| Password Reset Requests | Volume of password recovery attempts | User experience pain points |
### Auth API Gateway
The Auth API Gateway reports focus on API requests related to authentication and user management.
| Chart | Description | Key Insights |
| --------------- | --------------------------------------------- | ---------------------------------------------------------------------------- |
| Total Requests | Count of unique users performing auth actions | User engagement and retention patterns, including top routes |
| Response Errors | Error rates with 4XX and 5XX status codes | API reliability and user experience issues, including top routes |
| Response speed | Average response time for auth requests | Performance bottlenecks and optimization opportunities, including top routes |
| Network Traffic | Ingress and egress usage | Data transfer costs and CDN effectiveness |
## Database
The Database report provides a comprehensive view into your Postgres instance's health and performance characteristics. These charts help you identify performance bottlenecks and resource constraints at a glance.
The following charts are available for Free and Pro plans:
| Chart | Available Plans | Description | Key Insights |
| ---------------------------- | --------------- | -------------------------------------------- | -------------------------------------------------------------- |
| Memory usage | Free, Pro | RAM usage percentage by the database | Memory pressure and resource utilization |
| CPU usage | Free, Pro | Average CPU usage percentage | CPU-intensive query identification |
| Disk IOPS | Free, Pro | Read/write operations per second with limits | IO bottleneck detection and workload analysis |
| Database connections | Free, Pro | Number of pooler connections to the database | Connection pool monitoring |
| Dedicated Pooler connections | All | Client connections to PgBouncer | Dedicated pooler connection monitoring |
| Shared Pooler connections | All | Client connections to the shared pooler | Shared pooler usage patterns |
| Shared Pooler connections | All | Client connections to the shared pooler | Shared pooler usage patterns |
| Disk usage | Free, Pro | Disk space consumption breakdown | Storage capacity planning |
| Database size | Free, Pro | Total database size and growth trends | Space consumption monitoring, including list of largest tables |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Advanced Telemetry
{/* TODO: This is confusing and feels contradictory */}
The following charts provide a more advanced and detailed view of your database performance and are available only for Team, Enterprise, and Platform plans.
### Memory usage
| Component | Description |
| ------------------- | ------------------------------------------------------ |
| **Used** | RAM actively used by Postgres and the operating system |
| **Cache + buffers** | Memory used for page cache and OS buffers |
| **Free** | Available unallocated memory |
How it helps debug issues:
| Issue | Description |
| ------------------------------ | ------------------------------------------------ |
| Memory pressure detection | Identify when free memory is consistently low |
| Cache effectiveness monitoring | Monitor cache performance for query optimization |
| Memory leak detection | Detect inefficient memory usage patterns |
Actions you can take:
| Action | Description |
| --------------------------------------------------------------------------- | ---------------------------------------------- |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk#compute-size) | Increase available memory resources |
| [Optimize queries](/docs/content/guides/database/query-optimization) | Reduce memory consumption of expensive queries |
| [Tune Postgres configuration](https://pgtune.leopard.in.ua) | Improve memory management settings |
| Implement application caching | Add query result caching to reduce memory load |
### CPU usage
| Category | Description |
| ---------- | ------------------------------------------------ |
| **System** | CPU time for kernel operations |
| **User** | CPU time for database queries and user processes |
| **IOWait** | CPU time waiting for disk/network IO |
| **IRQs** | CPU time handling interrupts |
| **Other** | CPU time for miscellaneous tasks |
How it helps debug issues:
| Issue | Description |
| ---------------------------------- | -------------------------------------------------- |
| CPU-intensive query identification | Identify expensive queries when User CPU is high |
| IO bottleneck detection | Detect disk/network issues when IOWait is elevated |
| System overhead monitoring | Monitor resource contention and kernel overhead |
Actions you can take:
| Action | Description |
| ---------------------------------------------------------------------------------- | ----------------------------------------------- |
| [Optimize CPU-intensive queries](/docs/content/guides/database/query-optimization) | Target queries causing high User CPU usage |
| Address IO bottlenecks | Resolve disk/network issues when IOWait is high |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk) | Increase available CPU capacity |
| [Implement proper indexing](/docs/guides/database/postgres/indexes) | Use query optimization techniques |
### Disk input/output operations per second (IOPS)
This chart displays read and write IOPS with a reference line showing your compute size's maximum IOPS capacity.
How it helps debug issues:
| Issue | Description |
| --------------------------------- | ---------------------------------------------------------------- |
| Disk IO bottleneck identification | Identify when disk IO becomes a performance constraint |
| Workload pattern analysis | Distinguish between read-heavy vs write-heavy operations |
| Performance correlation | Spot disk activity spikes that correlate with performance issues |
Actions you can take:
| Action | Description |
| -------------------------------------------------------------- | --------------------------------------------------------- |
| [Optimize indexing](/docs/guides/database/postgres/indexes) | Reduce high read IOPS through better query indexing |
| Consider [read replicas](/docs/guides/platform/read-replicas) | Distribute read-heavy workloads across multiple instances |
| Batch write operations | Reduce write IOPS by grouping database writes |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk) | Increase IOPS limits with larger compute instances |
### Disk throughput
Available on Team and Enterprise plans.
This chart displays read and write throughput (bytes per second) with a reference line showing your compute size's maximum disk throughput.
How it helps debug issues:
| Issue | Description |
| ------------------------------------ | ------------------------------------------------------- |
| Throughput bottleneck identification | Spot when disk bandwidth is saturated |
| Workload pattern analysis | Differentiate read-heavy vs write-heavy bandwidth usage |
| Performance correlation | Correlate spikes with query performance changes |
Actions you can take:
| Action | Description |
| ------------------------------------------------------------------------------------ | ------------------------------------------------------------- |
| [Optimize disk-intensive queries](/docs/content/guides/database/query-optimization) | Reduce queries that perform excessive reads/writes |
| Tune caching and batching | Minimize repeated disk access and improve throughput headroom |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk) | Increase throughput limits for sustained workloads |
| Review database design | Optimize schema and query patterns for efficiency |
| [Add strategic indexes](http://localhost:3001/docs/guides/database/postgres/indexes) | Reduce sequential scans with appropriate indexing |
### Disk size
| Component | Description |
| ------------ | --------------------------------------------------------- |
| **Database** | Space used by your actual database data (tables, indexes) |
| **WAL** | Space used by Write-Ahead Logging |
| **System** | Reserved space for system operations |
How it helps debug issues:
| Issue | Description |
| ----------------------------- | ------------------------------------------- |
| Space consumption monitoring | Track disk usage trends over time |
| Growth pattern identification | Identify rapid growth requiring attention |
| Capacity planning | Plan upgrades before hitting storage limits |
Actions you can take:
| Action | Description |
| -------------------------------------------------------------------------------- | -------------------------------------------------------------------- |
| Run [VACUUM](https://www.postgresql.org/docs/current/sql-vacuum.html) operations | Reclaim dead tuple space and optimize storage |
| Analyze large tables | Use CLI commands like `table-sizes` to identify optimization targets |
| Implement data archival | Archive historical data to reduce active storage needs |
| [Upgrade disk size](/docs/guides/platform/database-size) | Increase storage capacity when approaching limits |
### Query Performance
Links to the [Query Performance Advisory page](/docs/guides/platform/performance#examine-query-performance) in the dashboard, which provides a detailed analysis of slow database queries
### Database connections
| Connection Type | Description |
| --------------- | ------------------------------------------------ |
| **Postgres** | Direct connections from your application |
| **PostgREST** | Connections from the PostgREST API layer |
| **Reserved** | Administrative connections for Supabase services |
| **Auth** | Connections from Supabase Auth service |
| **Storage** | Connections from Supabase Storage service |
| **Other roles** | Miscellaneous database connections |
How it helps debug issues:
| Issue | Description |
| ------------------------------- | ----------------------------------------------------------- |
| Connection pool exhaustion | Identify when approaching maximum connection limits |
| Connection leak detection | Spot applications not properly closing connections |
| Service distribution monitoring | Monitor connection usage across different Supabase services |
Actions you can take:
| Action | Description |
| ------------------------------------------------------------------------------------------ | --------------------------------------------------------------- |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk#compute-size) | Increase maximum connection limits |
| Implement [connection pooling](/docs/guides/database/connecting-to-postgres#shared-pooler) | Optimize connection management for high direct connection usage |
| Review application code | Ensure proper connection handling and cleanup |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Dedicated Pooler (PgBouncer) Client Connections
Available on Team and Enterprise plans.
This chart displays the number of PgBouncer connections over time.
How it helps debug issues:
| Issue | Description |
| ------------------------------- | ----------------------------------------------------------- |
| Connection pool exhaustion | Identify when approaching maximum connection limits |
| Connection leak detection | Spot applications not properly closing connections |
| Service distribution monitoring | Monitor connection usage across different Supabase services |
Actions you can take:
| Action | Description |
| ------------------------------------------------------------------------------------------ | --------------------------------------------------------------- |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk#compute-size) | Increase maximum connection limits |
| Implement [connection pooling](/docs/guides/database/connecting-to-postgres#shared-pooler) | Optimize connection management for high direct connection usage |
| Review application code | Ensure proper connection handling and cleanup |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Shared Pooler (Supavisor) Client Connections
Available on Team and Enterprise plans.
This chart displays the number of Supavisor connections over time.
How it helps debug issues:
| Issue | Description |
| ------------------------------- | ----------------------------------------------------------- |
| Connection pool exhaustion | Identify when approaching maximum connection limits |
| Connection leak detection | Spot applications not properly closing connections |
| Service distribution monitoring | Monitor connection usage across different Supabase services |
Actions you can take:
| Action | Description |
| ------------------------------------------------------------------------------------------ | --------------------------------------------------------------- |
| [Upgrade compute size](/docs/guides/platform/compute-and-disk#compute-size) | Increase maximum connection limits |
| Implement [connection pooling](/docs/guides/database/connecting-to-postgres#shared-pooler) | Optimize connection management for high direct connection usage |
| Review application code | Ensure proper connection handling and cleanup |
### Disk Usage
### Database size
| Component | Description |
| ------------ | --------------------------------------------------------- |
| **Database** | Space used by your actual database data (tables, indexes) |
| **WAL** | Space used by Write-Ahead Logging |
| **System** | Reserved space for system operations |
How it helps debug issues:
| Issue | Description |
| ----------------------------- | ------------------------------------------- |
| Space consumption monitoring | Track disk usage trends over time |
| Growth pattern identification | Identify rapid growth requiring attention |
| Capacity planning | Plan upgrades before hitting storage limits |
Actions you can take:
| Action | Description |
| -------------------------------------------------------------------------------- | -------------------------------------------------------------------- |
| Run [VACUUM](https://www.postgresql.org/docs/current/sql-vacuum.html) operations | Reclaim dead tuple space and optimize storage |
| Analyze large tables | Use CLI commands like `table-sizes` to identify optimization targets |
| Implement data archival | Archive historical data to reduce active storage needs |
| [Upgrade disk size](/docs/guides/platform/database-size) | Increase storage capacity when approaching limits |
## Edge Functions
The Edge Functions report provides insights into serverless function performance, execution patterns, and regional distribution across Supabase's global edge network.
| Chart | Description | Key Insights |
| ------------------------------------ | ----------------------------------------- | ---------------------------------------------- |
| Total Edge Function Invocations | Function response codes and error rates | Function reliability and error patterns |
| Edge Function Execution Status Codes | Function response codes and error rates | Function reliability and error patterns |
| Edge Function Execution Time | Average function duration and performance | Performance optimization opportunities |
| Edge Function Invocations by Region | Geographic distribution of function calls | Global usage patterns and latency optimization |
## PostgREST
The PostgREST report provides insights into RESTful API performance, request patterns, and response characteristics.
| Chart | Description | Key Insights |
| --------------- | -------------------------------------------- | ---------------------------------------------------------------------------- |
| Total Requests | HTTP requests to PostgREST endpoints | API usage alongside WebSocket activity |
| Response Errors | Error rates with 4XX and 5XX status codes | API reliability and user experience issues, including top routes |
| Response Speed | Average response time for PostgREST requests | Performance bottlenecks and optimization opportunities, including top routes |
| Network Traffic | Ingress and egress usage | Data transfer costs and CDN effectiveness |
## Realtime
The Realtime report tracks WebSocket connections, channel activity, and real-time event patterns in your Supabase project.
| Chart | Description | Key Insights |
| ---------------------------------------------------------- | --------------------------------------------------------------------------------------- | ------------------------------------------------- |
| Connected Clients | Active WebSocket connections over time | Concurrent user activity and connection stability |
| Broadcast Events | Broadcast events over time | Real-time feature usage patterns |
| Presence Events | Presence events over time | Real-time feature usage patterns |
| Postgres Changes Events | Postgres Changes events over time | Real-time feature usage patterns |
| Rate of Channel Joins | Frequency of new channel subscriptions | User engagement with real-time features |
| Message Payload Size | Median size of message payloads sent | Payload size that is being transmitted |
| Broadcast From Database Replication Lag | Median latency between database commit and broadcast when using broadcast from database | Latency to Broadcast from the database |
| Read/Write Private Channel Subscription RLS Execution Time | Median time to authorize private channels | `realtime.messages` RLS policies performance |
| Total Requests | HTTP requests to Realtime endpoints | API usage alongside WebSocket activity |
| Response Speed | Performance of Realtime API endpoints | Infrastructure optimization opportunities |
### Realtime API Gateway
The Realtime API Gateway reports focus on API requests related to Realtime functionality.
| Chart | Description | Key Insights |
| --------------- | ------------------------------------- | --------------------------------------------------------------- |
| Total Requests | HTTP requests to Realtime endpoints | API usage alongside WebSocket activity, including top routes |
| Response Errors | HTTP requests to Realtime endpoints | API usage alongside WebSocket activity, including top routes |
| Response Speed | Performance of Realtime API endpoints | Infrastructure optimization opportunities, including top routes |
## Storage
The Storage report provides visibility into how your Supabase Storage is being utilized, including request patterns, performance characteristics, and caching effectiveness.
| Chart | Description | Key Insights |
| --------------- | ------------------------------------------ | ---------------------------------------------------------------------------- |
| Total Requests | Overall request volume to Storage | Traffic patterns and usage trends, including top routes |
| Response Speed | Average response time for storage requests | Performance bottlenecks and optimization opportunities, including top routes |
| Network Traffic | Ingress and egress usage | Data transfer costs and CDN effectiveness |
| Request Caching | Cache hit rates and miss patterns | CDN performance and cost optimization, including top routes |
# Sentry integration
Integrate Sentry to monitor errors from a Supabase client
You can use [Sentry](https://sentry.io/welcome/) to monitor errors thrown from a Supabase JavaScript client. Install the [Supabase Sentry integration](https://github.com/supabase-community/sentry-integration-js) to get started.
The Sentry integration supports browser, Node, and edge environments.
## Installation
Install the Sentry integration using your package manager:
```sh
npm install @supabase/sentry-js-integration
```
```sh
yarn add @supabase/sentry-js-integration
```
```sh
pnpm add @supabase/sentry-js-integration
```
## Use
If you are using Sentry JavaScript SDK v7, reference [`supabase-community/sentry-integration-js` repository](https://github.com/supabase-community/sentry-integration-js/blob/master/README-v7.md) instead.
To use the Supabase Sentry integration, add it to your `integrations` list when initializing your Sentry client.
You can supply either the Supabase Client constructor or an already-initiated instance of a Supabase Client.
```ts
import * as Sentry from '@sentry/browser'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
],
})
```
```ts
import * as Sentry from '@sentry/browser'
import { createClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
const supabaseClient = createClient(SUPABASE_URL, SUPABASE_KEY)
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(supabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
],
})
```
All available configuration options are available in our [`supabase-community/sentry-integration-js` repository](https://github.com/supabase-community/sentry-integration-js/blob/master/README.md#options).
## Deduplicating spans
If you're already monitoring HTTP errors in Sentry, for example with the HTTP, Fetch, or Undici integrations, you will get duplicate spans for Supabase calls. You can deduplicate the spans by skipping them in your other integration:
```ts
import * as Sentry from '@sentry/browser'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
// @sentry/browser
Sentry.browserTracingIntegration({
shouldCreateSpanForRequest: (url) => {
return !url.startsWith(`${SUPABASE_URL}/rest`)
},
}),
// or @sentry/node
Sentry.httpIntegration({
tracing: {
ignoreOutgoingRequests: (url) => {
return url.startsWith(`${SUPABASE_URL}/rest`)
},
},
}),
// or @sentry/node with Fetch support
Sentry.nativeNodeFetchIntegration({
ignoreOutgoingRequests: (url) => {
return url.startsWith(`${SUPABASE_URL}/rest`)
},
}),
// or @sentry/WinterCGFetch for Next.js Proxy & Edge Functions
Sentry.winterCGFetchIntegration({
breadcrumbs: true,
shouldCreateSpanForRequest: (url) => {
return !url.startsWith(`${SUPABASE_URL}/rest`)
},
}),
],
})
```
## Example Next.js configuration
See this example for a setup with Next.js to cover browser, server, and edge environments. First, run through the [Sentry Next.js wizard](https://docs.sentry.io/platforms/javascript/guides/nextjs/#install) to generate the base Next.js configuration. Then add the Supabase Sentry Integration to all your `Sentry.init` calls with the appropriate filters.
```ts sentry.client.config.ts
import * as Sentry from '@sentry/nextjs'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
Sentry.browserTracingIntegration({
shouldCreateSpanForRequest: (url) => {
return !url.startsWith(`${process.env.NEXT_PUBLIC_SUPABASE_URL}/rest`)
},
}),
],
// Adjust this value in production, or use tracesSampler for greater control
tracesSampleRate: 1,
// Setting this option to true will print useful information to the console while you're setting up Sentry.
debug: true,
})
```
```ts sentry.server.config.ts
import * as Sentry from '@sentry/nextjs'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
Sentry.nativeNodeFetchIntegration({
breadcrumbs: true,
ignoreOutgoingRequests: (url) => {
return url.startsWith(`${process.env.NEXT_PUBLIC_SUPABASE_URL}/rest`)
},
}),
],
// Adjust this value in production, or use tracesSampler for greater control
tracesSampleRate: 1,
// Setting this option to true will print useful information to the console while you're setting up Sentry.
debug: true,
})
```
```js sentry.edge.config.ts
import * as Sentry from '@sentry/nextjs'
import { SupabaseClient } from '@supabase/supabase-js'
import { supabaseIntegration } from '@supabase/sentry-js-integration'
Sentry.init({
dsn: SENTRY_DSN,
integrations: [
supabaseIntegration(SupabaseClient, Sentry, {
tracing: true,
breadcrumbs: true,
errors: true,
}),
Sentry.winterCGFetchIntegration({
breadcrumbs: true,
shouldCreateSpanForRequest: (url) => {
return !url.startsWith(`${process.env.NEXT_PUBLIC_SUPABASE_URL}/rest`)
},
}),
],
// Adjust this value in production, or use tracesSampler for greater control
tracesSampleRate: 1,
// Setting this option to true will print useful information to the console while you're setting up Sentry.
debug: true,
})
```
```js instrumentation.ts
// https://nextjs.org/docs/app/building-your-application/optimizing/instrumentation
export async function register() {
if (process.env.NEXT_RUNTIME === 'nodejs') {
await import('./sentry.server.config')
}
if (process.env.NEXT_RUNTIME === 'edge') {
await import('./sentry.edge.config')
}
}
```
Afterwards, build your application (`npm run build`) and start it locally (`npm run start`). You will now see the transactions being logged in the terminal when making supabase-js requests.
# Metrics API with Grafana Cloud
Grafana Cloud gives you a fully managed Prometheus endpoint plus hosted Grafana dashboards, which makes it the fastest way to explore the Supabase Metrics API without operating your own infrastructure.
Grafana maintains a [Supabase integration guide](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/) for Grafana Cloud. It runs on the same Metrics API documented here, but is community-maintained by Grafana, so feature coverage might differ from what Supabase officially supports.
## Prerequisites
* A Supabase project with access to the Metrics API (Secret API key `sb_secret_...`).
* A Grafana Cloud account with Prometheus metrics enabled (Free or Pro tier).
* A Grafana API token with the `metrics:write` and `metrics:read` scopes if you plan to push data manually.
What you can do with the Metrics API} id="how-do-i-check-when-a-user-went-through-mfa" className="border-0 px-2 py-4">
Every Supabase project exposes a metrics feed at `https://.supabase.co/customer/v1/privileged/metrics`. Replace `` with the identifier from your project URL or from the dashboard sidebar.
1. Copy your project reference and confirm the base URL using the helper below.
2. Configure your collector to scrape once per minute. The endpoint already emits the full set of metrics on each request.
3. Authenticate with HTTP Basic Auth:
* **Username**: `service_role`
* **Password**: a **Secret API key** (`sb_secret_...`). You can create/copy it in [**Project Settings → API Keys**](/dashboard/project/_/settings/api-keys). For more context, see [Understanding API keys](/docs/guides/getting-started/api-keys).
Testing locally is as simple as running `curl` with your Secret API key:
```bash
curl /customer/v1/privileged/metrics \
--user 'service_role:sb_secret_...'
```
You can provision long-lived automation tokens in two ways:
* Create an account access token once at [**Account Settings > Access Tokens**](/dashboard/account/tokens) and reuse it wherever you configure observability tooling.
* **Optional**: programmatically exchange an access token for project API keys via the [Management API](/docs/reference/api/management-projects-api-keys-retrieve).
```bash
# (Optional) Exchange an account access token for project API keys
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
"https://api.supabase.com/v1/projects/$PROJECT_REF/api-keys?reveal=true"
```
## 1. Create a Grafana Cloud stack
1. Sign in to [Grafana Cloud](https://grafana.com/auth/sign-in).
2. Create (or select) a stack that has **Prometheus Metrics** enabled (Free and Pro tiers both work for this guide).
## 2. Configure the Supabase integration
1. Navigate to **Connections → Add new connection → Supabase** inside Grafana Cloud.
2. Provide:
* Your Supabase project ref (e.g. `abcd1234`).
* The Metrics API endpoint: `https://.supabase.co/customer/v1/privileged/metrics`.
* HTTP Basic Auth credentials (`sb_secret_...`).
3. Choose the scrape interval (1 minute recommended) and test the connection. Grafana Cloud will deploy an agent in the background that scrapes the Metrics API and forwards the data to Prometheus.
If you prefer to reuse an existing Grafana Agent deployment, configure an [integration pipeline](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/) with the same URL and credentials.
## 3. Import the Supabase dashboard
1. Open your Grafana Cloud dashboard list and click **New → Import**.
2. Paste the raw contents of [`supabase-grafana/dashboard.json`](https://raw.githubusercontent.com/supabase/supabase-grafana/refs/heads/main/grafana/dashboard.json).
3. When prompted for the datasource, choose the Prometheus instance that receives the Supabase metrics.
This dashboard includes 200+ charts grouped by CPU, IO, connections, replication, WAL, and bloat indicators.
## 4. Configure alerts (optional)
The [`docs/example-alerts.md`](https://github.com/supabase/supabase-grafana/blob/main/docs/example-alerts.md) file contains suggested alert rules (disk saturation, long-running queries, replication lag, etc.). Import the alert rules into Grafana Cloud’s Alerting UI or translate them into Grafana Cloud’s managed alert rule format.
## 5. Troubleshooting
* Metrics missing? Ensure the Grafana Cloud agent can reach `https://.supabase.co` and that the selected Secret API key is still valid.
* 401 errors? Create/rotate a Secret API key in [Project Settings → API Keys](/dashboard/project/_/settings/api-keys) and update the Grafana Cloud credentials.
* Long scrape durations? Reduce label cardinality in your Grafana queries or lower the time range to focus on recent data.
# Metrics API with Prometheus & Grafana (self-hosted)
Self-hosting [Prometheus](https://prometheus.io/docs/prometheus/latest/installation/) and Grafana gives you full control over retention, alert routing, and dashboards. The Supabase Metrics API slots into any standard Prometheus scrape job, so you can run everything locally, on a VM, or inside Kubernetes.
What you can do with the Metrics API} id="how-do-i-check-when-a-user-went-through-mfa" className="border-0 px-2 py-4">
Every Supabase project exposes a metrics feed at `https://.supabase.co/customer/v1/privileged/metrics`. Replace `` with the identifier from your project URL or from the dashboard sidebar.
1. Copy your project reference and confirm the base URL using the helper below.
2. Configure your collector to scrape once per minute. The endpoint already emits the full set of metrics on each request.
3. Authenticate with HTTP Basic Auth:
* **Username**: `service_role`
* **Password**: a **Secret API key** (`sb_secret_...`). You can create/copy it in [**Project Settings → API Keys**](/dashboard/project/_/settings/api-keys). For more context, see [Understanding API keys](/docs/guides/getting-started/api-keys).
Testing locally is as simple as running `curl` with your Secret API key:
```bash
curl /customer/v1/privileged/metrics \
--user 'service_role:sb_secret_...'
```
You can provision long-lived automation tokens in two ways:
* Create an account access token once at [**Account Settings > Access Tokens**](/dashboard/account/tokens) and reuse it wherever you configure observability tooling.
* **Optional**: programmatically exchange an access token for project API keys via the [Management API](/docs/reference/api/management-projects-api-keys-retrieve).
```bash
# (Optional) Exchange an account access token for project API keys
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
"https://api.supabase.com/v1/projects/$PROJECT_REF/api-keys?reveal=true"
```
Grafana also documents a [Supabase integration reference](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/). While it targets Grafana Cloud, the scrape and agent settings apply equally to self-hosted clusters and offer a community-maintained companion to this guide.
## Architecture
1. **Prometheus** scrapes `https://.supabase.co/customer/v1/privileged/metrics` every minute using HTTP Basic Auth.
2. **Grafana** reads from Prometheus and renders dashboards/alerts.
3. (Optional) **Alertmanager** or your preferred system sends notifications when Prometheus rules fire.
## 1. Deploy Prometheus
Install [Prometheus](https://prometheus.io/docs/prometheus/latest/installation/) using your preferred method (Docker, Helm, binaries). Then add a Supabase-specific job to `prometheus.yml`:
```yaml
scrape_configs:
- job_name: 'supabase'
scrape_interval: 60s
metrics_path: /customer/v1/privileged/metrics
scheme: https
basic_auth:
username: username
password: ''
static_configs:
- targets:
- '.supabase.co:443'
labels:
project: ''
```
* Keep the scrape interval at 60 seconds to match Supabase’s refresh cadence.
* If you run Prometheus behind a proxy, make sure it can establish outbound HTTPS connections to `*.supabase.co`.
* Store secrets (Secret API key) with your secret manager or inject them via environment variables.
## 2. Deploy Grafana
Install Grafana (Docker image, Helm chart, or packages) and connect it to Prometheus:
1. In Grafana, go to **Connections → Data sources → Add data source**.
2. Choose **Prometheus**, set the URL to your Prometheus endpoint (for example `http://prometheus:9090`), and click **Save & test**.
## 3. Import Supabase dashboards
1. Go to **Dashboards → New → Import**.
2. Paste the contents of [`supabase-grafana/dashboard.json`](https://raw.githubusercontent.com/supabase/supabase-grafana/refs/heads/main/grafana/dashboard.json).
3. Select your Prometheus datasource when prompted.
You now have over 200 production-ready panels covering CPU, IO, WAL, replication, index bloat, and query throughput.
## 4. Configure alerting
* Import the sample rules from [`docs/example-alerts.md`](https://github.com/supabase/supabase-grafana/blob/main/docs/example-alerts.md) into Prometheus or Grafana Alerting.
* Tailor thresholds (for example, disk utilization, long-running transactions, connection saturation) to your project’s size.
* Route notifications via Alertmanager, Grafana OnCall, PagerDuty, or any other supported destination.
## 5. Operating tips
* **Multiple projects:** add one scrape job per project ref so you can separate metrics and labels cleanly.
* **Right-sizing guidance:** pair the dashboards with Supabase’s [Query Performance report](/dashboard/project/_/observability/query-performance) and [Advisors](/dashboard/project/_/observability/database) to decide when to optimize vs upgrade.
* **Security:** rotate Secret API keys on a regular cadence and update the Prometheus config accordingly.
# Vendor-agnostic Metrics API setup
The Supabase Metrics API is intentionally vendor-agnostic. Any collector that can scrape a Prometheus text endpoint over HTTPS can ingest the data. This guide explains the moving pieces so you can adapt them to AWS Managed Prometheus, Grafana Mimir, VictoriaMetrics, Thanos, or any other system.
What you can do with the Metrics API} id="how-do-i-check-when-a-user-went-through-mfa" className="border-0 px-2 py-4">
Every Supabase project exposes a metrics feed at `https://.supabase.co/customer/v1/privileged/metrics`. Replace `` with the identifier from your project URL or from the dashboard sidebar.
1. Copy your project reference and confirm the base URL using the helper below.
2. Configure your collector to scrape once per minute. The endpoint already emits the full set of metrics on each request.
3. Authenticate with HTTP Basic Auth:
* **Username**: `service_role`
* **Password**: a **Secret API key** (`sb_secret_...`). You can create/copy it in [**Project Settings → API Keys**](/dashboard/project/_/settings/api-keys). For more context, see [Understanding API keys](/docs/guides/getting-started/api-keys).
Testing locally is as simple as running `curl` with your Secret API key:
```bash
curl /customer/v1/privileged/metrics \
--user 'service_role:sb_secret_...'
```
You can provision long-lived automation tokens in two ways:
* Create an account access token once at [**Account Settings > Access Tokens**](/dashboard/account/tokens) and reuse it wherever you configure observability tooling.
* **Optional**: programmatically exchange an access token for project API keys via the [Management API](/docs/reference/api/management-projects-api-keys-retrieve).
```bash
# (Optional) Exchange an account access token for project API keys
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
"https://api.supabase.com/v1/projects/$PROJECT_REF/api-keys?reveal=true"
```
## Components
* **Collector** – Prometheus, Grafana Agent, VictoriaMetrics agent, Mimir scraper, etc.
* **Long-term store (optional)** – Managed Prometheus, Thanos, Mimir, VictoriaMetrics.
* **Visualization/alerting** – Grafana, Datadog, New Relic, custom code.
## 1. Define the scrape job
No matter which collector you use, you need to hit the Metrics API once per minute with HTTP Basic Auth:
```yaml
- job_name: supabase
scrape_interval: 60s
metrics_path: /customer/v1/privileged/metrics
scheme: https
basic_auth:
username: username
password: ''
static_configs:
- targets:
- '.supabase.co:443'
labels:
project: ''
```
### Collector-specific notes
* **Grafana Agent / Alloy:** use the [`prometheus.scrape` component](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/integrations/integration-reference/integration-supabase/#manual-configuration) with the same parameters.
* **AWS Managed Prometheus (AMP):** deploy the Grafana Agent or AWS Distro for OpenTelemetry (ADOT) in your VPC, then remote-write the scraped metrics into AMP.
* **VictoriaMetrics / Mimir:** reuse the same scrape block; configure remote-write or retention rules as needed.
## 2. Secure the credentials
* Store the Secret API key in your secret manager (AWS Secrets Manager, GCP Secret Manager, Vault, etc.).
* Rotate the key periodically via [Project Settings → API Keys](/dashboard/project/_/settings/api-keys) and update your collector.
* If you need to give observability vendors access without exposing a broadly-scoped key, create a dedicated Secret API key for metrics-only automation.
## 3. Downstream dashboards
* Import the [Supabase Grafana dashboard](https://github.com/supabase/supabase-grafana) regardless of where Grafana is hosted.
* For other tools, group metrics by categories (CPU, IO, WAL, replication, connections) and recreate the visualizations that matter most to your team.
* Tag or relabel series with `project`, `env`, or `team` labels to make multi-project views easier.
## 4. Alerts and automation
* Start with the [example alert rules](https://github.com/supabase/supabase-grafana/blob/main/docs/example-alerts.md) and adapt thresholds for your workload sizes.
* Pipe alerts into PagerDuty, Slack, Opsgenie, or any other compatible target.
* Combine Metrics API data with log drains, Query Performance, and Advisors to build right-sizing playbooks.
## 5. Multi-project setups
* Create one scrape job per project ref so you can control sampling individually.
* If you run many projects, consider templating the scrape jobs via Helm, Terraform, or the Grafana Agent Operator.
* Use label joins (`project`, `instance_class`, `org`) to aggregate across tenants or environments.
# Pricing
You are charged for the total size of all assets in your buckets.
per GB-Hr ( per GB per month). You are only
charged for usage exceeding your subscription plan's quota.
| Plan | Quota in GB | Over-Usage per GB | Quota in GB-Hrs | Over-Usage per GB-Hr |
| ---------- | ----------- | ----------------------- | --------------- | ---------------------------- |
| Free | 1 | - | 744 | - |
| Pro | 100 | | 74,400 | |
| Team | 100 | | 74,400 | |
| Enterprise | Custom | Custom | Custom | Custom |
For a detailed explanation of how charges are calculated, refer to [Manage Storage size usage](/docs/guides/platform/manage-your-usage/storage-size).
If you use [Storage Image Transformations](/docs/guides/storage/serving/image-transformations), additional charges apply.
# Storage Quickstart
Learn how to use Supabase to store and serve files.
This guide shows the basic functionality of Supabase Storage. Find a full [example application on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/nextjs-user-management).
## Concepts
Supabase Storage consists of Files, Folders, and Buckets.
### Files
Files can be any sort of media file. This includes images, GIFs, and videos. It is best practice to store files outside of your database because of their sizes. For security, HTML files are returned as plain text.
### Folders
Folders are a way to organize your files (just like on your computer). There is no right or wrong way to organize your files. You can store them in whichever folder structure suits your project.
### Buckets
Buckets are distinct containers for files and folders. You can think of them like "super folders". Generally you would create distinct buckets for different Security and Access Rules. For example, you might keep all video files in a "video" bucket, and profile pictures in an "avatar" bucket.
File, Folder, and Bucket names **must follow** [AWS object key naming guidelines](https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-keys.html) and avoid use of any other characters.
## Create a bucket
You can create a bucket using the Supabase Dashboard. Since the storage is interoperable with your Postgres database, you can also use SQL or our client libraries. Here we create a bucket called "avatars":
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Click **New Bucket** and enter a name for the bucket.
3. Click **Create Bucket**.
```sql
-- Use Postgres to create a bucket.
insert into storage.buckets
(id, name)
values
('avatars', 'avatars');
```
```js
// Use the JS library to create a bucket.
const { data, error } = await supabase.storage.createBucket('avatars')
```
[Reference.](/docs/reference/javascript/storage-createbucket)
```dart
void main() async {
final supabase = SupabaseClient('supabaseUrl', 'supabaseKey');
final storageResponse = await supabase
.storage
.createBucket('avatars');
}
```
[Reference.](https://pub.dev/documentation/storage_client/latest/storage_client/SupabaseStorageClient/createBucket.html)
```swift
try await supabase.storage.createBucket("avatars")
```
[Reference.](/docs/reference/swift/storage-createbucket)
```python
response = supabase.storage.create_bucket('avatars')
```
[Reference.](/docs/reference/python/storage-createbucket)
## Upload a file
You can upload a file from the Dashboard, or within a browser using our JS libraries.
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Select the bucket you want to upload the file to.
3. Click **Upload File**.
4. Select the file you want to upload.
```js
const avatarFile = event.target.files[0]
const { data, error } = await supabase.storage
.from('avatars')
.upload('public/avatar1.png', avatarFile)
```
[Reference.](/docs/reference/javascript/storage-from-upload)
```dart
void main() async {
final supabase = SupabaseClient('supabaseUrl', 'supabaseKey');
// Create file `example.txt` and upload it in `public` bucket
final file = File('example.txt');
file.writeAsStringSync('File content');
final storageResponse = await supabase
.storage
.from('public')
.upload('example.txt', file);
}
```
[Reference.](https://pub.dev/documentation/storage_client/latest/storage_client/SupabaseStorageClient/createBucket.html)
## Download a file
You can download a file from the Dashboard, or within a browser using our JS libraries.
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Select the bucket that contains the file.
3. Select the file that you want to download.
4. Click **Download**.
```js
// Use the JS library to download a file.
const { data, error } = await supabase.storage.from('avatars').download('public/avatar1.png')
```
[Reference.](/docs/reference/javascript/storage-from-download)
```dart
void main() async {
final supabase = SupabaseClient('supabaseUrl', 'supabaseKey');
final storageResponse = await supabase
.storage
.from('public')
.download('example.txt');
}
```
[Reference.](/docs/reference/dart/storage-from-download)
```swift
let response = try await supabase.storage.from("avatars").download(path: "public/avatar1.png")
```
[Reference.](/docs/reference/swift/storage-from-download)
```python
response = supabase.storage.from_('avatars').download('public/avatar1.png')
```
[Reference.](/docs/reference/python/storage-from-download)
## Add security rules
To restrict access to your files you can use either the Dashboard or SQL.
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Click **Policies** in the sidebar.
3. Click **Add Policies** in the `OBJECTS` table to add policies for Files. You can also create policies for Buckets.
4. Choose whether you want the policy to apply to downloads (SELECT), uploads (INSERT), updates (UPDATE), or deletes (DELETE).
5. Give your policy a unique name.
6. Write the policy using SQL.
```sql
-- Use SQL to create a policy.
create policy "Public Access"
on storage.objects for select
using ( bucket_id = 'public' );
```
***
{/* Finish with a video. This also appears in the Sidebar via the "tocVideo" metadata */}
# Creating Vector Buckets
Set up vector buckets and indexes using the dashboard or JavaScript SDK.
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Vector buckets organize your vector data into logical units. Within each bucket, you create indexes that define how vectors are stored and searched based on their dimensions and distance metrics.
## Creating a Vector bucket
You can create vector buckets using either the Supabase Dashboard or the SDK.
### Using the Supabase Dashboard
1. Navigate to the **Storage** section in the Supabase Dashboard.
2. Click **Create Bucket**.
3. Enter a name for your bucket (e.g., `embeddings` or `semantic-search`).
4. Select **Vector Bucket** as the bucket type.
5. Click **Create**.
Your vector bucket is now ready. The next step is to create indexes within it.
### Using the SDK
```typescript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://your-project-id.supabase.co', 'your-service-key')
// Create a vector bucket
await supabase.storage.vectors.createBucket('embeddings')
console.log('✓ Vector bucket created: embeddings')
```
```python
from supabase import create_client
supabase = create_client('https://your-project-id.supabase.co', 'your-service-key')
# Create a vector bucket
supabase.storage.vectors().create_bucket('embeddings')
print('✓ Vector bucket created: embeddings')
```
## Creating indexes
Indexes organize vectors within a bucket with consistent dimensions and distance metrics. For comprehensive index management documentation, see [Working with Vector Indexes](/docs/guides/storage/vector/working-with-indexes).
### Quick start: Creating an index via Dashboard
1. Open your vector bucket.
2. Click **Create Index**.
3. Enter an index name (e.g., `documents-openai`).
4. Set the dimension matching your embeddings (e.g., `1536` for OpenAI's text-embedding-3-small).
5. Select the distance metric (`cosine`, `euclidean`, or `l2`).
6. Click **Create**.
### Quick start: Creating an index via SDK
```typescript
const bucket = supabase.storage.vectors.from('embeddings')
// Create an index
await bucket.createIndex({
indexName: 'documents-openai',
dataType: 'float32',
dimension: 1536,
distanceMetric: 'cosine',
})
console.log('✓ Index created: documents-openai')
```
```python
bucket = supabase.storage.vectors().from_('embeddings')
# Create an index
bucket.create_index(
index_name='documents-openai',
dimension=1536,
distance_metric='cosine',
data_type='float32'
)
print('✓ Index created: documents-openai')
```
### Key details
* **Dimension** must match your embedding model (e.g., 1536 for OpenAI)
* **Distance metric** (`cosine`, `euclidean`, or `l2`) is immutable after creation
* **Maximum indexes per bucket**: 10
* **Maximum batch size**: 500 vectors per operation
For detailed information on distance metrics, embedding dimensions, managing multiple indexes, and advanced index operations, see [Working with Vector Indexes](/docs/guides/storage/vector/working-with-indexes).
## Next steps
After creating your bucket and indexes, you can:
* [Store vectors](/docs/guides/storage/vector/storing-vectors)
* [Query vectors with similarity search](/docs/guides/storage/vector/querying-vectors)
* [Explore vector bucket limits](/docs/guides/storage/vector/limits)
# Vector Buckets
Store, index, and query vector embeddings at scale with similarity search.
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Vector buckets enable efficient storage and similarity search of vector embeddings. Built on S3-compatible storage, they provide high-performance semantic search capabilities for AI and machine learning applications.
## What are Vector buckets?
Vector buckets are specialized storage containers optimized for vector data. Unlike traditional databases optimized for transactional queries, vector buckets use specialized indexing and distance metrics to perform fast similarity searches across millions of embeddings.
Each vector bucket contains:
* **Indexes** - Organized collections of vectors with consistent dimensions and distance metrics
* **Vectors** - Embeddings with associated metadata for filtering and enrichment
* **Metadata** - Additional context about vectors (text, tags, IDs, etc.)
## Key features
* **Similarity Search** - Find semantically similar vectors using cosine, euclidean, or L2 distance metrics
* **Metadata Filtering** - Filter results by associated metadata before/after similarity search
* **Batch Operations** - Insert, update, and query up to 500 vectors per request
* **Scalable Storage** - Store millions of vectors in a single index
* **S3 Native** - Built on proven S3 infrastructure for reliability and durability
## Ideal use cases
Vector buckets excel at:
* **Semantic Search** - Find documents or images similar to a query
* **Recommendation Systems** - Suggest products, content, or connections based on embeddings
* **Clustering & Anomaly Detection** - Group similar items or identify outliers
* **Image Search** - Retrieve visually similar images from large catalogs
* **RAG (Retrieval-Augmented Generation)** - Find relevant context for LLM queries
* **Personalization** - Recommend tailored content based on user embeddings
## Comparison to pgvector
Vector buckets share similarities to pgvector and matches the developer experience of using pgvector as much as possible, but Vector buckets and any [Foreign Data Wrappers (FDW)](/docs/guides/database/extensions/wrappers/overview) they use only support one similarity search algorithm, the `<===>` distance operator.
This makes Vector buckets ideal for:
* Large-scale data storage
* Backend processing workflows
* Applications where speed is less critical
And pgvector is ideal for:
* Fast prototyping and small data volumes
* Applications requiring quick response times
* User-facing features closer to the front end
## How Vector buckets work
1. **Create a bucket** to organize your vector data
2. **Create indexes** within the bucket with specified dimensions and distance metrics
3. **Store vectors** with embeddings and optional metadata
4. **Query vectors** using similarity search to find nearest neighbors
The system automatically handles indexing and optimization, making searches fast and reliable even with millions of vectors.
## Next steps
Get started by learning how to [create vector buckets](/docs/guides/storage/vector/creating-vector-buckets) or dive into [storing vectors](/docs/guides/storage/vector/storing-vectors).
# Vector Bucket Limits
Understanding capacity, limits, and billing for vector buckets.
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Vector buckets have default limits during the alpha phase. These limits are designed to ensure fair resource allocation and can be adjusted on a case-by-case basis for production workloads.
## Storage limits
| Limit | Value | Notes |
| ----------------------- | ------------ | ----------------------------------------------------- |
| **Buckets per project** | 10 | Maximum number of vector buckets per Supabase project |
| **Indexes per bucket** | 10 | Maximum number of indexes per bucket |
| **Vector dimensions** | Max 4096 | Maximum dimension size for embeddings |
| **Batch size** | 1000 vectors | Maximum vectors per single insert/update request |
# Querying Vectors
Perform similarity search and retrieve vectors using JavaScript SDK or Postgres.
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Vector similarity search finds vectors most similar to a query vector using distance metrics. You can query vectors using the JavaScript SDK or directly from Postgres using SQL.
Vector buckets and any [Foreign Data Wrappers (FDW)](/docs/guides/database/extensions/wrappers/overview) they use only support one similarity search algorithm, the `<===>` distance operator.
## Basic similarity search
```typescript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://your-project-id.supabase.co', 'your-service-key')
const index = supabase.storage.vectors.from('embeddings').index('documents-openai')
// Query with a vector embedding
const { data, error } = await index.queryVectors({
queryVector: {
float32: [0.1, 0.2, 0.3 /* ... embedding of 1536 dimensions ... */],
},
topK: 5,
returnDistance: true,
returnMetadata: true,
})
if (error) {
console.error('Query failed:', error)
} else {
// Results are ranked by similarity (lowest distance = most similar)
data.vectors.forEach((result, rank) => {
console.log(`${rank + 1}. ${result.metadata?.title}`)
console.log(` Similarity score: ${result.distance.toFixed(4)}`)
})
}
```
```python
from supabase import create_client
supabase = create_client('https://your-project-id.supabase.co', 'your-service-key')
index = supabase.storage.vectors().from_('embeddings').index('documents-openai')
# Query with a vector embedding
results = index.query(
query_vector={'float32': [0.1, 0.2, 0.3]}, # ... embedding of 1536 dimensions
topK=5,
return_distance=True,
return_metadata=True
)
if results:
# Results are ranked by similarity (lowest distance = most similar)
for rank, result in enumerate(results.vectors, 1):
print(f'{rank}. {result.metadata.get("title") if result.metadata else "N/A"}')
if result.distance is not None:
print(f' Similarity score: {result.distance:.4f}')
```
```sql
-- Setup S3 Vector Wrapper (one-time setup)
-- https://supabase.com/docs/guides/database/extensions/wrappers/s3_vectors
-- Query similar vectors
SELECT
key,
metadata->>'title' as title,
embd_distance(data) as distance,
(1 - embd_distance(data)) as similarity_score
FROM s3_vectors.documents_openai
WHERE data <==> '[0.1, 0.2, 0.3, /* ... embedding ... */]'::embd
ORDER BY embd_distance(data) ASC
LIMIT 5;
```
## Semantic search
Find documents similar to a query by embedding the query text:
```typescript
import { createClient } from '@supabase/supabase-js'
import OpenAI from 'openai'
const supabase = createClient(...)
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY })
async function semanticSearch(query, topK = 5) {
// Embed the query
const queryEmbedding = await openai.embeddings.create({
model: 'text-embedding-3-small',
input: query
})
const queryVector = queryEmbedding.data[0].embedding
// Search for similar vectors
const { data, error } = await supabase.storage.vectors
.from('embeddings')
.index('documents-openai')
.queryVectors({
queryVector: { float32: queryVector },
topK,
returnDistance: true,
returnMetadata: true
})
if (error) {
throw error
}
return data.vectors.map((result) => ({
id: result.key,
title: result.metadata?.title,
similarity: 1 - result.distance, // Convert distance to similarity (0-1)
metadata: result.metadata
}))
}
// Usage
const results = await semanticSearch('How do I use vector search?')
results.forEach((result) => {
console.log(`${result.title} (${(result.similarity * 100).toFixed(1)}% similar)`)
})
```
```python
from supabase import create_client
from openai import OpenAI
import os
supabase = create_client(...)
openai = OpenAI(api_key=os.environ.get('OPENAI_API_KEY'))
async def semantic_search(query, top_k=5):
# Embed the query
query_embedding = openai.embeddings.create(
model='text-embedding-3-small',
input=query
)
query_vector = query_embedding.data[0].embedding
# Search for similar vectors
results = supabase.storage.vectors() \
.from_('embeddings') \
.index('documents-openai') \
.query(
query_vector={'float32': query_vector},
topK=top_k,
return_distance=True,
return_metadata=True
)
return [
{
'id': result.key,
'title': result.metadata.get('title') if result.metadata else None,
'similarity': 1 - result.distance if result.distance else 0, # Convert distance to similarity (0-1)
'metadata': result.metadata
}
for result in results.vectors
]
# Usage
results = semantic_search('How do I use vector search?')
for result in results:
print(f'{result["title"]} ({result["similarity"] * 100:.1f}% similar)')
```
```sql
-- Semantic search from PostgreSQL
-- First, generate embedding from external API and store in a variable
-- Then use it to query vectors
WITH query_embedding AS (
SELECT '[/* ... embedding from OpenAI API ... */]'::embd as embedding
)
SELECT
key,
metadata->>'title' as title,
embd_distance(data) as distance,
(1 - embd_distance(data)) as similarity_score
FROM s3_vectors.documents_openai,
query_embedding
WHERE data <==> query_embedding.embedding
ORDER BY embd_distance(data) ASC
LIMIT 5;
```
## Filtered similarity search
```typescript
const index = supabase.storage.vectors
.from('embeddings')
.index('documents-openai')
// Search with metadata filter
const { data } = await index.queryVectors({
queryVector: { float32: [...embedding...] },
topK: 10,
filter: {
// Filter by metadata fields
category: 'electronics',
in_stock: true,
price: { $lte: 500 } // Less than or equal to 500
},
returnDistance: true,
returnMetadata: true
})
```
```python
index = supabase.storage.vectors() \
.from_('embeddings') \
.index('documents-openai')
# Search with metadata filter
results = index.query(
query_vector={'float32': [...embedding...]},
topK=10,
filter={
# Filter by metadata fields
'category': 'electronics',
'in_stock': True,
'price': {'$lte': 500} # Less than or equal to 500
},
return_distance=True,
return_metadata=True
)
```
```sql
-- Search with metadata filters
SELECT
key,
metadata->>'title' as title,
(metadata->>'price')::numeric as price,
embd_distance(data) as distance,
(1 - embd_distance(data)) as similarity
FROM s3_vectors.documents_openai
WHERE data <==> '[...]'::embd
AND (metadata->>'category') = 'electronics'
AND (metadata->>'in_stock')::boolean = true
AND (metadata->>'price')::numeric <= 500
ORDER BY embd_distance(data) ASC
LIMIT 10;
```
## Retrieving specific vectors
```typescript
const index = supabase.storage.vectors.from('embeddings').index('documents-openai')
const { data, error } = await index.getVectors({
keys: ['doc-1', 'doc-2', 'doc-3'],
returnData: true,
returnMetadata: true,
})
if (!error) {
data.vectors.forEach((vector) => {
console.log(`${vector.key}: ${vector.metadata?.title}`)
})
}
```
```python
index = supabase.storage.vectors().from_('embeddings').index('documents-openai')
results = index.get('doc-1', 'doc-2', 'doc-3', return_data=True, return_metadata=True)
if results:
for vector in results.vectors:
print(f'{vector.key}: {vector.metadata.get("title") if vector.metadata else "N/A"}')
```
```sql
-- Retrieve specific vectors by key
select
key,
data as embedding,
metadata
from s3_vectors.documents_openai
where key in ('doc-1', 'doc-2', 'doc-3');
```
## Listing vectors
```typescript
const index = supabase.storage.vectors.from('embeddings').index('documents-openai')
let nextToken = undefined
let pageCount = 0
do {
const { data, error } = await index.listVectors({
maxResults: 100,
nextToken,
returnData: false, // Don't return embeddings for faster response
returnMetadata: true,
})
if (error) break
pageCount++
console.log(`Page ${pageCount}: ${data.vectors.length} vectors`)
data.vectors.forEach((vector) => {
console.log(` - ${vector.key}: ${vector.metadata?.title}`)
})
nextToken = data.nextToken
} while (nextToken)
```
```python
index = supabase.storage.vectors().from_('embeddings').index('documents-openai')
next_token = None
page_count = 0
while True:
results = index.list(
max_results=100,
next_token=next_token,
return_data=False, # Don't return embeddings for faster response
return_metadata=True
)
if not results:
break
page_count += 1
print(f'Page {page_count}: {len(results.vectors)} vectors')
for vector in results.vectors:
print(f' - {vector.key}: {vector.metadata.get("title") if vector.metadata else "N/A"}')
next_token = results.nextToken
if not next_token:
break
```
```sql
-- List all vectors with pagination
select
key,
metadata
from s3_vectors.documents_openai
order by key asc
limit 100 offset 0;
-- To paginate, increase OFFSET for next page:
-- OFFSET 100 for page 2, OFFSET 200 for page 3, etc.
```
## Hybrid search: Vectors + relational data
Combine similarity search with SQL filtering and joins:
```typescript
async function hybridSearch(queryVector, filters) {
const index = supabase.storage.vectors.from('embeddings').index('documents-openai')
// Get similar vectors with filters
const { data: vectorResults } = await index.queryVectors({
queryVector: { float32: queryVector },
topK: 100,
filter: filters,
returnDistance: true,
returnMetadata: true,
})
// Get additional details from relational database
const { data: details } = await supabase
.from('documents')
.select('*')
.in(
'id',
vectorResults.vectors.map((v) => v.metadata?.doc_id)
)
// Merge results
return vectorResults.vectors.map((vector) => {
const detail = details?.find((d) => d.id === vector.metadata?.doc_id)
return {
...vector,
...detail,
}
})
}
```
```python
def hybrid_search(query_vector, filters):
index = supabase.storage.vectors().from_('embeddings').index('documents-openai')
# Get similar vectors with filters
vector_results = index.query(
query_vector={'float32': query_vector},
topK=100,
filter=filters,
return_distance=True,
return_metadata=True
)
# Get additional details from relational database
doc_ids = [v.metadata.get('doc_id') for v in vector_results.vectors if v.metadata and v.metadata.get('doc_id')]
details_response = supabase.table('documents').select('*').in_('id', doc_ids).execute()
details = details_response.data if details_response.data else []
# Merge results
return [
{
**vector.__dict__ if hasattr(vector, '__dict__') else {},
**next((d for d in details if d['id'] == vector.metadata.get('doc_id')), {})
}
for vector in vector_results.vectors
]
```
```sql
-- Hybrid search: vectors + relational data join
SELECT
v.key as vector_id,
v.metadata->>'title' as vector_title,
d.id as document_id,
d.full_text,
d.author,
d.created_at,
embd_distance(v.data) as similarity_score
FROM s3_vectors.documents_openai v
LEFT JOIN public.documents d
ON v.metadata->>'doc_id' = d.id::text
WHERE v.data <==> '[...]'::embd
AND embd_distance(v.data) < 0.3 -- High similarity threshold
AND d.category = 'articles'
ORDER BY embd_distance(v.data) ASC
LIMIT 50;
```
## Real-world examples
### RAG (retrieval-augmented generation)
```typescript
import OpenAI from 'openai'
import { createClient } from '@supabase/supabase-js'
async function retrieveContextForLLM(userQuery) {
const supabase = createClient(...)
const openai = new OpenAI()
// 1. Embed the user query
const queryEmbedding = await openai.embeddings.create({
model: 'text-embedding-3-small',
input: userQuery
})
// 2. Retrieve relevant documents
const { data: vectorResults } = await supabase.storage.vectors
.from('embeddings')
.index('documents-openai')
.queryVectors({
queryVector: { float32: queryEmbedding.data[0].embedding },
topK: 5,
returnMetadata: true
})
// 3. Use vectors to augment LLM prompt
const context = vectorResults.vectors
.map(v => v.metadata?.content || '')
.join('\n\n')
const response = await openai.chat.completions.create({
model: 'gpt-4',
messages: [
{
role: 'system',
content: `Use the following context to answer the user's question:\n\n${context}`
},
{
role: 'user',
content: userQuery
}
]
})
return response.choices[0].message.content
}
```
```python
from openai import OpenAI
from supabase import create_client
async def retrieve_context_for_llm(user_query):
supabase = create_client(...)
openai = OpenAI()
# 1. Embed the user query
query_embedding = openai.embeddings.create(
model='text-embedding-3-small',
input=user_query
)
# 2. Retrieve relevant documents
vector_results = supabase.storage.vectors() \
.from_('embeddings') \
.index('documents-openai') \
.query(
query_vector={'float32': query_embedding.data[0].embedding},
topK=5,
return_metadata=True
)
# 3. Use vectors to augment LLM prompt
context = '\n\n'.join(
v.metadata.get('content', '') if v.metadata else ''
for v in vector_results.vectors
)
response = openai.chat.completions.create(
model='gpt-4',
messages=[
{
'role': 'system',
'content': f'Use the following context to answer the user\'s question:\n\n{context}'
},
{
'role': 'user',
'content': user_query
}
]
)
return response.choices[0].message.content
```
### Product recommendations
```typescript
async function recommendProducts(userEmbedding, topK = 5) {
const supabase = createClient(...)
// Find similar products
const { data } = await supabase.storage.vectors
.from('embeddings')
.index('products-openai')
.queryVectors({
queryVector: { float32: userEmbedding },
topK,
filter: {
in_stock: true
},
returnMetadata: true
})
return data.vectors.map((result) => ({
id: result.metadata?.product_id,
name: result.metadata?.name,
price: result.metadata?.price,
similarity: 1 - result.distance
}))
}
```
```python
def recommend_products(user_embedding, top_k=5):
supabase = create_client(...)
# Find similar products
results = supabase.storage.vectors() \
.from_('embeddings') \
.index('products-openai') \
.query(
query_vector={'float32': user_embedding},
topK=top_k,
filter={'in_stock': True},
return_metadata=True
)
return [
{
'id': result.metadata.get('product_id') if result.metadata else None,
'name': result.metadata.get('name') if result.metadata else None,
'price': result.metadata.get('price') if result.metadata else None,
'similarity': 1 - result.distance if result.distance else 0
}
for result in results.vectors
]
```
### Filtering before similarity search
```typescript
// Use metadata filters to reduce search scope
const { data } = await index.queryVectors({
queryVector,
topK: 100,
filter: {
category: 'electronics', // Pre-filter by category
},
})
```
```python
# Use metadata filters to reduce search scope
results = index.query(
query_vector=query_vector,
topK=100,
filter={'category': 'electronics'} # Pre-filter by category
)
```
## Next steps
* [Store vectors](/docs/guides/storage/vector/storing-vectors)
* [Work with vector indexes](/docs/guides/storage/vector/working-with-indexes)
* [Explore vector bucket limits](/docs/guides/storage/vector/limits)
# Storing Vectors
Insert and update vector embeddings with metadata using the JavaScript SDK or Postgres.
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Once you've created a bucket and index, you can start storing vectors. Vectors can include optional metadata for filtering and enrichment during queries.
## Basic vector insertion
```typescript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://your-project-id.supabase.co', 'your-service-key')
// Get bucket and index
const bucket = supabase.storage.vectors.from('embeddings')
const index = bucket.index('documents-openai')
// Insert vectors
const { error } = await index.putVectors({
vectors: [
{
key: 'doc-1',
data: {
float32: [0.1, 0.2, 0.3 /* ... rest of embedding ... */],
},
metadata: {
title: 'Getting Started with Vector Buckets',
source: 'documentation',
},
},
{
key: 'doc-2',
data: {
float32: [0.4, 0.5, 0.6 /* ... rest of embedding ... */],
},
metadata: {
title: 'Advanced Vector Search',
source: 'blog',
},
},
],
})
if (error) {
console.error('Error storing vectors:', error)
} else {
console.log('✓ Vectors stored successfully')
}
```
```python
from supabase import create_client
supabase = create_client('https://your-project-id.supabase.co', 'your-service-key')
# Get bucket and index
bucket = supabase.storage.vectors().from_('embeddings')
index = bucket.index('documents-openai')
# Insert vectors
index.put([
{
'key': 'doc-1',
'data': {'float32': [0.1, 0.2, 0.3]}, # ... rest of embedding
'metadata': {
'title': 'Getting Started with Vector Buckets',
'source': 'documentation',
},
},
{
'key': 'doc-2',
'data': {'float32': [0.4, 0.5, 0.6]}, # ... rest of embedding
'metadata': {
'title': 'Advanced Vector Search',
'source': 'blog',
},
},
])
print('✓ Vectors stored successfully')
```
```sql
-- Setup S3 Vector Wrapper (one-time setup)
-- https://supabase.com/docs/guides/database/extensions/wrappers/s3_vectors
-- Insert vectors into the index
INSERT INTO s3_vectors.documents_openai (key, data, metadata)
VALUES
(
'doc-1',
'[0.1, 0.2, 0.3, /* ... rest of embedding ... */]'::embd,
'{"title": "Getting Started with Vector Buckets", "source": "documentation"}'::jsonb
),
(
'doc-2',
'[0.4, 0.5, 0.6, /* ... rest of embedding ... */]'::embd,
'{"title": "Advanced Vector Search", "source": "blog"}'::jsonb
);
```
## Storing vectors from Embeddings API
Generate embeddings using an LLM API and store them directly:
```typescript
import { createClient } from '@supabase/supabase-js'
import OpenAI from 'openai'
const supabase = createClient('https://your-project-id.supabase.co', 'your-service-key')
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
})
// Documents to embed and store
const documents = [
{ id: '1', title: 'How to Train Your AI', content: 'Guide for training models...' },
{ id: '2', title: 'Vector Search Best Practices', content: 'Tips for semantic search...' },
{
id: '3',
title: 'Building RAG Systems',
content: 'Implementing retrieval-augmented generation...',
},
]
// Generate embeddings
const embeddings = await openai.embeddings.create({
model: 'text-embedding-3-small',
input: documents.map((doc) => doc.content),
})
// Prepare vectors for storage
const vectors = documents.map((doc, index) => ({
key: doc.id,
data: {
float32: embeddings.data[index].embedding,
},
metadata: {
title: doc.title,
source: 'knowledge_base',
created_at: new Date().toISOString(),
},
}))
// Store vectors in batches (max 500 per request)
const bucket = supabase.storage.vectors.from('embeddings')
const vectorIndex = bucket.index('documents-openai')
for (let i = 0; i < vectors.length; i += 500) {
const batch = vectors.slice(i, i + 500)
const { error } = await vectorIndex.putVectors({ vectors: batch })
if (error) {
console.error(`Error storing batch ${i / 500 + 1}:`, error)
} else {
console.log(`✓ Stored batch ${i / 500 + 1} (${batch.length} vectors)`)
}
}
```
```python
from supabase import create_client
from openai import OpenAI
from datetime import datetime
supabase = create_client('https://your-project-id.supabase.co', 'your-service-key')
openai = OpenAI(api_key=os.environ.get('OPENAI_API_KEY'))
# Documents to embed and store
documents = [
{'id': '1', 'title': 'How to Train Your AI', 'content': 'Guide for training models...'},
{'id': '2', 'title': 'Vector Search Best Practices', 'content': 'Tips for semantic search...'},
{'id': '3', 'title': 'Building RAG Systems', 'content': 'Implementing retrieval-augmented generation...'},
]
# Generate embeddings
embeddings_response = openai.embeddings.create(
model='text-embedding-3-small',
input=[doc['content'] for doc in documents]
)
# Prepare vectors for storage
vectors = []
for doc, embedding_data in zip(documents, embeddings_response.data):
vectors.append({
'key': doc['id'],
'data': {'float32': embedding_data.embedding},
'metadata': {
'title': doc['title'],
'source': 'knowledge_base',
'created_at': datetime.now().isoformat(),
},
})
# Store vectors in batches (max 500 per request)
bucket = supabase.storage.vectors().from_('embeddings')
vector_index = bucket.index('documents-openai')
batch_size = 500
for i in range(0, len(vectors), batch_size):
batch = vectors[i:i + batch_size]
vector_index.put(batch)
print(f'✓ Stored batch {i // batch_size + 1} ({len(batch)} vectors)')
```
```sql
-- Insert vectors with pre-generated embeddings
INSERT INTO s3_vectors.documents_openai (key, data, metadata)
VALUES
(
'1',
'[0.1, 0.2, 0.3, /* ... rest of embedding ... */]'::embd,
'{"title": "How to Train Your AI", "source": "knowledge_base", "created_at": "2025-01-01T00:00:00Z"}'::jsonb
),
(
'2',
'[0.4, 0.5, 0.6, /* ... rest of embedding ... */]'::embd,
'{"title": "Vector Search Best Practices", "source": "knowledge_base", "created_at": "2025-01-01T00:00:00Z"}'::jsonb
),
(
'3',
'[0.7, 0.8, 0.9, /* ... rest of embedding ... */]'::embd,
'{"title": "Building RAG Systems", "source": "knowledge_base", "created_at": "2025-01-01T00:00:00Z"}'::jsonb
);
```
## Updating vectors
```typescript
const index = bucket.index('documents-openai')
// Update a vector (same key)
const { error } = await index.putVectors({
vectors: [
{
key: 'doc-1',
data: {
float32: [0.15, 0.25, 0.35 /* ... updated embedding ... */],
},
metadata: {
title: 'Getting Started with Vector Buckets - Updated',
updated_at: new Date().toISOString(),
},
},
],
})
if (!error) {
console.log('✓ Vector updated successfully')
}
```
```python
index = bucket.index('documents-openai')
# Update a vector (same key)
index.put([
{
'key': 'doc-1',
'data': {'float32': [0.15, 0.25, 0.35]}, # ... updated embedding
'metadata': {
'title': 'Getting Started with Vector Buckets - Updated',
'updated_at': datetime.now().isoformat(),
},
},
])
print('✓ Vector updated successfully')
```
```sql
-- Update a vector (delete and re-insert)
DELETE FROM s3_vectors.documents_openai WHERE key = 'doc-1';
INSERT INTO s3_vectors.documents_openai (key, data, metadata)
VALUES (
'doc-1',
'[0.15, 0.25, 0.35, /* ... updated embedding ... */]'::embd,
'{"title": "Getting Started with Vector Buckets - Updated", "updated_at": "2025-01-01T00:00:00Z"}'::jsonb
);
```
## Deleting vectors
```typescript
const index = bucket.index('documents-openai')
// Delete specific vectors
const { error } = await index.deleteVectors({
keys: ['doc-1', 'doc-2'],
})
if (!error) {
console.log('✓ Vectors deleted successfully')
}
```
```python
index = bucket.index('documents-openai')
# Delete specific vectors
index.delete(['doc-1', 'doc-2'])
print('✓ Vectors deleted successfully')
```
```sql
-- Delete vectors by key
delete from s3_vectors.documents_openai
where key in ('doc-1', 'doc-2');
```
## Metadata best practices
Metadata makes vectors more useful by enabling filtering and context:
```typescript
const vectors = [
{
key: 'product-001',
data: { float32: [...] },
metadata: {
product_id: 'prod-001',
category: 'electronics',
price: 299.99,
in_stock: true,
tags: ['laptop', 'portable'],
description: 'High-performance ultrabook'
}
},
{
key: 'product-002',
data: { float32: [...] },
metadata: {
product_id: 'prod-002',
category: 'electronics',
price: 99.99,
in_stock: true,
tags: ['headphones', 'wireless'],
description: 'Noise-cancelling wireless headphones'
}
}
]
const { error } = await index.putVectors({ vectors })
```
### Metadata field guidelines
* **Keep it lightweight** - Metadata is returned with query results, so large values increase response size
* **Use consistent types** - Store the same field with consistent data types across vectors
* **Index key fields** - Mark fields you'll filter by to improve query performance
* **Avoid nested objects** - While supported, flat structures are easier to filter
## Batch processing large datasets
For storing large numbers of vectors efficiently:
```typescript
import { createClient } from '@supabase/supabase-js'
import fs from 'fs'
const supabase = createClient(...)
const index = supabase.storage.vectors
.from('embeddings')
.index('documents-openai')
// Read embeddings from file
const embeddingsFile = fs.readFileSync('embeddings.jsonl', 'utf-8')
const lines = embeddingsFile.split('\n').filter(line => line.trim())
const vectors = lines.map((line, idx) => {
const { key, embedding, metadata } = JSON.parse(line)
return {
key,
data: { float32: embedding },
metadata
}
})
// Process in batches
const BATCH_SIZE = 500
let processed = 0
for (let i = 0; i < vectors.length; i += BATCH_SIZE) {
const batch = vectors.slice(i, i + BATCH_SIZE)
try {
const { error } = await index.putVectors({ vectors: batch })
if (error) throw error
processed += batch.length
console.log(`Progress: ${processed}/${vectors.length}`)
} catch (error) {
console.error(`Batch failed at offset ${i}:`, error)
// Optionally implement retry logic
}
}
console.log('✓ All vectors stored successfully')
```
```python
from supabase import create_client
import json
supabase = create_client(...)
index = supabase.storage.vectors().from_('embeddings').index('documents-openai')
# Read embeddings from file
with open('embeddings.jsonl', 'r') as f:
lines = [line.strip() for line in f if line.strip()]
vectors = []
for line in lines:
data = json.loads(line)
vectors.append({
'key': data['key'],
'data': {'float32': data['embedding']},
'metadata': data.get('metadata', {})
})
# Process in batches
BATCH_SIZE = 500
processed = 0
for i in range(0, len(vectors), BATCH_SIZE):
batch = vectors[i:i + BATCH_SIZE]
try:
index.put(batch)
processed += len(batch)
print(f'Progress: {processed}/{len(vectors)}')
except Exception as e:
print(f'Batch failed at offset {i}: {e}')
# Optionally implement retry logic
print('✓ All vectors stored successfully')
```
## Performance optimization
### Batch operations
Always use batch operations for better performance:
```typescript
// ❌ Inefficient - Multiple requests
for (const vector of vectors) {
await index.putVectors({ vectors: [vector] })
}
// ✅ Efficient - Single batch operation
await index.putVectors({ vectors })
```
```python
# ❌ Inefficient - Multiple requests
for vector in vectors:
index.put([vector])
# ✅ Efficient - Single batch operation
index.put(vectors)
```
### Metadata considerations
Keep metadata concise:
```typescript
// ❌ Large metadata
metadata: {
full_document_text: 'Very long document content...',
detailed_analysis: { /* large object */ }
}
// ✅ Lean metadata
metadata: {
doc_id: 'doc-123',
category: 'news',
summary: 'Brief summary'
}
```
## Next steps
* [Query vectors with similarity search](/docs/guides/storage/vector/querying-vectors)
* [Work with vector indexes](/docs/guides/storage/vector/working-with-indexes)
* [Explore vector bucket limits](/docs/guides/storage/vector/limits)
# Working with Vector Indexes
Create, manage, and optimize vector indexes for efficient similarity search.
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Vector indexes organize embeddings within a bucket with consistent dimensions and distance metrics. Each index defines how similarity searches are performed across your vectors.
## Understanding vector indexes
An index specifies:
* **Index Name** - Unique identifier within the bucket
* **Dimension** - Size of vector embeddings (e.g., 1536 for OpenAI)
* **Distance Metric** - Similarity calculation method (cosine, euclidean, or L2)
* **Data Type** - Vector format (currently `float32`)
Think of an index as a table in a traditional database. It has a schema (dimension) and a query strategy (distance metric).
## Creating indexes
### Via Dashboard
1. Open your vector bucket in the Supabase Dashboard.
2. Click **Create Index**.
3. Enter an index name (e.g., `documents-openai`).
4. Set the dimension matching your embeddings (e.g., `1536` for OpenAI's text-embedding-3-small).
5. Select the distance metric (`cosine`, `euclidean`, or `l2`).
6. Click **Create**.
### Via SDK
```typescript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://your-project-id.supabase.co', 'your-service-key')
const bucket = supabase.storage.vectors.from('embeddings')
// Create an index
const { data, error } = await bucket.createIndex({
indexName: 'documents-openai',
dataType: 'float32',
dimension: 1536,
distanceMetric: 'cosine',
})
if (error) {
console.error('Error creating index:', error)
} else {
console.log('Index created:', data)
}
```
```python
from supabase import create_client
supabase = create_client('https://your-project-id.supabase.co', 'your-service-key')
bucket = supabase.storage.vectors().from_('embeddings')
# Create an index
bucket.create_index(
index_name='documents-openai',
dimension=1536,
distance_metric='cosine',
data_type='float32'
)
print('✓ Index created: documents-openai')
```
### Choosing the right metric
Most modern embedding models work best with **cosine** distance:
* **OpenAI** (text-embedding-3-small, text-embedding-3-large): Cosine
* **Cohere** (embed-english-v3.0): Cosine
* **Hugging Face** (sentence-transformers): Cosine
* **Google** (text-embedding-004): Cosine
* **Llama 2** embeddings: Cosine or L2
**Tip**: Check your embedding model's documentation for the recommended distance metric.
**Important**: Creating an index with incorrect dimensions will cause insert and query operations to fail.
## Managing multiple indexes
Create multiple indexes for different use cases or embedding models:
```typescript
const bucket = supabase.storage.vectors.from('embeddings')
// Index for OpenAI embeddings
await bucket.createIndex({
indexName: 'documents-openai',
dimension: 1536,
distanceMetric: 'cosine',
dataType: 'float32',
})
// Index for Cohere embeddings
await bucket.createIndex({
indexName: 'documents-cohere',
dimension: 1024,
distanceMetric: 'cosine',
dataType: 'float32',
})
// Index for different use case
await bucket.createIndex({
indexName: 'images-openai',
dimension: 1536,
distanceMetric: 'cosine',
dataType: 'float32',
})
// List all indexes
const { data: indexes } = await bucket.listIndexes()
console.log('All indexes:', indexes)
```
```python
bucket = supabase.storage.vectors().from_('embeddings')
# Index for OpenAI embeddings
bucket.create_index(
index_name='documents-openai',
dimension=1536,
distance_metric='cosine',
data_type='float32'
)
# Index for Cohere embeddings
bucket.create_index(
index_name='documents-cohere',
dimension=1024,
distance_metric='cosine',
data_type='float32'
)
# Index for different use case
bucket.create_index(
index_name='images-openai',
dimension=1536,
distance_metric='cosine',
data_type='float32'
)
# List all indexes
indexes = bucket.list_indexes()
print('All indexes:', indexes)
```
### Use cases for multiple indexes
* **Different embedding models** - Store vectors from OpenAI, Cohere, and local models separately
* **Different domains** - Maintain separate indexes for documents, images, products, etc.
* **A/B testing** - Compare different embedding models side-by-side
* **Multi-language** - Keep language-specific embeddings separate
## Listing and inspecting indexes
### List all indexes in a bucket
```typescript
const bucket = supabase.storage.vectors.from('embeddings')
const { data: indexes, error } = await bucket.listIndexes()
if (!error) {
indexes?.forEach((index) => {
console.log(`Index: ${index.name}`)
console.log(` Dimension: ${index.dimension}`)
console.log(` Distance: ${index.distanceMetric}`)
})
}
```
```python
bucket = supabase.storage.vectors().from_('embeddings')
indexes = bucket.list_indexes()
if indexes:
for index in indexes.indexes:
print(f'Index: {index.indexName}')
```
### Get index details
```typescript
const { data: indexDetails, error } = await bucket.getIndex('documents-openai')
if (!error && indexDetails) {
console.log(`Index: ${indexDetails.name}`)
console.log(`Created at: ${indexDetails.createdAt}`)
console.log(`Dimension: ${indexDetails.dimension}`)
console.log(`Distance metric: ${indexDetails.distanceMetric}`)
}
```
```python
index_details = bucket.get_index('documents-openai')
if index_details:
print(f'Index: {index_details.index.index_name}')
print(f'Dimension: {index_details.index.dimension}')
print(f'Distance metric: {index_details.index.distance_metric}')
```
## Deleting indexes
Delete an index to free storage space:
```typescript
const bucket = supabase.storage.vectors.from('embeddings')
const { error } = await bucket.deleteIndex('documents-openai')
if (error) {
console.error('Error deleting index:', error)
} else {
console.log('Index deleted successfully')
}
```
```python
bucket = supabase.storage.vectors().from_('embeddings')
bucket.delete_index('documents-openai')
print('✓ Index deleted successfully')
```
### Before deleting an index
**Warning**: Deleting an index is permanent and cannot be undone.
* **Backup important data** - Export vectors before deletion if needed
* **Update applications** - Ensure no code references the deleted index
* **Check dependencies** - Verify no active queries use the index
* **Plan the deletion** - Do this during low-traffic periods
### Immutable properties
Once created, these properties **cannot be changed**:
* **Dimension** - Must create new index with different dimension
* **Distance metric** - Cannot change after creation
* **Data type** - Currently only `float32` supported
### Optimizing index performance
```typescript
// Good - Appropriate batch size
const batch = vectors.slice(0, 250)
await index.putVectors({ vectors: batch })
// Good - Filter metadata before query
const { data } = await index.queryVectors({
queryVector,
topK: 5,
filter: { category: 'electronics' },
})
// Avoid - Single vector inserts
for (const vector of vectors) {
await index.putVectors({ vectors: [vector] })
}
// Avoid - Returning unnecessary data
const { data } = await index.queryVectors({
queryVector,
topK: 1000, // Too many results
returnData: true, // Include large embeddings
})
```
```python
# Good - Appropriate batch size
batch = vectors[:250]
index.put(batch)
# Good - Filter metadata before query
results = index.query(
query_vector=query_vector,
topK=5,
filter={'category': 'electronics'}
)
# Avoid - Single vector inserts
for vector in vectors:
index.put([vector])
# Avoid - Returning unnecessary data
results = index.query(
query_vector=query_vector,
topK=1000, # Too many results
return_data=True # Include large embeddings
)
```
## Next steps
* [Store vectors in indexes](/docs/guides/storage/vector/storing-vectors)
* [Query vectors for similarity search](/docs/guides/storage/vector/querying-vectors)
* [Understand vector bucket limits](/docs/guides/storage/vector/limits)
* [Create vector buckets](/docs/guides/storage/vector/creating-vector-buckets)
# Limits
Learn how to increase Supabase file limits.
## Global file size
You can set the maximum file size across all your buckets by setting the *Global file size limit* value in your [Storage Settings](/dashboard/project/_/storage/settings). For Free projects, the limit can't exceed 50 MB. On the Pro Plan and up, you can set this value to up to 500 GB. If you need more than 500 GB, [contact us](/dashboard/support/new).
| Plan | Max File Size Limit |
| ---------- | ------------------- |
| Free | 50 MB |
| Pro | 500 GB |
| Team | 500 GB |
| Enterprise | Custom |
This option is a global limit, which applies to all your buckets.
Additionally, you can specify the maximum file size on a per [bucket level](/docs/guides/storage/buckets/creating-buckets#restricting-uploads) but it can't be higher than this global limit. As a good practice, the global limit should be set to the highest possible file size that your application accepts, with smaller per-bucket limits set as needed.
## Per bucket restrictions
You can have different restrictions on a per bucket level such as restricting the file types (e.g. `pdf`, `images`, `videos`) or the maximum file size, which should be lower than the global limit. To apply these limits on a bucket level see [Creating Buckets](/docs/guides/storage/buckets/creating-buckets#restricting-uploads).
## File name restrictions
File names can only include the following characters:
* **Alphanumeric**: `A-Z`, `a-z`, `0-9`
* **Punctuation**: `_` (underscore), `-` (hyphen), `.` (dot), `'` (apostrophe), `,` (comma)
* **Special characters**: `!`, `*`, `&`, `$`, `@`, `=`, `;`, `:`, `+`, `?`, `(`, `)`
* **Whitespace**
# Resumable Uploads
Learn how to upload files to Supabase Storage.
The resumable upload method is recommended when:
* Uploading large files that may exceed 6MB in size
* Network stability is a concern
* You want to have progress events for your uploads
Supabase Storage implements the [TUS protocol](https://tus.io/) to enable resumable uploads. TUS stands for The Upload Server and is an open protocol for supporting resumable uploads. The protocol allows the upload process to be resumed from where it left off in case of interruptions. This method can be implemented using the [`tus-js-client`](https://github.com/tus/tus-js-client) library, or other client-side libraries like [Uppy](https://uppy.io/docs/tus/) that support the TUS protocol.
For optimal performance when uploading large files you should always use the direct storage hostname. This provides several performance enhancements that will greatly improve performance when uploading large files.
Instead of `https://project-id.supabase.co` use `https://project-id.storage.supabase.co`
Here's an example of how to upload a file using `tus-js-client`:
Typically we advise against using `getSession`, because the session is read from local storage and you can't trust its claims for auth decisions. In this case however, the code only needs the raw access token string to forward as a credential to Supabase storage, which validates the token server-side. Since no client-side auth decision is made based on the session data, `getSession` is appropriate here.
```javascript
const tus = require('tus-js-client')
const projectId = ''
async function uploadFile(bucketName, fileName, file) {
const { data: { session } } = await supabase.auth.getSession()
return new Promise((resolve, reject) => {
var upload = new tus.Upload(file, {
// Supabase TUS endpoint (with direct storage hostname)
endpoint: `https://${projectId}.storage.supabase.co/storage/v1/upload/resumable`,
retryDelays: [0, 3000, 5000, 10000, 20000],
headers: {
authorization: `Bearer ${session.access_token}`,
'x-upsert': 'true', // optionally set upsert to true to overwrite existing files
},
uploadDataDuringCreation: true,
removeFingerprintOnSuccess: true, // Important if you want to allow re-uploading the same file https://github.com/tus/tus-js-client/blob/main/docs/api.md#removefingerprintonsuccess
metadata: {
bucketName: bucketName,
objectName: fileName,
contentType: 'image/png',
cacheControl: '3600',
metadata: JSON.stringify({ // custom metadata passed to the user_metadata column
yourCustomMetadata: true,
}),
},
chunkSize: 6 * 1024 * 1024, // NOTE: it must be set to 6MB (for now) do not change it
onError: function (error) {
console.log('Failed because: ' + error)
reject(error)
},
onProgress: function (bytesUploaded, bytesTotal) {
var percentage = ((bytesUploaded / bytesTotal) * 100).toFixed(2)
console.log(bytesUploaded, bytesTotal, percentage + '%')
},
onSuccess: function () {
console.log('Download %s from %s', upload.file.name, upload.url)
resolve()
},
})
// Check if there are any previous uploads to continue.
return upload.findPreviousUploads().then(function (previousUploads) {
// Found previous uploads so we select the first one.
if (previousUploads.length) {
upload.resumeFromPreviousUpload(previousUploads[0])
}
// Start the upload
upload.start()
})
})
}
```
Here's an example of how to upload a file using `@uppy/tus` with react:
```javascript
import { useEffect, useState } from "react";
import { createClient } from "@supabase/supabase-js";
import Uppy from "@uppy/core";
import Tus from "@uppy/tus";
import Dashboard from "@uppy/dashboard";
import "@uppy/core/dist/style.min.css";
import "@uppy/dashboard/dist/style.min.css";
function App() {
// Initialize Uppy instance with the 'sample' bucket specified for uploads
const uppy = useUppyWithSupabase({ bucketName: "sample" });
useEffect(() => {
// Set up Uppy Dashboard to display as an inline component within a specified target
uppy.use(Dashboard, {
inline: true, // Ensures the dashboard is rendered inline
target: "#drag-drop-area", // HTML element where the dashboard renders
showProgressDetails: true, // Show progress details for file uploads
});
}, []);
return (
{/* Target element for the Uppy Dashboard */}
);
}
export default App;
/**
* Custom hook for configuring Uppy with Supabase authentication and TUS resumable uploads
* @param {Object} options - Configuration options for the Uppy instance.
* @param {string} options.bucketName - The bucket name in Supabase where files are stored.
* @returns {Object} uppy - Uppy instance with configured upload settings.
*/
export const useUppyWithSupabase = ({ bucketName }: { bucketName: string }) => {
// Initialize Uppy instance only once
const [uppy] = useState(() => new Uppy());
// Initialize Supabase client with project URL and publishable key
const supabase = createClient(`https://${projectId}.supabase.co`, publishableKey);
useEffect(() => {
const initializeUppy = async () => {
// Retrieve the current user's session for authentication
const {
data: { session },
} = await supabase.auth.getSession();
uppy.use(Tus, {
// Supabase TUS endpoint (with direct storage hostname)
endpoint: `https://${projectId}.storage.supabase.co/storage/v1/upload/resumable`,
retryDelays: [0, 3000, 5000, 10000, 20000], // Retry delays for resumable uploads
headers: {
authorization: `Bearer ${session?.access_token}`, // User session access token
apikey: anonKey, // API key for Supabase
},
uploadDataDuringCreation: true, // Send metadata with file chunks
removeFingerprintOnSuccess: true, // Remove fingerprint after successful upload
chunkSize: 6 * 1024 * 1024, // Chunk size for TUS uploads (6MB)
allowedMetaFields: [
"bucketName",
"objectName",
"contentType",
"cacheControl",
"metadata",
], // Metadata fields allowed for the upload
onError: (error) => console.error("Upload error:", error), // Error handling for uploads
}).on("file-added", (file) => {
// Attach metadata to each file, including bucket name and content type
file.meta = {
...file.meta,
bucketName, // Bucket specified by the user of the hook
objectName: file.name, // Use file name as object name
contentType: file.type, // Set content type based on file MIME type
metadata: JSON.stringify({ // custom metadata passed to the user_metadata column
yourCustomMetadata: true,
}),
};
});
};
// Initialize Uppy with Supabase settings
initializeUppy();
}, [uppy, bucketName]);
// Return the configured Uppy instance
return uppy;
};
```
Kotlin supports resumable uploads natively for all targets:
```kotlin
suspend fun uploadFile(file: File) {
val upload: ResumableUpload = supabase.storage.from("bucket_name")
.resumable.createOrContinueUpload("file_path", file)
upload.stateFlow
.onEach {
println(it.progress)
}
.launchIn(yourCoroutineScope)
upload.startOrResumeUploading()
}
// On other platforms you might have to give the bytes directly and specify a source if you want to continue it later:
suspend fun uploadData(bytes: ByteArray) {
val upload: ResumableUpload = supabase.storage.from("bucket_name")
.resumable.createOrContinueUpload(bytes, "source", "file_path")
upload.stateFlow
.onEach {
println(it.progress)
}
.launchIn(yourCoroutineScope)
upload.startOrResumeUploading()
}
```
Here's an example of how to upload a file using [`tus-py-client`](https://github.com/tus/tus-py-client):
```python
from io import BufferedReader
from tusclient import client
from supabase import create_client
def upload_file(
bucket_name: str, file_name: str, file: BufferedReader, access_token: str
):
# create Tus client
my_client = client.TusClient(
f"{supabase_url}/storage/v1/upload/resumable",
headers={"Authorization": f"Bearer {access_token}", "x-upsert": "true"},
)
uploader = my_client.uploader(
file_stream=file,
chunk_size=(6 * 1024 * 1024),
metadata={
"bucketName": bucket_name,
"objectName": file_name,
"contentType": "image/png",
"cacheControl": "3600",
},
)
uploader.upload()
# create client and sign in
supabase = create_client(supabase_url, supabase_key)
# retrieve the current user's session for authentication
session = supabase.auth.get_session()
# open file and send file stream to upload
with open("./assets/40mb.jpg", "rb") as fs:
upload_file(
bucket_name="assets",
file_name="large_file",
file=fs,
access_token=session.access_token,
)
```
### Upload URL
When uploading using the resumable upload endpoint, the storage server creates a unique URL for each upload, even for multiple uploads to the same path. All chunks will be uploaded to this URL using the `PATCH` method.
This unique upload URL will be valid for **up to 24 hours**. If the upload is not completed within 24 hours, the URL will expire and you'll need to start the upload again. TUS client libraries typically create a new URL if the previous one expires.
### Concurrency
When two or more clients upload to the same upload URL only one of them will succeed. The other clients will receive a `409 Conflict` error. Only 1 client can upload to the same upload URL at a time which prevents data corruption.
When two or more clients upload a file to the same path using different upload URLs, the first client to complete the upload will succeed and the other clients will receive a `409 Conflict` error.
If you provide the `x-upsert` header the last client to complete the upload will succeed instead.
### Uppy example
You can check a [full example using Uppy](https://github.com/supabase/supabase/tree/master/examples/storage/resumable-upload-uppy).
Uppy has integrations with different frameworks:
* [React](https://uppy.io/docs/react/)
* [Svelte](https://uppy.io/docs/svelte/)
* [Vue](https://uppy.io/docs/vue/)
* [Angular](https://uppy.io/docs/angular/)
### Presigned uploads
Resumable uploads also supports using signed upload tokens to created time-limited URLs that you can share to your users by invoking the `createSignedUploadUrl` method on the SDK and including the returned token in the `x-signature` header of the resumable upload.
```typescript
// Create a signed upload URL
const { data } = await supabase.storage.from('bucket_name').createSignedUploadUrl('file_path', {
upsert: true, // Optional: allow overwriting existing files
})
// Use the signed URL token in resumable upload headers
// Include data.token in the x-signature header
```
```python
# Create a signed upload URL with upsert option
response = supabase.storage.from_('bucket_name').create_signed_upload_url(
'file_path',
options={'upsert': 'true'} # Optional: allow overwriting existing files
)
# Use the signed URL token in resumable upload headers
# Include response.token in the x-signature header
```
See this [full example using Uppy with signed URLs](https://github.com/supabase/supabase/tree/master/examples/storage/resumable-upload-signed-uppy) for more context.
## Overwriting files
When uploading a file to a path that already exists, the default behavior is to return a `400 Asset Already Exists` error.
If you want to overwrite a file on a specific path you can set the `x-upsert` header to `true`.
We do advise against overwriting files when possible, as the CDN will take some time to propagate the changes to all the edge nodes leading to stale content.
Uploading a file to a new path is the recommended way to avoid propagation delays and stale content.
To learn more, see the [CDN](/docs/guides/storage/cdn/fundamentals) guide.
# S3 Uploads
Learn how to upload files to Supabase Storage using S3.
You can use the S3 protocol to upload files to Supabase Storage. To get started with S3, see the [S3 setup guide](/docs/guides/storage/s3/authentication).
The S3 protocol supports file upload using:
* A single request
* Multiple requests via Multipart Upload
## Single request uploads
The `PutObject` action uploads the file in a single request. This matches the behavior of the Supabase SDK [Standard Upload](/docs/guides/storage/uploads/standard-uploads).
Use `PutObject` to upload smaller files, where retrying the entire upload won't be an issue. The maximum file size on paid plans is 500 GB.
For example, using JavaScript and the `aws-sdk` client:
```javascript
import { S3Client, PutObjectCommand } from '@aws-sdk/client-s3'
const s3Client = new S3Client({...})
const file = fs.createReadStream('path/to/file')
const uploadCommand = new PutObjectCommand({
Bucket: 'bucket-name',
Key: 'path/to/file',
Body: file,
ContentType: 'image/jpeg',
})
await s3Client.send(uploadCommand)
```
## Multipart uploads
Multipart Uploads split the file into smaller parts and upload them in parallel, maximizing the upload speed on a fast network. When uploading large files, this allows you to retry the upload of individual parts in case of network issues.
This method is preferable over [Resumable Upload](/docs/guides/storage/uploads/resumable-uploads) for server-side uploads, when you want to maximize upload speed at the cost of resumability. The maximum file size on paid plans is 500 GB.
### Upload a file in parts
Use the `Upload` class from an S3 client to upload a file in parts. For example, using JavaScript:
```javascript
import { S3Client } from '@aws-sdk/client-s3'
import { Upload } from '@aws-sdk/lib-storage'
const s3Client = new S3Client({...})
const file = fs.createReadStream('path/to/very-large-file')
const upload = new Upload(s3Client, {
Bucket: 'bucket-name',
Key: 'path/to/file',
ContentType: 'image/jpeg',
Body: file,
})
await uploader.done()
```
### Aborting multipart uploads
All multipart uploads are automatically aborted after 24 hours. To abort a multipart upload before that, you can use the [`AbortMultipartUpload`](https://docs.aws.amazon.com/AmazonS3/latest/API/API_AbortMultipartUpload.html) action.
# Standard Uploads
Learn how to upload files to Supabase Storage.
## Uploading
The standard file upload method is ideal for small files that are not larger than 6MB.
It uses the traditional `multipart/form-data` format and is simple to implement using the supabase-js SDK. Here's an example of how to upload a file using the standard upload method:
Though you can upload up to 5GB files using the standard upload method, we recommend using [TUS Resumable Upload](/docs/guides/storage/uploads/resumable-uploads) for uploading files greater than 6MB in size for better reliability.
```javascript
// @noImplicitAny: false
// ---cut---
import { createClient } from '@supabase/supabase-js'
// Create Supabase client
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// Upload file using standard upload
async function uploadFile(file) {
const { data, error } = await supabase.storage.from('bucket_name').upload('file_path', file)
if (error) {
// Handle error
} else {
// Handle success
}
}
```
```dart
// Upload file using standard upload
Future uploadFile(File file) async {
await supabase.storage.from('bucket_name').upload('file_path', file);
}
```
```swift
import Supabase
// Create Supabase client
let supabase = SupabaseClient(supabaseURL: URL(string: "your_project_url")!, supabaseKey: "your_supabase_api_key")
try await supabase.storage.from("bucket_name").upload(path: "file_path", file: file)
```
```kotlin
supabase.storage.from("bucket_name").upload("file_path", bytes)
//Or on JVM/Android: (This will stream the data from the file to supabase)
supabase.storage.from("bucket_name").upload("file_path", file)
```
```python
response = supabase.storage.from_('bucket_name').upload('file_path', file)
```
```bash
curl -X POST "https://{your_project_ref}.supabase.co/storage/v1/object/{bucket_name}/{file_path}" \
-H "apikey: {your_anon_key}" \
-H "Authorization: Bearer {your_jwt_token}" \
--data-binary "@/local/path/to/your/file.ext"
```
## Overwriting files
When uploading a file to a path that already exists, the default behavior is to return a `400 Asset Already Exists` error.
If you want to overwrite a file on a specific path you can set the `upsert` options to `true` or using the `x-upsert` header.
```javascript
import { createClient } from '@supabase/supabase-js'
const file = new Blob()
// ---cut---
// Create Supabase client
const supabase = createClient('your_project_url', 'your_supabase_api_key')
await supabase.storage.from('bucket_name').upload('file_path', file, {
upsert: true,
})
```
```dart
await supabase.storage.from('bucket_name').upload(
'file_path',
file,
fileOptions: const FileOptions(upsert: true),
);
```
```swift
import Supabase
// Create Supabase client
let supabase = SupabaseClient(supabaseURL: URL(string: "your_project_url")!, supabaseKey: "your_supabase_api_key")
try await supabase.storage.from("bucket_name")
.upload(
path: "file_path",
file: file,
options: FileOptions(
upsert: true
)
)
```
```kotlin
supabase.storage.from("bucket_name").upload("file_path", bytes) {
upsert = true
}
```
```python
response = supabase.storage.from_('bucket_name').upload('file_path', file, {
'upsert': 'true',
})
```
```bash
curl -X POST "https://{your_project_ref}.supabase.co/storage/v1/object/{bucket_name}/{file_path}" \
-H "apikey: {your_anon_key}" \
-H "Authorization: Bearer {your_jwt_token}" \
-H "x-upsert: true" \
--data-binary "@/local/path/to/your/file.ext"
```
We do advise against overwriting files when possible, as our Content Delivery Network will take sometime to propagate the changes to all the edge nodes leading to stale content.
Uploading a file to a new path is the recommended way to avoid propagation delays and stale content.
## Content type
By default, Storage will assume the content type of an asset from the file extension. If you want to specify the content type for your asset, pass the `contentType` option during upload.
```javascript
import { createClient } from '@supabase/supabase-js'
const file = new Blob()
// ---cut---
// Create Supabase client
const supabase = createClient('your_project_url', 'your_supabase_api_key')
await supabase.storage.from('bucket_name').upload('file_path', file, {
contentType: 'image/jpeg',
})
```
```dart
await supabase.storage.from('bucket_name').upload(
'file_path',
file,
fileOptions: const FileOptions(contentType: 'image/jpeg'),
);
```
```swift
import Supabase
// Create Supabase client
let supabase = SupabaseClient(supabaseURL: URL(string: "your_project_url")!, supabaseKey: "your_supabase_api_key")
try await supabase.storage.from("bucket_name")
.upload(
path: "file_path",
file: file,
options: FileOptions(
contentType: "image/jpeg"
)
)
```
```kotlin
supabase.storage.from("bucket_name").upload("file_path", bytes) {
contentType = ContentType.Image.JPEG
}
```
```python
response = supabase.storage.from_('bucket_name').upload('file_path', file, {
'content-type': 'image/jpeg',
})
```
```bash
curl -X POST "https://{your_project_ref}.supabase.co/storage/v1/object/{bucket_name}/{file_path}" \
-H "apikey: {your_anon_key}" \
-H "Authorization: Bearer {your_jwt_token}" \
-H "Content-Type: {Content-Type}" \
--data-binary "@/local/path/to/your/file.ext"
```
## Concurrency
When two or more clients upload a file to the same path, the first client to complete the upload will succeed and the other clients will receive a `400 Asset Already Exists` error.
If you provide the `x-upsert` header the last client to complete the upload will succeed instead.
# Bandwidth & Storage Egress
Bandwidth & Storage Egress
## Bandwidth & Storage egress
Free Plan Organizations in Supabase have a limit of 10 GB of bandwidth (5 GB cached + 5 GB uncached). This limit is calculated by the sum of all the data transferred from the Supabase servers to the client. This includes all the data transferred from the database, storage, and functions.
### Checking Storage egress requests in Logs Explorer
We have a template query that you can use to get the number of requests for each object in [Logs Explorer](/dashboard/project/_/logs/explorer/templates).
```sql
select
request.method as http_verb,
request.path as filepath,
(responseHeaders.cf_cache_status = 'HIT') as cached,
count(*) as num_requests
from
edge_logs
cross join unnest(metadata) as metadata
cross join unnest(metadata.request) as request
cross join unnest(metadata.response) as response
cross join unnest(response.headers) as responseHeaders
where
(path like '%storage/v1/object/%' or path like '%storage/v1/render/%')
and request.method = 'GET'
group by 1, 2, 3
order by num_requests desc
limit 100;
```
Example of the output:
```json
[
{
"filepath": "/storage/v1/object/sign/large%20bucket/20230902_200037.gif",
"http_verb": "GET",
"cached": true,
"num_requests": 100
},
{
"filepath": "/storage/v1/object/public/demob/Sports/volleyball.png",
"http_verb": "GET",
"cached": false,
"num_requests": 168
}
]
```
### Calculating egress
If you already know the size of those files, you can calculate the egress by multiplying the number of requests by the size of the file.
You can also get the size of the file with the following cURL:
```bash
curl -s -w "%{size_download}\n" -o /dev/null "https://my_project.supabase.co/storage/v1/object/large%20bucket/20230902_200037.gif"
```
This will return the size of the file in bytes.
For this example, let's say that `20230902_200037.gif` has a file size of 3 megabytes and `volleyball.png` has a file size of 570 kilobytes.
Now, we have to sum all the egress for all the files to get the total egress:
```
100 * 3MB = 300MB
168 * 570KB = 95.76MB
Total Egress = 395.76MB
```
You can see that these values can get quite large, so it's important to keep track of the egress and optimize the files.
### Optimizing egress
See our [scaling tips for egress](/docs/guides/storage/production/scaling#egress).
# Serving assets from Storage
Serving assets from Storage
## Public buckets
As mentioned in the [Buckets Fundamentals](/docs/guides/storage/buckets/fundamentals) all files uploaded in a public bucket are publicly accessible and benefit a high CDN cache HIT ratio.
You can access them by using this conventional URL:
```
https://[project_id].supabase.co/storage/v1/object/public/[bucket]/[asset-name]
```
You can also use the Supabase SDK `getPublicUrl` to generate this URL for you
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const { data } = supabase.storage.from('bucket').getPublicUrl('filePath.jpg')
console.log(data.publicUrl)
```
### Downloading
If you want the browser to start an automatic download of the asset instead of trying serving it, you can add the `?download` query string parameter.
By default it will use the asset name to save the file on disk. You can optionally pass a custom name to the `download` parameter as following: `?download=customname.jpg`
#### Programmatic downloads with query parameters
When using the SDK's `download()` method, you can pass additional query parameters to customize the download behavior:
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
// Download with custom filename
const { data, error } = await supabase.storage.from('avatars').download('avatar1.png', {
download: 'my-custom-name.png',
})
```
```dart
// Download with additional query parameters
final response = await supabase.storage
.from('avatars')
.download(
'avatar1.png',
queryParams: {
'download': 'my-custom-name.png',
},
);
```
[Reference.](/docs/reference/dart/storage-from-download)
```swift
// Download with additional query parameters
let response = try await supabase.storage
.from("avatars")
.download(
path: "avatar1.png",
queryItems: [
URLQueryItem(name: "download", value: "my-custom-name.png")
]
)
```
[Reference.](/docs/reference/swift/storage-from-download)
## Private buckets
Assets stored in a non-public bucket are considered private and are not accessible via a public URL like the public buckets.
You can access them only by:
* Signing a time limited URL on the Server, for example with Edge Functions.
* with a GET request the URL `https://[project_id].supabase.co/storage/v1/object/authenticated/[bucket]/[asset-name]` and the user Authorization header
### Signing URLs
Storage signed URLs are signed with a dedicated internal key that is separate from your project's Auth JWT signing key. Each project has its own signing key.
Because signed URLs use this separate key, they are not affected by:
* Rotating or revoking Auth JWT legacy secret or signing key
* Disabling legacy keys in the dashboard
* Switching from HS256 to asymmetric (ES256) signing key
Signed URLs remain valid until their expiry time regardless of any Auth key changes.
If you need to revoke signed URLs, [contact Supabase support](/dashboard/support/new?projectRef=).
You can sign a time-limited URL that you can share to your users by invoking the `createSignedUrl` method on the SDK.
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const { data, error } = await supabase.storage
.from('bucket')
.createSignedUrl('private-document.pdf', 3600)
if (data) {
console.log(data.signedUrl)
}
```
# Storage Image Transformations
Transform images with Storage
Supabase Storage offers the functionality to optimize and resize images on the fly. Any image stored in your buckets can be transformed and optimized for fast delivery.
Image Resizing is currently enabled for [Pro Plan and above](/pricing).
## Manage image transformations
You can enable or disable Image Transformations for your project from the [**Storage** > **Settings**](/dashboard/project/_/storage/files/settings) section of the Dashboard and toggle the **Enable Image Transformations** option.
Disabling Image Transformations prevents any image transformation requests from being processed. This can be useful to prevent unexpected usage or cost if you do not use this feature.
## Get a public URL for a transformed image
Our client libraries methods like `getPublicUrl` and `createSignedUrl` support the `transform` option. This returns the URL that serves the transformed image.
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
supabase.storage.from('bucket').getPublicUrl('image.jpg', {
transform: {
width: 500,
height: 600,
},
})
```
```dart
final url = supabase.storage.from('bucket').getPublicUrl(
'image.jpg',
transform: const TransformOptions(
width: 500,
height: 600,
),
);
```
```swift
let url = try await supabase.storage.from("bucket")
.getPublicURL(
path: "image.jpg"
options: TransformOptions(with: 500, height: 600)
)
```
```kotlin
val url = supabase.storage.from("bucket").publicRenderUrl("image.jpg") {
size(width = 500, height = 600)
}
```
```python
url = supabase.storage.from_('avatars').get_public_url(
'image.jpg',
{
'transform': {
'width': 500,
'height': 500,
},
}
)
```
An example URL could look like this:
```
https://project_id.supabase.co/storage/v1/render/image/public/bucket/image.jpg?width=500&height=600`
```
## Signing URLs with transformation options
To share a transformed image in a private bucket for a fixed amount of time, provide the transform option when you create the signed URL:
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
supabase.storage.from('bucket').createSignedUrl('image.jpg', 60000, {
transform: {
width: 200,
height: 200,
},
})
```
```dart
final url = await supabase.storage.from('bucket').createSignedUrl(
'image.jpg',
60000,
transform: const TransformOptions(
width: 200,
height: 200,
),
);
```
```swift
let url = try await supabase.storage.from("bucket")
.createSignedURL(
path: "image.jpg",
expiresIn: 60,
transform: TransformOptions(
width: 200,
height: 200
)
)
```
```kotlin
val url = supabase.storage.from("bucket").createSignedUrl("image.jpg", 60.seconds) {
size(200, 200)
}
```
The transformation options are embedded into the token attached to the URL — they cannot be changed once signed.
## Downloading images
To download a transformed image, pass the `transform` option to the `download` function.
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
supabase.storage.from('bucket').download('image.jpg', {
transform: {
width: 800,
height: 300,
},
})
```
```dart
final data = await supabase.storage.from('bucket').download(
'image.jpg',
transform: const TransformOptions(
width: 800,
height: 300,
),
);
```
```swift
let data = try await supabase.storage.from("bucket")
.download(
path: "image.jpg",
options: TransformOptions(
width: 800,
height: 300
)
)
```
```kotlin
val data = supabase.storage.from("bucket").downloadAuthenticated("image.jpg") {
transform {
size(800, 300)
}
}
//Or on JVM stream directly to a file
val file = File("image.jpg")
supabase.storage.from("bucket").downloadAuthenticatedTo("image.jpg", file) {
transform {
size(800, 300)
}
}
```
```python
response = supabase.storage.from_('bucket').download(
'image.jpg',
{
'width': 800,
'height': 300,
},
)
```
## Automatic image optimization (WebP)
When using the image transformation API, Storage will automatically find the best format supported by the client and return that to the client, without any code change. For instance, if you use Chrome when viewing a JPEG image and using transformation options, you'll see that images are automatically optimized as `webp` images.
As a result, this will lower the egress that you send to your users and your application will load much faster.
We currently only support WebP. AVIF support will come in the near future.
**Disabling automatic optimization:**
In case you'd like to return the original format of the image and **opt-out** from the automatic image optimization detection, you can pass the `format=origin` parameter when requesting a transformed image, this is also supported in the JavaScript SDK starting from v2.2.0
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
await supabase.storage.from('bucket').download('image.jpeg', {
transform: {
width: 200,
height: 200,
format: 'origin',
},
})
```
```dart
final data = await supabase.storage.from('bucket').download(
'image.jpeg',
transform: const TransformOptions(
width: 200,
height: 200,
format: RequestImageFormat.origin,
),
);
```
```swift
let data = try await supabase.storage.from("bucket")
.download(
path: "image.jpg",
options: TransformOptions(
width: 200,
height: 200,
format: "origin"
)
)
```
```kotlin
val data = supabase.storage.from("bucket").downloadAuthenticated("image.jpg") {
transform {
size(200, 200)
format = ImageTransformation.Format.ORIGIN
}
}
//Or on JVM stream directly to a file
val file = File("image.jpg")
supabase.storage.from("bucket").downloadAuthenticatedTo("image.jpg", file) {
transform {
size(200, 200)
format = ImageTransformation.Format.ORIGIN
}
}
```
```python
response = supabase.storage.from_('bucket').download(
'image.jpeg',
{
'transform': {
'width': 200,
'height': 200,
'format': 'origin',
},
}
)
```
## Next.js loader
You can use Supabase Image Transformation to optimize your Next.js images using a custom [Loader](https://nextjs.org/docs/api-reference/next/image#loader-configuration).
To get started, create a `supabase-image-loader.js` file in your Next.js project which exports a default function:
```ts
const projectId = '' // your supabase project id
export default function supabaseLoader({ src, width, quality }) {
return `https://${projectId}.supabase.co/storage/v1/render/image/public/${src}?width=${width}&quality=${quality || 75}`
}
```
In your `next.config.js` file add the following configuration to instruct Next.js to use our custom loader
```js
module.exports = {
images: {
loader: 'custom',
loaderFile: './supabase-image-loader.js',
},
}
```
At this point you are ready to use the `Image` component provided by Next.js
```tsx
import Image from 'next/image'
const MyImage = (props) => {
return
}
```
## Transformation options
We currently support a few transformation options focusing on optimizing, resizing, and cropping images.
### Optimizing
You can set the quality of the returned image by passing a value from 20 to 100 (with 100 being the highest quality) to the `quality` parameter. This parameter defaults to 80.
Example:
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
supabase.storage.from('bucket').download('image.jpg', {
transform: {
quality: 50,
},
})
```
```dart
final data = await supabase.storage.from('bucket').download(
'image.jpg',
transform: const TransformOptions(
quality: 50,
),
);
```
```swift
let data = try await supabase.storage.from("bucket")
.download(
path: "image.jpg",
options: TransformOptions(
quality: 50
)
)
```
```kotlin
val data = supabase.storage["bucket"].downloadAuthenticated("image.jpg") {
transform {
quality = 50
}
}
//Or on JVM stream directly to a file
val file = File("image.jpg")
supabase.storage["bucket"].downloadAuthenticatedTo("image.jpg", file) {
transform {
quality = 50
}
}
```
```python
response = supabase.storage.from_('bucket').download(
'image.jpg',
{
'transform': {
'quality': 50,
},
}
)
```
### Resizing
You can use `width` and `height` parameters to resize an image to a specific dimension. If only one parameter is specified, the image will be resized and cropped, maintaining the aspect ratio.
### Modes
You can use different resizing modes to fit your needs, each of them uses a different approach to resize the image:
Use the `resize` parameter with one of the following values:
* `cover` : resizes the image while keeping the aspect ratio to fill a given size and crops projecting parts. (default)
* `contain` : resizes the image while keeping the aspect ratio to fit a given size.
* `fill` : resizes the image without keeping the aspect ratio.
Example:
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
supabase.storage.from('bucket').download('image.jpg', {
transform: {
width: 800,
height: 300,
resize: 'contain', // 'cover' | 'fill'
},
})
```
```dart
final data = supabase.storage.from('bucket').download(
'image.jpg',
transform: const TransformOptions(
width: 800,
height: 300,
resize: ResizeMode.contain, // 'cover' | 'fill'
),
);
```
```swift
let data = try await supabase.storage.from("bucket")
.download(
path: "image.jpg",
options: TransformOptions(
width: 800,
height: 300,
resize: "contain" // "cover" | "fill"
)
)
```
```kotlin
val data = supabase.storage.from("bucket").downloadAuthenticated("image.jpg") {
transform {
size(800, 300)
resize = ImageTransformation.Resize.CONTAIN
}
}
//Or on JVM stream directly to a file
val file = File("image.jpg")
supabase.storage.from("bucket").downloadAuthenticatedTo("image.jpg", file) {
transform {
size(800, 300)
resize = ImageTransformation.Resize.CONTAIN
}
}
```
```python
response = supabase.storage.from_('bucket').download(
'image.jpg',
{
'transform': {
'width': 800,
'height': 300,
'resize': 'contain', # 'cover' | 'fill'
}
}
)
```
### Limits
* Width and height must be an integer value between 1-2500.
* The image size cannot exceed 25MB.
* The image resolution cannot exceed 50MP.
### Supported image formats
| Format | Extension | Source | Result |
| ------ | --------- | ------ | ------ |
| PNG | `png` | ☑️ | ☑️ |
| JPEG | `jpg` | ☑️ | ☑️ |
| WebP | `webp` | ☑️ | ☑️ |
| AVIF | `avif` | ☑️ | ☑️ |
| GIF | `gif` | ☑️ | ☑️ |
| ICO | `ico` | ☑️ | ☑️ |
| SVG | `svg` | ☑️ | ☑️ |
| HEIC | `heic` | ☑️ | ❌ |
| BMP | `bmp` | ☑️ | ☑️ |
| TIFF | `tiff` | ☑️ | ☑️ |
per 1,000 origin images. You are only charged for usage exceeding your
subscription plan's quota.
The count resets at the start of each billing cycle.
| Plan | Quota | Over-Usage |
| ---------- | ------ | ------------------------------------------- |
| Pro | 100 | per 1,000 origin images |
| Team | 100 | per 1,000 origin images |
| Enterprise | Custom | Custom |
For a detailed breakdown of how charges are calculated, refer to [Manage Storage Image Transformations usage](/docs/guides/platform/manage-your-usage/storage-image-transformations).
## Self hosting
Our solution to image resizing and optimization can be self-hosted as with any other Supabase product. Under the hood we use [imgproxy](https://imgproxy.net/)
#### imgproxy configuration:
Deploy an imgproxy container with the following configuration:
```yaml
imgproxy:
image: darthsim/imgproxy
environment:
- IMGPROXY_ENABLE_WEBP_DETECTION=true
- IMGPROXY_JPEG_PROGRESSIVE=true
```
Note: make sure that this service can only be reachable within an internal network and not exposed to the public internet
#### Storage API configuration:
Once [imgproxy](https://imgproxy.net/) is deployed we need to configure a couple of environment variables in your self-hosted [`storage-api`](https://github.com/supabase/storage-api) service as follows:
```shell
ENABLE_IMAGE_TRANSFORMATION=true
IMGPROXY_URL=yourinternalimgproxyurl.internal.com
```
{/* Finish with a video. This also appears in the Sidebar via the "tocVideo" metadata */}
# Storage Access Control
Supabase Storage is designed to work perfectly with Postgres [Row Level Security](/docs/guides/database/postgres/row-level-security) (RLS).
You can use RLS to create [Security Access Policies](https://www.postgresql.org/docs/current/sql-createpolicy.html) that are incredibly powerful and flexible, allowing you to restrict access based on your business needs.
## Access policies
By default Storage does not allow any uploads to buckets without RLS policies. You selectively allow certain operations by creating RLS policies on the `storage.objects` table.
You can find the documentation for the storage schema [here](/docs/guides/storage/schema/design) , and to simplify the process of crafting your policies, you can utilize these [helper functions](/docs/guides/storage/schema/helper-functions) .
If you need different `SELECT` policies for different Storage actions, such as listing objects versus reading authenticated objects, use the operation-aware helpers `storage.allow_only_operation()` and `storage.allow_any_operation()` documented in [Storage Helper Functions](/docs/guides/storage/schema/helper-functions).
The RLS policies required for different operations are documented [here](/docs/reference/javascript/storage-createbucket)
For example, the only RLS policy required for [uploading](/docs/reference/javascript/storage-from-upload) objects is to grant the `INSERT` permission to the `storage.objects` table.
To allow overwriting files using the `upsert` functionality you will need to additionally grant `SELECT` and `UPDATE` permissions.
## Policy examples
An easy way to get started would be to create RLS policies for `SELECT`, `INSERT`, `UPDATE`, `DELETE` operations and restrict the policies to meet your security requirements. For example, one can start with the following `INSERT` policy:
```sql
create policy "policy_name"
ON storage.objects
for insert with check (
true
);
```
and modify it to only allow authenticated users to upload assets to a specific bucket by changing it to:
```sql
create policy "policy_name"
on storage.objects for insert to authenticated with check (
-- restrict bucket
bucket_id = 'my_bucket_id'
);
```
This example demonstrates how you would allow authenticated users to upload files to a folder called `private` inside `my_bucket_id`:
```sql
create policy "Allow authenticated uploads"
on storage.objects
for insert
to authenticated
with check (
bucket_id = 'my_bucket_id' and
(storage.foldername(name))[1] = 'private'
);
```
This example demonstrates how you would allow authenticated users to upload files to a folder called with their `users.id` inside `my_bucket_id`:
```sql
create policy "Allow authenticated uploads"
on storage.objects
for insert
to authenticated
with check (
bucket_id = 'my_bucket_id' and
(storage.foldername(name))[1] = (select auth.jwt()->>'sub')
);
```
Allow a user to access a file that was previously uploaded by the same user:
```sql
create policy "Individual user Access"
on storage.objects for select
to authenticated
using ( (select auth.jwt()->>'sub') = owner_id );
```
***
{/* Finish with a video. This also appears in the Sidebar via the "tocVideo" metadata */}
## Bypassing access controls
If you exclusively use Storage from trusted clients, such as your own servers, and need to bypass the RLS policies, you can use the `service key` in the `Authorization` header. Service keys entirely bypass RLS policies, granting you unrestricted access to all Storage APIs.
Remember you should not share the service key publicly.
# Ownership
When creating new buckets or objects in Supabase Storage, an owner is automatically assigned to the bucket or object. The owner is the user who created the resource and the value is derived from the `sub` claim in the JWT.
We store the `owner` in the `owner_id` column.
When using the `service_key` to create a resource, the owner will not be set and the resource will be owned by anyone. This is also the case when you are creating Storage resources via the Dashboard.
The Storage schema has 2 fields to represent ownership: `owner` and `owner_id`. `owner` is deprecated and will be removed. Use `owner_id` instead.
## Access control
By itself, the ownership of a resource does not provide any access control. However, you can enforce the ownership by implementing access control against storage resources scoped to their owner.
For example, you can implement a policy where only the owner of an object can delete it. To do this, check the `owner_id` field of the object and compare it with the `sub` claim of the JWT:
```sql
create policy "User can delete their own objects"
on storage.objects
for delete
to authenticated
using (
owner_id = (select auth.uid()::text)
);
```
The use of RLS policies is just one way to enforce access control. You can also implement access control in your server code by following the same pattern.
# Custom Roles
Learn about using custom roles with storage schema
In this guide, you will learn how to create and use custom roles with Storage to manage role-based access to objects and buckets. The same approach can be used to use custom roles with any other Supabase service.
Supabase Storage uses the same role-based access control system as any other Supabase service using RLS (Row Level Security).
## Create a custom role
Let's create a custom role `manager` to provide full read access to a specific bucket. For a more advanced setup, see the [RBAC Guide](/docs/guides/api/custom-claims-and-role-based-access-control-rbac#create-auth-hook-to-apply-user-role).
```sql
create role 'manager';
-- Important to grant the role to the authenticator and anon role
grant manager to authenticator;
grant anon to manager;
```
## Create a policy
Let's create a policy that gives full read permissions to all objects in the bucket `teams` for the `manager` role.
```sql
create policy "Manager can view all files in the bucket 'teams'"
on storage.objects
for select
to manager
using (
bucket_id = 'teams'
);
```
## Test the policy
To impersonate the `manager` role, you will need a valid JWT token with the `manager` role.
You can quickly create one using the `jsonwebtoken` library in Node.js.
Signing a new JWT requires your `JWT_SECRET`. You must store this secret securely. Never expose it in frontend code, and do not check it into version control.
```js
const jwt = require('jsonwebtoken')
const JWT_SECRET = 'your-jwt-secret' // You can find this in your Supabase project settings under API. Store this securely.
const USER_ID = '' // the user id that we want to give the manager role
const token = jwt.sign({ role: 'manager', sub: USER_ID }, JWT_SECRET, {
expiresIn: '1h',
})
```
Now you can use this token to access the Storage API.
```js
const { StorageClient } = require('@supabase/storage-js')
const PROJECT_URL = 'https://your-project-id.supabase.co/storage/v1'
const storage = new StorageClient(PROJECT_URL, {
authorization: `Bearer ${token}`,
})
await storage.from('teams').list()
```
# The Storage Schema
Learn about the storage schema
Storage uses Postgres to store metadata regarding your buckets and objects. Users can use RLS (Row-Level Security) policies for access control. This data is stored in a dedicated schema within your project called `storage`.
When working with SQL, it's crucial to consider all records in Storage tables as read-only. All operations, including uploading, copying, moving, and deleting, should **exclusively go through the API**.
This is important because the storage schema only stores the metadata and the actual objects are stored in a provider like S3. Deleting the metadata doesn't remove the object in the underlying storage provider. This results in your object being inaccessible, but you'll still be billed for it.
Here is the schema that represents the Storage service:
 You have the option to query this table directly to retrieve information about your files in Storage without the need to go through our API.
## Modifying the schema
We strongly recommend refraining from making any alterations to the `storage` schema and treating it as read-only. This approach is important because any modifications to the schema on your end could potentially clash with our future updates, leading to downtime.
However, we encourage you to add custom indexes as they can significantly improve the performance of the RLS policies you create for enforcing access control.
# Storage Helper Functions
Learn the storage schema
Supabase Storage provides SQL helper functions which you can use to write RLS policies.
### `storage.filename()`
Returns the name of a file. For example, if your file is stored in `public/subfolder/avatar.png` it would return: `'avatar.png'`
**Usage**
This example demonstrates how you would allow any user to download a file called `favicon.ico`:
```sql
create policy "Allow public downloads"
on storage.objects
for select
to public
using (
storage.filename(name) = 'favicon.ico'
);
```
### `storage.foldername()`
Returns an array path, with all of the subfolders that a file belongs to. For example, if your file is stored in `public/subfolder/avatar.png` it would return: `[ 'public', 'subfolder' ]`
**Usage**
This example demonstrates how you would allow authenticated users to upload files to a folder called `private`:
```sql
create policy "Allow authenticated uploads"
on storage.objects
for insert
to authenticated
with check (
(storage.foldername(name))[1] = 'private'
);
```
### `storage.extension()`
Returns the extension of a file. For example, if your file is stored in `public/subfolder/avatar.png` it would return: `'png'`
**Usage**
This example demonstrates how you would allow restrict uploads to only PNG files inside a bucket called `cats`:
```sql
create policy "Only allow PNG uploads"
on storage.objects
for insert
to authenticated
with check (
bucket_id = 'cats' and storage.extension(name) = 'png'
);
```
### `storage.allow_only_operation()`
Returns `true` when the current Storage API operation exactly matches the provided operation name.
This is useful when a single SQL privilege such as `SELECT` is used by multiple Storage actions, but you want a policy to apply to only one of them, such as object listing versus object download.
The current operation names are defined in [`src/http/routes/operations.ts`](https://github.com/supabase/storage/blob/master/src/http/routes/operations.ts).
Storage normalizes operation names before comparing them, so both of the following forms are treated as equivalent:
* `storage.object.list`
* `object.list`
The comparison remains exact after normalization. Partial values such as `object` do not match `object.list`. If the current operation is not set, or the input is empty, the function returns `false`.
**Usage**
This example demonstrates how you would allow authenticated users to list only their own objects:
```sql
create policy "Allow users to list their own objects"
on storage.objects
for select
to authenticated
using (
storage.allow_only_operation('object.list')
and owner_id = (select auth.uid()::text)
);
```
### `storage.allow_any_operation()`
Returns `true` when the current Storage API operation exactly matches any operation in the provided array.
Use this when the same policy should apply to a small set of Storage actions.
**Usage**
This example demonstrates how you would allow authenticated users to list their own objects and read their own authenticated objects:
```sql
create policy "Allow users to list and read their own authenticated objects"
on storage.objects
for select
to authenticated
using (
storage.allow_any_operation(ARRAY[
'object.list',
'storage.object.get_authenticated'
])
and owner_id = (select auth.uid()::text)
);
```
# S3 Authentication
Learn about authenticating with Supabase Storage S3.
You have two options to authenticate with Supabase Storage S3:
* Using the generated S3 access keys from your [project settings](/dashboard/project/_/storage/settings) (Intended exclusively for server-side use)
* Using a Session Token, which will allow you to authenticate with a user JWT token and provide limited access via Row Level Security (RLS).
## S3 access keys
S3 access keys provide full access to all S3 operations across all buckets and bypass RLS policies. These are meant to be used only on the server.
To authenticate with S3, generate a pair of credentials (Access Key ID and Secret Access Key), copy the endpoint and region from the [S3 configuration page](/dashboard/project/_/storage/s3).
This is all the information you need to connect to Supabase Storage using any S3-compatible service.
You have the option to query this table directly to retrieve information about your files in Storage without the need to go through our API.
## Modifying the schema
We strongly recommend refraining from making any alterations to the `storage` schema and treating it as read-only. This approach is important because any modifications to the schema on your end could potentially clash with our future updates, leading to downtime.
However, we encourage you to add custom indexes as they can significantly improve the performance of the RLS policies you create for enforcing access control.
# Storage Helper Functions
Learn the storage schema
Supabase Storage provides SQL helper functions which you can use to write RLS policies.
### `storage.filename()`
Returns the name of a file. For example, if your file is stored in `public/subfolder/avatar.png` it would return: `'avatar.png'`
**Usage**
This example demonstrates how you would allow any user to download a file called `favicon.ico`:
```sql
create policy "Allow public downloads"
on storage.objects
for select
to public
using (
storage.filename(name) = 'favicon.ico'
);
```
### `storage.foldername()`
Returns an array path, with all of the subfolders that a file belongs to. For example, if your file is stored in `public/subfolder/avatar.png` it would return: `[ 'public', 'subfolder' ]`
**Usage**
This example demonstrates how you would allow authenticated users to upload files to a folder called `private`:
```sql
create policy "Allow authenticated uploads"
on storage.objects
for insert
to authenticated
with check (
(storage.foldername(name))[1] = 'private'
);
```
### `storage.extension()`
Returns the extension of a file. For example, if your file is stored in `public/subfolder/avatar.png` it would return: `'png'`
**Usage**
This example demonstrates how you would allow restrict uploads to only PNG files inside a bucket called `cats`:
```sql
create policy "Only allow PNG uploads"
on storage.objects
for insert
to authenticated
with check (
bucket_id = 'cats' and storage.extension(name) = 'png'
);
```
### `storage.allow_only_operation()`
Returns `true` when the current Storage API operation exactly matches the provided operation name.
This is useful when a single SQL privilege such as `SELECT` is used by multiple Storage actions, but you want a policy to apply to only one of them, such as object listing versus object download.
The current operation names are defined in [`src/http/routes/operations.ts`](https://github.com/supabase/storage/blob/master/src/http/routes/operations.ts).
Storage normalizes operation names before comparing them, so both of the following forms are treated as equivalent:
* `storage.object.list`
* `object.list`
The comparison remains exact after normalization. Partial values such as `object` do not match `object.list`. If the current operation is not set, or the input is empty, the function returns `false`.
**Usage**
This example demonstrates how you would allow authenticated users to list only their own objects:
```sql
create policy "Allow users to list their own objects"
on storage.objects
for select
to authenticated
using (
storage.allow_only_operation('object.list')
and owner_id = (select auth.uid()::text)
);
```
### `storage.allow_any_operation()`
Returns `true` when the current Storage API operation exactly matches any operation in the provided array.
Use this when the same policy should apply to a small set of Storage actions.
**Usage**
This example demonstrates how you would allow authenticated users to list their own objects and read their own authenticated objects:
```sql
create policy "Allow users to list and read their own authenticated objects"
on storage.objects
for select
to authenticated
using (
storage.allow_any_operation(ARRAY[
'object.list',
'storage.object.get_authenticated'
])
and owner_id = (select auth.uid()::text)
);
```
# S3 Authentication
Learn about authenticating with Supabase Storage S3.
You have two options to authenticate with Supabase Storage S3:
* Using the generated S3 access keys from your [project settings](/dashboard/project/_/storage/settings) (Intended exclusively for server-side use)
* Using a Session Token, which will allow you to authenticate with a user JWT token and provide limited access via Row Level Security (RLS).
## S3 access keys
S3 access keys provide full access to all S3 operations across all buckets and bypass RLS policies. These are meant to be used only on the server.
To authenticate with S3, generate a pair of credentials (Access Key ID and Secret Access Key), copy the endpoint and region from the [S3 configuration page](/dashboard/project/_/storage/s3).
This is all the information you need to connect to Supabase Storage using any S3-compatible service.
 For optimal performance when uploading large files you should always use the direct storage hostname. This provides several performance enhancements that will greatly improve performance when uploading large files.
Instead of `https://project-id.supabase.co` use `https://project-id.storage.supabase.co`
```js
import { S3Client } from '@aws-sdk/client-s3';
const client = new S3Client({
forcePathStyle: true,
region: 'project_region',
endpoint: 'https://project_ref.storage.supabase.co/storage/v1/s3',
credentials: {
accessKeyId: 'your_access_key_id',
secretAccessKey: 'your_secret_access_key',
}
})
```
```bash
# ~/.aws/credentials
[supabase]
aws_access_key_id = your_access_key_id
aws_secret_access_key = your_secret_access_key
endpoint_url = https://project_ref.storage.supabase.co/storage/v1/s3
region = project_region
```
On [local development](/docs/guides/local-development), use these values:
* `region`: `local`
* `endpoint`: IP and port e.g. `http://127.0.0.1:54321/storage/v1/s3`
## Session token
You can authenticate to Supabase S3 with a user JWT token to provide limited access via RLS to all S3 operations. This is useful when you want initialize the S3 client on the server scoped to a specific user, or use the S3 client directly from the client side.
All S3 operations performed with the Session Token are scoped to the authenticated user. RLS policies on the Storage Schema are respected.
To authenticate with S3 using a Session Token, use the following credentials:
* access\_key\_id: `project_ref`
* secret\_access\_key: `anonKey` (`publishableKey` is [not yet supported](https://github.com/supabase/storage/issues/750))
* session\_token: `valid jwt token`
For example, using the `aws-sdk` library:
Typically we advise against using `getSession`, because the session is read from local storage and you can't trust its claims for auth decisions. In this case however, the code only needs the raw access token string to forward as a credential to the S3 service, which validates the token server-side. Since no client-side auth decision is made based on the session data, `getSession` is appropriate here.
```javascript
import { S3Client } from '@aws-sdk/client-s3'
const {
data: { session },
} = await supabase.auth.getSession()
const client = new S3Client({
forcePathStyle: true,
region: 'project_region',
endpoint: 'https://project_ref.storage.supabase.co/storage/v1/s3',
credentials: {
accessKeyId: 'project_ref',
secretAccessKey: 'anonKey',
sessionToken: session.access_token,
},
})
```
* On self-hosted Supabase, the `accessKeyId` is the `STORAGE_TENANT_ID` environment variable defined in the `.env` file. Refer to the [self-hosted S3 guide](/docs/guides/self-hosting/self-hosted-s3#session-token) for more details.
* On [local development](/docs/guides/local-development), use the following values:
* `region`: `local`
* `endpoint`: IP and port e.g. `http://127.0.0.1:54321/storage/v1/s3`
* `accessKeyId`: `stub`
* `secretAccessKey`: use `ANON_KEY` value from `supabase status -o env`
# S3 Compatibility
Learn about the compatibility of Supabase Storage with S3.
Supabase Storage is compatible with the S3 protocol. You can use almost any S3 client to interact with your Storage objects (such as [Cyberduck](/partners/integrations/cyberduck)).
Storage supports [standard](/docs/guides/storage/uploads/standard-uploads), [resumable](/docs/guides/storage/uploads/resumable-uploads) and [S3 uploads](/docs/guides/storage/uploads/s3-uploads) and all these protocols are interoperable. You can upload a file with the S3 protocol and list it with the REST API or upload with Resumable uploads and list with S3.
Storage supports presigning a URL using query parameters. Specifically, Supabase Storage expects requests to be made using [AWS Signature Version 4](https://docs.aws.amazon.com/AmazonS3/latest/API/sigv4-query-string-auth.html). To enable this feature, enable the S3 connection via S3 protocol in the Settings page for Supabase Storage.
**S3 versioning is not supported.** Supabase Storage does not enable S3's versioning capabilities for buckets. Deleted objects are permanently removed and cannot be restored.
## Implemented endpoints
The most commonly used endpoints are implemented, and more will be added. Implemented S3 endpoints are marked with ✅ in the following tables.
### Bucket operations
{/* supa-mdx-lint-disable Rule003Spelling */}
| API Name | Feature |
| ----------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| ✅ [ListBuckets](https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListBuckets.html) | |
| ✅ [HeadBucket](https://docs.aws.amazon.com/AmazonS3/latest/API/API_HeadBucket.html) | ❌ Bucket Owner:
For optimal performance when uploading large files you should always use the direct storage hostname. This provides several performance enhancements that will greatly improve performance when uploading large files.
Instead of `https://project-id.supabase.co` use `https://project-id.storage.supabase.co`
```js
import { S3Client } from '@aws-sdk/client-s3';
const client = new S3Client({
forcePathStyle: true,
region: 'project_region',
endpoint: 'https://project_ref.storage.supabase.co/storage/v1/s3',
credentials: {
accessKeyId: 'your_access_key_id',
secretAccessKey: 'your_secret_access_key',
}
})
```
```bash
# ~/.aws/credentials
[supabase]
aws_access_key_id = your_access_key_id
aws_secret_access_key = your_secret_access_key
endpoint_url = https://project_ref.storage.supabase.co/storage/v1/s3
region = project_region
```
On [local development](/docs/guides/local-development), use these values:
* `region`: `local`
* `endpoint`: IP and port e.g. `http://127.0.0.1:54321/storage/v1/s3`
## Session token
You can authenticate to Supabase S3 with a user JWT token to provide limited access via RLS to all S3 operations. This is useful when you want initialize the S3 client on the server scoped to a specific user, or use the S3 client directly from the client side.
All S3 operations performed with the Session Token are scoped to the authenticated user. RLS policies on the Storage Schema are respected.
To authenticate with S3 using a Session Token, use the following credentials:
* access\_key\_id: `project_ref`
* secret\_access\_key: `anonKey` (`publishableKey` is [not yet supported](https://github.com/supabase/storage/issues/750))
* session\_token: `valid jwt token`
For example, using the `aws-sdk` library:
Typically we advise against using `getSession`, because the session is read from local storage and you can't trust its claims for auth decisions. In this case however, the code only needs the raw access token string to forward as a credential to the S3 service, which validates the token server-side. Since no client-side auth decision is made based on the session data, `getSession` is appropriate here.
```javascript
import { S3Client } from '@aws-sdk/client-s3'
const {
data: { session },
} = await supabase.auth.getSession()
const client = new S3Client({
forcePathStyle: true,
region: 'project_region',
endpoint: 'https://project_ref.storage.supabase.co/storage/v1/s3',
credentials: {
accessKeyId: 'project_ref',
secretAccessKey: 'anonKey',
sessionToken: session.access_token,
},
})
```
* On self-hosted Supabase, the `accessKeyId` is the `STORAGE_TENANT_ID` environment variable defined in the `.env` file. Refer to the [self-hosted S3 guide](/docs/guides/self-hosting/self-hosted-s3#session-token) for more details.
* On [local development](/docs/guides/local-development), use the following values:
* `region`: `local`
* `endpoint`: IP and port e.g. `http://127.0.0.1:54321/storage/v1/s3`
* `accessKeyId`: `stub`
* `secretAccessKey`: use `ANON_KEY` value from `supabase status -o env`
# S3 Compatibility
Learn about the compatibility of Supabase Storage with S3.
Supabase Storage is compatible with the S3 protocol. You can use almost any S3 client to interact with your Storage objects (such as [Cyberduck](/partners/integrations/cyberduck)).
Storage supports [standard](/docs/guides/storage/uploads/standard-uploads), [resumable](/docs/guides/storage/uploads/resumable-uploads) and [S3 uploads](/docs/guides/storage/uploads/s3-uploads) and all these protocols are interoperable. You can upload a file with the S3 protocol and list it with the REST API or upload with Resumable uploads and list with S3.
Storage supports presigning a URL using query parameters. Specifically, Supabase Storage expects requests to be made using [AWS Signature Version 4](https://docs.aws.amazon.com/AmazonS3/latest/API/sigv4-query-string-auth.html). To enable this feature, enable the S3 connection via S3 protocol in the Settings page for Supabase Storage.
**S3 versioning is not supported.** Supabase Storage does not enable S3's versioning capabilities for buckets. Deleted objects are permanently removed and cannot be restored.
## Implemented endpoints
The most commonly used endpoints are implemented, and more will be added. Implemented S3 endpoints are marked with ✅ in the following tables.
### Bucket operations
{/* supa-mdx-lint-disable Rule003Spelling */}
| API Name | Feature |
| ----------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| ✅ [ListBuckets](https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListBuckets.html) | |
| ✅ [HeadBucket](https://docs.aws.amazon.com/AmazonS3/latest/API/API_HeadBucket.html) | ❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [CreateBucket](https://docs.aws.amazon.com/AmazonS3/latest/API/API_CreateBucket.html) | ❌ ACL:
❌ x-amz-acl
❌ x-amz-grant-full-control
❌ x-amz-grant-read
❌ x-amz-grant-read-acp
❌ x-amz-grant-write
❌ x-amz-grant-write-acp
❌ Object Locking:
❌ x-amz-bucket-object-lock-enabled
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [DeleteBucket](https://docs.aws.amazon.com/AmazonS3/latest/API/API_DeleteBucket.html) | ❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [GetBucketLocation](https://docs.aws.amazon.com/AmazonS3/latest/API/API_GetBucketLocation.html) | ❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ❌ [DeleteBucketCors](https://docs.aws.amazon.com/AmazonS3/latest/API/API_DeleteBucketCors.html) | ❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ❌ [GetBucketEncryption](https://docs.aws.amazon.com/AmazonS3/latest/API/API_GetBucketEncryption.html) | ❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ❌ [GetBucketLifecycleConfiguration](https://docs.aws.amazon.com/AmazonS3/latest/API/API_GetBucketLifecycleConfiguration.html) | ❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ❌ [GetBucketCors](https://docs.aws.amazon.com/AmazonS3/latest/API/API_GetBucketCors.html) | ❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ❌ [PutBucketCors](https://docs.aws.amazon.com/AmazonS3/latest/API/API_PutBucketCors.html) | ❌ Checksums:
❌ x-amz-sdk-checksum-algorithm
❌ x-amz-checksum-algorithm
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ❌ [PutBucketLifecycleConfiguration](https://docs.aws.amazon.com/AmazonS3/latest/API/API_PutBucketLifecycleConfiguration.html) | ❌ Checksums:
❌ x-amz-sdk-checksum-algorithm
❌ x-amz-checksum-algorithm
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
{/* supa-mdx-lint-enable Rule003Spelling */}
### Object operations
{/* supa-mdx-lint-disable Rule003Spelling */}
| API Name | Feature |
| ------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| ✅ [HeadObject](https://docs.aws.amazon.com/AmazonS3/latest/API/API_HeadObject.html) | ✅ Conditional Operations:
✅ If-Match
✅ If-Modified-Since
✅ If-None-Match
✅ If-Unmodified-Since
✅ Range:
✅ Range (has no effect in HeadObject)
✅ partNumber
❌ SSE-C:
❌ x-amz-server-side-encryption-customer-algorithm
❌ x-amz-server-side-encryption-customer-key
❌ x-amz-server-side-encryption-customer-key-MD5
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [ListObjects](https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListObjects.html) | Query Parameters:
✅ delimiter
✅ encoding-type
✅ marker
✅ max-keys
✅ prefix
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [ListObjectsV2](https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListObjectsV2.html) | Query Parameters:
✅ list-type
✅ continuation-token
✅ delimiter
✅ encoding-type
✅ fetch-owner
✅ max-keys
✅ prefix
✅ start-after
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [GetObject](https://docs.aws.amazon.com/AmazonS3/latest/API/API_GetObject.html) | ✅ Conditional Operations:
✅ If-Match
✅ If-Modified-Since
✅ If-None-Match
✅ If-Unmodified-Since
✅ Range:
✅ Range
✅ PartNumber
❌ SSE-C:
❌ x-amz-server-side-encryption-customer-algorithm
❌ x-amz-server-side-encryption-customer-key
❌ x-amz-server-side-encryption-customer-key-MD5
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [PutObject](https://docs.aws.amazon.com/AmazonS3/latest/API/API_PutObject.html) | System Metadata:
✅ Content-Type
✅ Cache-Control
✅ Content-Disposition
✅ Content-Encoding
✅ Content-Language
✅ Expires
❌ Content-MD5
❌ Object Lifecycle
❌ Website:
❌ x-amz-website-redirect-location
❌ SSE-C:
❌ x-amz-server-side-encryption
❌ x-amz-server-side-encryption-customer-algorithm
❌ x-amz-server-side-encryption-customer-key
❌ x-amz-server-side-encryption-customer-key-MD5
❌ x-amz-server-side-encryption-aws-kms-key-id
❌ x-amz-server-side-encryption-context
❌ x-amz-server-side-encryption-bucket-key-enabled
❌ Request Payer:
❌ x-amz-request-payer
❌ Tagging:
❌ x-amz-tagging
❌ Object Locking:
❌ x-amz-object-lock-mode
❌ x-amz-object-lock-retain-until-date
❌ x-amz-object-lock-legal-hold
❌ ACL:
❌ x-amz-acl
❌ x-amz-grant-full-control
❌ x-amz-grant-read
❌ x-amz-grant-read-acp
❌ x-amz-grant-write-acp
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [DeleteObject](https://docs.aws.amazon.com/AmazonS3/latest/API/API_DeleteObject.html) | ❌ Multi-factor authentication:
❌ x-amz-mfa
❌ Object Locking:
❌ x-amz-bypass-governance-retention
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [DeleteObjects](https://docs.aws.amazon.com/AmazonS3/latest/API/API_DeleteObjects.html) | ❌ Multi-factor authentication:
❌ x-amz-mfa
❌ Object Locking:
❌ x-amz-bypass-governance-retention
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [ListMultipartUploads](https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListMultipartUploads.html) | ✅ Query Parameters:
✅ delimiter
✅ encoding-type
✅ key-marker
✅️ max-uploads
✅ prefix
✅ upload-id-marker |
| ✅ [CreateMultipartUpload](https://docs.aws.amazon.com/AmazonS3/latest/API/API_CreateMultipartUpload.html) | ✅ System Metadata:
✅ Content-Type
✅ Cache-Control
✅ Content-Disposition
✅ Content-Encoding
✅ Content-Language
✅ Expires
❌ Content-MD5
❌ Website:
❌ x-amz-website-redirect-location
❌ SSE-C:
❌ x-amz-server-side-encryption
❌ x-amz-server-side-encryption-customer-algorithm
❌ x-amz-server-side-encryption-customer-key
❌ x-amz-server-side-encryption-customer-key-MD5
❌ x-amz-server-side-encryption-aws-kms-key-id
❌ x-amz-server-side-encryption-context
❌ x-amz-server-side-encryption-bucket-key-enabled
❌ Request Payer:
❌ x-amz-request-payer
❌ Tagging:
❌ x-amz-tagging
❌ Object Locking:
❌ x-amz-object-lock-mode
❌ x-amz-object-lock-retain-until-date
❌ x-amz-object-lock-legal-hold
❌ ACL:
❌ x-amz-acl
❌ x-amz-grant-full-control
❌ x-amz-grant-read
❌ x-amz-grant-read-acp
❌ x-amz-grant-write-acp
❌ Storage class:
❌ x-amz-storage-class
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [CompleteMultipartUpload](https://docs.aws.amazon.com/AmazonS3/latest/API/API_CompleteMultipartUpload.html) | ❌ Bucket Owner:
❌ x-amz-expected-bucket-owner
❌ Request Payer:
❌ x-amz-request-payer |
| ✅ [AbortMultipartUpload](https://docs.aws.amazon.com/AmazonS3/latest/API/API_AbortMultipartUpload.html) | ❌ Request Payer:
❌ x-amz-request-payer |
| ✅ [CopyObject](https://docs.aws.amazon.com/AmazonS3/latest/API/API_CopyObject.html) | ✅ Operation Metadata:
⚠️ x-amz-metadata-directive
✅ System Metadata:
✅ Content-Type
✅ Cache-Control
✅ Content-Disposition
✅ Content-Encoding
✅ Content-Language
✅ Expires
✅ Conditional Operations:
✅ x-amz-copy-source
✅ x-amz-copy-source-if-match
✅ x-amz-copy-source-if-modified-since
✅ x-amz-copy-source-if-none-match
✅ x-amz-copy-source-if-unmodified-since
❌ ACL:
❌ x-amz-acl
❌ x-amz-grant-full-control
❌ x-amz-grant-read
❌ x-amz-grant-read-acp
❌ x-amz-grant-write-acp
❌ Website:
❌ x-amz-website-redirect-location
❌ SSE-C:
❌ x-amz-server-side-encryption
❌ x-amz-server-side-encryption-customer-algorithm
❌ x-amz-server-side-encryption-customer-key
❌ x-amz-server-side-encryption-customer-key-MD5
❌ x-amz-server-side-encryption-aws-kms-key-id
❌ x-amz-server-side-encryption-context
❌ x-amz-server-side-encryption-bucket-key-enabled
❌ x-amz-copy-source-server-side-encryption-customer-algorithm
❌ x-amz-copy-source-server-side-encryption-customer-key
❌ x-amz-copy-source-server-side-encryption-customer-key-MD5
❌ Request Payer:
❌ x-amz-request-payer
❌ Tagging:
❌ x-amz-tagging
❌ x-amz-tagging-directive
❌ Object Locking:
❌ x-amz-object-lock-mode
❌ x-amz-object-lock-retain-until-date
❌ x-amz-object-lock-legal-hold
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner
❌ x-amz-source-expected-bucket-owner
❌ Checksums:
❌ x-amz-checksum-algorithm |
| ✅ [UploadPart](https://docs.aws.amazon.com/AmazonS3/latest/API/API_UploadPart.html) | ✅ System Metadata:
❌ Content-MD5
❌ SSE-C:
❌ x-amz-server-side-encryption
❌ x-amz-server-side-encryption-customer-algorithm
❌ x-amz-server-side-encryption-customer-key
❌ x-amz-server-side-encryption-customer-key-MD5
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
| ✅ [UploadPartCopy](https://docs.aws.amazon.com/AmazonS3/latest/API/API_UploadPartCopy.html) | ❌ Conditional Operations:
❌ x-amz-copy-source
❌ x-amz-copy-source-if-match
❌ x-amz-copy-source-if-modified-since
❌ x-amz-copy-source-if-none-match
❌ x-amz-copy-source-if-unmodified-since
✅ Range:
✅ x-amz-copy-source-range
❌ SSE-C:
❌ x-amz-server-side-encryption-customer-algorithm
❌ x-amz-server-side-encryption-customer-key
❌ x-amz-server-side-encryption-customer-key-MD5
❌ x-amz-copy-source-server-side-encryption-customer-algorithm
❌ x-amz-copy-source-server-side-encryption-customer-key
❌ x-amz-copy-source-server-side-encryption-customer-key-MD5
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner
❌ x-amz-source-expected-bucket-owner |
| ✅ [ListParts](https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListParts.html) | Query Parameters:
✅ max-parts
✅ part-number-marker
❌ Request Payer:
❌ x-amz-request-payer
❌ Bucket Owner:
❌ x-amz-expected-bucket-owner |
{/* supa-mdx-lint-enable Rule003Spelling */}
# Storage Optimizations
Scaling Storage
Here are some optimizations that you can consider to improve performance and reduce costs as you start scaling Storage.
## Egress
If your project has high egress, these optimizations can help reducing it.
#### Resize images
Images typically make up most of your egress. By keeping them as small as possible, you can cut down on egress and boost your application's performance. You can take advantage of our [Image Transformation](/docs/guides/storage/serving/image-transformations) service to optimize any image on the fly.
#### Set a high cache-control value
Using the browser cache can effectively lower your egress since the asset remains stored in the user's browser after the initial download. Setting a high `cache-control` value ensures the asset stays in the user's browser for an extended period, decreasing the need to download it from the server repeatedly. Read more [here](/docs/guides/storage/cdn/smart-cdn#cache-duration)
#### Limit the upload size
You have the option to set a maximum upload size for your bucket. Doing this can prevent users from uploading and then downloading excessively large files. You can control the maximum file size by configuring this option at the [bucket level](/docs/guides/storage/buckets/creating-buckets).
#### Smart CDN
By leveraging our [Smart CDN](/docs/guides/storage/cdn/smart-cdn), you can achieve a higher cache hit rate and therefore lower your egress cached, as we charge less for cached egress (see [egress pricing](/docs/guides/platform/manage-your-usage/egress#pricing)).
## Optimize listing objects
Once you have a substantial number of objects, you might observe that the `supabase.storage.list()` method starts to slow down. This occurs because the endpoint is quite generic and attempts to retrieve both folders and objects in a single query. While this approach is very useful for building features like the Storage viewer on the Supabase dashboard, it can impact performance with a large number of objects.
If your application doesn't need the entire hierarchy computed you can speed up drastically the query execution for listing your objects by creating a Postgres function as following:
```sql
create or replace function list_objects(
bucketid text,
prefix text,
limits int default 100,
offsets int default 0
) returns table (
name text,
id uuid,
updated_at timestamptz,
created_at timestamptz,
last_accessed_at timestamptz,
metadata jsonb
) as $$
begin
return query SELECT
objects.name,
objects.id,
objects.updated_at,
objects.created_at,
objects.last_accessed_at,
objects.metadata
FROM storage.objects
WHERE objects.name like prefix || '%'
AND bucket_id = bucketid
ORDER BY name ASC
LIMIT limits
OFFSET offsets;
end;
$$ language plpgsql stable;
```
You can then use the your Postgres function as following:
Using SQL:
```sql
select * from list_objects('bucket_id', '', 100, 0);
```
Using the SDK:
```js
const { data, error } = await supabase.rpc('list_objects', {
bucketid: 'yourbucket',
prefix: '',
limit: 100,
offset: 0,
})
```
## Optimizing RLS
When creating RLS policies against the storage tables you can add indexes to the interested columns to speed up the lookup
# Copy Objects
Learn how to copy and move objects
## Copy objects
You can copy objects between buckets or within the same bucket. Currently only objects up to 5 GB can be copied using the API.
When making a copy of an object, the owner of the new object will be the user who initiated the copy operation.
### Copying objects within the same bucket
To copy an object within the same bucket, use the `copy` method.
```javascript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
await supabase.storage.from('avatars').copy('public/avatar1.png', 'private/avatar2.png')
```
### Copying objects across buckets
To copy an object across buckets, use the `copy` method and specify the destination bucket.
```javascript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
await supabase.storage.from('avatars').copy('public/avatar1.png', 'private/avatar2.png', {
destinationBucket: 'avatars2',
})
```
## Move objects
You can move objects between buckets or within the same bucket. Currently only objects up to 5GB can be moved using the API.
When moving an object, the owner of the new object will be the user who initiated the move operation. Once the object is moved, the original object will no longer exist.
### Moving objects within the same bucket
To move an object within the same bucket, you can use the `move` method.
```javascript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const { data, error } = await supabase.storage
.from('avatars')
.move('public/avatar1.png', 'private/avatar2.png')
```
### Moving objects across buckets
To move an object across buckets, use the `move` method and specify the destination bucket.
```javascript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
await supabase.storage.from('avatars').move('public/avatar1.png', 'private/avatar2.png', {
destinationBucket: 'avatars2',
})
```
## Permissions
To **copy** objects, users need `select` permission on the source object and `insert` permission on the destination object. If the user also has `update` permission, the copy can be performed as an upsert, which will overwrite the destination object if it already exists.
To **move** objects, users need `select` and `update` permissions on the object.
For example:
```sql
create policy "User can select their own objects (in any buckets)"
on storage.objects
for select
to authenticated
using (
owner_id = (select auth.uid())
);
create policy "User can insert in their own folders (in any buckets)"
on storage.objects
for insert
to authenticated
with check (
(storage.folder(name))[1] = (select auth.uid())
);
create policy "User can update their own objects (in any buckets)"
on storage.objects
for update
to authenticated
using (
owner_id = (select auth.uid())
);
```
# Delete Objects
Learn about deleting objects
When you delete one or more objects from a bucket, the files are permanently removed and not recoverable. You can delete a single object or multiple objects at once.
Deleting objects should always be done via the **Storage API** and NOT via a **SQL query**. Deleting objects via a SQL query will not remove the object from the bucket and will result in the object being orphaned.
## Delete objects
To delete one or more objects, use the `remove` method.
```javascript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
await supabase.storage.from('bucket').remove(['object-path-2', 'folder/avatar2.png'])
```
When deleting objects, there is a limit of 1000 objects at a time using the `remove` method.
## RLS
To delete an object, the user must have the `delete` permission on the object. For example:
```sql
create policy "User can delete their own objects"
on storage.objects
for delete
TO authenticated
USING (
owner = (select auth.uid()::text)
);
```
# Download Objects
Learn about downloading objects
You can download Supabase Storage files can in a variety of ways depending on your use case.
## From the Dashboard
You can download individual files directly from the [**Storage > Files**](/dashboard/project/_/storage/buckets) section of the Dashboard by browsing to your bucket and selecting files.
## Using the Supabase CLI
You can use the `supabase storage` commands to list and copy objects from your linked project.
See the [CLI reference](/docs/reference/cli/supabase-storage) for available commands.
## Using an S3-compatible client
Supabase Storage exposes an S3-compatible endpoint, which means you can use tools like [Cyberduck](https://cyberduck.io/) (via a connection profile), AWS CLI, or rclone to browse and download your files.
To connect:
1. Go to [**Storage > Configuration > S3**](/dashboard/project/_/storage/s3) section of the Dashboard.
2. Enable the S3 protocol and generate an access key + secret key pair (Save it immediately as it is shown once).
3. Use your S3-compatible tool with the endpoint and credentials from the Dashboard.
See the [S3 authentication doc](/docs/guides/storage/s3/authentication) for full connection details.
For downloading a large number of objects, using an S3-compatible tool like rclone or Cyberduck is significantly more efficient than downloading files individually.
## Using migration scripts
For bulk downloads or project migrations, you can use the scripts from our migration docs:
* **Node.js script** — see "Migrating storage objects" in the [migration guide](/docs/guides/platform/migrating-within-supabase/backup-restore)
* **Google Colab script** — see "Migrate storage objects to new project's S3 storage" in the [dashboard restore guide](/docs/guides/platform/migrating-within-supabase/dashboard-restore)
## File metadata
File metadata is stored separately from the actual files. It lives in the `storage.buckets` and `storage.objects` tables in your Postgres database. If you need a complete backup (files + metadata), see the [backup and restore guide](/docs/guides/platform/migrating-within-supabase/backup-restore).
# Error Codes
Learn about the Storage error codes and how to resolve them
## Handling Storage errors in SDKs
When using the Supabase SDKs, storage errors provide detailed information to help you debug issues:
```js
try {
const { data, error } = await supabase.storage.from('avatars').download('avatar.png')
if (error) {
// Access error details
console.log('Error code:', error.error)
console.log('Error message:', error.message)
console.log('HTTP status:', error.status)
console.log('Status code:', error.statusCode)
}
} catch (err) {
console.error('Unexpected error:', err)
}
```
```python
try:
response = supabase.storage.from_('avatars').download('avatar.png')
except Exception as error:
# Access error details
print(f'Error: {error}')
# The SDK now handles bad responses from the server gracefully
```
## Storage error codes
We are transitioning to a new error code system. For backwards compatibility you'll still be able to see the old error codes
Error codes in Storage are returned as part of the response body. They are useful for debugging and understanding what went wrong with your request.
The error codes are returned in the following format:
```json
{
"code": "error_code",
"message": "error_message"
}
```
Here is the full list of error codes and their descriptions:
| `ErrorCode` | Description | `StatusCode` | Resolution |
| --------------------------- | --------------------------------------------------------------- | ------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `NoSuchBucket` | The specified bucket does not exist. | 404 | Verify the bucket name and ensure it exists in the system, if it exists you don't have permissions to access it. |
| `NoSuchKey` | The specified key does not exist. | 404 | Check the key name and ensure it exists in the specified bucket, if it exists you don't have permissions to access it. |
| `NoSuchUpload` | The specified upload does not exist. | 404 | The upload ID provided might not exists or the Upload was previously aborted |
| `InvalidJWT` | The provided JWT (JSON Web Token) is invalid. | 401 | The JWT provided might be expired or malformed, provide a valid JWT |
| `InvalidRequest` | The request is not properly formed. | 400 | Review the request parameters and structure, ensure they meet the API's requirements, the error message will provide more details |
| `TenantNotFound` | The specified tenant does not exist. | 404 | The Storage service had issues while provisioning, [Contact Support](/dashboard/support/new) |
| `EntityTooLarge` | The entity being uploaded is too large. | 413 | Verify the max-file-limit is equal or higher to the resource you are trying to upload, you can change this value on the [Project Settings](/dashboard/project/_/storage/settings) |
| `InternalError` | An internal server error occurred. | 500 | Investigate server logs to identify the cause of the internal error. If you think it's a Storage error [Contact Support](/dashboard/support/new) |
| `ResourceAlreadyExists` | The specified resource already exists. | 409 | Use a different name or identifier for the resource to avoid conflicts. Use `x-upsert:true` header to overwrite the resource. |
| `InvalidBucketName` | The specified bucket name is invalid. | 400 | Ensure the bucket name follows the naming conventions and does not contain invalid characters. |
| `InvalidKey` | The specified key is invalid. | 400 | Verify the key name and ensure it follows the naming conventions. |
| `InvalidRange` | The specified range is not valid. | 416 | Make sure that range provided is within the file size boundary and follow the [HTTP Range spec](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Range) |
| `InvalidMimeType` | The specified MIME type is not valid. | 400 | Provide a valid MIME type, ensure using the standard MIME type format |
| `InvalidUploadId` | The specified upload ID is invalid. | 400 | The upload ID provided is invalid or missing. Make sure to provide a active upload ID |
| `KeyAlreadyExists` | The specified key already exists. | 409 | Use a different key name to avoid conflicts with existing keys. Use `x-upsert:true` header to overwrite the resource. |
| `BucketAlreadyExists` | The specified bucket already exists. | 409 | Choose a unique name for the bucket that does not conflict with existing buckets. |
| `DatabaseTimeout` | Timeout occurred while accessing the database. | 504 | Investigate database performance and increase the default pool size. If this error still occurs, upgrade your instance |
| `InvalidSignature` | The signature provided does not match the calculated signature. | 403 | Check that you are providing the correct signature format, for more information refer to [SignatureV4](https://docs.aws.amazon.com/AmazonS3/latest/API/sig-v4-authenticating-requests.html) |
| `SignatureDoesNotMatch` | The request signature does not match the calculated signature. | 403 | Check your credentials, access key id / access secret key / region that are all correct, refer to [S3 Authentication](/docs/guides/storage/s3/authentication). |
| `AccessDenied` | Access to the specified resource is denied. | 403 | Check that you have the correct RLS policy to allow access to this resource |
| `ResourceLocked` | The specified resource is locked. | 423 | This resource cannot be altered while there is a lock. Wait and try the request again |
| `DatabaseError` | An error occurred while accessing the database. | 500 | Investigate database logs and system configuration to identify and address the database error. |
| `MissingContentLength` | The Content-Length header is missing. | 411 | Ensure the Content-Length header is included in the request with the correct value. |
| `MissingParameter` | A required parameter is missing in the request. | 400 | Provide all required parameters in the request to fulfill the API's requirements. The message field will contain more details |
| `InvalidUploadSignature` | The provided upload signature is invalid. | 403 | The `MultiPartUpload` record was altered while the upload was ongoing, the signature do not match. Do not alter the upload record |
| `LockTimeout` | Timeout occurred while waiting for a lock. | 423 | The lock couldn't be acquired within the specified timeout. Wait and try the request again |
| `S3Error` | An error occurred related to Amazon S3. | - | Refer to Amazon S3 documentation or [Contact Support](/dashboard/support/new) for assistance with resolving the S3 error. |
| `S3InvalidAccessKeyId` | The provided AWS access key ID is invalid. | 403 | Verify the AWS access key ID provided and ensure it is correct and active. |
| `S3MaximumCredentialsLimit` | The maximum number of credentials has been reached. | 400 | The maximum limit of credentials is reached. |
| `InvalidChecksum` | The checksum of the entity does not match. | 400 | Recalculate the checksum of the entity and ensure it matches the one provided in the request. |
| `MissingPart` | A part of the entity is missing. | 400 | Ensure all parts of the entity are included in the request before completing the operation. |
| `SlowDown` | The request rate is too high and has been throttled. | 503 | Reduce the request rate or implement exponential backoff and retry mechanisms to handle throttling. |
## Legacy error codes
As we are transitioning to a new error code system, you might still see the following error format:
```json
{
"httpStatusCode": 400,
"code": "error_code",
"message": "error_message"
}
```
Here's a list of the most common error codes and their potential resolutions:
### 404 `not_found`
Indicates that the resource is not found or you don't have the correct permission to access it
**Resolution:**
* Add an RLS policy to grant permission to the resource. See our [Access Control docs](/docs/guides/storage/security/access-control) for more information.
* Ensure you include the user `Authorization` header
* Verify the object exists
### 409 `already_exists`
Indicates that the resource already exists.
**Resolution:**
* Use the `upsert` functionality in order to overwrite the file. Find out more [here](/docs/guides/storage/uploads/standard-uploads#overwriting-files).
### 403 `unauthorized`
You don't have permission to action this request
**Resolution:**
* Add RLS policy to grant permission. See our [Access Control docs](/docs/guides/storage/security/access-control) for more information.
* Ensure you include the user `Authorization` header
### 429 `too many requests`
This problem typically arises when a large number of clients are concurrently interacting with the Storage service, and the pooler has reached its `max_clients` limit.
**Resolution:**
* Increase the max\_clients limits of the pooler.
* Upgrade to a bigger project compute instance [here](/dashboard/project/_/settings/addons).
### 544 `database_timeout`
This problem arises when a high number of clients are concurrently using the Storage service, and Postgres doesn't have enough available connections to efficiently handle requests to Storage.
**Resolution:**
* Increase the pool\_size limits of the pooler.
* Upgrade to a bigger project compute instance [here](/dashboard/project/_/settings/addons).
### 500 `internal_server_error`
This issue occurs where there is a unhandled error.
**Resolution:**
* File a support ticket to Storage team [here](/dashboard/support/new)
# Logs
The [Storage Logs](/dashboard/project/_/logs/storage-logs) provide a convenient way to examine all incoming request logs to your Storage service. You can filter by time and keyword searches.
For more advanced filtering needs, use the [Logs Explorer](/dashboard/project/_/logs/explorer) to query the Storage logs dataset directly. The Logs Explorer is separate from the SQL Editor and uses a subset of the BigQuery SQL syntax rather than traditional SQL.
For more details on filtering the log tables, see [Advanced Log Filtering](/docs/guides/telemetry/advanced-log-filtering)
### Example Storage queries for the Logs Explorer
#### Filter by status 5XX error
```sql
select
id,
storage_logs.timestamp,
event_message,
r.statusCode,
e.message as errorMessage,
e.raw as rawError
from
storage_logs
cross join unnest(metadata) as m
cross join unnest(m.res) as r
cross join unnest(m.error) as e
where r.statusCode >= 500
order by timestamp desc
limit 100;
```
#### Filter by status 4XX error
```sql
select
id,
storage_logs.timestamp,
event_message,
r.statusCode,
e.message as errorMessage,
e.raw as rawError
from
storage_logs
cross join unnest(metadata) as m
cross join unnest(m.res) as r
cross join unnest(m.error) as e
where r.statusCode >= 400 and r.statusCode < 500
order by timestamp desc
limit 100;
```
#### Filter by method
```sql
select id, storage_logs.timestamp, event_message, r.method
from
storage_logs
cross join unnest(metadata) as m
cross join unnest(m.req) as r
where r.method in ("POST")
order by timestamp desc
limit 100;
```
#### Filter by IP address
```sql
select id, storage_logs.timestamp, event_message, r.remoteAddress
from
storage_logs
cross join unnest(metadata) as m
cross join unnest(m.req) as r
where r.remoteAddress in ("IP_ADDRESS")
order by timestamp desc
limit 100;
```
# Storage CDN
All assets uploaded to Supabase Storage are cached on a Content Delivery Network (CDN) to improve the latency for users all around the world. CDNs are a geographically distributed set of servers or **nodes** which cache content from an **origin server**. For Supabase Storage, the origin is the storage server running in the [same region as your project](/dashboard/project/_/settings/general). Aside from performance, CDNs also help with security and availability by mitigating Distributed Denial of Service (DDoS) and other application attacks.
### Example
Let's walk through an example of how a CDN helps with performance.
A new bucket is created for a Supabase project launched in Singapore. All requests to the Supabase Storage API are routed to the CDN first.
A user from the United States requests an object and is routed to the U.S. CDN. At this point, that CDN node does not have the object in its cache and pings the origin server in Singapore.
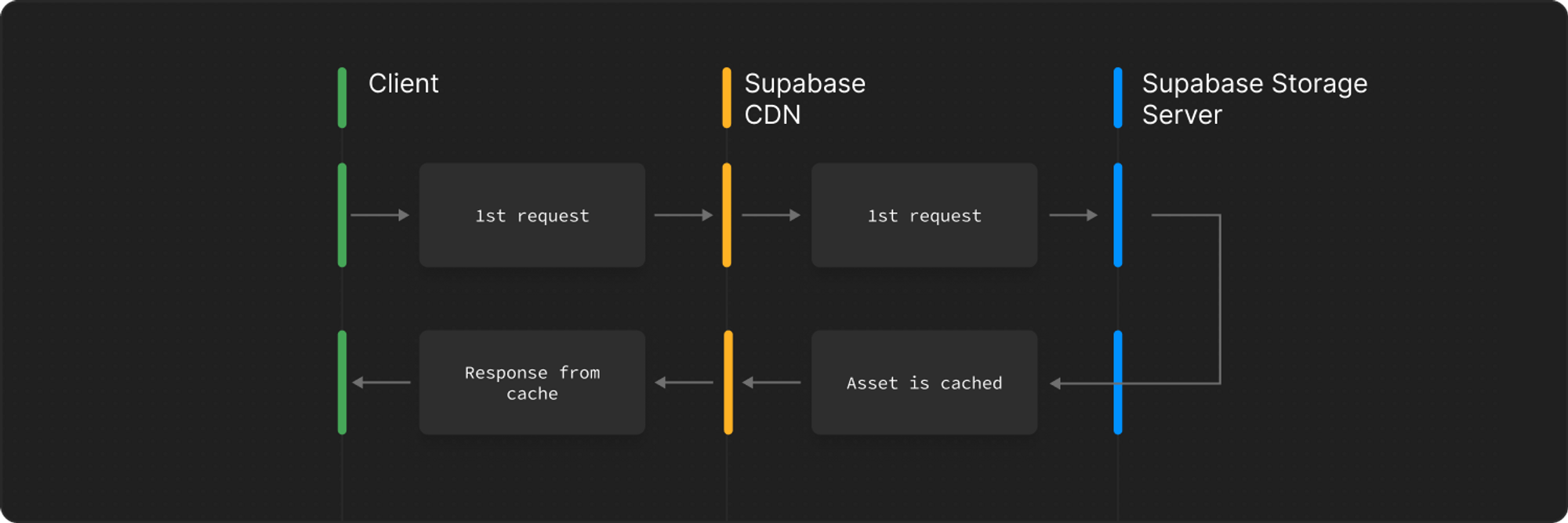
Another user, also in the United States, requests the same object and is served directly from the CDN cache in the United States instead of routing the request back to Singapore.
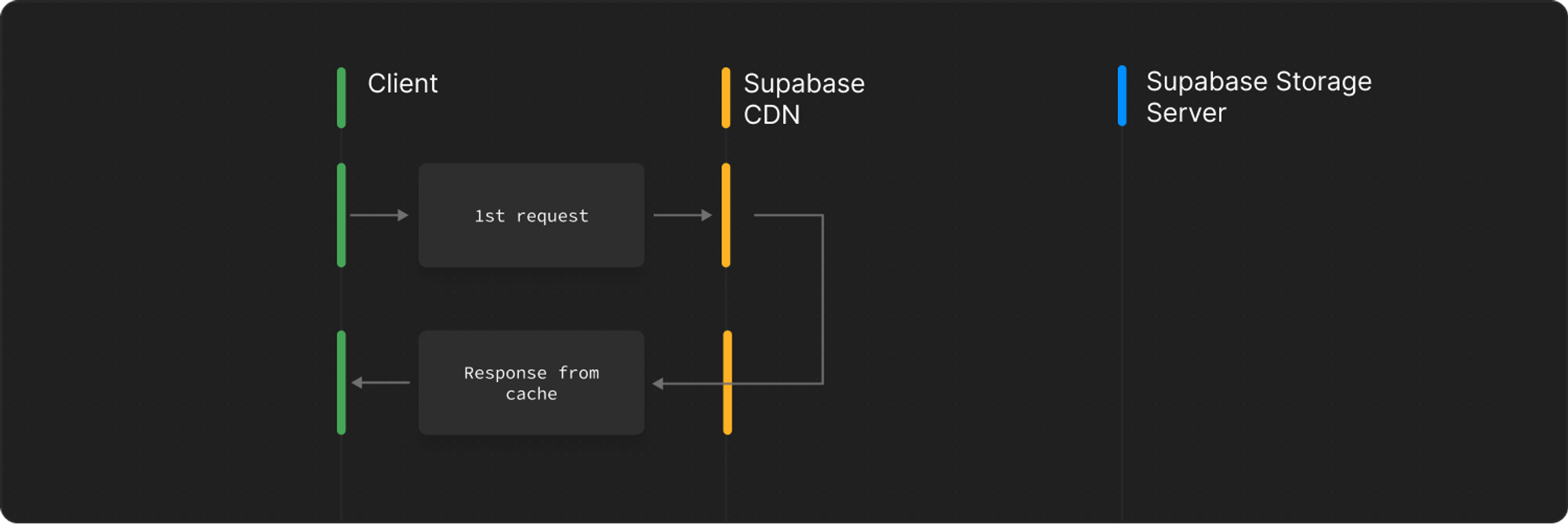
Note that CDNs might still evict your object from their cache if it has not been requested for a while from a specific region. For example, if no user from United States requests your object, it will be removed from the CDN cache even if we set a very long cache control duration.
The cache status of a particular request is sent in the `cf-cache-status` header. A cache status of `MISS` indicates that the CDN node did not have the object in its cache and had to ping the origin to get it. A cache status of `HIT` indicates that the object was sent directly from the CDN.
### Public vs private buckets
Objects in public buckets do not require any authorization to access objects. This leads to a better cache hit rate compared to private buckets.
For private buckets, permissions for accessing each object is checked on a per user level. For example, if two different users access the same object in a private bucket from the same region, it results in a cache miss for both the users since they might have different security policies attached to them.
On the other hand, if two different users access the same object in a public bucket from the same region, it results in a cache hit for the second user.
# Cache Metrics
Cache hits can be determined via the `metadata.response.headers.cf_cache_status` key in our [Logs Explorer](/docs/guides/platform/logs#logs-explorer). Any value that corresponds to either `HIT`, `STALE`, `REVALIDATED`, or `UPDATING` is categorized as a cache hit.
The following example query will show the top cache misses from the `edge_logs`:
```sql
select
r.path as path,
r.search as search,
count(id) as count
from
edge_logs as f
cross join unnest(f.metadata) as m
cross join unnest(m.request) as r
cross join unnest(m.response) as res
cross join unnest(res.headers) as h
where
starts_with(r.path, '/storage/v1/object')
and r.method = 'GET'
and h.cf_cache_status in ('MISS', 'NONE/UNKNOWN', 'EXPIRED', 'BYPASS', 'DYNAMIC')
group by path, search
order by count desc
limit 50;
```
Try out [this query](/dashboard/project/_/logs/explorer?q=%0Aselect%0A++r.path+as+path%2C%0A++r.search+as+search%2C%0A++count%28id%29+as+count%0Afrom%0A++edge_logs+as+f%0A++cross+join+unnest%28f.metadata%29+as+m%0A++cross+join+unnest%28m.request%29+as+r%0A++cross+join+unnest%28m.response%29+as+res%0A++cross+join+unnest%28res.headers%29+as+h%0Awhere%0A++starts_with%28r.path%2C+%27%2Fstorage%2Fv1%2Fobject%27%29%0A++and+r.method+%3D+%27GET%27%0A++and+h.cf_cache_status+in+%28%27MISS%27%2C+%27NONE%2FUNKNOWN%27%2C+%27EXPIRED%27%2C+%27BYPASS%27%2C+%27DYNAMIC%27%29%0Agroup+by+path%2C+search%0Aorder+by+count+desc%0Alimit+50%3B) in the Logs Explorer.
Your cache hit ratio over time can then be determined using the following query:
```sql
select
timestamp_trunc(timestamp, hour) as timestamp,
countif(h.cf_cache_status in ('HIT', 'STALE', 'REVALIDATED', 'UPDATING')) / count(f.id) as ratio
from
edge_logs as f
cross join unnest(f.metadata) as m
cross join unnest(m.request) as r
cross join unnest(m.response) as res
cross join unnest(res.headers) as h
where starts_with(r.path, '/storage/v1/object') and r.method = 'GET'
group by timestamp
order by timestamp desc;
```
Try out [this query](/dashboard/project/_/logs/explorer?q=%0Aselect%0A++timestamp_trunc%28timestamp%2C+hour%29+as+timestamp%2C%0A++countif%28h.cf_cache_status+in+%28%27HIT%27%2C+%27STALE%27%2C+%27REVALIDATED%27%2C+%27UPDATING%27%29%29+%2F+count%28f.id%29+as+ratio%0Afrom%0A++edge_logs+as+f%0A++cross+join+unnest%28f.metadata%29+as+m%0A++cross+join+unnest%28m.request%29+as+r%0A++cross+join+unnest%28m.response%29+as+res%0A++cross+join+unnest%28res.headers%29+as+h%0Awhere+starts_with%28r.path%2C+%27%2Fstorage%2Fv1%2Fobject%27%29+and+r.method+%3D+%27GET%27%0Agroup+by+timestamp%0Aorder+by+timestamp+desc%3B) in the Logs Explorer.
# Smart CDN
With Smart CDN caching enabled, the asset metadata in your database is synchronized to the edge. This automatically revalidates the cache when the asset is changed or deleted.
Moreover, the Smart CDN achieves a greater cache hit rate by shielding the origin server from asset requests that remain unchanged, even when different query strings are used in the URL.
Smart CDN caching is automatically enabled for [Pro Plan and above](/pricing).
## Cache duration
When Smart CDN is enabled, the asset is cached on the CDN for as long as possible. You can still control how long assets are stored in the browser using the [`cacheControl`](/docs/reference/javascript/storage-from-upload) option when uploading a file. Smart CDN caching works with all types of storage operations including signed URLs.
When a file is updated or deleted, the CDN cache is automatically invalidated to reflect the change (including transformed images). It can take **up to 60 seconds** for the CDN cache to be invalidated as the asset metadata has to propagate across all the data-centers around the globe.
When an asset is invalidated at the CDN level, browsers may not update its cache. This is where cache eviction comes into play.
## Cache eviction
Even when an asset is marked as invalidated at the CDN level, browsers may not refresh their cache for that asset.
If you have assets that undergo frequent updates, it is advisable to upload the new asset to a different path. This approach ensures that you always have the most up-to-date asset accessible.
If you anticipate that your asset might be deleted, it's advisable to set a shorter browser Time-to-Live (TTL) value using the `cacheControl` option. The default TTL is typically set to 1 hour, which is generally a reasonable default value.
## Bypassing cache
If you need to ensure assets refresh directly from the origin server and bypass the cache, you can achieve this by adding a unique query string such as `cacheNonce` to the URL.
For instance, you can use a URL like `/storage/v1/object/sign/profile-pictures/cat.jpg?cacheNonce=1` with a long browser cache (e.g., 1 year). To update the picture, increment the `cacheNonce` query parameter in the URL, like `/storage/v1/object/sign/profile-pictures/cat.jpg?cacheNonce=2`. The CDN will recognize it as a new object and fetch the updated version from the origin.
## Signed URLs and CDN caching
Signed URLs are the primary way to serve assets from private buckets to end users. With Smart CDN enabled, signed URL responses are cached at the CDN edge, just like any other storage request.
Unlike public bucket URLs, each signed URL contains a unique token query parameter (`?token=...`). Smart CDN treats each unique token as a separate cache key, meaning the first request with any given signed URL results in a cache miss, and only subsequent requests using that exact same URL will receive a cache hit. Two different signed URLs for the same object, even if generated seconds apart, each maintain their own independent cache entry.
This affects how you should think about serving private assets:
* If you generate a new signed URL on every request, the cache will never be warm and every request hits the origin.
* If you re-use the same signed URL across multiple requests, subsequent requests are served from cache. If the asset has no meaningful per-user access restriction, prefer a public bucket. It results in higher cache hit rates and removes the need to manage signed URL generation entirely.
* Revoking or expiring a token does not purge its CDN cache entry. The cached response persists at the edge until the cache duration expires.
* Deleting the object invalidates all cached entries for that object across all tokens. This can take up to a minute to propagate.
Token expiry (`expiresIn`) and the object's response cache TTL (`cacheControl`) are independent. Once a response is cached at the edge, that cached response can continue to be served for the same signed URL until the CDN cache duration expires, even if the token in that URL has already expired. If you need to cut off access to an asset, delete the object from the bucket rather than relying on token expiry alone.
# Creating Buckets
You can create a bucket using the Supabase Dashboard. Since storage is interoperable with your Postgres database, you can also use SQL or our client libraries.
Here we create a bucket called "avatars":
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient(process.env.SUPABASE_URL!, process.env.SUPABASE_KEY!)
// ---cut---
// Use the JS library to create a bucket.
const { data, error } = await supabase.storage.createBucket('avatars', {
public: true, // default: false
})
```
[Reference.](/docs/reference/javascript/storage-createbucket)
1. Go to the [Storage](/dashboard/project/_/storage/buckets) page in the Dashboard.
2. Click **New Bucket** and enter a name for the bucket.
3. Click **Create Bucket**.
```sql
-- Use Postgres to create a bucket.
insert into storage.buckets
(id, name, public)
values
('avatars', 'avatars', true);
```
```dart
void main() async {
final supabase = SupabaseClient('supabaseUrl', 'supabaseKey');
final storageResponse = await supabase
.storage
.createBucket('avatars');
}
```
[Reference.](https://pub.dev/documentation/storage_client/latest/storage_client/SupabaseStorageClient/createBucket.html)
```swift
try await supabase.storage.createBucket(
"avatars",
options: BucketOptions(public: true)
)
```
[Reference.](/docs/reference/swift/storage-createbucket)
```python
supabase.storage.create_bucket(
'avatars',
options={"public": True}
)
```
[Reference.](/docs/reference/python/storage-createbucket)
## Restricting uploads
When creating a bucket you can add additional configurations to restrict the type or size of files you want this bucket to contain.
For example, imagine you want to allow your users to upload only images to the `avatars` bucket and the size must not be greater than 1MB. You can achieve the following by providing `allowedMimeTypes` and `maxFileSize`:
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient(process.env.SUPABASE_URL!, process.env.SUPABASE_KEY!)
// ---cut---
// Use the JS library to create a bucket.
const { data, error } = await supabase.storage.createBucket('avatars', {
public: true,
allowedMimeTypes: ['image/*'],
fileSizeLimit: '1MB',
})
```
If an upload request doesn't meet the above restrictions it will be rejected. See [File Limits](/docs/guides/storage/uploads/file-limits) for more information.
# Storage Buckets
Buckets allow you to keep your files organized and determines the [Access Model](#access-model) for your assets. [Upload restrictions](/docs/guides/storage/buckets/creating-buckets#restricting-uploads) like max file size and allowed content types are also defined at the bucket level.
## Access model
There are 2 access models for buckets, **public** and **private** buckets.
### Private buckets
When a bucket is set to **Private** all operations are subject to access control via [RLS policies](/docs/guides/storage/security/access-control). This also applies when downloading assets. Buckets are private by default.
The only ways to download assets within a private bucket is to:
* Use the [download method](/docs/reference/javascript/storage-from-download) by providing an authorization header containing your user's JWT. The RLS policy you create on the `storage.objects` table will use this user to determine if they have access.
* Create a signed URL with the [`createSignedUrl` method](/docs/reference/javascript/storage-from-createsignedurl) that can be accessed for a limited time.
#### Example use cases:
* Uploading users' sensitive documents
* Securing private assets by using RLS to set up fine-grain access controls
### Public buckets
When a bucket is designated as 'Public,' it effectively bypasses access controls for both retrieving and serving files within the bucket. This means that anyone who possesses the asset URL can readily access the file.
Access control is still enforced for other types of operations including uploading, deleting, moving, and copying.
#### Example use cases:
* User profile pictures
* User public media
* Blog post content
Public buckets are more performant than private buckets since they are [cached differently](/docs/guides/storage/cdn/fundamentals#public-vs-private-buckets).
# Iceberg Catalog
Expect rapid changes, limited features, and possible breaking updates. [share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Analytics buckets require authentication with two distinct services:
## Architecture overview
**Iceberg REST Catalog** serves as the metadata management system for your Iceberg tables. It enables Iceberg clients such as PyIceberg and Apache Spark to perform critical operations:
* Creating and managing tables and namespaces
* Tracking schemas and handling schema evolution
* Managing partitions and table snapshots
* Ensuring transactional consistency and isolation
The REST Catalog only stores metadata describing your data's structure, schema, and partitioning strategy—not the actual data itself.
**S3-Compatible Storage Endpoint** handles the actual data storage and retrieval. It's optimized for reading and writing large analytical datasets stored in Parquet format, separate from the metadata management layer.
## Authentication setup
To connect to an analytics bucket, you need:
### 1. S3 credentials
Create S3 credentials through [**Project Settings > Storage**](/dashboard/project/_/storage/settings). See the [S3 Authentication Guide](/docs/guides/storage/s3/authentication) for detailed instructions.
You'll obtain:
* **Access Key ID**
* **Secret Access Key**
* **Region** (e.g., `us-east-1`)
### 2. Supabase service key
Retrieve your Service Key from [**Project Settings > API**](/dashboard/project/_/settings/api-keys). This key authenticates requests to the Iceberg REST Catalog.
### 3. Project reference
Your Supabase project reference is the subdomain in your project URL (e.g., `your-project-ref` in `https://your-project-ref.supabase.co`).
## Testing your connection
You can verify your setup by making a direct request to the Iceberg REST Catalog. Provide your Service Key as a Bearer token:
```bash
curl \
--request GET -sL \
--url 'https://.supabase.co/storage/v1/iceberg/v1/config?warehouse=' \
--header 'Authorization: Bearer '
```
A successful response returns the catalog configuration including warehouse location and settings.
## Next steps
* [Connect with PyIceberg](/docs/guides/storage/analytics/examples/pyiceberg)
* [Connect with Apache Spark](/docs/guides/storage/analytics/examples/apache-spark)
* [Query with Postgres](/docs/guides/storage/analytics/query-with-postgres)
# Creating Analytics Buckets
Set up your first analytics bucket using the SDK or dashboard.
This feature is in **Private Alpha**. API stability and backward compatibility are not guaranteed at this stage. Request access through this [form](https://forms.supabase.com/analytics-buckets).
Analytics buckets use [Apache Iceberg](https://iceberg.apache.org/), an open-table format for efficient management of large analytical datasets. You can interact with analytics buckets using tools such as [PyIceberg](https://py.iceberg.apache.org/), [Apache Spark](https://spark.apache.org/), or any client supporting the [Iceberg REST Catalog API](https://editor-next.swagger.io/?url=https://raw.githubusercontent.com/apache/iceberg/main/open-api/rest-catalog-open-api.yaml).
Analytics Buckets are still available, but managed replication into Analytics Buckets through Supabase ETL is no longer supported. If you need managed replication today, use [external replication](/docs/guides/database/replication/external-replication-setup) with **BigQuery**. If you want to use Analytics Buckets, bring your own ingestion pipeline.
## Creating an Analytics bucket
You can create an analytics bucket using either the Supabase SDK or the Supabase Dashboard.
### Using the Supabase SDK
```typescript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://your-project-id.supabase.co', 'your-service-key')
const { data, error } = await supabase.storage.analytics.createBucket('analytics-data')
if (error) {
console.error('Failed to create analytics bucket:', error)
} else {
console.log('Analytics bucket created:', data)
}
```
```python
from supabase import create_client
supabase = create_client('https://your-project-id.supabase.co', 'your-service-key')
response = supabase.storage.analytics().create('analytics-data')
print('Analytics bucket created:', response)
```
### Using the Supabase Dashboard
1. Navigate to the **Storage** section in the Supabase Dashboard.
2. Click **Create Bucket**.
3. Enter a name for your bucket (e.g., `my-analytics-bucket`).
4. Select **Analytics Bucket** as the bucket type.
5. Click **Create**.
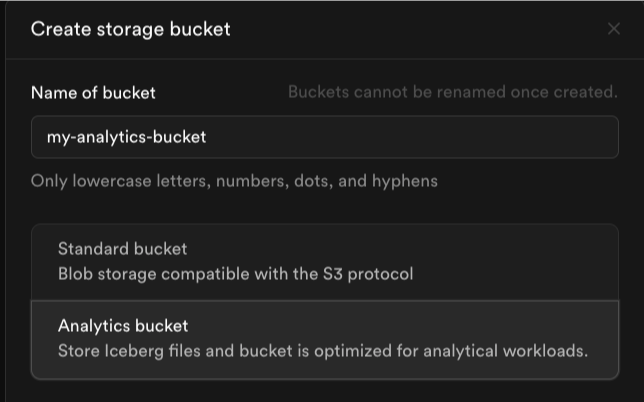 ## Next steps
Once you've created your analytics bucket, you can:
* [Connect with Iceberg clients](/docs/guides/storage/analytics/connecting-to-analytics-bucket) like PyIceberg or Apache Spark
* [Query data with Postgres](/docs/guides/storage/analytics/query-with-postgres) using the Iceberg Foreign Data Wrapper
# Analytics Buckets
Store large datasets for analytics and reporting.
Expect rapid changes, limited features, and possible breaking updates. [share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Analytics buckets enable analytical workflows on large-scale datasets while keeping your primary database optimized for transactional operations.
## Why Analytics buckets?
Postgres tables are purpose-built for transactional workloads with frequent inserts, updates, deletes, and low-latency queries. Analytical workloads have fundamentally different requirements:
* Processing large volumes of historical data
* Running complex queries and aggregations
* Minimizing storage costs
* Preventing analytical queries from impacting production traffic
Analytics buckets address these requirements using [Apache Iceberg](https://iceberg.apache.org/), an open-table format specifically designed for efficient management of large analytical datasets.
## Ideal use cases
Analytics buckets are perfect for:
* **Data warehousing and business intelligence** - Build scalable data warehouses for BI tools
* **Historical data archiving** - Retain large volumes of historical data cost-effectively
* **Periodically refreshed analytics** - Maintain near real-time analytical views
* **Complex analytical queries** - Execute sophisticated aggregations and joins over large datasets
By separating transactional and analytical workloads, Supabase lets you build scalable analytics pipelines without compromising your primary Postgres performance.
# Analytics Buckets Limits
Expect rapid changes, limited features, and possible breaking updates. [share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
The following default limits are applied when this feature is in the alpha stage, they can be adjusted on a case-by-case basis:
| **Category** | **Limit** |
| --------------------------------------- | --------- |
| Number of analytics buckets per project | 2 |
| Number of namespaces per bucket | 10 |
| Number of tables per namespace | 10 |
# Analytics Buckets Pricing
Expect rapid changes, limited features, and possible breaking updates. [share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Analytics buckets are **free** to use during the alpha phase. You will still be charged for the underlying egress.
# Query with Postgres
Query analytics bucket data directly from Postgres using SQL.
Once your data flows into an analytics bucket through your own ingestion pipeline, you can query it directly from Postgres using standard SQL.
This is made possible by the [Iceberg Foreign Data Wrapper](/docs/guides/database/extensions/wrappers/iceberg), which creates a bridge between your Postgres database and Iceberg tables.
Managed replication into Analytics Buckets through Supabase ETL is no longer supported. This guide assumes your Analytics Bucket is being populated by your own ingestion pipeline.
## Setup overview
You have two options to enable querying:
1. **Dashboard UI** (recommended) - Streamlined setup through the Supabase Dashboard
2. **Manual installation** - Install the wrapper using SQL and configuration
## Installing via Dashboard UI
The dashboard provides the easiest setup experience:
1. Navigate to your **Analytics Bucket** page in the Supabase Dashboard.
2. Locate the namespace you want to query and click **Query with Postgres**.
3. Enter the **Postgres schema** where you want to create the foreign tables.
4. Click **Connect**. The wrapper is now configured.
## Querying your data
Once the foreign data wrapper is installed, you can query your Iceberg tables using standard SQL:
```sql
select *
from schema_name.table_name
limit 100;
```
### Common query examples
Get the latest events:
```sql
select event_id, event_name, event_timestamp
from analytics.events
order by event_timestamp desc
limit 1000;
```
Join with transactional data:
```sql
SELECT
e.event_id,
e.event_name,
u.user_email
FROM analytics.events e
JOIN public.users u ON e.user_id = u.id
WHERE e.event_timestamp > NOW() - INTERVAL '7 days'
LIMIT 100;
```
## Manual installation
For advanced use cases, you can manually install and configure the Iceberg Foreign Data Wrapper. See the [Iceberg Foreign Data Wrapper documentation](/docs/guides/database/extensions/wrappers/iceberg) for detailed instructions.
# Apache Spark
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Apache Spark enables distributed analytical processing of large datasets stored in your analytics buckets. Use it for complex transformations, aggregations, and machine learning workflows.
## Installation
First, ensure you have Spark installed. For Python-based workflows:
```bash
pip install pyspark
```
For detailed Spark setup instructions, see the [Apache Spark documentation](https://spark.apache.org/docs/latest/).
## Basic setup
Here's a complete example showing how to configure Spark with your Supabase analytics bucket:
```python
from pyspark.sql import SparkSession
# Configuration - Update with your Supabase credentials
PROJECT_REF = "your-project-ref"
WAREHOUSE = "your-analytics-bucket-name"
SERVICE_KEY = "your-service-key"
# S3 credentials from Project Settings > Storage
S3_ACCESS_KEY = "your-access-key"
S3_SECRET_KEY = "your-secret-key"
S3_REGION = "us-east-1"
# Construct Supabase endpoints
S3_ENDPOINT = f"https://{PROJECT_REF}.supabase.co/storage/v1/s3"
CATALOG_URI = f"https://{PROJECT_REF}.supabase.co/storage/v1/iceberg"
# Initialize Spark session with Iceberg configuration
spark = SparkSession.builder \
.master("local[*]") \
.appName("SupabaseIceberg") \
.config("spark.driver.host", "127.0.0.1") \
.config("spark.driver.bindAddress", "127.0.0.1") \
.config(
'spark.jars.packages',
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1,org.apache.iceberg:iceberg-aws-bundle:1.6.1'
) \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.supabase", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.supabase.type", "rest") \
.config("spark.sql.catalog.supabase.uri", CATALOG_URI) \
.config("spark.sql.catalog.supabase.warehouse", WAREHOUSE) \
.config("spark.sql.catalog.supabase.token", SERVICE_KEY) \
.config("spark.sql.catalog.supabase.s3.endpoint", S3_ENDPOINT) \
.config("spark.sql.catalog.supabase.s3.path-style-access", "true") \
.config("spark.sql.catalog.supabase.s3.access-key-id", S3_ACCESS_KEY) \
.config("spark.sql.catalog.supabase.s3.secret-access-key", S3_SECRET_KEY) \
.config("spark.sql.catalog.supabase.s3.remote-signing-enabled", "false") \
.config("spark.sql.defaultCatalog", "supabase") \
.getOrCreate()
print("✓ Spark session initialized with Iceberg")
```
## Creating tables
```python
# Create a namespace for organization
spark.sql("CREATE NAMESPACE IF NOT EXISTS analytics")
# Create a new Iceberg table
spark.sql("""
CREATE TABLE IF NOT EXISTS analytics.events (
event_id BIGINT,
user_id BIGINT,
event_name STRING,
event_timestamp TIMESTAMP,
properties STRING
)
USING iceberg
""")
print("✓ Created table: analytics.events")
```
## Writing data
```python
# Insert data into the table
spark.sql("""
INSERT INTO analytics.events (event_id, user_id, event_name, event_timestamp, properties)
VALUES
(1, 101, 'login', TIMESTAMP '2024-01-15 10:30:00', '{"browser":"chrome"}'),
(2, 102, 'view_product', TIMESTAMP '2024-01-15 10:35:00', '{"product_id":"123"}'),
(3, 101, 'logout', TIMESTAMP '2024-01-15 10:40:00', '{}'),
(4, 103, 'purchase', TIMESTAMP '2024-01-15 10:45:00', '{"amount":99.99}')
""")
print("✓ Inserted 4 rows into analytics.events")
```
## Reading data
```python
# Read the entire table
result_df = spark.sql("SELECT * FROM analytics.events")
result_df.show(truncate=False)
# Apply filters
filtered_df = spark.sql("""
SELECT event_id, user_id, event_name
FROM analytics.events
WHERE event_name = 'login'
""")
filtered_df.show()
# Aggregations
summary_df = spark.sql("""
SELECT
event_name,
COUNT(*) as event_count,
COUNT(DISTINCT user_id) as unique_users
FROM analytics.events
GROUP BY event_name
ORDER BY event_count DESC
""")
summary_df.show()
```
## Advanced operations
### Working with dataframes
```python
# Read as DataFrame
events_df = spark.read.format("iceberg").load("analytics.events")
# Apply Spark transformations
from pyspark.sql.functions import count, col, year, month
# Monthly event counts
monthly_events = events_df \
.withColumn("month", month(col("event_timestamp"))) \
.withColumn("year", year(col("event_timestamp"))) \
.groupBy("year", "month", "event_name") \
.agg(count("event_id").alias("count")) \
.orderBy("year", "month")
monthly_events.show()
```
### Joining tables
```python
# Create another table
spark.sql("""
CREATE TABLE IF NOT EXISTS analytics.users (
user_id BIGINT,
username STRING,
email STRING
)
USING iceberg
""")
spark.sql("""
INSERT INTO analytics.users VALUES
(101, 'alice', 'alice@example.com'),
(102, 'bob', 'bob@example.com'),
(103, 'charlie', 'charlie@example.com')
""")
# Join events with users
joined_df = spark.sql("""
SELECT
e.event_id,
e.event_name,
u.username,
u.email,
e.event_timestamp
FROM analytics.events e
JOIN analytics.users u ON e.user_id = u.user_id
ORDER BY e.event_timestamp
""")
joined_df.show(truncate=False)
```
### Exporting results
```python
# Export to Parquet
spark.sql("""
SELECT event_name, COUNT(*) as count
FROM analytics.events
GROUP BY event_name
""").write \
.mode("overwrite") \
.parquet("/tmp/event_summary.parquet")
# Export to CSV
spark.sql("""
SELECT *
FROM analytics.events
WHERE event_timestamp > TIMESTAMP '2024-01-15 10:30:00'
""").write \
.mode("overwrite") \
.option("header", "true") \
.csv("/tmp/recent_events.csv")
print("✓ Results exported")
```
## Performance best practices
* **Partition tables** - Partition large tables by date or region for faster queries
* **Select columns** - Only select columns you need to reduce I/O
* **Use filters early** - Apply WHERE clauses to reduce data processed
* **Cache frequently accessed tables** - Use `spark.catalog.cacheTable()` for tables accessed multiple times
* **Cluster mode** - Use cluster mode for production workloads instead of local mode
## Complete example: Data processing pipeline
```python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, year, month, count
# Setup (see Basic Setup section above)
spark = SparkSession.builder \
.master("local[*]") \
.appName("SupabaseAnalytics") \
.config("spark.sql.defaultCatalog", "supabase") \
# ... (add all config from Basic Setup)
.getOrCreate()
# Step 1: Read raw events
raw_events = spark.sql("SELECT * FROM analytics.events")
# Step 2: Transform and aggregate
monthly_summary = raw_events \
.withColumn("month", month(col("event_timestamp"))) \
.withColumn("year", year(col("event_timestamp"))) \
.groupBy("year", "month", "event_name") \
.agg(count("event_id").alias("total_events"))
# Step 3: Save results
monthly_summary.write \
.mode("overwrite") \
.option("path", "analytics.monthly_summary") \
.saveAsTable("analytics.monthly_summary")
print("✓ Pipeline completed")
monthly_summary.show()
```
## Next steps
* [Query with Postgres](/docs/guides/storage/analytics/query-with-postgres)
* [Connect with PyIceberg](/docs/guides/storage/analytics/examples/pyiceberg)
* [Explore with DuckDB](/docs/guides/storage/analytics/examples/duckdb)
# DuckDB
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
DuckDB is a high-performance SQL database system optimized for analytical workloads. It can directly query Iceberg tables stored in your analytics buckets, making it ideal for data exploration and complex analytical queries.
## Installation
Install DuckDB and the Iceberg extension:
```bash
pip install duckdb duckdb-iceberg
```
## Connecting to Analytics buckets
Here's a complete example of connecting to your Supabase analytics bucket and querying Iceberg tables:
```python
import duckdb
import os
# Configuration
PROJECT_REF = "your-project-ref"
WAREHOUSE = "your-analytics-bucket-name"
SERVICE_KEY = "your-service-key"
# S3 credentials
S3_ACCESS_KEY = "your-access-key"
S3_SECRET_KEY = "your-secret-key"
S3_REGION = "us-east-1"
# Construct endpoints
S3_ENDPOINT = f"https://{PROJECT_REF}.supabase.co/storage/v1/s3"
CATALOG_URI = f"https://{PROJECT_REF}.supabase.co/storage/v1/iceberg"
# Initialize DuckDB connection
conn = duckdb.connect(":memory:")
# Install and load the Iceberg extension
conn.install_extension("iceberg")
conn.load_extension("iceberg")
# Configure Iceberg catalog with Supabase credentials
conn.execute(f"""
CREATE SECRET (
TYPE S3,
KEY_ID '{S3_ACCESS_KEY}',
SECRET '{S3_SECRET_KEY}',
REGION '{S3_REGION}',
ENDPOINT '{S3_ENDPOINT}',
URL_STYLE 'virtual'
);
""")
# Configure the REST catalog
conn.execute(f"""
ATTACH 'iceberg://{CATALOG_URI}' AS iceberg_catalog
(
TYPE ICEBERG_REST,
WAREHOUSE '{WAREHOUSE}',
TOKEN '{SERVICE_KEY}'
);
""")
# Query your Iceberg tables
result = conn.execute("""
SELECT *
FROM iceberg_catalog.default.events
LIMIT 10
""").fetchall()
for row in result:
print(row)
# Complex aggregation example
analytics = conn.execute("""
SELECT
event_name,
COUNT(*) as event_count,
COUNT(DISTINCT user_id) as unique_users
FROM iceberg_catalog.default.events
GROUP BY event_name
ORDER BY event_count DESC
""").fetchdf()
print(analytics)
```
## Key features with DuckDB
### Efficient data exploration
DuckDB's lazy evaluation means it only scans the data you need:
```python
# This only reads the columns you select
events = conn.execute("""
SELECT event_id, event_name, event_timestamp
FROM iceberg_catalog.default.events
WHERE event_timestamp > NOW() - INTERVAL '7 days'
""").fetchdf()
```
### Converting to Pandas
Convert results to Pandas DataFrames for further analysis:
```python
df = conn.execute("""
SELECT *
FROM iceberg_catalog.default.events
""").fetchdf()
# Use pandas for visualization or further processing
print(df.describe())
```
### Exporting results
Save your analytical results to various formats:
```python
# Export to Parquet
conn.execute("""
COPY (
SELECT * FROM iceberg_catalog.default.events
) TO 'results.parquet'
""")
# Export to CSV
conn.execute("""
COPY (
SELECT event_name, COUNT(*) as count
FROM iceberg_catalog.default.events
GROUP BY event_name
) TO 'summary.csv' (FORMAT CSV, HEADER true)
""")
```
## Best practices
* **Connection pooling** - Reuse connections for multiple queries
* **Partition pruning** - Filter by partition columns to improve query performance
* **Column selection** - Only select columns you need to reduce I/O
* **Limit results** - Use LIMIT during exploration to avoid processing large datasets
## Next steps
* [Query with Postgres](/docs/guides/storage/analytics/query-with-postgres)
* [Connect with PyIceberg](/docs/guides/storage/analytics/examples/pyiceberg)
* [Analyze with Apache Spark](/docs/guides/storage/analytics/examples/apache-spark)
# PyIceberg
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
PyIceberg is a Python client for Apache Iceberg that enables programmatic interaction with Iceberg tables. Use it to create, read, update, and delete data in your analytics buckets.
## Installation
```bash
pip install pyiceberg pyarrow
```
## Basic setup
Here's a complete example showing how to connect to your Supabase analytics bucket and perform operations:
```python
from pyiceberg.catalog import load_catalog
import pyarrow as pa
import datetime
# Configuration - Update with your Supabase credentials
PROJECT_REF = "your-project-ref"
WAREHOUSE = "your-analytics-bucket-name"
SERVICE_KEY = "your-service-key"
# S3 credentials from Project Settings > Storage
S3_ACCESS_KEY = "your-access-key"
S3_SECRET_KEY = "your-secret-key"
S3_REGION = "us-east-1"
# Construct Supabase endpoints
S3_ENDPOINT = f"https://{PROJECT_REF}.supabase.co/storage/v1/s3"
CATALOG_URI = f"https://{PROJECT_REF}.supabase.co/storage/v1/iceberg"
# Load the Iceberg REST Catalog
catalog = load_catalog(
"supabase-analytics",
type="rest",
warehouse=WAREHOUSE,
uri=CATALOG_URI,
token=SERVICE_KEY,
**{
"py-io-impl": "pyiceberg.io.pyarrow.PyArrowFileIO",
"s3.endpoint": S3_ENDPOINT,
"s3.access-key-id": S3_ACCESS_KEY,
"s3.secret-access-key": S3_SECRET_KEY,
"s3.region": S3_REGION,
"s3.force-virtual-addressing": False,
},
)
print("✓ Successfully connected to Iceberg catalog")
```
## Creating tables
```python
# Create a namespace for organization
catalog.create_namespace_if_not_exists("analytics")
# Define the schema for your Iceberg table
schema = pa.schema([
pa.field("event_id", pa.int64()),
pa.field("user_id", pa.int64()),
pa.field("event_name", pa.string()),
pa.field("event_timestamp", pa.timestamp("ms")),
pa.field("properties", pa.string()),
])
# Create the table
table = catalog.create_table_if_not_exists(
("analytics", "events"),
schema=schema
)
print("✓ Created table: analytics.events")
```
## Writing data
```python
import datetime
# Prepare your data
current_time = datetime.datetime.now()
data = pa.table({
"event_id": [1, 2, 3, 4, 5],
"user_id": [101, 102, 101, 103, 102],
"event_name": ["login", "view_product", "logout", "purchase", "login"],
"event_timestamp": [current_time] * 5,
"properties": [
'{"browser":"chrome"}',
'{"product_id":"123"}',
'{}',
'{"amount":99.99}',
'{"browser":"firefox"}'
],
})
# Append data to the table
table.append(data)
print("✓ Appended 5 rows to analytics.events")
```
## Reading data
```python
# Scan the entire table
scan_result = table.scan().to_pandas()
print(f"Total rows: {len(scan_result)}")
print(scan_result.head())
# Query with filters
filtered = table.scan(
filter="event_name = 'login'"
).to_pandas()
print(f"Login events: {len(filtered)}")
# Select specific columns
selected = table.scan(
selected_fields=["user_id", "event_name", "event_timestamp"]
).to_pandas()
print(selected.head())
```
## Advanced operations
### Listing tables and namespaces
```python
# List all namespaces
namespaces = catalog.list_namespaces()
print("Namespaces:", namespaces)
# List tables in a namespace
tables = catalog.list_tables("analytics")
print("Tables in analytics:", tables)
# Get table metadata
table_metadata = catalog.load_table(("analytics", "events"))
print("Schema:", table_metadata.schema())
print("Partitions:", table_metadata.partitions())
```
### Handling errors
```python
try:
# Attempt to load a table
table = catalog.load_table(("analytics", "nonexistent"))
except Exception as e:
print(f"Error loading table: {e}")
# Check if table exists before creating
namespace = "analytics"
table_name = "events"
try:
existing_table = catalog.load_table((namespace, table_name))
print(f"Table already exists")
except Exception:
print(f"Table does not exist, creating...")
table = catalog.create_table((namespace, table_name), schema=schema)
```
## Performance tips
* **Batch writes** - Insert data in batches rather than row-by-row for better performance
* **Partition strategies** - Use partitioning for large tables to improve query performance
* **Schema evolution** - PyIceberg supports schema changes without rewriting data
* **Data format** - Use Parquet for efficient columnar storage
## Complete example: ETL pipeline
```python
from pyiceberg.catalog import load_catalog
import pyarrow as pa
import pandas as pd
# Setup (see Basic Setup section above)
catalog = load_catalog(...)
# Step 1: Create analytics namespace
catalog.create_namespace_if_not_exists("warehouse")
# Step 2: Define table schema
schema = pa.schema([
pa.field("id", pa.int64()),
pa.field("name", pa.string()),
pa.field("created_at", pa.timestamp("ms")),
])
# Step 3: Create table
table = catalog.create_table_if_not_exists(
("warehouse", "products"),
schema=schema
)
# Step 4: Load data from CSV or database
df = pd.read_csv("products.csv")
data = pa.Table.from_pandas(df)
# Step 5: Write to analytics bucket
table.append(data)
print(f"✓ Loaded {len(data)} products to warehouse.products")
# Step 6: Verify
result = table.scan().to_pandas()
print(result.describe())
```
## Next steps
* [Query with Postgres](/docs/guides/storage/analytics/query-with-postgres)
* [Analyze with Apache Spark](/docs/guides/storage/analytics/examples/apache-spark)
* [Explore with DuckDB](/docs/guides/storage/analytics/examples/duckdb)
# Copy Storage Objects from Platform
Copy storage objects from a managed Supabase project to a self-hosted instance using rclone.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
This guide walks you through copying storage objects from a managed Supabase platform project to a self-hosted instance using [rclone](https://rclone.org/) with S3-to-S3 copy.
Direct file copy (e.g., downloading files and placing them into `volumes/storage/`) does not work. Self-hosted Storage uses an internal file structure that differs from what you get when downloading files from the platform. Use the S3 protocol to transfer objects so that Storage creates the correct metadata records.
## Before you begin
You need:
* A working self-hosted Supabase instance with the S3 protocol endpoint enabled - see [Configure S3 Storage](/docs/guides/self-hosting/self-hosted-s3#enable-the-s3-protocol-endpoint)
* Your platform project's S3 credentials - generated from the [S3 Configuration](/dashboard/project/_/storage/s3) page
* Matching buckets created on your self-hosted instance
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* [rclone](https://rclone.org/install/) installed on the machine running the copy
## Step 1: Get platform S3 credentials
In your managed Supabase project dashboard, go to **Storage** > **S3 Configuration** > **Access keys**. Generate a new access key pair and copy:
* **Endpoint**: `https://.supabase.co/storage/v1/s3`
* **Region**: your project's region (e.g., `us-east-1`)
* **Access Key ID** and **Secret access key**
For better performance with large files, use the direct storage hostname: `https://.storage.supabase.co/storage/v1/s3`
## Step 2: Create buckets on self-hosted
Buckets must exist on the destination before you can copy objects into them. You can create them through the dashboard UI, or with the **SQL Editor**.
If you already restored your platform database to self-hosted using the [restore guide](/docs/guides/self-hosting/restore-from-platform), your bucket definitions are already present. You can skip this step.
To list your platform buckets, connect to your platform database and run:
```sql
select id, name, public from storage.buckets order by name;
```
Then create matching buckets on your self-hosted instance. Connect to your self-hosted database and run:
```sql
insert into storage.buckets (id, name, public)
values
('your-storage-bucket', 'your-storage-bucket', false)
on conflict (id) do nothing;
```
Repeat for each bucket, setting `public` to `true` or `false` as appropriate.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
## Step 3: Configure rclone
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
Create or edit your rclone configuration file (`~/.config/rclone/rclone.conf`):
```ini rclone.conf
[platform]
type = s3
provider = Other
access_key_id = your-platform-access-key-id
secret_access_key = your-platform-secret-access-key
endpoint = https://your-project-ref.supabase.co/storage/v1/s3
region = your-project-region
[self-hosted]
type = s3
provider = Other
access_key_id = your-self-hosted-access-key-id
secret_access_key = your-self-hosted-secret-access-key
endpoint = http://your-domain:8000/storage/v1/s3
region = your-self-hosted-region
```
Replace the credentials with your actual values. For self-hosted, use the `REGION`, `S3_PROTOCOL_ACCESS_KEY_ID` and `S3_PROTOCOL_ACCESS_KEY_SECRET` you configured in [Configure S3 Storage](/docs/guides/self-hosting/self-hosted-s3#enable-the-s3-protocol-endpoint).
Verify both remotes connect:
```sh
rclone lsd platform:
rclone lsd self-hosted:
```
Both commands should list your buckets.
## Step 4: Copy objects
Copy a single bucket:
```sh
rclone copy platform:your-storage-bucket self-hosted:your-storage-bucket --progress
```
To copy all buckets:
```sh
for bucket in $(rclone lsf platform: | tr -d '/'); do
echo "Copying bucket: $bucket"
rclone copy "platform:$bucket" "self-hosted:$bucket" --progress
done
```
For large migrations, consider adding `--transfers 4` to increase parallelism, or `--checkers 8` to speed up the comparison phase. See the [flags documentation](https://rclone.org/flags/) for all options.
## Verify
Compare object counts between source and destination:
```sh
rclone size platform:your-storage-bucket && \
rclone size self-hosted:your-storage-bucket
```
Open Studio on your self-hosted instance and browse the storage buckets to confirm files are accessible.
## Troubleshooting
### Signature errors
If you see `SignatureDoesNotMatch` when connecting to either remote:
* **Platform**: Regenerate S3 access keys from your project's Storage Settings. Ensure the endpoint URL includes `/storage/v1/s3`.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* **Self-hosted**: Verify that `REGION`, `S3_PROTOCOL_ACCESS_KEY_ID` and `S3_PROTOCOL_ACCESS_KEY_SECRET` in `.env` file match your rclone config.
### Bucket not found
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
If rclone reports that a bucket doesn't exist on the self-hosted side, create it first - see [Step 2](#step-2-create-buckets-on-self-hosted). The S3 protocol does not auto-create buckets on copy.
### Timeouts on large files
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
For very large files, increase rclone's timeout:
```sh
rclone copy platform:your-storage-bucket self-hosted:your-storage-bucket --timeout 30m
```
### Empty listing on platform
If `rclone lsd platform:` returns nothing, verify the endpoint URL ends with `/storage/v1/s3` and that the S3 access keys have not expired. Regenerate them from the dashboard if needed.
# Custom Email Templates
Configure custom email templates with self-hosted Supabase instance
When running a self-hosted Supabase instance, you can fully customize emails sent by Supabase Auth.
## Overview
Supabase Auth does not read email templates from mounted Docker volumes. Instead, it expects each template to be available at a URL that returns a valid HTML template.
This URL:
* Does not need to be public
* Must be reachable from `auth` service
* Must return a valid Golang HTML template
To provide templates to Supabase Auth, you need a service that serves static HTML files. This can be any server of your choice. The only requirement is that the `auth` service must be able to reach it via a HTTP GET request.
This guide uses [Caddy](https://github.com/caddyserver/caddy) for serving templates.
If Supabase Auth cannot fetch the template or if the fetched template is invalid, it falls back to the default template.
## Authentication email templates
Authentication email templates can be configured using the following environment variables:
* `GOTRUE_MAILER_TEMPLATES_`: Provide a custom template URL. Falls back to the default template if not set.
* `GOTRUE_MAILER_SUBJECTS_`: Customize the email subject. Falls back to the default subject if not set.
| Auth flow | Sent |
| ------------------ | -------------------------------------------------------------------- |
| `CONFIRMATION` | When a user signs up and needs to verify their email address |
| `RECOVERY` | When a user requests a password reset |
| `MAGIC_LINK` | When a user requests a magic link for password-less authentication |
| `INVITE` | When a user is invited to join your application via email invitation |
| `EMAIL_CHANGE` | When a user requests to change their email address |
| `REAUTHENTICATION` | When a user needs to re-authenticate for sensitive operations |
For example:
```sh
GOTRUE_MAILER_TEMPLATES_MAGIC_LINK=''
GOTRUE_MAILER_SUBJECTS_MAGIC_LINK=''
```
### Example
Below is an example configuration for setting up a custom invite template.
### Step 1: Create a templates directory
Create a `templates` directory inside the existing `volumes` directory and add your email templates to it.
Your directory structure should look like this:
```
volumes/
templates/
invite.html
```
### Step 2: Update `docker-compose.yml`
Update the `auth` service to depend on `templates-server`, and pass the email template environment variables. Then add a `templates-server` service to serve the templates from `./volumes/templates`.
```yml name=docker-compose.yml
services:
auth:
depends_on:
db:
condition: service_healthy
templates-server: # 👈 new dependency
condition: service_started
environment:
GOTRUE_MAILER_TEMPLATES_INVITE: 'http://templates-server/invite.html'
GOTRUE_MAILER_SUBJECTS_INVITE: 'You have been invited'
templates-server:
image: caddy:2-alpine
command: ['caddy', 'file-server', '-r', '/templates', '--listen', ':80']
volumes:
- ./volumes/templates:/templates
```
#### What this configuration does
* Adds a `templates-server` service that runs alongside the Supabase services in the same docker network.
* Serves your custom email template files from the `./volumes/templates` directory.
* Keeps the templates-server private to the Docker network (no published ports), so it is not accessible from outside.
* Allows the `auth` service to fetch templates via `http://templates-server/.html`.
### Step 3: Restart containers
```sh
docker compose up -d --force-recreate --no-deps auth templates-server
```
## Notification email templates
Notification email templates can be configured using the following environment variables:
* `GOTRUE_MAILER_NOTIFICATIONS__ENABLED`: Enable the notification email
* `GOTRUE_MAILER_TEMPLATES__NOTIFICATION`: Provide a custom template URL. Falls back to the default template if not set.
* `GOTRUE_MAILER_SUBJECTS__NOTIFICATION`: Customize the email subject. Falls back to the default subject if not set.
| Notification Type | Sent |
| ----------------------- | ----------------------------------------------------- |
| `PASSWORD_CHANGED` | When a user's password is changed |
| `EMAIL_CHANGED` | When a user's email address is changed |
| `PHONE_CHANGED` | When a user's phone number is changed |
| `MFA_FACTOR_ENROLLED` | When a new MFA factor is added to the user's account |
| `MFA_FACTOR_UNENROLLED` | When an MFA factor is removed from the user's account |
| `IDENTITY_LINKED` | When a new identity is linked to the account |
| `IDENTITY_UNLINKED` | When an identity is unlinked from the account |
For example:
```sh
GOTRUE_MAILER_NOTIFICATIONS_EMAIL_CHANGED_ENABLED='true'
GOTRUE_MAILER_TEMPLATES_EMAIL_CHANGED_NOTIFICATION=''
GOTRUE_MAILER_SUBJECTS_EMAIL_CHANGED_NOTIFICATION=''
```
### Example
Below is an example configuration for setting up a custom password changed notification template.
### Step 1: Create the templates directory
This example reuses the directory created in **Auth Email Templates – Step 1** (`volumes/templates`). Add your notification email templates to this directory.
Your directory structure should look like this:
```
volumes/
templates/
invite.html
password_changed_notification.html
```
### Step 2: Update `docker-compose.yml`
Update the `auth` service in `docker-compose.yml` to enable password changed notification
```yml name=docker-compose.yml
services:
auth:
depends_on:
db:
condition: service_healthy
templates-server:
condition: service_started
environment:
GOTRUE_MAILER_NOTIFICATIONS_PASSWORD_CHANGED_ENABLED: 'true' # 👈 enabling the notification is required
GOTRUE_MAILER_TEMPLATES_PASSWORD_CHANGED_NOTIFICATION: 'http://templates-server/password_changed_notification.html'
GOTRUE_MAILER_SUBJECTS_PASSWORD_CHANGED_NOTIFICATION: 'Your password has been changed'
templates-server:
image: caddy:2-alpine
command: ['caddy', 'file-server', '-r', '/templates', '--listen', ':80']
volumes:
- ./volumes/templates:/templates
```
### Step 3: Restart containers
```sh
docker compose up -d --force-recreate --no-deps auth templates-server
```
# Self-Hosting with Docker
Learn how to configure and deploy Supabase with Docker.
Docker is the easiest way to get started with self-hosted Supabase. It should take you less than 30 minutes to get up and running.
## Contents
1. [Before you begin](#before-you-begin)
2. [System requirements](#system-requirements)
3. [Installing Supabase](#installing-supabase)
4. [Configuring and securing Supabase](#configuring-and-securing-supabase)
5. [Starting and stopping](#starting-and-stopping)
6. [Accessing Supabase services](#accessing-supabase-studio-dashboard)
7. [Updating](#updating)
8. [Uninstalling](#uninstalling)
9. [Advanced topics](#advanced-topics)
## Before you begin
This guide assumes you're comfortable with:
* Linux server administration basics
* Docker and Docker Compose
* Networking fundamentals (ports, DNS, firewalls)
If you're new to these topics, consider starting with the managed [Supabase platform](/dashboard) for free.
You need the following installed on your system:
* [Git](https://git-scm.com/downloads)
* [Docker](https://docs.docker.com/manuals/):
* **Linux server/VPS**: Install [Docker Engine](https://docs.docker.com/engine/install/) and [Docker Compose](https://docs.docker.com/compose/install/)
* **Linux desktop**: Install [Docker Desktop](https://docs.docker.com/desktop/setup/install/linux/)
* **macOS**: Install [Docker Desktop](https://docs.docker.com/desktop/install/mac-install/)
* **Windows**: Install [Docker Desktop](https://docs.docker.com/desktop/install/windows-install/)
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* OpenSSL
## System requirements
Minimum requirements for running all Supabase components, suitable for development and small to medium production workloads:
| Resource | Minimum | Recommended |
| -------- | --------- | ----------- |
| RAM | 4 GB | 8 GB+ |
| CPU | 2 cores | 4 cores+ |
| Disk | 50 GB SSD | 80 GB+ SSD |
If you don't need specific services, such as Logflare (Analytics), Realtime, Storage, imgproxy, or Edge Runtime (Functions), you can remove the corresponding sections and dependencies from `docker-compose.yml` to reduce resource requirements.
## Installing Supabase
Follow these steps to start Supabase on your machine:
```sh
# Get the code
git clone --depth 1 https://github.com/supabase/supabase
# Make your new supabase project directory
mkdir supabase-project
# Tree should look like this
# .
# ├── supabase
# └── supabase-project
# Copy the compose files over to your project
cp -rf supabase/docker/* supabase-project
# Copy the fake env vars
cp supabase/docker/.env.example supabase-project/.env
# Switch to your project directory
cd supabase-project
# Pull the latest images
docker compose pull
```
```sh
# Get the code using git sparse checkout
git clone --filter=blob:none --no-checkout --depth=1 --quiet https://github.com/supabase/supabase
cd supabase
git sparse-checkout init --cone
git sparse-checkout set docker
git checkout --quiet
cd ..
# Make your new supabase project directory
mkdir supabase-project
# Tree should look like this
# .
# ├── supabase
# └── supabase-project
# Copy the compose files over to your project
cp -rf supabase/docker/* supabase-project
# Copy the fake env vars
cp supabase/docker/.env.example supabase-project/.env
# Switch to your project directory
cd supabase-project
# Pull the latest images
docker compose pull
```
If you are using rootless Docker, edit `.env` and set `DOCKER_SOCKET_LOCATION` to your docker socket location. For example: `/run/user/1000/docker.sock`. Otherwise, you will see an error like `container supabase-vector exited (0)`.
## Configuring and securing Supabase
While we provided example placeholder passwords and keys in the `.env.example` file, you should NEVER start your self-hosted Supabase using these defaults.
Review the configuration steps below and ensure you set all secrets properly before starting the services.
### Quick setup
To generate secure passwords and secrets, run:
```sh
sh utils/generate-keys.sh
```
As the **next step**, use the following script to add the new API keys and asymmetric key pair:
```sh
sh utils/add-new-auth-keys.sh
```
Review the output of both scripts and check the `.env` file **before proceeding** to configure [Supabase URLs](#configure-supabase-urls).
For a description of all secrets refer to the [related section](#configuring-secrets) in the "Advanced topics" below. If you'd like to learn more about how the new API keys and asymmetric JWT signing work in a self-hosted Supabase setup, make sure to read the detailed [how-to guide](/docs/guides/self-hosting/self-hosted-auth-keys).
### Configure Supabase URLs
Review and change URL configuration variables:
* `SUPABASE_PUBLIC_URL`: base URL for accessing Supabase from the Internet (Dashboard, API, Storage, etc.), e.g., `http://example.com:8000`
* `API_EXTERNAL_URL`: used by the Auth service to configure callback URLs, e.g., `http://example.com:8000`
* `SITE_URL`: default [redirect URL](/docs/guides/auth/redirect-urls) for Auth, e.g., `http://example.com:3000`
Throughout the self-hosting guides, `` stands for the host where your Supabase instance is reachable: your domain name, your server's IP, or `localhost`, depending on your setup.
* **Default setup:** The API gateway (Kong) listens on port `8000`, so the full URL is `http://:8000`.
* **Behind a [reverse proxy](/docs/guides/self-hosting/self-hosted-proxy-https):** the proxy terminates TLS on port `443`, so the URL becomes `https://`.
### Where to find your credentials
The generated secrets and password are written to the `.env` file. The ones you are most likely to need when connecting your application to self-hosted Supabase are:
* `POSTGRES_PASSWORD`: database password used in Postgres connection strings and by `psql`
* `SUPABASE_PUBLISHABLE_KEY`: publishable API key for client-side use (e.g., in your frontend)
* `SUPABASE_SECRET_KEY`: secret API key for server-side use. Never expose this in client code
* `SUPABASE_PUBLIC_URL`: base URL you pass as `supabaseUrl` to the client libraries
If you are still using the [legacy API keys](#configuring-legacy-api-keys), look for `ANON_KEY` and `SERVICE_ROLE_KEY` instead of the new publishable and secret API keys above.
### Studio authentication
Access to Studio (Dashboard) is protected with **HTTP basic authentication**.
A secure password MUST be set before starting Supabase. The password must include at least one letter - do not use numbers only or any special characters.
In the `.env` file, edit `DASHBOARD_PASSWORD` to change the password, and optionally `DASHBOARD_USERNAME` to change the username.
## Starting and stopping
You can start Supabase by using the following command in the same directory as your `docker-compose.yml` file:
```sh
docker compose up -d
```
Check the status of the services:
```sh
docker compose ps
```
After a minute or less, all services should have a status `Up [...] (healthy)`. If you see a status such as `created` but not `Up`, run the test script to determine what the problem might be:
```sh
sh tests/test-container-logs.sh
```
Then try inspecting the Docker logs for a specific container, e.g.,
```sh
docker compose logs analytics
```
To stop Supabase, use:
```sh
docker compose down
```
If the API gateway (Kong) fails to start with an entrypoint error, your local files may have been checked out with CRLF line endings instead of LF. Re-clone the repository, or normalize everything in the `docker/` directory to LF, then restart Supabase. Fresh clones should already use LF because of `.gitattributes`.
## Accessing Supabase Studio (Dashboard)
By default, you can access the dashboard through the API gateway on port `8000`.
For example: `http://:8000`, or `http://:8000` (or `localhost:8000` if you are running Docker Compose locally).
You will be prompted for a username and password. See the [Studio authentication](#studio-authentication) section for details.
## Accessing Postgres
The self-hosted Supabase stack provides the [Supavisor](https://supabase.github.io/supavisor/development/docs/) connection pooler for accessing Postgres and managing database connections.
You can connect to the Postgres database via Supavisor using the methods described below. Use your domain name, your server IP, or `localhost` depending on whether you are running self-hosted Supabase on a VPS, or locally.
The default POOLER\_TENANT\_ID is `your-tenant-id` (can be changed in `.env`), and the password is the one you set previously in [Configure database password](#configure-database-password).
For session-based connections (equivalent to a direct Postgres connection):
```sh
psql 'postgres://postgres.[POOLER_TENANT_ID]:[POSTGRES_PASSWORD]@[your-domain]:5432/postgres'
```
For pooled transactional connections:
```sh
psql 'postgres://postgres.[POOLER_TENANT_ID]:[POSTGRES_PASSWORD]@[your-domain]:6543/postgres'
```
When using `psql` with command-line parameters instead of a connection string to connect to Supavisor, the `-U` parameter should also be `postgres.[POOLER_TENANT_ID]`, and not just `postgres`.
If you need to configure Postgres to be directly accessible from the Internet, read [Exposing your Postgres database](#exposing-your-postgres-database).
To change the database password, read [Changing database password](#changing-database-password).
## Accessing Edge Functions
Edge Functions live in `volumes/functions`. The default setup includes a `hello` function you can invoke with `curl`:
```sh
curl http://:8000/functions/v1/hello
```
Add new functions at `volumes/functions//index.ts`, then restart the service to pick them up:
```sh
docker compose restart functions --no-deps
```
See the [self-hosted Edge Functions guide](/docs/guides/self-hosting/self-hosted-functions) for more details.
## Accessing APIs
Each of the APIs is available through the same API gateway:
* REST: `http://:8000/rest/v1/`
* Auth: `http://:8000/auth/v1/`
* Storage: `http://:8000/storage/v1/`
* Realtime: `http://:8000/realtime/v1/`
## Configuring HTTPS
By default, Supabase is accessible over HTTP. For production deployments, especially when using OAuth providers, you need HTTPS with a valid TLS certificate. The recommended approach is to place a reverse proxy (such as Caddy or Nginx) in front of the API gateway.
See the [Configure HTTPS](/docs/guides/self-hosting/self-hosted-proxy-https) guide for detailed setup instructions.
## Updating
We publish stable releases of the Docker Compose setup approximately once a month. The versions in each release are tested together, so they may lag behind the latest images on Docker Hub. To update, apply the latest changes from the repository and restart the services. If you want to run different versions of individual services, you can change the image tags in the Docker Compose file, but compatibility is **not guaranteed**. All Supabase images are available on [Docker Hub](https://hub.docker.com/u/supabase).
To follow the changes and updates, refer to the self-hosted Supabase [changelog](https://github.com/supabase/supabase/blob/master/docker/CHANGELOG.md).
You need to restart services to pick up the changes, which may result in downtime for your applications and users.
**Example:**
You'd like to update or rollback the Studio image. Follow the steps below:
1. Check the [supabase/studio](https://hub.docker.com/r/supabase/studio/tags) images on [Supabase Docker Hub](https://hub.docker.com/u/supabase)
2. Find the latest version (tag) number. It looks something like `2025.11.26-sha-8f096b5`
3. Update the `image` field in the `docker-compose.yml` file. It should look like this: `image: supabase/studio:2025.11.26-sha-8f096b5`
4. Run `docker compose pull`, followed by `docker compose down && docker compose up -d` to restart Supabase.
## Uninstalling
Be careful — the following destroys all data, including the database and storage volumes!
To uninstall, stop Supabase (while in the same directory as your `docker-compose.yml` file).
Stop the containers and remove volumes:
```sh
docker compose down -v
```
Optionally, ensure removal of all Postgres data:
```sh
rm -rf volumes/db/data
```
and all Storage data:
```sh
rm -rf volumes/storage
```
## Advanced topics
Everything beyond this point in the guide helps you understand how the system works and how you can modify it to suit your needs.
### Architecture
Supabase is built from open source tools, each chosen or developed for production use.
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
If the tools and communities already exist, with an MIT, Apache 2, PostgreSQL, or equivalent open source license, we will use and support that tool. If the tool doesn't exist, we build and open source it ourselves.
* **[Studio](https://github.com/supabase/supabase/tree/master/apps/studio)** - A dashboard for managing your self-hosted Supabase project
* **[Kong](https://github.com/Kong/kong)** - Kong API gateway
* **[Auth](https://github.com/supabase/auth)** - JWT-based authentication API for user sign-ups, logins, and session management
* **[PostgREST](https://github.com/PostgREST/postgrest)** - Web server that turns your Postgres database directly into a RESTful API
* **[Realtime](https://github.com/supabase/realtime)** - Elixir server that listens to Postgres database changes and broadcasts them to subscribed clients
* **[Storage](https://github.com/supabase/storage)** - RESTful API for managing files in S3, with Postgres handling permissions
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* **[imgproxy](https://github.com/imgproxy/imgproxy)** - Fast and secure image processing server
* **[postgres-meta](https://github.com/supabase/postgres-meta)** - RESTful API for managing Postgres (fetch tables, add roles, run queries)
* **[Postgres](https://github.com/supabase/postgres)** - Object-relational database with over 30 years of active development
* **[Edge Runtime](https://github.com/supabase/edge-runtime)** - Web server based on Deno runtime for running JavaScript, TypeScript, and WASM services
* **[Logflare](https://github.com/Logflare/logflare)** - Log management and event analytics platform
* **[Vector](https://github.com/vectordotdev/vector)** - High-performance observability data pipeline for logs
* **[Supavisor](https://github.com/supabase/supavisor)** - Supabase's Postgres connection pooler
Multiple services require specific configuration within the Postgres database. Refer to the documentation describing the [default roles](/docs/guides/database/postgres/roles#supabase-roles) to learn more.
You can find all the default extensions inside the [schema migration scripts repo](https://github.com/supabase/postgres/tree/develop/migrations). These scripts are mounted at `/docker-entrypoint-initdb.d` to run automatically when starting the Postgres container.
### Setting database password
The `generate-keys.sh` script creates a secure random database password. If you want to use your own, you can change `POSTGRES_PASSWORD` in the `.env` file **before** starting Supabase for the first time.
Follow the [password guidelines](/docs/guides/database/postgres/roles#passwords) for choosing a secure password. For easier configuration, **use only letters and numbers** to avoid URL encoding issues in connection strings.
### Changing database password
To change the database password after the initial setup, run:
```sh
sh utils/db-passwd.sh
```
The script generates a new password, updates all database roles, and modifies your `.env` file. After running it, restart the services with `docker compose up -d --force-recreate`.
### Configuring legacy API keys
Use the key generator below to obtain and configure the following secure keys in `.env`:
* `JWT_SECRET`: Used by Auth, PostgREST, and other services to sign and verify JWTs.
* `ANON_KEY`: Client-side API key with limited permissions (`anon` role). Use this in your frontend applications.
* `SERVICE_ROLE_KEY`: Server-side API key with full database access (`service_role` role). **Never expose this in client code.**
1. Copy the generated value and update `JWT_SECRET` in the `.env` file. Do not share this secret publicly or commit it to version control.
2. Copy the generated value and update `ANON_KEY` in the `.env` file.
3. Copy the generated value and update `SERVICE_ROLE_KEY` in the `.env` file.
The generated keys expire in 5 years. You can verify them at [jwt.io](https://jwt.io) using the saved value of `JWT_SECRET`.
### Configuring secrets
The `generate-keys.sh` script sets the following secrets automatically. You can also configure them manually in the `.env` file if needed:
* `SECRET_KEY_BASE`: encryption key for securing Realtime and Supavisor communications. (Must be at least 64 characters; generate with `openssl rand -base64 48`)
* `VAULT_ENC_KEY`: encryption key used by Supavisor for storing encrypted configuration. (Must be exactly 32 characters; generate with `openssl rand -hex 16`)
* `PG_META_CRYPTO_KEY`: encryption key for securing connection strings used by Studio against postgres-meta. (Must be at least 32 characters; generate with `openssl rand -base64 24`)
* `LOGFLARE_PUBLIC_ACCESS_TOKEN`: API token for log ingestion and querying. Used by Vector and Studio to send and query logs. (Must be at least 32 characters; generate with `openssl rand -base64 24`)
* `LOGFLARE_PRIVATE_ACCESS_TOKEN`: API token for Logflare management operations. Used by Studio for administrative tasks. Never expose client-side. (Must be at least 32 characters; generate with `openssl rand -base64 24`)
* `S3_PROTOCOL_ACCESS_KEY_ID`: Access key ID (username-like) for [accessing](/docs/guides/self-hosting/self-hosted-s3) the S3 protocol endpoint in Storage. (Generate with `openssl rand -hex 16`)
* `S3_PROTOCOL_ACCESS_KEY_SECRET`: Secret key (password-like) used with S3\_PROTOCOL\_ACCESS\_KEY\_ID. (Generate with `openssl rand -hex 32`)
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* `MINIO_ROOT_PASSWORD`: Root administrator password for the [MinIO server](/docs/guides/self-hosting/self-hosted-s3#using-minio). (Must be 8+ characters; generate with `openssl rand -hex 16`)
### Configuring Supabase services
Each service has a number of configuration options you can find in the related documentation.
Configuration options are generally added to the `.env` file and referenced in `docker-compose.yml` service definitions, e.g.,
```yml name=docker-compose.yml
services:
rest:
image: postgrest/postgrest
environment:
PGRST_JWT_SECRET: ${JWT_SECRET}
```
```sh name=.env
## Never check your secrets into version control
JWT_SECRET=${JWT_SECRET}
```
### Configuring social login (OAuth) providers
See the [Configure Social Login (OAuth) Providers](/docs/guides/self-hosting/self-hosted-oauth) guide for setup instructions.
### Configuring phone login, SMS, and MFA
See the [Configure Phone Login & MFA](/docs/guides/self-hosting/self-hosted-phone-mfa) guide for SMS provider setup, OTP settings, and multi-factor authentication configuration.
### Configuring an email server
You will need to use a production-ready SMTP server for sending emails. You can configure the SMTP server by updating the following environment variables in the `.env` file:
```sh name=.env
SMTP_ADMIN_EMAIL=
SMTP_HOST=
SMTP_PORT=
SMTP_USER=
SMTP_PASS=
SMTP_SENDER_NAME=
```
We recommend using [AWS SES](https://aws.amazon.com/ses/). It's affordable and reliable. Restart all services to pick up the new configuration.
### Configuring S3 Storage
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
By default, all files are stored locally on the server. You can connect Storage to an S3-compatible backend (AWS S3, RustFS, MinIO, Cloudflare R2), enable the S3 protocol endpoint for tools like `rclone`, or both. These are independent features.
See the [Configure S3 Storage](/docs/guides/self-hosting/self-hosted-s3) guide for detailed setup instructions.
### Configuring Supabase AI Assistant
Configuring the Supabase AI Assistant is optional. By adding **your own** `OPENAI_API_KEY` to `.env` you can enable AI services, which help with writing SQL queries, statements, and policies.
### Accessing Postgres through Supavisor
By default, Postgres connections go through the Supavisor connection pooler for efficient connection management. Two ports are available:
* `POSTGRES_PORT` (default: 5432) - Session mode, behaves like a direct Postgres connection
* `POOLER_PROXY_PORT_TRANSACTION` (default: 6543) - Transaction mode, uses connection pooling
For more information on configuring and using Supavisor, see the [Supavisor documentation](https://supabase.github.io/supavisor/).
### Exposing your Postgres database
By default, Postgres is only accessible through Supavisor. If you need direct access to the database (bypassing the connection pooler), you need to disable Supavisor and expose the Postgres port.
Exposing Postgres directly bypasses connection pooling and exposes your database to the network. Configure firewall rules or network policies to restrict access to trusted IPs only.
Edit `docker-compose.yml`:
1. **Disable Supavisor** - Comment out or remove the entire `supavisor` service section
2. **Expose Postgres port** - Add the port mapping to the `db` service, it should look like the example below:
```yaml name=docker-compose.yml
db:
ports:
- ${POSTGRES_PORT}:${POSTGRES_PORT}
container_name: supabase-db
```
After restarting, you can connect to the database directly using a standard Postgres connection string:
```sh
postgres://postgres:[POSTGRES_PASSWORD]@[your-server-ip]:5432/[POSTGRES_DB]
```
### Setting log\_min\_messages in Postgres
By default, the database's `log_min_messages` configuration is set to `fatal` in [docker-compose.yml](https://github.com/supabase/supabase/blob/df8729a82b1847e2989c14ede27965612761d503/docker/docker-compose.yml#L466) to prevent redundant logs generated by Realtime. You can configure `log_min_messages` using any of the Postgres [Severity Levels](https://www.postgresql.org/docs/current/runtime-config-logging.html#RUNTIME-CONFIG-SEVERITY-LEVELS).
### Using file backend in Storage on macOS
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
By default, the Storage backend uses local files via a bind mount. On macOS, Docker Desktop bind mounts have known limitations (missing xattr support, permission issues) that can prevent Storage from working correctly. Change the [bind mount](https://github.com/supabase/supabase/blob/a5f4a59e0e262394b345600e8d8a2241d6ac3b64/docker/docker-compose.yml#L391) to a named Docker volume instead.
## Managing your secrets
Many components inside Supabase rely on secrets and passwords being kept securely. By default, all secrets are in the `.env` file, but we strongly recommend using a secrets manager when deploying to production.
Some suggested systems include:
* [Doppler](https://www.doppler.com/)
* [Infisical](https://infisical.com/)
* [Key Vault](https://docs.microsoft.com/en-us/azure/key-vault/general/overview) by Azure (Microsoft)
* [Secrets Manager](https://aws.amazon.com/secrets-manager/) by AWS
* [Secrets Manager](https://cloud.google.com/secret-manager) by GCP
* [Vault](https://www.hashicorp.com/products/vault) by HashiCorp
***
## Demo
## Next steps
Once you've created your analytics bucket, you can:
* [Connect with Iceberg clients](/docs/guides/storage/analytics/connecting-to-analytics-bucket) like PyIceberg or Apache Spark
* [Query data with Postgres](/docs/guides/storage/analytics/query-with-postgres) using the Iceberg Foreign Data Wrapper
# Analytics Buckets
Store large datasets for analytics and reporting.
Expect rapid changes, limited features, and possible breaking updates. [share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Analytics buckets enable analytical workflows on large-scale datasets while keeping your primary database optimized for transactional operations.
## Why Analytics buckets?
Postgres tables are purpose-built for transactional workloads with frequent inserts, updates, deletes, and low-latency queries. Analytical workloads have fundamentally different requirements:
* Processing large volumes of historical data
* Running complex queries and aggregations
* Minimizing storage costs
* Preventing analytical queries from impacting production traffic
Analytics buckets address these requirements using [Apache Iceberg](https://iceberg.apache.org/), an open-table format specifically designed for efficient management of large analytical datasets.
## Ideal use cases
Analytics buckets are perfect for:
* **Data warehousing and business intelligence** - Build scalable data warehouses for BI tools
* **Historical data archiving** - Retain large volumes of historical data cost-effectively
* **Periodically refreshed analytics** - Maintain near real-time analytical views
* **Complex analytical queries** - Execute sophisticated aggregations and joins over large datasets
By separating transactional and analytical workloads, Supabase lets you build scalable analytics pipelines without compromising your primary Postgres performance.
# Analytics Buckets Limits
Expect rapid changes, limited features, and possible breaking updates. [share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
The following default limits are applied when this feature is in the alpha stage, they can be adjusted on a case-by-case basis:
| **Category** | **Limit** |
| --------------------------------------- | --------- |
| Number of analytics buckets per project | 2 |
| Number of namespaces per bucket | 10 |
| Number of tables per namespace | 10 |
# Analytics Buckets Pricing
Expect rapid changes, limited features, and possible breaking updates. [share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Analytics buckets are **free** to use during the alpha phase. You will still be charged for the underlying egress.
# Query with Postgres
Query analytics bucket data directly from Postgres using SQL.
Once your data flows into an analytics bucket through your own ingestion pipeline, you can query it directly from Postgres using standard SQL.
This is made possible by the [Iceberg Foreign Data Wrapper](/docs/guides/database/extensions/wrappers/iceberg), which creates a bridge between your Postgres database and Iceberg tables.
Managed replication into Analytics Buckets through Supabase ETL is no longer supported. This guide assumes your Analytics Bucket is being populated by your own ingestion pipeline.
## Setup overview
You have two options to enable querying:
1. **Dashboard UI** (recommended) - Streamlined setup through the Supabase Dashboard
2. **Manual installation** - Install the wrapper using SQL and configuration
## Installing via Dashboard UI
The dashboard provides the easiest setup experience:
1. Navigate to your **Analytics Bucket** page in the Supabase Dashboard.
2. Locate the namespace you want to query and click **Query with Postgres**.
3. Enter the **Postgres schema** where you want to create the foreign tables.
4. Click **Connect**. The wrapper is now configured.
## Querying your data
Once the foreign data wrapper is installed, you can query your Iceberg tables using standard SQL:
```sql
select *
from schema_name.table_name
limit 100;
```
### Common query examples
Get the latest events:
```sql
select event_id, event_name, event_timestamp
from analytics.events
order by event_timestamp desc
limit 1000;
```
Join with transactional data:
```sql
SELECT
e.event_id,
e.event_name,
u.user_email
FROM analytics.events e
JOIN public.users u ON e.user_id = u.id
WHERE e.event_timestamp > NOW() - INTERVAL '7 days'
LIMIT 100;
```
## Manual installation
For advanced use cases, you can manually install and configure the Iceberg Foreign Data Wrapper. See the [Iceberg Foreign Data Wrapper documentation](/docs/guides/database/extensions/wrappers/iceberg) for detailed instructions.
# Apache Spark
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
Apache Spark enables distributed analytical processing of large datasets stored in your analytics buckets. Use it for complex transformations, aggregations, and machine learning workflows.
## Installation
First, ensure you have Spark installed. For Python-based workflows:
```bash
pip install pyspark
```
For detailed Spark setup instructions, see the [Apache Spark documentation](https://spark.apache.org/docs/latest/).
## Basic setup
Here's a complete example showing how to configure Spark with your Supabase analytics bucket:
```python
from pyspark.sql import SparkSession
# Configuration - Update with your Supabase credentials
PROJECT_REF = "your-project-ref"
WAREHOUSE = "your-analytics-bucket-name"
SERVICE_KEY = "your-service-key"
# S3 credentials from Project Settings > Storage
S3_ACCESS_KEY = "your-access-key"
S3_SECRET_KEY = "your-secret-key"
S3_REGION = "us-east-1"
# Construct Supabase endpoints
S3_ENDPOINT = f"https://{PROJECT_REF}.supabase.co/storage/v1/s3"
CATALOG_URI = f"https://{PROJECT_REF}.supabase.co/storage/v1/iceberg"
# Initialize Spark session with Iceberg configuration
spark = SparkSession.builder \
.master("local[*]") \
.appName("SupabaseIceberg") \
.config("spark.driver.host", "127.0.0.1") \
.config("spark.driver.bindAddress", "127.0.0.1") \
.config(
'spark.jars.packages',
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1,org.apache.iceberg:iceberg-aws-bundle:1.6.1'
) \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.supabase", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.supabase.type", "rest") \
.config("spark.sql.catalog.supabase.uri", CATALOG_URI) \
.config("spark.sql.catalog.supabase.warehouse", WAREHOUSE) \
.config("spark.sql.catalog.supabase.token", SERVICE_KEY) \
.config("spark.sql.catalog.supabase.s3.endpoint", S3_ENDPOINT) \
.config("spark.sql.catalog.supabase.s3.path-style-access", "true") \
.config("spark.sql.catalog.supabase.s3.access-key-id", S3_ACCESS_KEY) \
.config("spark.sql.catalog.supabase.s3.secret-access-key", S3_SECRET_KEY) \
.config("spark.sql.catalog.supabase.s3.remote-signing-enabled", "false") \
.config("spark.sql.defaultCatalog", "supabase") \
.getOrCreate()
print("✓ Spark session initialized with Iceberg")
```
## Creating tables
```python
# Create a namespace for organization
spark.sql("CREATE NAMESPACE IF NOT EXISTS analytics")
# Create a new Iceberg table
spark.sql("""
CREATE TABLE IF NOT EXISTS analytics.events (
event_id BIGINT,
user_id BIGINT,
event_name STRING,
event_timestamp TIMESTAMP,
properties STRING
)
USING iceberg
""")
print("✓ Created table: analytics.events")
```
## Writing data
```python
# Insert data into the table
spark.sql("""
INSERT INTO analytics.events (event_id, user_id, event_name, event_timestamp, properties)
VALUES
(1, 101, 'login', TIMESTAMP '2024-01-15 10:30:00', '{"browser":"chrome"}'),
(2, 102, 'view_product', TIMESTAMP '2024-01-15 10:35:00', '{"product_id":"123"}'),
(3, 101, 'logout', TIMESTAMP '2024-01-15 10:40:00', '{}'),
(4, 103, 'purchase', TIMESTAMP '2024-01-15 10:45:00', '{"amount":99.99}')
""")
print("✓ Inserted 4 rows into analytics.events")
```
## Reading data
```python
# Read the entire table
result_df = spark.sql("SELECT * FROM analytics.events")
result_df.show(truncate=False)
# Apply filters
filtered_df = spark.sql("""
SELECT event_id, user_id, event_name
FROM analytics.events
WHERE event_name = 'login'
""")
filtered_df.show()
# Aggregations
summary_df = spark.sql("""
SELECT
event_name,
COUNT(*) as event_count,
COUNT(DISTINCT user_id) as unique_users
FROM analytics.events
GROUP BY event_name
ORDER BY event_count DESC
""")
summary_df.show()
```
## Advanced operations
### Working with dataframes
```python
# Read as DataFrame
events_df = spark.read.format("iceberg").load("analytics.events")
# Apply Spark transformations
from pyspark.sql.functions import count, col, year, month
# Monthly event counts
monthly_events = events_df \
.withColumn("month", month(col("event_timestamp"))) \
.withColumn("year", year(col("event_timestamp"))) \
.groupBy("year", "month", "event_name") \
.agg(count("event_id").alias("count")) \
.orderBy("year", "month")
monthly_events.show()
```
### Joining tables
```python
# Create another table
spark.sql("""
CREATE TABLE IF NOT EXISTS analytics.users (
user_id BIGINT,
username STRING,
email STRING
)
USING iceberg
""")
spark.sql("""
INSERT INTO analytics.users VALUES
(101, 'alice', 'alice@example.com'),
(102, 'bob', 'bob@example.com'),
(103, 'charlie', 'charlie@example.com')
""")
# Join events with users
joined_df = spark.sql("""
SELECT
e.event_id,
e.event_name,
u.username,
u.email,
e.event_timestamp
FROM analytics.events e
JOIN analytics.users u ON e.user_id = u.user_id
ORDER BY e.event_timestamp
""")
joined_df.show(truncate=False)
```
### Exporting results
```python
# Export to Parquet
spark.sql("""
SELECT event_name, COUNT(*) as count
FROM analytics.events
GROUP BY event_name
""").write \
.mode("overwrite") \
.parquet("/tmp/event_summary.parquet")
# Export to CSV
spark.sql("""
SELECT *
FROM analytics.events
WHERE event_timestamp > TIMESTAMP '2024-01-15 10:30:00'
""").write \
.mode("overwrite") \
.option("header", "true") \
.csv("/tmp/recent_events.csv")
print("✓ Results exported")
```
## Performance best practices
* **Partition tables** - Partition large tables by date or region for faster queries
* **Select columns** - Only select columns you need to reduce I/O
* **Use filters early** - Apply WHERE clauses to reduce data processed
* **Cache frequently accessed tables** - Use `spark.catalog.cacheTable()` for tables accessed multiple times
* **Cluster mode** - Use cluster mode for production workloads instead of local mode
## Complete example: Data processing pipeline
```python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, year, month, count
# Setup (see Basic Setup section above)
spark = SparkSession.builder \
.master("local[*]") \
.appName("SupabaseAnalytics") \
.config("spark.sql.defaultCatalog", "supabase") \
# ... (add all config from Basic Setup)
.getOrCreate()
# Step 1: Read raw events
raw_events = spark.sql("SELECT * FROM analytics.events")
# Step 2: Transform and aggregate
monthly_summary = raw_events \
.withColumn("month", month(col("event_timestamp"))) \
.withColumn("year", year(col("event_timestamp"))) \
.groupBy("year", "month", "event_name") \
.agg(count("event_id").alias("total_events"))
# Step 3: Save results
monthly_summary.write \
.mode("overwrite") \
.option("path", "analytics.monthly_summary") \
.saveAsTable("analytics.monthly_summary")
print("✓ Pipeline completed")
monthly_summary.show()
```
## Next steps
* [Query with Postgres](/docs/guides/storage/analytics/query-with-postgres)
* [Connect with PyIceberg](/docs/guides/storage/analytics/examples/pyiceberg)
* [Explore with DuckDB](/docs/guides/storage/analytics/examples/duckdb)
# DuckDB
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
DuckDB is a high-performance SQL database system optimized for analytical workloads. It can directly query Iceberg tables stored in your analytics buckets, making it ideal for data exploration and complex analytical queries.
## Installation
Install DuckDB and the Iceberg extension:
```bash
pip install duckdb duckdb-iceberg
```
## Connecting to Analytics buckets
Here's a complete example of connecting to your Supabase analytics bucket and querying Iceberg tables:
```python
import duckdb
import os
# Configuration
PROJECT_REF = "your-project-ref"
WAREHOUSE = "your-analytics-bucket-name"
SERVICE_KEY = "your-service-key"
# S3 credentials
S3_ACCESS_KEY = "your-access-key"
S3_SECRET_KEY = "your-secret-key"
S3_REGION = "us-east-1"
# Construct endpoints
S3_ENDPOINT = f"https://{PROJECT_REF}.supabase.co/storage/v1/s3"
CATALOG_URI = f"https://{PROJECT_REF}.supabase.co/storage/v1/iceberg"
# Initialize DuckDB connection
conn = duckdb.connect(":memory:")
# Install and load the Iceberg extension
conn.install_extension("iceberg")
conn.load_extension("iceberg")
# Configure Iceberg catalog with Supabase credentials
conn.execute(f"""
CREATE SECRET (
TYPE S3,
KEY_ID '{S3_ACCESS_KEY}',
SECRET '{S3_SECRET_KEY}',
REGION '{S3_REGION}',
ENDPOINT '{S3_ENDPOINT}',
URL_STYLE 'virtual'
);
""")
# Configure the REST catalog
conn.execute(f"""
ATTACH 'iceberg://{CATALOG_URI}' AS iceberg_catalog
(
TYPE ICEBERG_REST,
WAREHOUSE '{WAREHOUSE}',
TOKEN '{SERVICE_KEY}'
);
""")
# Query your Iceberg tables
result = conn.execute("""
SELECT *
FROM iceberg_catalog.default.events
LIMIT 10
""").fetchall()
for row in result:
print(row)
# Complex aggregation example
analytics = conn.execute("""
SELECT
event_name,
COUNT(*) as event_count,
COUNT(DISTINCT user_id) as unique_users
FROM iceberg_catalog.default.events
GROUP BY event_name
ORDER BY event_count DESC
""").fetchdf()
print(analytics)
```
## Key features with DuckDB
### Efficient data exploration
DuckDB's lazy evaluation means it only scans the data you need:
```python
# This only reads the columns you select
events = conn.execute("""
SELECT event_id, event_name, event_timestamp
FROM iceberg_catalog.default.events
WHERE event_timestamp > NOW() - INTERVAL '7 days'
""").fetchdf()
```
### Converting to Pandas
Convert results to Pandas DataFrames for further analysis:
```python
df = conn.execute("""
SELECT *
FROM iceberg_catalog.default.events
""").fetchdf()
# Use pandas for visualization or further processing
print(df.describe())
```
### Exporting results
Save your analytical results to various formats:
```python
# Export to Parquet
conn.execute("""
COPY (
SELECT * FROM iceberg_catalog.default.events
) TO 'results.parquet'
""")
# Export to CSV
conn.execute("""
COPY (
SELECT event_name, COUNT(*) as count
FROM iceberg_catalog.default.events
GROUP BY event_name
) TO 'summary.csv' (FORMAT CSV, HEADER true)
""")
```
## Best practices
* **Connection pooling** - Reuse connections for multiple queries
* **Partition pruning** - Filter by partition columns to improve query performance
* **Column selection** - Only select columns you need to reduce I/O
* **Limit results** - Use LIMIT during exploration to avoid processing large datasets
## Next steps
* [Query with Postgres](/docs/guides/storage/analytics/query-with-postgres)
* [Connect with PyIceberg](/docs/guides/storage/analytics/examples/pyiceberg)
* [Analyze with Apache Spark](/docs/guides/storage/analytics/examples/apache-spark)
# PyIceberg
Expect rapid changes, limited features, and possible breaking updates. [Share feedback](https://github.com/orgs/supabase/discussions/40116) as we refine the experience and expand access.
PyIceberg is a Python client for Apache Iceberg that enables programmatic interaction with Iceberg tables. Use it to create, read, update, and delete data in your analytics buckets.
## Installation
```bash
pip install pyiceberg pyarrow
```
## Basic setup
Here's a complete example showing how to connect to your Supabase analytics bucket and perform operations:
```python
from pyiceberg.catalog import load_catalog
import pyarrow as pa
import datetime
# Configuration - Update with your Supabase credentials
PROJECT_REF = "your-project-ref"
WAREHOUSE = "your-analytics-bucket-name"
SERVICE_KEY = "your-service-key"
# S3 credentials from Project Settings > Storage
S3_ACCESS_KEY = "your-access-key"
S3_SECRET_KEY = "your-secret-key"
S3_REGION = "us-east-1"
# Construct Supabase endpoints
S3_ENDPOINT = f"https://{PROJECT_REF}.supabase.co/storage/v1/s3"
CATALOG_URI = f"https://{PROJECT_REF}.supabase.co/storage/v1/iceberg"
# Load the Iceberg REST Catalog
catalog = load_catalog(
"supabase-analytics",
type="rest",
warehouse=WAREHOUSE,
uri=CATALOG_URI,
token=SERVICE_KEY,
**{
"py-io-impl": "pyiceberg.io.pyarrow.PyArrowFileIO",
"s3.endpoint": S3_ENDPOINT,
"s3.access-key-id": S3_ACCESS_KEY,
"s3.secret-access-key": S3_SECRET_KEY,
"s3.region": S3_REGION,
"s3.force-virtual-addressing": False,
},
)
print("✓ Successfully connected to Iceberg catalog")
```
## Creating tables
```python
# Create a namespace for organization
catalog.create_namespace_if_not_exists("analytics")
# Define the schema for your Iceberg table
schema = pa.schema([
pa.field("event_id", pa.int64()),
pa.field("user_id", pa.int64()),
pa.field("event_name", pa.string()),
pa.field("event_timestamp", pa.timestamp("ms")),
pa.field("properties", pa.string()),
])
# Create the table
table = catalog.create_table_if_not_exists(
("analytics", "events"),
schema=schema
)
print("✓ Created table: analytics.events")
```
## Writing data
```python
import datetime
# Prepare your data
current_time = datetime.datetime.now()
data = pa.table({
"event_id": [1, 2, 3, 4, 5],
"user_id": [101, 102, 101, 103, 102],
"event_name": ["login", "view_product", "logout", "purchase", "login"],
"event_timestamp": [current_time] * 5,
"properties": [
'{"browser":"chrome"}',
'{"product_id":"123"}',
'{}',
'{"amount":99.99}',
'{"browser":"firefox"}'
],
})
# Append data to the table
table.append(data)
print("✓ Appended 5 rows to analytics.events")
```
## Reading data
```python
# Scan the entire table
scan_result = table.scan().to_pandas()
print(f"Total rows: {len(scan_result)}")
print(scan_result.head())
# Query with filters
filtered = table.scan(
filter="event_name = 'login'"
).to_pandas()
print(f"Login events: {len(filtered)}")
# Select specific columns
selected = table.scan(
selected_fields=["user_id", "event_name", "event_timestamp"]
).to_pandas()
print(selected.head())
```
## Advanced operations
### Listing tables and namespaces
```python
# List all namespaces
namespaces = catalog.list_namespaces()
print("Namespaces:", namespaces)
# List tables in a namespace
tables = catalog.list_tables("analytics")
print("Tables in analytics:", tables)
# Get table metadata
table_metadata = catalog.load_table(("analytics", "events"))
print("Schema:", table_metadata.schema())
print("Partitions:", table_metadata.partitions())
```
### Handling errors
```python
try:
# Attempt to load a table
table = catalog.load_table(("analytics", "nonexistent"))
except Exception as e:
print(f"Error loading table: {e}")
# Check if table exists before creating
namespace = "analytics"
table_name = "events"
try:
existing_table = catalog.load_table((namespace, table_name))
print(f"Table already exists")
except Exception:
print(f"Table does not exist, creating...")
table = catalog.create_table((namespace, table_name), schema=schema)
```
## Performance tips
* **Batch writes** - Insert data in batches rather than row-by-row for better performance
* **Partition strategies** - Use partitioning for large tables to improve query performance
* **Schema evolution** - PyIceberg supports schema changes without rewriting data
* **Data format** - Use Parquet for efficient columnar storage
## Complete example: ETL pipeline
```python
from pyiceberg.catalog import load_catalog
import pyarrow as pa
import pandas as pd
# Setup (see Basic Setup section above)
catalog = load_catalog(...)
# Step 1: Create analytics namespace
catalog.create_namespace_if_not_exists("warehouse")
# Step 2: Define table schema
schema = pa.schema([
pa.field("id", pa.int64()),
pa.field("name", pa.string()),
pa.field("created_at", pa.timestamp("ms")),
])
# Step 3: Create table
table = catalog.create_table_if_not_exists(
("warehouse", "products"),
schema=schema
)
# Step 4: Load data from CSV or database
df = pd.read_csv("products.csv")
data = pa.Table.from_pandas(df)
# Step 5: Write to analytics bucket
table.append(data)
print(f"✓ Loaded {len(data)} products to warehouse.products")
# Step 6: Verify
result = table.scan().to_pandas()
print(result.describe())
```
## Next steps
* [Query with Postgres](/docs/guides/storage/analytics/query-with-postgres)
* [Analyze with Apache Spark](/docs/guides/storage/analytics/examples/apache-spark)
* [Explore with DuckDB](/docs/guides/storage/analytics/examples/duckdb)
# Copy Storage Objects from Platform
Copy storage objects from a managed Supabase project to a self-hosted instance using rclone.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
This guide walks you through copying storage objects from a managed Supabase platform project to a self-hosted instance using [rclone](https://rclone.org/) with S3-to-S3 copy.
Direct file copy (e.g., downloading files and placing them into `volumes/storage/`) does not work. Self-hosted Storage uses an internal file structure that differs from what you get when downloading files from the platform. Use the S3 protocol to transfer objects so that Storage creates the correct metadata records.
## Before you begin
You need:
* A working self-hosted Supabase instance with the S3 protocol endpoint enabled - see [Configure S3 Storage](/docs/guides/self-hosting/self-hosted-s3#enable-the-s3-protocol-endpoint)
* Your platform project's S3 credentials - generated from the [S3 Configuration](/dashboard/project/_/storage/s3) page
* Matching buckets created on your self-hosted instance
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* [rclone](https://rclone.org/install/) installed on the machine running the copy
## Step 1: Get platform S3 credentials
In your managed Supabase project dashboard, go to **Storage** > **S3 Configuration** > **Access keys**. Generate a new access key pair and copy:
* **Endpoint**: `https://.supabase.co/storage/v1/s3`
* **Region**: your project's region (e.g., `us-east-1`)
* **Access Key ID** and **Secret access key**
For better performance with large files, use the direct storage hostname: `https://.storage.supabase.co/storage/v1/s3`
## Step 2: Create buckets on self-hosted
Buckets must exist on the destination before you can copy objects into them. You can create them through the dashboard UI, or with the **SQL Editor**.
If you already restored your platform database to self-hosted using the [restore guide](/docs/guides/self-hosting/restore-from-platform), your bucket definitions are already present. You can skip this step.
To list your platform buckets, connect to your platform database and run:
```sql
select id, name, public from storage.buckets order by name;
```
Then create matching buckets on your self-hosted instance. Connect to your self-hosted database and run:
```sql
insert into storage.buckets (id, name, public)
values
('your-storage-bucket', 'your-storage-bucket', false)
on conflict (id) do nothing;
```
Repeat for each bucket, setting `public` to `true` or `false` as appropriate.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
## Step 3: Configure rclone
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
Create or edit your rclone configuration file (`~/.config/rclone/rclone.conf`):
```ini rclone.conf
[platform]
type = s3
provider = Other
access_key_id = your-platform-access-key-id
secret_access_key = your-platform-secret-access-key
endpoint = https://your-project-ref.supabase.co/storage/v1/s3
region = your-project-region
[self-hosted]
type = s3
provider = Other
access_key_id = your-self-hosted-access-key-id
secret_access_key = your-self-hosted-secret-access-key
endpoint = http://your-domain:8000/storage/v1/s3
region = your-self-hosted-region
```
Replace the credentials with your actual values. For self-hosted, use the `REGION`, `S3_PROTOCOL_ACCESS_KEY_ID` and `S3_PROTOCOL_ACCESS_KEY_SECRET` you configured in [Configure S3 Storage](/docs/guides/self-hosting/self-hosted-s3#enable-the-s3-protocol-endpoint).
Verify both remotes connect:
```sh
rclone lsd platform:
rclone lsd self-hosted:
```
Both commands should list your buckets.
## Step 4: Copy objects
Copy a single bucket:
```sh
rclone copy platform:your-storage-bucket self-hosted:your-storage-bucket --progress
```
To copy all buckets:
```sh
for bucket in $(rclone lsf platform: | tr -d '/'); do
echo "Copying bucket: $bucket"
rclone copy "platform:$bucket" "self-hosted:$bucket" --progress
done
```
For large migrations, consider adding `--transfers 4` to increase parallelism, or `--checkers 8` to speed up the comparison phase. See the [flags documentation](https://rclone.org/flags/) for all options.
## Verify
Compare object counts between source and destination:
```sh
rclone size platform:your-storage-bucket && \
rclone size self-hosted:your-storage-bucket
```
Open Studio on your self-hosted instance and browse the storage buckets to confirm files are accessible.
## Troubleshooting
### Signature errors
If you see `SignatureDoesNotMatch` when connecting to either remote:
* **Platform**: Regenerate S3 access keys from your project's Storage Settings. Ensure the endpoint URL includes `/storage/v1/s3`.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* **Self-hosted**: Verify that `REGION`, `S3_PROTOCOL_ACCESS_KEY_ID` and `S3_PROTOCOL_ACCESS_KEY_SECRET` in `.env` file match your rclone config.
### Bucket not found
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
If rclone reports that a bucket doesn't exist on the self-hosted side, create it first - see [Step 2](#step-2-create-buckets-on-self-hosted). The S3 protocol does not auto-create buckets on copy.
### Timeouts on large files
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
For very large files, increase rclone's timeout:
```sh
rclone copy platform:your-storage-bucket self-hosted:your-storage-bucket --timeout 30m
```
### Empty listing on platform
If `rclone lsd platform:` returns nothing, verify the endpoint URL ends with `/storage/v1/s3` and that the S3 access keys have not expired. Regenerate them from the dashboard if needed.
# Custom Email Templates
Configure custom email templates with self-hosted Supabase instance
When running a self-hosted Supabase instance, you can fully customize emails sent by Supabase Auth.
## Overview
Supabase Auth does not read email templates from mounted Docker volumes. Instead, it expects each template to be available at a URL that returns a valid HTML template.
This URL:
* Does not need to be public
* Must be reachable from `auth` service
* Must return a valid Golang HTML template
To provide templates to Supabase Auth, you need a service that serves static HTML files. This can be any server of your choice. The only requirement is that the `auth` service must be able to reach it via a HTTP GET request.
This guide uses [Caddy](https://github.com/caddyserver/caddy) for serving templates.
If Supabase Auth cannot fetch the template or if the fetched template is invalid, it falls back to the default template.
## Authentication email templates
Authentication email templates can be configured using the following environment variables:
* `GOTRUE_MAILER_TEMPLATES_`: Provide a custom template URL. Falls back to the default template if not set.
* `GOTRUE_MAILER_SUBJECTS_`: Customize the email subject. Falls back to the default subject if not set.
| Auth flow | Sent |
| ------------------ | -------------------------------------------------------------------- |
| `CONFIRMATION` | When a user signs up and needs to verify their email address |
| `RECOVERY` | When a user requests a password reset |
| `MAGIC_LINK` | When a user requests a magic link for password-less authentication |
| `INVITE` | When a user is invited to join your application via email invitation |
| `EMAIL_CHANGE` | When a user requests to change their email address |
| `REAUTHENTICATION` | When a user needs to re-authenticate for sensitive operations |
For example:
```sh
GOTRUE_MAILER_TEMPLATES_MAGIC_LINK=''
GOTRUE_MAILER_SUBJECTS_MAGIC_LINK=''
```
### Example
Below is an example configuration for setting up a custom invite template.
### Step 1: Create a templates directory
Create a `templates` directory inside the existing `volumes` directory and add your email templates to it.
Your directory structure should look like this:
```
volumes/
templates/
invite.html
```
### Step 2: Update `docker-compose.yml`
Update the `auth` service to depend on `templates-server`, and pass the email template environment variables. Then add a `templates-server` service to serve the templates from `./volumes/templates`.
```yml name=docker-compose.yml
services:
auth:
depends_on:
db:
condition: service_healthy
templates-server: # 👈 new dependency
condition: service_started
environment:
GOTRUE_MAILER_TEMPLATES_INVITE: 'http://templates-server/invite.html'
GOTRUE_MAILER_SUBJECTS_INVITE: 'You have been invited'
templates-server:
image: caddy:2-alpine
command: ['caddy', 'file-server', '-r', '/templates', '--listen', ':80']
volumes:
- ./volumes/templates:/templates
```
#### What this configuration does
* Adds a `templates-server` service that runs alongside the Supabase services in the same docker network.
* Serves your custom email template files from the `./volumes/templates` directory.
* Keeps the templates-server private to the Docker network (no published ports), so it is not accessible from outside.
* Allows the `auth` service to fetch templates via `http://templates-server/.html`.
### Step 3: Restart containers
```sh
docker compose up -d --force-recreate --no-deps auth templates-server
```
## Notification email templates
Notification email templates can be configured using the following environment variables:
* `GOTRUE_MAILER_NOTIFICATIONS__ENABLED`: Enable the notification email
* `GOTRUE_MAILER_TEMPLATES__NOTIFICATION`: Provide a custom template URL. Falls back to the default template if not set.
* `GOTRUE_MAILER_SUBJECTS__NOTIFICATION`: Customize the email subject. Falls back to the default subject if not set.
| Notification Type | Sent |
| ----------------------- | ----------------------------------------------------- |
| `PASSWORD_CHANGED` | When a user's password is changed |
| `EMAIL_CHANGED` | When a user's email address is changed |
| `PHONE_CHANGED` | When a user's phone number is changed |
| `MFA_FACTOR_ENROLLED` | When a new MFA factor is added to the user's account |
| `MFA_FACTOR_UNENROLLED` | When an MFA factor is removed from the user's account |
| `IDENTITY_LINKED` | When a new identity is linked to the account |
| `IDENTITY_UNLINKED` | When an identity is unlinked from the account |
For example:
```sh
GOTRUE_MAILER_NOTIFICATIONS_EMAIL_CHANGED_ENABLED='true'
GOTRUE_MAILER_TEMPLATES_EMAIL_CHANGED_NOTIFICATION=''
GOTRUE_MAILER_SUBJECTS_EMAIL_CHANGED_NOTIFICATION=''
```
### Example
Below is an example configuration for setting up a custom password changed notification template.
### Step 1: Create the templates directory
This example reuses the directory created in **Auth Email Templates – Step 1** (`volumes/templates`). Add your notification email templates to this directory.
Your directory structure should look like this:
```
volumes/
templates/
invite.html
password_changed_notification.html
```
### Step 2: Update `docker-compose.yml`
Update the `auth` service in `docker-compose.yml` to enable password changed notification
```yml name=docker-compose.yml
services:
auth:
depends_on:
db:
condition: service_healthy
templates-server:
condition: service_started
environment:
GOTRUE_MAILER_NOTIFICATIONS_PASSWORD_CHANGED_ENABLED: 'true' # 👈 enabling the notification is required
GOTRUE_MAILER_TEMPLATES_PASSWORD_CHANGED_NOTIFICATION: 'http://templates-server/password_changed_notification.html'
GOTRUE_MAILER_SUBJECTS_PASSWORD_CHANGED_NOTIFICATION: 'Your password has been changed'
templates-server:
image: caddy:2-alpine
command: ['caddy', 'file-server', '-r', '/templates', '--listen', ':80']
volumes:
- ./volumes/templates:/templates
```
### Step 3: Restart containers
```sh
docker compose up -d --force-recreate --no-deps auth templates-server
```
# Self-Hosting with Docker
Learn how to configure and deploy Supabase with Docker.
Docker is the easiest way to get started with self-hosted Supabase. It should take you less than 30 minutes to get up and running.
## Contents
1. [Before you begin](#before-you-begin)
2. [System requirements](#system-requirements)
3. [Installing Supabase](#installing-supabase)
4. [Configuring and securing Supabase](#configuring-and-securing-supabase)
5. [Starting and stopping](#starting-and-stopping)
6. [Accessing Supabase services](#accessing-supabase-studio-dashboard)
7. [Updating](#updating)
8. [Uninstalling](#uninstalling)
9. [Advanced topics](#advanced-topics)
## Before you begin
This guide assumes you're comfortable with:
* Linux server administration basics
* Docker and Docker Compose
* Networking fundamentals (ports, DNS, firewalls)
If you're new to these topics, consider starting with the managed [Supabase platform](/dashboard) for free.
You need the following installed on your system:
* [Git](https://git-scm.com/downloads)
* [Docker](https://docs.docker.com/manuals/):
* **Linux server/VPS**: Install [Docker Engine](https://docs.docker.com/engine/install/) and [Docker Compose](https://docs.docker.com/compose/install/)
* **Linux desktop**: Install [Docker Desktop](https://docs.docker.com/desktop/setup/install/linux/)
* **macOS**: Install [Docker Desktop](https://docs.docker.com/desktop/install/mac-install/)
* **Windows**: Install [Docker Desktop](https://docs.docker.com/desktop/install/windows-install/)
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* OpenSSL
## System requirements
Minimum requirements for running all Supabase components, suitable for development and small to medium production workloads:
| Resource | Minimum | Recommended |
| -------- | --------- | ----------- |
| RAM | 4 GB | 8 GB+ |
| CPU | 2 cores | 4 cores+ |
| Disk | 50 GB SSD | 80 GB+ SSD |
If you don't need specific services, such as Logflare (Analytics), Realtime, Storage, imgproxy, or Edge Runtime (Functions), you can remove the corresponding sections and dependencies from `docker-compose.yml` to reduce resource requirements.
## Installing Supabase
Follow these steps to start Supabase on your machine:
```sh
# Get the code
git clone --depth 1 https://github.com/supabase/supabase
# Make your new supabase project directory
mkdir supabase-project
# Tree should look like this
# .
# ├── supabase
# └── supabase-project
# Copy the compose files over to your project
cp -rf supabase/docker/* supabase-project
# Copy the fake env vars
cp supabase/docker/.env.example supabase-project/.env
# Switch to your project directory
cd supabase-project
# Pull the latest images
docker compose pull
```
```sh
# Get the code using git sparse checkout
git clone --filter=blob:none --no-checkout --depth=1 --quiet https://github.com/supabase/supabase
cd supabase
git sparse-checkout init --cone
git sparse-checkout set docker
git checkout --quiet
cd ..
# Make your new supabase project directory
mkdir supabase-project
# Tree should look like this
# .
# ├── supabase
# └── supabase-project
# Copy the compose files over to your project
cp -rf supabase/docker/* supabase-project
# Copy the fake env vars
cp supabase/docker/.env.example supabase-project/.env
# Switch to your project directory
cd supabase-project
# Pull the latest images
docker compose pull
```
If you are using rootless Docker, edit `.env` and set `DOCKER_SOCKET_LOCATION` to your docker socket location. For example: `/run/user/1000/docker.sock`. Otherwise, you will see an error like `container supabase-vector exited (0)`.
## Configuring and securing Supabase
While we provided example placeholder passwords and keys in the `.env.example` file, you should NEVER start your self-hosted Supabase using these defaults.
Review the configuration steps below and ensure you set all secrets properly before starting the services.
### Quick setup
To generate secure passwords and secrets, run:
```sh
sh utils/generate-keys.sh
```
As the **next step**, use the following script to add the new API keys and asymmetric key pair:
```sh
sh utils/add-new-auth-keys.sh
```
Review the output of both scripts and check the `.env` file **before proceeding** to configure [Supabase URLs](#configure-supabase-urls).
For a description of all secrets refer to the [related section](#configuring-secrets) in the "Advanced topics" below. If you'd like to learn more about how the new API keys and asymmetric JWT signing work in a self-hosted Supabase setup, make sure to read the detailed [how-to guide](/docs/guides/self-hosting/self-hosted-auth-keys).
### Configure Supabase URLs
Review and change URL configuration variables:
* `SUPABASE_PUBLIC_URL`: base URL for accessing Supabase from the Internet (Dashboard, API, Storage, etc.), e.g., `http://example.com:8000`
* `API_EXTERNAL_URL`: used by the Auth service to configure callback URLs, e.g., `http://example.com:8000`
* `SITE_URL`: default [redirect URL](/docs/guides/auth/redirect-urls) for Auth, e.g., `http://example.com:3000`
Throughout the self-hosting guides, `` stands for the host where your Supabase instance is reachable: your domain name, your server's IP, or `localhost`, depending on your setup.
* **Default setup:** The API gateway (Kong) listens on port `8000`, so the full URL is `http://:8000`.
* **Behind a [reverse proxy](/docs/guides/self-hosting/self-hosted-proxy-https):** the proxy terminates TLS on port `443`, so the URL becomes `https://`.
### Where to find your credentials
The generated secrets and password are written to the `.env` file. The ones you are most likely to need when connecting your application to self-hosted Supabase are:
* `POSTGRES_PASSWORD`: database password used in Postgres connection strings and by `psql`
* `SUPABASE_PUBLISHABLE_KEY`: publishable API key for client-side use (e.g., in your frontend)
* `SUPABASE_SECRET_KEY`: secret API key for server-side use. Never expose this in client code
* `SUPABASE_PUBLIC_URL`: base URL you pass as `supabaseUrl` to the client libraries
If you are still using the [legacy API keys](#configuring-legacy-api-keys), look for `ANON_KEY` and `SERVICE_ROLE_KEY` instead of the new publishable and secret API keys above.
### Studio authentication
Access to Studio (Dashboard) is protected with **HTTP basic authentication**.
A secure password MUST be set before starting Supabase. The password must include at least one letter - do not use numbers only or any special characters.
In the `.env` file, edit `DASHBOARD_PASSWORD` to change the password, and optionally `DASHBOARD_USERNAME` to change the username.
## Starting and stopping
You can start Supabase by using the following command in the same directory as your `docker-compose.yml` file:
```sh
docker compose up -d
```
Check the status of the services:
```sh
docker compose ps
```
After a minute or less, all services should have a status `Up [...] (healthy)`. If you see a status such as `created` but not `Up`, run the test script to determine what the problem might be:
```sh
sh tests/test-container-logs.sh
```
Then try inspecting the Docker logs for a specific container, e.g.,
```sh
docker compose logs analytics
```
To stop Supabase, use:
```sh
docker compose down
```
If the API gateway (Kong) fails to start with an entrypoint error, your local files may have been checked out with CRLF line endings instead of LF. Re-clone the repository, or normalize everything in the `docker/` directory to LF, then restart Supabase. Fresh clones should already use LF because of `.gitattributes`.
## Accessing Supabase Studio (Dashboard)
By default, you can access the dashboard through the API gateway on port `8000`.
For example: `http://:8000`, or `http://:8000` (or `localhost:8000` if you are running Docker Compose locally).
You will be prompted for a username and password. See the [Studio authentication](#studio-authentication) section for details.
## Accessing Postgres
The self-hosted Supabase stack provides the [Supavisor](https://supabase.github.io/supavisor/development/docs/) connection pooler for accessing Postgres and managing database connections.
You can connect to the Postgres database via Supavisor using the methods described below. Use your domain name, your server IP, or `localhost` depending on whether you are running self-hosted Supabase on a VPS, or locally.
The default POOLER\_TENANT\_ID is `your-tenant-id` (can be changed in `.env`), and the password is the one you set previously in [Configure database password](#configure-database-password).
For session-based connections (equivalent to a direct Postgres connection):
```sh
psql 'postgres://postgres.[POOLER_TENANT_ID]:[POSTGRES_PASSWORD]@[your-domain]:5432/postgres'
```
For pooled transactional connections:
```sh
psql 'postgres://postgres.[POOLER_TENANT_ID]:[POSTGRES_PASSWORD]@[your-domain]:6543/postgres'
```
When using `psql` with command-line parameters instead of a connection string to connect to Supavisor, the `-U` parameter should also be `postgres.[POOLER_TENANT_ID]`, and not just `postgres`.
If you need to configure Postgres to be directly accessible from the Internet, read [Exposing your Postgres database](#exposing-your-postgres-database).
To change the database password, read [Changing database password](#changing-database-password).
## Accessing Edge Functions
Edge Functions live in `volumes/functions`. The default setup includes a `hello` function you can invoke with `curl`:
```sh
curl http://:8000/functions/v1/hello
```
Add new functions at `volumes/functions//index.ts`, then restart the service to pick them up:
```sh
docker compose restart functions --no-deps
```
See the [self-hosted Edge Functions guide](/docs/guides/self-hosting/self-hosted-functions) for more details.
## Accessing APIs
Each of the APIs is available through the same API gateway:
* REST: `http://:8000/rest/v1/`
* Auth: `http://:8000/auth/v1/`
* Storage: `http://:8000/storage/v1/`
* Realtime: `http://:8000/realtime/v1/`
## Configuring HTTPS
By default, Supabase is accessible over HTTP. For production deployments, especially when using OAuth providers, you need HTTPS with a valid TLS certificate. The recommended approach is to place a reverse proxy (such as Caddy or Nginx) in front of the API gateway.
See the [Configure HTTPS](/docs/guides/self-hosting/self-hosted-proxy-https) guide for detailed setup instructions.
## Updating
We publish stable releases of the Docker Compose setup approximately once a month. The versions in each release are tested together, so they may lag behind the latest images on Docker Hub. To update, apply the latest changes from the repository and restart the services. If you want to run different versions of individual services, you can change the image tags in the Docker Compose file, but compatibility is **not guaranteed**. All Supabase images are available on [Docker Hub](https://hub.docker.com/u/supabase).
To follow the changes and updates, refer to the self-hosted Supabase [changelog](https://github.com/supabase/supabase/blob/master/docker/CHANGELOG.md).
You need to restart services to pick up the changes, which may result in downtime for your applications and users.
**Example:**
You'd like to update or rollback the Studio image. Follow the steps below:
1. Check the [supabase/studio](https://hub.docker.com/r/supabase/studio/tags) images on [Supabase Docker Hub](https://hub.docker.com/u/supabase)
2. Find the latest version (tag) number. It looks something like `2025.11.26-sha-8f096b5`
3. Update the `image` field in the `docker-compose.yml` file. It should look like this: `image: supabase/studio:2025.11.26-sha-8f096b5`
4. Run `docker compose pull`, followed by `docker compose down && docker compose up -d` to restart Supabase.
## Uninstalling
Be careful — the following destroys all data, including the database and storage volumes!
To uninstall, stop Supabase (while in the same directory as your `docker-compose.yml` file).
Stop the containers and remove volumes:
```sh
docker compose down -v
```
Optionally, ensure removal of all Postgres data:
```sh
rm -rf volumes/db/data
```
and all Storage data:
```sh
rm -rf volumes/storage
```
## Advanced topics
Everything beyond this point in the guide helps you understand how the system works and how you can modify it to suit your needs.
### Architecture
Supabase is built from open source tools, each chosen or developed for production use.
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
If the tools and communities already exist, with an MIT, Apache 2, PostgreSQL, or equivalent open source license, we will use and support that tool. If the tool doesn't exist, we build and open source it ourselves.
* **[Studio](https://github.com/supabase/supabase/tree/master/apps/studio)** - A dashboard for managing your self-hosted Supabase project
* **[Kong](https://github.com/Kong/kong)** - Kong API gateway
* **[Auth](https://github.com/supabase/auth)** - JWT-based authentication API for user sign-ups, logins, and session management
* **[PostgREST](https://github.com/PostgREST/postgrest)** - Web server that turns your Postgres database directly into a RESTful API
* **[Realtime](https://github.com/supabase/realtime)** - Elixir server that listens to Postgres database changes and broadcasts them to subscribed clients
* **[Storage](https://github.com/supabase/storage)** - RESTful API for managing files in S3, with Postgres handling permissions
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* **[imgproxy](https://github.com/imgproxy/imgproxy)** - Fast and secure image processing server
* **[postgres-meta](https://github.com/supabase/postgres-meta)** - RESTful API for managing Postgres (fetch tables, add roles, run queries)
* **[Postgres](https://github.com/supabase/postgres)** - Object-relational database with over 30 years of active development
* **[Edge Runtime](https://github.com/supabase/edge-runtime)** - Web server based on Deno runtime for running JavaScript, TypeScript, and WASM services
* **[Logflare](https://github.com/Logflare/logflare)** - Log management and event analytics platform
* **[Vector](https://github.com/vectordotdev/vector)** - High-performance observability data pipeline for logs
* **[Supavisor](https://github.com/supabase/supavisor)** - Supabase's Postgres connection pooler
Multiple services require specific configuration within the Postgres database. Refer to the documentation describing the [default roles](/docs/guides/database/postgres/roles#supabase-roles) to learn more.
You can find all the default extensions inside the [schema migration scripts repo](https://github.com/supabase/postgres/tree/develop/migrations). These scripts are mounted at `/docker-entrypoint-initdb.d` to run automatically when starting the Postgres container.
### Setting database password
The `generate-keys.sh` script creates a secure random database password. If you want to use your own, you can change `POSTGRES_PASSWORD` in the `.env` file **before** starting Supabase for the first time.
Follow the [password guidelines](/docs/guides/database/postgres/roles#passwords) for choosing a secure password. For easier configuration, **use only letters and numbers** to avoid URL encoding issues in connection strings.
### Changing database password
To change the database password after the initial setup, run:
```sh
sh utils/db-passwd.sh
```
The script generates a new password, updates all database roles, and modifies your `.env` file. After running it, restart the services with `docker compose up -d --force-recreate`.
### Configuring legacy API keys
Use the key generator below to obtain and configure the following secure keys in `.env`:
* `JWT_SECRET`: Used by Auth, PostgREST, and other services to sign and verify JWTs.
* `ANON_KEY`: Client-side API key with limited permissions (`anon` role). Use this in your frontend applications.
* `SERVICE_ROLE_KEY`: Server-side API key with full database access (`service_role` role). **Never expose this in client code.**
1. Copy the generated value and update `JWT_SECRET` in the `.env` file. Do not share this secret publicly or commit it to version control.
2. Copy the generated value and update `ANON_KEY` in the `.env` file.
3. Copy the generated value and update `SERVICE_ROLE_KEY` in the `.env` file.
The generated keys expire in 5 years. You can verify them at [jwt.io](https://jwt.io) using the saved value of `JWT_SECRET`.
### Configuring secrets
The `generate-keys.sh` script sets the following secrets automatically. You can also configure them manually in the `.env` file if needed:
* `SECRET_KEY_BASE`: encryption key for securing Realtime and Supavisor communications. (Must be at least 64 characters; generate with `openssl rand -base64 48`)
* `VAULT_ENC_KEY`: encryption key used by Supavisor for storing encrypted configuration. (Must be exactly 32 characters; generate with `openssl rand -hex 16`)
* `PG_META_CRYPTO_KEY`: encryption key for securing connection strings used by Studio against postgres-meta. (Must be at least 32 characters; generate with `openssl rand -base64 24`)
* `LOGFLARE_PUBLIC_ACCESS_TOKEN`: API token for log ingestion and querying. Used by Vector and Studio to send and query logs. (Must be at least 32 characters; generate with `openssl rand -base64 24`)
* `LOGFLARE_PRIVATE_ACCESS_TOKEN`: API token for Logflare management operations. Used by Studio for administrative tasks. Never expose client-side. (Must be at least 32 characters; generate with `openssl rand -base64 24`)
* `S3_PROTOCOL_ACCESS_KEY_ID`: Access key ID (username-like) for [accessing](/docs/guides/self-hosting/self-hosted-s3) the S3 protocol endpoint in Storage. (Generate with `openssl rand -hex 16`)
* `S3_PROTOCOL_ACCESS_KEY_SECRET`: Secret key (password-like) used with S3\_PROTOCOL\_ACCESS\_KEY\_ID. (Generate with `openssl rand -hex 32`)
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* `MINIO_ROOT_PASSWORD`: Root administrator password for the [MinIO server](/docs/guides/self-hosting/self-hosted-s3#using-minio). (Must be 8+ characters; generate with `openssl rand -hex 16`)
### Configuring Supabase services
Each service has a number of configuration options you can find in the related documentation.
Configuration options are generally added to the `.env` file and referenced in `docker-compose.yml` service definitions, e.g.,
```yml name=docker-compose.yml
services:
rest:
image: postgrest/postgrest
environment:
PGRST_JWT_SECRET: ${JWT_SECRET}
```
```sh name=.env
## Never check your secrets into version control
JWT_SECRET=${JWT_SECRET}
```
### Configuring social login (OAuth) providers
See the [Configure Social Login (OAuth) Providers](/docs/guides/self-hosting/self-hosted-oauth) guide for setup instructions.
### Configuring phone login, SMS, and MFA
See the [Configure Phone Login & MFA](/docs/guides/self-hosting/self-hosted-phone-mfa) guide for SMS provider setup, OTP settings, and multi-factor authentication configuration.
### Configuring an email server
You will need to use a production-ready SMTP server for sending emails. You can configure the SMTP server by updating the following environment variables in the `.env` file:
```sh name=.env
SMTP_ADMIN_EMAIL=
SMTP_HOST=
SMTP_PORT=
SMTP_USER=
SMTP_PASS=
SMTP_SENDER_NAME=
```
We recommend using [AWS SES](https://aws.amazon.com/ses/). It's affordable and reliable. Restart all services to pick up the new configuration.
### Configuring S3 Storage
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
By default, all files are stored locally on the server. You can connect Storage to an S3-compatible backend (AWS S3, RustFS, MinIO, Cloudflare R2), enable the S3 protocol endpoint for tools like `rclone`, or both. These are independent features.
See the [Configure S3 Storage](/docs/guides/self-hosting/self-hosted-s3) guide for detailed setup instructions.
### Configuring Supabase AI Assistant
Configuring the Supabase AI Assistant is optional. By adding **your own** `OPENAI_API_KEY` to `.env` you can enable AI services, which help with writing SQL queries, statements, and policies.
### Accessing Postgres through Supavisor
By default, Postgres connections go through the Supavisor connection pooler for efficient connection management. Two ports are available:
* `POSTGRES_PORT` (default: 5432) - Session mode, behaves like a direct Postgres connection
* `POOLER_PROXY_PORT_TRANSACTION` (default: 6543) - Transaction mode, uses connection pooling
For more information on configuring and using Supavisor, see the [Supavisor documentation](https://supabase.github.io/supavisor/).
### Exposing your Postgres database
By default, Postgres is only accessible through Supavisor. If you need direct access to the database (bypassing the connection pooler), you need to disable Supavisor and expose the Postgres port.
Exposing Postgres directly bypasses connection pooling and exposes your database to the network. Configure firewall rules or network policies to restrict access to trusted IPs only.
Edit `docker-compose.yml`:
1. **Disable Supavisor** - Comment out or remove the entire `supavisor` service section
2. **Expose Postgres port** - Add the port mapping to the `db` service, it should look like the example below:
```yaml name=docker-compose.yml
db:
ports:
- ${POSTGRES_PORT}:${POSTGRES_PORT}
container_name: supabase-db
```
After restarting, you can connect to the database directly using a standard Postgres connection string:
```sh
postgres://postgres:[POSTGRES_PASSWORD]@[your-server-ip]:5432/[POSTGRES_DB]
```
### Setting log\_min\_messages in Postgres
By default, the database's `log_min_messages` configuration is set to `fatal` in [docker-compose.yml](https://github.com/supabase/supabase/blob/df8729a82b1847e2989c14ede27965612761d503/docker/docker-compose.yml#L466) to prevent redundant logs generated by Realtime. You can configure `log_min_messages` using any of the Postgres [Severity Levels](https://www.postgresql.org/docs/current/runtime-config-logging.html#RUNTIME-CONFIG-SEVERITY-LEVELS).
### Using file backend in Storage on macOS
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
By default, the Storage backend uses local files via a bind mount. On macOS, Docker Desktop bind mounts have known limitations (missing xattr support, permission issues) that can prevent Storage from working correctly. Change the [bind mount](https://github.com/supabase/supabase/blob/a5f4a59e0e262394b345600e8d8a2241d6ac3b64/docker/docker-compose.yml#L391) to a named Docker volume instead.
## Managing your secrets
Many components inside Supabase rely on secrets and passwords being kept securely. By default, all secrets are in the `.env` file, but we strongly recommend using a secrets manager when deploying to production.
Some suggested systems include:
* [Doppler](https://www.doppler.com/)
* [Infisical](https://infisical.com/)
* [Key Vault](https://docs.microsoft.com/en-us/azure/key-vault/general/overview) by Azure (Microsoft)
* [Secrets Manager](https://aws.amazon.com/secrets-manager/) by AWS
* [Secrets Manager](https://cloud.google.com/secret-manager) by GCP
* [Vault](https://www.hashicorp.com/products/vault) by HashiCorp
***
## Demo
1. The VPS instance is a DigitalOcean droplet. (For server requirements refer to [System requirements](#system-requirements))
2. To access Studio, use the IPv4 IP address of your Droplet.
3. If you're unable to use Studio, run `docker compose ps` to see if all services are up and healthy.
# Enabling MCP Server Access
Configure secure access to the MCP server in your self-hosted Supabase instance.
The MCP (Model Context Protocol) server in [self-hosted Supabase](/docs/guides/self-hosting/docker) runs behind the internal API. Currently, it does not offer OAuth 2.1 authentication, and is not intended to be exposed to the Internet. The corresponding API route has to be protected by restricting network connections from the outside. By default, all connections to the MCP server are denied.
This guide explains how to securely enable access to your self-hosted MCP server.
## Security considerations
Do not allow connections to the self-hosted MCP server from the Internet. Only access it via:
* A VPN connection to the server running the Studio container
* An SSH tunnel from your local machine
## Accessing via SSH tunnel
### Step 1: Determine the local IP address that will be used to access the MCP server
When connecting via an SSH tunnel to the Studio Docker container, the source IP will be that of the Docker bridge gateway. You need to allow connections from this IP address.
Determine the Docker bridge gateway IP on the host running your Supabase containers:
```sh
docker inspect supabase-kong \
--format '{{range .NetworkSettings.Networks}}{{println .Gateway}}{{end}}'
```
Determine the Docker bridge gateway IP on the host running your Supabase containers:
```sh
docker inspect supabase-envoy \
--format '{{range .NetworkSettings.Networks}}{{println .Gateway}}{{end}}'
```
This command will output an IP address, e.g., `172.18.0.1`.
### Step 2: Allow connections from the gateway IP
Add the IP address you discovered to the Kong configuration by editing the following section in `./volumes/api/kong.yml`:
1. Comment out the request-termination section
2. Remove the # symbols from the entire section starting with `- name: cors`, including `deny: []`
3. Add your local IP to the 'allow' list
4. **Preserve the existing indentation** - YAML is whitespace-sensitive and the config will fail to load if it changes
5. Your edited configuration should look like the example below:
```yaml name=volumes/api/kong.yml
## MCP endpoint - local access
- name: mcp
_comment: 'MCP: /mcp -> http://studio:3000/api/mcp (local access)'
url: http://studio:3000/api/mcp
routes:
- name: mcp
strip_path: true
paths:
- /mcp
plugins:
# Block access to /mcp by default
#- name: request-termination
# config:
# status_code: 403
# message: "Access is forbidden."
# Enable local access (danger zone!)
# 1. Comment out the 'request-termination' section above
# 2. Uncomment the entire section below, including 'deny'
# 3. Add your local IPs to the 'allow' list
- name: cors
- name: ip-restriction
config:
allow:
- 127.0.0.1
- ::1
# Add your Docker bridge gateway IP below
- 172.18.0.1
# Do not remove deny!
deny: []
```
Add the IP address you discovered to the Envoy configuration by editing the `/mcp` route in `./volumes/api/envoy/lds.template.yaml`:
1. Find the route with `prefix: /mcp`
2. Comment out the `rbac` block that denies all traffic and uncomment the allow-list policy below
3. Keep loopback entries (`127.0.0.1` and `::1`) and add your Docker bridge gateway IP
4. **Preserve the existing indentation** - YAML is whitespace-sensitive and the config will fail to load if it changes
5. Your edited configuration should look like the example below:
```yaml name=volumes/api/envoy/lds.template.yaml
- match:
prefix: /mcp
route:
cluster: studio
prefix_rewrite: /api/mcp
timeout: 30s
request_headers_to_add:
- header:
key: X-Forwarded-Prefix
value: /mcp
append_action: ADD_IF_ABSENT
typed_per_filter_config:
envoy.filters.http.basic_auth:
'@type': >-
type.googleapis.com/envoy.config.route.v3.FilterConfig
disabled: true
envoy.filters.http.rbac:
'@type': >-
type.googleapis.com/envoy.extensions.filters.http.rbac.v3.RBACPerRoute
# Block access to /mcp by default
#rbac:
# rules:
# action: DENY
# policies:
# deny_all:
# permissions:
# - any: true
# principals:
# - any: true
# Enable local access (danger zone!)
# 1. Comment out the 'rbac' block above.
# 2. Uncomment and adjust the 'rbac' block below.
# 3. Add or adjust your local IPs in 'principals'.
rbac:
rules:
action: ALLOW
policies:
allow_local:
permissions:
- any: true
principals:
- direct_remote_ip:
address_prefix: 127.0.0.1
prefix_len: 32
- direct_remote_ip:
address_prefix: ::1
prefix_len: 128
- direct_remote_ip:
# Add your Docker bridge gateway IP below
address_prefix: 172.18.0.1
prefix_len: 32
```
### Step 3: Restart API gateway
After you've added the local IP address as above, restart your gateway:
```sh
docker compose restart kong
```
```sh
docker compose -f docker-compose.yml -f docker-compose.envoy.yml restart api-gw
```
### Step 4: Create the SSH tunnel
From your local machine, create an SSH tunnel to your Supabase host:
```sh
ssh -L localhost:8080:localhost:8000 you@your-supabase-host
```
This command forwards local port `8080` to port `8000` on your Supabase host.
### Step 5: Configure your MCP client
Edit the settings for your MCP client and add the following to `"mcpServers": {}` or `"servers": {}`:
```json
{
"mcpServers": {
"supabase-self-hosted": {
"url": "http://localhost:8080/mcp"
}
}
}
```
### Step 6: Start using the self-hosted MCP server
From your local machine, check that the MCP server is reachable:
```sh
curl http://localhost:8080/mcp \
-X POST \
-H "Content-Type: application/json" \
-H "Accept: application/json, text/event-stream" \
-H "MCP-Protocol-Version: 2025-06-18" \
-d '{
"jsonrpc": "2.0",
"id": 1,
"method": "initialize",
"params": {
"protocolVersion": "2025-06-18",
"capabilities": {
"elicitation": {}
},
"clientInfo": {
"name": "test-client",
"title": "Test Client",
"version": "1.0.0"
}
}
}'
```
Start your MCP client (Claude Code, Cursor, etc.) and verify access to the MCP tools. For example, you can ask: "What is Supabase anon key? Use the Supabase MCP server tools."
## Troubleshooting
If you are unable to connect to the MCP server:
1. Update Kong configuration file to the [latest version](https://github.com/supabase/supabase/blob/master/docker/volumes/api/kong.yml) and edit carefully
2. Confirm the Docker bridge gateway IP is correctly added in `./volumes/api/kong.yml`
3. Check Kong's logs for errors: `docker compose logs kong`
4. Make sure your SSH tunnel is active
# Upgrade to Postgres 17
Start a new self-hosted Supabase deployment with Postgres 17, or upgrade an existing Postgres 15 installation.
Self-hosted Supabase ships with Postgres 15 by default. This guide covers two scenarios:
* **New deployment** - start fresh with Postgres 17 (no existing data)
* **Upgrade existing deployment** - migrate from Postgres 15 to Postgres 17 using `pg_upgrade`
## Before you begin
* Complete the [Self-Hosting with Docker](/docs/guides/self-hosting/docker) setup
* Your current database image should be `supabase/postgres:15.x`
## New deployment with Postgres 17
If you are starting a new self-hosted Supabase instance with **no existing data**, use the Postgres 17 compose override:
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml up -d
```
This uses the `docker-compose.pg17.yml` override file which swaps the database image:
```yaml name=docker-compose.pg17.yml
services:
db:
image: supabase/postgres:17.6.1.084
```
If you use the override file, remember to include both compose files when running commands. Alternatively, you can update the image tag directly in `docker-compose.yml` instead of using an override.
The rest of the setup is the same as for Postgres 15 (see the Docker install [guide](/docs/guides/self-hosting/docker)).
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
If the new Postgres 17 container fails to start, make sure to check for an old `db-config` Docker volume. See [Postgres 17 fails to start with a leftover db-config volume](#postgres-17-fails-to-start-with-a-leftover-db-config-volume) for details.
## Upgrade an existing Postgres 15 deployment
Upgrading an existing deployment uses `pg_upgrade` to migrate data in place. The included upgrade scripts automates the full process.
### What the upgrade does
1. Pulls a specific Postgres 17 image and extracts upgrade binaries
2. Pulls supplemental upgrade scripts from Supabase's [Postgres](https://github.com/supabase/postgres) repository
3. Stops all self-hosted Supabase containers
4. Runs `pg_upgrade` inside a temporary Postgres 15 container
5. Runs additional tasks inside a temporary Postgres 17 container (re-enables extensions, applies patches, runs `VACUUM ANALYZE`)
6. Swaps data directories (the original is kept as a backup)
7. Starts self-hosted Supabase with Postgres 17
8. Applies additional role migrations (new in Postgres 17)
### Create a backup
You should create your own independent backup in case of disk failure or other issues.
The upgrade script automatically preserves the pgsodium key and original data directory as `./volumes/db/data.bak.pg15` as the final step. However, it is recommended to **always** create your own independent backup before starting:
Back up the database data directory:
```sh
cp -a ./volumes/db/data ./volumes/db/data-manual-backup
```
Back up the pgsodium encryption key (stored in a Docker named volume):
```sh
docker compose run --rm db cat /etc/postgresql-custom/pgsodium_root.key > ./pgsodium_root.key.backup
```
The `db-config` Docker named volume contains the pgsodium root encryption key. If you lose this key and have vault secrets, they become unrecoverable. The `cp -a` above backs up the data directory but NOT the named volume.
Optionally, take a logical backup too:
```sh
docker exec supabase-db pg_dumpall -h localhost -U supabase_admin > ./pg15_dump.sql
```
### Requirements
* At least **2x your current database size + 5 GB** of free disk space (`pg_upgrade` copies the data directory; the upgrade tarball is ~1.2 GB compressed)
* The script prompts for confirmation at each major step (use `--yes` to skip prompts)
* All self-hosted Supabase containers must be running before starting the upgrade
* Requires `bash`
* Must be run as root or using `sudo`
### Extensions removed in Postgres 17
The following extensions are **not available** in Postgres 17 builds. The upgrade script will prompt you to drop them if any of these are found:
| Extension | Notes |
| ------------- | ------------------------- |
| `timescaledb` | Not built for Postgres 17 |
| `plv8` | Not built for Postgres 17 |
| `plcoffee` | Companion to plv8 |
| `plls` | Companion to plv8 |
None of the above extensions are installed by default in the self-hosted Supabase setup. If you have installed any of them manually and need to keep them, **do not proceed** with the upgrade.
### Run the upgrade
```sh
sudo bash utils/upgrade-pg17.sh
```
The script might require your confirmation at some steps (e.g., while checking for disk space, or whether to disable extensions, or remove previous backups).
### After the upgrade
After a successful upgrade, always use both compose files:
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml up -d
```
To verify that Postgres 17 is running:
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml exec db psql -U postgres -c "SELECT version();"
```
The original Postgres 15 data is preserved at `./volumes/db/data.bak.pg15`. The pgsodium root key is saved as `./volumes/db/pgsodium_root.key.bak.pg15`. The upgrade binaries tarball is cached at `./volumes/db/pg17_upgrade_bin_*.tar.gz`. Once you have verified that everything works, you can reclaim disk space:
```sh
rm -rf ./volumes/db/data.bak.pg15 \
./volumes/db/pgsodium_root.key.bak.pg15 \
./volumes/db/pg17_upgrade_bin_*.tar.gz
```
Do not delete `data.bak.pg15` until you have verified the upgrade. Rollback is only possible while the backup exists.
### Rollback
If you need to revert to Postgres 15 (run the following commands as root):
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml down && \
rm -rf ./volumes/db/data && \
mv ./volumes/db/data.bak.pg15 ./volumes/db/data && \
docker compose run --rm db chown -R postgres:postgres /etc/postgresql-custom/ && \
docker compose up -d
```
This restores the original data directory, fixes file ownership on the `db-config` volume (Supabase's Postgres 15 and 17 images use different user IDs), and starts with the old Postgres 15 image.
### Custom Postgres configuration
The Postgres 17 image loads any `.conf` files from `/etc/postgresql-custom/conf.d/` on startup. This directory is on the `db-config` named volume, so changes persist across restarts.
This is a Supabase Postgres 17 image feature. The Postgres 15 image does not load files from `conf.d/`.
To add custom Postgres settings, create a `.conf` file in the volume. Since `conf.d/` is on a Docker named volume (not a bind mount), you need to write through the container:
```sh
docker exec supabase-db bash -c 'cat > /etc/postgresql-custom/conf.d/custom.conf << EOF
max_connections = 200
EOF'
```
Restart to apply (`max_connections` requires a full restart):
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml restart db
```
Verify the new settings:
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml exec db psql -U postgres -c "SHOW max_connections;"
```
### Upgrade process details
The upgrade script delegates the core migration work to two scripts from the [supabase/postgres](https://github.com/supabase/postgres) repository (`ansible/files/admin_api_scripts/pg_upgrade_scripts/`).
**Phase 1 - Migrate data (Postgres 15 container):**
1. Disables extensions that are incompatible with `pg_upgrade` (`pg_graphql`, `pg_stat_monitor`, `pg_backtrace`, `wrappers`, `pgrouting`) and generates SQL to re-enable them after the upgrade
2. Temporarily grants superuser to the `postgres` role (required by `pg_upgrade`)
3. Extracts the previously saved Postgres 17 binaries tarball and runs `initdb` to create a new empty database
4. Runs `pg_upgrade --check` to verify the upgrade can succeed before making changes
5. Stops Postgres 15 and runs `pg_upgrade` to migrate all data to the new database
6. Copies Postgres configuration and the SQL scripts generated by `pg_upgrade` to a staging directory for the next phase
**Phase 2 - Finalize (Postgres 17 container):**
1. Moves the upgraded data directory into place and starts Postgres 17
2. Applies extension compatibility patches for Wrappers, `pg_net`, `pg_cron`, and Vault (fixes ownership, grants, and foreign server options)
3. Runs the SQL scripts generated by `pg_upgrade` to update system catalogs and extension versions
4. Re-enables the extensions that were disabled in phase 1
5. Grants predefined roles (`pg_monitor`, `pg_read_all_data`, `pg_signal_backend`, and on Postgres 16+ also `pg_create_subscription`) and revokes the temporary superuser grant
6. Restarts Postgres and runs `vacuumdb --all --analyze-in-stages` to rebuild optimizer statistics
After both phases complete, the upgrade script preserves the original Postgres 15 data directory as a backup and starts the full Supabase stack with Postgres 17.
## Troubleshooting
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### pg\_upgrade fails with replication slot errors
`pg_upgrade` cannot proceed if there are active replication slots. Default self-hosted installs don't have any, but if you set up logical replication or have custom replication configurations, drop the slots before upgrading:
```sh
docker exec supabase-db psql -h localhost -U supabase_admin -d postgres -c "
SELECT pg_drop_replication_slot(slot_name)
FROM pg_replication_slots;
"
```
Then re-run the upgrade script. Replication slots will need to be manually recreated after the upgrade.
### "Permission denied" on the data directory
The upgrade script fixes file ownership automatically (Postgres 15 and 17 use different UIDs). If you still see permission errors, run:
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml run --rm db \
chown -R postgres:postgres /var/lib/postgresql/data
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### pgsodium / Supabase Vault errors
The `db-config` named volume contains the pgsodium root encryption key at `/etc/postgresql-custom/pgsodium_root.key`. This volume is preserved during the upgrade. Never run `docker compose down -v` as this destroys named volumes and makes vault secrets unrecoverable.
### Services fail to connect after upgrade
Restart all services to pick up the new database:
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml down && \
docker compose -f docker-compose.yml -f docker-compose.pg17.yml up -d
```
### Disk space issues during upgrade
The upgrade needs space for:
* The upgrade tarball (~1.2 GB compressed, cached for re-runs)
* A full copy of your database (created by `pg_upgrade`)
* The original data (kept as backup)
The script uses `/tmp` (or `TMPDIR` if set) for its staging directory, which holds the downloaded tarball and upgrade scripts. If your `/tmp` filesystem is small or mounted with limited space, you can point it to a different location, e.g.:
```sh
sudo TMPDIR=/mnt/my-tmp bash utils/upgrade-pg17.sh
```
If you run out of space mid-upgrade, the safest path is to roll back and free up disk space before retrying.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
### Postgres 17 fails to start with a leftover db-config volume
If you are starting a **fresh** Postgres 17 deployment (not using the upgrade script) and the container fails to start, the most likely cause is a leftover `db-config` volume from a previous Postgres 15 installation. Start the containers without the `-d` option or check the logs for errors about `postgresql.conf` or other configuration mismatch.
To fix, remove the old volume and let Postgres 17 initialize a clean configuration:
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml down && \
docker volume rm $(docker volume ls --filter "name=db-config" --format '{{.Name}}') && \
docker compose -f docker-compose.yml -f docker-compose.pg17.yml up -d
```
Removing the `db-config` volume destroys any custom Postgres configuration and the pgsodium root key. Only do this for fresh installations with no existing data or vault secrets.
### Restoring from a manual backup
If the upgrade fails and the script's built-in rollback isn't sufficient, restore from the manual backups created in the [Create a backup](#create-a-backup) step:
Restore the data:
```sh
docker compose -f docker-compose.yml -f docker-compose.pg17.yml down && \
rm -rf ./volumes/db/data && \
cp -a ./volumes/db/data-manual-backup ./volumes/db/data
```
Restore the pgsodium key to the `db-config` volume:
```sh
docker compose run --rm db \
sh -c 'cat > /etc/postgresql-custom/pgsodium_root.key' < ./pgsodium_root.key.backup && \
docker compose run --rm db \
chown postgres:postgres /etc/postgresql-custom/pgsodium_root.key && \
docker compose run --rm db \
chmod 600 /etc/postgresql-custom/pgsodium_root.key
```
Start Postgres 15:
```sh
docker compose up -d
```
# Remove superuser access from Studio
Learn how to switch from the supabase_admin to postgres role in self-hosted Supabase.
## Overview
In late 2022, Supabase introduced a security change in hosted projects that removed superuser access from the dashboard SQL editor and shifted ownership of user-created database objects away from `supabase_admin` toward the `postgres` role.
You can read more about it in the [official announcement](https://github.com/orgs/supabase/discussions/9314).
However, this migration was never automatically applied to self-hosted Supabase instances.
As a result:
* Objects created via the dashboard may still be owned by `supabase_admin`
* Behavior differs from the Supabase platform
* Some migrations may fail when run as `postgres`
This guide explains how to align your self-hosted Supabase instance with the security enhancements and ownership model used on the Supabase platform.
## Changing the configuration
### Step 1: Update database object ownership
Use the provided script to reassign ownership of database objects in the `public` schema from `supabase_admin` to `postgres`. From the project directory containing `docker-compose.yml`, run:
```sh
sh utils/reassign-owner.sh
```
This script only updates ownership for database objects in the `public` schema. Supabase-managed and custom schemas are not affected.
### Step 2: Update environment variables in docker-compose.yml
* In your `docker-compose.yml` configuration, uncomment the following line for the `studio` service to use the `postgres` role for read/write operations:
```yml name=docker-compose.yml
studio:
environment:
POSTGRES_USER_READ_WRITE: postgres
```
* Locate the `meta` service environment variables and change the `PG_META_DB_USER` environment variable from `supabase_admin` to `postgres`:
```yml name=docker-compose.yml
meta:
environment:
PG_META_DB_USER: postgres
```
Studio uses its own credentials to access Postgres via `postgres-meta`, so this change is only needed for backward compatibility and consistency.
### Step 3: Restart Supabase
```sh
docker compose down && docker compose up -d
```
## Verify roles
After restarting your services, verify that Supabase Studio is now using the `postgres` role. Run the following query in the Supabase Studio SQL Editor:
```sql
select current_user;
-- expected result: postgres
```
# Restore a Platform Project to Self-Hosted
Restore your database from the Supabase platform to a self-hosted instance.
This guide walks you through restoring your database from a Supabase platform project to a [self-hosted Docker instance](/docs/guides/self-hosting/docker). Transferring storage objects or redeploying edge functions is not covered here.
## Before you begin
You need:
* A new self-hosted Supabase instance ([Docker setup guide](/docs/guides/self-hosting/docker))
* [Supabase CLI](/docs/guides/local-development/cli/getting-started) installed (or use `npx supabase`)
* [Docker Desktop](https://docs.docker.com/get-started/get-docker/) installed (required by the CLI)
* `psql` installed ([official installation guide](https://www.postgresql.org/download/))
* Your Supabase database passwords (for platform and self-hosted)
## Step 1: Get your platform connection string
On your managed Supabase project dashboard, click [**Connect**](/dashboard/project/_?showConnect=true) and copy the connection string (use the session pooler or direct connection).
## Step 2: Back up your platform database
Export roles, schema, and data as three separate SQL files:
```sh
supabase db dump --db-url "[CONNECTION_STRING]" -f roles.sql --role-only
```
```sh
supabase db dump --db-url "[CONNECTION_STRING]" -f schema.sql
```
```sh
supabase db dump --db-url "[CONNECTION_STRING]" -f data.sql --use-copy --data-only
```
This produces SQL files that are compatible across Postgres versions.
Using `supabase db dump` executes `pg_dump` under the hood but applies Supabase-specific filtering - it excludes internal schemas, strips reserved roles, and adds idempotent `IF NOT EXISTS` clauses. Using raw `pg_dump` directly will include Supabase internals and cause permission errors during restore. CLI requires Docker because it runs `pg_dump` inside a container from the Supabase Postgres image rather than requiring a local Postgres installation.
## Step 3: Prepare your self-hosted instance
Before restoring, check the following on your self-hosted instance:
* **Extensions**: Enable any non-default extensions your Supabase project uses. You can check which extensions are active by querying `select * from pg_extension;` on your managed database (or check Database Extensions in Dashboard).
## Step 4: Restore to your self-hosted database
Connect to your self-hosted Postgres and restore the dump files. The [default](/docs/guides/self-hosting/docker#accessing-postgres) connection string for self-hosted Supabase is:
```
postgres://postgres.your-tenant-id:[POSTGRES_PASSWORD]@[your-domain]:5432/postgres
```
Where `[POSTGRES_PASSWORD]` is the value of `POSTGRES_PASSWORD` in your self-hosted `.env` file.
Use your domain name, your server IP, or localhost for `[your-domain]` depending on whether you are running self-hosted Supabase on a VPS, or locally.
Run `psql` to restore:
```sh
psql \
--single-transaction \
--variable ON_ERROR_STOP=1 \
--file roles.sql \
--file schema.sql \
--command 'SET session_replication_role = replica' \
--file data.sql \
--dbname "postgres://postgres.your-tenant-id:[POSTGRES_PASSWORD]@[your-domain]:5432/postgres"
```
Setting `session_replication_role` to `replica` disables triggers during the data import, preventing issues like double-encryption of columns.
## Step 5: Verify the restore
Connect to your self-hosted database and run a few checks:
```sh
psql "postgres://postgres.your-tenant-id:[POSTGRES_PASSWORD]@[your-domain]:5432/postgres"
```
```sql
-- Check your tables are present
\dt public.*
-- Verify row counts on key tables
SELECT count(*) FROM auth.users;
-- Check extensions
SELECT * FROM pg_extension;
```
## What's included in the restore and what's not
The database dump includes your schema, data, roles, RLS policies, database functions, triggers, and `auth.users`. However, several things require separate configuration on your self-hosted instance:
| Requires manual setup | How to configure |
| ------------------------------------------- | ------------------------------------------------- |
| JWT secrets and API keys | Generate new ones and update `.env` |
| Auth provider settings (OAuth, Apple, etc.) | Configure `GOTRUE_EXTERNAL_*` variables in `.env` |
| Edge functions | Manually copy to your self-hosted instance |
| Storage objects | Transfer separately (not covered in this guide) |
| SMTP / email settings | Configure `SMTP_*` variables in `.env` |
| Custom domains and DNS | Point your DNS to the self-hosted server |
## Auth considerations
Your `auth.users` table and related data are included in the database dump, so user accounts are preserved. However:
* **JWT secrets differ** between your platform and self-hosted instances. Existing tokens issued by the platform project will not be valid. Users will need to re-authenticate.
* **Social auth providers** (Apple, Google, GitHub, etc.) need to be configured in your self-hosted `.env` file. Set the relevant `GOTRUE_EXTERNAL_*` variables. See the Auth repository [README](https://github.com/supabase/auth) for all available options.
* **Redirect URLs** in your OAuth provider consoles (Apple Developer, Google Cloud Console, etc.) must be updated to point to your self-hosted hostname instead of `*.supabase.co`.
## Postgres version compatibility
Managed Supabase may run a newer Postgres version (Postgres 17) than the self-hosted Docker image (currently it's Postgres 15 by default). The `supabase db dump` command produces plain SQL files that work across major Postgres versions.
If your managed project runs Postgres 17, consider starting your self-hosted deployment with Postgres 17 as well. See the [Postgres 17 guide](/docs/guides/self-hosting/postgres-upgrade-17) for setup instructions.
Keep in mind:
* The data dump may include Postgres 17-only settings or reference tables/columns from newer Auth and Storage versions that don't exist on self-hosted yet. See [Version mismatches](#version-mismatches-between-platform-and-self-hosted) in the troubleshooting section.
* Run the restore on a test self-hosted instance first to identify any incompatibilities.
* Check that all extensions you use are available on the self-hosted Postgres version.
## Troubleshooting
### Version mismatches between platform and self-hosted
The platform may run a newer Postgres version (17 vs 15) and newer Auth service versions than self-hosted. The data dump can contain settings, tables, or columns that don't exist on your new self-hosted instance.
**Common issues in `data.sql`:**
* `SET transaction_timeout = 0` - a Postgres 17-only setting that fails on Postgres 15
* `COPY` statements for tables that don't exist on self-hosted (e.g., `auth.oauth_clients`, `storage.buckets_vectors`, `storage.vector_indexes`)
* `COPY` statements with columns added in newer Auth versions (e.g., `auth.flow_state` with `oauth_client_state_id`, `linking_target_id`)
**Workaround:** Edit `data.sql` before restoring:
```sh
# Comment out PG17-only transaction_timeout
sed -i 's/^SET transaction_timeout/-- &/' data.sql
```
For missing tables or column mismatches, comment out the relevant `COPY ... FROM stdin;` line and its corresponding `\.` terminator. Run the restore without `--single-transaction` first to identify all failures, then fix them and run the final restore with `--single-transaction`.
Keeping your self-hosted configuration [up to date](https://github.com/supabase/supabase/blob/master/docker/CHANGELOG.md) will minimize these gaps.
### Extension not available
If the restore fails because an extension isn't available, check whether it's supported on your self-hosted Postgres version. You can list available extensions with:
```sql
select * from pg_available_extensions;
```
### Connection refused
Make sure your self-hosted Postgres port is accessible. In the default [self-hosted Supabase](/docs/guides/self-hosting/docker#accessing-postgres) setup, the user is `postgres.your-tenant-id` with Supavisor on port `5432`.
### Legacy Studio configuration
Studio in self-hosted Supabase historically used `supabase_admin` role (superuser) instead of `postgres`. Objects created via Studio UI were owned by `supabase_admin`. Check your `docker-compose.yml` [configuration](https://github.com/supabase/supabase/blob/2cb5befaa377a42b6d6ca152b98105b59054f2f4/docker/docker-compose.yml#L30) to see if `POSTGRES_USER_READ_WRITE` is set to `postgres`.
### Custom roles missing passwords
If you created custom database roles with the `LOGIN` attribute on your platform project, their passwords are not included in the dump. Set them manually after restore:
```sql
ALTER ROLE your_custom_role WITH PASSWORD 'new-password';
```
### Additional resources
* [Backup and Restore using the CLI](/docs/guides/platform/migrating-within-supabase/backup-restore)
* [Restore Dashboard backup](/docs/guides/platform/migrating-within-supabase/dashboard-restore)
# New API Keys and Asymmetric Authentication
Configure new API keys and ES256 asymmetric authentication for self-hosted Supabase.
You can configure self-hosted Supabase to use the [new API keys](/docs/guides/getting-started/api-keys) alongside the legacy API keys (`ANON_KEY` and `SERVICE_ROLE_KEY` HS256-signed JWTs).
## Before you begin
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* Complete the [Docker setup guide](/docs/guides/self-hosting/docker), including running `generate-keys.sh` so that `JWT_SECRET`, `ANON_KEY`, and `SERVICE_ROLE_KEY` are set in your `.env` file
* If you are upgrading an existing self-hosted Supabase environment, make sure to check the [changelog](https://github.com/supabase/supabase/blob/master/docker/CHANGELOG.md) and add/update the following files:
* `.env.example` (merge new sections into your `.env` file)
* `docker-compose.yml`
* `utils/add-new-auth-keys.sh`
* `utils/rotate-new-api-keys.sh`
* `volumes/api/kong-entrypoint.sh`
* `volumes/api/kong.yml`
## Adding the new keys
From your project directory where you have `docker-compose.yml`:
```sh
sh utils/add-new-auth-keys.sh --update-env
```
This generates new configuration environment variables and writes them to `.env`. Without `--update-env`, the script prints the values and prompts you interactively.
The script reads `JWT_SECRET` from `.env` and includes it as a symmetric key inside both `JWT_KEYS` and `JWT_JWKS`. If you later change `JWT_SECRET`, you must regenerate the JWKS as well.
The following configuration should be uncommented in the `.env` file for the new authentication to work correctly:
```yaml name=docker-compose.yml
auth:
environment:
# JSON array of signing JWKs (EC private + legacy symmetric)
GOTRUE_JWT_KEYS: ${JWT_KEYS:-[]}
rest:
environment:
# PostgREST accepts a plain-text symmetric secret, a single JWK, or a JWKS.
PGRST_JWT_SECRET: ${JWT_JWKS:-${JWT_SECRET}}
realtime:
environment:
# JWKS for token verification (EC public + legacy symmetric)
API_JWT_JWKS: ${JWT_JWKS:-{"keys":[]}}
storage:
environment:
# JWKS for token verification (EC public + legacy symmetric)
JWT_JWKS: ${JWT_JWKS:-{"keys":[]}}
```
Podman does not support nested variable interpolation (`${A:-${B}}`). If you are using Podman, replace each nested expression with the required variable directly - see the inline comments in `docker-compose.yml` for the exact substitutions.
Restart all services:
```sh
docker compose down && docker compose up -d
```
### New API keys format
The new API keys use the [same format](/docs/guides/getting-started/api-keys) as the Supabase platform:
```
sb_publishable_<22-char-random>_<8-char-checksum>
sb_secret_<22-char-random>_<8-char-checksum>
```
### Verifying the setup
Test with the new publishable key:
```sh
curl http:///rest/v1/ \
-H "apikey: your-supabase-secret-key"
```
You should receive a valid response from PostgREST. Then verify that the legacy key still works:
```sh
curl http:///rest/v1/ \
-H "apikey: your-service-role-key"
```
Both should work and return the same result.
You can also verify the public JWKS endpoint:
```sh
curl http:///auth/v1/.well-known/jwks.json
```
This should return the EC public key (the symmetric key is excluded). Third-party services can use this endpoint to obtain the public key and verify asymmetric user session JWTs without needing the private key.
### Environment variables configuration
New variables default to empty values in `.env.example`. When empty, the API gateway and all services operate in legacy-only mode: `sb_publishable` and `sb_secret` API keys are not configured.
| Environment variable (existing and new) | Type | Description |
| --------------------------------------- | ---------------- | ------------------------------------------------------------------------------------------------------------------------------------- |
| `JWT_SECRET` | Symmetric secret | **Existing:** Shared secret for signing and verifying HS256 JWTs. Used by multiple services. |
| `ANON_KEY` | HS256 JWT | **Existing:** Legacy client-side API key. Embedded JWT with `role: "anon"`. |
| `SERVICE_ROLE_KEY` | HS256 JWT | **Existing:** Legacy server-side API key. Embedded JWT with `role: "service_role"`. |
| `SUPABASE_PUBLISHABLE_KEY` | Opaque | **New:** Short random key with checksum. Replaces `ANON_KEY` for **client-side** use. |
| `SUPABASE_SECRET_KEY` | Opaque | **New:** Short random key with checksum. Replaces `SERVICE_ROLE_KEY` for **server-side** use. |
| `JWT_KEYS` | JSON array | **New:** JSON array of signing JWKs containing the new asymmetric key pair and the legacy symmetric key. Used by Auth to sign tokens. |
| `JWT_JWKS` | JWKS (JSON) | **New:** Contains the new public key and the legacy symmetric key. Used by PostgREST, Realtime, and Storage to verify tokens. |
### Differences from the Supabase platform
* **One key per role.** Self-hosted Supabase supports a single `sb_publishable` and a single `sb_secret`. The platform allows creating multiple `sb_` keys per project.
* **No checksum validation.** The opaque keys use the same format as the platform (`sb_publishable__`), but the API gateway does not validate the checksum. Keys are matched as opaque strings by the API gateway.
### Backward compatibility
The new authentication configuration is fully backward compatible:
* **The API Gateway accepts both key types simultaneously.** You can migrate clients incrementally - some using legacy API keys, others using the new ones.
* **JWKS includes the symmetric key.** `JWT_JWKS` contains both the EC public key (for verifying new ES256 tokens) and the legacy `JWT_SECRET` as a symmetric JWK (for verifying old HS256 tokens). Services that receive `JWT_JWKS` can verify both token types.
* **No database changes required.** The asymmetric key system operates entirely at the API gateway and service configuration layer.
When `JWT_KEYS` is set, Auth will start signing new user session JWTs with the new asymmetric ES256 key pair. Make sure all services that verify tokens (PostgREST, Realtime, Storage) are configured with `JWT_JWKS` so they can verify both the new ES256 and legacy HS256 tokens.
## Rotating the new API keys
If your new API keys are compromised or you want to rotate them periodically, you can regenerate `sb_publishable` and `sb_secret` without touching the asymmetric key pair:
```sh
sh utils/rotate-new-api-keys.sh --update-env
```
After rotating, restart services and update your client applications with the new keys:
```sh
docker compose down && docker compose up -d
```
Rotating new API keys does not invalidate existing user sessions. User session JWTs issued by Auth are unaffected because they are verified using the asymmetric key pair, which remains unchanged.
## Regenerating asymmetric key pair
If the EC private key is compromised or you need to regenerate everything:
```sh
sh utils/add-new-auth-keys.sh --update-env
```
This generates a new EC P-256 key pair, new JWKS, new asymmetric JWTs, and new `sb_` API keys. After updating `.env` and restarting services:
* New user session tokens will be signed with the new EC key.
* Existing user session tokens signed with the old EC key will fail verification. Users will need to sign in again.
* Existing user session tokens signed with the legacy symmetric key (`JWT_SECRET`) will continue to work, since `JWT_SECRET` hasn't changed and is still included in the new JWKS.
Regenerating asymmetric keys invalidates all ES256 user sessions. Plan a maintenance window if your users have active sessions.
## How it works
Below are a few notes on the details of the new authentication architecture.
### What client SDK sends
Every request via `supabase-js` includes two headers:
* `apikey` - the API key (`sb_` or legacy JWT)
* `Authorization` - when unauthenticated, the client SDK copies the API key here (`Bearer sb_publishable_xxx` or `Bearer eyJ...`). When authenticated, this contains the user session JWT minted by Auth.
For **Realtime WebSocket** connections, the API key is sent as a `?apikey=` query parameter in the upgrade URL instead of an `apikey` header.
**Storage** and **Edge Functions** accept requests without an API key. These services handle their own authentication.
### Kong API gateway routing
Kong is configured with two consumers that each accept both the legacy and new API keys:
```yaml name=volumes/api/kong.yml
consumers:
- username: anon
keyauth_credentials:
- key: $SUPABASE_ANON_KEY # legacy HS256 JWT (ANON_KEY)
- key: $SUPABASE_PUBLISHABLE_KEY # new opaque key (omitted when not configured)
- username: service_role
keyauth_credentials:
- key: $SUPABASE_SERVICE_KEY # legacy HS256 JWT (SERVICE_ROLE_KEY)
- key: $SUPABASE_SECRET_KEY # new opaque key (omitted when not configured)
```
When new API keys have not been added yet, the `kong-entrypoint.sh` script removes the empty credential entries before Kong loads the config.
To assist with the authorization flows a specialized configuration in `kong.yml` substitutes internal, gateway-level-only pre-signed JWTs for `sb_publishable` and `sb_secret` API keys. These pre-signed JWTs are also auto-configured in `.env` but **should not** be used in any application code.
| Route | Service | API key required | Header substitution |
| -------------------- | -------------------- | ---------------- | ------------------- |
| `/auth/v1/*` | Auth | Yes | `Authorization` |
| `/rest/v1/*` | PostgREST | Yes | `Authorization` |
| `/graphql/v1` | PostgREST | Yes | `Authorization` |
| `/realtime/v1/api/*` | Realtime (REST) | Yes | `Authorization` |
| `/realtime/v1/*` | Realtime (WebSocket) | Yes | `x-api-key` |
| `/storage/v1/*` | Storage | No | `Authorization` |
| `/functions/v1/*` | Edge Functions | No | - |
### Request flows
The API gateway (Kong) configuration has the logic to decide what `Authorization` header the upstream service, such as Auth, receives. The logic handles two cases: requests that only carry an API key (no user session), and requests that carry a user session JWT.
#### Unauthenticated requests (API key only, no user session JWT)
When the client sends only an `apikey` header with the API key (no `Authorization` header), or also the API key duplicated in `Authorization` by `supabase-js`:
1. The client sends `apikey: sb_publishable_xxx` (or legacy `apikey: eyJ...`).
2. The API gateway checks the key and identifies the consumer (`anon` or `service_role`).
3. The API gateway inspects the `Authorization` header. Since it is either absent or starts with `Bearer sb_` (an opaque key, not a session JWT), the plugin replaces it:
* **The new `sb_` key:** `Authorization` header is set to the internal pre-signed ES256 JWT that corresponds to the role.
* **The Legacy JWT key:** `Authorization` header is set to the legacy HS256 JWT (the `apikey` value is copied as-is).
4. The upstream service receives a valid JWT in `Authorization` and verifies it using `JWT_JWKS` (or `JWT_SECRET`).
#### Authenticated requests (user session JWT)
When the client has previously signed in through Auth and has a valid user session JWT token:
1. The client sends `Authorization: Bearer eyJ...` (a JWT session token from Auth) alongside `apikey: sb_publishable_xxx` (or legacy `apikey: eyJ...`).
2. The API gateway checks the API key and identifies the consumer.
3. The API gateway inspects the `Authorization` header. Since it exists and does **not** start with `Bearer sb_` (it's a real JWT, not an `sb_` API key), the plugin **passes it through unchanged**. This works the same way regardless of whether the `apikey` is a new `sb_` key or a legacy JWT - the gateway only looks at the `Authorization` header to decide whether a user session is present.
4. The upstream service verifies the session JWT. If Auth signed it with ES256 (when `JWT_KEYS` is configured), verification uses the EC public key. If Auth signed it with HS256 (legacy), verification uses the symmetric key. Both keys are available in `JWT_JWKS`.
The `request-transformer` expression in `kong.yml` implements this as a single Lua conditional:
```lua
-- Pseudocode for the Authorization header logic:
if authorization exists AND does not start with "Bearer sb_" then
-- User session JWT: pass through unchanged
keep authorization
elseif apikey matches secret key then
-- Replace with pre-signed service_role ES256 JWT
set authorization = "Bearer "
elseif apikey matches publishable key then
-- Replace with pre-signed anon ES256 JWT
set authorization = "Bearer "
else
-- Legacy JWT key: copy apikey as authorization
set authorization = apikey
end
```
## Additional resources
* [Understanding API keys](/docs/guides/getting-started/api-keys) - How API keys work on the Supabase platform
* [Auth architecture](/docs/guides/auth/architecture) - How the Auth service handles authentication and token signing
* [JWT Signing Keys](/docs/guides/auth/signing-keys) - Best practices on managing keys used by Supabase Auth to create and verify JSON Web Tokens
* [JSON Web Token (JWT)](/docs/guides/auth/jwts) - How to best use JSON Web Tokens with Supabase
* [Self-hosting with Docker](/docs/guides/self-hosting/docker) - Initial setup guide, including legacy key generation
On GitHub:
* [Upcoming changes to Supabase API Keys (Discussion #29260)](https://github.com/orgs/supabase/discussions/29260)
* [Supabase Auth: Asymmetric Keys support (Discussion #29289)](https://github.com/orgs/supabase/discussions/29289)
# Envoy API Gateway
Architecture and configuration of the Envoy API gateway for self-hosted Supabase.
Self-hosted Supabase ships with an optional [Envoy](https://www.envoyproxy.io/)-based API gateway. It accepts incoming client requests, routes them to internal services (Auth, PostgREST, Realtime, Storage, Edge Functions, postgres-meta, Studio), and enforces API key authentication by translating opaque `sb_` keys into the internal credentials used by those services.
This guide explains the architecture, configuration layout, and security posture of the Envoy gateway for operators who want to understand or customize it. It is not an Envoy tutorial - for reference on filters, routes, and clusters, see the [Envoy documentation](https://www.envoyproxy.io/docs/envoy/latest/).
## Before you begin
* Complete the [Self-Hosting with Docker](/docs/guides/self-hosting/docker) setup
* To enable opaque `sb_` key translation, see [New API Keys and Asymmetric Authentication](/docs/guides/self-hosting/self-hosted-auth-keys)
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
## Enabling the Envoy gateway
The Envoy gateway is provided as a Docker Compose override.
If your stack is already running from the initial setup, bring it down first with `docker compose down`.
Start your self-hosted Supabase stack with both the base compose file and the Envoy override:
```sh
docker compose -f docker-compose.yml -f docker-compose.envoy.yml up -d
```
The override disables the default Kong gateway and starts Envoy on the same port (default `8000`). It also reconfigures the Functions service to wait for Envoy via a dependency.
Envoy is registered as the `api-gw` service and also exposes `kong` as a network alias; the base Kong service likewise exposes `api-gw`. Either hostname resolves to whichever gateway is currently active, so internal configs that hardcode `kong:8000` (for example, in Edge Functions or Studio) keep working without changes.
### Verify
Confirm the gateway is routing requests and enforcing API keys:
```sh
curl -i -H "apikey: your-service-role-key" http:///rest/v1/
```
A `200 OK` response from PostgREST confirms the gateway is up. A `401 Unauthorized` without the `apikey` header confirms enforcement is active.
## Architecture
Envoy runs as a single container (`supabase-envoy`) with one listener on port `8000`. Every incoming request passes through an ordered chain of HTTP filters before being forwarded to an upstream cluster:
```
Client
│
▼
Listener (port 8000)
│
▼
HTTP filter chain
├─ CORS
├─ Basic Auth (dashboard only)
├─ Lua: copy ?apikey query to header
├─ Lua: translate opaque keys in query
├─ Lua: translate opaque keys in header
├─ Lua: mirror apikey to x-api-key (Realtime WS)
├─ Lua: synthesize Authorization header
├─ Lua: 401 for missing/invalid API key
├─ RBAC (global: service_role → /pg/, apikey → other API routes;
│ per-route DENY override on /mcp)
└─ Router
│
▼
Upstream clusters
├─ auth (auth:9999)
├─ rest (rest:3000)
├─ realtime (realtime-dev.supabase-realtime:4000)
├─ storage (storage:5000)
├─ functions (functions:9000)
├─ meta (meta:8080)
└─ studio (studio:3000)
```
Routes are matched in the order declared in the listener config. Each route selects an upstream cluster, rewrites the request path prefix, and can override filter behavior (for example, disabling basic auth on API routes or denying all traffic on MCP routes).
## Configuration file structure
All Envoy configuration lives in `./volumes/api/envoy/` (relative to the directory containing `docker-compose.yml`):
| File | Purpose |
| ---------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `envoy.yaml` | Bootstrap configuration. Points Envoy at the CDS and LDS files, configures the admin interface, and sets an overload manager limit on downstream connections. |
| `cds.yaml` | Cluster Discovery Service - upstream service definitions (DNS, ports, health checks, connect timeouts, circuit breakers). |
| `lds.template.yaml` | Listener Discovery Service template. Defines the listener, filter chain, routes, RBAC policy, and CORS policy. Contains placeholders for keys and credentials. |
| `docker-entrypoint.sh` | Renders the LDS template into `lds.yaml` at container startup by substituting environment variables, computes a SHA1+base64 hash of `DASHBOARD_PASSWORD` for basic auth, then starts Envoy. |
### How the configuration is rendered at startup
Envoy cannot natively read environment variables inside its config. The entrypoint script renders environment-specific values into the listener config with `sed` before launching Envoy:
1. A SHA1+base64 hash of `DASHBOARD_PASSWORD` is computed and joined with `DASHBOARD_USERNAME` into a single `DASHBOARD_BASIC_AUTH` string in the `username:{SHA}` format that Envoy's `basic_auth` filter expects. Other hash formats are not supported.
2. The following variables are then substituted into `lds.template.yaml` and the result is written to `lds.yaml`:
| Variable | Used for |
| ----------------------------- | -------------------------------------------------------------------------- |
| `ANON_KEY` | Legacy HS256 anon JWT (API key validation, RBAC) |
| `SERVICE_ROLE_KEY` | Legacy HS256 service\_role JWT (API key validation, RBAC) |
| `SUPABASE_PUBLISHABLE_KEY` | Opaque `sb_publishable_*` key (translation source) |
| `SUPABASE_SECRET_KEY` | Opaque `sb_secret_*` key (translation source) |
| `ANON_KEY_ASYMMETRIC` | Pre-signed ES256 anon JWT (translation target; internal use only) |
| `SERVICE_ROLE_KEY_ASYMMETRIC` | Pre-signed ES256 service\_role JWT (translation target; internal use only) |
| `DASHBOARD_BASIC_AUTH` | Dashboard basic auth credentials (computed in step 1) |
3. If all four of `SUPABASE_SECRET_KEY`, `SUPABASE_PUBLISHABLE_KEY`, `ANON_KEY_ASYMMETRIC`, and `SERVICE_ROLE_KEY_ASYMMETRIC` are set, opaque key translation is enabled. Otherwise, Envoy runs in legacy-only mode and only legacy HS256 keys are accepted. The entrypoint prints which mode is active to the container log at startup.
Configuration changes require restarting the container so the entrypoint re-renders the template:
```sh
docker compose -f docker-compose.yml -f docker-compose.envoy.yml restart api-gw
```
## Routes
Routes are matched in the order declared. The first matching prefix wins. Protected routes require a valid `apikey` header; open routes pass through without API key validation.
| Path prefix | Upstream | Path rewrite | Access control | Notes |
| ----------------------------------------- | --------- | ------------------------ | ----------------- | ---------------------------------------------------------------------- |
| `/auth/v1/verify` | auth | `/verify` | Open | Email verification |
| `/auth/v1/callback` | auth | `/callback` | Open | OAuth callback |
| `/auth/v1/authorize` | auth | `/authorize` | Open | OAuth authorize |
| `/auth/v1/.well-known/jwks.json` | auth | `/.well-known/jwks.json` | Open | JWKS for third-party verification |
| `/.well-known/oauth-authorization-server` | auth | - | Open | OAuth 2.0 Authorization Server Metadata (RFC 8414) |
| `/sso/saml/acs` | auth | - | Open | SAML assertion consumer |
| `/sso/saml/metadata` | auth | - | Open | SAML metadata |
| `/functions/v1/` | functions | `/` | Bypass | Edge Functions runtime performs its own JWT verification; 150s timeout |
| `/storage/v1/` | storage | `/` | Bypass | Storage performs its own authorization |
| `/auth/v1/` | auth | `/` | API key | Protected Auth endpoints |
| `/rest/v1/` | rest | `/` | API key | PostgREST |
| `/graphql/v1` | rest | `/rpc/graphql` | API key | pg\_graphql (adds `Content-Profile: graphql_public`) |
| `/realtime/v1/api` | realtime | `/api` | API key | Realtime REST API |
| `/realtime/v1/` | realtime | `/socket/` | API key | Realtime WebSocket |
| `/pg/` | meta | `/` | Service role only | postgres-meta - used by Studio for database access |
| `/api/mcp` | studio | - | Denied | MCP endpoint (blocked by default via RBAC DENY) |
| `/mcp` | studio | `/api/mcp` | Denied | MCP endpoint (blocked by default via RBAC DENY) |
| `/` (catch-all) | studio | - | Basic auth | Dashboard; strips inbound `Authorization` header |
MCP routes are denied at the gateway by default. Allowing local access requires editing the RBAC rule on the `/mcp` route. See the inline comments in `lds.template.yaml` for the allowed pattern, and [Enabling MCP Server Access](/docs/guides/self-hosting/enable-mcp) for the security model.
## Authentication
The gateway handles three authentication-related steps: dashboard basic auth on the catch-all route, API key enforcement on protected routes, and an opaque-to-internal key translation step that runs before enforcement.
### Dashboard basic auth
The catch-all `/` route requires HTTP basic auth with credentials from `DASHBOARD_USERNAME` and `DASHBOARD_PASSWORD`. The `Authorization` header is stripped (regardless of scheme) before the request is forwarded to Studio, so the basic auth credentials never reach the upstream service.
### API key enforcement on protected routes
The protected routes (`/auth/v1/`, `/rest/v1/`, `/graphql/v1`, `/realtime/v1/api`, `/realtime/v1/`, `/pg/`) require the `apikey` header to contain a valid configured key. Acceptable keys are the new opaque `sb_publishable_*` and `sb_secret_*` keys (translated to internal JWTs) or the legacy `ANON_KEY` and `SERVICE_ROLE_KEY` HS256 JWT API keys.
A Lua filter rejects missing or invalid keys with HTTP `401 Unauthorized`. An RBAC filter then applies finer-grained rules:
* `/pg/` - only `service_role` keys (`sb_secret_*` or legacy `SERVICE_ROLE_KEY`) are allowed (HTTP `403` otherwise).
* All other protected routes - any valid configured key is allowed.
### Opaque key translation
When the new API keys (`sb_publishable_*`, `sb_secret_*`) are configured, a chain of Lua filters translates opaque keys into the corresponding pre-signed internal JWTs before the request reaches API key enforcement and upstream services. **The entire chain is skipped on `/functions/v1/`**: the Edge Runtime receives the original `apikey` and `Authorization` headers unchanged.
The chain operates in this order:
1. **Query parameter copy.** If the request has `?apikey=...` but no `apikey` header, the value is copied into the `apikey` header. This normalizes query-only clients (such as Realtime WebSocket connections from browsers, where custom headers are not available).
2. **Query parameter translation.** If the `apikey` query parameter contains an opaque key, it is replaced - both in the URL and in the `apikey` header - with the corresponding pre-signed internal JWT.
3. **Header translation.** If the `apikey` header contains an opaque key, it is replaced with the corresponding pre-signed internal JWT.
4. **`x-api-key` mirror.** On the Realtime WebSocket route, the `apikey` value is copied into the `x-api-key` header (which Realtime reads first for WebSocket authentication).
5. **`Authorization` synthesis.** If the client did not send a real JWT in the `Authorization` header (or sent only a `Bearer sb_*` value, which is not a valid JWT), the gateway synthesizes `Authorization: Bearer ` from the (potentially translated) `apikey` header. This is skipped on the Realtime WebSocket route, which uses `x-api-key` instead.
For background on opaque vs asymmetric keys, see [New API Keys and Asymmetric Authentication](/docs/guides/self-hosting/self-hosted-auth-keys).
## Forwarded headers and CORS
### X-Forwarded headers
Envoy attaches forwarded headers to every upstream request so downstream services can reconstruct the original client-facing URL.
| Header | Value |
| -------------------- | --------------------------------------------------------------------------------- |
| `X-Forwarded-Host` | The client's `Host` header (added if not already present) |
| `X-Forwarded-Port` | The listener port (`8000`) |
| `X-Forwarded-Proto` | Set automatically by Envoy based on the connection (`http` or `https`) |
| `X-Forwarded-Prefix` | Set per-route to the matched path prefix (for example, `/storage/v1` for Storage) |
| `X-Forwarded-For` | Set automatically because `use_remote_address: true` is enabled on the listener |
`X-Forwarded-Prefix` is required by Storage for S3 signature v4 verification and for constructing TUS upload Location URLs.
### CORS
The gateway applies a permissive CORS policy at the virtual-host level:
* All origins allowed
* Methods: `GET, POST, PUT, PATCH, DELETE, OPTIONS, HEAD, CONNECT, TRACE`
* All request and response headers allowed
* Preflight max-age: 3600 seconds
This matches both the current Supabase platform behavior and the previous Kong-based gateway. The auth boundary for Supabase APIs is the `apikey` header rather than the request origin.
If you customize the `cors:` block in `lds.template.yaml` to enable `allow_credentials: true`, you must restrict `allow_origin_string_match` to specific origins - browsers (and Envoy) reject the combination of credentials with a wildcard origin.
## Security hardening
The gateway is configured with these production-oriented settings:
| Setting | Purpose |
| ----------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `normalize_path: true`, `merge_slashes: true` | Prevents path-confusion bypass of RBAC prefix rules |
| `path_with_escaped_slashes_action: REJECT_REQUEST` | Rejects requests that contain URL-encoded slashes in the path |
| `use_remote_address: true` | Treats Envoy as an edge proxy: uses the peer connection IP as the trusted client address (rather than trusting client-supplied `X-Forwarded-For`) and strips untrusted `x-envoy-*` request headers |
| `headers_with_underscores_action: REJECT_REQUEST` | Blocks header smuggling attacks that exploit underscore-vs-hyphen normalization |
| `per_connection_buffer_limit_bytes: 32768` | Caps per-connection buffer memory to 32 KiB |
| `max_active_downstream_connections: 30000` | Overload manager limit on total downstream connections |
| Admin interface bound to `127.0.0.1:9901` | The admin API is reachable only from inside the container, not from other containers or the host |
| Image pinned to `envoyproxy/envoy:v1.37.2` (or newer) | Includes published security patches for Envoy 1.37.x |
The Envoy admin interface at `127.0.0.1:9901` exposes `/config_dump`, which contains the fully rendered configuration including all API keys, JWTs, and the basic auth hash in plaintext. Never expose port 9901 to other containers or to the host.
The gateway listens on plain HTTP only and does not terminate TLS. For public deployments, terminate TLS at an upstream reverse proxy - the Docker setup ships `docker-compose.caddy.yml` and `docker-compose.nginx.yml` for this purpose.
## Customizing the configuration
All routing, filter, and cluster changes are made in the YAML files under `./volumes/api/envoy/`.
* **Adding or modifying routes.** Edit `lds.template.yaml`. Routes are ordered - place new routes before the catch-all `/` route to ensure they match. Keep per-route `basic_auth: disabled` for API routes and set an appropriate RBAC override if the route should bypass the global policy.
* **Adding a new upstream service.** Add a cluster definition to `cds.yaml` with the service's DNS name and port, then reference it from a route's `cluster:` field.
* **Adding a new environment variable.** Placeholders in the template use the `${VAR_NAME}` form. If you add a placeholder, update both `docker-compose.envoy.yml` (to pass the variable into the container) and `docker-entrypoint.sh` (to substitute it with `sed`).
* **Applying changes.** Envoy reads the rendered `lds.yaml` from the filesystem. Configuration changes require restarting the container so the entrypoint re-renders the template:
```sh
docker compose -f docker-compose.yml -f docker-compose.envoy.yml restart api-gw
```
This guide does not cover Envoy's route, filter, and cluster reference. See the [Envoy documentation](https://www.envoyproxy.io/docs/envoy/latest/) for the full configuration surface.
## Admin interface
Envoy exposes an admin interface on `127.0.0.1:9901` inside the container, with endpoints like `/ready`, `/clusters`, `/stats`, and `/config_dump`. The standard `envoyproxy/envoy` image is minimal (no `curl` or `wget`), so the admin endpoints are not reachable via `docker exec` without adding tooling.
The simplest way to query the admin interface during debugging is to run a short-lived `curl` container that joins the same network namespace as `supabase-envoy`:
```sh
docker run --rm --network container:supabase-envoy curlimages/curl http://127.0.0.1:9901/clusters
```
```sh
docker run --rm --network container:supabase-envoy curlimages/curl http://127.0.0.1:9901/stats
```
```sh
docker run --rm --network container:supabase-envoy curlimages/curl http://127.0.0.1:9901/config_dump
```
`/config_dump` includes secrets in plaintext. Never expose port `9901` to a public network or untrusted host, and never share its output without first removing secrets.
## Troubleshooting
### Logs
Envoy writes access logs and filter output to stdout. View them with:
```sh
docker compose -f docker-compose.yml -f docker-compose.envoy.yml logs api-gw
```
The access log format is a standard combined log with the request method, original path, response code, and bytes sent.
### Common issues
* **`401 Unauthorized` on a protected route.** The `apikey` header is missing or does not match any configured key. Verify that the header value exactly matches one of `ANON_KEY`, `SERVICE_ROLE_KEY`, `SUPABASE_PUBLISHABLE_KEY`, or `SUPABASE_SECRET_KEY` in your `.env` file. Note that `SUPABASE_PUBLISHABLE_KEY` and `SUPABASE_SECRET_KEY` are only accepted when the new key configuration is fully set up - see [New API Keys and Asymmetric Authentication](/docs/guides/self-hosting/self-hosted-auth-keys).
* **`403 Forbidden` on `/pg/`.** The `/pg/` route requires a service\_role key (`SUPABASE_SECRET_KEY` or legacy `SERVICE_ROLE_KEY`). Anon and publishable keys are rejected.
* **`403 Forbidden` on `/api/mcp` or `/mcp`.** These routes are blocked by default. See [Enabling MCP Server Access](/docs/guides/self-hosting/enable-mcp).
* **`SignatureDoesNotMatch` on S3 requests to Storage.** Verify that the Storage service configuration in `docker-compose.yml` contains `REQUEST_ALLOW_X_FORWARDED_PATH=true` and `STORAGE_PUBLIC_URL`. Storage uses the `X-Forwarded-Prefix` header the gateway sends to reconstruct the original request path for SigV4 verification.
* **`400 Bad Request` with underscore headers.** `headers_with_underscores_action: REJECT_REQUEST` is enabled. Some clients send headers like `X_Forwarded_For` with underscores; these are rejected. Use hyphens in header names.
## See also
* [New API Keys and Asymmetric Authentication](/docs/guides/self-hosting/self-hosted-auth-keys) - Background on opaque keys and asymmetric JWTs
* [Configure Reverse Proxy and HTTPS](/docs/guides/self-hosting/self-hosted-proxy-https) - Caddy or Nginx in front of the gateway
* [Envoy documentation](https://www.envoyproxy.io/docs/envoy/latest/) - Filter, route, and cluster reference
# Self-Hosted Functions
Run and manage Edge Functions in your self-hosted Supabase instance.
Edge Functions work out of the box in a self-hosted Supabase setup. The `functions` service, API gateway routing, and a `hello` example function are all [pre-configured](https://github.com/supabase/supabase/tree/master/docker).
On managed Supabase platform, Edge Functions are deployed across multiple regions. Self-hosted standalone instance configuration resembles a standard serverless setup.
## Invoke the default function
The default `hello` function is located at `volumes/functions/hello/index.ts`. You can invoke it immediately after starting your stack:
```sh
curl http:///functions/v1/hello
```
This returns `"Hello from Edge Functions!"`.
## Create a new function
### Step 1: Add a new function directory and the function code
```sh
mkdir -p volumes/functions/my-function &&
touch volumes/functions/my-function/index.ts
```
Add the following code to `index.ts`:
```typescript
Deno.serve(async (req: Request) => {
const { name } = await req.json()
const message = `Hello, ${name}!`
return new Response(JSON.stringify({ message }), {
headers: { 'Content-Type': 'application/json' },
})
})
```
### Step 2: Restart the functions service to pick up the new function
```sh
docker compose restart functions --no-deps
```
### Step 3: Invoke your function
```sh
curl -X POST http:///functions/v1/my-function \
-H 'Content-Type: application/json' \
-d '{"name": "World"}'
```
You should be able to see the response from `my-function`:
```json
{ "message": "Hello, World!" }
```
## Custom environment variables
### Using an env file (recommended)
For multiple variables or secrets, create a separate env file, e.g., `.env.functions` in your `docker/` directory:
```
MY_CUSTOM_VAR=some-value
```
Add `env_file` to the `functions` service in `docker-compose.yml` (variables in `env_file` load first, then `environment` values take precedence):
```yaml name=docker-compose.yml
functions:
env_file:
- .env.functions
environment:
JWT_SECRET: ${JWT_SECRET}
SUPABASE_URL: http://kong:8000
```
Don't commit `.env.functions` to version control if it contains secrets. Add it to your `.gitignore`.
Restart the functions service:
```sh
docker compose up -d --force-recreate --no-deps functions
```
### Using inline environment variables
For one or two variables, you can add them directly under `environment` in `docker-compose.yml`:
```yaml name=docker-compose.yml
functions:
environment:
# Custom variables
MY_CUSTOM_VAR: ${MY_CUSTOM_VAR}
# Required variables
JWT_SECRET: ${JWT_SECRET}
SUPABASE_URL: http://kong:8000
```
Then define `MY_CUSTOM_VAR` in your main `.env` file, or specify the value directly.
### Accessing variables in functions
All container environment variables are forwarded to the function workers by `main/index.ts`. Access them with:
```typescript
const customVar = Deno.env.get('MY_CUSTOM_VAR')
```
## Calling Supabase services from functions
The functions service is pre-configured with the following environment variables:
| Variable | Value | Purpose |
| --------------------------- | --------------------------------- | ------------------------------------------------- |
| `SUPABASE_URL` | `http://kong:8000` | Internal API gateway URL |
| `SUPABASE_PUBLIC_URL` | `http(s)://` | Base URL for accessing Supabase from the Internet |
| `JWT_SECRET` | `your-jwt-secret` | Legacy symmetric encryption key for JWTs |
| `SUPABASE_ANON_KEY` | `your-anon-key` | Client-side API key (`anon` role). |
| `SUPABASE_SERVICE_ROLE_KEY` | `your-service-role-key` | Server-side API key (`service_role` role) |
| `SUPABASE_DB_URL` | `postgresql://...` | Postgres connection string |
| `SUPABASE_PUBLISHABLE_KEYS` | `{"default":"sb_publishable_...}` | New publishable API key |
| `SUPABASE_SECRET_KEYS` | `{"default":"sb_secret_...}` | New secret API key |
Here's an example function that queries a table using `@supabase/supabase-js`:
```typescript
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2'
Deno.serve(async () => {
const supabase = createClient(
Deno.env.get('SUPABASE_URL')!,
Deno.env.get('SUPABASE_SERVICE_ROLE_KEY')!
)
const { data, error } = await supabase.from('todos').select('*')
return new Response(JSON.stringify({ data, error }), {
headers: { 'Content-Type': 'application/json' },
})
})
```
### Internal vs external URLs
This is a key distinction that affects how you build URLs in your functions:
* **`SUPABASE_URL`** contains an internal Docker network hostname. Use it for server-side calls from your functions to other Supabase services (Auth, Storage, database via PostgREST). This is what the Supabase JS client should use inside functions.
* **`SUPABASE_PUBLIC_URL`** is the externally-reachable URL of your Supabase instance. Use it if your function needs to build URLs that HTTP clients can reach from the outside.
## Managing functions via dashboard
Self-hosted Studio [mounts](https://github.com/supabase/supabase/blob/df8729a82b1847e2989c14ede27965612761d503/docker/docker-compose.yml#L66) the same `volumes/functions` directory as the functions service. You can check what functions are available using **Edge Functions** > **Functions** UI.
## Deploying functions to a remote server
To deploy a function to a remote server running self-hosted Supabase, copy the function directory with `scp`:
```sh
scp -r ./my-function user@:/path/to/self-hosted/volumes/functions/
```
Then restart the functions service on the remote host:
```sh
ssh user@ 'cd /path/to/self-hosted && docker compose restart functions --no-deps'
```
## Copying functions from Supabase platform
If you have existing functions on Supabase platform, you can download them and run them on your self-hosted instance. There are two ways to get the function source code:
* **Dashboard** - open the function details in Dashboard and click **Download**.
* **Local development & CLI** - run `supabase functions download --project-ref [` to download the source.
Use `scp` to copy the function into `volumes/functions//` on your self-hosted instance, then restart the functions service.
For more details, see:
* [Quick start - Download edge functions](/docs/guides/functions/quickstart-dashboard#download-edge-functions)
* [CLI commands - Download a function](/docs/reference/cli/supabase-functions-download)
## Troubleshooting
### 400 "missing function name in request"
The request URL must include the function name after `/functions/v1/`. For example, `/functions/v1/hello` — not just `/functions/v1/`.
### 500 error on invocation
Check the functions service logs:
```sh
docker compose logs functions
```
Common causes: syntax errors in your function code, invalid imports, or missing dependencies.
### 401 "invalid JWT"
* Check that `FUNCTIONS_VERIFY_JWT` matches your intent (`true` or `false`) in `.env`
* If verification is enabled, ensure you're passing a valid token: `Authorization: Bearer `
### Changes to function code not reflected after editing
Restart the functions service:
```sh
docker compose restart functions --no-deps
```
### Custom env vars not available in functions
* Verify the variable is defined in `docker-compose.yml` (under `env_file` or `environment`)
* Recreate the functions container after changing configuration
* Check that the variable name matches exactly (case-sensitive)
Use the following command to recreate the container, not just `restart`:
```sh
docker compose up -d --force-recreate --no-deps functions
```
### Memory or timeout errors
The default limits are 150 MB memory and 60 seconds timeout per function invocation. These are set in `volumes/functions/main/index.ts`. To adjust them, edit the `memoryLimitMb` and `workerTimeoutMs` values and restart the functions service.
# Configure Social Login (OAuth) Providers
Set up social login (OAuth/OIDC) providers for self-hosted Supabase with Docker.
This guide covers the **server-side configuration** required to enable social login providers on a self-hosted Supabase instance running with Docker Compose. This applies to all OAuth and OIDC-based providers, including third-party identity providers like Keycloak.
## Before you begin
You need:
* A working self-hosted Supabase installation. See [Self-Hosting with Docker](/docs/guides/self-hosting/docker).
* `API_EXTERNAL_URL` set to the publicly reachable URL of your Supabase instance (e.g., `https://`).
HTTPS is required by most OAuth providers - `http://` callback URLs are rejected (except `localhost`). See the HTTPS [how-to guide](/docs/guides/self-hosting/self-hosted-proxy-https) for setup instructions.
Your **OAuth callback URL** should look like the following:
```
https:///auth/v1/callback
```
You will have to register this URL with each OAuth provider.
## OAuth request flow
When a user signs in with an OAuth provider, the following flow occurs:
1. Your app calls `supabase.auth.signInWithOAuth()` and the browser redirects to the Auth service
2. The API gateway routes the request to the Auth container (`/auth/v1/authorize`)
3. Auth redirects the user to the OAuth provider (e.g., Google) for consent
4. The provider redirects back to `https:///auth/v1/callback`
5. Auth exchanges the authorization code for tokens and redirects the user to your `SITE_URL` or an allowed redirect URL
## Auth environment variables
The Auth service (GoTrue) uses the prefix `GOTRUE_EXTERNAL_` followed by a provider name for all OAuth configuration. For example, when using Google:
* `GOTRUE_EXTERNAL_GOOGLE_ENABLED`
* `GOTRUE_EXTERNAL_GOOGLE_CLIENT_ID`
* `GOTRUE_EXTERNAL_GOOGLE_SECRET`
* `GOTRUE_EXTERNAL_GOOGLE_REDIRECT_URI`
## Step-by-step configuration
The default `.env.example` and `docker-compose.yml` include commented-out placeholders for Google, GitHub, and Azure.
### Step 1: Register your app with the provider
1. Go to the OAuth provider's developer console and create an application.
2. Set the **authorized redirect URL**, e.g., `https:///auth/v1/callback`
3. Copy the **client ID** and **client secret** into your `.env` file.
### Step 2: Configure environment variables
Uncomment the lines for your provider in `.env` and add your client ID and secret, e.g., for Google:
```sh
GOOGLE_ENABLED=true
GOOGLE_CLIENT_ID=your-client-id
GOOGLE_SECRET=your-client-secret
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Step 3: Enable the matching lines in Docker Compose configuration
Uncomment the corresponding `GOTRUE_EXTERNAL_` lines in the `auth` service's `environment`:
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_EXTERNAL_GOOGLE_ENABLED: ${GOOGLE_ENABLED}
GOTRUE_EXTERNAL_GOOGLE_CLIENT_ID: ${GOOGLE_CLIENT_ID}
GOTRUE_EXTERNAL_GOOGLE_SECRET: ${GOOGLE_SECRET}
GOTRUE_EXTERNAL_GOOGLE_REDIRECT_URI: ${API_EXTERNAL_URL}/auth/v1/callback
```
For providers **not** pre-configured in the files (see the [full provider list](#other-supported-providers) below), add the lines manually following the same pattern: variables in `.env`, passthrough with `GOTRUE_EXTERNAL_PROVIDER_` in `docker-compose.yml`.
### Step 4: Restart the auth service
```sh
docker compose up -d --force-recreate --no-deps auth
```
### Step 5: Verify the configuration
Check that the provider is enabled:
```sh
curl -H 'apikey: your-anon-key' https:///auth/v1/settings
```
The response should include your provider under `external`:
```json
{
"external": {
"google": true
}
}
```
## Provider-specific setup
**Google Cloud Console setup:**
1. Go to [Google Cloud Console](https://console.cloud.google.com/)
2. Create or select a project
3. Select **Solutions** > **All products** in the navigation menu on the left
4. Go to **APIs & services** > **OAuth consent screen** and click **Get started**
5. Follow the configuration steps and add an **External** app
6. Go to **APIs & Services** > **Credentials**
7. Click **Create Credentials** > **OAuth client ID**
8. Set application type to **Web application**
9. Under **Authorized redirect URIs**, add: `https:///auth/v1/callback`
10. Click **Create** and copy the client ID and client secret
```sh name=.env
GOOGLE_ENABLED=true
GOOGLE_CLIENT_ID=your-google-client-id.apps.googleusercontent.com
GOOGLE_SECRET=your-google-client-secret
```
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_EXTERNAL_GOOGLE_ENABLED: ${GOOGLE_ENABLED}
GOTRUE_EXTERNAL_GOOGLE_CLIENT_ID: ${GOOGLE_CLIENT_ID}
GOTRUE_EXTERNAL_GOOGLE_SECRET: ${GOOGLE_SECRET}
GOTRUE_EXTERNAL_GOOGLE_REDIRECT_URI: ${API_EXTERNAL_URL}/auth/v1/callback
```
**GitHub setup:**
1. Go to [GitHub Developer Settings](https://github.com/settings/developers)
2. Click **New OAuth app**
3. Fill in **Homepage URL**, e.g., `https://`
4. Set **Authorization callback URL** to: `https:///auth/v1/callback`
5. Click **Register application**
6. Copy the client ID, generate and copy a client secret
```sh name=.env
GITHUB_ENABLED=true
GITHUB_CLIENT_ID=your-github-client-id
GITHUB_SECRET=your-github-client-secret
```
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_EXTERNAL_GITHUB_ENABLED: ${GITHUB_ENABLED}
GOTRUE_EXTERNAL_GITHUB_CLIENT_ID: ${GITHUB_CLIENT_ID}
GOTRUE_EXTERNAL_GITHUB_SECRET: ${GITHUB_SECRET}
GOTRUE_EXTERNAL_GITHUB_REDIRECT_URI: ${API_EXTERNAL_URL}/auth/v1/callback
```
**Azure Portal setup:**
1. Go to [Azure Portal](https://portal.azure.com/)
2. Go to **All services** > **Identity** > **App registrations** via the navigation menu on the left
3. Click **New registration**
4. Add application **Name**
5. Under **Redirect URI**, select **Web** and enter: `https:///auth/v1/callback`
6. Click **Register**
7. Copy the **Application (client) ID**
8. Click on **Client credentials** > **Add a certificate or secret**
9. Click on **New client secret** and add a client secret
10. Copy the secret value (not "secret ID")
```sh name=.env
AZURE_ENABLED=true
AZURE_CLIENT_ID=your-azure-application-client-id
AZURE_SECRET=your-azure-client-secret
## Optional: restrict to a specific tenant (defaults to 'common')
# AZURE_URL=https://login.microsoftonline.com/your-tenant-id
```
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_EXTERNAL_AZURE_ENABLED: ${AZURE_ENABLED}
GOTRUE_EXTERNAL_AZURE_CLIENT_ID: ${AZURE_CLIENT_ID}
GOTRUE_EXTERNAL_AZURE_SECRET: ${AZURE_SECRET}
GOTRUE_EXTERNAL_AZURE_REDIRECT_URI: ${API_EXTERNAL_URL}/auth/v1/callback
## Optional: uncomment for tenant-specific Azure login
# GOTRUE_EXTERNAL_AZURE_URL: ${AZURE_URL}
```
**Apple Developer setup:**
1. Refer to [Apple Developer documentation](https://developer.apple.com/documentation/signinwithapple/configuring-your-environment-for-sign-in-with-apple) to learn how to enable App ID and create a Services ID
2. Create a private key for sign in with Apple
3. Generate a client secret JWT from your private key. See [Apple Developer documentation](https://developer.apple.com/documentation/accountorganizationaldatasharing/creating-a-client-secret) for details.
```sh name=.env
APPLE_ENABLED=true
APPLE_CLIENT_ID=com.example.your-services-id
APPLE_SECRET=your-generated-jwt-client-secret
```
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_EXTERNAL_APPLE_ENABLED: ${APPLE_ENABLED}
GOTRUE_EXTERNAL_APPLE_CLIENT_ID: ${APPLE_CLIENT_ID}
GOTRUE_EXTERNAL_APPLE_SECRET: ${APPLE_SECRET}
GOTRUE_EXTERNAL_APPLE_REDIRECT_URI: ${API_EXTERNAL_URL}/auth/v1/callback
```
Apple uses `response_mode=form_post` for its OAuth flow. The Auth service handles this automatically - no additional configuration is needed.
**Keycloak setup:**
1. Open your Keycloak admin console
2. Select (or create) the realm you want to use
3. Go to **Clients** > **Create client**
4. Set **Client type** to **OpenID Connect**
5. Set **Client ID** (e.g., `supabase`)
6. On the next screen, enable **Client authentication**
7. Under **Valid redirect URIs**, add: `https:///auth/v1/callback`
8. Save, then go to the **Credentials** tab and copy the **Client secret**
```sh name=.env
KEYCLOAK_ENABLED=true
KEYCLOAK_CLIENT_ID=supabase
KEYCLOAK_SECRET=your-keycloak-client-secret
## Required: your Keycloak realm URL
KEYCLOAK_URL=https://keycloak.example.com/realms/myrealm
```
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_EXTERNAL_KEYCLOAK_ENABLED: ${KEYCLOAK_ENABLED}
GOTRUE_EXTERNAL_KEYCLOAK_CLIENT_ID: ${KEYCLOAK_CLIENT_ID}
GOTRUE_EXTERNAL_KEYCLOAK_SECRET: ${KEYCLOAK_SECRET}
GOTRUE_EXTERNAL_KEYCLOAK_REDIRECT_URI: ${API_EXTERNAL_URL}/auth/v1/callback
GOTRUE_EXTERNAL_KEYCLOAK_URL: ${KEYCLOAK_URL}
```
`KEYCLOAK_URL` is **required**. It must be the full realm URL (e.g., `https://keycloak.example.com/realms/myrealm`). The Auth service uses this to discover the OIDC endpoints (`.well-known/openid-configuration`). Without it, Keycloak login will not work.
## Other supported providers
Supabase Auth supports the following OAuth providers:
| Provider | Env prefix | Additional variables | Docs |
| ----------------- | ---------------- | ------------------------------- | --------------------------------------------------------------------- |
| Apple | `APPLE_` | - | [Login with Apple](/docs/guides/auth/social-login/auth-apple) |
| Azure (Microsoft) | `AZURE_` | `URL` (tenant URL) | [Login with Azure](/docs/guides/auth/social-login/auth-azure) |
| Bitbucket | `BITBUCKET_` | - | [Login with Bitbucket](/docs/guides/auth/social-login/auth-bitbucket) |
| Discord | `DISCORD_` | - | [Login with Discord](/docs/guides/auth/social-login/auth-discord) |
| Facebook | `FACEBOOK_` | - | [Login with Facebook](/docs/guides/auth/social-login/auth-facebook) |
| Figma | `FIGMA_` | - | [Login with Figma](/docs/guides/auth/social-login/auth-figma) |
| GitHub | `GITHUB_` | `URL` (for GitHub Enterprise) | [Login with GitHub](/docs/guides/auth/social-login/auth-github) |
| GitLab | `GITLAB_` | `URL` (for self-hosted GitLab) | [Login with GitLab](/docs/guides/auth/social-login/auth-gitlab) |
| Google | `GOOGLE_` | - | [Login with Google](/docs/guides/auth/social-login/auth-google) |
| Kakao | `KAKAO_` | - | [Login with Kakao](/docs/guides/auth/social-login/auth-kakao) |
| Keycloak (OIDC) | `KEYCLOAK_` | `URL` (realm URL, **required**) | [Login with Keycloak](/docs/guides/auth/social-login/auth-keycloak) |
| LinkedIn (OIDC) | `LINKEDIN_OIDC_` | - | [Login with LinkedIn](/docs/guides/auth/social-login/auth-linkedin) |
| Notion | `NOTION_` | - | [Login with Notion](/docs/guides/auth/social-login/auth-notion) |
| Slack (OIDC) | `SLACK_OIDC_` | - | [Login with Slack](/docs/guides/auth/social-login/auth-slack) |
| Snapchat | `SNAPCHAT_` | - | - |
| Spotify | `SPOTIFY_` | - | [Login with Spotify](/docs/guides/auth/social-login/auth-spotify) |
| Twitch | `TWITCH_` | - | [Login with Twitch](/docs/guides/auth/social-login/auth-twitch) |
| Twitter | `TWITTER_` | - | [Login with Twitter](/docs/guides/auth/social-login/auth-twitter) |
| WorkOS | `WORKOS_` | - | [Login with WorkOS](/docs/guides/auth/social-login/auth-workos) |
| Zoom | `ZOOM_` | - | [Login with Zoom](/docs/guides/auth/social-login/auth-zoom) |
For each provider, you need at minimum `ENABLED`, `CLIENT_ID`, `SECRET`, and `REDIRECT_URI` in `.env` and `docker-compose.yml`.
**LinkedIn (OIDC)** and **Slack (OIDC)** use multi-word env prefixes. The full Docker Compose variables are `GOTRUE_EXTERNAL_LINKEDIN_OIDC_CLIENT_ID` and `GOTRUE_EXTERNAL_SLACK_OIDC_CLIENT_ID` respectively - not `LINKEDIN_CLIENT_ID` or `SLACK_CLIENT_ID`.
## Test the login flow
You can test OAuth with the following minimal HTML page:
* Save the code below to `index.html`
* Start `python -m http.server 3000` in the same directory
* Make sure `SITE_URL` is set to `http://localhost:3000` in your self-hosted Supabase `.env` configuration
* Open your browser and go to `http://localhost:3000`
```html
]Supabase OAuth Test
```
For detailed client-side integration, see [Social Login](/docs/guides/auth/social-login).
## Troubleshooting
### "Provider not enabled" or provider seen as false in settings
* Check that `GOTRUE_EXTERNAL_*_ENABLED` is set to `true` in `docker-compose.yml`
* Verify the `.env` variable is not empty, e.g., check with `docker compose exec auth env | grep GOOGLE`
### Variables added to the environment but provider still not working
Configuration variables from `.env` are **not** automatically available inside the container unless there's a matching passthrough definition in `docker-compose.yml`. Check, e.g., for:
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_EXTERNAL_GOOGLE_ENABLED: ${GOOGLE_ENABLED}
```
Run `docker compose exec auth env | grep GOTRUE_EXTERNAL` to verify the variables are reaching the container.
### Site URL or redirect URL errors after login
After a successful OAuth login, the Auth service redirects to `SITE_URL` or a URL from `ADDITIONAL_REDIRECT_URLS`. Ensure:
* `SITE_URL` in `.env` is set to your application's URL
* If your app uses a different redirect URL, add it to `ADDITIONAL_REDIRECT_URLS` (comma-separated)
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Nonce check failure on mobile (Google Sign In)
When using Google Sign In on mobile with ID tokens, nonce verification may fail because mobile SDKs don't always support the nonce flow that the Auth service expects.
`GOTRUE_EXTERNAL_SKIP_NONCE_CHECK` disables nonce validation on ID tokens, which weakens replay-attack protection. Treat it as a **short-lived troubleshooting workaround**, not a permanent fix:
* Enable it only in the environment where you're debugging the issue.
* Revert it as soon as the issue is resolved.
* Prefer fixing the client-side nonce handling or switching to an OAuth flow (authorization code with PKCE) that avoids ID-token nonce issues entirely.
To enable it, uncomment the following line in `docker-compose.yml`:
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_EXTERNAL_SKIP_NONCE_CHECK: 'true'
```
### Auth service fails to start
Check the auth container logs:
```sh
docker compose logs auth
```
Common causes:
* Missing required environment variable (e.g., `CLIENT_ID` or `SECRET` is empty)
* Invalid `API_EXTERNAL_URL` (must be a valid URL with protocol)
## Environment variable reference
All OAuth-related environment variables for the `auth` service in `docker-compose.yml`:
| Variable | Description | Required |
| -------------------------------- | ------------------------------------------------------------------------ | -------- |
| `GOTRUE_EXTERNAL_*_ENABLED` | Enable the provider (`true`/`false`) | Yes |
| `GOTRUE_EXTERNAL_*_CLIENT_ID` | OAuth client ID from the provider | Yes |
| `GOTRUE_EXTERNAL_*_SECRET` | OAuth client secret from the provider | Yes |
| `GOTRUE_EXTERNAL_*_REDIRECT_URI` | Callback URL: `${API_EXTERNAL_URL}/auth/v1/callback` | Yes |
| `GOTRUE_SITE_URL` | Default redirect URL after authentication (set via `SITE_URL` in `.env`) | Yes |
## Additional resources
* [Redirect URLs](/docs/guides/auth/redirect-urls)
* [Auth server on GitHub](https://github.com/supabase/auth) (check README and `example.env`)
# Configure Phone Login & MFA
Set up phone login SMS providers, OTP settings, and multi-factor authentication for self-hosted Supabase with Docker.
This guide covers the **server-side configuration** for phone login and multi-factor authentication (MFA) on a self-hosted Supabase instance running with Docker Compose.
For client-side implementation, see [Phone Login](/docs/guides/auth/phone-login) and [Multi-Factor Authentication](/docs/guides/auth/auth-mfa).
## Before you begin
You need:
* A working self-hosted Supabase installation. See [Self-Hosting with Docker](/docs/guides/self-hosting/docker).
* An account with an SMS provider (e.g., Twilio)
Phone auth is **enabled by default** in the Docker setup (`ENABLE_PHONE_SIGNUP=true` in `.env`). However, without an SMS provider configured, the Auth service has no way to deliver OTP codes.
## SMS provider configuration
The default `.env.example` and `docker-compose.yml` include commented-out SMS provider placeholders. The example below uses Twilio - you'll need a Twilio account with an account SID, auth token, and message service SID. See [Twilio's documentation](https://www.twilio.com/docs/messaging) for how to obtain these credentials.
To enable SMS delivery:
### Step 1: Uncomment and configure the environment variables
Edit the `.env` file as follows:
```sh name=.env
SMS_PROVIDER=twilio
SMS_OTP_EXP=60
SMS_OTP_LENGTH=6
SMS_MAX_FREQUENCY=60s
SMS_TEMPLATE=Your code is {{ .Code }}
## Twilio credentials
SMS_TWILIO_ACCOUNT_SID=your-account-sid
SMS_TWILIO_AUTH_TOKEN=your-auth-token
SMS_TWILIO_MESSAGE_SERVICE_SID=your-message-service-sid
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Step 2: Uncomment the matching lines in Docker Compose configuration
Uncomment the `GOTRUE_SMS_*` lines in the `auth` service's `environment` block:
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
GOTRUE_SMS_PROVIDER: ${SMS_PROVIDER}
GOTRUE_SMS_OTP_EXP: ${SMS_OTP_EXP}
GOTRUE_SMS_OTP_LENGTH: ${SMS_OTP_LENGTH}
GOTRUE_SMS_MAX_FREQUENCY: ${SMS_MAX_FREQUENCY}
GOTRUE_SMS_TEMPLATE: ${SMS_TEMPLATE}
GOTRUE_SMS_TWILIO_ACCOUNT_SID: ${SMS_TWILIO_ACCOUNT_SID}
GOTRUE_SMS_TWILIO_AUTH_TOKEN: ${SMS_TWILIO_AUTH_TOKEN}
GOTRUE_SMS_TWILIO_MESSAGE_SERVICE_SID: ${SMS_TWILIO_MESSAGE_SERVICE_SID}
```
### Step 3: Restart the auth service
```sh
docker compose up -d --force-recreate --no-deps auth
```
### Step 4: Verify
```sh
docker compose exec auth env | grep GOTRUE_SMS
```
Confirm your provider and credentials appear in the output.
For providers other than Twilio, add the provider-specific `GOTRUE_SMS_*` lines manually to `docker-compose.yml`.
## OTP settings
### Expiration
The default OTP expiration is **60 seconds**. This is often too short for production use, consider increasing it.
Set `SMS_OTP_EXP` in `.env` (value is in seconds):
```sh name=.env
# Set expiration to 5 minutes
SMS_OTP_EXP=300
```
And ensure `GOTRUE_SMS_OTP_EXP: ${SMS_OTP_EXP}` is uncommented in `docker-compose.yml`.
### Length
The default OTP length is 6 digits. You can set it to any value between 6 and 10:
```sh name=.env
SMS_OTP_LENGTH=8
```
### Rate limiting
`SMS_MAX_FREQUENCY` controls the minimum interval between SMS sends to the same phone number. The default is 60 seconds:
```sh name=.env
## Allow one SMS every 30 seconds
SMS_MAX_FREQUENCY=30s
```
## Test OTPs for development
To avoid sending real SMS during development, use `SMS_TEST_OTP` to map phone numbers to fixed OTP codes:
```sh name=.env
SMS_TEST_OTP=16505551234:123456,16505555678:654321
```
Make sure to also uncomment `GOTRUE_SMS_TEST_OTP: ${SMS_TEST_OTP}` in `docker-compose.yml`.
When a test phone number requests an OTP, the Auth service skips SMS delivery and accepts only the mapped code. Other phone numbers continue to use the real SMS provider.
Remove test OTPs before deploying to production. You can also set an expiration with `SMS_TEST_OTP_VALID_UNTIL` (ISO 8601 datetime, e.g., `2026-12-31T23:59:59Z`) so they stop working automatically.
## Multi-factor authentication (MFA)
The Auth service supports three MFA factor types. Configure them by uncommenting variables in `.env` and the matching `GOTRUE_MFA_*` lines in `docker-compose.yml`.
### App authenticator (TOTP)
TOTP is **enabled by default** - users can enroll with apps like Google Authenticator or Authy without any additional configuration.
To disable TOTP:
```sh name=.env
MFA_TOTP_ENROLL_ENABLED=false
MFA_TOTP_VERIFY_ENABLED=false
```
### Phone MFA
Phone MFA is **disabled by default** (opt-in). It uses the same SMS provider configuration as phone login.
To enable:
```sh name=.env
MFA_PHONE_ENROLL_ENABLED=true
MFA_PHONE_VERIFY_ENABLED=true
```
### Maximum enrolled factors
By default, a user can enroll up to 10 MFA factors. To change this:
```sh name=.env
MFA_MAX_ENROLLED_FACTORS=5
```
## Troubleshooting
### OTP expires too quickly
The default `SMS_OTP_EXP` is 60 seconds. Increase it in `.env`:
```sh name=.env
SMS_OTP_EXP=300
```
Ensure `GOTRUE_SMS_OTP_EXP: ${SMS_OTP_EXP}` is uncommented in `docker-compose.yml`, then restart:
```sh
docker compose up -d --force-recreate --no-deps auth
```
### SMS not being delivered
Check the auth container logs for errors:
```sh
docker compose logs auth --tail 50
```
Verify provider credentials reach the container:
```sh
docker compose exec auth env | grep GOTRUE_SMS
```
Common causes:
* Provider credentials are in `.env` but the matching `GOTRUE_SMS_*` line is still commented out in `docker-compose.yml`
* Provider credentials are wrong
* Phone number format is wrong (use E.164 format: `+1234567890`)
### Variables added to the environment but not working
Configuration variables from `.env` are **not** automatically available inside the container unless there's a matching passthrough definition in `docker-compose.yml`. Check, e.g., for:
```sh
docker compose exec auth env | grep -E 'GOTRUE_SMS|GOTRUE_MFA'
```
After changing the configuration environment variables, recreate the Auth service container:
```sh
docker compose up -d --force-recreate --no-deps auth
```
### Rate limit errors
If users see "rate limit exceeded" errors, check `SMS_MAX_FREQUENCY` (minimum interval between sends) and the global rate limit `GOTRUE_RATE_LIMIT_SMS_SENT` (default: 30 per hour).
### Additional resources
* [Multi-Factor Authentication (Phone)](/docs/guides/auth/auth-mfa/phone)
* [Multi-Factor Authentication (TOTP)](/docs/guides/auth/auth-mfa/totp)
* [Auth server on GitHub](https://github.com/supabase/auth) (check README and `example.env`)
# Configure Reverse Proxy and HTTPS
Set up a reverse proxy with HTTPS for self-hosted Supabase.
HTTPS is required for production self-hosted Supabase deployments. This guide covers two production approaches using a reverse proxy in front of self-hosted Supabase API gateway, plus a self-signed certificate option for development environment.
## Before you begin
You need:
* A working self-hosted Supabase installation. See [Self-Hosting with Docker](/docs/guides/self-hosting/docker)
* A domain name with DNS pointing to your server's public IP address (to obtain Let's Encrypt certificate)
* Ports 80 and 443 open
## Set up HTTPS
Below are two options for adding a reverse proxy with automatic HTTPS in front of your self-hosted Supabase: **Caddy** (simpler, zero-config TLS) and **Nginx + Let's Encrypt** (more control over proxy settings). Both sit in front of the API gateway and terminate TLS, so internal traffic stays on HTTP.
If you already run [HAProxy](https://www.haproxy.com/), [Traefik](https://traefik.io/), [Nginx Proxy Manager](https://nginxproxymanager.com/), or another reverse proxy for your infrastructure, you can use it instead of Caddy or Nginx above. The key requirements are:
* Proxy to the API gateway on port `8000` (or `:8000` if the proxy runs outside the Docker network)
* Enable WebSocket support (required for Realtime)
* Add `X-Forwarded` headers to all requests
* Comment out the API gateway's host port bindings in `docker-compose.yml` if the proxy runs in the same Docker network
* Update `SUPABASE_PUBLIC_URL`, `API_EXTERNAL_URL`, and `SITE_URL` in `.env` to your HTTPS URL
* See `volumes/proxy` for example proxy configuration files
Envoy is an optional [API gateway](/docs/guides/self-hosting/self-hosted-envoy), enabled via the `docker-compose.envoy.yml` override. If you already run Envoy instead of Kong, edit `docker-compose.caddy.yml` or `docker-compose.nginx.yml` to comment out the `kong:` block and uncomment the `api-gw:` block (and the matching `depends_on` entry) so the reverse proxy sits in front of Envoy.
### Step 1: Update environment variables
Update the URL configuration in your `.env` file to use your HTTPS domain:
```sh name=.env
SUPABASE_PUBLIC_URL=https://
API_EXTERNAL_URL=https://
SITE_URL=https://
```
For Nginx, change the following to your domain name and a **valid** email address:
```sh name=.env
PROXY_DOMAIN=your-domain.example.com
CERTBOT_EMAIL=admin@your-domain.example.com
```
### Step 2: Start the reverse proxy
Pick one of the options below and use the corresponding Docker Compose override.
[Caddy](https://caddyserver.com/) automatically provisions and renews Let's Encrypt TLS certificates with zero configuration. It also handles HTTP-to-HTTPS redirects, WebSocket upgrades, and HTTP/2 and HTTP/3 out of the box.
Start Caddy by using the pre-configured `docker-compose.caddy.yml` override:
```sh
docker compose -f docker-compose.yml -f docker-compose.caddy.yml up -d
```
Caddy configuration is in `volumes/proxy/caddy/Caddyfile`.
This option uses a third-party Nginx Docker image ([`jonasal/nginx-certbot`](https://github.com/JonasAlfredsson/docker-nginx-certbot)), which includes Certbot for automatic Let's Encrypt certificate issuance and renewal in a single container.
Start Nginx by using the pre-configured `docker-compose.nginx.yml` override:
```sh
docker compose -f docker-compose.yml -f docker-compose.nginx.yml up -d
```
Nginx configuration template is in `volumes/proxy/nginx/supabase-nginx.conf.tpl`. On container startup, `${NGINX_SERVER_NAME}` is substituted using the environment variable from the `.env` file. The [`jonasal/nginx-certbot`](https://github.com/JonasAlfredsson/docker-nginx-certbot) image reads the resolved `server_name` to determine which domain to request a Let's Encrypt certificate for.
HTTP-to-HTTPS redirects are handled automatically by the `jonasal/nginx-certbot` image.
### Step 3: Verify HTTPS connection
Test the HTTPS connection - you should get a `401` response confirming you could connect to Auth:
```sh
curl -I https:///auth/v1/
```
Check container logs if needed (use `supabase-nginx` for Nginx):
```sh
docker logs supabase-caddy
```
## Self-signed certificates (development only)
Self-signed certificates trigger browser warnings and are rejected by most OAuth providers. Use this approach only in development environment or internal networks.
For development or internal networks where you cannot use Let's Encrypt, here's how you can configure Kong (the current default API gateway) to serve HTTPS directly using self-signed certificates.
### Step 1: Generate a self-signed certificate
Change `` in the example below, and create certificates with `openssl`:
```sh
openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout volumes/api/server.key \
-out volumes/api/server.crt \
-subj "/CN=" && \
chmod 640 volumes/api/server.key && \
chgrp 65533 volumes/api/server.key
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Step 2: Configure Kong for SSL
Comment out Kong's **HTTP** port mapping in `docker-compose.yml`:
```yaml name=docker-compose.yml
kong:
# ...
ports:
#- ${KONG_HTTP_PORT}:8000/tcp
```
Uncomment the certificate volume mounts and SSL environment variables in `docker-compose.yml`:
```yaml name=docker-compose.yml
kong:
# ... existing configuration ...
volumes:
- ./volumes/api/kong.yml:/home/kong/temp.yml:ro,z
- ./volumes/api/server.crt:/home/kong/server.crt:ro
- ./volumes/api/server.key:/home/kong/server.key:ro
environment:
# ... existing environment variables ...
KONG_SSL_CERT: /home/kong/server.crt
KONG_SSL_CERT_KEY: /home/kong/server.key
```
### Step 3: Update configuration variables
Edit your `.env` file to use HTTPS with the Kong HTTPS port:
```sh name=.env
SUPABASE_PUBLIC_URL=https://:8443
API_EXTERNAL_URL=https://:8443
SITE_URL=https://:8443
```
### Step 4: Restart and verify
```sh
docker compose down && docker compose up -d
```
```sh
curl -I -k https://:8443/auth/v1/
```
The `-k` flag tells curl to accept the self-signed certificate.
## Troubleshooting
### Certificate not issued
If Caddy or Certbot fails to obtain a certificate:
* Verify that ports 80 and 443 are open on your firewall
* Verify that your domain's DNS A record points to your server's public IP
* Check proxy logs via `docker logs supabase-caddy` or `docker logs supabase-nginx`
* Let's Encrypt has [rate limits](https://letsencrypt.org/docs/rate-limits/) - if you hit them, wait before retrying
### WebSocket connection failed
If Realtime subscriptions fail to connect:
* **Caddy** handles WebSocket upgrades automatically - check that the API gateway is healthy
* **Nginx** requires explicit `Upgrade` and `Connection` headers on the `/realtime/v1/` location. Verify your `nginx.conf` includes these headers as shown above
### OAuth callback URL mismatch
If OAuth redirects fail with a callback URL error:
* Verify `API_EXTERNAL_URL` in `.env` is set to your HTTPS URL
* Verify the callback URL registered with your OAuth provider matches `API_EXTERNAL_URL` followed by `/auth/v1/callback`
* After changing `API_EXTERNAL_URL`, restart all services with `docker compose down && docker compose up -d`
### Mixed content warnings
If the browser console shows mixed content errors:
* Verify `SUPABASE_PUBLIC_URL` is set to your HTTPS URL
* Verify `SITE_URL` is also set to HTTPS
* Clear your browser cache after making changes
### ERR\_CERT\_AUTHORITY\_INVALID
This is expected when using self-signed certificates. For production, use Caddy or Nginx with Let's Encrypt. If you need to use self-signed certificates, add the certificate to your system's trust store or use a browser flag to bypass the warning.
## Additional resources
* [Caddy documentation](https://caddyserver.com/docs/)
* [Nginx documentation](https://nginx.org/en/docs/) (on nginx.org)
* [docker-nginx-certbot on GitHub](https://github.com/JonasAlfredsson/docker-nginx-certbot)
# Configure S3 Storage
Enable S3-compatible client endpoint and set up an S3 backend for self-hosted Supabase Storage.
Self-hosted Supabase Storage has two independent S3-related features:
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* **S3 protocol endpoint** - an S3-compatible API that Storage exposes at `/storage/v1/s3`. This allows standard S3 tools like `rclone` and the AWS CLI to interact with your Storage instance.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* **S3 backend** - where Storage keeps data. By default, files are stored on the local filesystem. You can switch to an S3-compatible service (AWS S3, MinIO, etc.) for durability, scalability, or to use existing infrastructure.
You can configure either feature independently. For example, you can enable the S3 protocol endpoint to use `rclone` while keeping the default file-based storage, or switch to an S3 backend without enabling the S3 protocol endpoint.
## Enable the S3 protocol endpoint
The S3 protocol endpoint at `/storage/v1/s3` allows standard S3 clients to interact with your self-hosted Storage instance. It works with any storage backend, including the default file-based storage - you do not need to configure an S3 backend first. The Supabase REST API and SDK do not use the S3 protocol.
Make sure to check that `REGION`, `S3_PROTOCOL_ACCESS_KEY_ID` and `S3_PROTOCOL_ACCESS_KEY_SECRET` are properly configured in your `.env` file. Read more about the secrets and passwords in [Configuring and securing Supabase](/docs/guides/self-hosting/docker#configuring-and-securing-supabase).
```yaml name=docker-compose.yml
storage:
environment:
# ... existing variables ...
REGION: ${REGION}
S3_PROTOCOL_ACCESS_KEY_ID: ${S3_PROTOCOL_ACCESS_KEY_ID}
S3_PROTOCOL_ACCESS_KEY_SECRET: ${S3_PROTOCOL_ACCESS_KEY_SECRET}
```
### Test with the AWS CLI
```sh
( set -a && \
source .env > /dev/null 2>&1 && \
echo "" && \
AWS_ACCESS_KEY_ID=$S3_PROTOCOL_ACCESS_KEY_ID \
AWS_SECRET_ACCESS_KEY=$S3_PROTOCOL_ACCESS_KEY_SECRET \
aws s3 ls \
--endpoint-url http://localhost:8000/storage/v1/s3 \
--region $REGION \
s3://your-storage-bucket )
```
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
### Test with rclone
```sh
( set -a && \
source .env > /dev/null 2>&1 && \
echo "" && \
rclone ls \
--s3-endpoint http://localhost:8000/storage/v1/s3 \
--s3-region $REGION \
--s3-provider Other \
--s3-access-key-id "$S3_PROTOCOL_ACCESS_KEY_ID" \
--s3-secret-access-key "$S3_PROTOCOL_ACCESS_KEY_SECRET" \
:s3:your-storage-bucket )
```
Use `aws login` and `rclone config` for persistent configuration.
## How to configure an S3 backend
In general, the following configuration variables define S3 backend configuration for Storage in `docker-compose.yml`:
```yaml name=docker-compose.yml
storage:
environment:
# ... existing variables ...
STORAGE_BACKEND: s3
GLOBAL_S3_BUCKET: your-s3-bucket-or-dirname
GLOBAL_S3_ENDPOINT: https://your-s3-endpoint
GLOBAL_S3_PROTOCOL: https
GLOBAL_S3_FORCE_PATH_STYLE: 'true'
AWS_ACCESS_KEY_ID: your-access-key-id
AWS_SECRET_ACCESS_KEY: your-secret-access-key
REGION: your-region
```
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
Depending on your setup, you may need to adjust these values - for example, to use a local S3-compatible service like RustFS, MinIO or a cloud provider like AWS.
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
### Using RustFS
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
An override `docker-compose.rustfs.yml` can be added to enable RustFS container and provide an S3-compatible API for Storage backend:
```sh
docker compose -f docker-compose.yml -f docker-compose.rustfs.yml up -d
```
Make sure to review the Storage section in your `.env` file for related configuration options.
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
### Using MinIO
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
MinIO no longer publishes open source Docker images or maintains their open source repository. The MinIO configuration is provided for backward compatibility and uses images built by [Chainguard](https://images.chainguard.dev/directory/image/minio/overview) (`cgr.dev/chainguard/minio`). For new deployments, consider using [RustFS](#using-rustfs) instead.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
An override `docker-compose.s3.yml` can be added to enable MinIO container and provide an S3-compatible API for Storage backend:
```sh
docker compose -f docker-compose.yml -f docker-compose.s3.yml up -d
```
Make sure to review the Storage section in your `.env` file for related configuration options.
### Using AWS S3
Create an S3 bucket and an IAM user with access to it. Then configure the storage service:
```yaml name=docker-compose.yml
storage:
environment:
# ... existing variables ...
STORAGE_BACKEND: s3
GLOBAL_S3_BUCKET: your-aws-bucket-name
AWS_ACCESS_KEY_ID: your-aws-access-key
AWS_SECRET_ACCESS_KEY: your-aws-secret-key
REGION: your-aws-region
```
For AWS S3, you do not need `GLOBAL_S3_ENDPOINT` or `GLOBAL_S3_FORCE_PATH_STYLE` - the Storage S3 client automatically resolves the endpoint from the region and uses virtual-hosted-style URLs, which is what AWS S3 expects. These variables are only needed for non-AWS S3-compatible providers.
### S3-compatible providers
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
Use the same configuration as MinIO, but point to your provider's endpoint, e.g.:
```yaml name=docker-compose.yml
storage:
environment:
# ... existing variables ...
STORAGE_BACKEND: s3
GLOBAL_S3_BUCKET: your-bucket-name
GLOBAL_S3_ENDPOINT: https://your-account-id.r2.cloudflarestorage.com
```
## Verify
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* Open Studio and upload a file to a bucket. List the file using the AWS CLI or `rclone` to confirm the S3 endpoint works.
* If using an S3 backend: confirm the file appears in your S3 provider's console.
## Session token
You can authenticate to Supabase's S3-compatible storage using a user’s JWT to enforce Row-Level Security (RLS) across S3 operations. This is useful when initializing the S3 client on the server for a specific user session, or when using the client directly from the frontend.
All operations performed with a session token are scoped to the authenticated user, and any RLS policies defined in the storage schema will be applied.
To authenticate with S3 using a session token, provide the following credentials:
* **region:** value from the `REGION` environment variable in your `.env` file
* **access\_key\_id:** value from the `STORAGE_TENANT_ID` environment variable in your `.env` file
* **secret\_access\_key:** value from the `ANON_KEY` environment variable
* **session\_token:** a valid user JWT
Example using the `aws-sdk` library:
```javascript
import { S3Client } from '@aws-sdk/client-s3'
const {
data: { session },
} = await supabase.auth.getSession()
const client = new S3Client({
forcePathStyle: true,
region: 'stub', // REGION in .env
endpoint: 'http:///storage/v1/s3', // Edit
credentials: {
accessKeyId: 'stub', // STORAGE_TENANT_ID in .env
secretAccessKey: 'your-anon-key', // ANON_KEY in .env
sessionToken: session.access_token,
},
})
```
## Troubleshooting
### Signature mismatch errors
S3 clients sign requests using the access key ID and secret. If you see `SignatureDoesNotMatch`, verify that the `REGION`, `S3_PROTOCOL_ACCESS_KEY_ID` and `S3_PROTOCOL_ACCESS_KEY_SECRET` in your `.env` file match what your S3 client is using.
**If you use a custom reverse proxy**: with the [new API keys and auth](/docs/guides/self-hosting/self-hosted-auth-keys) configuration, requests to Storage should be forwarded to the API gateway for proper handling. If you are still using legacy API keys and proxy directly to Storage, make sure your proxy sets the `X-Forwarded-Prefix` header to `/storage/v1` so that signed URLs are generated correctly. In both cases, `STORAGE_PUBLIC_URL` must be [set properly](https://github.com/supabase/supabase/blob/a5f4a59e0e262394b345600e8d8a2241d6ac3b64/docker/docker-compose.yml#L369) in `docker-compose.yml`.
### TUS upload errors on Cloudflare R2
If resumable (TUS) uploads fail with HTTP 500 and a message about `x-amz-tagging`, add `TUS_ALLOW_S3_TAGS: "false"` to the storage service environment. Cloudflare R2 does not implement this S3 feature.
### Permission denied on uploads
Setting a bucket to "Public" only allows unauthenticated **downloads**. Uploads are always blocked unless you create an RLS policy on the `storage.objects` table. Go to **Storage** > **Files** > **Policies** in Studio and create a policy that allows `INSERT` for the appropriate roles.
### Upload URLs point to localhost
If uploads from a browser fail (CORS or mixed content errors), check that `API_EXTERNAL_URL` and `SUPABASE_PUBLIC_URL` in your `.env` file match your actual domain and protocol - not `http://localhost:8000`.
### Additional resources
* [Storage repository `.env.sample`](https://github.com/supabase/storage/blob/master/.env.sample)
* [S3 Authentication](/docs/guides/storage/s3/authentication)
# Configure SAML SSO
Set up SAML 2.0 Single Sign-On for self-hosted Supabase with Docker.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
SAML 2.0 SSO lets your users authenticate through an enterprise Identity Provider (IdP) such as Okta, Azure AD (Entra ID), Google Workspace, or any SAML 2.0-compliant provider. Unlike OAuth providers, SAML IdPs are not configured through environment variables - they are managed dynamically at runtime through the Auth admin API.
This guide covers the full setup: generating a signing key, enabling SAML in your Supabase instance, registering an IdP, and integrating SSO into your application.
Client-side integration uses the same `supabase.auth.signInWithSSO()` method documented in the [SSO with SAML 2.0](/docs/guides/auth/enterprise-sso/auth-sso-saml) guide. This guide focuses on the self-hosted server configuration.
## Before you begin
You need:
* A running self-hosted Supabase instance (see the [setup guide](/docs/guides/self-hosting/docker))
* Open SSL installed (for key generation)
* Your IdP's SAML metadata URL or metadata XML
* The `SERVICE_ROLE_KEY` from your `.env` file (needed for admin API calls)
* `API_EXTERNAL_URL` set to the publicly-accessible URL of your Supabase Auth service (e.g., `https://`). This URL is used as the SAML Service Provider entity ID and for constructing the ACS endpoint URL
## How SAML SSO works in Supabase
SAML SSO is configured in two layers:
1. **Global SAML enable (environment variables)** - a small set of env vars that enable the SAML engine and provide a signing key. These go in `.env` and `docker-compose.yml`.
2. **Per-IdP configuration (admin API)** - individual Identity Providers are registered, updated, and deleted at runtime via the Auth admin API. No restart is needed when adding or removing providers.
The login flow works as follows:
1. Your app calls `POST /auth/v1/sso` with a domain or provider\_id
2. Auth generates a SAML `AuthnRequest` and returns a redirect URL to the IdP
3. The user authenticates at the IdP
4. The IdP POSTs a SAML Response to `POST /sso/saml/acs`
5. Auth validates the assertion, creates or links the user, and issues a session
6. The user is redirected back to your app with session tokens
## Step 1: Generate an RSA private key
SAML requests must be signed. The value expected by `GOTRUE_SAML_PRIVATE_KEY` is a Base64-encoded PKCS#1 DER RSA private key (with a 2048-bit key as the minimum requirement). Generate it with:
```sh
openssl genpkey -algorithm RSA -out pk_pkcs8.pem -quiet && \
openssl pkey -in pk_pkcs8.pem -out pk_rsa1.der -outform DER -traditional && \
base64 -w 0 -i pk_rsa1.der
```
The commands above:
1. Generate an RSA private key in PKCS#8 PEM format
2. Convert the key to PKCS#1 DER format
3. Base64-encode the key for use as the value of `GOTRUE_SAML_PRIVATE_KEY`
Save the Base64 output - make sure to copy it as single line, ignoring the trailing newline. Remove the temporary files.
Keep this key secret. Anyone with the private key can forge SAML requests on behalf of your Service Provider. Do not commit it to the version control system.
For a production deployment, consider using a 4096-bit key by adding `-pkeyopt rsa_keygen_bits:4096` to the `openssl genpkey` command above.
## Step 2: Add environment variables
Add the following to your `.env` file:
```sh name=.env
############
# SAML SSO
############
SAML_ENABLED=true
SAML_PRIVATE_KEY=
# Optional: accept encrypted SAML assertions from IdPs (default: false)
# SAML_ALLOW_ENCRYPTED_ASSERTIONS=false
# Optional: how long relay state tokens remain valid (default: 2m0s)
# SAML_RELAY_STATE_VALIDITY_PERIOD=2m0s
# Optional: override the SAML entity ID / ACS base URL
# Defaults to API_EXTERNAL_URL if not set
# SAML_EXTERNAL_URL=https://supabase.example.com:8000
# Optional: rate limit on the ACS endpoint (requests per second, default: 15)
# SAML_RATE_LIMIT_ASSERTION=15
```
## Step 3: Pass SAML variables to the Auth container
In `docker-compose.yml`, add the SAML environment variables to the `auth` service. Auth expects the `GOTRUE_` prefix for all of its configuration variables:
```yaml name=docker-compose.yml
auth:
environment:
# ... existing variables ...
# SAML SSO
GOTRUE_SAML_ENABLED: ${SAML_ENABLED}
GOTRUE_SAML_PRIVATE_KEY: ${SAML_PRIVATE_KEY}
# GOTRUE_SAML_ALLOW_ENCRYPTED_ASSERTIONS: ${SAML_ALLOW_ENCRYPTED_ASSERTIONS}
# GOTRUE_SAML_RELAY_STATE_VALIDITY_PERIOD: ${SAML_RELAY_STATE_VALIDITY_PERIOD}
# GOTRUE_SAML_EXTERNAL_URL: ${SAML_EXTERNAL_URL}
# GOTRUE_SAML_RATE_LIMIT_ASSERTION: ${SAML_RATE_LIMIT_ASSERTION}
```
## Step 4: Restart the containers
Apply the configuration changes:
```sh
docker compose down && \
docker compose up -d
```
Verify the Auth service is healthy:
```sh
docker compose ps auth
```
## Step 5: Retrieve your service provider metadata
Once SAML is enabled, your Supabase instance exposes service provider (SP) metadata at `{API_EXTERNAL_URL}/sso/saml/metadata`.
Verify it using `curl`:
```sh
curl http:///sso/saml/metadata
```
This returns an XML document containing your SP entity ID, ACS endpoint URL, and signing certificate. You will need to provide this to your IdP.
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
Add `?download=true` to the request URL to get the metadata as a downloadable XML file with a 5-year validity period - this is useful for IdPs that require a file upload instead of a URL.
Key values in the metadata:
{/* supa-mdx-lint-disable Rule003Spelling */}
| Field | Value |
| ------------------- | -------------------------------------- |
| Entity ID | `{API_EXTERNAL_URL}/sso/saml/metadata` |
| ACS URL | `{API_EXTERNAL_URL}/sso/saml/acs` |
| NameID formats | `persistent`, `emailAddress` |
| Signing certificate | Derived from your `SAML_PRIVATE_KEY` |
{/* supa-mdx-lint-enable Rule003Spelling */}
## Step 6: Register an identity provider
Use the Auth admin API to register your IdP. You need the `SERVICE_ROLE_KEY` for authentication.
### Option A: Register with a metadata URL (recommended)
If your IdP provides a metadata URL, Auth will fetch and cache the metadata automatically and refresh it when it becomes stale:
```sh
curl -X POST 'http:///auth/v1/admin/sso/providers' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'Content-Type: application/json' \
-H 'apikey: your-service-role-key' \
-d '{
"type": "saml",
"metadata_url": "https://idp.example.com/saml/metadata",
"domains": ["example.com"],
"attribute_mapping": {
"keys": {
"email": {
"name": "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress"
},
"name": {
"name": "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name"
}
}
}
}'
```
### Option B: Register with inline metadata XML
If you have the IdP metadata as an XML string:
```sh
curl -X POST 'http:///auth/v1/admin/sso/providers' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'Content-Type: application/json' \
-H 'apikey: your-service-role-key' \
-d '{
"type": "saml",
"metadata_xml": "...",
"domains": ["example.com"]
}'
```
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
When using `metadata_url`, the URL must use HTTPS. Auth validates the metadata XML format and checks that the EntityID is unique across all registered providers.
The response includes the provider `id` (UUID) - save this for use in your application or for later management:
```json
{
"id": "d3f5a1b2-...",
"resource_id": null,
"disabled": false,
"saml": {
"entity_id": "https://idp.example.com/saml",
"metadata_url": "https://idp.example.com/saml/metadata"
},
"domains": [{ "domain": "example.com" }],
"created_at": "...",
"updated_at": "..."
}
```
### Registration parameters reference
{/* supa-mdx-lint-disable Rule003Spelling */}
| Parameter | Required | Description |
| ------------------- | ------------ | --------------------------------------------------------------------------------------------- |
| `type` | Yes | Must be `"saml"` |
| `metadata_url` | One of these | HTTPS URL to the IdP's SAML metadata (auto-refreshed) |
| `metadata_xml` | One of these | Raw IdP metadata XML string |
| `domains` | No | Array of email domains to associate (e.g., `["acme.com"]`). Used for domain-based SSO lookup. |
| `attribute_mapping` | No | Map SAML attributes to user claims (see [Attribute mapping](#attribute-mapping)) |
| `name_id_format` | No | Request a specific NameID format: `persistent`, `emailAddress`, `transient`, or `unspecified` |
| `resource_id` | No | A custom external identifier for the provider |
| `disabled` | No | Set to `true` to register but disable the provider |
{/* supa-mdx-lint-enable Rule003Spelling */}
## Step 8: Configure your identity provider
On the IdP side, create a new SAML application and configure it with your SP details:
{/* supa-mdx-lint-disable Rule003Spelling */}
| IdP setting | Value |
| ----------------------- | ----------------------------------------------------------- |
| SP Entity ID / Audience | `{API_EXTERNAL_URL}/sso/saml/metadata` |
| ACS URL / Reply URL | `{API_EXTERNAL_URL}/sso/saml/acs` |
| NameID format | `persistent` (recommended) or `emailAddress` |
| Signing certificate | Upload from the SP metadata XML or provide the metadata URL |
{/* supa-mdx-lint-enable Rule003Spelling */}
### IdP-specific configuration
**Okta setup:**
{/* supa-mdx-lint-disable Rule003Spelling */}
* Create a "SAML 2.0" application
* Single Sign-On URL: `{API_EXTERNAL_URL}/sso/saml/acs`
* Audience URI (SP Entity ID): `{API_EXTERNAL_URL}/sso/saml/metadata`
* Default RelayState: leave blank
* Name ID format: `Persistent`
{/* supa-mdx-lint-enable Rule003Spelling */}
**Azure AD (Entra ID):**
* Create an "Enterprise Application" → "Non-gallery application"
* Set up single sign-on → SAML
* Identifier (Entity ID): `{API_EXTERNAL_URL}/sso/saml/metadata`
* Reply URL (ACS): `{API_EXTERNAL_URL}/sso/saml/acs`
* Metadata URL for Auth: App Federation Metadata URL (from the SAML Signing Certificate section)
**Google Workspace:**
* Admin console → Apps → Web and mobile apps → Add custom SAML app
* ACS URL: `{API_EXTERNAL_URL}/sso/saml/acs`
* Entity ID: `{API_EXTERNAL_URL}/sso/saml/metadata`
* Name ID format: `PERSISTENT`
## Attribute mapping
Attribute mapping lets you control how SAML assertion attributes are translated into Supabase user claims. If no mapping is provided, Auth uses sensible defaults:
**Default email detection order:**
{/* supa-mdx-lint-disable Rule003Spelling */}
1. `urn:oid:0.9.2342.19200300.100.1.3` (LDAP mail OID)
2. `http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress`
3. `http://schemas.xmlsoap.org/claims/EmailAddress`
4. Attributes named `mail`, `Mail`, or `email`
5. Subject NameID (if it looks like an email address)
{/* supa-mdx-lint-enable Rule003Spelling */}
**Default user ID detection:**
{/* supa-mdx-lint-disable Rule003Spelling */}
1. `urn:oasis:names:tc:SAML:attribute:subject-id` attribute
2. Subject NameID (if format is `persistent`)
{/* supa-mdx-lint-enable Rule003Spelling */}
### Custom attribute mapping example
Map IdP-specific attributes to user metadata:
```json
{
"attribute_mapping": {
"keys": {
"email": {
"name": "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress"
},
"name": {
"name": "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name"
},
"department": {
"name": "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/department",
"default": "unknown"
},
"groups": {
"name": "http://schemas.microsoft.com/ws/2008/06/identity/claims/groups",
"array": true
},
"role": {
"names": ["http://schemas.microsoft.com/ws/2008/06/identity/claims/role", "role", "Role"],
"default": "member"
}
}
}
}
```
Each mapping key supports:
| Field | Description |
| --------- | ---------------------------------------------------------------------------------------------------------- |
| `name` | Primary SAML attribute name to look for (matched against both `Name` and `FriendlyName`, case-insensitive) |
| `names` | Array of fallback attribute names to try in order |
| `default` | Default value if the attribute is not present in the assertion |
| `array` | Set to `true` to collect all values (for multi-valued attributes like groups) |
Mapped attributes are stored in the user's `raw_user_meta_data` and are available via `user.user_metadata` in your application.
## Managing providers
### List all providers
```sh
curl 'http:///auth/v1/admin/sso/providers' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'apikey: your-service-role-key'
```
Filter by resource ID using exact match:
```sh
curl 'http:///auth/v1/admin/sso/providers?resource_id=my-idp' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'apikey: your-service-role-key'
```
or prefix match:
```sh
curl 'http:///auth/v1/admin/sso/providers?resource_id_prefix=prod-' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'apikey: your-service-role-key'
```
### Get a specific provider
```sh
curl 'http:///auth/v1/admin/sso/providers/{provider_id}' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'apikey: your-service-role-key'
```
### Update a provider
```sh
curl -X PUT 'http:///auth/v1/admin/sso/providers/{provider_id}' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'Content-Type: application/json' \
-H 'apikey: your-service-role-key' \
-d '{
"domains": ["example.com", "subsidiary.com"],
"attribute_mapping": {
"keys": {
"email": {
"name": "mail"
}
}
}
}'
```
### Disable a provider (without deleting)
```sh
curl -X PUT 'http:///auth/v1/admin/sso/providers/{provider_id}' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'Content-Type: application/json' \
-H 'apikey: your-service-role-key' \
-d '{ "disabled": true }'
```
### Delete a provider
```sh
curl -X DELETE 'http:///auth/v1/admin/sso/providers/{provider_id}' \
-H 'Authorization: Bearer your-service-role-key' \
-H 'apikey: your-service-role-key'
```
## Client-side integration
### Using supabase-js
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('http://', 'your-anon-key')
// Option 1: SSO by email domain
const { data, error } = await supabase.auth.signInWithSSO({
domain: 'example.com',
})
// Option 2: SSO by provider ID
const { data, error } = await supabase.auth.signInWithSSO({
providerId: 'd3f5a1b2-...',
})
// Redirect the user to the IdP
if (data?.url) {
window.location.href = data.url
}
```
Both methods return an object with a `url` property - redirect the user to this URL to begin authentication at the IdP.
### Using the REST API directly
By domain:
```sh
curl -X POST 'http:///auth/v1/sso' \
-H 'Content-Type: application/json' \
-H 'apikey: your-anon-key' \
-d '{
"domain": "example.com",
"skip_http_redirect": true
}'
```
By provider ID:
```sh
curl -X POST 'http:///auth/v1/sso' \
-H 'Content-Type: application/json' \
-H 'apikey: your-anon-key' \
-d '{
"provider_id": "d3f5a1b2-...",
"skip_http_redirect": true
}'
```
Both return `{ "url": "https://idp.example.com/sso?SAMLRequest=..." }`.
### Domain-based vs provider-based lookup
| Method | Use case |
| ------------ | --------------------------------------------------------------------------------------------------------------------------------------- |
| `domain` | Extract the domain from the user's email and let Auth find the right IdP. Best for login forms where the user enters their email first. |
| `providerId` | Use when you know the exact provider - for example, a dedicated "Sign in with Okta" button. |
## Test the login flow
1. Open your application and trigger SSO login (or use the curl command above)
2. You should be redirected to your IdP's login page
3. After authenticating, the IdP posts back to the ACS endpoint
4. Auth processes the assertion and redirects you back to your `SITE_URL` (or `redirect_to` URL) with session tokens
To verify the session was created:
```sh
curl 'http:///auth/v1/user' \
-H 'Authorization: Bearer user-session-token' \
-H 'apikey: your-anon-key'
```
The response should include `app_metadata.provider: "sso:saml"` and any mapped attributes in `user_metadata`.
## Environment variable reference
{/* supa-mdx-lint-disable Rule003Spelling */}
| Variable | Default | Description |
| ---------------------------------- | ------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `SAML_ENABLED` | `false` | Enable the SAML SSO engine |
| `SAML_PRIVATE_KEY` | - | Base64-encoded PKCS#1 RSA private key (min 2048-bit). Used to sign SAML requests and optionally decrypt assertions. |
| `SAML_ALLOW_ENCRYPTED_ASSERTIONS` | `false` | Accept encrypted SAML assertions from IdPs |
| `SAML_RELAY_STATE_VALIDITY_PERIOD` | `2m0s` | How long relay state tokens remain valid. Increase if users on slow networks time out during the IdP redirect. |
| `SAML_EXTERNAL_URL` | `API_EXTERNAL_URL` | Override the base URL used for the SAML entity ID and ACS endpoint. Only needed if the SAML endpoints are served on a different URL than the rest of the Auth API. |
| `SAML_RATE_LIMIT_ASSERTION` | `15` | Maximum ACS requests per second. Protects against assertion replay floods. |
{/* supa-mdx-lint-enable Rule003Spelling */}
## Troubleshooting
### "SAML is not enabled on this server"
The `GOTRUE_SAML_ENABLED` variable is not set to `true`, or the Auth container did not pick up the change. Verify the env var is passed through `docker-compose.yml` and restart:
```sh
docker compose down && docker compose up -d
```
### "Invalid private key" on startup
The `GOTRUE_SAML_PRIVATE_KEY` value is malformed. Ensure it is:
* Base64-encoded (single line, no line breaks)
* In PKCS#1 format (`openssl pkey ... -traditional` output)
* At least 2048-bit RSA
Regenerate if needed:
```sh
openssl genpkey -algorithm RSA -out pk_pkcs8.pem -quiet && \
openssl pkey -in pk_pkcs8.pem -out pk_rsa1.der -outform DER -traditional && \
base64 -w 0 -i pk_rsa1.der
```
### IdP cannot reach the ACS endpoint
* Verify `API_EXTERNAL_URL` is set to a URL the IdP can reach (not `localhost` unless testing locally)
* Check that the API gateway routes for `/sso/saml/acs` and `/sso/saml/metadata` are configured as open (no `key-auth` plugin).
* Check the Auth container logs: `docker compose logs auth`
### "No SSO provider found for this domain"
* Verify the domain is registered: list providers and check the `domains` array
* Domain matching is exact and case-insensitive - `Example.com` matches `example.com`
### Assertion validation fails
* Ensure the IdP's signing certificate matches what is in the metadata registered with Auth
* If using `metadata_url`, Auth automatically refreshes stale metadata (after `ValidUntil`, `CacheDuration`, or 24 hours). Force a refresh by updating the provider.
* Check clock sync between your server and the IdP - SAML assertions have time-based validity windows (`NotBefore` / `NotOnOrAfter`)
### User is created but attributes are missing
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
* Check your `attribute_mapping` configuration. Use the IdP's SAML assertion viewer (most IdPs have one) to see the exact attribute names being sent.
* Attribute names are matched case-insensitively against both the `Name` and `FriendlyName` fields in the assertion.
* Mapped attributes appear in `user.user_metadata`.
### Relay state expired
The user took too long between initiating SSO and completing authentication at the IdP. Increase `GOTRUE_SAML_RELAY_STATE_VALIDITY_PERIOD` (default is 2 minutes).
## Additional resources
* [SSO with SAML 2.0](/docs/guides/auth/enterprise-sso/auth-sso-saml) - Client-side SAML integration guide
* [Auth server configuration reference](/docs/guides/self-hosting/auth/config) - Full list of Auth environment variables
* [SAML 2.0 specification](http://docs.oasis-open.org/security/saml/v2.0/) - The underlying standard
# HIPAA Compliance and Supabase
The [Health Insurance Portability and Accountability Act (HIPAA)](https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/index.html) is a comprehensive law that protects individuals' health information while ensuring the continuity of health insurance coverage. It sets standards for privacy and security that must be followed by all entities that handle Protected Health Information (PHI), also known as electronic PHI (ePHI). HIPAA is specific to the United States, however many countries have similar or laws already in place or under legislation.
Under HIPAA, both covered entities and business associates have distinct responsibilities to ensure the protection of PHI. Supabase acts as a business associate for customers (the covered entity) who wish to provide healthcare related services. As a business associate, Supabase has a number of obligations and has undergone auditing of the security and privacy controls that are in place to meet these. Supabase has signed a Business Associate Agreement (BAA) with all of our vendors who would have access to ePHI, such as AWS, and ensure that we follow their terms listed in the agreements. Similarly when a customer signs a BAA with us, they have some responsibilities they agree to when using Supabase to store PHI.
The hosted Supabase platform has the necessary controls to meet HIPAA requirements. These controls are not supported out of the box in self-hosted Supabase. HIPAA controls extend further than the Supabase product, encompassing legal agreements (BAAs) with providers, operating controls and policies. Achieving HIPAA compliance with self-hosted Supabase is out of scope for this documentation and you should consult your auditor for further guidance.
### Customer responsibilities
Covered entities (the customer) are organizations that directly handle PHI, such as health plans, healthcare clearinghouses, and healthcare providers that conduct certain electronic transactions.
1. **Compliance with HIPAA Rules**: Covered entities must comply with the [HIPAA Privacy Rule](https://www.hhs.gov/hipaa/for-professionals/privacy/index.html), [Security Rule](https://www.hhs.gov/hipaa/for-professionals/security/index.html), and [Breach Notification Rule](https://www.hhs.gov/hipaa/for-professionals/breach-notification/index.html) to protect the privacy and security of ePHI.
2. **Business Associate Agreements (BAAs)**: Customers must sign a BAA with Supabase. When the covered entity engages a business associate to help carry out its healthcare activities, it must have a written BAA. This agreement outlines the business associate's responsibilities and requires them to comply with HIPAA Rules.
3. **Internal Compliance Programs**: Customers must [configure their HIPAA projects](/docs/guides/platform/hipaa-projects) and follow the guidance given by the security advisor. Covered entities are responsible for implementing internal processes and compliance programs to ensure they meet HIPAA requirements.
### Supabase responsibilities
Supabase as the business associate, and the vendors used by Supabase, are the entities that perform functions or activities on behalf of the customer.
1. **Direct Liability**: Supabase is directly liable for compliance with certain provisions of the HIPAA Rules. This means Supabase has to implement safeguards to protect ePHI and report breaches to the customer.
2. **Compliance with BAAs**: Supabase must comply with the terms of the BAA, which includes implementing appropriate administrative, physical, and technical safeguards to protect ePHI.
3. **Vendor Management**: Supabase must also ensure that our vendors, who may have access to ePHI, comply with HIPAA Rules. This is done through a BAA with each vendor.
## Staying compliant and secure
Compliance is a continuous process and should not be treated as a point-in-time audit of controls. Supabase applies all the necessary privacy and security controls to ensure HIPAA compliance at audit time, but also has additional checks and monitoring in place to ensure those controls are not disabled or altered in between audit periods. Customers commit to doing the same in their HIPAA environments. Supabase provides a growing set of checks that warn customers of changes to their projects that disable or weaken HIPAA required controls. Customers will receive warnings and guidance via the Security Advisor, however the responsibility of applying the recommended controls falls directly to the customer.
Our [shared responsibility model](/docs/guides/deployment/shared-responsibility-model#managing-healthcare-data) document discusses both HIPAA and general data management best practices, how this responsibility is shared between customers and Supabase, and how to stay compliant.
## Frequently asked questions
**What is the difference between SOC 2 and HIPAA?**
Both are frameworks for protecting sensitive data, however they serve two different purposes. They share many security and privacy controls and meeting the controls of one normally means being close to complying with the other.
The main differentiator comes down to purpose and scope.
* SOC 2 is not industry-specific and can be applied to any service organization that handles customer data.
* HIPAA is a federal regulation in the United States. HIPAA sets standards for the privacy and security of PHI/ePHI, ensuring that patient data is handled confidentially and securely.
**Are Supabase HIPAA environments also SOC 2 compliant?**
Yes. Supabase applies the same SOC 2 controls to all environments, with additional controls being applied to HIPAA environments.
**How often is Supabase audited?**
Supabase undergoes annual audits. The HIPAA controls are audited during the same audit period as the SOC 2 controls.
## Resources
1. [Health Insurance Portability and Accountability Act (HIPAA)](https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/index.html)
2. [HIPAA Privacy Rule](https://www.hhs.gov/hipaa/for-professionals/privacy/index.html)
3. [Security Rule](https://www.hhs.gov/hipaa/for-professionals/security/index.html)
4. [Breach Notification Rule](https://www.hhs.gov/hipaa/for-professionals/breach-notification/index.html)
5. [Configuring HIPAA projects](/docs/guides/platform/hipaa-projects) on Supabase
6. [Shared Responsibility Model](/docs/guides/deployment/shared-responsibility-model)
7. [HIPAA shared responsibility](/docs/guides/deployment/shared-responsibility-model#managing-healthcare-data)
# Platform Audit Logs
Any [Platform API](/docs/reference/api/introduction) or [dashboard](/dashboard) actions performed by organization members are logged automatically for auditing and security purposes. This includes actions such as creating a new project, inviting members, modifying an edge function or changing project settings.
Besides Platform Audit Logs, Supabase Auth also provides [Auth Audit Logs](/docs/guides/auth/audit-logs) to monitor authentication-related activities within your projects.
Platform Audit Logs are only available on the [Team and Enterprise plans](/pricing).
## Accessing audit logs
Platform Audit Logs can be found under your [organization's audit logs](/dashboard/org/_/audit).
For each audit log, you can see additional details by clicking on the log entry:
* Timestamp of action
* Actor who performed the action
* IP address
* Email
* Token Type
* Action performed
* Name
* Metadata such as route and response status
* Action Target (Project, organization, Edge Function, ...)
## Limitations
* There is currently no way to export the logs via dashboard
* There is currently no way to set up a log drain of platform audit logs
* Retention periods depend on your plan
# Secure configuration of Supabase platform
The Supabase hosted platform provides a secure by default configuration. Some organizations may however require further security controls to meet their own security policies or compliance requirements.
Access to additional security controls can be found under the [security tab](/dashboard/org/_/security) for organizations.
## Available controls
Additional security controls are under active development. Any changes will be published here and
in our [changelog](/changelog).
### Enforce multi-factor authentication (MFA)
Organization owners can choose to enforce MFA for all team members.
For configuration information, see [Enforce MFA on Organization](/docs/guides/platform/mfa/org-mfa-enforcement)
### SSO for organizations
Supabase offers single sign-on (SSO) as a login option to provide additional account security for your team. This allows company administrators to enforce the use of an identity provider when logging into Supabase.
For configuration information, see [Enable SSO for Your Organization](/docs/guides/platform/sso).
### Postgres SSL enforcement
Supabase projects support connecting to the Postgres DB without SSL enforced to maximize client compatibility. For increased security, you can prevent clients from connecting if they're not using SSL.
For configuration information, see [Postgres SSL Enforcement](/docs/guides/platform/ssl-enforcement)
Controlling this at the organization level is on our roadmap.
### Network restrictions
Each Supabase project comes with configurable restrictions on the IP ranges that are allowed to connect to Postgres and its pooler ("your database"). These restrictions are enforced before traffic reaches the database. If a connection is not restricted by IP, it still needs to authenticate successfully with valid database credentials.
For configuration information, see [Network Restrictions](/docs/guides/platform/network-restrictions)
Controlling this at the organization level is on our roadmap.
### PrivateLink
PrivateLink provides enterprise-grade private network connectivity between your AWS VPC and your Supabase database using AWS VPC Lattice. This eliminates exposure to the public internet by creating a secure, private connection that keeps your database traffic within the AWS network backbone.
For configuration information, see [PrivateLink](/docs/guides/platform/privatelink)
PrivateLink is currently in beta. To establish PrivateLink with a Read Replica, reach out to your account rep.
# Secure configuration of Supabase products
The Supabase [production checklist](/docs/guides/deployment/going-into-prod) provides detailed advice on preparing an app for production. While our [SOC 2](/docs/guides/security/soc-2-compliance) and [HIPAA](/docs/guides/security/hipaa-compliance) compliance documents outline the roles and responsibilities for building a secure and compliant app.
Various products at Supabase have their own hardening and configuration guides, below is a definitive list of these to help guide your way.
## Auth
* [Password security](/docs/guides/auth/password-security)
* [Rate limits](/docs/guides/auth/rate-limits)
* [Bot detection / Prevention](/docs/guides/auth/auth-captcha)
* [JWTs](/docs/guides/auth/jwts)
## Database
* [Row Level Security](/docs/guides/database/postgres/row-level-security)
* [Column Level Security](/docs/guides/database/postgres/column-level-security)
* [Securing your API](/docs/guides/api/securing-your-api)
* [Custom claims and role based access control](/docs/guides/api/custom-claims-and-role-based-access-control-rbac)
* [Managing Postgres roles](/docs/guides/database/postgres/roles)
* [Managing secrets with Vault](/docs/guides/database/vault)
* [Superuser access and unsupported operations](docs/guides/database/postgres/roles-superuser)
## Storage
* [Object ownership](/docs/guides/storage/security/ownership)
* [Access control](/docs/guides/storage/security/access-control)
* The Storage API docs contain hints about required [RLS policy permissions](/docs/reference/javascript/storage-createbucket)
* [Custom roles with the storage schema](/docs/guides/storage/schema/custom-roles)
## Realtime
* [Authorization](/docs/guides/realtime/authorization)
# Security testing of your Supabase projects
Supabase customer support policy for penetration testing
Customers of Supabase are permitted to carry out security assessments or penetration tests of their hosted Supabase project components. This testing may be carried out without prior approval for the customer services listed under [permitted services](#permitted-services). Supabase does not permit hosting security tooling that may be perceived as malicious or part of a campaign against Supabase customers or external services. This section is covered by the [Supabase Acceptable Use Policy](/aup) (AUP).
It is the customer’s responsibility to ensure that testing activities are aligned with this policy. Any testing performed outside of the policy will be seen as testing directly against Supabase and may be flagged as abuse behaviour. If Supabase receives an abuse report for activities related to your security testing, we will forward these to you. If you discover a security issue within any of the Supabase products, contact [Supabase Security](mailto:security@supabase.com) immediately.
Furthermore, Supabase runs a [Vulnerability Disclosure Program](https://hackerone.com/ca63b563-9661-4ac3-8d23-7581582ef451/embedded_submissions/new) (VDP) with HackerOne, and external security researchers may report any bugs found within the scope of the aforementioned program. Customer penetration testing does not form part of this VDP.
### Permitted services
* Authentication
* Database
* Edge Functions
* Storage
* Realtime
* `https://.supabase.co/*`
* `https://db..supabase.co/*`
### Prohibited testing and activities
* Any activity contrary to what is listed in the AUP.
* Denial of Service (DoS) and Distributed Denial of Service (DDoS) testing.
* Cross-tenant attacks, testing that directly targets other Supabase customers' accounts, organizations, and projects not under the customer’s control.
* Request flooding.
## Terms and conditions
The customer agrees to the following,
Security testing:
* Will be limited to the services within the customer’s project.
* Is subject to the general [Terms of Service](/terms).
* Is within the [Acceptable Usage Policy](/aup).
* Will be stopped if contacted by Supabase due to a breach of the above or a negative impact on Supabase and Supabase customers.
* Any vulnerabilities discovered directly in a Supabase product will be reported to Supabase Security within 24 hours of completion of testing.
# SOC 2 Compliance and Supabase
Supabase is Systems and Organization Controls 2 (SOC 2) Type 2 compliant and is assessed annually to ensure continued adherence to the SOC 2 security framework. SOC 2 assesses Supabase’s adherence to, and implementation of, controls governing the security, availability, processing integrity, confidentiality, and privacy on the Supabase platform. These controls define requirements for the management and storage of customer data on the platform. These controls applied to Supabase, as a service provider, serve two customer data environments.
The first environment is the customer relationship with Supabase, this refers to the data Supabase has on a customer of the platform. All billing, contact, usage and contract information is managed and stored according to SOC 2 requirements.
The second environment is the backend as a service (the product) that Supabase provides to customers. Supabase implements the controls from the SOC 2 framework to ensure the security of the platform, which hosts the backend as a service (the product), including the Postgres Database, Storage, Authentication, Realtime, Edge Functions and Data API features. Supabase can assert that the environment hosting customer data, stored within the product, adheres to SOC 2 requirements. And the management and storage of data within this environment (the product) is strictly controlled and kept secure.
Supabase’s SOC 2 compliance does not transfer to environments outside of the Supabase product or Supabase’s control. This is known as the security or compliance boundary and forms part of the Shared Responsibility Model that Supabase and their customers enter into.
SOC 2 does not cover, nor is it a substitute for, compliance with the Health Insurance Portability and Accountability Act (HIPAA).
Organizations must have a signed Business Associate Agreement (BAA) with Supabase and have the HIPAA add-on enabled when dealing with Protected Health Information (PHI).
Our [HIPAA documentation](/docs/guides/security/hipaa-compliance) provides more information about the responsibilities and requirements for HIPAA on Supabase.
# Meeting compliance requirements
SOC 2 compliance is a critical aspect of data security for Supabase and our customers. Being fully SOC 2 compliant is a shared responsibility and here’s a breakdown of the responsibilities for both parties:
### Supabase responsibilities
1. **Security Measures**: Supabase implements robust security controls to protect customer data. These includes measures to prevent data breaches and ensure the confidentiality and integrity of the information managed and stored by the platform. Supabase is obliged to be vigilant about security risks and must demonstrate that our security measures meet industry standards through regular audits.
2. **Compliance Audits**: Supabase undergoes SOC 2 audits yearly to verify that our data management practices comply with the Trust Services Criteria (TSC), which include security, availability, processing integrity, confidentiality, and privacy. These audits are conducted by an independent third party.
3. **Incident Response**: Supabase has an incident response plan in place to handle data breaches efficiently. This plan outlines how the organization detects issues, responds to incidents, and manages system vulnerabilities.
4. **Reporting**: Upon a successful audit, Supabase receive a SOC 2 report that details our compliance status. This report is available to customers as a SOC 2 Type 2 report, and allows customers and stakeholders to assure that Supabase has implemented adequate and the requisite safeguards to protect sensitive information.
### Customer responsibilities
1. **Compliance Requirements**: Understand your own compliance requirements. While SOC 2 compliance is not a legal requirement, many enterprise customers require their providers to have a SOC 2 report. This is because it provides assurance that the provider has implemented robust controls to protect customer data.
2. **Due Diligence**: Customers must perform due diligence when selecting Supabase as a provider. This includes reviewing the SOC 2 Type 2 report to ensure that Supabase meets the expected security standards. Customers should also understand the division of responsibilities between themselves and Supabase to avoid duplication of effort.
3. **Monitoring and Review**: Customers should regularly monitor and review Supabase’s compliance status.
4. **Control Compliance**: If a customer needs to be SOC 2 compliant, they should themselves implement the requisite controls and undergo a SOC 2 audit.
### Shared responsibilities
1. **Data Security**: Both customers and Supabase share the responsibility of ensuring data security. While the Supabase, as the provider, implements the security controls, the customer must ensure that their use of the Supabase platform does not compromise these controls.
2. **Control Compliance**: Supabase asserts through our SOC 2 that all requisite security controls are met. Customers wishing to also be SOC 2 compliant need to go through their own SOC 2 audit, verifying that security controls are met on the customer's side.
In summary, SOC 2 compliance involves a shared responsibility between Supabase and our customers to ensure the security and integrity of data. Supabase, as a provider, must implement and maintain robust security measures, customers must perform due diligence and monitor Supabase's compliance status, while also implement their own compliance controls to protect their sensitive information.
## Frequently asked questions
**How often is Supabase SOC 2 audited?**
Supabase has obtained SOC 2 Type 2 certification, which means Supabase's controls are fully audited annually. The auditor's reports on these examinations are issued as soon as they are ready after the audit. Supabase makes the SOC 2 Type 2 report available to [Enterprise and Team Plan](/pricing) customers. The audit report covers a rolling 12-month window, known as the audit period, and runs from 1 March to 28 February of the next calendar year.
**How to obtain Supabase's SOC 2 Type 2 report?**
To access the SOC 2 Type 2 report, you must be a Enterprise or Team Plan Supabase customer. The report is downloadable from the [Legal Documents](/dashboard/org/_/documents) section in the organization dashboard.
**Why does it matter that Supabase is SOC 2 Compliant?**
SOC 2 is used to assert that controls are in place to ensure the proper management and storage of data. SOC 2 provides a framework for measuring how secure a service provider is and re-evaluates the provider on an annual basis. This provides the confidence and assurance that data stored within the Supabase platform is correctly secured and managed.
**If Supabase’s SOC 2 does not transfer to the customer, why does it matter that Supabase has SOC 2?**
Even though Supabase’s SOC 2 compliance does not transfer outside of the product, it does provide the assurance that all data within the product is correctly managed and stored. Supabase can assert that only authorized persons have access to the data, and security controls are in place to prevent, detect and respond to data intrusions. This forms part of a customer’s own adherence to the SOC 2 framework and relieves part of the burden of data management and storage on the customer. In many organizations' security and risk departments require all vendors or sub-processors to be SOC 2 compliant.
**What is the security or compliance boundary?**
This defines the boundary or border between Supabase and customer responsibility for data security within the Shared Responsibility Model. Customer data stored within the Supabase product, on the Supabase side of the security boundary, is managed and secured by Supabase. Supabase ensures the safe handling and storage of data within this environment. This includes controls for preventing unauthorized access, monitoring data access, alerting, data backups and redundancy. Data on the customer side of the boundary, the data that enters and leaves the Supabase product, is the responsibility of the customer. Management and possible storage of such data outside of Supabase should be performed by the customer, and any security and compliance controls are the responsibility of the customer.
**We have strong data residency requirements. Does Supabase SOC 2 cover data residency?**
While SOC 2 itself does not mandate specific data residency requirements, organizations may still need to comply with other regulatory frameworks, such as GDPR, that do have such requirements. Ensuring projects are deployed in the correct region is a customer responsibility as each Supabase project is deployed into the region the customer specifies at creation time. All data will remain within the chosen region.
[Read replicas](/docs/guides/platform/read-replicas) can be created for multi-region availability, it remains the customer's responsibility to ensure regions chosen for read replicas are within the geographic area required by any additional regulatory frameworks.
**Does SOC 2 cover health related data (HIPAA)?**
SOC 2 is non-industry specific and provides a framework for the security and privacy of data. This is however not sufficient in most cases when dealing with Protected Healthcare Information (PHI), which requires additional privacy and legal controls.
When dealing with PHI in the United States or for United States customers, HIPAA is mandatory.
## Resources
1. [System and Organization Controls: SOC Suite of Services](https://www.aicpa-cima.com/resources/landing/system-and-organization-controls-soc-suite-of-services)
2. [Shared Responsibility Model](/docs/guides/deployment/shared-responsibility-model)
# Glossary
Definitions for terminology and acronyms used in the Supabase documentation.
## Access token
An access token is a short-lived (usually no more than 1 hour) token that authorizes a client to access resources on a server. It comes in the form of a [JSON Web Token (JWT)](#json-web-token-jwt).
## Authentication
Authentication (often abbreviated `authn.`) is the process of verifying the identity of a user. Verification of the identity of a user can happen in multiple ways:
1. Asking users for something they know. For example: password, passphrase.
2. Checking that users have access to something they own. For example: an email address, a phone number, a hardware key, recovery codes.
3. Confirming that users have some biological features. For example: a fingerprint, a certain facial structure, an iris print.
## Authenticator app
An authenticator app generates time-based one-time passwords (TOTPs). These passwords are generated based off a long and difficult to guess secret string. The secret is initially passed to the application by scanning a QR code.
## Authorization
Authorization (often abbreviated `authz.`) is the process of verifying if a certain identity is allowed to access resources. Authorization often occurs by verifying an access token.
## Identity provider
An identity provider is software or service that allows third-party applications to identify users without the exchange of passwords. Social login and enterprise single-sign on won't be possible without identity providers.
Social login platforms typically use the OAuth protocol, while enterprise single-sign on is based on the OIDC or SAML protocols.
## JSON Web Token (JWT)
A [JSON Web Token](https://jwt.io/introduction) is a type of data structure, represented as a string, that usually contains identity and authorization information about a user. It encodes information about its lifetime and is signed with cryptographic key making it tamper resistant.
Access tokens are JWTs and by inspecting the information they contain you can allow or deny access to resources. Row level security policies are based on the information present in JWTs.
## JWT signing secret
JWTs issued by Supabase are signed using the HMAC-SHA256 algorithm. The secret key used in the signing is called the JWT signing secret. You should not share this secret with someone or some thing you don't trust, nor should you post it publicly. Anyone with access to the secret can create arbitrary JWTs.
## Multi-factor authentication (MFA or 2FA)
Multi-factor authentication is the process of authenticating a user's identity by using a combination of factors: something users know, something users have or something they are.
## Nonce
Nonce means number used once. In reality though, it is a unique and difficult to guess string used to either initialize a protocol or algorithm securely, or detect abuse in various forms of replay attacks.
## OAuth
OAuth is a protocol allowing third-party applications to request and receive authorization from their users. It is typically used to implement social login, and serves as a base for enterprise single-sign on in the OIDC protocol. Applications can request different levels of access, including basic user identification information such as name, email address, and user ID.
## OIDC
OIDC stands for OpenID Connect and is a protocol that enables single-sign on for enterprises. OIDC is based on modern web technologies such as OAuth and JSON Web Tokens. It is commonly used instead of the older SAML protocol.
## One-time password (OTP)
A one-time password is a short, randomly generated and difficult to guess password or code that is sent to a device (like a phone number) or generated by a device or application.
## Password hashing function
Password hashing functions are specially-designed algorithms that allow web servers to verify a password without storing it as-is. Unlike other difficult to guess strings generated from secure random number generators, passwords are picked by users and often are easy to guess by attackers. These algorithms slow down and make it very costly for attackers to guess passwords.
There are three generally accepted password hashing functions: Argon2, bcrypt and scrypt.
## Password strength
Password strength is a measurement of how difficult a password is to guess. Simple measurement includes calculating the number of possibilities given the types of characters used in the password. For example a password of only letters has fewer variations than ones with letters and digits. Better measurements include strategies such as looking for similarity to words, phrases or already known passwords.
## PKCE
Proof Key for Code Exchange is an extension to the OAuth protocol that enables secure exchange of refresh and access tokens between an application (web app, single-page app or mobile app) and the authorization server. It is used in places where the exchange of the refresh and access token may be intercepted by third parties such as other applications running in the operating system. This is a common problem on mobile devices where the operating system may hand out URLs to other applications. This can sometimes be also exploited in single-page apps too.
## Provider refresh token
A provider refresh token is a refresh token issued by a third-party identity provider which can be used to refresh the provider token returned.
## Provider tokens
A provider token is a long-lived token issued by a third-party identity provider. These are issued by social login services (e.g., Google, Twitter, Apple, Microsoft) and uniquely identify a user on those platforms.
## Refresh token
A refresh token is a long-lived (in most cases with an indefinite lifetime) token that is meant to be stored and exchanged for a new refresh and access tokens only once. Once a refresh token is exchanged it becomes invalid, and can't be exchanged again. In practice, though, a refresh token can be exchanged multiple times but in a short time window.
## Refresh token flow
The refresh token flow is a mechanism that issues a new refresh and access token on the basis of a valid refresh token. It is used to extend authorization access for an application. An application that is being constantly used will invoke the refresh token flow just before the access token expires.
## Replay attack
A replay attack is when sensitive information is stolen or intercepted by attackers who then attempt to use it again (thus replay) in an effort to compromise a system. Commonly replay attacks can be mitigated with the proper use of nonces.
## Row level security policies (RLS)
Row level security policies are special objects within the Postgres database that limit the available operations or data returned to clients. RLS policies use information contained in a JWT to identify users and the actions and data they are allowed to perform or view.
## SAML
SAML stands for Security Assertion Markup Language and is a protocol that enables single-sign on for enterprises. SAML was invented in the early 2000s and is based on XML technology. It is the de facto standard for enabling single-sign on for enterprises, although the more recent OIDC (OpenID Connect) protocol is gaining popularity.
## Session
A session or authentication session is the concept that binds a verified user identity to a web browser. A session usually is long-lived, and can be terminated by the user logging out. An access and refresh token pair represent a session in the browser, and they are stored in local storage or as cookies.
## Single-sign on (SSO)
Single-sign on allows enterprises to centrally manage accounts and access to applications. They use identity provider software or services to organize employee information in directories and connect those accounts with applications via OIDC or SAML protocols.
## Time-based one-time password (TOTP)
A time-based one-time password is a one-time password generated at regular time intervals from a secret, usually from an application in a mobile device (e.g., Google Authenticator, 1Password).
# Realtime Architecture
Realtime is a globally distributed Elixir cluster. Clients can connect to any node in the cluster via WebSockets and send messages to any other client connected to the cluster.
Realtime is written in [Elixir](https://elixir-lang.org/), which compiles to [Erlang](https://www.erlang.org/), and utilizes many tools the [Phoenix Framework](https://www.phoenixframework.org/) provides out of the box.
## Elixir & Phoenix
Phoenix is fast and able to handle millions of concurrent connections.
Phoenix can handle many concurrent connections because Elixir provides lightweight processes (not OS processes) to work with.
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
Client-facing WebSocket servers need to handle many concurrent connections. Elixir & Phoenix let the Supabase Realtime cluster do this easily.
## Channels
Channels are implemented using [Phoenix Channels](https://hexdocs.pm/phoenix/channels.html) which uses [Phoenix.PubSub](https://hexdocs.pm/phoenix_pubsub/Phoenix.PubSub.html) with the default `Phoenix.PubSub.PG2` adapter.
The PG2 adapter utilizes Erlang [process groups](https://www.erlang.org/docs/18/man/pg2.html) to implement the PubSub model where a publisher can send messages to many subscribers.
## Global cluster
Presence is an in-memory key-value store backed by a CRDT. When a user is connected to the cluster the state of that user is sent to all connected Realtime nodes.
Broadcast lets you send a message from any connected client to a Channel. Any other client connected to that same Channel will receive that message.
This works globally. A client connected to a Realtime node in the United States can send a message to another client connected to a node in Singapore. Connect two clients to the same Realtime Channel and they'll all receive the same messages.
Broadcast is useful for getting messages to users in the same location very quickly. If a group of clients are connected to a node in Singapore, the message only needs to go to that Realtime node in Singapore and back down. If users are close to a Realtime node they'll get Broadcast messages in the time it takes to ping the cluster.
Thanks to the Realtime cluster, you (an amazing Supabase user) don't have to think about which regions your clients are connected to.
If you're using Broadcast, Presence, or streaming database changes, messages will always get to your users via the shortest path possible.
## Connecting to a database
Realtime allows you to listen to changes from your Postgres database. When a new client connects to Realtime and initializes the `postgres_changes` Realtime Extension the cluster will connect to your Postgres database and start streaming changes from a replication slot.
Realtime knows the region your database is in, and connects to it from the closest region possible.
Every Realtime region has at least two nodes so if one node goes offline the other node should reconnect and start streaming changes again.
## Broadcast from Postgres
Realtime Broadcast sends messages when changes happen in your database. Behind the scenes, Realtime creates a publication on the `realtime.messages` table. It then reads the Write-Ahead Log (WAL) file for this table, and sends a message whenever an insert happens. Messages are sent as JSON packages over WebSockets.
The `realtime.messages` table is partitioned by day. This allows old messages to be deleted performantly, by dropping old partitions. Partitions are retained for 3 days before being deleted.
Broadcast uses [Realtime Authorization](/docs/guides/realtime/authorization) by default to protect your data.
## Streaming the Write-Ahead Log
A Postgres logical replication slot is acquired when connecting to your database.
Realtime delivers changes by polling the replication slot and appending channel subscription IDs to each wal record.
Subscription IDs are Erlang processes representing underlying sockets on the cluster. These IDs are globally unique and messages to processes are routed automatically by the Erlang virtual machine.
After receiving results from the polling query, with subscription IDs appended, Realtime delivers records to those clients.
# Realtime Authorization
You can control client access to Realtime [Broadcast](/docs/guides/realtime/broadcast) and [Presence](/docs/guides/realtime/presence) by adding Row Level Security policies to the `realtime.messages` table. Each RLS policy can map to a specific action a client can take:
* Control which clients can broadcast to a Channel
* Control which clients can receive broadcasts from a Channel
* Control which clients can publish their presence to a Channel
* Control which clients can receive messages about the presence of other clients
To enforce private channels you need to disable the 'Allow public access' setting in [Realtime Settings](/dashboard/project/_/realtime/settings)
## How it works
Realtime uses the `messages` table in your database's `realtime` schema to generate access policies for your clients when they connect to a Channel topic.
By creating RLS policies on the `realtime.messages` table you can control the access users have to a Channel topic, and features within a Channel topic.
The validation is done when the user connects. When their WebSocket connection is established and a Channel topic is joined, their permissions are calculated based on:
* The RLS policies on the `realtime.messages` table
* The user information sent as part of their [Auth JWT](/docs/guides/auth/jwts)
* The request headers
* The Channel topic the user is trying to connect to
When Realtime generates a policy for a client it performs a query on the `realtime.messages` table and then rolls it back. Realtime does not store any messages in your `realtime.messages` table.
Using Realtime Authorization involves two steps:
* In your database, create RLS policies on the `realtime.messages`
* In your client, instantiate the Realtime Channel with the `config` option `private: true`
Increased RLS complexity can impact database performance and connection time, leading to higher connection latency and decreased join rates.
## Accessing request information
### `realtime.topic`
You can use the `realtime.topic` helper function when writing RLS policies. It returns the Channel topic the user is attempting to connect to.
```sql
create policy "authenticated can read all messages on topic"
on "realtime"."messages"
for select
to authenticated
using (
(select realtime.topic()) = 'room-1'
);
```
### JWT claims
The user claims can be accessed using the `current_setting` function. The claims are available as a JSON object in the `request.jwt.claims` setting.
```sql
create policy "authenticated with supabase.io email can read all"
on "realtime"."messages"
for select
to authenticated
using (
-- Only users with the email claim ending with @supabase.io
(((current_setting('request.jwt.claims'))::json ->> 'email') ~~ '%@supabase.io')
);
```
## Examples
The following examples use this schema:
```sql
create table public.rooms (
id bigint generated by default as identity primary key,
topic text not null unique
);
GRANT SELECT ON public.rooms TO anon;
alter table public.rooms enable row level security;
create table public.profiles (
id uuid not null references auth.users on delete cascade,
email text NOT NULL,
primary key (id)
);
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.profiles TO authenticated;
alter table public.profiles enable row level security;
create table public.rooms_users (
user_id uuid references auth.users (id),
room_topic text references public.rooms (topic),
created_at timestamptz default current_timestamp
);
GRANT SELECT ON public.rooms_users TO authenticated;
alter table public.rooms_users enable row level security;
create policy "authenticated can read own room memberships"
on public.rooms_users
for select
to authenticated
using ((select auth.uid()) = user_id);
```
### Broadcast
The `extension` field on the `realtime.messages` table records the message type. For Broadcast messages, the value of `realtime.messages.extension` is `broadcast`. You can check for this in your RLS policies.
#### Allow a user to join (and read) a Broadcast topic
To join a Broadcast Channel, a user must have at least one read or write permission on the Channel topic.
Here, we allow reads (`select`s) for users who are linked to the requested topic within the relationship table `public.room_users`:
```sql
create policy "authenticated can receive broadcast"
on "realtime"."messages"
for select
to authenticated
using (
exists (
select
user_id
from
rooms_users
where
user_id = (select auth.uid())
and room_topic = (select realtime.topic())
and realtime.messages.extension in ('broadcast')
)
);
```
Then, to join a topic with RLS enabled, instantiate the Channel with the `private` option set to `true`.
```javascript
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const channel = supabase.channel('room-1', {
config: { private: true },
})
channel
.on('broadcast', { event: 'test' }, (payload) => console.log(payload))
.subscribe((status, err) => {
if (status === 'SUBSCRIBED') {
console.log('Connected!')
} else {
console.error(err)
}
})
```
```dart
final channel = supabase.channel(
'room-1',
opts: const RealtimeChannelConfig(private: true),
);
channel
.onBroadcast(event: 'test', callback: (payload) => print(payload))
.subscribe((status, err) {
if (status == RealtimeSubscribeStatus.subscribed) {
print('Connected!');
} else {
print(err);
}
});
```
```swift
let channel = supabase.channel("room-1") {
$0.isPrivate = true
}
Task {
for await payload in channel.broadcastStream(event: "test") {
print(payload)
}
}
await channel.subscribe()
print("Connected!")
```
```kotlin
val channel = supabase.channel("room-1") {
isPrivate = true
}
channel.broadcastFlow(event = "test").onEach {
println(it)
}.launchIn(scope) // launch in your coroutine scope
channel.subscribe(blockUntilSubscribed = true)
println("Connected!")
```
```py
channel = realtime.channel(
"room-1", {"config": {"private": True}}
)
await channel.on_broadcast(
"test", callback=lambda payload: print(payload)
).subscribe(
lambda state, err: (
print("Connected")
if state == RealtimeSubscribeStates.SUBSCRIBED
else print(err)
)
)
```
#### Allow a user to send a Broadcast message
To authorize sending Broadcast messages, create a policy for `insert` where the value of `realtime.messages.extension` is `broadcast`.
Here, we allow writes (sends) for users who are linked to the requested topic within the relationship table `public.room_users`:
```sql
create policy "authenticated can send broadcast on topic"
on "realtime"."messages"
for insert
to authenticated
with check (
exists (
select
user_id
from
rooms_users
where
user_id = (select auth.uid())
and room_topic = (select realtime.topic())
and realtime.messages.extension in ('broadcast')
)
);
```
### Presence
The `extension` field on the `realtime.messages` table records the message type. For Presence messages, the value of `realtime.messages.extension` is `presence`. You can check for this in your RLS policies.
#### Allow users to listen to Presence messages on a Channel
Create a policy for `select` on `realtime.messages` where `realtime.messages.extension` is `presence`.
```sql
create policy "authenticated can listen to presence in topic"
on "realtime"."messages"
for select
to authenticated
using (
exists (
select
user_id
from
rooms_users
where
user_id = (select auth.uid())
and room_topic = (select realtime.topic())
and realtime.messages.extension in ('presence')
)
);
```
#### Allow users to send Presence messages on a channel
To update the Presence status for a user create a policy for `insert` on `realtime.messages` where the value of `realtime.messages.extension` is `presence`.
```sql
create policy "authenticated can track presence on topic"
on "realtime"."messages"
for insert
to authenticated
with check (
exists (
select
user_id
from
rooms_users
where
user_id = (select auth.uid())
and room_topic = (select realtime.topic())
and realtime.messages.extension in ('presence')
)
);
```
### Presence and Broadcast
Authorize both Presence and Broadcast by including both extensions in the `where` filter.
#### Broadcast and Presence read
Authorize Presence and Broadcast read in one RLS policy.
```sql
create policy "authenticated can listen to broadcast and presence on topic"
on "realtime"."messages"
for select
to authenticated
using (
exists (
select
user_id
from
rooms_users
where
user_id = (select auth.uid())
and room_topic = (select realtime.topic())
and realtime.messages.extension in ('broadcast', 'presence')
)
);
```
#### Broadcast and Presence write
Authorize Presence and Broadcast write in one RLS policy.
```sql
create policy "authenticated can send broadcast and presence on topic"
on "realtime"."messages"
for insert
to authenticated
with check (
exists (
select
user_id
from
rooms_users
where
user_id = (select auth.uid())
and room_topic = (select realtime.topic())
and realtime.messages.extension in ('broadcast', 'presence')
)
);
```
## Interaction with Postgres Changes
When using Postgres Changes on tables with RLS, database records are sent only to clients who are allowed to read them based on your RLS policies.
Private and public channels can subscribe to Postgres Changes.
## Updating RLS policies
Client access policies are cached for the duration of the connection. Your database is not queried for every Channel message.
Realtime updates the access policy cache for a client based on your RLS policies when:
* A client connects to Realtime and subscribes to a Channel
* A new JWT is sent to Realtime from a client via the [`access_token` message](/docs/guides/realtime/protocol#access-token)
If a new JWT is never received on the Channel, the client will be disconnected when the JWT expires.
Make sure to keep the JWT expiration window short.
# Benchmarks
Scalability Benchmarks for Supabase Realtime.
This guide explores the scalability of Realtime's features: Broadcast, Presence, and Postgres Changes.
## Methodology
* The benchmarks are conducted using k6, an open-source load testing tool, against a Realtime Cluster deployed on AWS.
* The cluster configurations use 2-6 nodes, tested in both single-region and multi-region setups, all connected to a single Supabase project.
* The load generators (k6 servers) are deployed on AWS to minimize network latency impact on the results.
* Tests are executed with a full load from the start without warm-up runs.
The metrics collected include: message throughput, latency percentiles, CPU and memory utilization, and connection success rates. Note that performance in production environments may vary based on factors such as network conditions, hardware specifications, and specific usage patterns.
## Workloads
The proposed workloads are designed to demonstrate Supabase Realtime's throughput and scalability. These benchmarks focus on core functionality and common usage patterns. The benchmarking results include the following workloads:
1. **Broadcast Performance**
2. **Payload Size Impact on Broadcast**
3. **Large-Scale Broadcasting**
4. **Authentication and New Connection Rate**
5. **Database Events**
## Results
### Broadcast: Using WebSockets
This workload evaluates the system's capacity to handle multiple concurrent WebSocket connections and sending Broadcast messages via the WebSocket. Each virtual user (VU) in the test:
* Establishes and maintains a WebSocket connection
* Joins two distinct channels:
* An echo channel (1 user per channel) for direct message reflection
* A broadcast channel (6 users per channel) for group communication
* Generates traffic by sending 2 messages per second to each joined channel for 10 minutes
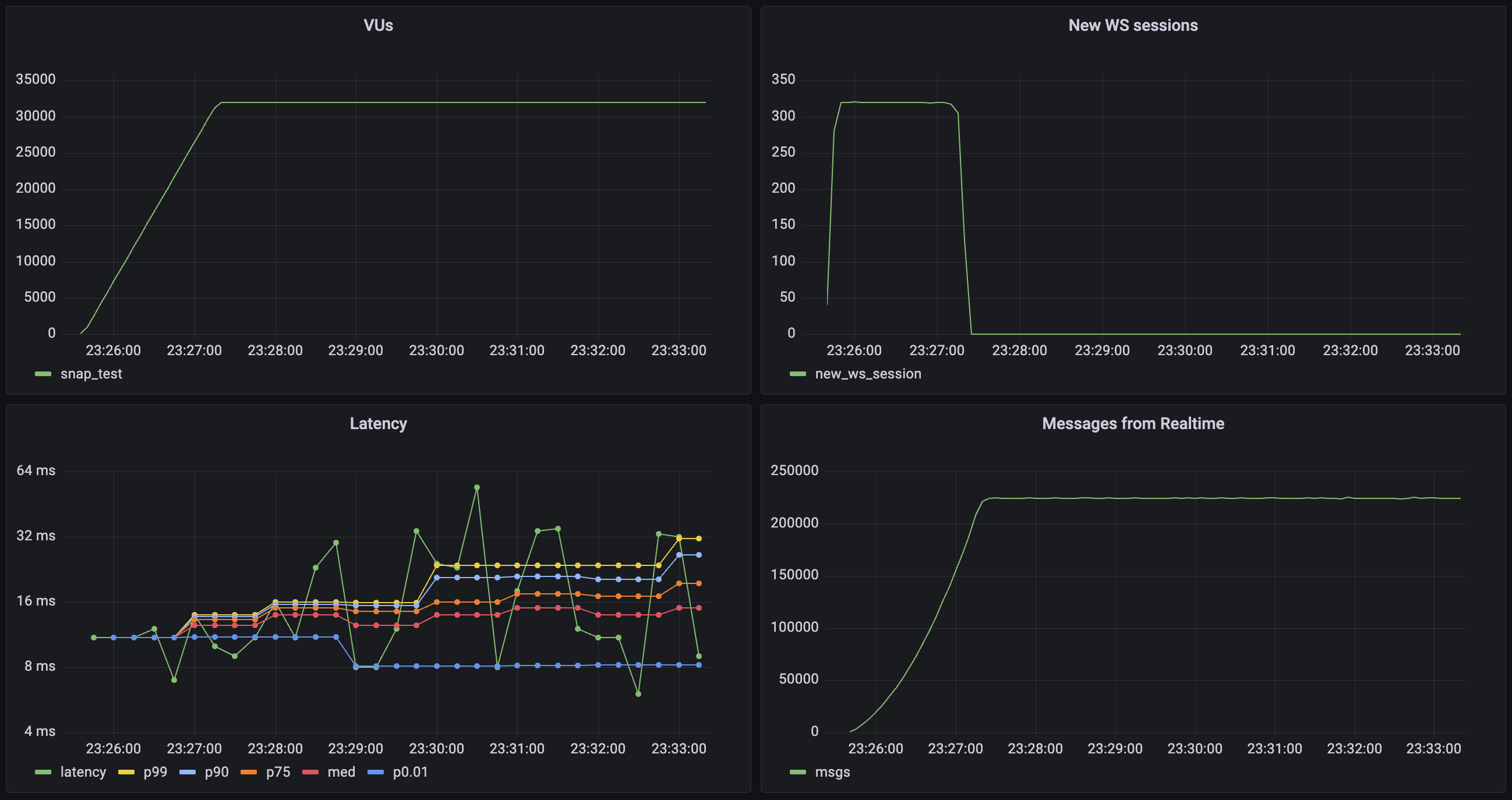
| Metric | Value |
| ------------------- | ----------------------- |
| Concurrent Users | 32\_000 |
| Total Channel Joins | 64\_000 |
| Message Throughput | 224\_000 msgs/sec |
| Median Latency | 6 ms |
| Latency (p95) | 28 ms |
| Latency (p99) | 213 ms |
| Data Received | 6.4 MB/s (7.9 GB total) |
| Data Sent | 23 KB/s (28 MB total) |
| New Connection Rate | 320 conn/sec |
| Channel Join Rate | 640 joins/sec |
### Broadcast: Using the database
This workload evaluates the system's capacity to send Broadcast messages from the database using the `realtime.broadcast_changes` function. Each virtual user (VU) in the test:
* Establishes and maintains a WebSocket connection
* Joins a distinct channel:
* A single channel (100 users per channel) for group communication
* Database has a trigger set to run `realtime.broadcast_changes` on every insert
* Database triggers 10\_000 inserts per second
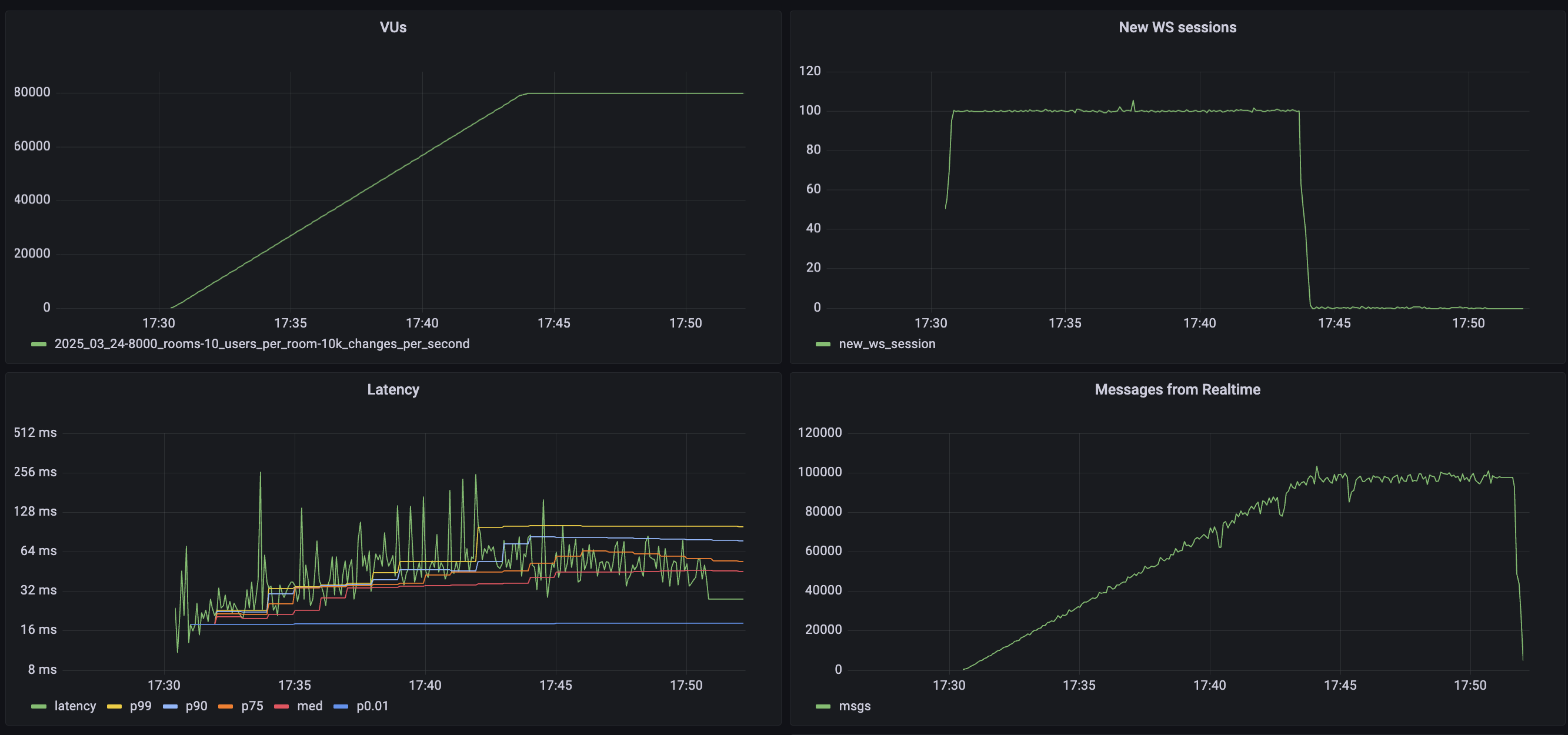
| Metric | Value |
| ------------------- | ---------------------- |
| Concurrent Users | 80\_000 |
| Total Channel Joins | 160\_000 |
| Message Throughput | 10\_000 msgs/sec |
| Median Latency | 46 ms |
| Latency (p95) | 132 ms |
| Latency (p99) | 159 ms |
| Data Received | 1.7 MB/s (42 GB total) |
| Data Sent | 0.4 MB/s (4 GB total) |
| New Connection Rate | 2000 conn/sec |
| Channel Join Rate | 4000 joins/sec |
### Broadcast: Impact of payload size
This workload tests the system's performance with different message payload sizes to understand how data volume affects throughput and latency. Each virtual user (VU) follows the same connection pattern as the broadcast test, but with varying message sizes:
* Establishes and maintains a WebSocket connection
* Joins two distinct channels:
* An echo channel (1 user per channel) for direct message reflection
* A broadcast channel (6 users per channel) for group communication
* Sends messages with payloads of 1KB, 10KB, and 50KB
* Generates traffic by sending 2 messages per second to each joined channel for 5 minutes
#### 1KB payload
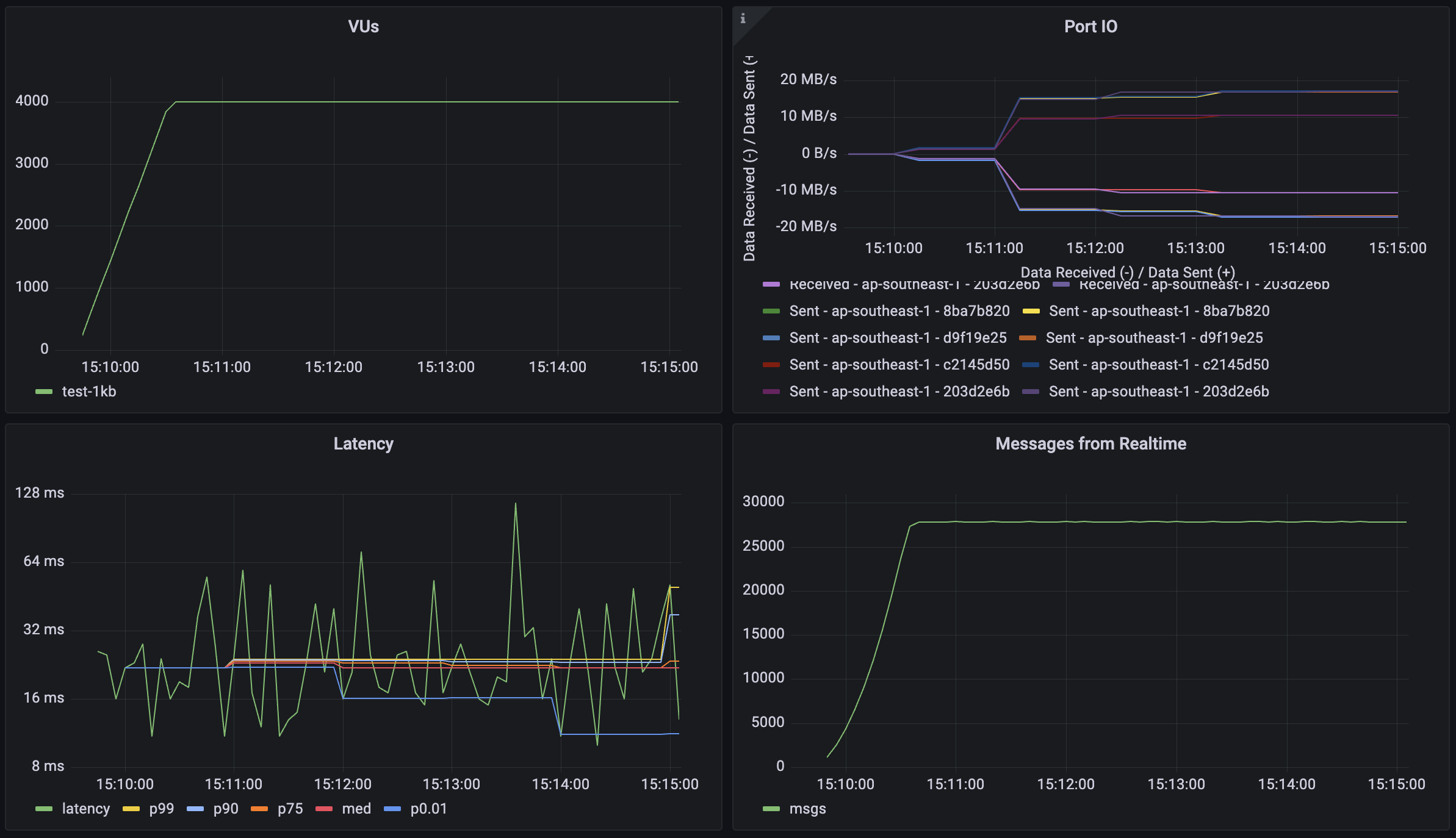
#### 10KB payload
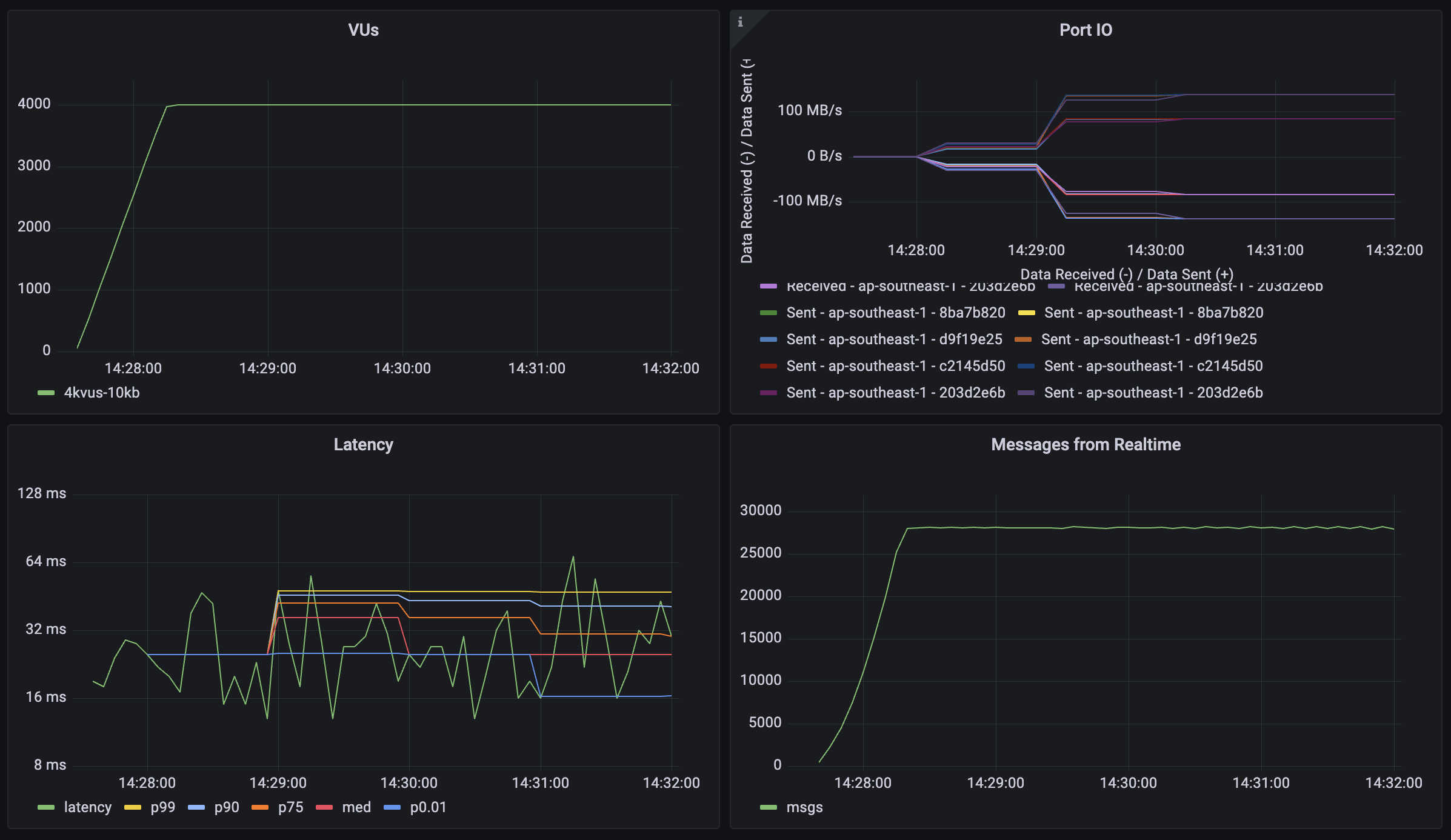
#### 50KB payload
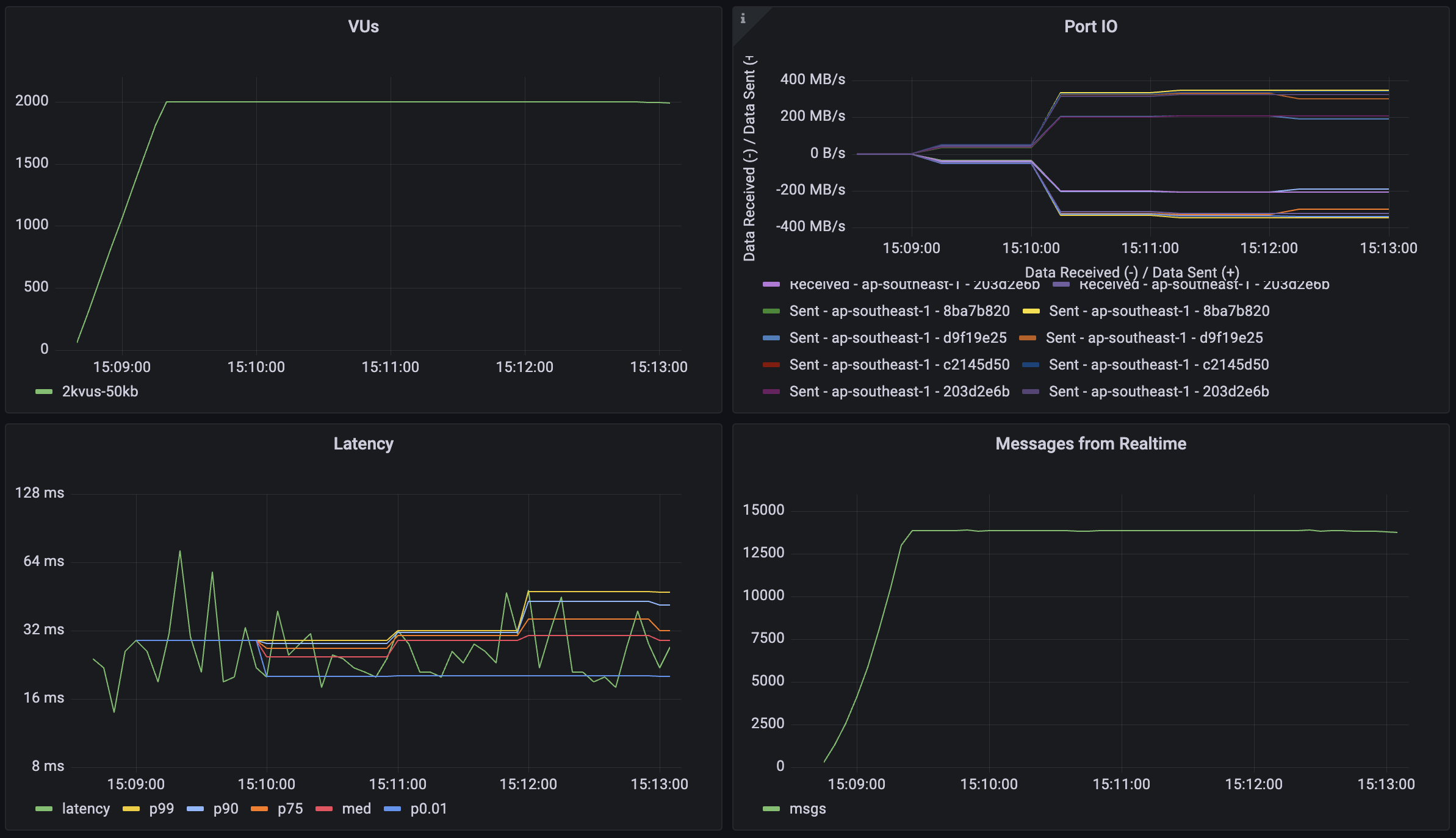
| Metric | 1KB Payload | 10KB Payload | 50KB Payload | 50KB Payload (Reduced Load) |
| ------------------ | ------------------- | ----------------- | ------------------ | --------------------------- |
| Concurrent Users | 4\_000 | 4\_000 | 4\_000 | 2\_000 |
| Message Throughput | 28\_000 msgs/sec | 28\_000 msgs/sec | 28\_000 msgs/sec | 14\_000 msgs/sec |
| Median Latency | 13 ms | 16 ms | 27 ms | 19 ms |
| Latency (p95) | 36 ms | 42 ms | 81 ms | 39 ms |
| Latency (p99) | 85 ms | 93 ms | 146 ms | 82 ms |
| Data Received | 31.2 MB/s (10.4 GB) | 268 MB/s (72 GB) | 1284 MB/s (348 GB) | 644 MB/s (176 GB) |
| Data Sent | 9.2 MB/s (3.1 GB) | 76 MB/s (20.8 GB) | 384 MB/s (104 GB) | 192 MB/s (52 GB) |
> Note: The final column shows results with reduced load (2,000 users) for the 50KB payload test, demonstrating how the system performs with larger payloads under different concurrency levels.
### Broadcast: Scalability scenarios
This workload demonstrates Realtime's capability to handle high-scale scenarios with a large number of concurrent users and broadcast channels. The test simulates a scenario where each user participates in group communications with periodic message broadcasts. Each virtual user (VU):
* Establishes and maintains a WebSocket connection (30-120 minutes)
* Joins 2 broadcast channels
* Sends 1 message per minute to each joined channel
* Each message is broadcast to 100 other users
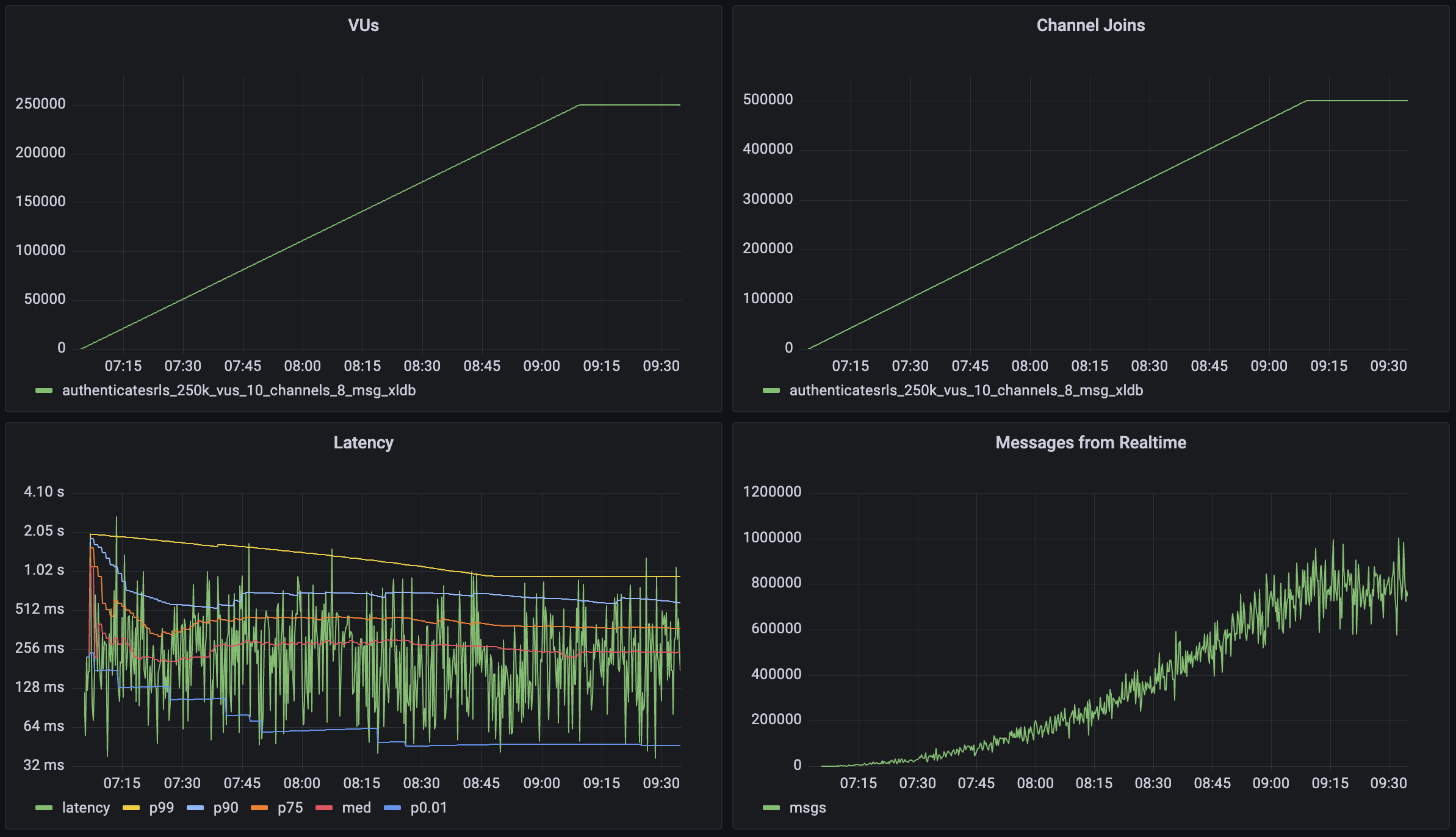
| Metric | Value |
| ------------------- | ------------------ |
| Concurrent Users | 250\_000 |
| Total Channel Joins | 500\_000 |
| Users per Channel | 100 |
| Message Throughput | >800\_000 msgs/sec |
| Median Latency | 58 ms |
| Latency (p95) | 279 ms |
| Latency (p99) | 508 ms |
| Data Received | 68 MB/s (600 GB) |
| Data Sent | 0.64 MB/s (5.7 GB) |
### Realtime Auth
This workload demonstrates Realtime's capability to handle large amounts of new connections per second and channel joins per second with Authentication Row Level Security (RLS) enabled for these channels. The test simulates a scenario where large volumes of users connect to realtime and participate in auth protected communications. Each virtual user (VU):
* Establishes and maintains a WebSocket connection (2.5 minutes)
* Joins 2 broadcast channels
* Sends 1 message per minute to each joined channel
* Each message is broadcast to 100 other users
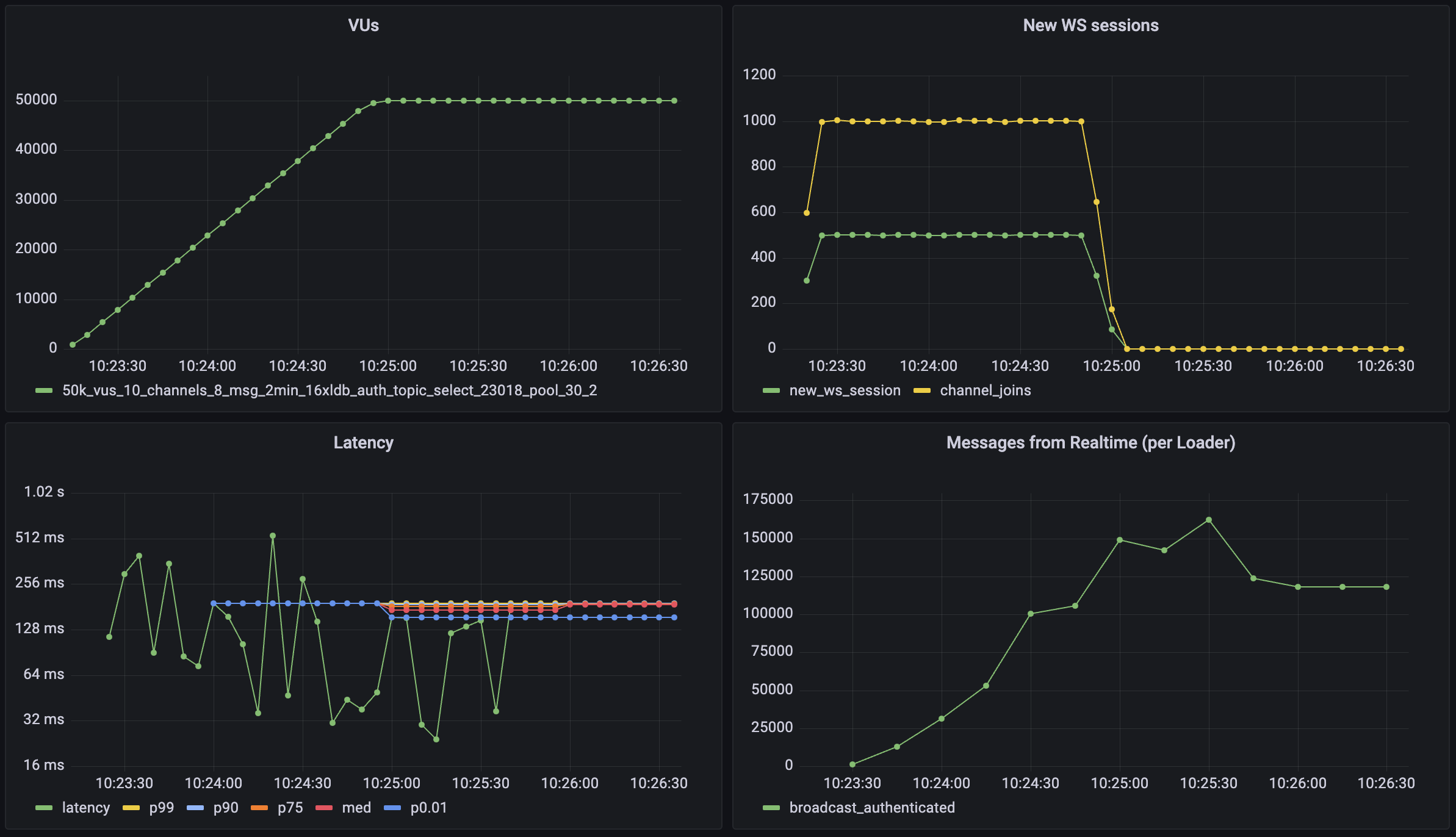
| Metric | Value |
| ------------------- | ------------------ |
| Concurrent Users | 50\_000 |
| Total Channel Joins | 100\_000 |
| Users per Channel | 100 |
| Message Throughput | >150\_000 msgs/sec |
| New Connection Rate | 500 conn/sec |
| Channel Join Rate | 1000 joins/sec |
| Median Latency | 19 ms |
| Latency (p95) | 49 ms |
| Latency (p99) | 96 ms |
### Postgres Changes
Realtime systems usually require forethought because of their scaling dynamics. For the `Postgres Changes` feature, every change event must be checked to see if the subscribed user has access. For instance, if you have 100 users subscribed to a table where you make a single insert, it will then trigger 100 "reads": one for each user.
There can be a database bottleneck which limits message throughput. If your database cannot authorize the changes rapidly enough, the changes will be delayed until you receive a timeout.
Database changes are processed on a single thread to maintain the change order. That means compute upgrades don't have a large effect on the performance of Postgres change subscriptions. You can estimate the expected maximum throughput for your database below.
If you are using Postgres Changes at scale, you should consider using a separate "public" table without RLS and filters. Alternatively, you can use Realtime server-side only and then re-stream the changes to your clients using a Realtime Broadcast.
Enter your database settings to estimate the maximum throughput for your instance:
Don't forget to run your own benchmarks to make sure that the performance is acceptable for your use case.
Supabase continues to make improvements to Realtime's Postgres Changes. If you are uncertain about your use case performance, reach out using the [Support Form](/dashboard/support/new). The support team can advise on the best solution for each use-case.
# Broadcast
Send low-latency messages using the client libs, REST, or your Database.
You can use Realtime Broadcast to send low-latency messages between users. Messages can be sent using the client libraries, REST APIs, or directly from your database.
## How Broadcast works
The way Broadcast works changes based on the channel you are using:
* **REST API**: Receives an HTTP request and then sends a message via WebSocket to connected clients
* **Client libraries**: Sends a message via WebSocket to the server, and then the server sends a message via WebSocket to connected clients
* **Database**: Adds a new entry to `realtime.messages` where a logical replication is set to listen for changes, and then sends a message via WebSocket to connected clients
The public flag (the last argument in `realtime.send(payload, event, topic, is_private)`) only affects who can subscribe to the topic not who can read messages from the database.
* Public (`false`) → Anyone can subscribe to that topic without authentication
* Private (`true`) → Only authenticated clients can subscribe to that topic
Regardless if it's public or private, the Realtime service connects to your database as the authenticated Supabase Admin role.
For Authorization, we insert a message and try to read it, and rollback the transaction to verify that the Row Level Security (RLS) policies set by the user are being respected by the user joining the channel, but this message isn't sent to the user. You can read more about it in [Authorization](/docs/guides/realtime/authorization).
## Subscribe to messages
You can use the Supabase client libraries to receive Broadcast messages.
### Initialize the client
{/* TODO: Further consolidate partial */}
Get the Project URL and key from [the project's **Connect** dialog](/dashboard/project/_?showConnect=true).
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement](https://github.com/orgs/supabase/discussions/29260), but in the transition period, you can use both the current `anon` and `service_role` keys and the new publishable key with the form `sb_publishable_xxx` which will replace the older keys.
**The legacy keys will be deprecated shortly, so we strongly encourage switching to and using the new publishable and secret API keys**.
In most cases, you can get the correct key from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true), but if you want a specific key, you can find all keys in [the API Keys section of a Project's Settings page](/dashboard/project/_/settings/api-keys/):
**For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
```js
import { createClient } from '@supabase/supabase-js'
const SUPABASE_URL = 'https://.supabase.co'
const SUPABASE_KEY = ''
const supabase = createClient(SUPABASE_URL, SUPABASE_KEY)
```
```dart
import 'package:supabase_flutter/supabase_flutter.dart';
void main() async {
Supabase.initialize(
url: 'https://.supabase.co',
publishableKey: '',
);
runApp(MyApp());
}
final supabase = Supabase.instance.client;
```
```swift
import Supabase
let SUPABASE_URL = "https://.supabase.co"
let SUPABASE_KEY = ""
let supabase = SupabaseClient(supabaseURL: URL(string: SUPABASE_URL)!, supabaseKey: SUPABASE_KEY)
```
```kotlin
val supabaseUrl = "https://.supabase.co"
val supabaseKey = ""
val supabase = createSupabaseClient(supabaseUrl, supabaseKey) {
install(Realtime)
}
```
```python
import asyncio
from supabase import acreate_client
URL = "https://.supabase.co"
KEY = ""
async def create_supabase():
supabase = await acreate_client(URL, KEY)
return supabase
```
### Receive Broadcast messages
You can receive Broadcast messages by providing a callback to the channel.
{/* prettier-ignore */}
```js
// @noImplicitAny: false
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://.supabase.co', '')
// ---cut---
// Join a room/topic. Can be anything except for 'realtime'.
const myChannel = supabase.channel('test-channel')
// Simple function to log any messages we receive
function messageReceived(payload) {
console.log(payload)
}
// Subscribe to the Channel
myChannel
.on(
'broadcast',
{ event: 'shout' }, // Listen for "shout". Can be "*" to listen to all events
(payload) => messageReceived(payload)
)
.subscribe()
```
{/* prettier-ignore */}
```dart
final myChannel = supabase.channel('test-channel');
// Simple function to log any messages we receive
void messageReceived(payload) {
print(payload);
}
// Subscribe to the Channel
myChannel
.onBroadcast(
event: 'shout', // Listen for "shout". Can be "*" to listen to all events
callback: (payload) => messageReceived(payload)
)
.subscribe();
```
```swift
let myChannel = await supabase.channel("test-channel")
// Listen for broadcast messages
let broadcastStream = await myChannel.broadcast(event: "shout") // Listen for "shout". Can be "*" to listen to all events
await myChannel.subscribe()
for await event in broadcastStream {
print(event)
}
```
{/* prettier-ignore */}
```kotlin
val myChannel = supabase.channel("test-channel")
/ Listen for broadcast messages
val broadcastFlow: Flow = myChannel
.broadcastFlow("shout") // Listen for "shout". Can be "*" to listen to all events
.onEach { println(it) }
.launchIn(yourCoroutineScope) // you can also use .collect { } here
myChannel.subscribe()
```
In the following Realtime examples, certain methods are awaited. These should be enclosed within an `async` function.
{/* prettier-ignore */}
```python
# Join a room/topic. Can be anything except for 'realtime'.
my_channel = supabase.channel('test-channel')
# Simple function to log any messages we receive
def message_received(payload):
print(f"Broadcast received: {payload}")
# Subscribe to the Channel
await my_channel
.on_broadcast('shout', message_received) # Listen for "shout". Can be "*" to listen to all events
.subscribe()
```
## Send messages
### Broadcast using the client libraries
You can use the Supabase client libraries to send Broadcast messages.
{/* prettier-ignore */}
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const myChannel = supabase.channel('test-channel')
/**
* Sending a message before subscribing will use HTTP
*/
myChannel
.send({
type: 'broadcast',
event: 'shout',
payload: { message: 'Hi' },
})
.then((resp) => console.log(resp))
/**
* Sending a message after subscribing will use WebSockets
*/
myChannel.subscribe((status) => {
if (status !== 'SUBSCRIBED') {
return null
}
myChannel.send({
type: 'broadcast',
event: 'shout',
payload: { message: 'Hi' },
})
})
```
{/* prettier-ignore */}
```dart
final myChannel = supabase.channel('test-channel');
// Sending a message before subscribing will use HTTP
final res = await myChannel.sendBroadcastMessage(
event: "shout",
payload: { 'message': 'Hi' },
);
print(res);
// Sending a message after subscribing will use WebSockets
myChannel.subscribe((status, error) {
if (status != RealtimeSubscribeStatus.subscribed) {
return;
}
myChannel.sendBroadcastMessage(
event: 'shout',
payload: { 'message': 'hello, world' },
);
});
```
{/* prettier-ignore */}
```swift
let myChannel = await supabase.channel("test-channel") {
$0.broadcast.acknowledgeBroadcasts = true
}
// Sending a message before subscribing will use HTTP
await myChannel.broadcast(event: "shout", message: ["message": "HI"])
// Sending a message after subscribing will use WebSockets
await myChannel.subscribe()
try await myChannel.broadcast(
event: "shout",
message: YourMessage(message: "hello, world!")
)
```
```kotlin
val myChannel = supabase.channel("test-channel") {
broadcast {
acknowledgeBroadcasts = true
}
}
// Sending a message before subscribing will use HTTP
myChannel.broadcast(event = "shout", buildJsonObject {
put("message", "Hi")
})
// Sending a message after subscribing will use WebSockets
myChannel.subscribe(blockUntilSubscribed = true)
channelB.broadcast(
event = "shout",
payload = YourMessage(message = "hello, world!")
)
```
When an asynchronous method needs to be used within a synchronous context, such as the callback for `.subscribe()`, utilize `asyncio.create_task()` to schedule the coroutine. This is why the [initialize the client](#initialize-the-client) example includes an import of `asyncio`.
{/* prettier-ignore */}
```python
my_channel = supabase.channel('test-channel')
# Sending a message after subscribing will use WebSockets
def on_subscribe(status, err):
if status != RealtimeSubscribeStates.SUBSCRIBED:
return
asyncio.create_task(my_channel.send_broadcast(
'shout',
{ "message": 'hello, world' },
))
await my_channel.subscribe(on_subscribe)
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Broadcast from the Database
All the messages sent using Broadcast from the Database are stored in `realtime.messages` table and will be deleted after 3 days.
You can send messages directly from your database using the `realtime.send()` function:
{/* prettier-ignore */}
```sql
select
realtime.send(
jsonb_build_object('hello', 'world'), -- JSONB Payload
'event', -- Event name
'topic', -- Topic
false -- Public / Private flag
);
```
The `realtime.send()` function in the database includes a flag that determines whether the broadcast is private or public, and client channels also have the same configuration. For broadcasts to work correctly, these settings must match. A public broadcast only reaches public channels and a private broadcast only reaches private channels.
By default, all database broadcasts are private, meaning clients must authenticate to receive them. If the database sends a public message but the client subscribes to a private channel, the message is not delivered because private channels only accept signed, authenticated messages.
You can use the `realtime.broadcast_changes()` helper function to broadcast messages when a record is created, updated, or deleted. For more details, read [Subscribing to Database Changes](/docs/guides/realtime/subscribing-to-database-changes).
### Broadcast using the REST API
You can send a Broadcast message by making an HTTP request to Realtime servers.
{/* prettier-ignore */}
```bash
curl -v \
-H 'apikey: ' \
-H 'Content-Type: application/json' \
--data-raw '{
"messages": [
{
"topic": "test",
"event": "event",
"payload": { "test": "test" }
}
]
}' \
'https://.supabase.co/realtime/v1/api/broadcast'
```
{/* prettier-ignore */}
```bash
POST /realtime/v1/api/broadcast HTTP/1.1
Host: {PROJECT_REF}.supabase.co
Content-Type: application/json
apikey: {SUPABASE_TOKEN}
{
"messages": [
{
"topic": "test",
"event": "event",
"payload": {
"test": "test"
}
}
]
}
```
## Broadcast options
You can pass configuration options while initializing the Supabase Client.
### Self-send messages
By default, broadcast messages are only sent to other clients. You can broadcast messages back to the sender by setting Broadcast's `self` parameter to `true`.
{/* prettier-ignore */}
```js
const myChannel = supabase.channel('room-2', {
config: {
broadcast: { self: true },
},
})
myChannel.on(
'broadcast',
{ event: 'test-my-messages' },
(payload) => console.log(payload)
)
myChannel.subscribe((status) => {
if (status !== 'SUBSCRIBED') { return }
myChannel.send({
type: 'broadcast',
event: 'test-my-messages',
payload: { message: 'talking to myself' },
})
})
```
By default, broadcast messages are only sent to other clients. You can broadcast messages back to the sender by setting Broadcast's `self` parameter to `true`.
```dart
final myChannel = supabase.channel(
'room-2',
opts: const RealtimeChannelConfig(
self: true,
),
);
myChannel.onBroadcast(
event: 'test-my-messages',
callback: (payload) => print(payload),
);
myChannel.subscribe((status, error) {
if (status != RealtimeSubscribeStatus.subscribed) return;
// channelC.send({
myChannel.sendBroadcastMessage(
event: 'test-my-messages',
payload: {'message': 'talking to myself'},
);
});
```
By default, broadcast messages are only sent to other clients. You can broadcast messages back to the sender by setting Broadcast's `receiveOwnBroadcasts` parameter to `true`.
```swift
let myChannel = await supabase.channel("room-2") {
$0.broadcast.receiveOwnBroadcasts = true
}
let broadcastStream = await myChannel.broadcast(event: "test-my-messages")
await myChannel.subscribe()
try await myChannel.broadcast(
event: "test-my-messages",
payload: YourMessage(
message: "talking to myself"
)
)
```
By default, broadcast messages are only sent to other clients. You can broadcast messages back to the sender by setting Broadcast's `receiveOwnBroadcasts` parameter to `true`.
```kotlin
val myChannel = supabase.channel("room-2") {
broadcast {
receiveOwnBroadcasts = true
}
}
val broadcastFlow: Flow = myChannel.broadcastFlow("test-my-messages")
.onEach {
println(it)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe(blockUntilSubscribed = true) //You can also use the myChannel.status flow instead, but this parameter will block the coroutine until the status is joined.
myChannel.broadcast(
event = "test-my-messages",
payload = YourMessage(
message = "talking to myself"
)
)
```
When an asynchronous method needs to be used within a synchronous context, such as the callback for `.subscribe()`, utilize `asyncio.create_task()` to schedule the coroutine. This is why the [initialize the client](#initialize-the-client) example includes an import of `asyncio`.
By default, broadcast messages are only sent to other clients. You can broadcast messages back to the sender by setting Broadcast's `self` parameter to `True`.
```python
# Join a room/topic. Can be anything except for 'realtime'.
my_channel = supabase.channel('room-2', {"config": {"broadcast": {"self": True}}})
my_channel.on_broadcast(
'test-my-messages',
lambda payload: print(payload)
)
def on_subscribe(status, err):
if status != RealtimeSubscribeStates.SUBSCRIBED:
return
# Send a message once the client is subscribed
asyncio.create_task(channel_b.send_broadcast(
'test-my-messages',
{ "message": 'talking to myself' },
))
my_channel.subscribe(on_subscribe)
```
### Acknowledge messages
You can confirm that the Realtime servers have received your message by setting Broadcast's `ack` setting to `true`.
{/* prettier-ignore */}
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const myChannel = supabase.channel('room-3', {
config: {
broadcast: { ack: true },
},
})
myChannel.subscribe(async (status) => {
if (status !== 'SUBSCRIBED') { return }
const serverResponse = await myChannel.send({
type: 'broadcast',
event: 'acknowledge',
payload: {},
})
console.log('serverResponse', serverResponse)
})
```
```dart
final myChannel = supabase.channel('room-3',opts: const RealtimeChannelConfig(
ack: true,
),
);
myChannel.subscribe( (status, error) async {
if (status != RealtimeSubscribeStatus.subscribed) return;
final serverResponse = await myChannel.sendBroadcastMessage(
event: 'acknowledge',
payload: {},
);
print('serverResponse: $serverResponse');
});
```
You can confirm that Realtime received your message by setting Broadcast's `acknowledgeBroadcasts` config to `true`.
```swift
let myChannel = await supabase.channel("room-3") {
$0.broadcast.acknowledgeBroadcasts = true
}
await myChannel.subscribe()
await myChannel.broadcast(event: "acknowledge", message: [:])
```
By default, broadcast messages are only sent to other clients. You can broadcast messages back to the sender by setting Broadcast's `acknowledgeBroadcasts` parameter to `true`.
```kotlin
val myChannel = supabase.channel("room-2") {
broadcast {
acknowledgeBroadcasts = true
}
}
myChannel.subscribe(blockUntilSubscribed = true) //You can also use the myChannel.status flow instead, but this parameter will block the coroutine until the status is joined.
myChannel.broadcast(event = "acknowledge", buildJsonObject { })
```
Unsupported in Python yet.
Use this to guarantee that the server has received the message before resolving `channelD.send`'s promise. If the `ack` config is not set to `true` when creating the channel, the promise returned by `channelD.send` will resolve immediately.
### Send messages using REST calls
You can also send a Broadcast message by making an HTTP request to Realtime servers. This is useful when you want to send messages from your server or client without having to first establish a WebSocket connection.
This is currently available only in the Supabase JavaScript client version 2.37.0 and later.
```js
const channel = supabase.channel('test-channel')
// No need to subscribe to channel
channel
.send({
type: 'broadcast',
event: 'test',
payload: { message: 'Hi' },
})
.then((resp) => console.log(resp))
// Remember to clean up the channel
supabase.removeChannel(channel)
```
```dart
// No need to subscribe to channel
final channel = supabase.channel('test-channel');
final res = await channel.sendBroadcastMessage(
event: "test",
payload: {
'message': 'Hi',
},
);
print(res);
```
```swift
let myChannel = await supabase.channel("room-2") {
$0.broadcast.acknowledgeBroadcasts = true
}
// No need to subscribe to channel
await myChannel.broadcast(event: "test", message: ["message": "HI"])
```
```kotlin
val myChannel = supabase.channel("room-2") {
broadcast {
acknowledgeBroadcasts = true
}
}
// No need to subscribe to channel
myChannel.broadcast(event = "test", buildJsonObject {
put("message", "Hi")
})
```
Unsupported in Python yet.
## Trigger broadcast messages from your database
### How it works
Broadcast Changes allows you to trigger messages from your database. To achieve it, Realtime directly reads your Write-Ahead Log (WAL) file using a publication against the `realtime.messages` table. Whenever a new insert occurs, a message is sent to connected users.
It uses partitioned tables per day, which allows performant deletion of your previous messages by dropping the physical tables of this partitioned table. Tables older than 3 days are deleted.
Broadcasting from the database works like a client-side broadcast, using WebSockets to send JSON payloads. [Realtime Authorization](/docs/guides/realtime/authorization) is required and enabled by default to protect your data.
Broadcast Changes provides two functions to help you send messages:
* `realtime.send()` inserts a message into `realtime.messages` without a specific format.
* `realtime.broadcast_changes()` inserts a message with the required fields to emit database changes to clients. This helps you set up triggers on your tables to emit changes.
### Broadcasting a message from your database
The `realtime.send()` function provides the most flexibility by allowing you to broadcast messages from your database without a specific format. This allows you to use database broadcast for messages that aren't necessarily tied to the shape of a Postgres row change.
```sql
SELECT realtime.send (
'{}'::jsonb, -- JSONB Payload
'event', -- Event name
'topic', -- Topic
FALSE -- Public / Private flag
);
```
### Broadcast record changes
#### Setup realtime authorization
Realtime Authorization is required and enabled by default. To allow your users to listen to messages from topics, create an RLS policy:
```sql
CREATE POLICY "authenticated can receive broadcasts"
ON "realtime"."messages"
FOR SELECT
TO authenticated
USING ( true );
```
Read [Realtime Authorization](/docs/guides/realtime/authorization) to learn how to set up more specific policies.
#### Set up trigger function
First, set up a trigger function that uses the `realtime.broadcast_changes()` function to insert an event whenever it is triggered. The event is set up to include data on the schema, table, operation, and field changes that triggered it.
For this example, you're going broadcast events to a topic named `topic:`.
```sql
CREATE OR REPLACE FUNCTION public.your_table_changes()
RETURNS trigger
SECURITY DEFINER SET search_path = ''
AS $$
BEGIN
PERFORM realtime.broadcast_changes(
'topic:' || NEW.id::text, -- topic
TG_OP, -- event
TG_OP, -- operation
TG_TABLE_NAME, -- table
TG_TABLE_SCHEMA, -- schema
NEW, -- new record
OLD -- old record
);
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
```
The Postgres native trigger special variables used are:
* `TG_OP` - the operation that triggered the function
* `TG_TABLE_NAME` - the table that caused the trigger
* `TG_TABLE_SCHEMA` - the schema of the table that caused the trigger invocation
* `NEW` - the record after the change
* `OLD` - the record before the change
You can read more about them in this [guide](https://www.postgresql.org/docs/current/plpgsql-trigger.html#PLPGSQL-DML-TRIGGER).
#### Set up trigger
Next, set up a trigger so the function runs whenever your target table has a change.
```sql
CREATE TRIGGER broadcast_changes_for_your_table_trigger
AFTER INSERT OR UPDATE OR DELETE ON public.your_table
FOR EACH ROW
EXECUTE FUNCTION your_table_changes ();
```
As you can see, it will be broadcasting all operations so our users will receive events when records are inserted, updated or deleted from `public.your_table` .
#### Listen on client side
Finally, client side will requires to be set up to listen to the topic `topic:` to receive the events.
```jsx
const gameId = 'id'
await supabase.realtime.setAuth() // Needed for Realtime Authorization
const changes = supabase
.channel(`topic:${gameId}`)
.on('broadcast', { event: 'INSERT' }, (payload) => console.log(payload))
.on('broadcast', { event: 'UPDATE' }, (payload) => console.log(payload))
.on('broadcast', { event: 'DELETE' }, (payload) => console.log(payload))
.subscribe()
```
## Broadcast replay
### How it works
Broadcast Replay enables **private** channels to access messages that were sent earlier. Only messages published via [Broadcast From the Database](#broadcast-from-the-database) are available for replay.
You can configure replay with the following options:
* **`since`** (Required): The epoch timestamp in milliseconds (for example, `1697472000000`), specifying the earliest point from which messages should be retrieved.
* **`limit`** (Optional): The number of messages to return. This must be a positive integer, with a maximum value of 25.
This is currently available only in the Supabase JavaScript client version 2.74.0 and later.
```js
const config = {
private: true,
broadcast: {
replay: {
since: 1697472000000, // Unix timestamp in milliseconds
limit: 10
}
}
}
const channel = supabase.channel('main:room', { config })
// Broadcast callback receives meta field
channel.on('broadcast', { event: 'position' }, (payload) => {
if (payload?.meta?.replayed) {
console.log('Replayed message: ', payload)
} else {
console.log('This is a new message', payload)
}
// ...
})
.subscribe()
```
This is currently available only in the Supabase Dart client version 2.10.0 and later.
```dart
// Configure broadcast with replay
final channel = supabase.channel(
'my-channel',
RealtimeChannelConfig(
self: true,
ack: true,
private: true,
replay: ReplayOption(
since: 1697472000000, // Unix timestamp in milliseconds
limit: 25,
),
),
);
// Broadcast callback receives meta field
channel.onBroadcast(
event: 'position',
callback: (payload) {
final meta = payload['meta'] as Map?;
if (meta?['replayed'] == true) {
print('Replayed message: ${meta?['id']}');
}
},
).subscribe();
```
This is currently available only in the Supabase Swift client version 2.34.0 and later.
```swift
// Configure broadcast with replay
let channel = supabase.realtimeV2.channel("my-channel") {
$0.isPrivate = true
$0.broadcast.acknowledgeBroadcasts = true
$0.broadcast.receiveOwnBroadcasts = true
$0.broadcast.replay = ReplayOption(
since: 1697472000000, // Unix timestamp in milliseconds
limit: 25
)
}
var subscriptions = Set()
// Broadcast callback receives meta field
channel.onBroadcast(event: "position") { message in
if let meta = message["payload"]?.objectValue?["meta"]?.objectValue,
let replayed = meta["replayed"]?.boolValue,
replayed {
print("Replayed message: \(meta["id"]?.stringValue ?? "")")
}
}
.store(in: &subscriptions)
await channel.subscribe()
```
Unsupported in Kotlin for now.
This is currently available only in the Supabase Python client version 2.22.0 and later.
```python
# Configure broadcast with replay
channel = client.channel('my-channel', {
'config': {
"private": True,
'broadcast': {
'self': True,
'ack': True,
'replay': {
'since': 1697472000000,
'limit': 100
}
}
}
})
# Broadcast callback receives meta field
def on_broadcast(payload):
if payload.get('meta', {}).get('replayed'):
print(f"Replayed message: {payload['meta']['id']}")
await channel.on_broadcast('position', on_broadcast)
await channel.subscribe()
```
#### When to use Broadcast replay
A few common use cases for Broadcast Replay include:
* Displaying the most recent messages from a chat room
* Loading the last events that happened during a sports event
* Ensuring users always see the latest events after a page reload or network interruption
* Highlighting the most recent sections that changed in a web page
# Realtime Concepts
## Concepts
There are several concepts and terminology that is useful to understand how Realtime works.
* **Channels**: the foundation of Realtime. Think of them as rooms where clients can communicate and listen to events. Channels are identified by a topic name and if they are public or private.
* **Topics**: the name of the channel. They are used to identify the channel and are a string used to identify the channel.
* **Events**: the type of messages that can be sent and received.
* **Payload**: the actual data that is sent and received and that the user will act upon.
* **Concurrent Connections**: number of total channels subscribed for all clients.
## Channels
Channels are the foundation of Realtime. Think of them as rooms where clients can communicate and listen to events. Channels are identified by a topic name and if they are public or private.
For private channels, you need to use [Realtime Authorization](/docs/guides/realtime/authorization) to control access to the channel and if they are able to send messages.
For public channels, any user can subscribe to the channel, send and receive messages.
You can set your project to use only private channels or both private and public channels in the [Realtime Settings](/docs/guides/realtime/settings).
If you have a private channel and a public channel with the same topic name, Realtime sees them as unique channels and won't send messages between them.
## Database resources
### Database connections
Realtime uses several database connections to perform various operations. You can configure some of these connections through [Realtime Settings](/docs/guides/realtime/settings).
The connections include:
* **Migrations**: Two temporary connections to run database migrations when needed
* **Authorization**: Configurable connection pool to check authorization policies on join that are always started.
* **Broadcast from database**: One connection to receive data from replication slot used to broadcast the changes to the clients that is always started.
* **Postgres Changes**: Multiple connection pools required. These pools are only started if you use Postgres Changes.
* **Subscription management**: To manage the subscribers to Postgres Changes
* **Subscription cleanup**: To cleanup the subscribers to Postgres Changes
* **WAL pull**: To pull the changes from the database
The number of connections varies based on your compute add-on size and configuration. The following table shows the default connection pool sizes for different compute add-on variants:
| Compute Add-on | Broadcast from database | Authorization Pool Size | Subscription management | Subscription cleanup | WAL pull |
| -------------- | ----------------------- | ----------------------- | ----------------------- | -------------------- | -------- |
| Nano | 1 | 2 | 2 | 2 | 2 |
| Micro | 1 | 2 | 2 | 2 | 2 |
| Small | 1 | 5 | 4 | 4 | 4 |
| Medium | 1 | 5 | 4 | 4 | 4 |
| Large | 1 | 5 | 4 | 4 | 4 |
| XL | 1 | 10 | 7 | 7 | 7 |
| 2XL | 1 | 10 | 7 | 7 | 7 |
| 4XL | 1 | 10 | 7 | 7 | 7 |
| 8XL | 1 | 15 | 9 | 9 | 9 |
| 12XL | 1 | 15 | 9 | 9 | 9 |
| 16XL | 1 | 15 | 9 | 9 | 9 |
| >16XL | 1 | 15 | 9 | 9 | 9 |
You can customize `Authorization Pool Size` through the `Database connection pool size` parameter in your Realtime configuration. If not specified, the default values shown in the table will be used.
### Replication slots
Realtime also uses, at maximum, 2 replication slots.
* **Broadcast from database**: To broadcast the changes from the database to the clients
* **Postgres Changes**: To listen to changes from the database
### Schema and tables
The `realtime` schema creates the following tables:
* `schema_migrations` - To track the migrations that have been run on the database from Realtime
* `subscription` - Track the subscribers to Postgres Changes
* `messages` - Partitioned table per day that's used for Authorization and Broadcast from database
* **Authorization**: To check the authorization policies on join by checking if a given user can read and write to this table
* **Broadcast from database**: Replication slot tracks a publication to this table to broadcast the changes to the connected clients.
* The schema from the table is the following:
```sql
create table realtime.messages (
topic text not null, -- The topic of the message
extension text not null, -- The extension of the message (presence, broadcast)
payload jsonb null, -- The payload of the message
event text null, -- The event of the message
private boolean null default false, -- If the message is going to use a private channel
updated_at timestamp without time zone not null default now(), -- The timestamp of the message
inserted_at timestamp without time zone not null default now(), -- The timestamp of the message
id uuid not null default gen_random_uuid (), -- The id of the message
constraint messages_pkey primary key (id, inserted_at)) partition by RANGE (inserted_at);
```
Realtime has a cleanup process that will delete tables older than 3 days.
### Functions
Realtime creates two functions on your database:
* `realtime.send` - Inserts an entry into `realtime.messages` table that will trigger the replication slot to broadcast the changes to the clients. It also captures errors to prevent the trigger from breaking.
* `realtime.broadcast_changes` - uses `realtime.send` to broadcast the changes with a format that is compatible with Postgres Changes
# Operational Error Codes
List of operational codes to help understand your deployment and usage.
# Getting Started with Realtime
Learn how to build real-time applications with Supabase Realtime
## Quick start
### 1. Install the client library
```bash
npm install @supabase/supabase-js
```
```bash
flutter pub add supabase_flutter
```
```swift
let package = Package(
// ...
dependencies: [
// ...
.package(
url: "https://github.com/supabase/supabase-swift.git",
from: "2.0.0"
),
],
targets: [
.target(
name: "YourTargetName",
dependencies: [
.product(
name: "Supabase",
package: "supabase-swift"
),
]
)
]
)
```
```bash
pip install supabase
```
```bash
conda install -c conda-forge supabase
```
### 2. Initialize the client
Get your project URL and key.
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=\&framework=).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=\&framework=), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://.supabase.co', '')
```
```dart
import 'package:supabase_flutter/supabase_flutter.dart';
void main() async {
await Supabase.initialize(
url: 'https://.supabase.co',
publishableKey: '',
);
runApp(MyApp());
}
final supabase = Supabase.instance.client;
```
```swift
import Supabase
let supabase = SupabaseClient(
supabaseURL: URL(string: "https://.supabase.co")!,
supabaseKey: ""
)
```
```python
from supabase import create_client, Client
url: str = "https://.supabase.co"
key: str = ""
supabase: Client = create_client(url, key)
```
### 3. Create your first Channel
Channels are the foundation of Realtime. Think of them as rooms where clients can communicate. Each channel is identified by a topic name and if they are public or private.
```ts
// Create a channel with a descriptive topic name
const channel = supabase.channel('room:lobby:messages', {
config: { private: true }, // Recommended for production
})
```
```dart
// Create a channel with a descriptive topic name
final channel = supabase.channel('room:lobby:messages');
```
```swift
// Create a channel with a descriptive topic name
let channel = supabase.channel("room:lobby:messages") {
$0.isPrivate = true
}
```
```python
# Create a channel with a descriptive topic name
channel = supabase.channel('room:lobby:messages', params={'config': {'private': True }})
```
### 4. Set up authorization
Since we're using a private channel, you need to create a basic RLS policy on the `realtime.messages` table to allow authenticated users to connect. Row Level Security (RLS) policies control who can access your Realtime channels based on user authentication and custom rules:
```sql
-- Allow authenticated users to receive broadcasts
CREATE POLICY "authenticated_users_can_receive" ON realtime.messages
FOR SELECT TO authenticated USING (true);
-- Allow authenticated users to send broadcasts
CREATE POLICY "authenticated_users_can_send" ON realtime.messages
FOR INSERT TO authenticated WITH CHECK (true);
```
### 5. Send and receive messages
There are three main ways to send messages with Realtime:
#### 5.1 using client libraries
Send and receive messages using the Supabase client:
```ts
// Listen for messages
channel
.on('broadcast', { event: 'message_sent' }, (payload: { payload: any }) => {
console.log('New message:', payload.payload)
})
.subscribe()
// Send a message
channel.send({
type: 'broadcast',
event: 'message_sent',
payload: {
text: 'Hello, world!',
user: 'john_doe',
timestamp: new Date().toISOString(),
},
})
```
```dart
// Listen for messages
channel.onBroadcast(
event: 'message_sent',
callback: (payload) {
print('New message: ${payload['payload']}');
},
).subscribe();
// Send a message
channel.sendBroadcastMessage(
event: 'message_sent',
payload: {
'text': 'Hello, world!',
'user': 'john_doe',
'timestamp': DateTime.now().toIso8601String(),
},
);
```
```swift
// Listen for messages
await channel.onBroadcast(event: "message_sent") { message in
print("New message: \(message.payload)")
}
let status = await channel.subscribe()
// Send a message
await channel.sendBroadcastMessage(
event: "message_sent",
payload: [
"text": "Hello, world!",
"user": "john_doe",
"timestamp": ISO8601DateFormatter().string(from: Date())
]
)
```
```python
# Listen for messages
def message_handler(payload):
print(f"New message: {payload['payload']}")
channel.on_broadcast(event="message_sent", callback=message_handler).subscribe()
# Send a message
channel.send_broadcast_message(
event="message_sent",
payload={
"text": "Hello, world!",
"user": "john_doe",
"timestamp": datetime.now().isoformat()
}
)
```
#### 5.2 using HTTP/REST API
Send messages via HTTP requests, perfect for server-side applications:
```ts
// Send message via REST API
const response = await fetch(`https://.supabase.co/rest/v1/rpc/broadcast`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
-H "apikey: "
},
body: JSON.stringify({
topic: 'room:lobby:messages',
event: 'message_sent',
payload: {
text: 'Hello from server!',
user: 'system',
timestamp: new Date().toISOString(),
},
private: true,
}),
})
```
```dart
import 'package:http/http.dart' as http;
import 'dart:convert';
// Send message via REST API
final response = await http.post(
Uri.parse('https://.supabase.co/rest/v1/rpc/broadcast'),
headers: {
'Content-Type': 'application/json',
-H "apikey: "
},
body: jsonEncode({
'topic': 'room:lobby:messages',
'event': 'message_sent',
'payload': {
'text': 'Hello from server!',
'user': 'system',
'timestamp': DateTime.now().toIso8601String(),
},
'private': true,
}),
);
```
```swift
import Foundation
// Send message via REST API
let url = URL(string: "https://.supabase.co/rest/v1/rpc/broadcast")!
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
request.setValue("", forHTTPHeaderField: "apikey")
let payload = [
"topic": "room:lobby:messages",
"event": "message_sent",
"payload": [
"text": "Hello from server!",
"user": "system",
"timestamp": ISO8601DateFormatter().string(from: Date())
],
"private": true
] as [String: Any]
request.httpBody = try JSONSerialization.data(withJSONObject: payload)
let (data, response) = try await URLSession.shared.data(for: request)
```
```python
import requests
from datetime import datetime
# Send message via REST API
response = requests.post(
'https://.supabase.co/rest/v1/rpc/broadcast',
headers={
'Content-Type': 'application/json',
'apikey': ''
},
json={
'topic': 'room:lobby:messages',
'event': 'message_sent',
'payload': {
'text': 'Hello from server!',
'user': 'system',
'timestamp': datetime.now().isoformat()
},
'private': True
}
)
```
#### 5.3 using database triggers
Automatically broadcast database changes using triggers. Choose the approach that best fits your needs:
**Using `realtime.broadcast_changes` (Best for mirroring database changes)**
```sql
-- Create a trigger function for broadcasting database changes
CREATE OR REPLACE FUNCTION broadcast_message_changes()
RETURNS TRIGGER AS $$
BEGIN
-- Broadcast to room-specific channel
PERFORM realtime.broadcast_changes(
'room:' || NEW.room_id::text || ':messages',
TG_OP,
TG_OP,
TG_TABLE_NAME,
TG_TABLE_SCHEMA,
NEW,
OLD
);
RETURN NULL;
END;
$$ LANGUAGE plpgsql SECURITY DEFINER;
-- Apply trigger to your messages table
CREATE TRIGGER messages_broadcast_trigger
AFTER INSERT OR UPDATE OR DELETE ON messages
FOR EACH ROW EXECUTE FUNCTION broadcast_message_changes();
```
**Using `realtime.send` (Best for custom notifications and filtered data)**
```sql
-- Create a trigger function for custom notifications
CREATE OR REPLACE FUNCTION notify_message_activity()
RETURNS TRIGGER AS $$
BEGIN
-- Send custom notification when new message is created
IF TG_OP = 'INSERT' THEN
PERFORM realtime.send(
jsonb_build_object(
'message_id', NEW.id,
'user_id', NEW.user_id,
'room_id', NEW.room_id,
'created_at', NEW.created_at
),
'message_created',
'room:' || NEW.room_id::text || ':notifications',
true -- private channel
);
END IF;
RETURN NULL;
END;
$$ LANGUAGE plpgsql SECURITY DEFINER;
-- Apply trigger to your messages table
CREATE TRIGGER messages_notification_trigger
AFTER INSERT ON messages
FOR EACH ROW EXECUTE FUNCTION notify_message_activity();
```
* **`realtime.broadcast_changes`** sends the full database change with metadata
* **`realtime.send`** allows you to send custom payloads and control exactly what data is broadcast
## Essential best practices
### Use private channels
Always use private channels for production applications to ensure proper security and authorization:
```ts
const channel = supabase.channel('room:123:messages', {
config: { private: true },
})
```
### Follow naming conventions
**Channel Topics:** Use the pattern `scope:id:entity`
* `room:123:messages` - Messages in room 123
* `game:456:moves` - Game moves for game 456
* `user:789:notifications` - Notifications for user 789
### Clean up subscriptions
Always unsubscribe when you are done with a channel to ensure you free up resources:
```ts
// React example
import { useEffect } from 'react'
useEffect(() => {
const channel = supabase.channel('room:123:messages')
return () => {
supabase.removeChannel(channel)
}
}, [])
```
```dart
// Flutter example
class _MyWidgetState extends State {
RealtimeChannel? _channel;
@override
void initState() {
super.initState();
_channel = supabase.channel('room:123:messages');
}
@override
void dispose() {
_channel?.unsubscribe();
super.dispose();
}
}
```
```swift
// SwiftUI example
struct ContentView: View {
@State private var channel: RealtimeChannelV2?
var body: some View {
// Your UI here
.onAppear {
channel = supabase.realtimeV2.channel("room:123:messages")
}
.onDisappear {
Task {
await channel?.unsubscribe()
}
}
}
}
```
```python
# Python example with context manager
class RealtimeManager:
def __init__(self):
self.channel = None
def __enter__(self):
self.channel = supabase.channel('room:123:messages')
return self.channel
def __exit__(self, exc_type, exc_val, exc_tb):
if self.channel:
self.channel.unsubscribe()
# Usage
with RealtimeManager() as channel:
# Use channel here
pass
```
## Choose the right feature
### When to use Broadcast
* Real-time messaging and notifications
* Custom events and game state
* Database change notifications (with triggers)
* High-frequency updates (e.g. Cursor tracking)
* Most use cases
### When to use Presence
* User online/offline status
* Active user counters
* Use minimally due to computational overhead
### When to use Postgres Changes
* Quick testing and development
* Low amount of connected users
## Next steps
Now that you understand the basics, dive deeper into each feature:
### Core features
* **[Broadcast](/docs/guides/realtime/broadcast)** - Learn about sending messages, database triggers, and REST API usage
* **[Presence](/docs/guides/realtime/presence)** - Implement user state tracking and online indicators
* **[Postgres Changes](/docs/guides/realtime/postgres-changes)** - Understanding database change listeners (consider migrating to Broadcast)
### Security & configuration
* **[Authorization](/docs/guides/realtime/authorization)** - Set up RLS policies for private channels
* **[Settings](/docs/guides/realtime/settings)** - Configure your Realtime instance for optimal performance
### Advanced topics
* **[Architecture](/docs/guides/realtime/architecture)** - Understand how Realtime works under the hood
* **[Benchmarks](/docs/guides/realtime/benchmarks)** - Performance characteristics and scaling considerations
* **[Limits](/docs/guides/realtime/limits)** - Usage limits and best practices
### Integration guides
* **[Realtime with Next.js](/docs/guides/realtime/realtime-with-nextjs)** - Build real-time Next.js applications
* **[User Presence](/docs/guides/realtime/realtime-user-presence)** - Implement user presence features
* **[Database Changes](/docs/guides/realtime/subscribing-to-database-changes)** - Listen to database changes
### Framework examples
* **[Flutter Integration](/docs/guides/realtime/realtime-listening-flutter)** - Build real-time Flutter applications
Ready to build something amazing? Start with the [Broadcast guide](/docs/guides/realtime/broadcast) to create your first real-time feature!
# Realtime Limits
Our cluster supports millions of concurrent connections and message throughput for production workloads.
Upgrade your plan to increase your limits. Without a spend cap, or on an Enterprise plan, some limits are still in place to protect budgets. All limits are configurable per project. [Contact support](/dashboard/support/new) if you need your limits increased.
## Limits by plan
| | Free | Pro | Pro (no spend cap) | Team | Enterprise |
| ----------------------------------------------------------------------------------- | -------- | -------- | ------------------ | -------- | ---------- |
| **Concurrent connections** | 200 | 500 | 10,000 | 10,000 | 10,000+ |
| **Messages per second** | 100 | 500 | 2,500 | 2,500 | 2,500+ |
| **Channel joins per second** | 100 | 500 | 2,500 | 2,500 | 2,500+ |
| **Channels per connection** | 100 | 100 | 100 | 100 | 100+ |
| **Presence keys per object** | 10 | 10 | 10 | 10 | 10+ |
| **Presence messages per second** | 20 | 50 | 1,000 | 1,000 | 1,000+ |
| **Broadcast payload size** | 256 KB | 3,000 KB | 3,000 KB | 3,000 KB | 3,000+ KB |
| **Postgres change payload size ([**read more**](#postgres-changes-payload-limit))** | 1,024 KB | 1,024 KB | 1,024 KB | 1,024 KB | 1,024+ KB |
Beyond the Free and Pro Plan you can customize your limits by [contacting support](/dashboard/support/new).
## Limit errors
When you exceed a limit, errors will appear in the backend logs and client-side messages in the WebSocket connection.
* **Logs**: check the [Realtime logs](/dashboard/project/_/database/realtime-logs) inside your project Dashboard.
* **WebSocket errors**: Use your browser's developer tools to find the WebSocket initiation request and view individual messages.
You can use the [Realtime Inspector](https://realtime.supabase.com/inspector/new) to reproduce an error and share those connection details with Supabase support.
Some limits can cause a Channel join to be refused. Realtime will reply with one of the following WebSocket messages:
### `too_many_channels`
Too many channels currently joined for a single connection.
### `too_many_connections`
Too many total concurrent connections for a project.
### `too_many_joins`
Too many Channel joins per second.
### `tenant_events`
Connections will be disconnected if your project is generating too many messages per second. `supabase-js` will reconnect automatically when the message throughput decreases below your plan limit. An `event` is a WebSocket message delivered to, or sent from a client.
## Postgres changes payload limit
When this limit is reached, the `new` and `old` record payloads only include the fields with a value size of less than or equal to 64 bytes.
# Postgres Changes
Listen to Postgres changes using Supabase Realtime.
Let's explore how to use Realtime's Postgres Changes feature to listen to database events.
## Quick start
In this example we'll set up a database table, secure it with Row Level Security, and subscribe to all changes using the Supabase client libraries.
[Create a new project](https://app.supabase.com) in the Supabase Dashboard.
After your project is ready, create a table in your Supabase database. You can do this with either the Table interface or the [SQL Editor](https://app.supabase.com/project/_/sql).
```sql
-- Create a table called "todos"
-- with a column to store tasks.
create table todos (
id serial primary key,
task text
);
```
In this example we'll turn on [Row Level Security](/docs/guides/database/postgres/row-level-security) for this table and allow anonymous access. In production, be sure to secure your application with the appropriate permissions.
```sql
-- Grant the privileges roles need
GRANT SELECT ON public.todos TO anon;
-- Turn on security
alter table "todos"
enable row level security;
-- Allow anonymous access
create policy "Allow anonymous access"
on todos
for select
to anon
using (true);
```
Go to your project's [Publications settings](/dashboard/project/_/database/publications), and under `supabase_realtime`, toggle on the tables you want to listen to.
Alternatively, add tables to the `supabase_realtime` publication by running the given SQL:
```sql
alter publication supabase_realtime
add table your_table_name;
```
Install the Supabase JavaScript client.
```bash
npm install @supabase/supabase-js
```
This client will be used to listen to Postgres changes.
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient(
'https://.supabase.co',
''
)
```
Listen to changes on all tables in the `public` schema by setting the `schema` property to 'public' and event name to `*`. The event name can be one of:
* `INSERT`
* `UPDATE`
* `DELETE`
* `*`
The channel name can be any string except 'realtime'.
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const channelA = supabase
.channel('schema-db-changes')
.on(
'postgres_changes',
{
event: '*',
schema: 'public',
},
(payload) => console.log(payload)
)
.subscribe()
```
Now we can add some data to our table which will trigger the `channelA` event handler.
```sql
insert into todos (task)
values
('Change!');
```
## Usage
You can use the Supabase client libraries to subscribe to database changes.
### Listening to specific schemas
Subscribe to specific schema events using the `schema` parameter:
{/* prettier-ignore */}
```js
const changes = supabase
.channel('schema-db-changes')
.on(
'postgres_changes',
{
schema: 'public', // Subscribes to the "public" schema in Postgres
event: '*', // Listen to all changes
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('schema-db-changes')
.onPostgresChanges(
schema: 'public', // Subscribes to the "public" schema in Postgres
event: PostgresChangeEvent.all, // Listen to all changes
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("schema-db-changes")
let changes = await myChannel.postgresChange(AnyAction.self, schema: "public")
await myChannel.subscribe()
for await change in changes {
switch change {
case .insert(let action): print(action)
case .update(let action): print(action)
case .delete(let action): print(action)
case .select(let action): print(action)
}
}
```
```kotlin
val myChannel = supabase.channel("schema-db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public")
changes
.onEach {
when(it) { //You can also check for , etc.. manually
is HasRecord -> println(it.record)
is HasOldRecord -> println(it.oldRecord)
else -> println(it)
}
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('schema-db-changes').on_postgres_changes(
"*",
schema="public",
callback=lambda payload: print(payload)
)
.subscribe()
```
The channel name can be any string except 'realtime'.
### Listening to `INSERT` events
Use the `event` parameter to listen only to database `INSERT`s:
```js
const changes = supabase
.channel('schema-db-changes')
.on(
'postgres_changes',
{
event: 'INSERT', // Listen only to INSERTs
schema: 'public',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
final changes = supabase
.channel('schema-db-changes')
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
callback: (payload) => print(payload))
.subscribe();
```
Use `InsertAction.self` as type to listen only to database `INSERT`s:
```swift
let myChannel = await supabase.channel("schema-db-changes")
let changes = await myChannel.postgresChange(InsertAction.self, schema: "public")
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
Use `PostgresAction.Insert` as type to listen only to database `INSERT`s:
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public")
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('schema-db-changes').on_postgres_changes(
"INSERT", # Listen only to INSERTs
schema="public",
callback=lambda payload: print(payload)
)
.subscribe()
```
The channel name can be any string except 'realtime'.
### Listening to `UPDATE` events
Use the `event` parameter to listen only to database `UPDATE`s:
```js
const changes = supabase
.channel('schema-db-changes')
.on(
'postgres_changes',
{
event: 'UPDATE', // Listen only to UPDATEs
schema: 'public',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('schema-db-changes')
.onPostgresChanges(
event: PostgresChangeEvent.update, // Listen only to UPDATEs
schema: 'public',
callback: (payload) => print(payload))
.subscribe();
```
Use `UpdateAction.self` as type to listen only to database `UPDATE`s:
```swift
let myChannel = await supabase.channel("schema-db-changes")
let changes = await myChannel.postgresChange(UpdateAction.self, schema: "public")
await myChannel.subscribe()
for await change in changes {
print(change.oldRecord, change.record)
}
```
Use `PostgresAction.Update` as type to listen only to database `UPDATE`s:
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public")
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('schema-db-changes').on_postgres_changes(
"UPDATE", # Listen only to UPDATEs
schema="public",
callback=lambda payload: print(payload)
)
.subscribe()
```
The channel name can be any string except 'realtime'.
### Listening to `DELETE` events
Use the `event` parameter to listen only to database `DELETE`s:
```js
const changes = supabase
.channel('schema-db-changes')
.on(
'postgres_changes',
{
event: 'DELETE', // Listen only to DELETEs
schema: 'public',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('schema-db-changes')
.onPostgresChanges(
event: PostgresChangeEvent.delete, // Listen only to DELETEs
schema: 'public',
callback: (payload) => print(payload))
.subscribe();
```
Use `DeleteAction.self` as type to listen only to database `DELETE`s:
```swift
let myChannel = await supabase.channel("schema-db-changes")
let changes = await myChannel.postgresChange(DeleteAction.self, schema: "public")
await myChannel.subscribe()
for await change in changes {
print(change.oldRecord)
}
```
Use `PostgresAction.Delete` as type to listen only to database `DELETE`s:
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public")
changes
.onEach {
println(it.oldRecord)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('schema-db-changes').on_postgres_changes(
"DELETE", # Listen only to DELETEs
schema="public",
callback=lambda payload: print(payload)
)
.subscribe()
```
The channel name can be any string except 'realtime'.
### Listening to specific tables
Subscribe to specific table events using the `table` parameter:
```js
const changes = supabase
.channel('table-db-changes')
.on(
'postgres_changes',
{
event: '*',
schema: 'public',
table: 'todos',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('table-db-changes')
.onPostgresChanges(
event: PostgresChangeEvent.all,
schema: 'public',
table: 'todos',
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(AnyAction.self, schema: "public", table: "todos")
await myChannel.subscribe()
for await change in changes {
switch change {
case .insert(let action): print(action)
case .update(let action): print(action)
case .delete(let action): print(action)
case .select(let action): print(action)
}
}
```
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "todos"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"UPDATE",
schema="public",
table="todos",
callback=lambda payload: print(payload)
)
.subscribe()
```
The channel name can be any string except 'realtime'.
### Listening to multiple changes
To listen to different events and schema/tables/filters combinations with the same channel:
```js
const channel = supabase
.channel('db-changes')
.on(
'postgres_changes',
{
event: '*',
schema: 'public',
table: 'messages',
},
(payload) => console.log(payload)
)
.on(
'postgres_changes',
{
event: 'INSERT',
schema: 'public',
table: 'users',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('db-changes')
.onPostgresChanges(
event: PostgresChangeEvent.all,
schema: 'public',
table: 'messages',
callback: (payload) => print(payload))
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
table: 'users',
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let messageChanges = await myChannel.postgresChange(AnyAction.self, schema: "public", table: "messages")
let userChanges = await myChannel.postgresChange(InsertAction.self, schema: "public", table: "users")
await myChannel.subscribe()
```
```kotlin
val myChannel = supabase.channel("db-changes")
val messageChanges = myChannel.postgresChangeFlow(schema = "public") {
table = "messages"
}
val userChanges = myChannel.postgresChangeFlow(schema = "public") {
table = "users"
}
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"*",
schema="public",
table="messages"
callback=lambda payload: print(payload)
).on_postgres_changes(
"INSERT",
schema="public",
table="users",
callback=lambda payload: print(payload)
).subscribe()
```
### Filtering for specific changes
Use the `filter` parameter for granular changes:
```js
const changes = supabase
.channel('table-filter-changes')
.on(
'postgres_changes',
{
event: 'INSERT',
schema: 'public',
table: 'todos',
filter: 'id=eq.1',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('table-filter-changes')
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
table: 'todos',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.eq,
column: 'id',
value: 1,
),
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
InsertAction.self,
schema: "public",
table: "todos",
filter: .eq("id", value: 1)
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "todos"
filter = "id=eq.1"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"INSERT",
schema="public",
table="todos",
filter="id=eq.1",
callback=lambda payload: print(payload)
)
.subscribe()
```
## Available filters
Realtime offers filters so you can specify the data your client receives at a more granular level.
### Equal to (`eq`)
To listen to changes when a column's value in a table equals a client-specified value:
```js
const channel = supabase
.channel('changes')
.on(
'postgres_changes',
{
event: 'UPDATE',
schema: 'public',
table: 'messages',
filter: 'body=eq.hey',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('changes')
.onPostgresChanges(
event: PostgresChangeEvent.update,
schema: 'public',
table: 'messages',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.eq,
column: 'body',
value: 'hey',
),
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
UpdateAction.self,
schema: "public",
table: "messages",
filter: .eq("body", value: "hey")
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "messages"
filter = "body=eq.hey"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"UPDATE",
schema="public",
table="messages",
filter="body=eq.hey",
callback=lambda payload: print(payload)
)
.subscribe()
```
This filter uses Postgres's `=` filter.
### Not equal to (`neq`)
To listen to changes when a column's value in a table does not equal a client-specified value:
```js
const channel = supabase
.channel('changes')
.on(
'postgres_changes',
{
event: 'INSERT',
schema: 'public',
table: 'messages',
filter: 'body=neq.bye',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('changes')
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
table: 'messages',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.neq,
column: 'body',
value: 'bye',
),
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
UpdateAction.self,
schema: "public",
table: "messages",
filter: .neq("body", value: "hey")
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val myChannel = supabase.realtime.createChannel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "messages"
filter = "body=neq.bye"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
supabase.realtime.connect()
myChannel.join()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"INSERT",
schema="public",
table="messages",
filter="body=neq.bye",
callback=lambda payload: print(payload)
)
.subscribe()
```
This filter uses Postgres's `!=` filter.
### Less than (`lt`)
To listen to changes when a column's value in a table is less than a client-specified value:
```js
const channel = supabase
.channel('changes')
.on(
'postgres_changes',
{
event: 'INSERT',
schema: 'public',
table: 'profiles',
filter: 'age=lt.65',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('changes')
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
table: 'profiles',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.lt,
column: 'age',
value: 65,
),
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
InsertAction.self,
schema: "public",
table: "profiles",
filter: .lt("age", value: 65)
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "profiles"
filter = "age=lt.65"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"INSERT",
schema="public",
table="profiles",
filter="age=lt.65",
callback=lambda payload: print(payload)
)
.subscribe()
```
This filter uses Postgres's `<` filter, so it works for non-numeric types. Make sure to check the expected behavior of the compared data's type.
### Less than or equal to (`lte`)
To listen to changes when a column's value in a table is less than or equal to a client-specified value:
```js
const channel = supabase
.channel('changes')
.on(
'postgres_changes',
{
event: 'UPDATE',
schema: 'public',
table: 'profiles',
filter: 'age=lte.65',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('changes')
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
table: 'profiles',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.lte,
column: 'age',
value: 65,
),
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
InsertAction.self,
schema: "public",
table: "profiles",
filter: .lte("age", value: 65)
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "profiles"
filter = "age=lte.65"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"UPDATE",
schema="public",
table="profiles",
filter="age=lte.65",
callback=lambda payload: print(payload)
)
.subscribe()
```
This filter uses Postgres' `<=` filter, so it works for non-numeric types. Make sure to check the expected behavior of the compared data's type.
### Greater than (`gt`)
To listen to changes when a column's value in a table is greater than a client-specified value:
```js
const channel = supabase
.channel('changes')
.on(
'postgres_changes',
{
event: 'INSERT',
schema: 'public',
table: 'products',
filter: 'quantity=gt.10',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('changes')
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
table: 'products',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.gt,
column: 'quantity',
value: 10,
),
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
InsertAction.self,
schema: "public",
table: "products",
filter: .gt("quantity", value: 10)
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "products"
filter = "quantity=gt.10"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"UPDATE",
schema="public",
table="products",
filter="quantity=gt.10",
callback=lambda payload: print(payload)
)
.subscribe()
```
This filter uses Postgres's `>` filter, so it works for non-numeric types. Make sure to check the expected behavior of the compared data's type.
### Greater than or equal to (`gte`)
To listen to changes when a column's value in a table is greater than or equal to a client-specified value:
```js
const channel = supabase
.channel('changes')
.on(
'postgres_changes',
{
event: 'INSERT',
schema: 'public',
table: 'products',
filter: 'quantity=gte.10',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('changes')
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
table: 'products',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.gte,
column: 'quantity',
value: 10,
),
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
InsertAction.self,
schema: "public",
table: "products",
filter: .gte("quantity", value: 10)
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "products"
filter = "quantity=gte.10"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"UPDATE",
schema="public",
table="products",
filter="quantity=gte.10",
callback=lambda payload: print(payload)
)
.subscribe()
```
This filter uses Postgres's `>=` filter, so it works for non-numeric types. Make sure to check the expected behavior of the compared data's type.
### Contained in list (in)
To listen to changes when a column's value in a table equals any client-specified values:
```js
const channel = supabase
.channel('changes')
.on(
'postgres_changes',
{
event: 'INSERT',
schema: 'public',
table: 'colors',
filter: 'name=in.(red, blue, yellow)',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase
.channel('changes')
.onPostgresChanges(
event: PostgresChangeEvent.insert,
schema: 'public',
table: 'colors',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.inFilter,
column: 'name',
value: ['red', 'blue', 'yellow'],
),
callback: (payload) => print(payload))
.subscribe();
```
```swift
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
InsertAction.self,
schema: "public",
table: "products",
filter: .in("name", values: ["red", "blue", "yellow"])
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "products"
filter = "name=in.(red, blue, yellow)"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
changes = supabase.channel('db-changes').on_postgres_changes(
"UPDATE",
schema="public",
table="products",
filter="name=in.(red, blue, yellow)",
callback=lambda payload: print(payload)
)
.subscribe()
```
This filter uses Postgres's `= ANY`. Realtime allows a maximum of 100 values for this filter.
## Receiving `old` records
By default, only `new` record changes are sent but if you want to receive the `old` record (previous values) whenever you `UPDATE` or `DELETE` a record, you can set the `replica identity` of your table to `full`:
```sql
alter table
messages replica identity full;
```
RLS policies are not applied to `DELETE` statements, because there is no way for Postgres to verify that a user has access to a deleted record. When RLS is enabled and `replica identity` is set to `full` on a table, the `old` record contains only the primary key(s).
## Private schemas
Postgres Changes works out of the box for tables in the `public` schema. You can listen to tables in your private schemas by granting table `SELECT` permissions to the database role found in your access token. You can run a query similar to the following:
```sql
grant select on "non_private_schema"."some_table" to authenticated;
```
We strongly encourage you to enable RLS and create policies for tables in private schemas. Otherwise, any role you grant access to will have unfettered read access to the table.
## Custom tokens
You may choose to sign your own tokens to customize claims that can be checked in your RLS policies.
Your project JWT secret is found in the [**Settings > API keys**](/dashboard/project/_/settings/api-keys) section of the Dashboard.
Do not expose the `service_role` token on the client because the role is authorized to bypass row-level security.
To use your own JWT with Realtime make sure to set the token after instantiating the Supabase client and before connecting to a Channel.
```js
const { createClient } = require('@supabase/supabase-js')
const supabase = createClient(process.env.SUPABASE_URL, process.env.SUPABASE_KEY, {})
// Set your custom JWT here
supabase.realtime.setAuth('your-custom-jwt')
const channel = supabase
.channel('db-changes')
.on(
'postgres_changes',
{
event: '*',
schema: 'public',
table: 'messages',
filter: 'body=eq.bye',
},
(payload) => console.log(payload)
)
.subscribe()
```
```dart
supabase.realtime.setAuth('your-custom-jwt');
supabase
.channel('db-changes')
.onPostgresChanges(
event: PostgresChangeEvent.all,
schema: 'public',
table: 'messages',
filter: PostgresChangeFilter(
type: PostgresChangeFilterType.eq,
column: 'body',
value: 'bye',
),
callback: (payload) => print(payload),
)
.subscribe();
```
```swift
await supabase.realtime.setAuth("your-custom-jwt")
let myChannel = await supabase.channel("db-changes")
let changes = await myChannel.postgresChange(
UpdateAction.self,
schema: "public",
table: "products",
filter: "name=in.(red, blue, yellow)"
)
await myChannel.subscribe()
for await change in changes {
print(change.record)
}
```
```kotlin
val supabase = createSupabaseClient(supabaseUrl, supabaseKey) {
install(Realtime) {
jwtToken = "your-custom-jwt"
}
}
val myChannel = supabase.channel("db-changes")
val changes = myChannel.postgresChangeFlow(schema = "public") {
table = "products"
filter = "name=in.(red, blue, yellow)"
}
changes
.onEach {
println(it.record)
}
.launchIn(yourCoroutineScope)
myChannel.subscribe()
```
```python
supabase.realtime.set_auth('your-custom-jwt')
changes = supabase.channel('db-changes').on_postgres_changes(
"UPDATE",
schema="public",
table="products",
filter="name=in.(red, blue, yellow)",
callback=lambda payload: print(payload)
)
.subscribe()
```
### Refreshed tokens
You will need to refresh tokens on your own, but once generated, you can pass them to Realtime.
For example, if you're using the `supabase-js` `v2` client then you can pass your token like this:
```js
// Client setup
supabase.realtime.setAuth('fresh-token')
```
```dart
supabase.realtime.setAuth('fresh-token');
```
```swift
await supabase.realtime.setAuth("fresh-token")
```
In Kotlin, you have to update the token manually per channel:
```kotlin
myChannel.updateAuth("fresh-token")
```
```python
supabase.realtime.set_auth('fresh-token')
```
## Limitations
### Delete events are not filterable
You can't filter Delete events when tracking Postgres Changes. This limitation is due to the way changes are pulled from Postgres.
### Spaces in table names
Realtime currently does not work when table names contain spaces.
### Database instance and realtime performance
Realtime systems usually require forethought because of their scaling dynamics. For the `Postgres Changes` feature, every change event must be checked to see if the subscribed user has access. For instance, if you have 100 users subscribed to a table where you make a single insert, it will then trigger 100 "reads": one for each user.
There can be a database bottleneck which limits message throughput. If your database cannot authorize the changes rapidly enough, the changes will be delayed until you receive a timeout.
Database changes are processed on a single thread to maintain the change order. That means compute upgrades don't have a large effect on the performance of Postgres change subscriptions. You can estimate the expected maximum throughput for your database below.
If you are using Postgres Changes at scale, you should consider using separate "public" table without RLS and filters. Alternatively, you can use Realtime server-side only and then re-stream the changes to your clients using a Realtime Broadcast.
Enter your database settings to estimate the maximum throughput for your instance:
Don't forget to run your own benchmarks to make sure that the performance is acceptable for your use case.
We are making many improvements to Realtime's Postgres Changes. If you are uncertain about the performance of your use case, reach out using [Support Form](/dashboard/support/new) and we will be happy to help you. We have a team of engineers that can advise you on the best solution for your use-case.
# Presence
Share state between users with Realtime Presence.
Let's explore how to implement Realtime Presence to track state between multiple users.
## Usage
You can use the Supabase client libraries to track Presence state between users.
### How Presence works
Presence lets each connected client publish a small piece of state—called a “presence payload”—to a shared channel. Supabase stores each client’s payload under a unique presence key and keeps a merged view of all connected clients.
When any client subscribes, disconnects, or updates their presence payload, Supabase triggers one of three events:
* **`sync`** — the full presence state has been updated
* **`join`** — a new client has started tracking presence
* **`leave`** — a client has stopped tracking presence
During a `sync` event, you may receive `join` and `leave` events simultaneously, even though no users are actually joining or leaving. This is expected behavior—Presence reconciles its local state with the server state, which can trigger these events as part of the synchronization process. This reflects state reconciliation, not real user movement.
The complete presence state returned by `presenceState()` looks like this:
```json
{
"client_key_1": [{ "userId": 1, "typing": false }],
"client_key_2": [{ "userId": 2, "typing": true }]
}
```
### Initialize the client
Get the Project URL and key from [the project's **Connect** dialog](/dashboard/project/_?showConnect=true).
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement](https://github.com/orgs/supabase/discussions/29260), but in the transition period, you can use both the current `anon` and `service_role` keys and the new publishable key with the form `sb_publishable_xxx` which will replace the older keys.
**The legacy keys will be deprecated shortly, so we strongly encourage switching to and using the new publishable and secret API keys**.
In most cases, you can get the correct key from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true), but if you want a specific key, you can find all keys in [the API Keys section of a Project's Settings page](/dashboard/project/_/settings/api-keys/):
**For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
```js
import { createClient } from '@supabase/supabase-js'
const SUPABASE_URL = 'https://.supabase.co'
const SUPABASE_KEY = ''
const supabase = createClient(SUPABASE_URL, SUPABASE_KEY)
```
```dart
void main() {
Supabase.initialize(
url: 'https://.supabase.co',
publishableKey: '',
);
runApp(MyApp());
}
final supabase = Supabase.instance.client;
```
```swift
let supabaseURL = "https://.supabase.co"
let supabaseKey = ""
let supabase = SupabaseClient(supabaseURL: URL(string: supabaseURL)!, supabaseKey: supabaseKey)
let realtime = supabase.realtime
```
```kotlin
val supabaseUrl = "https://.supabase.co"
val supabaseKey = ""
val supabase = createSupabaseClient(supabaseUrl, supabaseKey) {
install(Realtime)
}
```
```python
from supabase import create_client
SUPABASE_URL = 'https://.supabase.co'
SUPABASE_KEY = ''
supabase = create_client(SUPABASE_URL, SUPABASE_KEY)
```
### Sync and track state
Listen to the `sync`, `join`, and `leave` events triggered whenever any client joins or leaves the channel or changes their slice of state:
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const roomOne = supabase.channel('room_01')
roomOne
.on('presence', { event: 'sync' }, () => {
const newState = roomOne.presenceState()
console.log('sync', newState)
})
.on('presence', { event: 'join' }, ({ key, newPresences }) => {
console.log('join', key, newPresences)
})
.on('presence', { event: 'leave' }, ({ key, leftPresences }) => {
console.log('leave', key, leftPresences)
})
.subscribe()
```
```dart
final supabase = Supabase.instance.client;
final roomOne = supabase.channel('room_01');
roomOne.onPresenceSync((_) {
final newState = roomOne.presenceState();
print('sync: $newState');
}).onPresenceJoin((payload) {
print('join: $payload');
}).onPresenceLeave((payload) {
print('leave: $payload');
}).subscribe();
```
Listen to the presence change stream, emitting a new `PresenceAction` whenever someone joins or leaves:
```swift
let roomOne = await supabase.channel("room_01")
let presenceStream = await roomOne.presenceChange()
await roomOne.subscribe()
for await presence in presenceStream {
print(presence.join) // You can also use presence.decodeJoins(as: MyType.self)
print(presence.leaves) // You can also use presence.decodeLeaves(as: MyType.self)
}
```
Listen to the presence change flow, emitting new a new `PresenceAction` whenever someone joins or leaves:
```kotlin
val roomOne = supabase.channel("room_01")
val presenceFlow: Flow = roomOne.presenceChangeFlow()
presenceFlow
.onEach {
println(it.joins) //You can also use it.decodeJoinsAs()
println(it.leaves) //You can also use it.decodeLeavesAs()
}
.launchIn(yourCoroutineScope) //You can also use .collect { } here
roomOne.subscribe()
```
Listen to the `sync`, `join`, and `leave` events triggered whenever any client joins or leaves the channel or changes their slice of state:
```python
room_one = supabase.channel('room_01')
room_one
.on_presence_sync(lambda: print('sync', room_one.presenceState()))
.on_presence_join(lambda key, curr_presences, joined_presences: print('join', key, curr_presences, joined_presences))
.on_presence_leave(lambda key, curr_presences, left_presences: print('leave', key, curr_presences, left_presences))
.subscribe()
```
### Sending state
You can send state to all subscribers using `track()`:
{/* prettier-ignore */}
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const roomOne = supabase.channel('room_01')
const userStatus = {
user: 'user-1',
online_at: new Date().toISOString(),
}
roomOne.subscribe(async (status) => {
if (status !== 'SUBSCRIBED') { return }
const presenceTrackStatus = await roomOne.track(userStatus)
console.log(presenceTrackStatus)
})
```
```dart
final roomOne = supabase.channel('room_01');
final userStatus = {
'user': 'user-1',
'online_at': DateTime.now().toIso8601String(),
};
roomOne.subscribe((status, error) async {
if (status != RealtimeSubscribeStatus.subscribed) return;
final presenceTrackStatus = await roomOne.track(userStatus);
print(presenceTrackStatus);
});
```
```swift
let roomOne = await supabase.channel("room_01")
// Using a custom type
let userStatus = UserStatus(
user: "user-1",
onlineAt: Date().timeIntervalSince1970
)
await roomOne.subscribe()
try await roomOne.track(userStatus)
// Or using a raw JSONObject.
await roomOne.track(
[
"user": .string("user-1"),
"onlineAt": .double(Date().timeIntervalSince1970)
]
)
```
```kotlin
val roomOne = supabase.channel("room_01")
val userStatus = UserStatus( //Your custom class
user = "user-1",
onlineAt = Clock.System.now().toEpochMilliseconds()
)
roomOne.subscribe(blockUntilSubscribed = true) //You can also use the roomOne.status flow instead, but this parameter will block the coroutine until the status is joined.
roomOne.track(userStatus)
```
```python
room_one = supabase.channel('room_01')
user_status = {
"user": 'user-1',
"online_at": datetime.datetime.now().isoformat(),
}
def on_subscribe(status, err):
if status != RealtimeSubscribeStates.SUBSCRIBED:
return
room_one.track(user_status)
room_one.subscribe(on_subscribe)
```
A client will receive state from any other client that is subscribed to the same topic (in this case `room_01`). It will also automatically trigger its own `sync` and `join` event handlers.
### Stop tracking
You can stop tracking presence using the `untrack()` method. This will trigger the `sync` and `leave` event handlers.
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
const roomOne = supabase.channel('room_01')
// ---cut---
const untrackPresence = async () => {
const presenceUntrackStatus = await roomOne.untrack()
console.log(presenceUntrackStatus)
}
untrackPresence()
```
```dart
final roomOne = supabase.channel('room_01');
untrackPresence() async {
final presenceUntrackStatus = await roomOne.untrack();
print(presenceUntrackStatus);
}
untrackPresence();
```
```swift
await roomOne.untrack()
```
```kotlin
suspend fun untrackPresence() {
roomOne.untrack()
}
untrackPresence()
```
```python
room_one.untrack()
```
## Presence options
You can pass configuration options while initializing the Supabase Client.
### Presence key
By default, Presence will generate a unique `UUIDv1` key on the server to track a client channel's state. If you prefer, you can provide a custom key when creating the channel. This key should be unique among clients.
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('SUPABASE_URL', 'SUPABASE_PUBLISHABLE_KEY')
const channelC = supabase.channel('test', {
config: {
presence: {
key: 'userId-123',
},
},
})
```
```dart
final channelC = supabase.channel(
'test',
opts: const RealtimeChannelConfig(key: 'userId-123'),
);
```
```swift
let channelC = await supabase.channel("test") {
$0.presence.key = "userId-123"
}
```
```kotlin
val channelC = supabase.channel("test") {
presence {
key = "userId-123"
}
}
```
```python
channel_c = supabase.channel('test', {
"config": {
"presence": {
"key": 'userId-123',
},
},
})
```
# Realtime Pricing
You are charged for the number of Realtime messages and the number of Realtime peak connections.
## Messages
per 1 million messages. You are only charged for usage exceeding your
subscription plan's quota.
| Plan | Quota | Over-Usage |
| ---------- | --------- | --------------------------------------------- |
| Free | 2 million | - |
| Pro | 5 million | per 1 million messages |
| Team | 5 million | per 1 million messages |
| Enterprise | Custom | Custom |
For a detailed explanation of how charges are calculated, refer to [Manage Realtime Messages usage](/docs/guides/platform/manage-your-usage/realtime-messages).
## Peak connections
per 1,000 peak connections. You are only charged for usage exceeding your
subscription plan's quota.
| Plan | Quota | Over-Usage |
| ---------- | ------ | ----------------------------------------------- |
| Free | 200 | - |
| Pro | 500 | per 1,000 peak connections |
| Team | 500 | per 1,000 peak connections |
| Enterprise | Custom | Custom |
For a detailed explanation of how charges are calculated, refer to [Manage Realtime Peak Connections usage](/docs/guides/platform/manage-your-usage/realtime-peak-connections).
# Realtime Protocol
## WebSocket connection setup
To start the connection we use the WebSocket URL, which for:
* Supabase projects: `wss://.supabase.co/realtime/v1/websocket?apikey=`
* self-hosted projects: `wss://:/socket/websocket?apikey=`
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
As an example, using [websocat](https://github.com/vi/websocat), you would run the following command in your terminal:
```bash
# With Supabase
websocat "wss://.supabase.co/realtime/v1/websocket?apikey="
# With self-hosted
websocat "wss://:/socket/websocket?apikey="
```
During this stage you can also set other URL params:
* `vsn`: sets the protocol version. Possible values are `1.0.0` and `2.0.0`. Defaults to `1.0.0`.
* `log_level`: sets the log level to be used by this connection to help you debug potential issues. This only affects server side logs.
After connecting a `phx_join` event must be sent to the server to join a channel. The next sections outline the different messages types and events that are supported.
## Protocol messages
Messages can be serialized in different formats. The Realtime protocol supports two versions: `1.0.0` and `2.0.0`.
## 1.0.0
Version 1.0.0 is extremely simple. It uses JSON as the serialization format for messages. The underlying WebSocket messages are all text frames.
Messages contain the following fields:
* `event`: The type of event being sent or received. Example `phx_join`, `postgres_changes`, `broadcast`, etc.
* `topic`: The topic to which the message belongs. This is a string that identifies the channel or context of the message.
* `payload`: The data associated with the event. This can be any JSON-serializable data structure, such as an object or an array.
* `ref`: A unique reference ID for the message. This is useful to track replies to a specific message.
* `join_ref`: A unique reference ID to uniquely identify a joined topic for pushes, broadcasts, replies, etc.
Example:
```json
{
"topic": "realtime:presence-room",
"event": "phx_join",
"payload": {
"config": {
"broadcast": {
"ack": false,
"self": false
},
"presence": {
"enabled": false
},
"private": false
}
},
"ref": "1",
"join_ref": "1"
}
```
## 2.0.0
Version 2.0.0 uses text and binary WebSocket frames.
### Text frames
Text frames are always JSON encoded, but unlike version 1.0.0, they use a JSON array where the element order must be exactly:
* `join_ref`
* `ref`
* `topic`
* `event`
* `payload`
Example:
```json
[
"1",
"1",
"realtime:presence-room",
"phx_join",
{
"config": {
"broadcast": {
"ack": false,
"self": false
},
"presence": {
"enabled": false
},
"private": false
}
}
]
```
### Binary frames
The two special message types have a well defined binary format where the first byte defines the type of message. Both are used to send and receive broadcast events. See the [client](#client-sent-events) and [server](#server-sent-events) sent events for more details.
| Code | Type | Description |
| ---- | --------------------- | ----------------------------- |
| 3 | USER\_BROADCAST\_PUSH | User-initiated broadcast push |
| 4 | USER\_BROADCAST | User broadcast message |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### User Broadcast Push
```
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type (0x03) | Join Ref Size | Ref Size | Topic Size |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|User Event Size| Metadata Size | Payload Enc. | Join Ref ... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Ref (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Topic (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User Event (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Metadata (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User Payload (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
```
**Field Descriptions:**
* **Type**: 1 byte, value = 0x03
* **Join Ref Size**: 1 byte, size of join reference string (max 255)
* **Ref Size**: 1 byte, size of reference string (max 255)
* **Topic Size**: 1 byte, size of topic string (max 255)
* **User Event Size**: 1 byte, size of user event string (max 255)
* **Metadata Size**: 1 byte, size of metadata string (max 255)
* **Payload Encoding**: 1 byte (0 = binary, 1 = JSON)
* **Join Ref**: Variable length string
* **Ref**: Variable length string
* **Topic**: Variable length string
* **User Event**: Variable length string
* **Metadata**: Variable length JSON string
* **User Payload**: Variable length payload data
#### User Broadcast
```
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type (0x04) | Topic Size |User Event Size| Metadata Size |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Enc. | Topic (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User Event (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Metadata (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User Payload (variable length) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
```
**Field Descriptions:**
* **Type**: 1 byte, value = 0x04
* **Topic Size**: 1 byte, size of topic string (max 255)
* **User Event Size**: 1 byte, size of user event string (max 255)
* **Metadata Size**: 1 byte, size of metadata JSON string (max 255)
* **Payload Encoding**: 1 byte (0 = binary, 1 = JSON)
* **Topic**: Variable length string
* **User Event**: Variable length string
* **Metadata**: Variable length JSON string
* **User Payload**: Variable length payload data
## Event types
Messages for all events are encoded as text frames using JSON except with the `broadcast` event type which can happen on both text and binary frames.
### Client sent events
| Event Type | Description | Requires Ref | Requires Join Ref |
| -------------- | -------------------------------------------------------- | ------------ | ----------------- |
| `phx_join` | Initial message to join a channel and configure features | ✅ | ✅ |
| `phx_leave` | Message to leave a channel | ✅ | ✅ |
| `heartbeat` | Heartbeat message to keep the connection alive | ✅ | ⛔ |
| `access_token` | Message to update the access token | ✅ | ✅ |
| `broadcast` | Broadcast message sent to all clients in a channel | ✅ | ✅ |
| `presence` | Presence state update sent after joining a channel | ✅ | ✅ |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### phx\_join
This is the initial message required to join a channel. The client sends this message to the server to join a specific topic and configure the features it wants to use, such as Postgres changes, Presence, and Broadcast. The payload of the `phx_join` event contains the configuration options for the channel.
```ts
{
"config": {
"broadcast": {
"ack": boolean,
"self": boolean,
"replay" : {
"since": integer,
"limit": integer
}
},
"presence": {
"enabled": boolean,
"key": string
},
"postgres_changes": [
{
"event": string,
"schema": string,
"table": string,
"filter": string
}
]
"private": boolean
},
"access_token": string
}
```
* `config`:
* `private`: Whether the channel is private
* `broadcast`: Configuration options for broadcasting messages
* `ack`: Acknowledge broadcast messages
* `self`: Include the sender in broadcast messages
* `replay`: Configuration options for broadcast replay (Optional)
* `since`: Replay messages since a specific timestamp in milliseconds
* `limit`: Limit the number of replayed messages (Optional)
* `presence`: Configuration options for presence tracking
* `enabled`: Whether presence tracking is enabled for this channel
* `key`: Key to be used for presence tracking, if not specified or empty, a UUID will be generated and used
* `postgres_changes`: Array of configurations for Postgres changes
* `event`: Database change event to listen to, accepts `INSERT`, `UPDATE`, `DELETE`, or `*` to listen to all events.
* `schema`: Schema of the table to listen to, accepts `*` wildcard to listen to all schemas
* `table`: Table of the database to listen to, accepts `*` wildcard to listen to all tables
* `filter`: Filter to be used when pulling changes from database. Read more about filters in the usage docs for [Postgres Changes](/docs/guides/realtime/postgres-changes?queryGroups=language\&language=js#filtering-for-specific-changes)
* `access_token`: Optional access token for authentication, if not provided, the server will use the API key.
Example on protocol version `2.0.0`:
```json
[
"3",
"5",
"realtime:chat-room",
"phx_join",
{
"config": {
"broadcast": {
"ack": false,
"self": true,
"replay": {
"since": 1763407103911,
"limit": 10
}
},
"presence": {
"key": "user_id-827",
"enabled": true
},
"postgres_changes": [],
"private": true
}
}
]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### phx\_leave
This message is sent by the client to leave a channel. It can be used to clean up resources or stop listening for events on that channel. Payload should be empty object.
Example on protocol version `2.0.0`:
```json
["1", "3", "realtime:avatar-stack-demo", "phx_leave", {}]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### heartbeat
The heartbeat message should be sent at least every 25 seconds to avoid a connection timeout. Payload should be an empty object.
For heartbeat, the topic `phoenix` is used as this special message is not connected to a specific channel.
Example on protocol version `2.0.0`:
```json
[null, "26", "phoenix", "heartbeat", {}]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### access\_token
Used to setup a new token to be used by Realtime for authentication and to refresh the token to prevent a private channel from closing when the token expires.
```ts
{
"access_token": string
}
```
* `access_token`: The new access token to be used for authentication. Either to change it or to refresh it.
Example on protocol version `2.0.0`:
```json
[
"10",
"1",
"realtime:chat-room",
"access_token",
{
"access_token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWUsImlhdCI6MTUxNjIzOTAyMn0.KMUFsIDTnFmyG3nMiGM6H9FNFUROf3wh7SmqJp-QV30"
}
]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### broadcast (text frame)
Used to send a broadcast event to all clients in a channel.
The `payload` field contains the event name and the data to broadcast.
```ts
{
"event": string,
"payload": json,
"type": "broadcast"
}
```
* `event`: The name of the user event to broadcast.
* `payload`: The user data associated with the event, which can be any JSON-serializable data structure.
* `type`: The type of message, which must always be `broadcast`.
Example on protocol version `2.0.0`:
```json
[
"10",
"1",
"realtime:chat-room",
"broadcast",
{
"event": "user-event",
"type": "broadcast",
"payload": {
"content": "Hello, World!",
"createdAt": "2025-11-17T21:14:14Z",
"id": "9b823349-71c0-465b-9a83-a63aa2a9ae6d",
"username": "VCSHLD556nQD-B-vUTJJ3"
}
}
]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### broadcast (binary frame)
See the [User Broadcast Push](#user-broadcast-push) section for the binary frame structure.
This message is a streamlined version of the text frame broadcast event that also supports non-JSON payloads.
Below is the same example from the previous section, showing the binary frame structure with hexadecimal values for the header and plain text for the remaining fields:
* Join Ref: `10`
* Ref: `1`
* Topic: `realtime:chat-room`
* Payload encoding being JSON
* User Event: `user-event`
* Metadata is empty
* User Payload
```
0x03 // Type
0x02 // Join Ref Size
0x01 // Ref Size
0x12 // Topic Size
0x0A // User Event Size
0x00 // Metadata Size
0x01 // Payload Encoding (1 = JSON)
10 // Actual Join Ref
1 // Actual Ref
realtime:chat-room // Topic
user-event // User Event
{ // User Event Payload
"content": "Hello, World!",
"createdAt": "2025-11-17T21:14:14Z",
"id": "9b823349-71c0-465b-9a83-a63aa2a9ae6d",
"username": "VCSHLD556nQD-B-vUTJJ3"
}
```
The payload encoding is just a hint for the client to know if the payload should be treated as JSON or not.
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### presence
Used to send presence metadata after joining a channel. The payload contains the presence information to be tracked by the server.
This metadata is then sent back to all clients in the channel via `presence_state` and `presence_diff` events.
```ts
{
"type": "presence",
"event": "track",
"payload": json
}
```
Example on protocol version `2.0.0`:
```json
[
"1",
"5",
"realtime:presence-room",
"presence",
{
"type": "presence",
"event": "track",
"payload": {
"name": "Alice",
"color": "hsl(29, 100%, 70%)"
}
}
]
```
### Server sent events
| Event Type | Description | Requires Ref | Requires Join Ref |
| ------------------ | ----------------------------------------------------------------------- | ------------ | ----------------- |
| `phx_close` | Message from server to signal channel closed | ✅ | ✅ |
| `phx_error` | Error message sent by the server when an error occurs | ✅ | ✅ |
| `phx_reply` | Response to a `phx_join` or other requests | ✅ | ✅\* |
| `system` | System messages to inform about the status of the Postgres subscription | ⛔ | ⛔ |
| `broadcast` | Broadcast message sent to all clients in a channel | ⛔ | ⛔ |
| `presence_state` | Presence state sent by the server on join | ⛔ | ⛔ |
| `presence_diff` | Presence state diff update sent after a change in presence state | ⛔ | ⛔ |
| `postgres_changes` | Postgres CDC message containing changes to the database | ⛔ | ⛔ |
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### phx\_close
This message is sent by the server to signal that the channel has been closed. Payload will be empty object.
Example on protocol version `2.0.0`:
```json
["3", "3", "realtime:avatar-stack-demo", "phx_close", {}]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### phx\_error
This message is sent by the server when an unexpected error occurs in the channel. Payload will be an empty object
```json
["3", "3", "realtime:avatar-stack-demo", "phx_error", {}]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### phx\_reply
The server sends these messages in response to client requests that require acknowledgment.
```ts
{
"status": string,
"response": any,
}
```
* `status`: The status of the response, can be `ok` or `error`.
* `response`: The response data, which can vary based on the event that was replied to
`phx_join` has a specific response structure outlined below.
Contains the status of the join request and any additional information requested in the `phx_join` payload.
```ts
{
"postgres_changes": [
{
"id": number,
"event": string,
"schema": string,
"table": string
}
]
}
```
* `postgres_changes`: Array of Postgres changes that the client is subscribed to, each object contains:
* `id`: Unique identifier for the Postgres changes subscription
* `event`: The type of event the client is subscribed to, such as `INSERT`, `UPDATE`, `DELETE`, or `*`
* `schema`: The schema of the table the client is subscribed to
* `table`: The table the client is subscribed to
Example on protocol version `2.0.0`:
```json
[
"1",
"1",
"realtime:chat-room",
"phx_reply",
{
"status": "ok",
"response": {
"postgres_changes": [
{
"id": 106243155,
"event": "*",
"schema": "public",
"table": "test"
}
]
}
}
]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### system
The server sends system messages to inform clients about the status of their Realtime channel subscriptions.
```ts
{
"message": string,
"status": string,
"extension": string,
"channel": string
}
```
* `message`: A human-readable message describing the status of the subscription.
* `status`: The status of the subscription, can be `ok`, `error`, or `timeout`.
* `extension`: The extension that sent the message.
* `channel`: The channel to which the message belongs, such as `realtime:room1`.
Example on protocol version `2.0.0`:
```json
[
"13",
null,
"realtime:chat-room",
"system",
{
"message": "Subscribed to PostgreSQL",
"status": "ok",
"extension": "postgres_changes",
"channel": "main"
}
]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### broadcast (text frame)
{/* supa-mdx-lint-disable-next-line Rule003Spelling */}
This is the structure of broadcast events received by all clients subscribed to a channel. The `payload` field contains the event name and data that was broadcasted.
```ts
{
"event": string,
"meta" : {
"id" : uuid,
"replayed" : boolean
},
"payload": json,
"type": "broadcast"
}
```
* `event`: The name of the user event to broadcast.
* `meta`: Metadata about the broadcast message. Not always present.
* `id`: A unique identifier for the broadcast message in UUID format.
* `replayed`: A boolean indicating whether the message is a replayed message. Not always present
* `payload`: The user data associated with the event, which can be any JSON-serializable data structure.
* `type`: The type of message, which must always be `broadcast` for broadcast messages.
Example on protocol version `2.0.0`:
```json
[
null,
null,
"realtime:chat-room",
"broadcast",
{
"event": "message",
"type": "broadcast",
"meta": {
"id": "006554ce-d22d-469c-877a-88bef47214a3"
},
"payload": {
"id": "513edcc1-4cbc-4274-aa26-c195f7e8c090",
"content": "oi",
"username": "hpK9jN2iY-I2HioHWr5ml",
"createdAt": "2025-11-18T22:44:29Z"
}
}
]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### broadcast (binary frame)
See the [User Broadcast](#user-broadcast) section for the binary frame structure.
This message is a streamlined version of the text frame broadcast event that also supports non-JSON payloads.
Below is the same example from the previous section, showing the binary frame structure with hexadecimal values for the header and plain text for the remaining fields:
* Topic: `realtime:chat-room`
* Payload encoding being JSON
* Metadata: `{"id":"006554ce-d22d-469c-877a-88bef47214a3"}`
* User Event: `message`
* User Payload
```
0x04 // Type
0x12 // Topic Size
0x07 // User Event Size
0x2D // Metadata Size
0x01 // Payload Encoding (1 = JSON)
realtime:chat-room // Topic
message // User Event
{"id":"006554ce-d22d-469c-877a-88bef47214a3"} // Metadata
{ // User Event Payload
"id": "513edcc1-4cbc-4274-aa26-c195f7e8c090",
"content": "oi",
"username": "hpK9jN2iY-I2HioHWr5ml",
"createdAt": "2025-11-18T22:44:29Z"
}
```
The metadata field is JSON encoded. The payload encoding is just a hint for the client to know if the payload should be treated as JSON or not.
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### postgres\_changes
The server sends this message when a database change occurs in a subscribed schema and table. The payload contains the details of the change, including the schema, table, event type, and the new and old records.
```ts
{
"ids": [
number
],
"data": {
"schema": string,
"table": string,
"commit_timestamp": string,
"type": "*" | "INSERT" | "UPDATE" | "DELETE",
"columns": [
{
"name": string,
"type": string
}
]
"record": {
[key: string]: boolean | number | string | null
},
"old_record": {
[key: string]: boolean | number | string | null
},
"errors": string | null
}
}
```
* `ids`: An array of unique identifiers matching the subscription when joining the channel.
* `data`: An object containing the details of the change:
* `schema`: The schema of the table where the change occurred.
* `table`: The table where the change occurred.
* `commit_timestamp`: The timestamp when the change was committed to the database.
* `type`: The type of event that occurred, such as `INSERT`, `UPDATE`, `DELETE`, or `*` for all events.
* `columns`: An array of objects representing the columns of the table, each containing:
* `name`: The name of the column.
* `type`: The data type of the column.
* `record`: An object representing the new values after the change, with keys as column names and values as their corresponding values.
* `old_record`: An object representing the old values before the change, with keys as column names and values as their corresponding values.
* `errors`: Any errors that occurred during the change, if applicable.
```json
[
null,
null,
"realtime:chat-room",
"postgres_changes",
{
"ids": [104868189],
"data": {
"schema": "public",
"table": "test",
"commit_timestamp": "2025-11-19T00:22:40.877Z",
"type": "UPDATE",
"columns": [
{
"name": "id",
"type": "int8"
},
{
"name": "created_at",
"type": "timestamptz"
},
{
"name": "text",
"type": "text"
}
],
"record": {
"id": 46,
"text": "content",
"created_at": "2025-11-03T09:32:55+00:00"
},
"old_record": {
"id": 46
},
"errors": null
}
}
]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### presence\_state
After joining, the server sends a `presence_state` message to a client with presence information. The payload field contains keys, where each key represents a client and its value is a JSON object containing information about that client. The key is defined by the client when joining the channel. If not specified, a UUID is automatically generated.
```ts
{
[key: string]: {
metas: [
{
phx_ref: string,
[key: string]: any
}
]
}
}
```
* `key`: The client key.
* `metas`: An array of metadata objects for the client, each containing:
* `phx_ref`: A unique reference ID for the metadata.
* Any other custom fields defined by the client, such as `name`.
Example on protocol version `2.0.0`:
```json
[
"4",
null,
"realtime:cursor-room",
"presence_state",
{
"2wCojG1xWgxG2ZxwocvSX": {
"metas": [
{
"phx_ref": "GHlA1fShRjMmZhnL",
"color": "hsl(204, 100%, 70%)",
"key": "2wCojG1xWgxG2ZxwocvSX"
}
]
},
"6eorYR7andHiq-7tCkmxQ": {
"metas": [
{
"phx_ref": "GHk99Q_ez6-GzaeG",
"color": "hsl(7, 100%, 70%)",
"key": "6eorYR7andHiq-7tCkmxQ"
}
]
},
"FOeQUamq3OLOWAAZK8iH3": {
"metas": [
{
"phx_ref": "GHk-wA8Z61GGzeoG",
"color": "hsl(212, 100%, 70%)",
"key": "FOeQUamq3OLOWAAZK8iH3"
}
]
}
}
]
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### presence\_diff
After a change to the presence state, such as a client joining or leaving, the server sends a presence\_diff message to update the client's view of the presence state. The payload field contains two keys, `joins` and `leaves`, which represent clients that have joined and left, respectively. Each key is either specified by the client when joining the channel or automatically generated as a UUID.
```ts
{
"joins": {
[key: string]: {
metas: [
{
phx_ref: string,
[key: string]: any
}
]
}
},
"leaves": {
[key: string]: {
metas: [
{
phx_ref: string,
[key: string]: any
}
]
}
}
}
```
* `joins`: An object containing metadata for clients that have joined the channel, with keys as UUIDs and values as metadata objects.
* `leaves`: An object containing metadata for clients that have left the channel, with keys as UUIDs and values as metadata objects.
Example on protocol version `2.0.0`:
```json
[
null,
null,
"realtime:cursor-room",
"presence_diff",
{
"joins": {
"XnAJXkZVEJuBYZcp9GCG5": {
"metas": [
{
"phx_ref": "GHlE8VLvxuKGzQJN",
"color": "hsl(60, 100%, 70%)",
"user": "123"
}
]
}
},
"leaves": {
"ouCsaiOdKZ9yauoy4x5pv": {
"metas": [
{
"phx_ref": "GHlE8HyhSPAmZgdB",
"color": "hsl(72, 100%, 70%)",
"user": "456"
}
]
}
}
}
]
```
# Listening to Postgres Changes with Flutter
The Postgres Changes extension listens for database changes and sends them to clients which enables you to receive database changes in real-time.
# Using Realtime Presence with Flutter
Use Supabase Presence to display the currently online users on your Flutter application.
Displaying the list of currently online users is a common feature for real-time collaborative applications. Supabase Presence makes it easy to track users joining and leaving the session so that you can make a collaborative app.
# Using Realtime with Next.js
In this guide, we explore the best ways to receive real-time Postgres changes with your Next.js application.
We'll show both client and server side updates, and explore which option is best.
# Realtime Reports
{/* supa-mdx-lint-disable Rule001HeadingCase */}
Realtime reports give insights into how your application uses Supabase Realtime, including connections, broadcast and change events, execution times, and lag.
These reports help you:
* Monitor connection counts and message volumes against your plan's quotas
* Identify performance bottlenecks in RLS policies or database replication
* Troubleshoot errors and connection issues
* Plan capacity upgrades based on usage trends
Access Realtime reports from **[Project Settings > Product Reports > Realtime](/dashboard/project/_/observability/realtime)** in your project dashboard.
## Realtime reports overview
| Report | Available Plans | Description | Key Insights |
| ----------------------------------------------------------------------------------------------------------------- | --------------------- | ------------------------------------------------------------------------------------ | ----------------------------------------------------------------------------- |
| [Connected Clients](#connected-clients) | All | Number of connected clients | Total number of connected clients |
| [Broadcast Events](#broadcast-events) | All | Number of broadcast events | Broadcast events sent by clients |
| [Presence Events](#presence-events) | All | Number of presence events | Presence events sent by clients |
| [Postgres Changes Events](#postgres-changes-events) | All | Number of Postgres changes events | Postgres changes events received by clients |
| [Rate of Channel Joins](#rate-of-channel-joins) | All | Rate of channel joins | Rate of change of users joining channels |
| [Message Payload Size](#message-payload-size) | All | Median size of message payloads sent | Understand the payload sizes sent and received by clients |
| [Broadcast from Database Replication Lag](#broadcast-from-database-replication-lag) | Pro, Team, Enterprise | Median time between database commit and broadcast when using broadcast from database | Time taken from database change received and when it was broadcast to clients |
| [(Read) Private Channel Subscription RLS Execution Time](#read-private-channel-subscription-rls-execution-time) | Pro, Team, Enterprise | Execution median time of RLS (Row Level Security) to subscribe to a private channel | RLS policy impact on time to validate if user can join private channel |
| [(Write) Private Channel Subscription RLS Execution Time](#write-private-channel-subscription-rls-execution-time) | Pro, Team, Enterprise | Execution median time of RLS (Row Level Security) to publish to a private channel | RLS policy impact on time to validate if user can write to private channel |
| [Total Requests](#total-requests) | All | Total requests | Total requests made to the Realtime API |
| [Response Errors](#response-errors) | All | Response errors | Response errors from the Realtime API |
| [Response Speed](#response-speed) | All | Response speed | Average response time from the Realtime API |
## Connected Clients
The Connected Clients report helps you monitor the total number of concurrent Realtime client connections to your project over time. This metric is essential for understanding your application's connection usage patterns and identifying when you're approaching your plan's connection limits.
The report displays the total number of connected Realtime clients, showing how connection counts fluctuate throughout the selected time period. Each client connection represents an active WebSocket connection to your Realtime service, which can subscribe to multiple channels for receiving real-time updates.
### Actions you can take
| Action | Description | More information |
| --------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------ |
| Configure connection limit | Adjust the "Max concurrent connections" setting to increase or decrease the connection limit for your project | [Realtime Settings Guide](/docs/guides/realtime/settings) |
| Upgrade plan | Increase available client connections. Connection limits vary by plan: Free (200), Pro (500), Pro no spend cap (10,000), Team (10,000), Enterprise (10,000+) | [Pricing and Plans](/pricing) |
| Review quotas | Understand connection limits and other Realtime quotas for your plan | [Realtime Quotas Reference](/docs/guides/realtime/quotas) |
| Understand connection quota | Learn how the concurrent connections quota works and how to configure it for your plan | [Concurrent Peak Connections Quota Troubleshooting](/docs/troubleshooting/realtime-concurrent-peak-connections-quota-jdDqcp) |
| Fix silent disconnections | Fix connection issues in background applications using heartbeat callbacks and Web Workers | [Handling Silent Disconnections in Background Apps](/docs/troubleshooting/realtime-handling-silent-disconnections-in-backgrounded-applications-592794) |
| Check logs | Investigate connection errors and quota errors in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Contact support | Request custom quota increases for Enterprise plans or discuss connection requirements | [Support Portal](/dashboard/support/new) |
## Broadcast Events
The Broadcast Events report helps you monitor the volume of broadcast messages sent through your Realtime channels over time. This metric is essential for understanding your application's real-time messaging patterns and identifying when you're approaching your plan's message throughput limits.
The report displays the total number of broadcast events sent by clients, showing message volume throughout the selected time period. Broadcast events are low-latency messages sent between users using Realtime's pub/sub pattern, which can be sent from client libraries, REST APIs, or directly from your database. Each event represents a message broadcast to subscribers of a specific channel topic.
### Actions you can take
| Action | Description | More information |
| ---------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------- |
| Configure event limits | Adjust "Max events per second" and "Max payload size in KB" settings to optimize broadcast throughput and message size limits | [Realtime Settings Guide](/docs/guides/realtime/settings) |
| Review quotas | Understand message per second limits (Free: 100, Pro: 500, Pro no spend cap/Team/Enterprise: 2,500) and broadcast payload size limits (Free: 256 KB, Pro+: 3,000 KB) | [Realtime Quotas Reference](/docs/guides/realtime/quotas) |
| Check logs | Investigate broadcast errors or quota limit issues in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Debug with logger | Enable logging to track messages sent and received, and diagnose broadcast delivery issues | [Debugging Realtime with Logger](/docs/troubleshooting/realtime-debugging-with-logger) |
| Learn broadcast basics | Understand how to implement and optimize broadcast messaging in your application | [Broadcast Guide](/docs/guides/realtime/broadcast) |
| Contact support | Request custom quota increases for Enterprise plans or discuss messaging requirements | [Support Portal](/dashboard/support/new) |
## Presence Events
The Presence Events report helps you monitor the volume of presence state updates sent through your Realtime channels over time. This metric is essential for understanding how your application tracks and synchronizes shared state between users, such as online status, user activity, or custom state information.
The report displays the total number of presence events sent by clients, showing state synchronization activity throughout the selected time period. Presence events occur when clients `track`, `update`, or `untrack` their presence state in a channel, triggering `sync`, `join`, or `leave` events. Unlike broadcast messages, presence state is persisted in the channel so new joiners immediately receive the current state without waiting for other users to send updates.
### Actions you can take
| Action | Description | More information |
| ------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------- |
| Configure presence limits | Adjust the "Max presence events per second" setting to optimize presence state update throughput | [Realtime Settings Guide](/docs/guides/realtime/settings) |
| Review quotas | Understand presence messages per second limits (Free: 20, Pro: 50, Pro no spend cap/Team/Enterprise: 1,000) and presence keys per object limits (10 for most plans) | [Realtime Quotas Reference](/docs/guides/realtime/quotas) |
| Check logs | Investigate presence errors or quota limit issues in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Debug with logger | Enable logging to track presence events and diagnose state synchronization issues | [Debugging Realtime with Logger](/docs/troubleshooting/realtime-debugging-with-logger) |
| Learn presence basics | Understand how to implement and optimize presence state tracking in your application | [Presence Guide](/docs/guides/realtime/presence) |
| Contact support | Request custom quota increases for Enterprise plans or discuss presence requirements | [Support Portal](/dashboard/support/new) |
## Postgres Changes Events
The Postgres Changes Events report helps you monitor the volume of database change events (INSERT, UPDATE, DELETE) sent to your Realtime clients over time. This metric is essential for understanding how your application processes database changes and identifying potential performance bottlenecks or scaling issues.
The report displays the total number of Postgres change events received by clients, showing database change activity throughout the selected time period. Postgres Changes use logical replication to stream database changes from the Write-Ahead Log (WAL) to subscribed clients. Each event represents a database change that has been broadcast to clients subscribed to the relevant schema and table. Note that Postgres Changes process changes on a single thread to maintain order, which can create bottlenecks at scale compared to Broadcast.
### Actions you can take
| Action | Description | More information |
| ------------------------ | ----------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------ |
| Review quotas | Understand Postgres change payload size limits (1,024 KB for all plans) and message throughput limits | [Realtime Quotas Reference](/docs/guides/realtime/quotas) |
| Check logs | Investigate Postgres Changes errors or performance issues in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Learn Postgres Changes | Understand limitations and best practices for using Postgres Changes | [Postgres Changes Guide](/docs/guides/realtime/postgres-changes) |
| Migrate to Broadcast | For better scalability, consider using Broadcast with database triggers instead of Postgres Changes | [Broadcast Guide](/docs/guides/realtime/broadcast) |
| Create database triggers | Understand how to create triggers that can send Broadcast messages on database events | [Database Triggers Guide](/docs/guides/database/postgres/triggers) |
| Monitor replication | Monitor logical replication health and lag since Postgres Changes reads from the WAL | [manual replication monitoring guide](/docs/guides/database/replication/manual-replication-monitoring) |
| Contact support | Discuss scaling strategies or custom solutions for high-volume database change subscriptions | [Support Portal](/dashboard/support/new) |
## Rate of Channel Joins
The Rate of Channel Joins report helps you monitor how quickly clients are joining Realtime channels over time. This metric is essential for understanding your application's channel subscription patterns and identifying when you're approaching your plan's channel join rate limits.
The report displays the rate of channel joins per second, showing how frequently clients subscribe to channels throughout the selected time period. A channel join occurs whenever a client subscribes to a channel topic to receive real-time updates. Each client connection can join multiple channels (up to 100 per connection for most plans), and the join rate measures how many of these subscriptions happen per second across your entire project.
### Actions you can take
| Action | Description | More information |
| -------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------- |
| Review quotas | Understand channel joins per second limits (Free: 100, Pro: 500, Pro no spend cap/Team/Enterprise: 2,500) and channels per connection limits (100 for most plans) | [Realtime Quotas Reference](/docs/guides/realtime/quotas) |
| Check logs | Investigate `too_many_joins` errors or channel join failures in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Fix channel errors | Learn how to properly manage channel lifecycle and prevent channel leaks in your application | [TooManyChannels Error Troubleshooting](/docs/troubleshooting/realtime-too-many-channels-error) |
| Learn channel basics | Understand how Realtime channels work and best practices for channel management | [Realtime Channels Concepts](/docs/guides/realtime/concepts#channels) |
| Contact support | Request custom quota increases for Enterprise plans or discuss high-volume channel join requirements | [Support Portal](/dashboard/support/new) |
## Message Payload Size
The Message Payload Size report helps you monitor the median size of message payloads sent through your Realtime channels over time. This metric is essential for understanding how message size impacts performance, latency, and bandwidth usage in your real-time application.
The report displays the median payload size in bytes, showing how message sizes fluctuate throughout the selected time period. Payload size directly affects message throughput and latency—larger payloads require more bandwidth and processing time, which can increase latency and reduce the number of messages your system can handle per second. Monitoring this metric helps you optimize your message structure and identify opportunities to reduce payload sizes for better performance.
### Actions you can take
| Action | Description | More information |
| ------------------------ | ---------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------- |
| Configure payload limits | Adjust the "Max payload size in KB" setting to increase or decrease the maximum message size allowed | [Realtime Settings Guide](/docs/guides/realtime/settings) |
| Review quotas | Understand payload size limits: Broadcast (Free: 256 KB, Pro+: 3,000 KB) and Postgres Changes (1,024 KB for all plans) | [Realtime Quotas Reference](/docs/guides/realtime/quotas) |
| Check logs | Investigate payload-related errors or performance issues in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Review benchmarks | Understand how payload size affects latency and throughput (larger payloads increase latency) | [Payload Size Performance Benchmarks](/docs/guides/realtime/benchmarks#broadcast-impact-of-payload-size) |
| Debug query performance | Use `explain()` to analyze queries and identify performance bottlenecks that may be causing large payloads | [Query Performance Debugging Guide](/docs/guides/database/debugging-performance) |
| Learn broadcast basics | Understand best practices for structuring broadcast messages and optimizing payload sizes | [Broadcast Guide](/docs/guides/realtime/broadcast) |
| Contact support | Discuss payload optimization strategies or custom solutions for high-volume messaging | [Support Portal](/dashboard/support/new) |
## Broadcast From Database Replication Lag
The Broadcast from Database Replication Lag report helps you monitor the median time between when a message is committed to your database and when it's broadcast to Realtime clients. This metric is essential for understanding the latency introduced by the database replication process when using broadcast from database.
The report displays the median replication lag in milliseconds, showing the delay between database commit and broadcast throughout the selected time period. When you use broadcast from database (by inserting messages into `realtime.messages`), Realtime reads changes from the Write-Ahead Log (WAL) using logical replication. The lag represents the time it takes for these changes to be processed and broadcast to subscribed clients. Higher lag values indicate delays in the replication pipeline, which can impact the real-time responsiveness of your application.
### Actions you can take
| Action | Description | More information |
| -------------------------- | ----------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------- |
| Check logs | Investigate replication errors or performance issues in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Monitor database | Review database resource utilization, connection counts, and query performance that may affect replication | [Database Observability Dashboard](/dashboard/project/_/observability/database) |
| Review replication metrics | Use `pg_stat_subscription`, `pg_replication_slots`, and other Postgres views to diagnose replication issues | [manual replication monitoring guide](/docs/guides/database/replication/manual-replication-monitoring) |
| Debug database issues | Use CLI inspection tools to identify bloat, lock contention, and long-running queries affecting replication | [Database Inspection Tools Guide](/docs/guides/database/inspect) |
| Optimize performance | Optimize query performance and connection management to reduce database load | [Performance Tuning Guide](/docs/guides/platform/performance) |
| Configure timeouts | Configure statement timeouts to prevent long-running transactions from blocking replication | [Database Timeouts Guide](/docs/guides/database/postgres/timeouts) |
| Learn broadcast from DB | Understand how broadcast from database works and best practices for implementation | [Broadcast from Database Guide](/docs/guides/realtime/broadcast#trigger-broadcast-messages-from-your-database) |
| Contact support | Discuss replication lag issues or request assistance with database performance optimization | [Support Portal](/dashboard/support/new) |
## (Read) Private Channel Subscription RLS Execution Time
The (Read) Private Channel Subscription RLS Execution Time report helps you monitor the median time it takes to execute Row Level Security (RLS) policies when users subscribe to private channels. This metric is essential for understanding how RLS policy complexity impacts channel join latency and overall connection performance.
The report displays the median RLS execution time in milliseconds, showing how long it takes to validate user permissions when subscribing to private channels throughout the selected time period. When a user joins a private channel, Realtime checks RLS policies on the `realtime.messages` table to determine if the user has read access. This authorization check happens once per channel subscription and the result is cached for the duration of the connection. However, complex RLS policies with joins, function calls, or missing indexes can significantly increase this initial connection time.
### Actions you can take
| Action | Description | More information |
| -------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- |
| Configure connection pool | Adjust the "Database connection pool size" setting to increase the number of connections available for RLS authorization checks, which can improve performance for high-volume channel subscriptions | [Realtime Settings Guide](/docs/guides/realtime/settings) |
| Optimize RLS policies | Learn how to optimize RLS policies with indexes, function wrapping, and query optimization techniques | [RLS Performance Best Practices](/docs/troubleshooting/rls-performance-and-best-practices-Z5Jjwv) |
| Check logs | Investigate RLS authorization errors or timeout issues in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Learn authorization basics | Understand how RLS policies work with private channels and best practices for implementation | [Realtime Authorization Guide](/docs/guides/realtime/authorization) |
| Create indexes | Add indexes on columns frequently used in RLS policy conditions to speed up authorization checks | [Database Indexes Guide](/docs/guides/database/postgres/indexes) |
| Use index advisor | Automatically detect missing indexes that could improve RLS policy performance | [Index Advisor Extension Guide](/docs/guides/database/extensions/index_advisor) |
| Optimize queries | Learn techniques for optimizing queries including partial indexes and composite indexes for RLS conditions | [Query Optimization Guide](/docs/guides/database/query-optimization) |
| Monitor database | Review database query performance and identify slow queries that may be affecting RLS execution | [Database Observability Dashboard](/dashboard/project/_/observability/database) |
| Contact support | Discuss RLS optimization strategies or get assistance with complex authorization requirements | [Support Portal](/dashboard/support/new) |
## (Write) Private Channel Subscription RLS Execution Time
The (Write)Private Channel Subscription RLS Execution Time report helps you monitor the median time it takes to execute Row Level Security (RLS) policies when users publish messages to private channels. This metric is essential for understanding how RLS policy complexity impacts message publishing latency and overall broadcast performance.
The report displays the median RLS execution time in milliseconds, showing how long it takes to validate user permissions when publishing to private channels throughout the selected time period. When a user sends a broadcast message to a private channel, Realtime checks RLS policies on the `realtime.messages` table to determine if the user has write (INSERT) access. This authorization check happens for the first message sent and then it's cached. Complex RLS policies with joins, function calls, or missing indexes can significantly increase first message publishing latency.
### Actions you can take
| Action | Description | More information |
| -------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- |
| Configure connection pool | Adjust the "Database connection pool size" setting to increase the number of connections available for RLS authorization checks, which can improve performance for high-frequency message publishing | [Realtime Settings Guide](/docs/guides/realtime/settings) |
| Optimize RLS policies | Learn how to optimize RLS policies with indexes, function wrapping, and query optimization techniques | [RLS Performance Best Practices](/docs/troubleshooting/rls-performance-and-best-practices-Z5Jjwv) |
| Check logs | Investigate RLS authorization errors or timeout issues when publishing messages in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Learn authorization basics | Understand how RLS policies work with private channels for write operations and best practices for implementation | [Realtime Authorization Guide](/docs/guides/realtime/authorization) |
| Create indexes | Add indexes on columns used in INSERT policies to speed up write authorization checks | [Database Indexes Guide](/docs/guides/database/postgres/indexes) |
| Use index advisor | Automatically detect missing indexes that could improve write RLS policy performance | [Index Advisor Extension Guide](/docs/guides/database/extensions/index_advisor) |
| Optimize queries | Learn techniques for optimizing INSERT policy queries including partial indexes for specific conditions | [Query Optimization Guide](/docs/guides/database/query-optimization) |
| Monitor database | Review database query performance and identify slow queries that may be affecting write RLS execution | [Database Observability Dashboard](/dashboard/project/_/observability/database) |
| Contact support | Discuss RLS optimization strategies or get assistance with complex authorization requirements for high-frequency messaging | [Support Portal](/dashboard/support/new) |
## Total Requests
The Total Requests report helps you monitor the overall volume of HTTP requests for Realtime over time. This metric is essential for understanding your application's usage patterns and identifying traffic trends or potential issues with API request handling.
The report displays the total number of HTTP requests made to the Realtime service which include the WebSocket upgrade requests and the REST API requests.
### Actions you can take
| Action | Description | More information |
| ------------------------ | ---------------------------------------------------------------------------- | -------------------------------------------------------------------------------------- |
| Check logs | Investigate request errors or issues in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Review error rates | Compare total requests with error rates to identify failure patterns | [Response Errors Report](#response-errors) |
| Review response times | Monitor API response times to identify performance bottlenecks | [Response Speed Report](#response-speed) |
| Learn REST API broadcast | Understand how to send broadcast messages using HTTP requests | [Broadcast via REST API Guide](/docs/guides/realtime/broadcast#broadcast-via-rest-api) |
| Monitor database | Review database resource utilization that may affect API request processing | [Database Observability Dashboard](/dashboard/project/_/observability/database) |
| Contact support | Discuss high-volume request patterns or get assistance with API optimization | [Support Portal](/dashboard/support/new) |
## Response Errors
The Response Errors report helps you monitor the number of failed HTTP requests to the Realtime service over time. This metric is essential for identifying issues with API requests, WebSocket upgrade failures, authentication problems, and other error conditions that may impact your application's real-time functionality.
The report displays the total number of response errors from the Realtime API, showing error frequency throughout the selected time period. These errors include HTTP error status codes (4xx client errors and 5xx server errors) from REST API requests, failed WebSocket upgrade requests, authorization failures, and other error responses. Monitoring error rates alongside total requests helps you identify patterns, correlate errors with specific events, and troubleshoot issues affecting your Realtime service availability.
### Actions you can take
| Action | Description | More information |
| ----------------------- | --------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------- |
| Configure limits | Adjust "Max concurrent connections" or "Max events per second" settings if errors are related to quota limits being reached | [Realtime Settings Guide](/docs/guides/realtime/settings) |
| Check logs | Investigate specific error messages, error codes, and request details in your project dashboard | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Review request volume | Compare error rates with total request volume to calculate error percentages and identify trends | [Total Requests Report](#total-requests) |
| Understand error codes | Understand specific error codes and their resolutions | [Realtime Error Codes Reference](/docs/guides/realtime/error_codes) |
| Learn HTTP status codes | Learn about HTTP status codes including 4XX client errors and 5XX server errors | [HTTP Status Codes Troubleshooting](/docs/troubleshooting/http-status-codes) |
| Fix timeout errors | Resolve WebSocket timeout errors caused by Node.js version incompatibility | [TIMED\_OUT Connection Errors Troubleshooting](/docs/troubleshooting/realtime-connections-timed_out-status) |
| Understand heartbeats | Monitor heartbeat status to detect connection issues and handle timeouts | [Realtime Heartbeats Guide](/docs/troubleshooting/realtime-heartbeat-messages) |
| Review quotas | Check if errors are related to quota limits (e.g., `too_many_connections`, `too_many_joins`) | [Realtime Quotas Reference](/docs/guides/realtime/quotas) |
| Learn authorization | Troubleshoot authorization-related errors for private channels | [Realtime Authorization Guide](/docs/guides/realtime/authorization) |
| Contact support | Get assistance with persistent errors or investigate service-level issues | [Support Portal](/dashboard/support/new) |
## Response Speed
The Response Speed report helps you monitor the average response time for HTTP requests to the Realtime service over time. This metric is essential for understanding API performance, identifying latency issues, and ensuring your real-time features meet performance expectations.
The report displays the average response time in milliseconds, showing how quickly the Realtime service responds to HTTP requests throughout the selected time period. This includes response times for REST API requests such as broadcast messages, WebSocket upgrade requests, and other HTTP-based interactions. Higher response times can indicate performance bottlenecks, database load issues, or network problems that may impact the real-time responsiveness of your application.
### Actions you can take
| Action | Description | More information |
| ------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- |
| Configure connection pool | Adjust the "Database connection pool size" setting to optimize database connection usage, which can improve response times for authorization checks | [Realtime Settings Guide](/docs/guides/realtime/settings) |
| Check logs | Investigate slow requests and identify specific endpoints or operations causing delays | [Realtime Logs Dashboard](/dashboard/project/_/database/realtime-logs) |
| Review request volume | Correlate response times with request volume to identify performance degradation under load | [Total Requests Report](#total-requests) |
| Monitor database | Review database resource utilization, connection counts, and query performance that may affect response times | [Database Observability Dashboard](/dashboard/project/_/observability/database) |
| Review benchmarks | Understand expected latency and throughput for different Realtime operations | [Realtime Performance Benchmarks](/docs/guides/realtime/benchmarks) |
| Understand heartbeats | Monitor heartbeat status and customize intervals to balance detection speed with network overhead | [Realtime Heartbeats Guide](/docs/troubleshooting/realtime-heartbeat-messages) |
| Optimize RLS policies | If using private channels, optimize RLS policies that may be slowing down authorization checks | [RLS Performance Best Practices](/docs/troubleshooting/rls-performance-and-best-practices-Z5Jjwv) |
| Contact support | Discuss performance optimization strategies or investigate persistent latency issues | [Support Portal](/dashboard/support/new) |
# Settings
Realtime Settings that allow you to configure your Realtime usage.
## Settings
All changes made in this screen will disconnect all your connected clients to ensure Realtime starts with the appropriate settings and all changes are stored in Supabase middleware.
You can set the following settings using the Realtime Settings screen in your Dashboard:
* Enable Realtime service: Determines if the Realtime service is enabled or disabled for your project.
* Channel Restrictions: You can toggle this settings to set Realtime to allow public channels or set it to use only private channels with [Realtime Authorization](/docs/guides/realtime/authorization).
* Database connection pool size: Determines the number of connections used for Realtime Authorization RLS checking
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
* Max concurrent clients: Determines the maximum number of clients that can be connected
* Max events per second: Determines the maximum number of events per second that can be sent
* Max presence events per second: Determines the maximum number of presence events per second that can be sent
* Max payload size in KB: Determines the maximum number of payload size in KB that can be sent
# Subscribing to Database Changes
Listen to database changes in real-time from your website or application.
You can use Supabase to subscribe to real-time database changes. There are two options available:
1. [Broadcast](/docs/guides/realtime/broadcast). This is the recommended method for scalability and security.
2. [Postgres Changes](/docs/guides/realtime/postgres-changes). This is a simpler method. It requires less setup, but does not scale as well as Broadcast.
## Using Broadcast
To automatically send messages when a record is created, updated, or deleted, we can attach a [Postgres trigger](/docs/guides/database/postgres/triggers) to any table. Supabase Realtime provides a `realtime.broadcast_changes()` function which we can use in conjunction with a trigger. This function will use a private channel and needs broadcast authorization RLS policies to be met.
### Broadcast authorization
[Realtime Authorization](/docs/guides/realtime/authorization) is required for receiving Broadcast messages. This is an example of a policy that allows authenticated users to listen to messages from topics:
{/* prettier-ignore */}
```sql
create policy "Authenticated users can receive broadcasts"
on "realtime"."messages"
for select
to authenticated
using ( true );
```
### Create a trigger function
Let's create a function that we can call any time a record is created, updated, or deleted. This function will make use of some of Postgres's native [trigger variables](https://www.postgresql.org/docs/current/plpgsql-trigger.html#PLPGSQL-DML-TRIGGER). For this example, we want to have a topic with the name `topic:` to which we're going to broadcast events.
{/* prettier-ignore */}
```sql
create or replace function public.your_table_changes()
returns trigger
security definer
language plpgsql
as $$
begin
perform realtime.broadcast_changes(
'topic:' || coalesce(NEW.id, OLD.id) ::text, -- topic - the topic to which you're broadcasting where you can use the topic id to build the topic name
TG_OP, -- event - the event that triggered the function
TG_OP, -- operation - the operation that triggered the function
TG_TABLE_NAME, -- table - the table that caused the trigger
TG_TABLE_SCHEMA, -- schema - the schema of the table that caused the trigger
NEW, -- new record - the record after the change
OLD -- old record - the record before the change
);
return null;
end;
$$;
```
### Create a trigger
Let's set up a trigger so the function is executed after any changes to the table.
{/* prettier-ignore */}
```sql
create trigger handle_your_table_changes
after insert or update or delete
on public.your_table
for each row
execute function your_table_changes ();
```
#### Listening on client side
Finally, on the client side, listen to the topic `topic:` to receive the events. Remember to set the channel as a private channel, since `realtime.broadcast_changes` uses Realtime Authorization.
```js
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const gameId = 'id'
await supabase.realtime.setAuth() // Needed for Realtime Authorization
const changes = supabase
.channel(`topic:${gameId}`, {
config: { private: true },
})
.on('broadcast', { event: 'INSERT' }, (payload) => console.log(payload))
.on('broadcast', { event: 'UPDATE' }, (payload) => console.log(payload))
.on('broadcast', { event: 'DELETE' }, (payload) => console.log(payload))
.subscribe()
```
## Using Postgres Changes
Postgres Changes are simple to use, but have some [limitations](/docs/guides/realtime/postgres-changes#limitations) as your application scales. We recommend using Broadcast for most use cases.
### Enable Postgres Changes
You'll first need to create a `supabase_realtime` publication and add your tables (that you want to subscribe to) to the publication:
```sql
begin;
-- remove the supabase_realtime publication
drop
publication if exists supabase_realtime;
-- re-create the supabase_realtime publication with no tables
create publication supabase_realtime;
commit;
-- add a table called 'messages' to the publication
-- (update this to match your tables)
alter
publication supabase_realtime add table messages;
```
### Streaming inserts
You can use the `INSERT` event to stream all new rows.
```js
// @noImplicitAny: false
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const channel = supabase
.channel('schema-db-changes')
.on(
'postgres_changes',
{
event: 'INSERT',
schema: 'public',
},
(payload) => console.log(payload)
)
.subscribe()
```
### Streaming updates
You can use the `UPDATE` event to stream all updated rows.
```js
// @noImplicitAny: false
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const channel = supabase
.channel('schema-db-changes')
.on(
'postgres_changes',
{
event: 'UPDATE',
schema: 'public',
},
(payload) => console.log(payload)
)
.subscribe()
```
# API
{/* */}
When you create a Queue in Supabase, you can choose to create helper database functions in the `pgmq_public` schema. This schema exposes operations to manage Queue Messages to consumers client-side, but does not expose functions for creating or dropping Queues.
Database functions in `pgmq_public` can be exposed via Supabase Data API so consumers client-side can call them. Visit the [Quickstart](/docs/guides/queues/quickstart) for an example.
### `pgmq_public.pop(queue_name)`
Retrieves the next available message and deletes it from the specified Queue.
* `queue_name` (`text`): Queue name
***
### `pgmq_public.send(queue_name, message, sleep_seconds)`
Adds a Message to the specified Queue, optionally delaying its visibility to all consumers by a number of seconds.
* `queue_name` (`text`): Queue name
* `message` (`jsonb`): Message payload to send
* `sleep_seconds` (`integer`, optional): Delay message visibility by specified seconds. Defaults to 0
***
### `pgmq_public.send_batch(queue_name, messages, sleep_seconds)`
Adds a batch of Messages to the specified Queue, optionally delaying their availability to all consumers by a number of seconds.
* `queue_name` (`text`): Queue name
* `messages` (`jsonb[]`): Array of message payloads to send
* `sleep_seconds` (`integer`, optional): Delay messages visibility by specified seconds. Defaults to 0
***
### `pgmq_public.archive(queue_name, message_id)`
Archives a Message by moving it from the Queue table to the Queue's archive table.
* `queue_name` (`text`): Queue name
* `message_id` (`bigint`): ID of the Message to archive
***
### `pgmq_public.delete(queue_name, message_id)`
Permanently deletes a Message from the specified Queue.
* `queue_name` (`text`): Queue name
* `message_id` (`bigint`): ID of the Message to delete
***
### `pgmq_public.read(queue_name, sleep_seconds, n)`
Reads up to "n" Messages from the specified Queue with an optional "sleep\_seconds" (visibility timeout).
* `queue_name` (`text`): Queue name
* `sleep_seconds` (`integer`): Visibility timeout in seconds
* `n` (`integer`): Maximum number of Messages to read
# Consuming Supabase Queue Messages with Edge Functions
Learn how to consume Supabase Queue messages server-side with a Supabase Edge Function
This guide helps you read & process queue messages server-side with a Supabase Edge Function. Read [Queues API Reference](/docs/guides/queues/api) for more details on our API.
## Concepts
Supabase Queues is a pull-based Message Queue consisting of three main components: Queues, Messages, and Queue Types. You should already be familiar with the [Queues Quickstart](/docs/guides/queues/quickstart).
### Consuming messages in an Edge Function
This is a Supabase Edge Function that reads 5 messages off the queue, processes each of them, and deletes each message when it is done.
```tsx
import 'jsr:@supabase/functions-js/edge-runtime.d.ts'
import { createClient } from 'npm:@supabase/supabase-js@2'
const supabaseUrl = 'supabaseURL'
const supabaseKey = 'supabaseKey'
const supabase = createClient(supabaseUrl, supabaseKey)
const queueName = 'your_queue_name'
// Type definition for queue messages
interface QueueMessage {
msg_id: bigint
read_ct: number
vt: string
enqueued_at: string
message: any
}
async function processMessage(message: QueueMessage) {
//
// Do whatever logic you need to with the message content
//
// Delete the message from the queue
const { error: deleteError } = await supabase.schema('pgmq_public').rpc('delete', {
queue_name: queueName,
msg_id: message.msg_id,
})
if (deleteError) {
console.error(`Failed to delete message ${message.msg_id}:`, deleteError)
} else {
console.log(`Message ${message.msg_id} deleted from queue`)
}
}
Deno.serve(async (req) => {
const { data: messages, error } = await supabase.schema('pgmq_public').rpc('read', {
queue_name: queueName,
sleep_seconds: 0, // Don't wait if queue is empty
n: 5, // Read 5 messages off the queue
})
if (error) {
console.error(`Error reading from ${queueName} queue:`, error)
return new Response(JSON.stringify({ error: error.message }), {
status: 500,
headers: { 'Content-Type': 'application/json' },
})
}
if (!messages || messages.length === 0) {
console.log('No messages in workflow_messages queue')
return new Response(JSON.stringify({ message: 'No messages in queue' }), {
status: 200,
headers: { 'Content-Type': 'application/json' },
})
}
console.log(`Found ${messages.length} messages to process`)
// Process each message that was read off the queue
for (const message of messages) {
try {
await processMessage(message as QueueMessage)
} catch (error) {
console.error(`Error processing message ${message.msg_id}:`, error)
}
}
// Return immediately while background processing continues
return new Response(
JSON.stringify({
message: `Processing ${messages.length} messages in background`,
count: messages.length,
}),
{
status: 200,
headers: { 'Content-Type': 'application/json' },
}
)
})
```
Every time this Edge Function is run it:
1. Read 5 messages off the queue
2. Call the `processMessage` function
3. At the end of `processMessage`, the message is deleted from the queue
4. If `processMessage` throws an error, the error is logged. In this case, the message is still in the queue, so the next time this Edge Function runs it reads the message again.
You might find this kind of setup handy to run with [Supabase Cron](/docs/guides/cron). You can set up Cron so that every N number of minutes or seconds, the Edge Function will run and process a number of messages off the queue.
Similarly, you can invoke the Edge Function on command at any given time with [`supabase.functions.invoke`](/docs/guides/functions/quickstart-dashboard#usage).
# Expose Queues for local and self-hosted Supabase
Learn how to expose Queues when running Supabase with Supabase CLI or Docker Compose
By default, local and self-hosted Supabase instances expose only core schemas like public and graphql\_public.
To allow client-side consumers to use your queues, you have to add `pgmq_public` schema to the list of exposed schemas.
Before continuing, complete the step [Expose queues to client-side consumers](/docs/guides/queues/quickstart#expose-queues-to-client-side-consumers) from the Queues Quickstart guide. This creates the `pgmq_public` schema, which must exist before it can be exposed through the API.
You only need to expose the `pgmq_public` schema manually when running Supabase locally with the Supabase CLI or self-hosting using Docker Compose.
## Expose Queues with Supabase CLI
When running Supabase locally with Supabase CLI, update your project's `config.toml` file.
Locate the `[api]` section and add `pgmq_public` to the list of schemas.
```toml
[api]
enabled = true
port = 54321
schemas = ["public", "graphql_public", "pgmq_public"]
```
Then restart your local Supabase stack.
```bash
supabase stop && supabase start
```
## Expose queues with Docker compose
When running Supabase with Docker Compose, locate the `PGRST_DB_SCHEMAS` variable inside your `.env` file and add `pgmq_public` to it. This environment variable is passed to the `rest` service inside `docker-compose.yml`.
```
PGRST_DB_SCHEMAS=public,graphql_public,pgmq_public
```
Restart your containers for the changes to take effect.
```bash
docker compose down
docker compose up -d
```
## Stop exposing queues
If you no longer want to expose the `pgmq_public` schema, you can remove it from your configuration.
* For Supabase CLI, remove `pgmq_public` from the `[api]` schemas list in your `config.toml` file.
* For Docker Compose, remove `pgmq_public` from the `PGRST_DB_SCHEMAS` variable in your `.env` file.
After updating your configuration, restart your containers for the changes to take effect.
# PGMQ Extension
pgmq is a lightweight message queue built on Postgres.
## Features
* Lightweight - No background worker or external dependencies, just Postgres functions packaged in an extension
* "exactly once" delivery of messages to a consumer within a visibility timeout
* API parity with AWS SQS and RSMQ
* Messages stay in the queue until explicitly removed
* Messages can be archived, instead of deleted, for long-term retention and replayability
## Enable the extension
```sql
create extension pgmq;
```
## Usage \[#get-usage]
### Queue management
#### `create`
Create a new queue.
{/* prettier-ignore */}
```sql
pgmq.create(queue_name text)
returns void
```
**Parameters:**
| Parameter | Type | Description |
| :---------- | :--- | :-------------------- |
| queue\_name | text | The name of the queue |
Example:
{/* prettier-ignore */}
```sql
select from pgmq.create('my_queue');
create
--------
```
#### `create_unlogged`
Creates an unlogged table. This is useful when write throughput is more important than durability.
See Postgres documentation for [unlogged tables](https://www.postgresql.org/docs/current/sql-createtable.html#SQL-CREATETABLE-UNLOGGED) for more information.
{/* prettier-ignore */}
```sql
pgmq.create_unlogged(queue_name text)
returns void
```
**Parameters:**
| Parameter | Type | Description |
| :---------- | :--- | :-------------------- |
| queue\_name | text | The name of the queue |
Example:
{/* prettier-ignore */}
```sql
select pgmq.create_unlogged('my_unlogged');
create_unlogged
-----------------
```
***
#### `detach_archive`
Drop the queue's archive table as a member of the PGMQ extension. Useful for preventing the queue's archive table from being dropped when `drop extension pgmq` is executed.
This does not prevent the further archives() from appending to the archive table.
{/* prettier-ignore */}
```sql
pgmq.detach_archive(queue_name text)
```
**Parameters:**
| Parameter | Type | Description |
| :---------- | :--- | :-------------------- |
| queue\_name | text | The name of the queue |
Example:
{/* prettier-ignore */}
```sql
select * from pgmq.detach_archive('my_queue');
detach_archive
----------------
```
***
#### `drop_queue`
Deletes a queue and its archive table.
{/* prettier-ignore */}
```sql
pgmq.drop_queue(queue_name text)
returns boolean
```
**Parameters:**
| Parameter | Type | Description |
| :---------- | :--- | :-------------------- |
| queue\_name | text | The name of the queue |
Example:
{/* prettier-ignore */}
```sql
select * from pgmq.drop_queue('my_unlogged');
drop_queue
------------
t
```
### Sending messages
#### `send`
Send a single message to a queue.
{/* prettier-ignore */}
```sql
pgmq.send(
queue_name text,
msg jsonb,
delay integer default 0
)
returns setof bigint
```
**Parameters:**
| Parameter | Type | Description |
| :----------- | :-------- | :----------------------------------------------------------------- |
| `queue_name` | `text` | The name of the queue |
| `msg` | `jsonb` | The message to send to the queue |
| `delay` | `integer` | Time in seconds before the message becomes visible. Defaults to 0. |
Example:
{/* prettier-ignore */}
```sql
select * from pgmq.send('my_queue', '{"hello": "world"}');
send
------
4
```
***
#### `send_batch`
Send 1 or more messages to a queue.
{/* prettier-ignore */}
```sql
pgmq.send_batch(
queue_name text,
msgs jsonb[],
delay integer default 0
)
returns setof bigint
```
**Parameters:**
| Parameter | Type | Description |
| :----------- | :-------- | :------------------------------------------------------------------ |
| `queue_name` | `text` | The name of the queue |
| `msgs` | `jsonb[]` | Array of messages to send to the queue |
| `delay` | `integer` | Time in seconds before the messages becomes visible. Defaults to 0. |
{/* prettier-ignore */}
```sql
select * from pgmq.send_batch(
'my_queue',
array[
'{"hello": "world_0"}'::jsonb,
'{"hello": "world_1"}'::jsonb
]
);
send_batch
------------
1
2
```
***
### Reading messages
#### `read`
Read 1 or more messages from a queue. The VT specifies the duration of time in seconds that the message is invisible to other consumers. At the end of that duration, the message is visible again and could be read by other consumers.
{/* prettier-ignore */}
```sql
pgmq.read(
queue_name text,
vt integer,
qty integer
)
returns setof pgmq.message_record
```
**Parameters:**
| Parameter | Type | Description |
| :----------- | :-------- | :-------------------------------------------------------------- |
| `queue_name` | `text` | The name of the queue |
| `vt` | `integer` | Time in seconds that the message become invisible after reading |
| `qty` | `integer` | The number of messages to read from the queue. Defaults to 1 |
Example:
{/* prettier-ignore */}
```sql
select * from pgmq.read('my_queue', 10, 2);
msg_id | read_ct | enqueued_at | vt | message
--------+---------+-------------------------------+-------------------------------+----------------------
1 | 1 | 2023-10-28 19:14:47.356595-05 | 2023-10-28 19:17:08.608922-05 | {"hello": "world_0"}
2 | 1 | 2023-10-28 19:14:47.356595-05 | 2023-10-28 19:17:08.608974-05 | {"hello": "world_1"}
(2 rows)
```
***
#### `read_with_poll`
Same as read(). Also provides convenient long-poll functionality.
When there are no messages in the queue, the function call will wait for `max_poll_seconds` in duration before returning.
If messages reach the queue during that duration, they will be read and returned immediately.
{/* prettier-ignore */}
```sql
pgmq.read_with_poll(
queue_name text,
vt integer,
qty integer,
max_poll_seconds integer default 5,
poll_interval_ms integer default 100
)
returns setof pgmq.message_record
```
**Parameters:**
| Parameter | Type | Description |
| :----------------- | :-------- | :-------------------------------------------------------------------------- |
| `queue_name` | `text` | The name of the queue |
| `vt` | `integer` | Time in seconds that the message become invisible after reading. |
| `qty` | `integer` | The number of messages to read from the queue. Defaults to 1. |
| `max_poll_seconds` | `integer` | Time in seconds to wait for new messages to reach the queue. Defaults to 5. |
| `poll_interval_ms` | `integer` | Milliseconds between the internal poll operations. Defaults to 100. |
Example:
{/* prettier-ignore */}
```sql
select * from pgmq.read_with_poll('my_queue', 1, 1, 5, 100);
msg_id | read_ct | enqueued_at | vt | message
--------+---------+-------------------------------+-------------------------------+--------------------
1 | 1 | 2023-10-28 19:09:09.177756-05 | 2023-10-28 19:27:00.337929-05 | {"hello": "world"}
```
***
#### `pop`
Reads a single message from a queue and deletes it upon read.
Note: utilization of pop() results in at-most-once delivery semantics if the consuming application does not guarantee processing of the message.
{/* prettier-ignore */}
```sql
pgmq.pop(queue_name text)
returns setof pgmq.message_record
```
**Parameters:**
| Parameter | Type | Description |
| :---------- | :--- | :-------------------- |
| queue\_name | text | The name of the queue |
Example:
{/* prettier-ignore */}
```sql
pgmq=# select * from pgmq.pop('my_queue');
msg_id | read_ct | enqueued_at | vt | message
--------+---------+-------------------------------+-------------------------------+--------------------
1 | 2 | 2023-10-28 19:09:09.177756-05 | 2023-10-28 19:27:00.337929-05 | {"hello": "world"}
```
***
### Deleting/Archiving messages
#### `delete` (single)
Deletes a single message from a queue.
{/* prettier-ignore */}
```sql
pgmq.delete (queue_name text, msg_id: bigint)
returns boolean
```
**Parameters:**
| Parameter | Type | Description |
| :----------- | :------- | :---------------------------------- |
| `queue_name` | `text` | The name of the queue |
| `msg_id` | `bigint` | Message ID of the message to delete |
Example:
{/* prettier-ignore */}
```sql
select pgmq.delete('my_queue', 5);
delete
--------
t
```
***
#### `delete` (batch)
Delete one or many messages from a queue.
{/* prettier-ignore */}
```sql
pgmq.delete (queue_name text, msg_ids: bigint[])
returns setof bigint
```
**Parameters:**
| Parameter | Type | Description |
| :----------- | :--------- | :----------------------------- |
| `queue_name` | `text` | The name of the queue |
| `msg_ids` | `bigint[]` | Array of message IDs to delete |
Examples:
Delete two messages that exist.
{/* prettier-ignore */}
```sql
select * from pgmq.delete('my_queue', array[2, 3]);
delete
--------
2
3
```
Delete two messages, one that exists and one that does not. Message `999` does not exist.
```sql
select * from pgmq.delete('my_queue', array[6, 999]);
delete
--------
6
```
***
#### `purge_queue`
Permanently deletes all messages in a queue. Returns the number of messages that were deleted.
```text
purge_queue(queue_name text)
returns bigint
```
**Parameters:**
| Parameter | Type | Description |
| :---------- | :--- | :-------------------- |
| queue\_name | text | The name of the queue |
Example:
Purge the queue when it contains 8 messages;
{/* prettier-ignore */}
```sql
select * from pgmq.purge_queue('my_queue');
purge_queue
-------------
8
```
***
#### `archive` (single)
Removes a single requested message from the specified queue and inserts it into the queue's archive.
{/* prettier-ignore */}
```sql
pgmq.archive(queue_name text, msg_id bigint)
returns boolean
```
**Parameters:**
| Parameter | Type | Description |
| :----------- | :------- | :----------------------------------- |
| `queue_name` | `text` | The name of the queue |
| `msg_id` | `bigint` | Message ID of the message to archive |
Returns
Boolean value indicating success or failure of the operation.
Example; remove message with ID 1 from queue `my_queue` and archive it:
{/* prettier-ignore */}
```sql
select * from pgmq.archive('my_queue', 1);
archive
---------
t
```
***
#### `archive` (batch)
Deletes a batch of requested messages from the specified queue and inserts them into the queue's archive.
Returns an array of message ids that were successfully archived.
```text
pgmq.archive(queue_name text, msg_ids bigint[])
RETURNS SETOF bigint
```
**Parameters:**
| Parameter | Type | Description |
| :----------- | :--------- | :------------------------------ |
| `queue_name` | `text` | The name of the queue |
| `msg_ids` | `bigint[]` | Array of message IDs to archive |
Examples:
Delete messages with ID 1 and 2 from queue `my_queue` and move to the archive.
{/* prettier-ignore */}
```sql
select * from pgmq.archive('my_queue', array[1, 2]);
archive
---------
1
2
```
Delete messages 4, which exists and 999, which does not exist.
{/* prettier-ignore */}
```sql
select * from pgmq.archive('my_queue', array[4, 999]);
archive
---------
4
```
***
### Utilities
#### `set_vt`
Sets the visibility timeout of a message to a specified time duration in the future. Returns the record of the message that was updated.
{/* prettier-ignore */}
```sql
pgmq.set_vt(
queue_name text,
msg_id bigint,
vt_offset integer
)
returns pgmq.message_record
```
**Parameters:**
| Parameter | Type | Description |
| :----------- | :-------- | :-------------------------------------------------------------------- |
| `queue_name` | `text` | The name of the queue |
| `msg_id` | `bigint` | ID of the message to set visibility time |
| `vt_offset` | `integer` | Duration from now, in seconds, that the message's VT should be set to |
Example:
Set the visibility timeout of message 1 to 30 seconds from now.
```sql
select * from pgmq.set_vt('my_queue', 11, 30);
msg_id | read_ct | enqueued_at | vt | message
--------+---------+-------------------------------+-------------------------------+----------------------
1 | 0 | 2023-10-28 19:42:21.778741-05 | 2023-10-28 19:59:34.286462-05 | {"hello": "world_0"}
```
***
#### `list_queues`
List all the queues that currently exist.
{/* prettier-ignore */}
```sql
list_queues()
RETURNS TABLE(
queue_name text,
created_at timestamp with time zone,
is_partitioned boolean,
is_unlogged boolean
)
```
Example:
{/* prettier-ignore */}
```sql
select * from pgmq.list_queues();
queue_name | created_at | is_partitioned | is_unlogged
----------------------+-------------------------------+----------------+-------------
my_queue | 2023-10-28 14:13:17.092576-05 | f | f
my_partitioned_queue | 2023-10-28 19:47:37.098692-05 | t | f
my_unlogged | 2023-10-28 20:02:30.976109-05 | f | t
```
***
#### `metrics`
Get metrics for a specific queue.
{/* prettier-ignore */}
```sql
pgmq.metrics(queue_name: text)
returns table(
queue_name text,
queue_length bigint,
newest_msg_age_sec integer,
oldest_msg_age_sec integer,
total_messages bigint,
scrape_time timestamp with time zone
)
```
**Parameters:**
| Parameter | Type | Description |
| :---------- | :--- | :-------------------- |
| queue\_name | text | The name of the queue |
**Returns:**
| Attribute | Type | Description |
| :------------------- | :------------------------- | :------------------------------------------------------------------------ | -------------------------------------------------- |
| `queue_name` | `text` | The name of the queue |
| `queue_length` | `bigint` | Number of messages currently in the queue |
| `newest_msg_age_sec` | `integer | null` | Age of the newest message in the queue, in seconds |
| `oldest_msg_age_sec` | `integer | null` | Age of the oldest message in the queue, in seconds |
| `total_messages` | `bigint` | Total number of messages that have passed through the queue over all time |
| `scrape_time` | `timestamp with time zone` | The current timestamp |
Example:
{/* prettier-ignore */}
```sql
select * from pgmq.metrics('my_queue');
queue_name | queue_length | newest_msg_age_sec | oldest_msg_age_sec | total_messages | scrape_time
------------+--------------+--------------------+--------------------+----------------+-------------------------------
my_queue | 16 | 2445 | 2447 | 35 | 2023-10-28 20:23:08.406259-05
```
***
#### `metrics_all`
Get metrics for all existing queues.
```text
pgmq.metrics_all()
RETURNS TABLE(
queue_name text,
queue_length bigint,
newest_msg_age_sec integer,
oldest_msg_age_sec integer,
total_messages bigint,
scrape_time timestamp with time zone
)
```
**Returns:**
| Attribute | Type | Description |
| :------------------- | :------------------------- | :------------------------------------------------------------------------ | -------------------------------------------------- |
| `queue_name` | `text` | The name of the queue |
| `queue_length` | `bigint` | Number of messages currently in the queue |
| `newest_msg_age_sec` | `integer | null` | Age of the newest message in the queue, in seconds |
| `oldest_msg_age_sec` | `integer | null` | Age of the oldest message in the queue, in seconds |
| `total_messages` | `bigint` | Total number of messages that have passed through the queue over all time |
| `scrape_time` | `timestamp with time zone` | The current timestamp |
{/* prettier-ignore */}
```sql
select * from pgmq.metrics_all();
queue_name | queue_length | newest_msg_age_sec | oldest_msg_age_sec | total_messages | scrape_time
----------------------+--------------+--------------------+--------------------+----------------+-------------------------------
my_queue | 16 | 2563 | 2565 | 35 | 2023-10-28 20:25:07.016413-05
my_partitioned_queue | 1 | 11 | 11 | 1 | 2023-10-28 20:25:07.016413-05
my_unlogged | 1 | 3 | 3 | 1 | 2023-10-28 20:25:07.016413-05
```
### Types
#### `message_record`
The complete representation of a message in a queue.
| Attribute Name | Type | Description |
| :------------- | :------------------------- | :--------------------------------------------------------------------- |
| `msg_id` | `bigint` | Unique ID of the message |
| `read_ct` | `bigint` | Number of times the message has been read. Increments on read(). |
| `enqueued_at` | `timestamp with time zone` | time that the message was inserted into the queue |
| `vt` | `timestamp with time zone` | Timestamp when the message will become available for consumers to read |
| `message` | `jsonb` | The message payload |
Example:
{/* prettier-ignore */}
```sql
msg_id | read_ct | enqueued_at | vt | message
--------+---------+-------------------------------+-------------------------------+--------------------
1 | 1 | 2023-10-28 19:06:19.941509-05 | 2023-10-28 19:06:27.419392-05 | {"hello": "world"}
```
## Resources
* Official Docs: [pgmq/api](https://pgmq.github.io/pgmq/#creating-a-queue)
# Quickstart
Learn how to use Supabase Queues to add and read messages
{/* */}
This guide is an introduction to interacting with Supabase Queues via the Dashboard and official client library. Check out [Queues API Reference](/docs/guides/queues/api) for more details on our API.
## Concepts
Supabase Queues is a pull-based Message Queue consisting of three main components: Queues, Messages, and Queue Types.
### Pull-Based Queue
A pull-based Queue is a Message storage and delivery system where consumers actively fetch Messages when they're ready to process them - similar to constantly refreshing a webpage to display the latest updates. Our pull-based Queues process Messages in a First-In-First-Out (FIFO) manner without priority levels.
### Message
A Message in a Queue is a JSON object that is stored until a consumer explicitly processes and removes it, like a task waiting in a to-do list until someone checks and completes it.
### Queue types
Supabase Queues offers three types of Queues:
* **Basic Queue**: A durable Queue that stores Messages in a logged table.
* **Unlogged Queue**: A transient Queue that stores Messages in an unlogged table for better performance but may result in loss of Queue Messages.
* **Partitioned Queue** (*Coming Soon*): A durable and scalable Queue that stores Messages in multiple table partitions for better performance.
## Create Queues
To get started, navigate to the [Supabase Queues](/dashboard/project/_/integrations/queues/overview) Postgres Module under Integrations in the Dashboard and enable the `pgmq` extension.
`pgmq` extension is available in Postgres version 15.6.1.143 or later.
On the [Queues page](/dashboard/project/_/integrations/queues/queues):
* Click **Add a new queue** button
If you've already created a Queue click the **Create a queue** button instead.
* Name your queue
Queue names can only be lowercase and hyphens and underscores are permitted.
* Select your [Queue Type](#queue-types)
### What happens when you create a queue?
Every new Queue creates two tables in the `pgmq` schema. These tables are `pgmq.q_` to store and process active messages and `pgmq.a_` to store any archived messages.
A "Basic Queue" will create `pgmq.q_` and `pgmq.a_` tables as logged tables.
However, an "Unlogged Queue" will create `pgmq.q_` as an unlogged table for better performance while sacrificing durability. The `pgmq.a_` table will still be created as a logged table so your archived messages remain safe and secure.
## Expose Queues to client-side consumers
Queues, by default, are not exposed over Supabase Data API and are only accessible via Postgres clients.
However, you may grant client-side consumers access to your Queues by enabling the Supabase Data API and granting permissions to the Queues API, which is a collection of database functions in the `pgmq_public` schema that wraps the database functions in the `pgmq` schema.
This is to prevent direct access to the `pgmq` schema and its tables (RLS is not enabled by default on any tables) and database functions.
To get started, navigate to the Queues [Settings page](/dashboard/project/_/integrations/queues/settings) and toggle on “Expose Queues via PostgREST”. Once enabled, Supabase creates and exposes a `pgmq_public` schema containing database function wrappers to a subset of `pgmq`'s database functions.
### Enable RLS on your tables in `pgmq` schema
For security purposes, you must enable Row Level Security (RLS) on all Queue tables (all tables in `pgmq` schema that begin with `q_`) if the Data API is enabled.
You’ll want to create RLS policies for any Queues you want your client-side consumers to interact with.
### Grant permissions to `pgmq_public` database functions
On top of enabling RLS and writing RLS policies on the underlying Queue tables, you must grant the correct permissions to the `pgmq_public` database functions for each Data API role.
The permissions required for each Queue API database function:
| **Operations** | **Permissions Required** |
| ------------------- | ------------------------ |
| `send` `send_batch` | `Select` `Insert` |
| `read` `pop` | `Select` `Update` |
| `archive` `delete` | `Select` `Delete` |
To manage your queue permissions, click on the Queue Settings button.
Then enable the required roles permissions.
`postgres` and `service_role` roles should never be exposed client-side.
### Enqueueing and dequeueing messages
Once your Queue has been created, you can begin enqueueing and dequeueing Messages.
```tsx
import { createClient } from '@supabase/supabase-js'
const supabaseUrl = 'supabaseURL'
const supabaseKey = 'supabaseKey'
const supabase = createClient(supabaseUrl, supabaseKey)
const QueuesTest: React.FC = () => {
//Add a Message
const sendToQueue = async () => {
const result = await supabase.schema('pgmq_public').rpc('send', {
queue_name: 'foo',
message: { hello: 'world' },
sleep_seconds: 30,
})
console.log(result)
}
//Dequeue Message
const popFromQueue = async () => {
const result = await supabase.schema('pgmq_public').rpc('pop', { queue_name: 'foo' })
console.log(result)
}
return (
Queue Test Component
)
}
export default QueuesTest
```
```dart
import 'package:supabase_flutter/supabase_flutter.dart';
final supabase = Supabase.instance.client;
// Add a Message
Future sendToQueue() async {
final result = await supabase.schema('pgmq_public').rpc('send', params: {
'queue_name': 'foo',
'message': {'hello': 'world'},
'sleep_seconds': 30,
});
print(result);
}
// Dequeue Message
Future popFromQueue() async {
final result = await supabase.schema('pgmq_public').rpc('pop', params: {
'queue_name': 'foo',
});
print(result);
}
```
```swift
import Supabase
let supabase = SupabaseClient(
supabaseURL: URL(string: "supabaseURL")!,
supabaseKey: "supabaseKey"
)
// Add a Message
func sendToQueue() async throws {
let result = try await supabase
.schema("pgmq_public")
.rpc("send", params: [
"queue_name": AnyJSON.string("foo"),
"message": AnyJSON.object(["hello": "world"]),
"sleep_seconds": AnyJSON.integer(30)
])
.execute()
print(result)
}
// Dequeue Message
func popFromQueue() async throws {
let result = try await supabase
.schema("pgmq_public")
.rpc("pop", params: ["queue_name": "foo"])
.execute()
print(result)
}
```
```python
from supabase import create_client, Client
supabase_url = "supabaseURL"
supabase_key = "supabaseKey"
supabase: Client = create_client(supabase_url, supabase_key)
# Add a Message
def send_to_queue():
result = supabase.schema("pgmq_public").rpc(
"send",
{
"queue_name": "foo",
"message": {"hello": "world"},
"sleep_seconds": 30,
}
).execute()
print(result)
# Dequeue Message
def pop_from_queue():
result = supabase.schema("pgmq_public").rpc(
"pop",
{"queue_name": "foo"}
).execute()
print(result)
```
# Access Control
Supabase provides granular access controls to manage permissions across your organizations and projects.
For each organization and project, a member can have one of the following roles:
* **Owner**: full access to everything in organization and project resources.
* **Administrator**: full access to everything in organization and project resources **except** updating organization settings, transferring projects outside of the organization, and adding new owners.
* **Developer**: read-only access to organization resources and content access to project resources but cannot change any project settings.
* **Read-Only**: read-only access to organization and project resources.
Read-Only role is only available on the [Team and Enterprise plans](/pricing).
When you first create an account, a default organization is created for you and you'll be assigned as the **Owner**. Any organizations you create will assign you as **Owner** as well.
## Manage organization members
To invite others to collaborate, visit your organization's team [settings](/dashboard/org/_/team) to send an invite link to another user's email. The invite is valid for 24 hours. For project scoped roles, you may only assign a role to a single project for the user when sending the invite. You can assign roles to multiple projects after the user accepts the invite.
Invites sent from a SAML SSO account can only be accepted by another SAML SSO account from the same identity provider.
This is a security measure to prevent accidental invites to accounts not managed by your enterprise's identity provider.
### Viewing organization members using the Management API
You can also view organization members using the Management API:
```bash
# Get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
export ORG_ID="your-organization-id"
# List organization members
curl "https://api.supabase.com/v1/organizations/$ORG_ID/members" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN"
```
### Transferring ownership of an organization
Each Supabase organization must have at least one owner. If your organization has other owners then you can relinquish ownership and leave the organization by clicking **Leave team** in your organization's team [settings](/dashboard/org/_/team).
Otherwise, you'll need to invite a user as **Owner**, and they need to accept the invitation, or promote an existing organization member to **Owner** before you can leave the organization.
### Organization scoped roles vs project scoped roles
Project scoped roles are only available on the [Team and Enterprise plans](/pricing).
Each member in the organization can be assigned a role that is scoped either to the entire organization or to specific projects.
* If a member has an organization-level role, they will have the corresponding permissions across all current and future projects within that organization.
* If a member is assigned a project-scoped role, they will only have access to the specific projects they've been assigned to. They will not be able to view, access, or even see other projects within the organization on the Supabase Dashboard.
This allows for more granular control, ensuring that users only have visibility and access to the projects relevant to their role.
### Organization permissions across roles
The table below shows the actions each role can take on the resources belonging to the organization.
| Resource | Action | Owner | Administrator | Developer | Read-Only\[^1] |
| ----------------------------------------------------------------------------------------------------------- | ---------- | :-------------------------------------: | :-------------------------------------: | :-------------------------------------: | :-------------------------------------: |
| **Organization** | | | | | |
| Organization Management | Update | | | | |
| | Delete | | | | |
| OpenAI Telemetry Configuration\[^2] | Update | | | | |
| **Members** | | | | | |
| Organization Members | List | | | | |
| Owner | Add | | | | |
| | Remove | | | | |
| Administrator | Add | | | | |
| | Remove | | | | |
| Developer | Add | | | | |
| | Remove | | | | |
| Owner (Project-Scoped) | Add | | | | |
| | Remove | | | | |
| Administrator (Project-Scoped) | Add | | | | |
| | Remove | | | | |
| Developer (Project-Scoped) | Add | | | | |
| | Remove | | | | |
| Invite | Revoke | | | | |
| | Resend | | | | |
| | Accept\[^3] | | | | |
| **Billing** | | | | | |
| Invoices | List | | | | |
| Billing Email | View | | | | |
| | Update | | | | |
| Subscription | View | | | | |
| | Update | | | | |
| Billing Address | View | | | | |
| | Update | | | | |
| Tax Codes | View | | | | |
| | Update | | | | |
| Payment Methods | View | | | | |
| | Update | | | | |
| Usage | View | | | | |
| **Integrations (Org Settings)** | | | | | |
| Authorize GitHub | - | | | | |
| Add GitHub Repositories | - | | | | |
| GitHub Connections | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| Vercel Connections | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| **OAuth Apps** | | | | | |
| OAuth Apps | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | List | | | | |
| **Audit Logs** | | | | | |
| View Audit logs | - | | | | |
| **Legal Documents** | | | | | |
| SOC2 Type 2 Report | Download | | | | |
| Security Questionnaire | Download | | | | |
### Project permissions across roles
The table below shows the actions each role can take on the resources belonging to the project.
| Resource | Action | Owner | Admin | Developer | Read-Only\[^4]\[^6] |
| ------------------------------------------------------------------------------------------------------ | ---------------------- | :-------------------------------------: | :-------------------------------------: | :-------------------------------------: | :-------------------------------------------------------------: |
| **Project** | | | | | |
| Project Management | Transfer | | | | |
| | Create | | | | |
| | Delete | | | | |
| | Update (Name) | | | | |
| | Pause | | | | |
| | Restore | | | | |
| | Restart | | | | |
| Custom Domains | View | | | | |
| | Update | | | | |
| Data (Database) | View | | | | |
| | Manage | | | | |
| **Infrastructure** | | | | | |
| Read Replicas | List | | | | |
| | Create | | | | |
| | Delete | | | | |
| Add-ons | Update | | | | |
| **Integrations** | | | | | |
| Authorize GitHub | - | | | | |
| Add GitHub Repositories | - | | | | |
| GitHub Connections | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| Vercel Connections | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| **Database Configuration** | | | | | |
| Reset Password | - | | | | |
| Pooling Settings | View | | | | |
| | Update | | | | |
| SSL Configuration | View | | | | |
| | Update | | | | |
| Disk Size Configuration | View | | | | |
| | Update | | | | |
| Network Restrictions | View | | | | |
| | Create | | | | |
| | Delete | | | | |
| Network Bans | View | | | | |
| | Unban | | | | |
| **API Configuration** | | | | | |
| API Keys | Read service key | | | | |
| | Read anon key | | | | |
| JWT Secret | View | | | | |
| | Generate new | | | | |
| API settings | View | | | | |
| | Update | | | | |
| **Auth Configuration** | | | | | |
| Auth Settings | View | | | | |
| | Update | | | | |
| SMTP Settings | View | | | | |
| | Update | | | | |
| Advanced Settings | View | | | | |
| | Update | | | | |
| **Storage Configuration** | | | | | |
| Upload Limit | View | | | | |
| | Update | | | | |
| S3 Access Keys | View | | | | |
| | Create | | | | |
| | Delete | | | | |
| **Edge Functions Configuration** | | | | | |
| Secrets | View | | | | \[^5] |
| | Create | | | | |
| | Delete | | | | |
| **SQL Editor** | | | | | |
| Queries | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| | List | | | | |
| | Run | | | | \[^7] |
| **Database** | | | | | |
| Scheduled Backups | View | | | | |
| | Download | | | | |
| | Restore | | | | |
| Physical backups (PITR) | View | | | | |
| | Restore | | | | |
| **Authentication** | | | | | |
| Users | Create | | | | |
| | Delete | | | | |
| | List | | | | |
| | Send OTP | | | | |
| | Send password recovery | | | | |
| | Send magic link | | | | |
| | Remove MFA factors | | | | |
| Providers | View | | | | |
| | Update | | | | |
| Rate Limits | View | | | | |
| | Update | | | | |
| Email Templates | View | | | | |
| | Update | | | | |
| URL Configuration | View | | | | |
| | Update | | | | |
| Hooks | View | | | | |
| | Create | | | | |
| | Delete | | | | |
| **Storage** | | | | | |
| Buckets | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| | List | | | | |
| Files | Create (Upload) | | | | |
| | Update | | | | |
| | Delete | | | | |
| | List | | | | |
| **Edge Functions** | | | | | |
| Edge Functions | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| | List | | | | |
| **Reports** | | | | | |
| Custom Report | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| | List | | | | |
| **Logs & Analytics** | | | | | |
| Queries | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
| | View | | | | |
| | List | | | | |
| | Run | | | | |
| **Branching** | | | | | |
| Production Branch | Read | | | | |
| | Write | | | | |
| Development Branches | List | | | | |
| | Create | | | | |
| | Update | | | | |
| | Delete | | | | |
\[^1]: Available on the Team and Enterprise Plans.
\[^2]: Sending anonymous data to OpenAI is opt in and can improve Studio AI Assistant's responses.
\[^3]: Invites sent from a SSO account can only be accepted by another SSO account coming from the same identity provider. This is a security measure that prevents accidental invites to accounts not managed by your company's enterprise systems.
\[^4]: Available on the Team and Enterprise Plans.
\[^5]: Read-Only role is able to access secrets.
\[^6]: Listed permissions are for the API and Dashboard.
\[^7]: Limited to executing SELECT queries. SQL Query Snippets run by the Read-Only role are run against the database using the **supabase\_read\_only\_user**. This role has the [predefined Postgres role pg\_read\_all\_data](https://www.postgresql.org/docs/current/predefined-roles.html).
# AWS Marketplace
You can purchase Supabase through the AWS Marketplace. Buying through AWS Marketplace can mean simpler billing, faster progress toward your AWS spend commitments, and centralized purchasing across all your AWS accounts. Start the purchase process from our marketplace [product page](https://aws.amazon.com/marketplace/pp/prodview-zjciuce2qsb3q).
When you make a purchase on AWS Marketplace, AWS will calculate sales taxes, VAT, GST, service tax, etc. (“Indirect Taxes”), if applicable, based on the location of your AWS account. You can find more details in the [AWS tax help guide](https://aws.amazon.com/tax-help/marketplace-buyers/).
### Plans available through the AWS Marketplace
* Free Plan: not available
* Pro Plan: available, self-serve
* Team Plan: available, self-serve
* Enterprise Plan: available, via AWS Marketplace Private Offer. [Contact us](https://forms.supabase.com/enterprise) for more information.
## More information
* Implications of managing your Supabase organization through the AWS Marketplace. Refer to the [Account Setup guide](./aws-marketplace/account-setup#implications-of-linking-a-supabase-organization-to-a-marketplace-subscription).
* [AWS Marketplace FAQ](./aws-marketplace/faq)
* General guidance on using the AWS Marketplace as a buyer. Refer to the [AWS documentation](https://docs.aws.amazon.com/marketplace/latest/buyerguide/using-aws-marketplace-as-a-subscriber.html).
## Next steps
* Purchase Supabase through the AWS Marketplace. Refer to the [Getting Started guide](./aws-marketplace/getting-started).
# Database Backups
We automatically back up all Free, Pro, Team, and Enterprise Plan projects on a daily basis. You can find backups in the [**Database** > **Backups**](/dashboard/project/_/database/backups/scheduled) section of the Dashboard.
Pro Plan projects can access the last 7 days of daily backups. Team Plan projects can access the last 14 days of daily backups, while Enterprise Plan projects can access up to 30 days of daily backups. If you need more frequent backups, consider enabling [Point-in-Time Recovery](#point-in-time-recovery). We recommend that free tier plan projects regularly export their data using the [Supabase CLI `db dump` command](/docs/reference/cli/supabase-db-dump) and maintain off-site backups.
When you delete a project, we permanently remove all associated data, including any backups stored in S3. This action is irreversible, so consider it carefully before proceeding.
## Types of backups
Database backups can be categorized into two types: **logical** and **physical**. You can learn more about them [in this blog post](/blog/postgresql-physical-logical-backups).
All projects on Postgres `15.8.1.079` and newer use the newer physical backup process.
Projects on older Postgres versions have to upgrade in order to be transitioned to physical backups. Once upgraded to an eligible version, your project is automatically transitioned over to physical backups.
For security purposes, daily backups do not store passwords for custom roles, and you will not find them in downloadable files. If you restore from a daily backup and use custom roles, you will need to reset their passwords after the restoration completes.
Database backups do not include objects you store via the Storage API, as the database only includes metadata about these objects. Restoring an old backup does not restore objects you deleted after that backup.
## Backup and restore process
You can access daily backups in the [**Database** > **Backups**](/dashboard/project/_/database/backups/scheduled) section of the Dashboard and restore a project to any of the backups.
You can restore your project to any of the backups. To generate a logical backup yourself, use the [Supabase CLI `db dump` command](/docs/reference/cli/supabase-db-dump).
## Managing backups programmatically
You can also manage backups programmatically [using the Management API](/docs/reference/api/v1-list-all-backups):
```bash
# Get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
# List all available backups
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
"https://api.supabase.com/v1/projects/$PROJECT_REF/database/backups"
# Restore from a PITR backup (replace Unix timestamp with desired restore point)
curl -X POST "https://api.supabase.com/v1/projects/$PROJECT_REF/database/backups/restore-pitr" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"recovery_time_target_unix": "1735689600"
}'
```
### Restoration process
When selecting a backup to restore to, choose the closest available backup made before your desired restore point. You can always choose earlier backups, but consider how many days of data you might lose.
The Dashboard prompts you for confirmation before proceeding with the restoration. The project is inaccessible during this process, so plan for downtime beforehand. Downtime depends on the size of the database—the larger it is, the longer the downtime will be.
After you confirm, we trigger the process to restore the desired backup data to your project. The dashboard will display a notification once the restoration completes.
If your project uses subscriptions or replication slots, you need to drop them before the restoration and re-create them afterwards. We exempt the slot used by Realtime from this requirement and handle it automatically.
{/* screenshot of the Dashboard of the project completing restoration */}
## Point-in-Time recovery
Point-in-Time Recovery (PITR) allows you to back up a project at shorter intervals, giving you the option to restore to any chosen point with up to seconds of granularity. Even with daily backups, you could still lose a day's worth of data. With PITR, you can back up to the point of disaster.
Pro, Team and Enterprise Plan projects can enable PITR as an add-on.
Projects that want to use PITR must also use at least a Small compute add-on to ensure smooth functioning.
As [covered in this blog post](/blog/postgresql-physical-logical-backups), a combination of physical backups and [Write Ahead Log (WAL)](https://www.postgresql.org/docs/current/wal-intro.html) file archiving makes PITR possible. Physical backups provide a snapshot of the underlying directory of the database, while WAL files contain records of every change the database processes.
We use [WAL-G](https://github.com/wal-g/wal-g), an open source archival and restoration tool, to handle both aspects of PITR. Daily, we take a snapshot of the database and send it to our storage servers. Throughout the day, as database transactions occur, we generate and upload WAL files.
By default, we back up WAL files at two-minute intervals. If these files exceed a certain file size threshold, we back them up immediately. During periods of high transaction volume, WAL file backups therefore become more frequent. Conversely, when the database has no activity, we do not make WAL file backups. Overall, in the worst case scenario, PITR achieves a Recovery Point Objective (RPO) of two minutes.
If you enable PITR, we will no longer take Daily Backups. PITR provides finer granularity than Daily Backups, so running both is unnecessary.
### Backup process
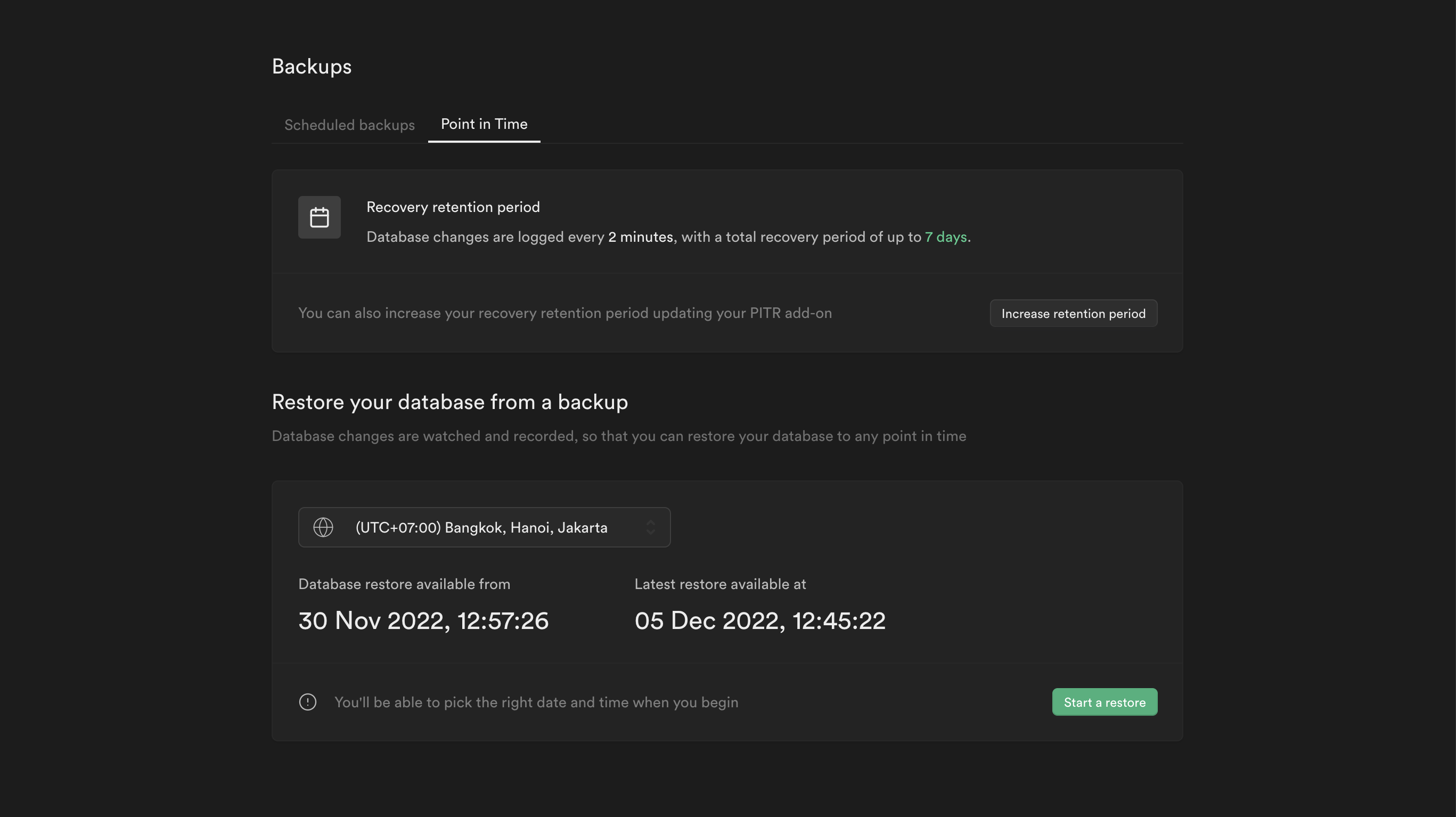
You can access PITR in the [Point in Time](/dashboard/project/_/database/backups/pitr) settings in the Dashboard. The recovery period of a project is shown by the earliest and latest recovery points displayed in your preferred timezone. You can change the maximum recovery period if needed.
The latest restore point of the project could be significantly behind the current time. This occurs when the database has had no recent activity, and therefore we have not made any recent WAL file backups. However, the state of the database at the latest recovery point still reflects the current state of the database, given that no transactions have occurred in between.
### Restoration process
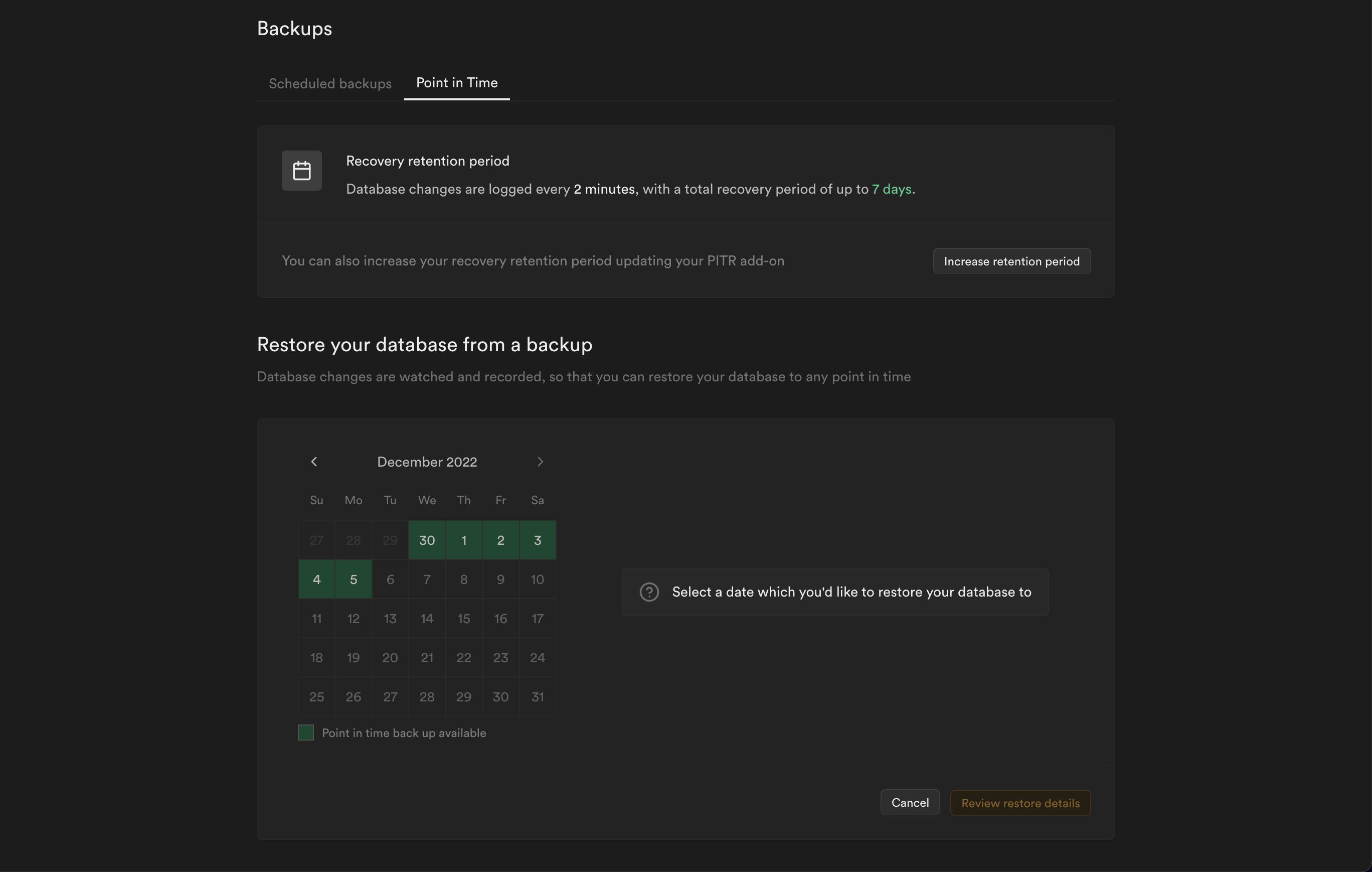
A date and time picker appears when you click the **Start a restore** button. The process only proceeds if the selected date and time fall within the earliest and latest recovery points.
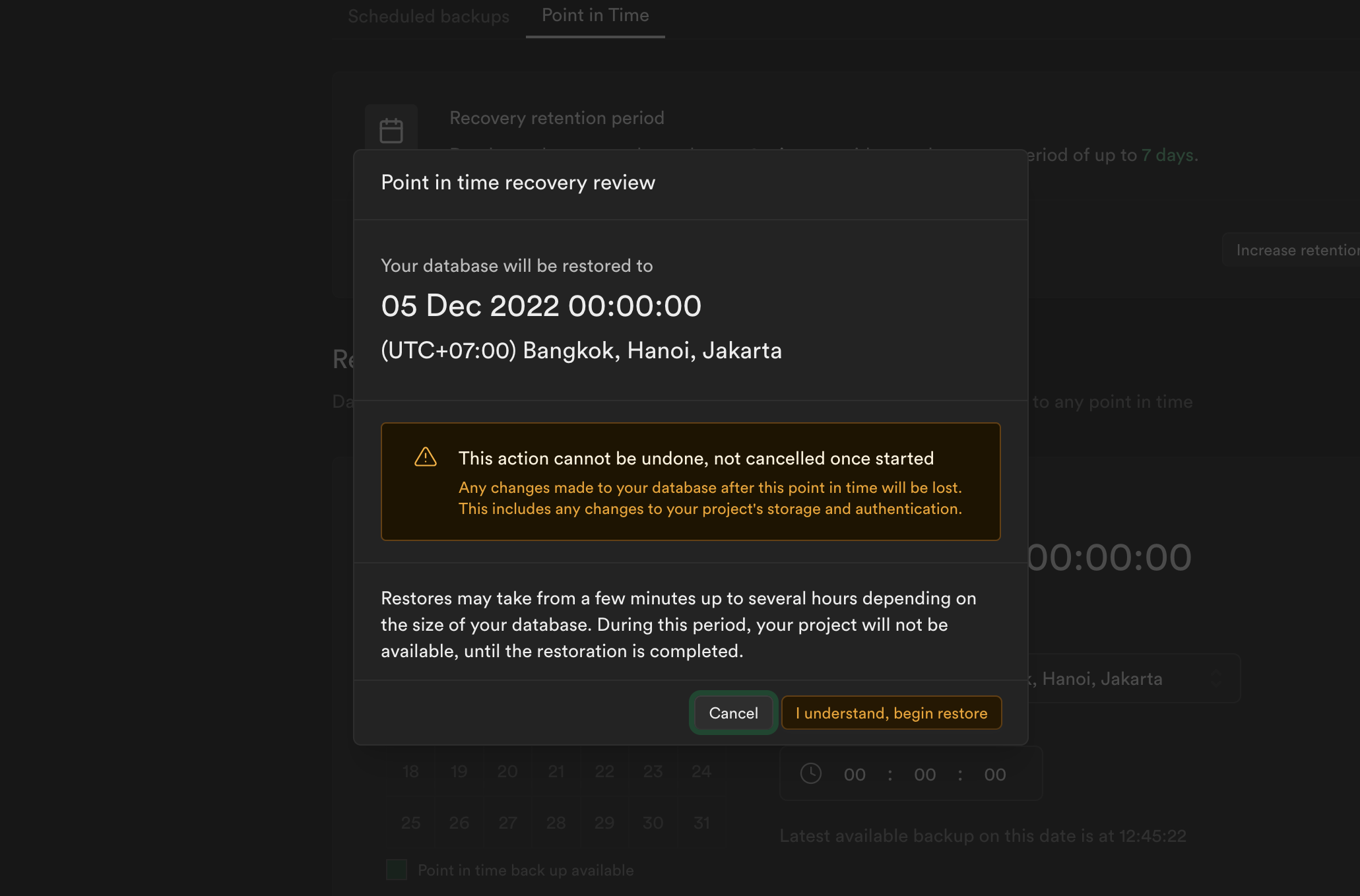
After selecting your desired recovery point, the Dashboard prompts you to review and confirm before proceeding with the restoration. The project is inaccessible during this process, so plan for downtime beforehand. Downtime depends on the size of the database—the larger it is, the longer the downtime will be. After you confirm, we download the latest available physical backup to the project and partially restore the database. We then download the WAL files generated after this physical backup up to your specified point in time. We replay the underlying transaction records in these files against the database to complete the restoration. The Dashboard will display a notification once the restoration completes.
### Pricing
Pricing depends on the recovery retention period, which determines how many days back you can restore data to any chosen point of up to seconds in granularity.
| Recovery Retention Period in Days | Hourly Price USD | Monthly Price USD |
| --------------------------------- | ----------------------- | --------------------- |
| 7 | | |
| 14 | | |
| 28 | | |
For a detailed breakdown of how charges are calculated, refer to [Manage Point-in-Time Recovery usage](/docs/guides/platform/manage-your-usage/point-in-time-recovery).
### Downloading backups after disabling PITR
When you disable PITR, we still take all new backups as physical backups only. You can still use physical backups for restoration, but they are not available for direct download. If you need to download a backup after disabling PITR, you need to take a manual [legacy logical backup using the Supabase CLI or pg\_dump](/docs/guides/platform/migrating-within-supabase/backup-restore#backup-database-using-the-cli).
## Restore to a new project
See the [Duplicate Project docs](/docs/guides/platform/clone-project).
# Billing FAQ
This documentation covers frequently asked questions around subscription plans, payments, invoices and billing in general
{/* supa-mdx-lint-disable Rule004ExcludeWords */}
## Organizations and projects
#### What are organizations and projects?
The Supabase Platform has "organizations" and "projects". An organization may contain multiple projects. Each project is a dedicated Supabase instance with all of its sub-services including Storage, Auth, Functions and Realtime.
Each organization only has a single subscription with a single plan (Free, Pro, Team or Enterprise). Project add-ons such as [Compute](/docs/guides/platform/compute-add-ons), [IPv4](/docs/guides/platform/ipv4-address), [Log Drains](/docs/guides/platform/log-drains), [Advanced MFA](/docs/guides/auth/auth-mfa/phone), [Custom Domains](/docs/guides/platform/custom-domains) and [PITR](/docs/guides/platform/backups#point-in-time-recovery) are configured per project and are added to your organization subscription.
Read more on [About billing on Supabase](/docs/guides/platform/billing-on-supabase#organization-based-billing).
#### How many free projects can I have?
You are entitled to two active free projects. Paused projects do not count towards your quota. Note that within an organization, we count the free project limits from all members that are either Owner or Admin. If you’ve got another organization member with the Admin or Owner role that has already exhausted their free project quota, you won’t be able to launch another free project in that organization. You can create another Free Plan organization or change the role of the affected member in your [organization’s team settings](/dashboard/org/_/team).
#### Can I mix free and paid projects in a single organization?
The subscription plan is set on the organization level and it is not possible to mix paid and non-paid projects inside a single organization. However, you can have a paid and a free organization and make use of the [self-serve project transfers](/docs/guides/platform/project-transfer) to organize your projects. All projects in an organization benefit from the subscription plan. If your organization is on the Pro Plan, all projects within the organization benefit from no project pausing, automated backups and so on.
#### Can I transfer my projects to another organization?
Yes, you can transfer your projects to another organization. You can find instructions on how to transfer your projects [here](/docs/guides/platform/project-transfer).
#### Can I transfer my credits to another organization?
Yes, you can transfer the credits to another organization. Submit a [support ticket](https://supabase.help).
## Pricing
See the [Pricing page](/pricing) for details.
#### Are there any charges for paused projects?
No, we do not charge for paused projects. Compute hours are only counted for active instances. Paused projects do not incur any compute usage charges.
#### How are multiple projects billed under a paid organization?
We provide a dedicated server for every Supabase project. Each paid organization comes with in Compute Credits to cover one project on the default compute size. Additional projects start at ~ a month (billed hourly).
Running 3 projects in a Pro Plan organization on the default Micro instance:
* Pro Plan
* for 3 projects on the default compute size
* Compute credits ⇒ / month
Refer to our [Compute](/docs/guides/platform/manage-your-usage/compute#billing-examples) docs for more examples and insights.
#### How does compute billing work?
Each Supabase project is a dedicated VM and Postgres database. By default, your instance runs on the Micro compute instance. You have the option to upgrade your compute size in your [Project settings](/dashboard/project/_/settings/addons). See [Compute Add-ons](/docs/guides/platform/compute-add-ons) for available options.
When you change your compute size, there are no immediate upfront charges. Instead, you will be billed based on the compute hours during your billing cycle reset.
If you launch additional instances on your paid plan, we will add the corresponding compute hours to your final invoice.
If you upgrade your project to a larger instance for 10 hours and then downgrade, you’ll only pay for the larger instance for the 10 hours of usage at the end of your billing cycle. You can see your current compute usage on your [organization’s usage page](/dashboard/org/_/usage).
Read more about [Compute usage](/docs/guides/platform/manage-your-usage/compute).
#### What is egress and how is it billed?
Egress refers to the total bandwidth (network traffic) quota available to each organization. This quota can be utilized for various purposes such as Storage, Realtime, Auth, Functions, Supavisor, Log Drains and Database. Each plan includes a specific egress quota, and any additional usage beyond that quota is billed accordingly.
We differentiate between cached (served via our CDN from cache hits) and uncached egress and give quotas for each type and have varying pricing (cached egress is cheaper). Cached egress only applies to Storage.
Read more about [Egress usage](/docs/guides/platform/manage-your-usage/egress).
## Plans and subscriptions
#### How do I change my subscription plan?
Change your subscription plan in your [organization's billing settings](/dashboard/org/_/billing). To upgrade to an Enterprise Plan, complete the [Enterprise request form](https://forms.supabase.com/enterprise).
#### What happens if I cancel my subscription?
The organization is given [credits](/docs/guides/platform/credits) for unused time on the subscription plan. The credits will not expire and can be used again in the future. You may see an additional charge for unbilled excessive usage charges from your previous billing cycle.
Read more about [downgrades](/docs/guides/platform/manage-your-subscription#downgrade).
#### I mistakenly upgraded the wrong organization and then downgraded it. Could you issue a refund?
We can transfer the amount as [credits](/docs/guides/platform/credits) to another organization of your choice. You can use these credits to upgrade the organization, or if you have already upgraded, the credits will be used to pay the next month's invoice. Please create a [support ticket](https://supabase.help) for this case.
#### How do I get an annual subscription?
We currently do not support annual plans officially. However, you can do a [credit top-up](/docs/guides/platform/credits#credit-top-ups) to avoid monthly payments.
## Quotas and spend caps
#### What will happen when I exceed the Free Plan quota?
You will be notified when you exceed the Free Plan quota. It is important to take action at this point. If you continue to exceed the limits without reducing your usage, service restrictions will apply. To avoid service restrictions, you have two options: reduce your usage or upgrade to a paid plan. Learn more about restrictions in the [Fair Use Policy](#fair-use-policy) section.
#### What will happen when I exceed the Pro Plan quota and have the spend cap on?
You will be notified when you exceed your Pro Plan quota. To unblock yourself, you can toggle off your spend cap in your [organization's billing settings](/dashboard/org/_/billing) to pay for over-usage beyond the Pro plans limits. If you continue to exceed the limits without reducing your usage or turning off the spend cap, restrictions will apply. Learn more about restrictions in the [Fair Use Policy](#fair-use-policy) section.
#### How do I scale beyond the limits of my Pro Plan?
The Pro Plan has a Spend Cap enabled by default to keep costs under control. If you want to scale beyond the plan's included quota, switch off the Spend Cap to pay for additional usage beyond the plans included limits. You can toggle the Spend Cap in the [organization's billing settings](/dashboard/org/_/billing). Read more about the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
## Fair Use Policy
#### What is the Fair Use Policy?
Our Fair Use Policy gives developers the freedom to build and experiment with Supabase, while protecting our infrastructure. Under the Fair Use policy, service restrictions may apply to your organization if:
* You continually exceed the Free Plan quota
* You continually exceed Pro Plan quota and have the spend cap enabled
* You have overdue invoices
* You have an expired credit card
You will receive a notification before Fair Use Policy restrictions are applied. However, in some cases, like suspected abuse of our services, restrictions may be applied without prior notice.
#### What is a grace period and does it reset after usage drops?
When your organization exceeds plan limits, you receive a grace period before fair use policy applies. After this grace period ends, the dashboard will continue to show a notice indicating that your grace period is over, even if you have dropped back under plan limits. This is a warning that serves as an indicator that your organization previously exceeded usage limits.
This persistent warning means that if you exceed your plan limits again, you will not receive another grace period and your project will be restricted. The notice and indicator will automatically clear if you continue to stay under plan limits for multiple billing cycles.
#### How is the Fair Use Policy applied?
The Fair Use Policy is applied through service restrictions. This could mean:
* Pausing projects
* Switching databases to read-only mode
* Disabling new project launches/transfers
* Responding with a [402 status code](/docs/guides/platform/http-status-codes#402-service-restriction) for all API requests
The Fair Use Policy is generally applied to all projects of the restricted organization.
#### How can I remove restrictions applied from the Fair Use Policy?
To remove restrictions, you will need to address the issue that caused the restriction. This could be reducing your usage, paying overdue invoices, updating your payment method, or any other issue that caused the restriction. Once the issue is resolved, the restriction will be lifted.
Restrictions due to usage limits are lifted once your quota refills at the start of the next billing cycle. Note that there may be a short delay after your billing period resets before restrictions are fully lifted. You can see when your current billing cycle ends on the [billing page](/dashboard/org/_/billing) under "Upcoming Invoice". You can also lift restrictions immediately by [upgrading](/dashboard/org/_/billing?panel=subscriptionPlan) to Pro (if on Free Plan) or by [disabling spend cap](/dashboard/org/_/billing?panel=costControl) (if on Pro Plan with spend cap enabled).
Pausing or deleting a project stops new usage from accumulating, but does not remove usage that already occurred during the current billing cycle. For quota-based limits, that usage still counts until the billing period resets.
## Reports and invoices
#### Where do I find my invoices?
You can find all invoices from your organization on your [organization’s invoices page](/dashboard/org/_/billing#invoices).
#### Where can I see a breakdown of usage?
You can find the breakdown of your usage on your [organization’s usage page](/dashboard/org/_/usage).
#### Where can I check my credit balance?
You can check your Credit balance on the [organization’s billing page](/dashboard/org/_/billing). Credits will be used on future invoices before charging your payment method. If you have enough credits to cover an invoice, there is no charge at all.
#### Can I change the details of an existing invoice?
Any changes made to your billing details will only be reflected in your upcoming invoices. Our payment provider cannot regenerate previous invoices. Therefore, make sure to update the billing details before the upcoming invoices are finalized.
## Payments and billing cycle
#### What payment methods are available?
We accept credit card payments only. If you cannot pay via credit card, we do offer alternatives for larger upfront payments. Create a [support ticket](https://supabase.help) in case you’re interested.
#### What credit card brands are supported?
Visa, Mastercard, American Express, Japan Credit Bureau (JCB), China UnionPay (CUP), Cartes Bancaires
#### What currency can I pay in?
All our invoices are issued in USD, but you can pay in any currency so long as the credit card provider allows charging in USD after conversion.
#### Can I change the payment method?
Yes, you will have to add the new payment method before being allowed to remove the old one.
This can be done from your dashboard on the [organization’s billing page](/dashboard/org/_/billing).
Read more on [Manage your payment methods](/docs/guides/platform/manage-your-subscription#manage-your-payment-methods).
#### Can I pay upfront for multiple months?
You can top up your credit balance to cover multiple months through your [organization’s billing page](/dashboard/org/_/billing).
Read more on [Credit top-ups](/docs/guides/platform/credits#credit-top-ups).
#### When are payments taken?
Payments are taken at the beginning of each billing cycle. You will be charged once a month. You can see the current billing cycle and upcoming invoice in your [organization's billing settings](/dashboard/org/_/billing). The subscription plan fee is charged upfront, whereas usage-charges, including compute, are charged in arrears based on your usage.
Read more on [Your monthly invoice](/docs/guides/platform/your-monthly-invoice).
#### Where can I change my billing details?
You can update your billing details on the [organization’s billing page](/dashboard/org/_/billing).
Note that any changes made to your billing details will only be reflected in your upcoming invoices. Our payment provider cannot regenerate previous invoices.
#### What happens if I am unable to make the payment?
When an invoice becomes overdue, we will pause your projects and downgrade your organization to the Free Plan. You will be able to restore your projects once you have paid all outstanding invoices.
#### Why am I overdue?
We were unable to charge your payment method. This likely means that the payment was not successfully processed with the credit card on your account profile.
You can be overdue when
* A card is expired
* The bank declined the payment
* You had insufficient funds
* There was no card on record
Check your payment methods in your [organization’s billing page](/dashboard/org/_/billing) to ensure there are no expired payment methods and the correct payment method is marked as default.
If you are still facing issues, raise a [support ticket](https://supabase.help).
Payments are always in USD and may show up as coming from Singapore, given our payment entity is in Singapore. Make sure you allow payments from Singapore and in USD
#### Can I delay my payment?
No, you cannot delay your payment.
#### Can I get a refund of my unused credits?
No, we do not provide refunds. Please refer to our [Terms of Service](/terms#1-fees).
#### What do I do if my bill looks wrong?
Take a moment to review our [Your monthly invoice](/docs/guides/platform/your-monthly-invoice) page, which may help clarify any questions about your invoice. If it still looks wrong, submit a [support ticket](https://supabase.help) through the dashboard. Select the affected organization and provide the invoice number for us to look at your case.
## Taxes
#### Does Supabase charge sales tax, VAT or GST?
Supabase is rolling out sales tax in applicable US states, and VAT, GST, and other indirect taxes for customers where required by law. The tax amount applied to your invoice depends on your billing address and the tax regulations in your jurisdiction.
#### Why is Supabase collecting tax now?
As a cloud services provider operating globally, Supabase is required to collect and remit indirect taxes in an increasing number of jurisdictions. We’re updating our billing practices to meet these obligations and ensure compliance with local tax regulations.
#### Will every customer be charged tax?
No. Tax is only applied in jurisdictions where Supabase is registered to collect it. If your billing address is in one of those jurisdictions, you’ll see tax applied on your invoice. If it is not, your invoices will not include tax.
#### When will customers start seeing tax on their invoices?
We are progressively rolling out tax collection across international jurisdictions. The roll out begins on May 1, 2026 and completes by June 30, 2026.
You will receive an email notification in advance of any changes to your invoicing.
#### Do I need to do anything?
For most customers, nothing changes on your end. Supabase automatically calculates the applicable tax based on the billing address associated with your organization.
There are two cases where action may be needed:
* If your organization is VAT- or GST-registered, make sure you have entered a valid Tax ID in your [organization’s billing page](/dashboard/org/_/billing#address). This allows us to apply the correct tax treatment, such as reverse charge for eligible B2B transactions.
* If your organization is tax-exempt, submit your exemption certificate to [tax-documents@supabase.io](mailto:tax-documents@supabase.io) so we can verify and apply the exemption to your organization.
#### What if my billing address is missing or incorrect?
A valid billing address is required for us to calculate the correct tax and comply with tax regulations. Make sure your billing address is up to date in your [organization’s billing page](/dashboard/org/_/billing#address) to avoid any disruption.
#### Where do I add my tax ID?
You can add or update your Tax ID directly in the Supabase Dashboard under your [organization’s billing page](/dashboard/org/_/billing#address).
Providing a valid Tax ID ensures we apply the correct tax treatment for your region. In many jurisdictions, this enables the reverse charge mechanism, where you self-assess and remit tax to your local authority instead of being charged on your Supabase invoice.
If you do not see an option for your country’s Tax ID format, please open a [support ticket](https://supabase.help) and we’ll make sure it is recorded on your account.
#### What if my organization is tax-exempt?
If your organization qualifies for a tax exemption, email your exemption certificate to [tax-documents@supabase.io](mailto:tax-documents@supabase.io).
Our team will verify the certificate and update your account accordingly. Once approved, tax will no longer be applied to your invoices.
#### How does tax appear on my invoices?
Tax is shown separately at the bottom of your invoice, clearly broken out from the cost of the products and services you’re subscribed to. This makes it easy to distinguish between your subscription costs and any applicable tax.
#### How is tax handled on prepaid credit top ups or packages?
If you purchase a prepaid top up or credit package, tax is assessed at the time of purchase, not when the credits are later consumed against usage or subscription invoices. This ensures the correct tax rate is applied based on your billing address at the time of purchase.
#### Are marketplace purchases affected?
If you use Supabase through a cloud marketplace such as AWS Marketplace or Vercel Marketplace, the marketplace provider handles tax collection and remittance. In those cases, Supabase does not separately charge tax on marketplace-billed invoices.
#### Who should I contact with questions about tax?
For questions about tax collection, exemptions, or your Tax ID, please open a [support ticket](https://supabase.help).
# About billing on Supabase
## Subscription plans
Supabase offers different subscription plans—Free, Pro, Team, and Enterprise. For a closer look at each plan's features and pricing, visit our [pricing page](/pricing).
### Free Plan
The Free Plan helps you get started and explore the platform. You are granted two free projects. The project limit applies across all organizations where you are an Owner or Administrator. This means you could have two Free Plan organizations with one project each, or one Free Plan organization with two projects. Paused projects do not count towards your free project limit.
### Paid plans
Upgrading your organization to a paid plan provides additional features, and you receive a higher [usage quota](/docs/guides/platform/billing-on-supabase#variable-usage-fees-and-quotas). You unlock the benefits of the paid plan for all projects within your organization - for example, no projects in your Pro Plan organization will be paused.
## Organization-based billing
Supabase bills separately for each organization. Each organization has its own subscription, including a unique subscription plan (Free, Pro, Team, or Enterprise), payment method, billing cycle, and invoices.
Different plans cannot be mixed within a single organization. For example, you cannot have both a Pro Plan project and a Free Plan project in the same organization. To have projects on different plans, you must create separate organizations. See [Project Transfers](/docs/guides/platform/project-transfer) if you need to move a project to a different organization.
## Costs
Monthly costs for paid plans include a fixed subscription fee based on your chosen plan and variable usage fees. To learn more about billing and cost management, refer to the following resources.
* [Your monthly invoice](/docs/guides/platform/your-monthly-invoice) - For a detailed breakdown of what a monthly invoice includes
* [Manage your usage](/docs/guides/platform/manage-your-usage) - For details on how the different usage items are billed, and how to optimize usage and reduce costs
* [Control your costs](/docs/guides/platform/cost-control) - For details on how you can control your costs in case unexpected high usage occurs
### Compute costs for projects
An organization can have multiple projects. Each project includes a dedicated Postgres instance running on its own server. You are charged for the Compute resources of that server, independent of your database usage.
Each project you launch increases your monthly Compute costs.
Read more about [Compute costs](/docs/guides/platform/manage-your-usage/compute).
## Variable Usage Fees and Quotas
Each subscription plan includes a built-in quota for some selected usage items, such as [Egress](/docs/guides/platform/manage-your-usage/egress), [Storage Size](/docs/guides/platform/manage-your-usage/storage-size), or [Edge Function Invocations](/docs/guides/platform/manage-your-usage/edge-function-invocations). This quota represents your free usage allowance. If you stay within it, you incur no extra charges for these items. Only usage beyond the quota is billed as overage.
For usage items without a quota, such as [Compute](/docs/guides/platform/manage-your-usage/compute) or [Custom Domains](/docs/guides/platform/manage-your-usage/custom-domains), you are charged for your entire usage.
The quota is applied to your entire organization, independent of how many projects you launch within that organization. For billing purposes, we sum the usage across all projects in a monthly invoice.
| Usage Item | Free | Pro/Team | Enterprise |
| -------------------------------- | ------------------------ | ------------------------------------------------------------------- | ---------- |
| Egress | 5 GB | 250 GB included, then per GB | Custom |
| Database Size | 500 MB per project | 8 GB disk per project included, then per GB | Custom |
| Monthly Active Users | 50,000 MAU | 100,000 MAU included, then per MAU | Custom |
| Monthly Active Third-Party Users | 50,000 MAU | 100,000 MAU included, then per MAU | Custom |
| Monthly Active SSO Users | Unavailable on Free Plan | 50 MAU included, then per MAU | Custom |
| Storage Size | 1 GB | 100 GB included, then per GB | Custom |
| Storage Images Transformed | Unavailable on Free Plan | 100 included, then per 1000 | Custom |
| Edge Function Invocations | 500,000 | 2 million included, then per million | Custom |
| Realtime Message Count | 2 million | 5 million included, then per million | Custom |
| Realtime Peak Connections | 200 | 500 included, then per 1000 | Custom |
You can find a detailed breakdown of all usage items and how they are billed on the [Manage your usage](/docs/guides/platform/manage-your-usage) page.
## Project add-ons
While your subscription plan applies to your entire organization and is charged only once, you can enhance individual projects by opting into various add-ons.
* [Compute](/docs/guides/platform/compute-and-disk#compute) to scale your database up to 64 cores and 256 GB RAM
* [Read Replicas](/docs/guides/platform/read-replicas) to scale read operations and provide resiliency
* [Disk](/docs/guides/platform/compute-and-disk#disk) to provision extra IOPS/throughput or use a high-performance SSD
* [Log Drains](/docs/guides/telemetry/log-drains) to sync Supabase logs to a logging system of your choice
* [Custom Domains](/docs/guides/platform/custom-domains) to provide a branded experience
* [PITR](/docs/guides/platform/backups#point-in-time-recovery) to roll back to any specific point in time, down to the minute
* [IPv4](/docs/guides/platform/ipv4-address) for a dedicated IPv4 address
* [Advanced MFA](/docs/guides/auth/auth-mfa/phone) to provide other options than TOTP
# Restore to a new project
How to clone your existing Supabase project
You can clone your Supabase project by restoring your data from an existing project into a completely new one. This process creates a database-only copy and requires manual reconfiguration to fully replicate your original project.
**What will be transferred?**
* Database schema (tables, views, procedures)
* All data and indexes
* Database roles, permissions and users
* Auth user data (user accounts, hashed passwords, and authentication records from the auth schema)
**What needs manual reconfiguration?**
* Storage objects & settings (Your S3/storage files and bucket configurations are **NOT** copied)
* Edge Functions
* Auth settings & API keys
* Realtime settings
* Database extensions and settings
* Read replicas
Whether you're using physical backups or Point-in-Time recovery (PITR), this feature allows you to duplicate project data with ease, perform testing safely, or recover data for analysis. Access to this feature is exclusive to users on paid plans and requires that physical backups are enabled for the source project.
PITR is an additional add-on available for organizations on a paid plan with physical backups enabled.
To begin, switch to the source project—the project containing the data you wish to restore—and go to the [database backups](/dashboard/project/_/database/backups/restore-to-new-project) page. Select the **Restore to a New Project** tab.
A list of available backups is displayed. Select the backup you want to use and click the "Restore" button. For projects with PITR enabled, use the date and time selector to specify the exact point in time from which you wish to restore data.
Once you’ve made your choice, Supabase takes care of the rest. A new project is automatically created, replicating key configurations from the original, including the compute instance size, disk attributes, SSL enforcement settings, and network restrictions. The data will remain in the same region as the source project to ensure compliance with data residency requirements. The entire process is fully automated.
The time required to complete the restoration can vary depending largely on the volume of data involved. If you have a large amount of data you can opt for higher performing disk attributes on the source project *before* starting a clone operation. These disk attributes will be replicated to the new project. This incurs additional costs which will be displayed before starting.
There are a few important restrictions to be aware of with the "Restore to a New Project" process:
* Projects that are created through the restoration process cannot themselves be used as a source for further clones at this time.
* The feature is only accessible to paid plan users with physical backups enabled, ensuring that the necessary resources and infrastructure are available for the restore process.
Before starting the restoration, you’ll be presented with an overview of the costs associated with creating the new project. The new project will incur additional monthly expenses based on the mirrored resources from the source project. It’s important to review these costs carefully before proceeding.
Once the restoration is complete, the new project will be available in your dashboard and will include all data, tables, schemas, and selected settings from the chosen backup source. It is recommended to thoroughly review the new project and perform any necessary tests to ensure everything has been restored as expected.
New projects are completely independent of their source, and as such can be modified and used as desired.
As the entire database is copied to the new project, this will include all extensions that were enabled at the source. If the source project included extensions that are configured to carry out external operations—for example pg\_net, pg\_cron, wrappers—these should be disabled once the copy process has completed to avoid any unwanted actions from taking place.
Restoring to a new project is an excellent way to manage environments more effectively. You can use this feature to create staging environments for testing, experiment with changes without risk to production data, or swiftly recover from unexpected data loss scenarios.
# Compute and Disk
## Compute
Every project on the Supabase Platform comes with its own dedicated Postgres instance.
The following table describes the base instances, Nano (free plan) and Micro (paid plans), with additional compute instance sizes available if you need extra performance when scaling up.
In paid organizations, Nano Compute are billed at the same price as Micro Compute. It is recommended to upgrade your Project from Nano Compute to Micro Compute when it's convenient for you. Compute sizes are not auto-upgraded because of the downtime incurred. See [Supabase Pricing](/pricing) for more information. You cannot launch Nano instances on paid plans, only Micro and above - but you might have Nano instances after upgrading from Free Plan.
| Compute Size | Hourly Price USD | Monthly Price USD | CPU | Memory | Max DB Size (Recommended)\[^2] |
| ------------ | ------------------------- | -------------------------------------------------------------------------------------------------------- | ----------------------- | ------------ | ----------------------------- |
| Nano\[^3] | | | Shared | Up to 0.5 GB | 500 MB |
| Micro | | ~ | 2-core ARM (shared) | 1 GB | 10 GB |
| Small | | ~ | 2-core ARM (shared) | 2 GB | 50 GB |
| Medium | | ~ | 2-core ARM (shared) | 4 GB | 100 GB |
| Large | | ~ | 2-core ARM (dedicated) | 8 GB | 200 GB |
| XL | | ~ | 4-core ARM (dedicated) | 16 GB | 500 GB |
| 2XL | | ~ | 8-core ARM (dedicated) | 32 GB | 1 TB |
| 4XL | | ~ | 16-core ARM (dedicated) | 64 GB | 2 TB |
| 8XL | | ~,870 | 32-core ARM (dedicated) | 128 GB | 4 TB |
| 12XL | | ~,800 | 48-core ARM (dedicated) | 192 GB | 6 TB |
| 16XL | | ~,730 | 64-core ARM (dedicated) | 256 GB | 10 TB |
| >16XL | - | [Contact Us](/dashboard/support/new?category=sales\&subject=Enquiry%20about%20larger%20instance%20sizes) | Custom | Custom | Custom |
\[^1]: Database max connections are recommended values and can be [customized via `max_connections`](/docs/guides/database/custom-postgres-config) depending on your use case. Be aware of [these considerations](/docs/guides/troubleshooting/how-to-change-max-database-connections-_BQ8P5) before modifying.
\[^2]: Database size for each compute instance is the default recommendation but the actual performance of your database has many contributing factors, including resources available to it and the size of the data contained within it. See the [shared responsibility model](/docs/guides/platform/shared-responsibility-model) for more information.
\[^3]: Compute resources on the Free plan are subject to change.
Compute sizes can be changed by first selecting your project in the dashboard [here](/dashboard/project/_/settings/compute-and-disk) and the upgrade process will [incur downtime](/docs/guides/platform/compute-and-disk#upgrades).
We charge hourly for additional compute based on your usage. Read more about [usage-based billing for compute](/docs/guides/platform/manage-your-usage/compute).
### Dedicated vs shared CPU
All Postgres databases on Supabase run in isolated environments. Compute instances smaller than `Large` compute size have CPUs which can burst to higher performance levels for short periods of time. Instances bigger than `Large` have predictable performance levels and do not exhibit the same burst behavior.
### Compute upgrades \[#upgrades]
Compute instance changes are usually applied with less than 2 minutes of downtime, but can take longer depending on the underlying Cloud Provider.
When considering compute upgrades, assess whether your bottlenecks are hardware-constrained or software-constrained. For example, you may want to look into [optimizing the number of connections](/docs/guides/platform/performance#optimizing-the-number-of-connections) or [examining query performance](/docs/guides/platform/performance#examining-query-performance). When you're happy with your Postgres instance's performance, then you can focus on additional compute resources. For example, you can load test your application in staging to understand your compute requirements. You can also start out on a smaller tier, [create a report](/dashboard/project/_/observability) in the Dashboard to monitor your CPU utilization, and upgrade as needed.
## Disk
Supabase databases are backed by high performance SSD disks. The *effective performance* depends on a combination of all the following factors:
* Compute size
* Provisioned Disk Throughput
* Provisioned Disk IOPS: Input/Output Operations per Second, which measures the number of read and write operations.
* Disk type: io2 or gp3
* Disk size
The disk size and the disk type dictate the maximum IOPS and throughput that can be provisioned. The effective IOPS is the lower of the IOPS supported by the compute size or the provisioned IOPS of the disk. Similarly, the effective throughout is the lower of the throughput supported by the compute size and the provisioned throughput of the disk.
The following sections explain how these attributes affect disk performance.
### Compute size
The compute size of your project affects the effective disk throughput and IOPS. The table below shows both the baseline (sustained) limits and the burst (maximum) limits for each instance size. For instance, an 8XL compute instance has a throughput of 1,188 MB/s and IOPS of 40,000.
Smaller compute instances like Nano, Micro, Small, and Medium can burst above baseline for short periods of time. Once burst capacity is exhausted, performance returns to baseline. If you need consistent disk performance, consider upgrading your compute size.
Larger compute instances (4XL and above) are designed for sustained, high performance with specific IOPS and throughput limits which you can [configure](/docs/guides/platform/manage-your-usage/disk-throughput). If you hit your IOPS or throughput limit, throttling will occur.
### Choosing the right compute instance for consistent disk performance
If you need consistent disk performance, choose the 4XL or larger compute instance. If you're unsure of how much throughput or IOPS your application requires, you can load test your project and inspect these [metrics in the Dashboard](/dashboard/project/_/observability). If the `Disk IO % consumed` stat is more than 1%, it indicates that your workload has exceeded the baseline IO throughput during the day. If this metric goes to 100%, the workload has used up all available disk IO budget. Projects that use any disk IO budget are good candidates for upgrading to a larger compute instance with higher throughput.
### Provisioned disk throughput and IOPS
The default disk type is gp3, which comes with a baseline throughput of 125 MB/s and a default IOPS of 3,000. You can provision additional IOPS and throughput from the [Database Settings](/dashboard/project/_/settings/compute-and-disk) page, but keep in mind that the effective IOPS and throughput will be limited by the compute instance size. This requires Large compute size or above.
Be aware that increasing IOPS or throughput incurs additional charges.
### Disk types
When selecting your disk, it's essential to focus on the performance needs of your workload. Here's a comparison of our available disk types:
| | General Purpose SSD (gp3) | High Performance SSD (io2) |
| ----------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------- |
| **Use Case** | General workloads, development environments, small to medium databases | High-performance needs, large-scale databases, mission-critical applications |
| **Max Disk Size** | 16 TB | 60 TB |
| **Max IOPS** | 16,000 IOPS (at 32 GB disk size) | 80,000 IOPS (at 80 GB disk size) |
| **Throughput** | 125 MB/s (default) to 1,000 MB/s (maximum) | Automatically scales with IOPS |
| **Best For** | Great value for most use cases | Low latency and very high IOPS requirements |
| **Pricing** | Disk: 8 GB included, then per GB
IOPS: 3,000 included, then per IOPS
Throughput: 125 MB/s included, then per MB/s | Disk: per GB
IOPS: per IOPS
Throughput: Scales with IOPS at no additional cost |
For general, day-to-day operations, gp3 should be more than enough. If you need high throughput and IOPS for critical systems, io2 will provide the performance required.
Compute instance size changes will not change your selected disk type or disk size, but your IO limits may change according to what your selected compute instance size supports.
### Disk size
* General Purpose (gp3) disks come with a baseline of 3,000 IOPS and 125 MB/s. You can provision additional 500 IOPS for every GB of disk size and additional 0.25 MB/s throughput per provisioned IOPS.
* High Performance (io2) disks can be provisioned with 1,000 IOPS per GB of disk size.
## Limits and constraints
### Postgres replication slots, WAL senders, and connections
[Replication Slots](https://postgresqlco.nf/doc/en/param/max_replication_slots) and [WAL Senders](https://postgresqlco.nf/doc/en/param/max_wal_senders/) are used to enable [Postgres Replication](/docs/guides/database/replication). Each compute instance also has limits on the maximum number of database connections and connection pooler clients it can handle.
The maximum number of replication slots, WAL senders, database connections, and pooler clients depends on your compute instance size, as follows:
| Compute instance | Max Replication Slots | Max WAL Senders | Database Max Connections\[^1] | Connection Pooler Max Clients |
| ---------------- | --------------------- | --------------- | ---------------------------- | ----------------------------- |
| Nano (free) | 5 | 5 | 60 | 200 |
| Micro | 5 | 5 | 60 | 200 |
| Small | 5 | 5 | 90 | 400 |
| Medium | 5 | 5 | 120 | 600 |
| Large | 8 | 8 | 160 | 800 |
| XL | 24 | 24 | 240 | 1,000 |
| 2XL | 80 | 80 | 380 | 1,500 |
| 4XL | 80 | 80 | 480 | 3,000 |
| 8XL | 80 | 80 | 490 | 6,000 |
| 12XL | 80 | 80 | 500 | 9,000 |
| 16XL | 80 | 80 | 500 | 12,000 |
As mentioned in the Postgres [documentation](https://postgresqlco.nf/doc/en/param/max_replication_slots/), setting `max_replication_slots` to a lower value than the current number of replication slots will prevent the server from starting. If you are downgrading your compute instance, ensure that you are using fewer slots than the maximum number of replication slots available for the new compute instance.
### Constraints
* You can modify disk attributes up to **four times** within a rolling 24-hour window. A new modification can be initiated as soon as the previous one completes. If you reach this limit, you will encounter throttling and must wait for the rolling 24-hour window to permit further adjustments.
* You can increase disk size but cannot decrease it.
# Control your costs
## Spend Cap
The Spend Cap determines whether your organization can exceed your subscription plan's quota for any usage item. Scenarios that could lead to high usage—and thus high costs—include system attacks or bugs in your software. The Spend Cap can protect you from these unexpected costs for certain usage items.
This feature is available only with the Pro Plan. However, you will not be charged while using the Free Plan.
### What happens when the Spend Cap is on?
After exceeding the quota for a usage item, further usage of that item is disallowed until the next billing cycle. You don't get charged for over-usage but your services will be restricted according to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy) if you consistently exceed the quota.
Note that only certain usage items are covered by the Spend Cap.
### What happens when the Spend Cap is off?
Your projects will continue to operate after exceeding the quota for a usage item. Any additional usage will be charged based on the item's cost per unit, as outlined on the [pricing page](/pricing).
When the Spend Cap is off, we recommend monitoring your usage and costs on the [organization's usage page](/dashboard/org/_/usage).
### Usage items covered by the Spend Cap
* [Disk Size](/docs/guides/platform/manage-your-usage/disk-size)
* [Egress](/docs/guides/platform/manage-your-usage/egress)
* [Edge Function Invocations](/docs/guides/platform/manage-your-usage/edge-function-invocations)
* [Monthly Active Users](/docs/guides/platform/manage-your-usage/monthly-active-users)
* [Monthly Active SSO Users](/docs/guides/platform/manage-your-usage/monthly-active-users-sso)
* [Monthly Active Third Party Users](/docs/guides/platform/manage-your-usage/monthly-active-users-third-party)
* [Realtime Messages](/docs/guides/platform/manage-your-usage/realtime-messages)
* [Realtime Peak Connections](/docs/guides/platform/manage-your-usage/realtime-peak-connections)
* [Storage Image Transformations](/docs/guides/platform/manage-your-usage/storage-image-transformations)
* [Storage Size](/docs/guides/platform/manage-your-usage/storage-size)
### Usage items not covered by the Spend Cap
Usage items that are predictable and explicitly opted into by the user are excluded.
* [Compute](/docs/guides/platform/manage-your-usage/compute)
* [Branching Compute](/docs/guides/platform/manage-your-usage/branching)
* [Read Replica Compute](/docs/guides/platform/manage-your-usage/read-replicas)
* [Custom Domain](/docs/guides/platform/manage-your-usage/custom-domains)
* Additionally provisioned [Disk IOPS](/docs/guides/platform/manage-your-usage/disk-iops)
* Additionally provisioned [Disk Throughput](/docs/guides/platform/manage-your-usage/disk-throughput)
* [IPv4 address](/docs/guides/platform/manage-your-usage/ipv4)
* [Log Drain Hours](/docs/guides/platform/manage-your-usage/log-drains#log-drain-hours)
* [Log Drain Events](/docs/guides/platform/manage-your-usage/log-drains#log-drain-events)
* [Multi-Factor Authentication Phone](/docs/guides/platform/manage-your-usage/advanced-mfa-phone)
* [Point-in-Time-Recovery](/docs/guides/platform/manage-your-usage/point-in-time-recovery)
### What the Spend Cap is not
The Spend Cap doesn't allow for fine-grained cost control, such as setting budgets for specific usage item or receiving notifications when certain costs are reached. We plan to make cost control more flexible in the future.
### Configure the Spend Cap
You can configure the Spend Cap when creating an organization on the Pro Plan or at any time in the Cost Control section of the [organization's billing page](/dashboard/org/_/billing).
## Keep track of your usage and costs
You can monitor your usage on the [organization's usage page](/dashboard/org/_/usage). The Upcoming Invoice section of the [organization's billing page](/dashboard/org/_/billing) shows your current spending and provides an estimate of your total costs for the billing cycle based on your usage.
# Credits
## Credit balance
Each organization has a credit balance. Credits are applied to future invoices to reduce the amount due. As long as the credit balance is greater than , credits will be used before charging your payment method on file.
You can find the credit balance on the [organization's billing page](/dashboard/org/_/billing).
### What causes the credit balance to change?
**Subscription plan downgrades:** Upon subscription downgrade, any prepaid subscription fee will be credited back to your organization for unused time in the billing cycle.\
As an example, if you start a Pro Plan subscription on January 1 and downgrade to the Free Plan on January 15, your organization will receive about 50% of the subscription fee as credits for the unused time between January 15 and January 31.
**Credit top-ups:** You self-served a credit top-up or have signed an upfront credits deal with our growth team.
## Credit top-ups
You can top up credits at any time, with a maximum of per top-up. These credits do not expire and are non-refundable. Credits are granted on the pre-tax amount. Any applicable taxes added at checkout are not credited.
You may want to consider this option to avoid issues with recurring payments, gain more control over how often your credit card is charged, and potentially make things easier for your accounting department.
If you are interested in larger (> ) credit packages, [reach out](/dashboard/support/new?subject=I%20would%20like%20to%20inquire%20about%20larger%20credit%20packages\&category=Sales).
### How to top up credits
1. On the [organization's billing page](/dashboard/org/_/billing), go to section **Credit Balance**
2. Click **Top Up**
3. Choose the amount
4. Choose a payment method or add a new payment method
5. Click **Top Up**
## Credit FAQ
{/* supa-mdx-lint-disable Rule004ExcludeWords */}
### Will I get an invoice for the credits purchase?
Yes, once the payment is confirmed, you will get a matching invoice that can be accessed through your [organization's invoices page](/dashboard/org/_/billing#invoices).
### Can I transfer credits to another organization?
Yes, you can transfer credits to another organization. Submit a [support ticket](https://supabase.help).
### Can I get a refund of my unused credits?
No, we do not provide refunds. Please refer to our [Terms of Service](/terms#1-fees).
# Custom Domains
Custom domains allow you to present a branded experience to your users. These are available as a [paid add-on for projects on a paid plan](/dashboard/project/_/settings/addons?panel=customDomain).
There are two types of domains supported by Supabase:
1. Custom domains, where you use a domain such as `api.example.com` instead of the project's default domain.
2. Vanity subdomains (experimental), where you can set up a different subdomain on `supabase.co` for your project.
You can choose either a custom domain or vanity subdomain for each project.
## Custom domains
Custom domains change the way your project's URLs appear to your users. This is useful when:
* You are using [OAuth (Social Login)](/docs/guides/auth/social-login) with Supabase Auth and the project's URL is shown on the OAuth consent screen.
* You are creating APIs for third-party systems, for example, implementing webhooks or external API calls to your project via [Edge Functions](/docs/guides/functions).
* You are storing URLs in a database or encoding them in QR codes.
Custom domains help you keep your APIs portable for the long term. By using a custom domain you can migrate from one Supabase project to another, or make it easier to version APIs in the future.
### Limitations
* Custom domains are not intended to enable hosting of frontend applications through [Edge Functions](/docs/guides/functions).
* You can only attach a single custom domain to any given Supabase project. It is not possible to break out your project's resources into multiple custom domains.
* Custom domains can only be powered by CNAME records.
### Configure a custom domain using the Supabase dashboard
Follow the **Custom Domains** steps in the [General Settings](/dashboard/project/_/settings/general) page in the Dashboard to set up a custom domain for your project.
### Configure a custom domain using the Supabase CLI
This example assumes your Supabase project is `abcdefghijklmnopqrst` with a corresponding API URL `abcdefghijklmnopqrst.supabase.co` and configures a custom domain at `api.example.com`.
To get started:
1. [Install](/docs/guides/resources/supabase-cli) the latest version of the Supabase CLI.
2. [Log in](/docs/guides/cli/local-development#log-in-to-the-supabase-cli) to your Supabase account using the CLI.
3. Ensure you have [Owner or Admin permissions](/docs/guides/platform/access-control#manage-team-members) for the project.
4. Get a custom domain from a DNS provider. Currently, only subdomains are supported.
* Use `api.example.com` instead of `example.com`.
### Add a CNAME record
You need to add a CNAME record to your domain's DNS settings to ensure your custom domain points to the Supabase project.
If your project's default domain is `abcdefghijklmnopqrst.supabase.co` you should:
* Create a CNAME record for `api.example.com` that resolves to `abcdefghijklmnopqrst.supabase.co.`.
* Use a low TTL value to quickly propagate changes in case you make a mistake.
### Verify ownership of the domain
Register your domain with Supabase to prove that you own it. You need to download two TXT records and add them to your DNS settings.
In the CLI, run [`domains create`](/docs/reference/cli/supabase-domains-create) to register the domain and Supabase and get your verification records:
```bash
supabase domains create --project-ref abcdefghijklmnopqrst --custom-hostname api.example.com
```
A single TXT records is returned. For example:
```text
[...]
Required outstanding validation records:
_acme-challenge.api.example.com. TXT -> ca3-F1HvR9i938OgVwpCFwi1jTsbhe1hvT0Ic3efPY3Q
```
Add the record to your domains' DNS settings. Make sure to trim surrounding whitespace. Use a low TTL value so you can quickly change the records if you make a mistake.
Some DNS registrars automatically append your domain name to the DNS entries being created. As such, creating a DNS record for `api.example.com` might instead create a record for `api.example.com.example.com`. In such cases, remove the domain name from the records you're creating; as an example, you would create a TXT record for `api`, instead of `api.example.com`.
### Verify your domain
Make sure you've configured all required DNS settings:
* CNAME for your custom domain pointing to the Supabase project domain.
* TXT record for `_acme-challenge.`.
Use the [`domains reverify`](/docs/reference/cli/supabase-domains-reverify) command to begin the verification process of your domain. You may need to run this command a few times because DNS records take a while to propagate.
```bash
supabase domains reverify --project-ref abcdefghijklmnopqrst
```
In the background, Supabase will check your DNS records and issue an SSL certificate. Supabase uses multiple Certificate Authorities (including Let's Encrypt, Google Trust Services and SSL.com) to ensure high availability. The specific issuer is chosen based on availability and this process can take up to 30 minutes.
### Prepare to activate your domain
Before you activate your domain, prepare your applications and integrations for the domain change:
* The project's Supabase domain remains active.
* You do not need to change the Supabase URL in your applications immediately.
* You can use it interchangeably with the custom domain.
* Supabase Auth will use the custom domain immediately once activated.
* OAuth flows will advertise the custom domain as a callback URL.
* SAML will use the custom domain instead. This means that the `EntityID` of your project has changed, and this may cause SAML with existing identity providers to stop working.
To prevent issues for your users, follow these steps:
1. For each of your Supabase OAuth providers:
* In the provider's developer console (not in the Supabase dashboard), find the OAuth application and add the custom domain Supabase Auth callback URL **in addition to the Supabase project URL.** Example:
* `https://abcdefghijklmnopqrst.supabase.co/auth/v1/callback` **and**
* `https://api.example.com/auth/v1/callback`
* [Sign in with Twitter](/docs/guides/auth/social-login/auth-twitter) uses cookies bound to the project's domain. Make sure your frontend code uses the custom domain instead of the default project's domain.
2. For each of your SAML identity providers:
* Contact your provider and ask them to update the metadata for the SAML application. They should use `https://api.example.com/auth/v1/...` instead of `https://abcdefghijklmnopqrst.supabase.co/auth/v1/sso/saml/{metadata,acs,slo}`.
* Once these changes are made, SAML Single Sign-On will likely stop working until the domain is activated. Plan for this ahead of time.
### Activate your domain
Once you've done the necessary preparations to activate the new domain for your project, you can activate it using the [`domains activate`](/docs/reference/cli/supabase-domains-activate) CLI command.
```bash
supabase domains activate --project-ref abcdefghijklmnopqrst
```
When this step completes, Supabase will serve the requests from your new domain. The Supabase project domain **continues to work** and serve requests so you do not need to rush to change client code URLs.
If you wish to use the new domain in client code, change the URL used in your Supabase client libraries:
```js
import { createClient } from '@supabase/supabase-js'
// Use a custom domain as the supabase URL
const supabase = createClient('https://api.example.com', 'sb_publishable_...')
```
Similarly, your Edge Functions will now be available at `https://api.example.com/functions/v1/your_function_name`, and your Storage objects at `https://api.example.com/storage/v1/object/public/your_file_path.ext`.
### Remove a custom domain
Removing a custom domain may cause some issues when using Supabase Auth with OAuth or SAML. You may have to reverse the changes made in the *[Prepare to activate your domain](#prepare-to-activate-your-domain)* step above.
To remove an activated custom domain you can use the [`domains delete`](/docs/reference/cli/supabase-domains-delete) CLI command.
```bash
supabase domains delete --project-ref abcdefghijklmnopqrst
```
## Vanity subdomains
Vanity subdomains allow you to present a basic branded experience, compared to custom domains. They allow you to host your services at a custom subdomain on Supabase (e.g., `my-example-brand.supabase.co`) instead of the default, randomly assigned `abcdefghijklmnopqrst.supabase.co`.
To get started:
1. [Install](/docs/guides/resources/supabase-cli) the latest version of the Supabase CLI.
2. [Log in](/docs/guides/cli/local-development#log-in-to-the-supabase-cli) to your Supabase account using the CLI.
3. Ensure that you have [Owner or Admin permissions](/docs/guides/platform/access-control#manage-team-members) for the project you'd like to set up a vanity subdomain for.
4. Ensure that your organization is on a paid plan (Pro/Team/Enterprise Plan) in the [Billing page of the Dashboard](/dashboard/org/_/billing).
### Configure a vanity subdomain
You can configure vanity subdomains via the CLI only.
Let's assume your Supabase project's domain is `abcdefghijklmnopqrst.supabase.co` and you wish to configure a vanity subdomain at `my-example-brand.supabase.co`.
### Check subdomain availability
Use the [`vanity-subdomains check-availability`](/docs/reference/cli/supabase-vanity-subdomains-check-availability) command of the CLI to check if your desired subdomain is available for use:
```bash
supabase vanity-subdomains --project-ref abcdefghijklmnopqrst check-availability --desired-subdomain my-example-brand --experimental
```
### Prepare to activate the subdomain
Before you activate your vanity subdomain, prepare your applications and integrations for the subdomain change:
* The project's Supabase domain remains active and will not go away.
* You do not need to change the Supabase URL in your applications immediately or at once.
* You can use it interchangeably with the custom domain.
* Supabase Auth will use the subdomain immediately once activated.
* OAuth flows will advertise the subdomain as a callback URL.
* SAML will use the subdomain instead. This means that the `EntityID` of your project has changed, and this may cause SAML with existing identity providers to stop working.
To prevent issues for your users, make sure you have gone through these steps:
1. Go through all of your Supabase OAuth providers:
* In the provider's developer console (not in the Supabase dashboard!), find the OAuth application and add the subdomain Supabase Auth callback URL **in addition to the Supabase project URL.** Example:
* `https://abcdefghijklmnopqrst.supabase.co/auth/v1/callback` **and**
* `https://my-example-brand.supabase.co/auth/v1/callback`
* [Sign in with Twitter](/docs/guides/auth/social-login/auth-twitter) uses cookies bound to the project's domain. In this case make sure your frontend code uses the subdomain instead of the default project's domain.
2. Go through all of your SAML identity providers:
* You will need to reach out via email to all of your existing identity providers and ask them to update the metadata for the SAML application (your project). Use `https://example-brand.supabase.co/auth/v1/...` instead of `https://abcdefghijklmnopqrst.supabase.co/auth/v1/sso/saml/{metadata,acs,slo}`.
* Once these changes are made, SAML Single Sign-On will likely stop working until the domain is activated. Plan for this ahead of time.
### Activate a subdomain
Once you've chosen an available subdomain and have done all the necessary preparations for it, you can reconfigure your Supabase project to start using it.
Use the [`vanity-subdomains activate`](/docs/reference/cli/supabase-vanity-subdomains-activate) command to activate and claim your subdomain:
```bash
supabase vanity-subdomains --project-ref abcdefghijklmnopqrst activate --desired-subdomain my-example-brand --experimental
```
If you wish to use the new domain in client code, you can set it up like so:
```js
import { createClient } from '@supabase/supabase-js'
// Use a custom domain as the supabase URL
const supabase = createClient('https://my-example-brand.supabase.co', 'sb_publishable_...')
```
When using [Sign in with Twitter](/docs/guides/auth/social-login/auth-twitter) make sure your frontend code is using the subdomain only.
### Remove a vanity subdomain
Removing a subdomain may cause some issues when using Supabase Auth with OAuth or SAML. You may have to reverse the changes made in the *[Prepare to activate the subdomain](#prepare-to-activate-the-subdomain)* step above.
Use the [`vanity-subdomains delete`](/docs/reference/cli/supabase-vanity-subdomains-delete) command of the CLI to remove the subdomain `my-example-brand.supabase.co` from your project.
```bash
supabase vanity-subdomains delete --project-ref abcdefghijklmnopqrst --experimental
```
## Pricing
For a detailed breakdown of how charges are calculated, refer to [Manage Custom Domain usage](/docs/guides/platform/manage-your-usage/custom-domains).
# Understanding Database and Disk Size
Disk metrics refer to the storage usage reported by Postgres. These metrics are updated daily. As you read through this document, we will refer to "database size" and "disk size":
* *Database size*: Displays the actual size of the data within your Postgres database. This can be found on the [Database Reports page](/dashboard/project/_/observability/database).
* *Disk size*: Shows the overall disk space usage, which includes both the database size and additional files required for Postgres to function like the Write Ahead Log (WAL) and other system log files. You can view this on the [Database Settings page](/dashboard/project/_/database/settings).
## Database size
This SQL query will show the size of all databases in your Postgres cluster:
```sql
select
pg_size_pretty(sum(pg_database_size(pg_database.datname)))
from pg_database;
```
This value is reported in the [database report page](/dashboard/project/_/observability/database).
Database size is consumed primarily by your data, indexes, and materialized views. You can reduce your database size by removing any of these and running a Vacuum operation.
Depending on your billing plan, your database can go into read-only mode which can prevent you inserting and deleting data. There are instructions for managing read-only mode in the [Disk Management](#disk-management) section.
### Disk space usage
Your database size is part of the disk usage for your Supabase project, there are many components to Postgres that consume additional disk space. One of the primary components, is the [Write Ahead Log (WAL)](https://www.postgresql.org/docs/current/wal-intro.html). Postgres will store database changes in log files that are cleared away after they are applied to the database. These same files are also used by [Read Replicas](/docs/guides/platform/read-replicas) or other replication methods.
If you would like to determine the size of the WAL files stored on disk, Postgres provides `pg_ls_waldir` as a helper function; the following query can be run:
```sql
select pg_size_pretty(sum(size)) as wal_size from pg_ls_waldir();
```
### Vacuum operations
Postgres does not immediately reclaim the physical space used by dead tuples (i.e., deleted rows) in the DB. They are marked as "removed" until a [vacuum operation](https://www.postgresql.org/docs/current/routine-vacuuming.html) is executed. As a result, deleting data from your database may not immediately reduce the reported disk usage. You can use the [Supabase CLI](/docs/guides/cli/getting-started) `inspect db bloat` command to view all dead tuples in your database. Alternatively, you can run the [query](https://github.com/supabase/cli/blob/c9cce58025fded16b4c332747f819a44f45c3b83/internal/inspect/bloat/bloat.go#L17) found in the CLI's GitHub repo in the [SQL Editor](/dashboard/project/_/sql/)
```bash
# Login to the CLI
npx supabase login
# Initialize a local supabase directory
npx supabase init
# Link a project
npx supabase link
# Detect bloat
npx supabase inspect db bloat --linked
```
If you find a table you would like to immediately clean, you can run the following in the [SQL Editor](/dashboard/project/_/sql/new):
```sql
vacuum full ;
```
Vacuum operations can temporarily increase resource utilization, which may adversely impact the observed performance of your project until the maintenance is completed. The [vacuum full](https://www.postgresql.org/docs/current/sql-vacuum.html) command will lock the table until the operation concludes.
Supabase projects have automatic vacuuming enabled, which ensures that these operations are performed regularly to keep the database healthy and performant.
It is possible to [fine-tune](https://www.percona.com/blog/2018/08/10/tuning-autovacuum-in-postgresql-and-autovacuum-internals/) the [autovacuum parameters](https://www.enterprisedb.com/blog/postgresql-vacuum-and-analyze-best-practice-tips), or [manually initiate](https://www.postgresql.org/docs/current/sql-vacuum.html) vacuum operations.
Running a manual vacuum after deleting large amounts of data from your DB could help reduce the database size reported by Postgres.
### Preoccupied space
New Supabase projects have a database size of ~40-60mb. This space includes pre-installed extensions, schemas, and default Postgres data. Additional database size is used when installing extensions, even if those extensions are inactive.
## Disk size
Supabase uses network-attached storage to balance performance with scalability. The disk scaling behavior depends on your billing plan.
### Paid plan behavior
Projects on the Pro Plan and higher have auto-scaling disks.
Disk size expands automatically when the database reaches 90% of the allocated disk size. The disk is expanded to be 50% larger (for example, 8 GB -> 12 GB).
Auto-scaling is limited to four modifications within a rolling 24-hour window. While a new modification can be initiated immediately after the previous one completes, reaching the quota of four resizes within the current rolling 24-hour window will prevent further scaling until the window allows it. If you reach 95% disk utilization and have exhausted your modification quota, your project will enter read-only mode.
The automatic resize operation will add an additional 50% capped to a maximum of 200 GB. If 50% of your current usage is more than 200 GB then only 200 GB will be added to your disk (for example a size of 1500 GB will resize to 1700 GB).
Disk size can also be manually expanded on the [Database Settings page](/dashboard/project/_/database/settings). The maximum disk size for the Pro/Team Plan is 60 TB. If you need more than this, [contact us](https://forms.supabase.com/enterprise) to learn more about the Enterprise Plan.
You may want to import a lot of data into your database which requires multiple disk expansions. for example, uploading more than 1.5x the current size of your database storage will put your database into [read-only mode](#read-only-mode). If so, it is highly recommended you increase the disk size manually on the [Database Settings page](/dashboard/project/_/database/settings).
Due to restrictions on the underlying cloud provider, disk modifications are limited to four operations within a rolling 24-hour window. While a new modification can be initiated as soon as the previous one completes, you will be unable to make further adjustments if you reach this rolling 24-hour limit until the rolling 24-hour window permits it.
### Free Plan behavior
Free Plan projects enter [read-only](#read-only-mode) mode when your **database size** exceeds 500 MB. Note that this is the *database size* limit (the size of your actual Postgres data), not the *disk size*. Free Plan projects include 1 GB of disk space, but read-only mode is triggered by the 500 MB database size quota. Once in read-only mode, you have these options:
* [Upgrade to the Pro Plan](/dashboard/org/_/billing) to increase the database size quota. [Disable the Spend Cap](https://app.supabase.com/org/_/billing?panel=costControl) if you want your Pro instance to auto-scale beyond the 8 GB disk size limit.
* [Disable read-only mode](#disabling-read-only-mode) and reduce your database size.
### Read-only mode
In some cases Supabase may put your database into read-only mode to prevent your database from exceeding the billing or disk limitations.
In read-only mode, clients will encounter errors such as `cannot execute INSERT in a read-only transaction`. Regular operation (read-write mode) is automatically re-enabled once usage is below 95% of the disk size,
### Disabling read-only mode
You manually override read-only mode to reduce disk size. To do this, run the following in the [SQL Editor](/dashboard/project/_/sql):
First, change the [transaction access mode](https://www.postgresql.org/docs/current/sql-set-transaction.html):
```sql
set session characteristics as transaction read write;
```
This allows you to delete data from within the session. After deleting data, consider running a vacuum to reclaim as much space as possible:
```sql
vacuum;
```
Once you have reclaimed space, you can run the following to disable [read-only](https://www.postgresql.org/docs/current/runtime-config-client.html#GUC-DEFAULT-TRANSACTION-READ-ONLY) mode:
```sql
set default_transaction_read_only = 'off';
```
### Disk size distribution
You can check the distribution of your disk size on your [project's compute and disk page](/dashboard/project/_/settings/compute-and-disk).
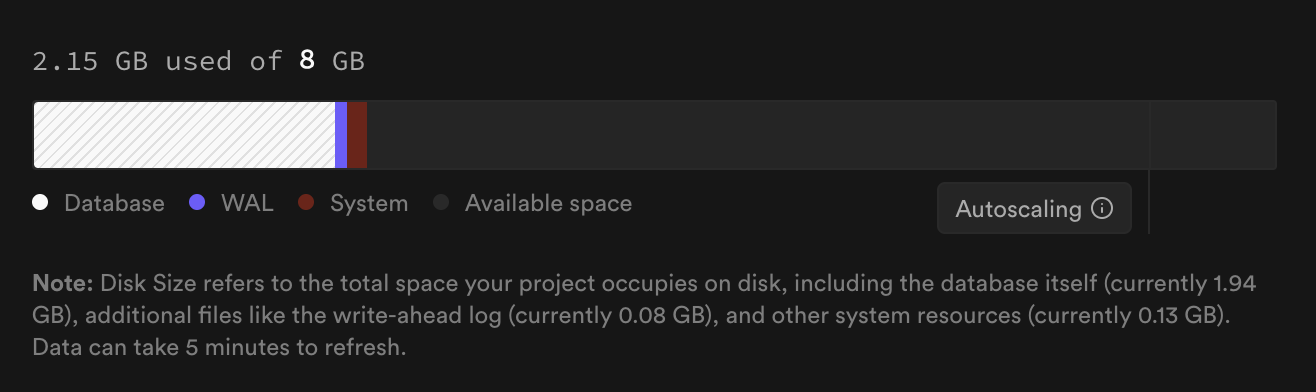
Your disk size usage falls in three categories:
* **Database** - Disk usage by the database. This includes the actual data, indexes, materialized views, ...
* **WAL** - Disk usage by the write-ahead log. The usage depends on your WAL settings and the amount of data being written to the database.
* **System** - Disk usage reserved by the system to ensure the database can operate smoothly. Users cannot modify this and it should only take very little space.
### Reducing disk size
Disks don't automatically downsize during normal operation. Once you have [reduced your database size](/docs/guides/platform/database-size#database-size), they *will* automatically "right-size" during a [project upgrade](/docs/guides/platform/upgrading). The final disk size after the upgrade is 1.2x the size of the database with a minimum of 8 GB. For example, if your database size is 100GB, and you have a 200GB disk, the size after a project upgrade will be 120 GB.
In case you have a large WAL directory, you may [modify WAL settings](/docs/guides/database/custom-postgres-config) such as `max_wal_size`. Use at your own risk as changing these settings can have side effects. To query your current WAL size, use `SELECT SUM(size) FROM pg_ls_waldir()`.
In the event that your project is already on the latest version of Postgres and cannot be upgraded, a new version of Postgres will be released approximately every week which you can then upgrade to once it becomes available.
# Get set up for billing
Correct billing settings are essential for ensuring successful payment processing and uninterrupted services. Additionally, it's important to configure all invoicing-related data early, as this information cannot be changed once an invoice is issued. Review these key points to ensure everything is set up correctly from the start.
## Payments
### Ensuring valid credit card details
Paid plans require a credit card to be on file. Ensure the correct credit card is set as active and
* has not expired
* has sufficient funds
* has a sufficient transaction limit
For more information on managing payment methods, see [Manage your payment methods](/docs/guides/platform/manage-your-subscription#manage-your-payment-methods).
### Alternatives to monthly charges
Instead of having your credit card charged every month, you can make an upfront payment by topping up your credit balance.
You may want to consider this option to avoid issues with recurring payments, gain more control over how often your credit card is charged, and potentially make things easier for your accounting department.
For more information on credits and credit top-ups, see the [Credits page](/docs/guides/platform/credits).
## Billing details
Billing details cannot be changed once an invoice is issued, so it's crucial to configure them correctly from the start.
You can update your billing email address, billing address and tax ID on the [organization's billing page](/dashboard/org/_/billing).
# HIPAA Projects
You can use Supabase to store and process Protected Health Information (PHI). If you want to start developing healthcare apps on Supabase, reach out to the Supabase team [here](https://forms.supabase.com/hipaa2) to sign the Business Associate Agreement (BAA).
Organizations must have a signed BAA with Supabase and have the Health Insurance Portability and Accountability Act (HIPAA) add-on enabled when dealing with PHI.
## Configuring a HIPAA project
When the HIPAA add-on is enabled on an organization, projects within the organization can be configured as *High Compliance*. This configuration can be found in the [General Project Settings page](/dashboard/project/_/settings) of the dashboard.
Once enabled, additional security checks will be run against the project to ensure the deployed configuration is compliant. These checks are performed on a continual basis and security warnings will appear in the [Security Advisor](/dashboard/project/_/advisors/security) if a non-compliant setting is detected.
The required project configuration is outlined in the [shared responsibility model](/docs/guides/deployment/shared-responsibility-model#managing-healthcare-data) for managing healthcare data.
These include:
* Enabling [Point in Time Recovery](/docs/guides/platform/backups#point-in-time-recovery) which requires at least a [small compute add-on](/docs/guides/platform/compute-add-ons).
* Turning on [SSL Enforcement](/docs/guides/platform/ssl-enforcement).
* Enabling [Network Restrictions](/docs/guides/platform/network-restrictions).
Additional security checks and controls will be added as the security advisor is extended and additional security controls are made available.
# Dedicated IPv4 Address for Ingress
Attach an IPv4 address to your database
The Supabase IPv4 add-on provides a dedicated IPv4 address for your Postgres database connection. It can be configured in the [Add-ons Settings](/dashboard/project/_/settings/addons).
## Understanding IP addresses
The Internet Protocol (IP) addresses devices on the internet. There are two main versions:
* **IPv4**: The older version, with a limited address space.
* **IPv6**: The newer version, offering a much larger address space and the future-proof option.
## When you need the IPv4 add-on:
IPv4 addresses are guaranteed to be static for ingress traffic. If your database is making outbound connections, the outbound IP address is not static and cannot be guaranteed.
* When using the direct connection string in an IPv6-incompatible network instead of Supavisor or client libraries.
* When you need a dedicated IP address for your direct connection string
## Enabling the IPv4 add-on
You can enable the IPv4 add-on in your project's [add-ons settings](/dashboard/project/_/settings/addons).
You can also manage the IPv4 add-on using the Management API:
```bash
# Get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
# Get current IPv4 add-on status
curl -X GET "https://api.supabase.com/v1/projects/$PROJECT_REF/billing/addons" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN"
# Enable IPv4 add-on
curl -X PATCH "https://api.supabase.com/v1/projects/$PROJECT_REF/billing/addons" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"addon_variant": "ipv4_default",
"addon_type": "ipv4"
}'
# Disable IPv4 add-on
curl -X DELETE "https://api.supabase.com/v1/projects/$PROJECT_REF/billing/addons/ipv4_default" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN"
```
Note that direct database connections can experience a short amount of downtime when toggling the add-on due to DNS reconfiguration and propagation. Generally, this should be less than a minute.
## Read replicas and IPv4 add-on
When using the add-on, each database (including read replicas) receives an IPv4 address. Each replica adds to the total IPv4 cost.
## Changes and updates
* While the IPv4 address generally remains the same, actions like pausing/unpausing the project or enabling/disabling the add-on can lead to a new IPv4 address.
## Supabase and IPv6 compatibility
By default, Supabase Postgres use IPv6 addresses. If your system doesn't support IPv6, you have the following options:
1. **Supavisor Connection Strings**: The Supavisor connection strings are IPv4-compatible alternatives to direct connections
2. **Supabase Client Libraries**: These libraries are compatible with IPv4
3. **Dedicated IPv4 Add-On (Pro Plans+)**: For a guaranteed IPv4 and static database address for the direct connection, enable this paid add-on.
### Checking your network IPv6 support
You can check if your personal network is IPv6 compatible at [https://test-ipv6.com](https://test-ipv6.com).
### Checking platforms for IPv6 support:
The majority of services are IPv6 compatible. However, there are a few prominent ones that only accept IPv4 connections:
* [Retool](https://retool.com/)
* [Vercel](https://vercel.com/)
* [GitHub Actions](https://docs.github.com/en/actions)
* [Render](https://render.com/)
## Finding your database's IP address
Use an IP lookup website or this command (replace ``):
```sh
nslookup db..supabase.co
```
## Identifying your connections
The pooler and direct connection strings can be found in the [project connect page](/dashboard/project/_?showConnect=true):
#### Direct connection
IPv6 unless IPv4 Add-On is enabled
```sh
# Example direct connection string
postgresql://postgres:[YOUR-PASSWORD]@db.ajrbwkcuthywfihaarmflo.supabase.co:5432/postgres
```
#### Supavisor in transaction mode (port 6543)
Always uses an IPv4 address
```sh
# Example transaction string
postgresql://postgres.ajrbwkcuthywddfihrmflo:[YOUR-PASSWORD]@aws-0-us-east-1.pooler.supabase.com:6543/postgres
```
#### Supavisor in session mode (port 5432)
Always uses an IPv4 address
```sh
# Example session string
postgresql://postgres.ajrbwkcuthywfddihrmflo:[YOUR-PASSWORD]@aws-0-us-east-1.pooler.supabase.com:5432/postgres
```
## Pricing
For a detailed breakdown of how charges are calculated, refer to [Manage IPv4 usage](/docs/guides/platform/manage-your-usage/ipv4).
# Manage your subscription
## Manage your subscription plan
To change your subscription plan
1. On the [organization's billing page](/dashboard/org/_/billing), go to section **Subscription Plan**
2. Click **Change subscription plan**
3. On the side panel, choose a subscription plan
4. Follow the prompts
### Upgrade
Upgrades take effect immediately. During the process, you are informed of the associated costs.
If you still have credits in your account, we will use the credits first before charging your card.
### Downgrade
Downgrades take effect immediately. During the process, you are informed of the implications.
#### Credits upon downgrade
Upon subscription downgrade, any prepaid subscription fee will be credited back to your organization for unused time in the billing cycle. These credits do not expire and will be applied to future invoices.
**Example:**
If you start a Pro Plan subscription on January 1 and downgrade to the Free Plan on January 15, your organization will receive about 50% of the subscription fee as credits for the unused time between January 15 and January 31.
As stated in our [Terms of Service](/terms#1-fees), we do not offer refunds to the payment method on file.
#### Charges on downgrade
When you downgrade from a paid plan to the Free Plan, you will get credits for the unused time on the paid plan. However, you will also be charged for any excessive usage in the billing cycle.
The plan line item (e.g. Pro Plan) gets charged upfront, whereas all usage charges get charged in arrears, as we only know your usage by the end of the billing cycle. Excessive usage is charged whenever a billing cycle resets, so either when your monthly cycle resets, or whenever you do a plan change.
If you got charged after downgrading to the Free Plan, you had excessive usage in the previous billing cycle. You can check your invoices to see what exactly you were charged for.
### Cancel subscription
To cancel your subscription, go to your [organization's billing settings](/dashboard/org/_/billing), click "Change subscription plan" and select the Free Plan. The cancellation is immediate, refer to [downgrade docs](#downgrade) for full details.
Cancellations are fully self-serve. Your Free Plan subscription will run indefinitely unless you delete the organization through your [organization's settings](/dashboard/org/_/general).
## Manage your payment methods
You can add multiple payment methods, but only one can be active at a time.
### Add a payment method
1. On the [organization's billing page](/dashboard/org/_/billing), go to section **Payment Methods**
2. Click **Add new card**
3. Provide your credit card details
4. Click **Add payment method**
### Delete a payment method
1. On the [organization's billing page](/dashboard/org/_/billing), go to section **Payment Methods**
2. In the context menu of the payment method you want to delete, click **Delete card**
3. Click **Confirm**
### Set a payment method as active
1. On the [organization's billing page](/dashboard/org/_/billing), go to section **Payment Methods**
2. In the context menu of the payment method you want to delete, click **Use this card**
3. Click **Confirm**
## Manage your billing details
You can update your billing email address, billing address and tax ID on the [organization's billing page](/dashboard/org/_/billing).
Any changes made to your billing details will only be reflected in your upcoming invoices. Our payment provider cannot regenerate previous invoices.
# Manage your usage
Each subpage breaks down a specific usage item and details what you're charged for, how costs are calculated, and how to optimize usage and reduce costs.
* [Compute](/docs/guides/platform/manage-your-usage/compute)
* [Read Replicas](/docs/guides/platform/manage-your-usage/read-replicas)
* [Branching](/docs/guides/platform/manage-your-usage/branching)
* [Egress](/docs/guides/platform/manage-your-usage/egress)
* [Disk Size](/docs/guides/platform/manage-your-usage/disk-size)
* [Disk Throughput](/docs/guides/platform/manage-your-usage/disk-throughput)
* [Disk IOPS](/docs/guides/platform/manage-your-usage/disk-iops)
* [Monthly Active Users](/docs/guides/platform/manage-your-usage/monthly-active-users)
* [Monthly Active Third-Party Users](/docs/guides/platform/manage-your-usage/monthly-active-users-third-party)
* [Monthly Active SSO Users](/docs/guides/platform/manage-your-usage/monthly-active-users-sso)
* [Storage Size](/docs/guides/platform/manage-your-usage/storage-size)
* [Storage Image Transformations](/docs/guides/platform/manage-your-usage/storage-image-transformations)
* [Edge Function Invocations](/docs/guides/platform/manage-your-usage/edge-function-invocations)
* [Realtime Messages](/docs/guides/platform/manage-your-usage/realtime-messages)
* [Realtime Peak Connections](/docs/guides/platform/manage-your-usage/realtime-peak-connections)
* [Custom Domains](/docs/guides/platform/manage-your-usage/custom-domains)
* [Point-in-Time Recovery](/docs/guides/platform/manage-your-usage/point-in-time-recovery)
* [IPv4](/docs/guides/platform/manage-your-usage/ipv4)
* [MFA Phone](/docs/guides/platform/manage-your-usage/advanced-mfa-phone)
* [Log Drains](/docs/guides/platform/manage-your-usage/log-drains)
# Migrating to Supabase
Learn how to migrate to Supabase from another database service.
## Migration guides
{(migrationPages) => (
{migrationPages.map((page) => (
))}
)}
# Migrating within Supabase
Learn how to migrate from one Supabase project to another
If you are on a Paid Plan and have physical backups enabled, you should instead use the [Restore
to another project feature](/docs/guides/platform/clone-project).
## Database migration guides
If you need to migrate from one Supabase project to another, choose the appropriate guide below:
### Backup file from the dashboard (\*.backup)
Follow the [Restore dashboard backup guide](/docs/guides/platform/migrating-within-supabase/dashboard-restore)
### SQL backup files (\*.sql)
Follow the [Backup and Restore using the CLI guide](/docs/guides/platform/migrating-within-supabase/backup-restore)
## Transfer project to a different organization
Project migration is primarily for changing regions or upgrading to new major versions of the platform in some scenarios. If you need to move your project to a different organization without touching the infrastructure, see [project transfers](/docs/guides/platform/project-transfer).
# Multi-factor Authentication
Enable multi-factor authentication (MFA) to keep your account secure.
This guide is for adding MFA to your Supabase user account. If you want to enable MFA for users in your Supabase project, refer to [**this guide**](/docs/guides/auth/auth-mfa) instead.
Multi-factor authentication (MFA) adds an additional layer of security to your user account, by requiring a second factor to verify your user identity. Supabase allows users to enable MFA on their account and set it as a requirement for subsequent logins.
## Supported authentication factors
Currently, Supabase supports adding a unique time-based one-time password (TOTP) to your user account as an additional security factor. You can manage your TOTP factor using apps such as 1Password, Authy, Google Authenticator or Apple's Keychain.
## Enable MFA
You can enable MFA for your user account under your [Supabase account settings](/dashboard/account/security). Enabling MFA will result in all other user sessions to be automatically logged out and forced to sign-in again with MFA.
Supabase does not return recovery codes. Instead, we recommend that you register a backup TOTP factor to use in an event that you lose access to your primary TOTP factor. Make sure you use a different device and app, or store the secret in a secure location different than your primary one.
For security reasons, we will not be able to restore access to your account if you lose all your two-factor authentication credentials. Do register a backup factor if necessary.
## Login with MFA
Once you've enabled MFA for your Supabase user account, you will be prompted to enter your second factor challenge code as seen in your preferred TOTP app.
If you are an organization owner and on the Pro, Team or Enterprise plan, you can enforce that all organization members [must have MFA enabled](/docs/guides/platform/mfa/org-mfa-enforcement).
## Disable MFA
You can disable MFA for your user account under your [Supabase account settings](/dashboard/account/security). On subsequent login attempts, you will not be prompted to enter an MFA code.
We strongly recommend that you do not disable MFA to avoid unauthorized access to your user account.
# Network Restrictions
If you can't find the Network Restrictions section at the bottom of your [Database Settings](/dashboard/project/_/database/settings), update your version of Postgres in the [Infrastructure Settings](/dashboard/project/_/settings/infrastructure).
Each Supabase project comes with configurable restrictions on the IP ranges that are allowed to connect to Postgres and its pooler ("your database"). These restrictions are enforced before traffic reaches your database. If a connection is not restricted by IP, it still needs to authenticate successfully with valid database credentials.
If direct connections to your database [resolve to a IPv6 address](/dashboard/project/_/database/settings), you need to add both IPv4 and IPv6 CIDRs to the list of allowed CIDRs. Network Restrictions will be applied to all database connection routes, whether pooled or direct. You will need to add both the IPv4 and IPv6 networks you want to allow. There are two exceptions: If you have been granted an extension on the IPv6 migration OR if you have purchased the [IPv4 add-on](/dashboard/project/_/settings/addons), you need only add IPv4 CIDRs.
## To get started via the Dashboard:
Network restrictions can be configured in the [Database Settings](/dashboard/project/_/database/settings) page. Ensure that you have [Owner or Admin permissions](/docs/guides/platform/access-control#manage-team-members) for the project that you are enabling network restrictions.
## To get started via the Management API:
You can also manage network restrictions using the Management API:
```bash
# Get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
# Get current network restrictions
curl -X GET "https://api.supabase.com/v1/projects/$PROJECT_REF/network-restrictions" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN"
# Update network restrictions
curl -X POST "https://api.supabase.com/v1/projects/$PROJECT_REF/network-restrictions/apply" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"db_allowed_cidrs": [
"192.168.0.1/24",
]
}'
```
## To get started via the CLI:
1. [Install](/docs/guides/cli) the Supabase CLI 1.22.0+.
2. [Log in](/docs/guides/cli/local-development#log-in-to-the-supabase-cli) to your Supabase account using the CLI.
3. If your project was created before 23rd December 2022, it will need to be [upgraded to the latest Supabase version](/docs/guides/platform/migrating-and-upgrading-projects) before Network Restrictions can be used.
4. Ensure that you have [Owner or Admin permissions](/docs/guides/platform/access-control#manage-team-members) for the project that you are enabling network restrictions.
### Check restrictions
You can use the `get` subcommand of the CLI to retrieve the restrictions currently in effect.
If restrictions have been applied, the output of the `get` command will reflect the IP ranges allowed to connect:
```bash
> supabase network-restrictions --project-ref {ref} get --experimental
DB Allowed IPv4 CIDRs: &[183.12.1.1/24]
DB Allowed IPv6 CIDRs: &[2001:db8:3333:4444:5555:6666:7777:8888/64]
Restrictions applied successfully: true
```
If restrictions have never been applied to your project, the list of allowed CIDRs will be empty, but they will also not have been applied ("Restrictions applied successfully: false"). As a result, all IPs are allowed to connect to your database:
```bash
> supabase network-restrictions --project-ref {ref} get --experimental
DB Allowed IPv4 CIDRs: []
DB Allowed IPv6 CIDRs: []
Restrictions applied successfully: false
```
### Update restrictions
The `update` subcommand is used to apply network restrictions to your project:
```bash
> supabase network-restrictions --project-ref {ref} update --db-allow-cidr 183.12.1.1/24 --db-allow-cidr 2001:db8:3333:4444:5555:6666:7777:8888/64 --experimental
DB Allowed IPv4 CIDRs: &[183.12.1.1/24]
DB Allowed IPv6 CIDRs: &[2001:db8:3333:4444:5555:6666:7777:8888/64]
Restrictions applied successfully: true
```
The restrictions specified (in the form of CIDRs) replaces any restrictions that might have been applied in the past.
To add to the existing restrictions, you must include the existing restrictions within the list of CIDRs provided to the `update` command.
### Remove restrictions
To remove all restrictions on your project, you can use the `update` subcommand with the CIDR `0.0.0.0/0`:
```bash
> supabase network-restrictions --project-ref {ref} update --db-allow-cidr 0.0.0.0/0 --db-allow-cidr ::/0 --experimental
DB Allowed IPv4 CIDRs: &[0.0.0.0/0]
DB Allowed IPv6 CIDRs: &[::/0]
Restrictions applied successfully: true
```
## Limitations
* The current iteration of Network Restrictions applies to connections to Postgres and the database pooler; it doesn't currently apply to APIs offered over HTTPS (e.g., PostgREST, Storage, and Auth). This includes using Supabase client libraries like [supabase-js](/docs/reference/javascript).
* If network restrictions are enabled, direct access to your database from Edge Functions will always be blocked. Using the Supabase client library [supabase-js](/docs/reference/javascript) is recommended to connect to a database with network restrictions from Edge Functions.
# Performance Tuning
The Supabase platform automatically optimizes your Postgres database to take advantage of the compute resources of the plan your project is on. However, these optimizations are based on assumptions about the type of workflow the project is being utilized for, and it is likely that better results can be obtained by tuning the database for your particular workflow.
## Examining query performance
Unoptimized queries are a major cause of poor database performance. To analyze the performance of your queries, see the [Debugging and monitoring guide](/docs/guides/database/inspect).
## Optimizing the number of connections
The default connection limits for Postgres and Supavisor is based on your compute size. See the default connection numbers in the [Compute Add-ons](/docs/guides/platform/compute-add-ons) section.
If the number of connections is insufficient, you will receive the following error upon connecting to the DB:
```shell
$ psql -U postgres -h ...
FATAL: remaining connection slots are reserved for non-replication superuser connections
```
In such a scenario, you can consider:
* [upgrading to a larger compute add-on](/dashboard/project/_/settings/compute-and-disk)
* configuring your clients to use fewer connections
* manually configuring the database for a higher number of connections
### Configuring clients to use fewer connections
You can use the [pg\_stat\_activity](https://www.postgresql.org/docs/current/monitoring-stats.html#MONITORING-PG-STAT-ACTIVITY-VIEW) view to debug which clients are holding open connections on your DB. `pg_stat_activity` only exposes information on direct connections to the database. Information on the number of connections to Supavisor is available [via the metrics endpoint](../platform/metrics).
Depending on the clients involved, you might be able to configure them to work with fewer connections (e.g. by imposing a limit on the maximum number of connections they're allowed to use), or shift specific workloads to connect via [Supavisor](/docs/guides/database/connecting-to-postgres#connection-pooler) instead. Transient workflows, which can quickly scale up and down in response to traffic (e.g. serverless functions), can especially benefit from using a connection pooler rather than connecting to the DB directly.
### Allowing higher number of connections
You can configure Postgres connection limit among other parameters by using [Custom Postgres Config](/docs/guides/platform/custom-postgres-config#custom-postgres-config).
### Enterprise
[Contact us](https://forms.supabase.com/enterprise) if you need help tuning your database for your specific workflow.
# Permissions
The Supabase platform offers additional services (e.g. Storage) on top of the Postgres database that comes with each project. These services default to storing their operational data within your database, to ensure that you retain complete control over it.
However, these services assume a base level of access to their data, in order to e.g. be able to run migrations over it. Breaking these assumptions runs the risk of rendering these services inoperational for your project:
* all entities under the `storage` schema are owned by `supabase_storage_admin`
* all entities under the `auth` schema are owned by `supabase_auth_admin`
It is possible for violations of these assumptions to not cause an immediate outage, but take effect at a later time when a newer migration becomes available.
# PrivateLink
PrivateLink is currently in beta and available only to Team and Enterprise customers.
Contact support if you would like to create a PrivateLink connection for a read-only replica.
PrivateLink provides enterprise-grade private network connectivity between your AWS VPC and your Supabase database using AWS VPC Lattice. This eliminates exposure to the public internet by creating a secure, private connection that keeps your database traffic within the AWS network backbone.
By enabling PrivateLink, database connections never traverse the public internet, enabling the disablement of public facing connectivity and providing an additional layer of security and compliance for sensitive workloads. This infrastructure-level security feature helps organizations meet strict data governance requirements and reduces potential attack vectors.
## How PrivateLink works
Supabase PrivateLink is an organisation level configuration. It works by sharing a [VPC Lattice Resource Configuration](https://docs.aws.amazon.com/vpc-lattice/latest/ug/resource-configuration.html) to any number of AWS Accounts for each of your Supabase projects. Connectivity can be achieved by either associating the Resource Configuration to a PrivateLink endpoint, or a [VPC Lattice Service Network](https://docs.aws.amazon.com/vpc-lattice/latest/ug/service-networks.html). This means:
* Database traffic flows through private AWS infrastructure only
* Connection latency is typically reduced compared to public internet routing
* Network isolation provides enhanced security posture
* Attack surface is minimized by eliminating public exposure
The connection architecture changes from public internet routing to a dedicated private path through AWS's secure network backbone.
Supabase PrivateLink is currently just for direct database and PgBouncer connections only. It does not support other Supabase services like API, Storage, Auth, or Realtime. These services will continue to operate over public internet connections.
## Requirements
To use PrivateLink with your Supabase project:
* Team or Enterprise Supabase subscription
* AWS VPC in the same region as your Supabase project
* Appropriate permissions to accept Resource Shares, and create and manage endpoints
## Getting started
#### Step 1: Add AWS account
Navigate to your project's Integrations section to set up PrivateLink:
1. Go to your Supabase project dashboard
2. Navigate to [**Settings** > **Integrations**](/dashboard/project/_/settings/integrations)
3. Find the **AWS PrivateLink** section
4. Click **Add Account**
5. Enter your AWS Account ID
6. Provide a description for the account (recommended)
7. Click **Add Account** to submit
After submission, Supabase creates a VPC Lattice Resource Configuration for your project and sends an AWS Resource Share to the specified AWS Account ID. This process may take a few moments. Once complete, the account will show a "Ready" status, indicating that the resource share has been sent to your AWS account and is ready to be accepted.
#### Step 2: Accept resource share
Supabase will send you an AWS Resource Share containing the VPC Lattice Resource Configurations for your projects. To accept this share:
1. Login to your AWS Management Console, ensure you are in the AWS region where your Supabase project is located
2. Navigate to the AWS Resource Access Manager (RAM) console
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
3. Go to [Shared with me > Resource shares](https://console.aws.amazon.com/ram/home#SharedResourceShares)
4. Locate the resource share from Supabase.
* The resource share has the format `sspl-[project_ref]-[random alphanumeric string]`
5. Click on the resource share name to view details. Review the list of resource shares - it should only include resources of type vpc-lattice:ResourceConfiguration.
6. Click **Accept resource share**
7. Confirm the acceptance in the dialog box
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
After accepting, you'll see the resource configurations appear in your [Shared with me > Shared resources](https://console.aws.amazon.com/ram/home#SharedResources) section of the RAM console and the [PrivateLink and Lattice > Resource configurations](https://console.aws.amazon.com/vpcconsole/home#ResourceConfigs) section of the VPC console.
#### Step 3: Configure security groups
Ensure your security groups allow traffic on the appropriate ports:
1. Navigate to the [VPC console > Security Groups](https://console.aws.amazon.com/vpcconsole/home#SecurityGroups:)
2. Create a new security group for the endpoint or service network by clicking [Create security group](https://console.aws.amazon.com/vpcconsole/home#CreateSecurityGroup:)
3. Give your security group a descriptive name and select the appropriate VPC
4. Add an inbound rule for:
* Type: Postgres (TCP, port 5432)
* Destination that is appropriate for your network. i.e. the subnet of your VPC or security group of your application instances
5. Finish creating the security group by clicking **Create security group**
#### Step 4: Create connection
In your AWS account, you have two options to establish connectivity:
##### Option A: Create a PrivateLink endpoint
1. Navigate to the VPC console in your AWS account
2. Go to [Endpoints](https://console.aws.amazon.com/vpcconsole/home#Endpoints:) in the left sidebar
3. Click [Create endpoint](https://console.aws.amazon.com/vpcconsole/home#CreateVpcEndpoint:)
4. Give your endpoint a name (e.g. `supabase-privatelink-[project name]`)
5. Under Type, select **Resources**
6. In the **Resource configurations** section select the appropriate resource configuration
* The resource configuration name will be in the format `[organisation]-[project-ref]-rc`
7. Select your VPC from the dropdown. This should match the VPC you selected for your security group in Step 3
8. Enable the **Enable DNS name** option if you want to use a DNS record instead of the endpoints IP address(es)
9. Choose the appropriate subnets for your network
* AWS will provision a private ENI for you in each selected subnet
* IP address type should be set to IPv4
10. Choose the security group you created in Step 3.
11. Click **Create endpoint**
12. After creation, you will see the endpoint in the [Endpoints](https://console.aws.amazon.com/vpcconsole/home#Endpoints:) section with a status of "Available"
13. For connectivity:
* The IP addresses of the endpoint will be listed in the **Subnets** section of the endpoint details
* The DNS record will be in the **Associations** section of the endpoint details in the **DNS Name** field if you enabled it in step 8
##### Option B: Attach resource configuration to an existing VPC lattice service network
1. **This method is only recommended if you have an existing VPC Lattice Service Network**
2. Navigate to the VPC Lattice console in your AWS account
3. Go to [Service networks](https://console.aws.amazon.com/vpcconsole/home#ServiceNetworks) in the left sidebar and select your service network
4. In the service network details, go to the **Resource configuration associations** tab
5. Click **Create associations**
6. Select the appropriate **Resource configuration** from the dropdown
7. Click **Save changes**
8. After creation, you will see the resource configuration in the Resource configurations section of your service network with the status "Active"
9. For connectivity, click on the association details and the domain name will be listed in the **DNS entries** section
#### Step 5: Test connectivity
Verify the private connection is working correctly from your VPC:
1. Launch an EC2 instance or use an existing instance within your VPC
2. Install a Postgres client (e.g., `psql`)
3. Test the connection using the private endpoint:
```bash
psql "postgresql://[username]:[password]@[private-endpoint]:5432/postgres"
```
You should see a successful connection without any public internet traffic.
#### Step 6: Update applications
Configure your applications to use the private connection details:
1. Update your database connection strings to use the private endpoint hostname
2. Ensure your application instances are in the same VPC or connected VPCs
3. Update any database connection pooling configurations
4. Test application connectivity thoroughly
Example connection string update:
```
# Before (public)
postgresql://user:pass@db.[project-ref].supabase.co:5432/postgres
# After (private)
postgresql://user:pass@your-private-endpoint.vpce.amazonaws.com:5432/postgres
```
#### Step 7: Disable public connectivity (optional)
For maximum security, you can disable public internet access for your database:
1. Contact Supabase support to disable public connectivity
2. Ensure all applications are successfully using the private connection
3. Update any monitoring or backup tools to use the private endpoint
## Beta limitations
During the beta phase:
* **Read Replicas**: To establish PrivateLink with a Read Replica, reach out to your account rep.
* **Feature Evolution**: The setup process and capabilities may evolve as we refine the offering
## Compatibility
The PrivateLink endpoint is a layer 3 solution so behaves like a standard Postgres endpoint, allowing you to connect using:
* Direct Postgres connections using standard tools
* Third-party database tools and ORMs (with the appropriate routing)
## Next steps
Ready to enhance your database security with PrivateLink? [Contact our Enterprise team](/contact/enterprise) to discuss your requirements and begin the setup process.
Our support team will guide you through the configuration and ensure your private database connectivity meets your security and performance requirements.
## Regional availability
PrivateLink is not currently available in the following regions:
* **eu-central-2 (Zurich)** - Expected availability: April 2026
# Project Transfers
You can freely transfer projects between different organizations. Head to your [projects' general settings](/dashboard/project/_/settings/general) to initiate a project transfer.
Source organization - the organization the project currently belongs to
Target organization - the organization you want to move the project to
## Pre-Requirements
* You need to be the owner of the source organization.
* You need to be at least a member of the target organization you want to move the project to.
* No active GitHub integration connection
* No project-scoped roles pointing to the project (Team/Enterprise plan)
* No log drains configured
## Usage-billing and project add-ons
For usage metrics such as disk size, egress or image transformations and project add-ons such as [Compute Add-On](/docs/guides/platform/compute-add-ons), [Point-In-Time-Recovery](/docs/guides/platform/backups#point-in-time-recovery), [IPv4](/docs/guides/platform/ipv4-address), [Log Drains](/docs/guides/platform/log-drains), [Advanced MFA](/docs/guides/auth/auth-mfa/phone) or a [Custom Domain](/docs/guides/platform/custom-domains), the source organization will still be charged for the usage up until the transfer. The charges will be added to the invoice when the billing cycle resets.
The target organization will be charged at the end of the billing cycle for usage after the project transfer.
## Things to watch out for
* Transferring a project might come with a short 1-2 minute downtime if you're moving a project from a paid to a Free Plan.
* You could lose access to certain project features depending on the plan of the target organization, i.e. moving a project from a Pro Plan to a Free Plan.
* When moving your project to a Free Plan, we also ensure you’re not exceeding your two free project limit. In these cases, it is best to upgrade your target organization to Pro Plan first.
* You could have less rights on the project depending on your role in the target organization, i.e. you were an Owner in the previous organization and only have a Read-Only role in the target organization.
## Transfer to a different region
Note that project transfers are only transferring your projects across an organization and cannot be used to transfer between different regions. To move your project to a different region, see [migrating your project](/docs/guides/platform/migrating-within-supabase).
# Read Replicas
Deploy read-only databases across multiple regions, for lower latency and better resource management.
Read Replicas are additional databases kept in sync with your Primary database. You can read your data from a Read Replica, which helps with:
* **Load balancing:** Read Replicas reduce load on the Primary database. For example, you can use a Read Replica for complex analytical queries and reserve the Primary for user-facing create, update, and delete operations.
* **Improved latency:** For projects with a global user base, additional databases can be deployed closer to users to reduce latency.
* **Redundancy:** Read Replicas provide data redundancy.
## About Read Replicas
The database you start with when launching a Supabase project is your Primary database. A process called "replication" keeps Read Replicas in sync with the Primary. Replication is asynchronous to ensure that transactions on the Primary aren't blocked. There is a delay between an update on the Primary and the time that a Read Replica receives the change. This delay is called "replication lag."
You can only read data from a Read Replica. This is in contrast to a Primary database, where you can both read and write:
| | select | insert | update | delete |
| ------------ | ------ | ------ | ------ | ------ |
| Primary | ✅ | ✅ | ✅ | ✅ |
| Read Replica | ✅ | - | - | - |
When your database starts slowing down, you face a choice: make your existing database bigger (scale vertically), or spread the load across multiple databases (scale horizontally). Both approaches work. Neither is universally correct. The right answer depends on your workload, your budget, and where the bottleneck actually is.
## Features
Read Replicas offer the following features:
### Dedicated endpoints
Each Read Replica has its own dedicated database and API endpoints.
* Find the database endpoint on the project's [**Connect** panel](/dashboard/project/_?showConnect=true). Toggle between Primary and Read Replicas using the **Source** dropdown.
* Find the API endpoint on the [API Settings page](/dashboard/project/_/settings/api) under **Project URL**. Toggle between Primary and Read Replicas using the **Source** dropdown.
If you use an [IPv4 add-on](/docs/guides/platform/ipv4-address#read-replicas), the database endpoints for your Read Replicas also use an IPv4 add-on.
Read Replicas only support `GET` requests from the [REST API](/docs/guides/api). If you are calling a read-only Postgres function through the REST API, make sure to set the `get: true` [option](/docs/reference/javascript/rpc?queryGroups=example\&example=call-a-read-only-postgres-function).
Requests to other Supabase products, such as Auth, Storage, and Realtime, aren't able to use a Read Replica or its API endpoint. Support for more products will be added in the future.
### Dedicated connection pool
A connection pool through Supavisor is also available for each Read Replica. Find the connection string on the [Database Settings page](/dashboard/project/_/database/settings) under **Connection String**.
### API load balancer
A load balancer automatically balances requests between your Primary database and Read Replicas. Find its endpoint on the [**API Settings page**](/dashboard/project/_/settings/api).
The load balancer enables geo-routing for Data API requests to automatically route `GET` requests to the database closest to your user ensuring the lowest latency. You can also send Non-`GET` requests through this endpoint, and they are routed to the Primary database automatically.
You can also interact with other Supabase services (Auth, Edge Functions, Realtime, and Storage) through this load balancer so there's no need to worry about which endpoint to use and in which situations. Geo-routing for Auth, Realtime, and Storage aren't yet available but are coming soon.
Due to the requirements of the Auth service, all Auth requests are handled by the Primary, even when sent over the load balancer endpoint. This is similar to how non-Read requests for the Data API (PostgREST) are exclusively handled by the Primary.
To call a read-only Postgres function on Read Replicas through the REST API, use the `get: true` [option](/docs/reference/javascript/rpc?queryGroups=example\&example=call-a-read-only-postgres-function).
If you remove all Read Replicas from your project, the load balancer and its endpoint are removed as well. Make sure to redirect requests back to your Primary database before removal.
From April 4th, 2025, the routing behavior for eligible Data API requests changed:
* **Old behavior**: Round-Robin distribution among all databases (all read replicas + primary) of your project, regardless of location
* **New behavior**: Geo-routing, that directs requests to the closest available database (all read replicas + primary)
The new behavior delivers a better experience for your users by minimizing the latency to your project. You can take full advantage of this by placing Read Replicas close to your major customer bases.
If you use a [custom domain](/docs/guides/platform/custom-domains), requests will not be routed through the load balancer. You should instead use the dedicated endpoints provided in the dashboard.
### Querying through the SQL editor
In the SQL editor, you can choose if you want to run the query on a particular Read Replica.
### Logging
When a Read Replica is deployed, it emits logs from the following services:
* [API](/dashboard/project/_/logs/edge-logs)
* [Postgres](/dashboard/project/_/logs/postgres-logs)
* [PostgREST](/dashboard/project/_/logs/postgrest-logs)
* [Supavisor](/dashboard/project/_/logs/pooler-logs)
Views on [Log Explorer](/docs/guides/platform/logs) are automatically filtered by databases, with the logs of the Primary database displayed by default. Viewing logs from other databases can be toggled with the `Source` button found on the upper-right part section of the Logs Explorer page.
For API logs, logs can originate from the API Load Balancer as well. The upstream database or the one that eventually handles the request can be found under the `Redirect Identifier` field. This is equivalent to `metadata.load_balancer_redirect_identifier` when querying the underlying logs.
### Metrics
Observability and metrics for Read Replicas are available on the Supabase Dashboard. Resource utilization for a specific Read Replica can be viewed on the [Database Reports page](/dashboard/project/_/observability/database) by toggling for `Source`. Likewise, metrics on API requests going through either a Read Replica or Load Balancer API endpoint are also available on the dashboard through the [API Reports page](/dashboard/project/_/observability/api-overview)
We recommend ingesting your [project's metrics](/docs/guides/platform/metrics#accessing-the-metrics-endpoint) into your own environment. If you have an existing ingestion pipeline set up for your project, you can [update it](https://github.com/supabase/supabase-grafana?tab=readme-ov-file#read-replica-support) to additionally ingest metrics from your Read Replicas.
### Centralized configuration management
All settings configured through the dashboard will be propagated across all databases of a project. This ensures that no Read Replica get out of sync with the Primary database or with other Read Replicas.
## Pricing
For a detailed breakdown of how we calculate charges, read the [Manage Read Replica usage guide](/docs/guides/platform/manage-your-usage/read-replicas).
# Available regions
Each Supabase project is deployed to one primary region. Choose the location closest to your users for the best performance.
## General regions
For most projects, we recommend choosing a general region. Supabase will deploy your project to an available AWS region within that area based on current infrastructure capacity.
Note: General regions aren’t yet supported for read replicas or management via the API.
## Specific regions
If you prefer, you can choose an exact AWS region for your project.
# Postgres SSL Enforcement
Your Supabase project supports connecting to the Postgres DB without SSL enabled to maximize client compatibility. For increased security, you can prevent clients from connecting if they're not using SSL.
Disabling SSL enforcement only applies to connections to Postgres and Supavisor ("Connection Pooler"); all HTTP APIs offered by Supabase (e.g., PostgREST, Storage, Auth) automatically enforce SSL on all incoming connections.
Applying or updating SSL enforcement triggers a fast database reboot. On small projects this usually completes in a few seconds, but larger databases may see a longer interruption.
## Manage SSL enforcement via the dashboard
SSL enforcement can be configured via the "Enforce SSL on incoming connections" setting under the SSL Configuration section in [Database Settings page](/dashboard/project/_/database/settings) of the dashboard.
Updating SSL enforcement requires a brief database reboot. This restarts only the database and involves a few minutes of downtime.
## Manage SSL enforcement via the Management API
You can also manage SSL enforcement using the Management API:
```bash
# Get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
# Get current SSL enforcement status
curl -X GET "https://api.supabase.com/v1/projects/$PROJECT_REF/ssl-enforcement" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN"
# Enable SSL enforcement
curl -X PUT "https://api.supabase.com/v1/projects/$PROJECT_REF/ssl-enforcement" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"requestedConfig": {
"database": true
}
}'
# Disable SSL enforcement
curl -X PUT "https://api.supabase.com/v1/projects/$PROJECT_REF/ssl-enforcement" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"requestedConfig": {
"database": false
}
}'
```
## Manage SSL enforcement via the CLI
To get started:
1. [Install](/docs/guides/cli) the Supabase CLI 1.37.0+.
2. [Log in](/docs/guides/getting-started/local-development#log-in-to-the-supabase-cli) to your Supabase account using the CLI.
3. Ensure that you have [Owner or Admin permissions](/docs/guides/platform/access-control#manage-team-members) for the project that you are enabling SSL enforcement.
### Check enforcement status
You can use the `get` subcommand of the CLI to check whether SSL is currently being enforced:
```bash
supabase ssl-enforcement --project-ref {ref} get --experimental
```
Response if SSL is being enforced:
```bash
SSL is being enforced.
```
Response if SSL is not being enforced:
```bash
SSL is *NOT* being enforced.
```
### Update enforcement
The `update` subcommand is used to change the SSL enforcement status for your project:
```bash
supabase ssl-enforcement --project-ref {ref} update --enable-db-ssl-enforcement --experimental
```
Similarly, to disable SSL enforcement:
```bash
supabase ssl-enforcement --project-ref {ref} update --disable-db-ssl-enforcement --experimental
```
### A note about Postgres SSL modes
Postgres supports [multiple SSL modes](https://www.postgresql.org/docs/current/libpq-ssl.html#LIBPQ-SSL-PROTECTION) on the client side. These modes provide different levels of protection. Depending on your needs, it is important to verify that the SSL mode in use is performing the required level of enforcement and verification of SSL connections.
| SSL Mode | Encryption | Verifies CA | Verifies Hostname | Description |
| ------------- | ---------- | ----------- | ----------------- | -------------------------------------------------------------------------------------------------------------------------------------- |
| `disable` | No | No | No | SSL is not used. All data is transmitted in plaintext. |
| `allow` | Optional | No | No | Tries a non-SSL connection first; falls back to SSL if the server requires it. |
| `prefer` | Optional | No | No | Tries an SSL connection first; falls back to non-SSL if the server doesn't support it. This is the default. |
| `require` | Yes | No | No | Always uses SSL, but does not verify the server certificate or hostname. |
| `verify-ca` | Yes | Yes | No | Uses SSL and verifies that the server certificate is signed by a trusted CA. |
| `verify-full` | Yes | Yes | Yes | Uses SSL, verifies the CA certificate, and confirms the hostname matches the certificate. Recommended when SSL enforcement is enabled. |
The strongest mode offered by Postgres is `verify-full` and this is the mode you most likely want to use when SSL enforcement is enabled. To use `verify-full` you will need to download the Supabase CA certificate for your database. The certificate is available through the dashboard under the SSL Configuration section in the [Database Settings page](/dashboard/project/_/database/settings).
Once the CA certificate has been downloaded, add it to the certificate authority list used by Postgres.
```bash
cat {location of downloaded prod-ca-2021.crt} >> ~/.postgres/root.crt
```
With the CA certificate added to the trusted certificate authorities list, use `psql` or your client library to connect to Supabase:
```bash
psql "postgresql://aws-0-eu-central-1.pooler.supabase.com:6543/postgres?sslmode=verify-full" -U postgres.
```
# Enable SSO for Your Organization
Looking for docs on how to add Single Sign-On support in your Supabase project? Head on over to [Single Sign-On with SAML 2.0 for Projects](/docs/guides/auth/enterprise-sso/auth-sso-saml).
Supabase offers single sign-on (SSO) as a login option to provide additional account security for your team. This allows company administrators to enforce the use of an identity provider when logging into Supabase. SSO improves the onboarding and offboarding experience of the company as the employee only needs a single set of credentials to access third-party applications or tools which can also be revoked by an administrator.
Supabase currently provides SAML SSO for [Team and Enterprise Plan customers](/pricing). If you are an existing Team or Enterprise Plan customer, continue with the setup below.
## Supported providers
Supabase supports practically all identity providers (IdP) that support the SAML 2.0 SSO protocol. These guides cover commonly used identity providers to help you get started. If you use a different provider, contact support.
* [Google Workspaces (formerly G Suite)](/docs/guides/platform/sso/gsuite)
* [Azure Active Directory](/docs/guides/platform/sso/azure)
* [Okta](/docs/guides/platform/sso/okta)
Once configured, you can update your settings anytime from [the **SSO** section](/dashboard/org/_/sso) of the dashboard under **Organization Settings**.
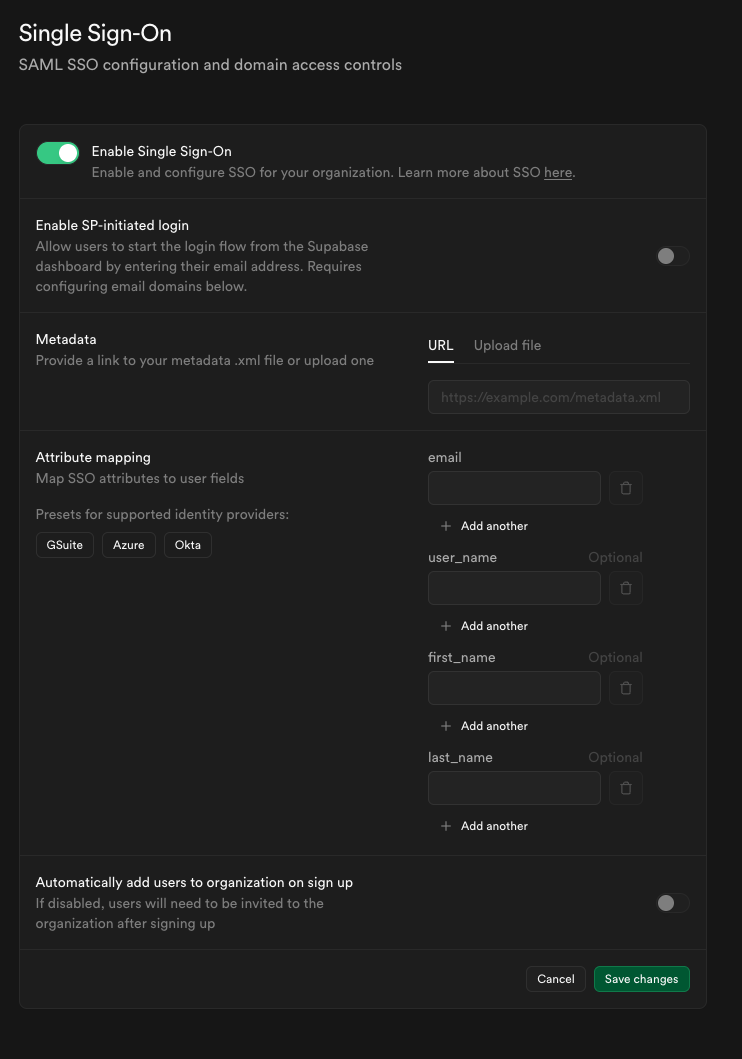
After configuring your SSO provider, thorough testing is essential. See our [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices) guide for:
* Step-by-step testing instructions
* Troubleshooting common issues
* Security best practices
* Pre-launch checklist
## Choosing your login flow
Supabase supports two SSO login flows: **IdP-initiated** and **SP-initiated**. You can enable one or both depending on your organization's needs.
### IdP-initiated login (recommended)
Users start their login from your identity provider (Okta, Azure AD, Google Workspace) by clicking an app tile or bookmark. This is the **simplest and most common configuration** - it requires no domain configuration and works automatically once SSO is enabled.
**Best for:**
* Organizations with established IdP workflows
* Multiple SAML apps per domain (Dev, Staging, Prod)
* Simplest user experience
### SP-initiated login
Users start their login at supabase.com by entering their email address, then are redirected to your identity provider. This flow requires configuring email domains to route users to the correct IdP.
**Best for:**
* Users who bookmark supabase.com directly
* Organizations migrating from password authentication
* Supporting domain-based automatic IdP routing
### Need help choosing?
* **Quick decision:** Start with IdP-initiated only (the default). It works for 90% of use cases.
* **Detailed guidance:** See [Choosing the Right Login Flow](/docs/guides/platform/sso/choosing-login-flow) for scenario-based recommendations.
* **Technical details:** Read [Understanding SSO Login Flows](/docs/guides/platform/sso/login-flows) for in-depth explanations.
## Key configuration options
* **Login flows** - Choose between IdP-initiated (users start from identity provider), SP-initiated (users start at supabase.com), or both. IdP-initiated is recommended for most organizations and requires no domain configuration. See [Choosing the Right Login Flow](/docs/guides/platform/sso/choosing-login-flow) for guidance.
* **Email domains** - Required only if you enable SP-initiated login. You can associate one or more email domains with your SSO provider. Users with matching email addresses can sign in via SSO at supabase.com. Not required for IdP-initiated flow.
* **Auto-join** - Optionally allow users with a matching domain to be added to your organization automatically when they sign in via SSO. Auto-join applies on every login, not just first signup, making it easy to test before enabling.
* **Default role for auto-joined users** - Choose the role (e.g., `Read-only`, `Developer`, `Administrator`, `Owner`) that automatically joined users receive. We recommend using `Developer` as the default (principle of least privilege) and promoting users individually as needed. Refer to [access control](/docs/guides/platform/access-control) for more information about roles.
* **Invitation types** - When inviting users to your organization, you can explicitly choose whether the invitation requires SSO authentication or allows non-SSO login (password/social). This enables mixed authentication organizations with both SSO and non-SSO users.
## How SSO works in Supabase
When SSO is enabled for an organization:
* Organization invites are restricted to company members belonging to the same identity provider.
* Every user has an organization created by default. They can create as many projects as they want.
* An SSO user will not be able to update or reset their password since the company administrator manages their access via the identity provider.
* If an SSO user with the following email of `alice@foocorp.com` attempts to sign in with a GitHub account that uses the same email, a separate Supabase account is created and will not be linked to the SSO user's account.
* SSO users will only see organizations/projects they've been invited to or auto-joined into. See [access control](/docs/guides/platform/access-control) for more details.
## Enabling SSO for an organization
**Recommended workflow:**
1. Create or verify at least one non-SSO owner account exists (required for safety)
2. Configure your SSO provider following one of our [provider-specific guides](#supported-providers)
3. Start with auto-join **disabled** to test the configuration
4. Test SSO login with your own account
5. Once confirmed working, enable auto-join if desired
6. Thoroughly test using our [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices) guide
7. Invite users to the organization or let them auto-join on login
If a user is already a member of the organization under a non-SSO account, they will need to be removed and invited again with an SSO-required invitation to join under their SSO account. SSO and non-SSO accounts with the same email are treated as separate accounts.
Each user account verified using a SSO identity provider will not be automatically linked to existing user accounts in the system. That is, if a user `valid.email@supabase.io` had signed up with a password, and then uses their company SSO login with your project, there will be two `valid.email@supabase.io` user accounts in the system.
Users will need to ensure they are logged in with the correct account when accepting invites or accessing organizations/projects.
## Disabling SSO for an organization
If you disable or delete the SSO provider for an organization, **all SSO users will immediately be unable to sign in**.
The system requires at least one non-SSO owner account before allowing SSO provider deletion. This prevents complete organization lockout. When you delete an SSO provider, all SSO members are automatically removed from the organization.
Before disabling or deleting SSO:
* Verify a non-SSO owner account exists and can log in
* Communicate to affected users in advance
* Consider whether disabling is better than deleting if the change is temporary
## Removing an individual SSO user's access
To revoke access for a specific SSO user without disabling the provider entirely you may:
* Remove or disable the user's account in your identity provider
* Downgrade or remove their permissions for any organizations in Supabase.
## Testing and best practices
Before rolling out SSO to your organization, we strongly recommend thorough testing and following security best practices. Our comprehensive guide covers:
* Step-by-step testing procedures for SSO login, auto-join, and invitations
* Troubleshooting common issues (many of which previously required support intervention)
* Security best practices including certificate monitoring and domain configuration
* Operational guidance for making SSO changes safely
* Pre-launch verification checklist
Visit the [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices) guide for complete details.
## Advanced scenarios
Most organizations use a single SSO provider for all users. However, Supabase supports multiple SSO providers within an organization for advanced use cases such as:
* Separate providers for development, staging, and production environments
* Different providers for different teams or business units
* Gradual migration from one identity provider to another
If you need to configure multiple SSO providers, refer to the [Multiple SSO Providers](/docs/guides/platform/sso/multiple-providers) guide for detailed configuration steps, and contact your Supabase support representative if you need additional guidance.
# Upgrading
Supabase ships fast and we endeavor to add all new features to existing projects wherever possible. In some cases, access to new features require upgrading or migrating your Supabase project.
This guide refers to upgrading the Postgres version of your Supabase Project. For scaling your compute size, refer to the [Compute and Disk page](/docs/guides/platform/compute-and-disk).
You can upgrade your project using in-place upgrades or by pausing and restoring your project.
## In-place upgrades
For security purposes, passwords for custom roles are not backed up and, following a restore, they would need to be reset. See [here](/docs/guides/platform/backups#daily-backups) for more details
In-place upgrades uses `pg_upgrade`. For projects larger than 1GB, this method is generally faster than a pause and restore cycle, and the speed advantage grows with the size of the database.
1. Plan for an appropriate downtime window, and ensure you have reviewed the [caveats](#caveats) section of this document before executing the upgrade.
2. Use the "Upgrade project" button on the [Infrastructure](/dashboard/project/_/settings/infrastructure) section of your dashboard.
Additionally, if the upgrade should fail, your original database would be brought back up online and be able to service requests.
As a rough rule of thumb, pg\_upgrade operates at ~100MBps (when executing an upgrade on your data). Using the size of your database, you can use this metric to derive an approximate sense of the downtime window necessary for the upgrade. During this window, you should plan for your database and associated services to be unavailable.
## Pause and restore
We recommend using the In-place upgrade method, as it is faster, and more reliable. Additionally, only Free-tier projects are eligible to use the Pause and Restore method.
When you pause and restore a project, the restored database includes the latest features. **This method includes downtime**, so be aware that your project will be inaccessible for a short period of time.
1. On the [General Settings](/dashboard/project/_/settings/general) page in the Dashboard, click **Pause project**. You will be redirected to the home screen in the meantime.
2. After this, click **Restore project**. Your project will be restored from the [physical backup](/guides/platform/backups). You should receive an email once the restoration is complete.
Pausing and restoring project will take some time depending on how much data your database has. If the restore process fails, [contact Supabase support](/dashboard/support/new?projectRef=) to bring your project back online.
## Caveats
Regardless of the upgrade method, a few caveats apply:
### Logical replication
If you are using logical replication, the replication slots will not be preserved by the upgrade process. You will need to manually recreate them after the upgrade with the method `pg_create_logical_replication_slot`. Refer to the Postgres docs on [Replication Management Functions](https://www.postgresql.org/docs/current/functions-admin.html#FUNCTIONS-REPLICATION) for more details about the method.
### Breaking changes
Newer versions of services can break functionality or change the performance characteristics you rely on. If your project is eligible for an upgrade, you will be able to find your current service versions from within [the Supabase dashboard](/dashboard/project/_/settings/infrastructure).
Breaking changes are generally only present in major version upgrades of Postgres and PostgREST. You can find their respective release notes at:
* [Postgres](https://www.postgresql.org/docs/release/)
* [PostgREST](https://github.com/PostgREST/postgrest/releases)
If you are upgrading from a significantly older version, you will need to consider the release notes for any intermediary releases as well.
### Time limits
Starting from 2024-06-24, when a project is paused, users then have a 90-day window to restore the project on the platform from within Supabase Studio.
The 90-day window allows Supabase to introduce platform changes that may not be backwards compatible with older backups. Unlike active projects, static backups can't be updated to accommodate such changes.
During the 90-day restore window a paused project can be restored to the platform with a single button click from [Studio's dashboard page](/dashboard/projects).
After the 90-day restore window, you can download your project's backup file, and Storage objects from the project dashboard. You can restore the data in the following ways:
* [Restore a backup to a new Supabase project](/docs/guides/platform/migrating-within-supabase/dashboard-restore)
* [Restore a backup locally](/docs/guides/local-development/restoring-downloaded-backup)
If you upgrade to a paid plan while your project is paused within the 90-day restore window, any expired one-click restore options are reenabled. Since the backup was taken outside the backwards compatibility window, it may fail to restore. If you have a problem restoring your backup after upgrading, contact [Support](/support).
### Disk sizing
When upgrading, the Supabase platform will "right-size" your disk based on the current size of the database. For example, if your database is 100GB in size, and you have a 200GB disk, the upgrade will reduce the disk size to 120GB (1.2x the size of your database).
### Objects dependent on Postgres extensions
In-place upgrades do not support upgrading of databases containing reg\* data types referencing system OIDs.
If you have created any objects that depend on the following extensions, you will need to recreate them after the upgrade.
### `pg_cron` records
[pg\_cron](https://github.com/citusdata/pg_cron#viewing-job-run-details) does not automatically clean up historical records. This can lead to extremely large `cron.job_run_details` tables if the records are not regularly pruned; you should clean unnecessary records from this table prior to an upgrade.
During an in-place upgrade, the `pg_cron` extension gets dropped and recreated. Prior to this process, the `cron.job_run_details` table is duplicated to avoid losing historical logs. The instantaneous disk pressure created by duplicating an extremely large details table can cause at best unnecessary performance degradation, or at worst, upgrade process failures.
### Extensions
In-place upgrades do not currently support upgrading of databases using extensions older than the following versions:
* TimescaleDB 2.16.1
* plv8 3.1.10
To upgrade to a newer version of Postgres, you will need to drop the extensions before the upgrade, and recreate them after the upgrade.
#### Authentication method changes - deprecating md5 in favor of scram-sha-256
The md5 hashing method has [known weaknesses](https://en.wikipedia.org/wiki/MD5#Security) that make it unsuitable for cryptography.
As such, we are deprecating md5 in favor of [scram-sha-256](https://www.postgresql.org/docs/current/auth-password.html), which is the default and most secure authentication method used in the latest Postgres versions.
We automatically migrate Supabase-managed roles' passwords to scram-sha-256 during the upgrade process, but you will need to manually migrate the passwords of any custom roles you have created, else you won't be able to connect using them after the upgrade.
To identify roles using the md5 hashing method and migrate their passwords, you can use the following SQL statements after the upgrade:
```sql
-- List roles using md5 hashing method
SELECT
rolname
FROM pg_authid
WHERE rolcanlogin = true
AND rolpassword LIKE 'md5%';
-- Migrate a role's password to scram-sha-256
ALTER ROLE WITH PASSWORD '';
```
### Database size reduction
As part of the upgrade process, maintenance operations such as [vacuuming](https://www.postgresql.org/docs/current/routine-vacuuming.html#ROUTINE-VACUUMING) are also executed. This can result in a reduction in the reported database size.
### Post-upgrade validation
Supabase performs extensive pre- and post-upgrade validations to ensure that the database has been correctly upgraded. However, you should plan for your own application-level validations, as there might be changes you might not have anticipated, and this should be budgeted for when planning your downtime window.
## Specific upgrade notes
### Upgrading to Postgres 17
In projects using Postgres 17, the following extensions are deprecated:
* `plcoffee`
* `plls`
* `plv8`
* `timescaledb`
* `pgjwt`
Projects planning to upgrade from Postgres 15 to Postgres 17 need to first disable these extensions in the [Supabase Dashboard](/dashboard/project/_/database/extensions).
`pgjwt` was enabled by default on every Supabase project up until Postgres 17. If you weren’t explicitly using `pgjwt` in your project, it’s most likely safe to disable.
Existing projects on lower versions of Postgres are not impacted, and the extensions will continue to be supported on projects using Postgres 15, until the end of life of Postgres 15 on the Supabase platform.
# Your monthly invoice
## Billing cycle
When you sign up for a paid plan you get charged once a month at the beginning of the billing cycle. A billing cycle starts with the creation of a Supabase organization. If you create an organization on the sixth of January your billing cycle resets on the sixth of each month. If the anchored day is not present in the current month, then the last day of the month is used.
## Your invoice explained
When your billing cycle resets an invoice gets issued. That invoice contains line items from both the current and the previous billing cycle. Fixed fees for the current billing cycle, usage based fees for the previous billing cycle.
### Fixed fees
Fixed fees are independent of usage and paid in-advance. Whether you have one or several projects, hundreds or millions of active users, the fee is always the same, and doesn't vary. Examples are the subscription fee, the fee for HIPAA and for priority support.
### Usage based fees
Fees vary depending on usage and are paid in arrears. The more usage you have, the higher the fee. Examples are fees for monthly active users and storage size.
### Discounted line items
Paid plans come with a usage quota for certain line items. You only pay for usage that goes beyond the quota. The quota for Storage for example is 100 GB. If you use 105 GB, you pay for 5 GB. If you use 95 GB, you pay nothing. This quota is declared as a discount on your invoice.
#### Compute Credits
Paid plans come with in Compute Credits per month. This suffices for a single project using a Nano or Micro compute instance. Every additional project adds compute fees to your monthly invoice though.
### Example invoice
The following invoice was issued on January 6, 2025 with the previous billing cycle from December 6, 2024 - January 5, 2025, and the current billing cycle from January 6 - February 5, 2025.
1. The final amount due
2. Fixed subscription fee for the current billing cycle
3. Usage based fee for Compute for the previous billing cycle. There were two projects (`wsmmedyqtlrvbcesxdew`, `wwxdpovgtfcmcnxwsaad`) running 744 hours (24 hours \* 31 days). These projects incurred in Compute fees each. With in Compute Credits deducted, the final Compute fees are
4. Usage based fee for Custom Domain for the previous billing cycle. There is no free usage quota for Custom Domain. You get charged for the 744 hours (24 hours \* 31 days) a Custom Domain was active. The final Custom Domain fees are .
5. Usage based fee for Egress for the previous billing cycle. There is a free usage quota of 250 GB for Egress. You get charged for usage beyond 250 GB only, meaning for 2,119.47 GB. The final Egress fees are .
6. Usage based fee for Monthly Active Users for the previous billing cycle. There is a free usage quota of 100,000 users. With 141 users there is no charge for this line item.
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
### Why is my invoice more than ?
The amount due of your invoice being higher than the subscription fee for the Pro Plan can have several reasons.
* **Running several projects:** You had more than one project running in the previous billing cycle. Supabase provides a dedicated server and database for every project. That means that every project you launch incurs compute costs. While the Compute Credits cover a single project using a Nano or Micro compute instance, every additional project adds at least compute costs to your invoice.
* **Usage beyond quota:** You exceeded the included usage quota for one or more line items in the previous billing cycle while having the Spend Cap disabled.
* **Usage that is not covered by the Spend Cap:** You had usage in the previous billing cycle that is not covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap). For example using an IPv4 address or a custom domain.
## How to settle your invoices
Monthly invoices are auto-collected by charging the payment method marked as "active" for an organization.
### Payment failure
If your payment fails, Supabase retries the charge several times. We send you a Payment Failure email with the reason for the failure. Follow the steps outlined in this email. You can manually trigger a charge at any time via
* the link in the Payment Failure email
* the "Pay now" button on the [organization's invoices page](/dashboard/org/_/billing#invoices)
## Where to find your invoices
Your invoice is sent to you via email. You can also find your invoices on the [organization's invoices page](/dashboard/org/_/billing#invoices).
# Set Up SSO with Azure AD
This feature is only available on the [Team and Enterprise Plans](/pricing). If you are an existing Team or Enterprise Plan customer, continue with the setup below.
Looking for docs on how to add Single Sign-On support in your Supabase project? Head on over to [Single Sign-On with SAML 2.0 for Projects](/docs/guides/auth/enterprise-sso/auth-sso-saml).
Supabase supports single sign-on (SSO) using Microsoft Azure AD.
## Step 1: Add and register an Enterprise application \[#add-and-register-enterprise-application]
Open up the [Azure Active Directory](https://portal.azure.com/#view/Microsoft_AAD_IAM/ActiveDirectoryMenuBlade/~/Overview) dashboard for your Azure account.
Click the *Add* button then *Enterprise application*.
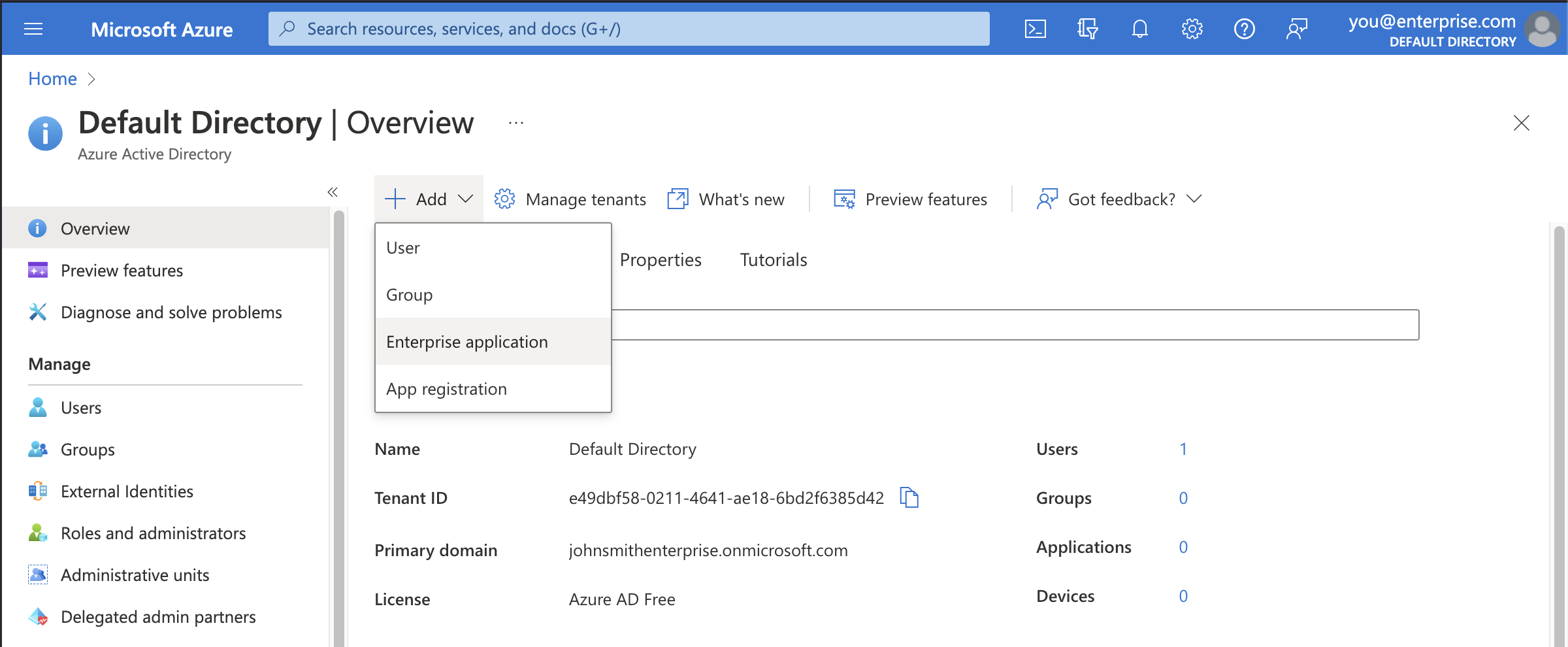
## Step 2: Choose to create your own application \[#create-application]
You'll be using the custom enterprise application setup for Supabase.
## Step 3: Fill in application details \[#add-application-details]
In the modal titled *Create your own application*, enter a display name for Supabase. This is the name your Azure AD users will see when signing in to Supabase from Azure. `Supabase` works in most cases.
Make sure to choose the third option: *Integrate any other application you
don't find in the gallery (Non-gallery)*.
## Step 4: Set up single sign-on \[#set-up-single-sign-on]
Before you get to assigning users and groups, which would allow accounts in Azure AD to access Supabase, you need to configure the SAML details that allows Supabase to accept sign in requests from Azure AD.
## Step 5: Select SAML single sign-on method \[#saml-sso]
Supabase only supports the SAML 2.0 protocol for Single Sign-On, which is an industry standard.
## Step 6: Upload SAML-based sign-on metadata file \[#upload-saml-metadata]
First you need to download Supabase's SAML metadata file. Click the button below to initiate a download of the file.
}>
Download Supabase SAML Metadata File
Alternatively, visit this page to initiate a download: `https://alt.supabase.io/auth/v1/sso/saml/metadata?download=true`
Click on the *Upload metadata file* option in the toolbar and select the file you just downloaded.
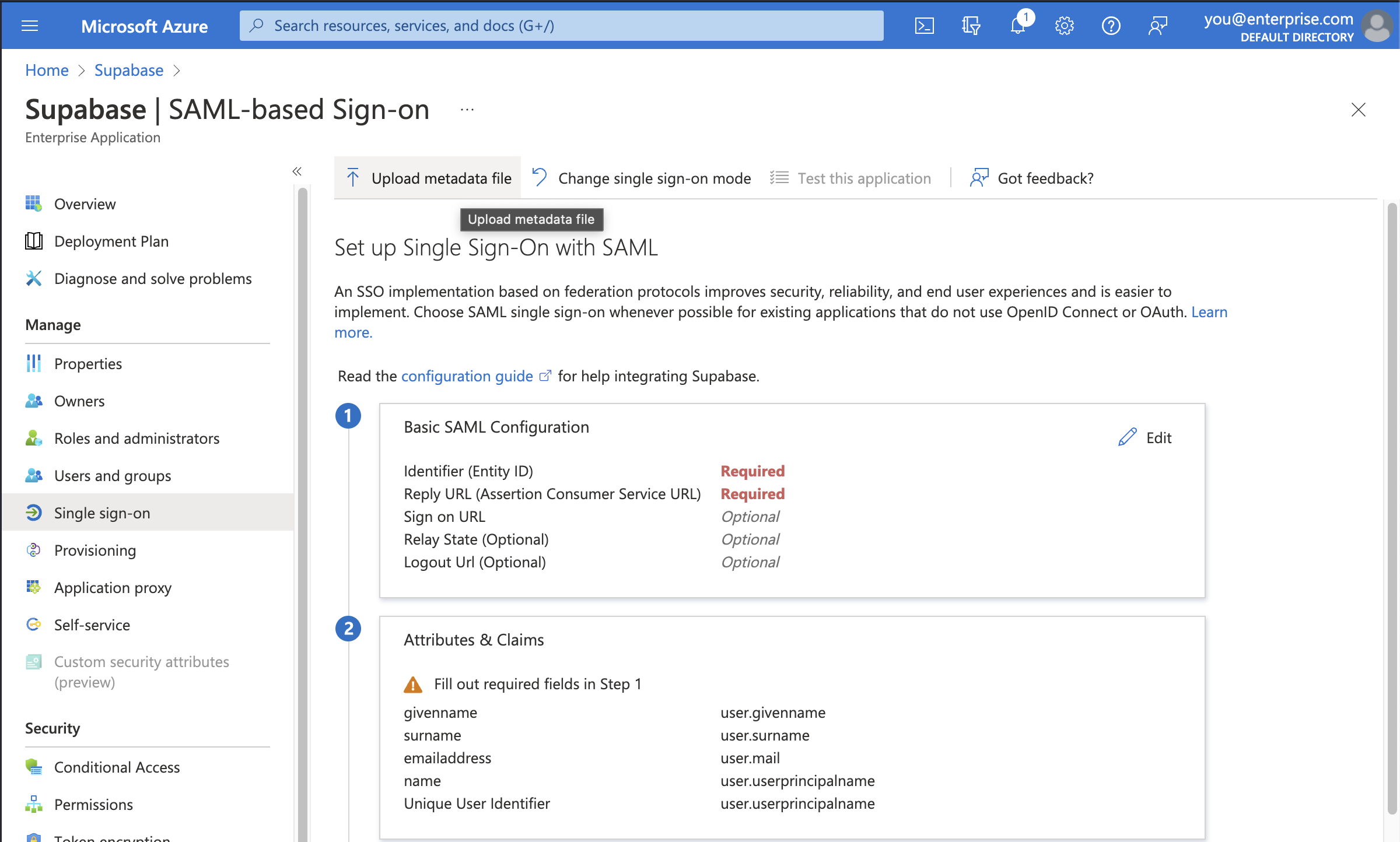
All of the correct information should automatically populate the *Basic SAML Configuration* screen as shown.
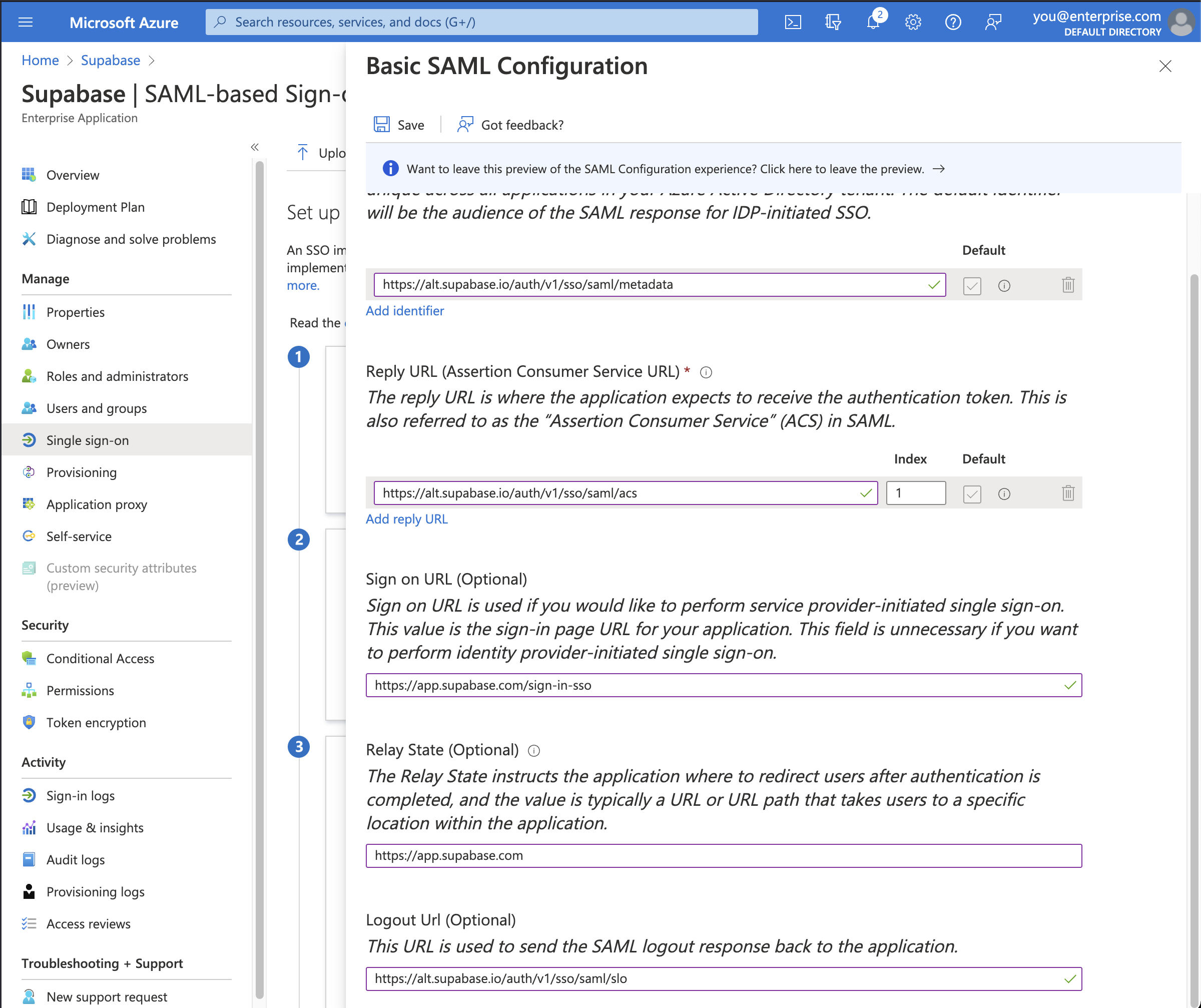
**Make sure you input these additional settings.**
| Setting | Value |
| ----------- | -------------------------------------------- |
| Sign on URL | `https://supabase.com/dashboard/sign-in-sso` |
| Relay State | `https://supabase.com/dashboard` |
Finally, click the *Save* button to save the configuration.
## Step 7: Obtain metadata URL \[#idp-metadata-url]
Save the link under **App Federation Metadata URL** in \*section 3 **SAML Certificates\***. You will need to enter this URL later in [Step 10](#dashboard-configure-metadata).
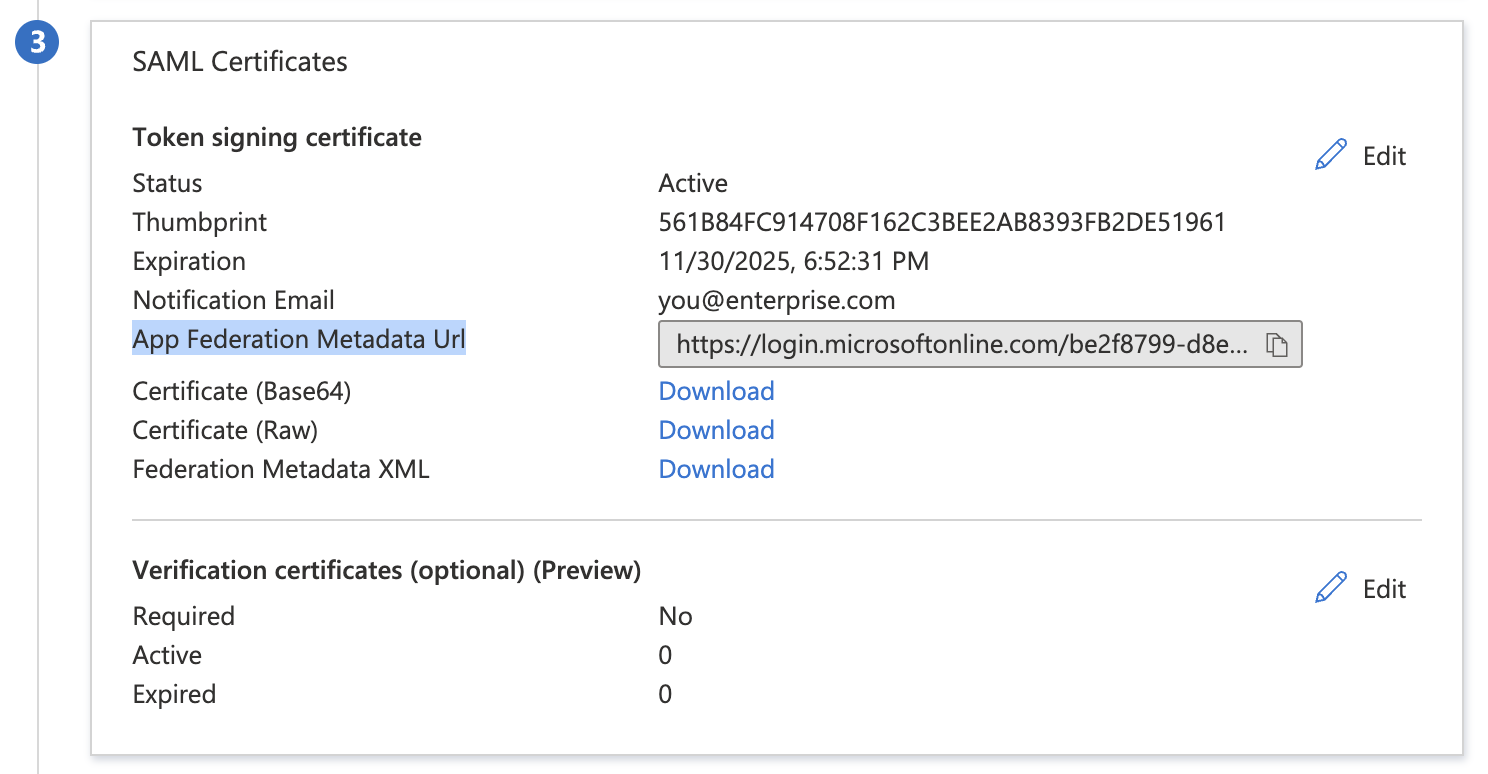
## Step 8: Enable SSO in the Dashboard \[#dashboard-enable-sso]
1. Visit the [SSO tab](/dashboard/org/_/sso) under the Organization Settings page. 
2. Toggle **Enable Single Sign-On** to begin configuration. Once enabled, the configuration form appears. 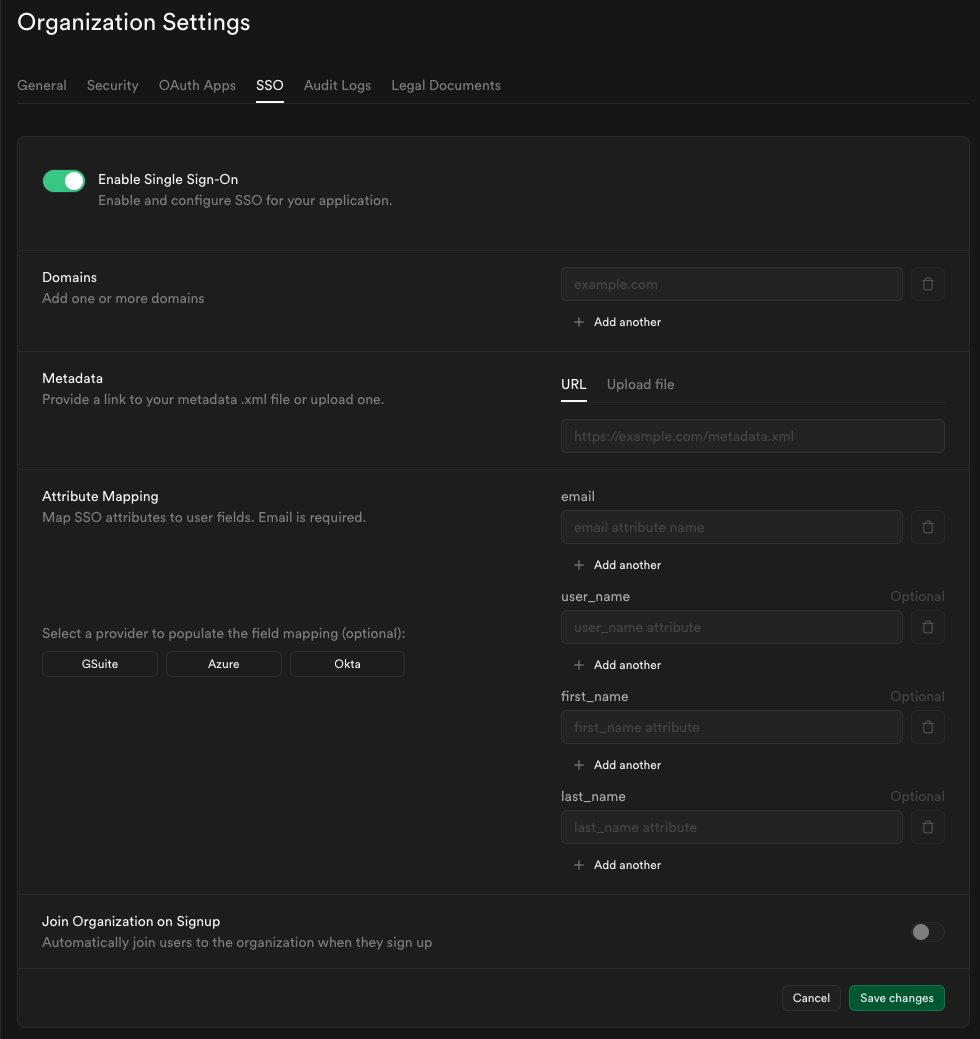
## Step 9: Configure domains \[#dashboard-configure-domain]
Enter one or more domains associated with your users email addresses (e.g., `supabase.com`).
These domains determine which users are eligible to sign in via SSO.

If your organization uses more than one email domain - for example, `supabase.com` for staff and `supabase.io` for contractors - you can add multiple domains here. All listed domains will be authorized for SSO sign-in.

We do not permit use of public domains like `gmail.com`, `yahoo.com`.
You can configure each SSO provider with different email domains. For multi-environment setups (Dev/Staging/Prod), we recommend using IdP-initiated flow with multiple SAML apps under the same domain rather than domain-based routing. For more details, see the [Multiple SSO Providers guide](/docs/guides/platform/sso/multiple-providers).
## Step 10: Configure metadata \[#dashboard-configure-metadata]
Enter the metadata URL you obtained from [Step 7](#idp-metadata-url) into the Metadata URL field:

## Step 11: Configure attribute mapping \[#dashboard-configure-attributes]
Fill out the Attribute Mapping section using the **Azure** preset.
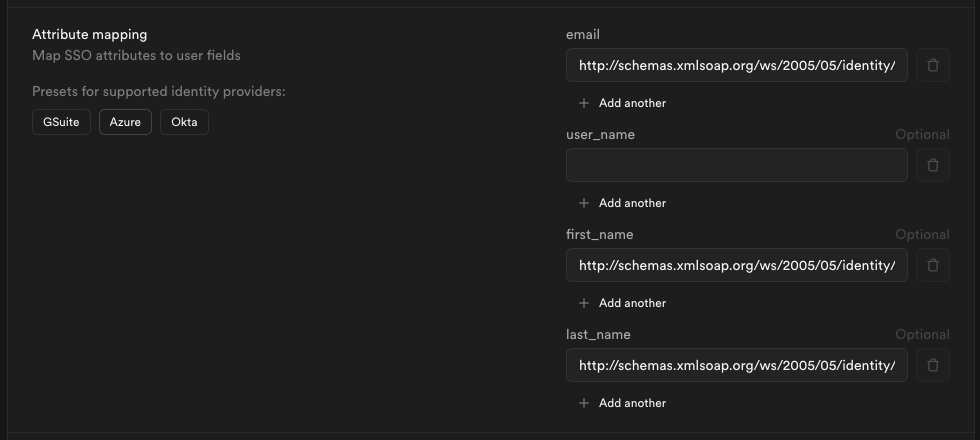
## Step 12: Join organization on signup (optional) \[#dashboard-configure-autojoin]
By default this setting is disabled, users logging in via SSO will not be added to your organization automatically.

Toggle this on if you want SSO-authenticated users to be **automatically added to your organization** when they log in via SSO. Auto-join applies on **every login**, not just first signup - this makes it safe to test SSO before enabling this feature.

When auto-join is enabled, you can choose the **default role** for new users:
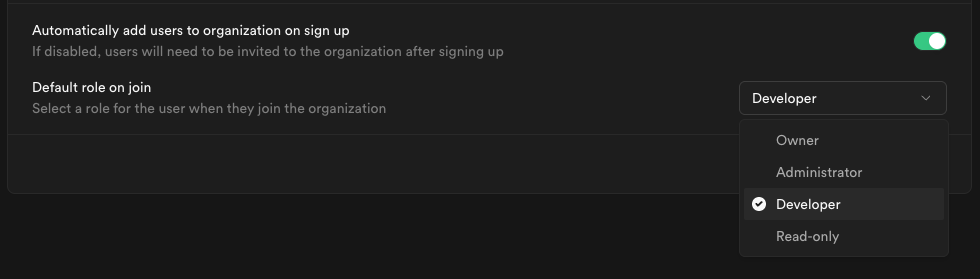
We recommend choosing **Developer** as the default role (principle of least privilege) and promoting users individually as needed.
Read [the Access Control documentation](/docs/guides/platform/access-control) for details about each role.
## Step 13: Save changes \[#dashboard-configure-save]
When you click **Save changes**, your new SSO configuration is applied immediately. From that moment, any user with an email address matching one of your configured domains who visits your organization's sign-in URL will be routed through the SSO flow.
## Step 14: Test your SSO configuration
Before rolling out SSO to your organization, we strongly recommend thorough testing. Read [the SSO Testing and Best Practices guide](/docs/guides/platform/sso/testing-best-practices) for:
* Step-by-step testing instructions
* How to verify auto-join works correctly
* Common issues and troubleshooting
* Security best practices
* Pre-launch checklist
If your organization has an Azure sandbox or test tenant, consider testing your SSO configuration there first before applying to production.
# Choosing the Right SSO Login Flow
Not sure which single sign-on (SSO) login flow to enable? This guide maps common enterprise scenarios to the recommended configuration.
Start with identity provider (IdP)-initiated, the default behavior. It requires no domain configuration, and works for most enterprise use cases. You can enable SP-initiated later if needed.
## Decision flowchart
```
Do users need to start login at supabase.com?
│
├─ No → Use IdP-initiated only (default) ✅
│ - No domain configuration needed
│ - Simplest setup
│ - Users access via IdP dashboard
│
└─ Yes → Do you need multiple SAML apps per domain?
│
├─ Yes → Use IdP-initiated only ✅
│ - Supports Dev/Staging/Prod under same domain
│ - Each environment is a separate IdP tile
│
└─ No → Enable both flows ✅
- SP-initiated for users who bookmark supabase.com
- IdP-initiated still works from IdP dashboard
- Configure email domains
```
## Common scenarios
### Scenario 1: Multiple environments (dev, staging, prod)
**Your situation:**
* You need separate Supabase organizations for Dev, Staging, and Production
* All employees use `company.com` email addresses
* You can't assign different email domains to different environments
**Recommended configuration:** IdP-initiated only ✅
**Why:**
* Create separate SAML apps in your IdP for each environment
* All apps use the same domain (`company.com`)
* Users click "Supabase Dev", "Supabase Staging", or "Supabase Prod" tiles
* No domain conflicts
**How to configure:**
1. In your IdP, create three SAML apps:
* "Supabase Dev" → Points to dev org ACS URL
* "Supabase Staging" → Points to staging org ACS URL
* "Supabase Production" → Points to prod org ACS URL
2. In each Supabase organization:
* Enable SSO
* Leave "Enable SP-initiated login" **OFF**
* Configure metadata from corresponding IdP app
3. Users access each environment via IdP tiles
**Result:** Clean separation of environments with single domain.
***
### Scenario 2: Single production organization
**Your situation:**
* One Supabase organization for your entire company
* All employees use company email domain
* Users are comfortable with IdP dashboard
**Recommended configuration:** IdP-initiated only ✅
**Why:**
* Simplest possible setup
* No domain configuration required
* Users access Supabase with one click from IdP
* Fewer potential failure points
**How to configure:**
1. Enable SSO in your Supabase organization
2. Leave "Enable SP-initiated login" **OFF**
3. Configure identity provider metadata
4. Create Supabase app tile in your IdP
**Result:** One-click SSO login for all users.
***
### Scenario 3: Users bookmark supabase.com
**Your situation:**
* Users frequently bookmark supabase.com directly
* You want to support starting login from Supabase
* Single domain, single organization
**Recommended configuration:** Enable both flows ✅
**Why:**
* Supports users who start at supabase.com (SP-initiated)
* Also supports users who prefer IdP tiles (IdP-initiated)
* Flexible for different user preferences
**How to configure:**
1. Enable SSO in your Supabase organization
2. Toggle "Enable SP-initiated login" **ON**
3. Add your email domain(s) (e.g., `company.com`)
4. Configure identity provider metadata
5. Create Supabase app tile in your IdP (optional but recommended)
**Result:** Users can start login from either Supabase or IdP.
***
### Scenario 4: Migrating from password authentication
**Your situation:**
* Currently using password-based login
* Transitioning to SSO
* Users are used to starting at supabase.com
**Recommended configuration:** Enable both flows ✅
**Why:**
* Familiar login starting point for existing users
* Gradual transition to IdP-based access
* Can promote IdP tiles after users adapt
**How to configure:**
1. Ensure at least one non-SSO owner account exists
2. Enable SSO and toggle "Enable SP-initiated login" **ON**
3. Add email domain(s)
4. Start with auto-join **disabled**
5. Test with small group
6. Enable auto-join once confirmed
7. Communicate new IdP tiles to users
8. Gradually encourage IdP-initiated usage
**Migration path:**
* **Week 1:** Enable both flows, announce SSO availability
* **Week 2-4:** Monitor usage, troubleshoot issues
* **Month 2+:** Promote IdP tiles, consider disabling SP-initiated if usage drops
***
### Scenario 5: Multiple subsidiaries with different domains
**Your situation:**
* Parent company (`parent.com`) and subsidiaries (`sub1.com`, `sub2.com`)
* All use the same Supabase organization
* Each domain maps to same identity provider
**Recommended configuration:** SP-initiated with multiple domains ✅
**Why:**
* Multiple domains supported in SP-initiated configuration
* Automatic routing based on email domain
* Centralized organization management
**How to configure:**
1. Enable SSO in your Supabase organization
2. Toggle "Enable SP-initiated login" **ON**
3. Add all domains: `parent.com`, `sub1.com`, `sub2.com`
4. Configure identity provider to accept all domains
5. Create Supabase app tiles in IdP (IdP-initiated also works)
**Result:** Users with any configured domain can access organization.
***
### Scenario 6: SaaS platform with customer-specific SSO
**Your situation:**
* You're building a SaaS product
* Each customer has their own organization
* Each customer uses their own identity provider
**Recommended configuration:** Per-customer decision (typically IdP-initiated)
**Why:**
* Each customer may have different preferences
* Default to IdP-initiated for simplicity
* Enable SP-initiated only if customer requests it
**How to configure:**
1. For each customer organization:
* Enable SSO with their IdP metadata
* Default: Leave SP-initiated **OFF**
* If customer requests SP-initiated: Toggle **ON** and add their domain
2. Document both options in customer onboarding
3. Let customers choose based on their workflow
**Result:** Flexible, customer-specific SSO configurations.
***
### Scenario 7: Mixed authentication (SSO + non-SSO users)
**Your situation:**
* Some users authenticate via SSO (employees)
* Some users use password/social auth (contractors, external partners)
* Single organization with mixed membership
**Recommended configuration:** Both flows with careful planning ⚠️
**Why:**
* SSO users can use either flow
* Non-SSO users use password/social login
* Separate invitation types for each group
**How to configure:**
1. Enable SSO with both flows (toggle SP-initiated **ON**)
2. Configure employee email domain(s)
3. Use **SSO-required invitations** for employees
4. Use **non-SSO invitations** for contractors
5. Consider disabling auto-join to control membership
SSO and non-SSO accounts with the same email are treated as separate accounts. An employee with `alice@company.com` will have two accounts if they:
1. Join via SSO (SSO account)
2. Previously joined via password (non-SSO account)
Communicate clearly which authentication method each user should use.
**Result:** Mixed authentication with clear separation.
## Configuration quick reference
| Use Case | IdP-initiated | SP-initiated | Domains Required |
| ---------------------------------------- | ------------- | ------------ | ----------------- |
| Multiple environments (Dev/Staging/Prod) | ✅ Only | ❌ Off | No |
| Single production org | ✅ Only | ❌ Off | No |
| Users bookmark supabase.com | ✅ Yes | ✅ Yes | Yes |
| Migrating from passwords | ✅ Yes | ✅ Yes | Yes |
| Multiple email domains | ✅ Yes | ✅ Yes | Yes (all domains) |
| Customer-specific SSO (SaaS) | ✅ Default | Optional | Per customer |
| Mixed authentication | ✅ Yes | ✅ Yes | Yes |
## Testing your configuration
After choosing your login flow, thoroughly test:
1. **IdP-initiated:** Click app tile in IdP → Verify redirect to Supabase
2. **SP-initiated:** Go to supabase.com/sign-in-sso → Enter email → Verify IdP redirect
3. **Auto-join:** Test with new user accounts
4. **Domain restrictions:** Try non-matching domain (should fail for SP-initiated)
See our comprehensive [SSO Testing and Best Practices guide](/docs/guides/platform/sso/testing-best-practices) for detailed testing procedures.
## When to change configuration
You can safely change login flow configuration at any time:
### Adding SP-initiated to IdP-only
* Toggle "Enable SP-initiated login" ON
* Add required domains
* Test with existing users
* No disruption to IdP-initiated flow
### Removing SP-initiated
* Toggle "Enable SP-initiated login" OFF
* Domains are preserved (can re-enable later)
* IdP-initiated continues working
* Users who bookmarked supabase.com need to use IdP tiles instead
**No migration required** - Changes take effect immediately.
## Still not sure?
If you're uncertain which configuration to use:
1. Start with IdP-initiated only (simplest, works for most cases)
2. Test with a small group of users
3. Gather feedback on user experience
4. Enable SP-initiated if users request it
5. Monitor usage to see which flow is preferred
If you need help choosing the right configuration for your organization, contact Supabase support with details about your use case. We're happy to provide personalized recommendations.
## Next steps
* **Understand the technical details:** Read [Understanding SSO Login Flows](/docs/guides/platform/sso/login-flows)
* **Configure your provider:** Follow our [provider-specific guides](/docs/guides/platform/sso#supported-providers)
* **Test your setup:** Review [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices)
* **Enable auto-join:** Configure [auto-join settings](/docs/guides/platform/sso#key-configuration-options)
# Set Up SSO with Google Workspace
This feature is only available on the [Team and Enterprise Plans](/pricing). If you are an existing Team or Enterprise Plan customer, continue with the setup below.
Looking for docs on how to add Single Sign-On support in your Supabase project? Head on over to [Single Sign-On with SAML 2.0 for Projects](/docs/guides/auth/enterprise-sso/auth-sso-saml).
Supabase supports single sign-on (SSO) using Google Workspace (formerly known as G Suite).
## Step 1: Open the Google Workspace web and mobile apps console \[#google-workspace-console]
## Step 2: Choose to add custom SAML app \[#add-custom-saml-app]
From the *Add app* button in the toolbar choose *Add custom SAML app*.
## Step 3: Fill out app details \[#add-app-details]
The information you enter here is for visibility into your Google Workspace. You can choose any values you like. `Supabase` as a name works well for most use cases. Optionally enter a description.
## Step 4: Download IdP metadata \[#download-idp-metadata]
This is a very important step. Click on *DOWNLOAD METADATA* and save the file that was downloaded. You will need to upload this file later in [Step 10](#dashboard-configure-metadata).
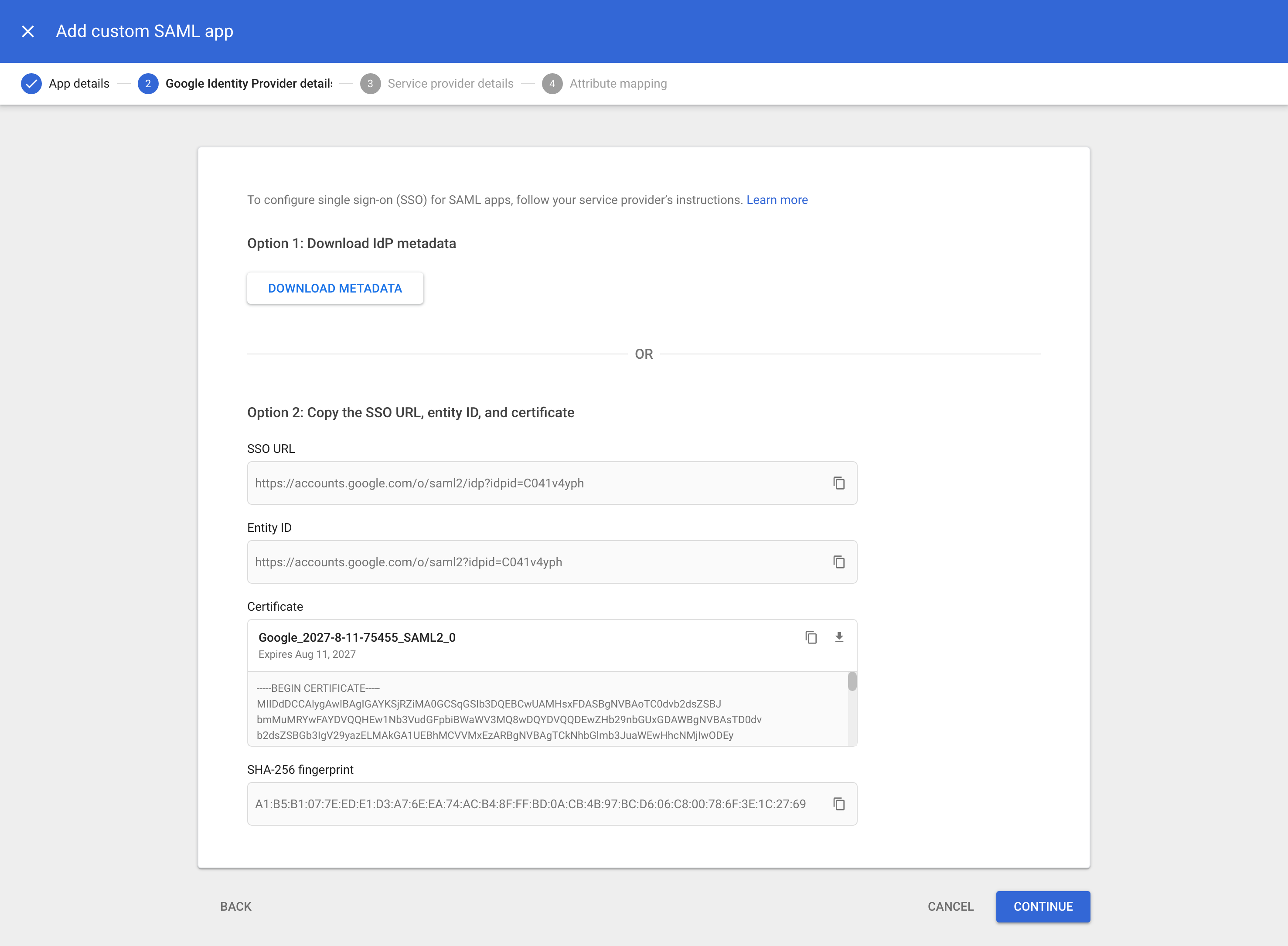
**Important: Make sure the certificate as shown on screen has at least 1 year before it expires.**
**Certificate expiration:** Set a calendar reminder 30 days before the certificate expiration date. When the certificate is renewed, you'll need to download the new metadata file and update it in your Supabase SSO settings. Expired certificates are a common cause of SSO sign-in failures.
## Step 5: Add service provider details \[#add-service-provider-details]
Fill out these service provider details on the next screen.
| Detail | Value |
| -------------- | --------------------------------------------------- |
| ACS URL | `https://alt.supabase.io/auth/v1/sso/saml/acs` |
| Entity ID | `https://alt.supabase.io/auth/v1/sso/saml/metadata` |
| Start URL | `https://supabase.com/dashboard` |
| Name ID format | PERSISTENT |
| Name ID | *Basic Information > Primary email* |
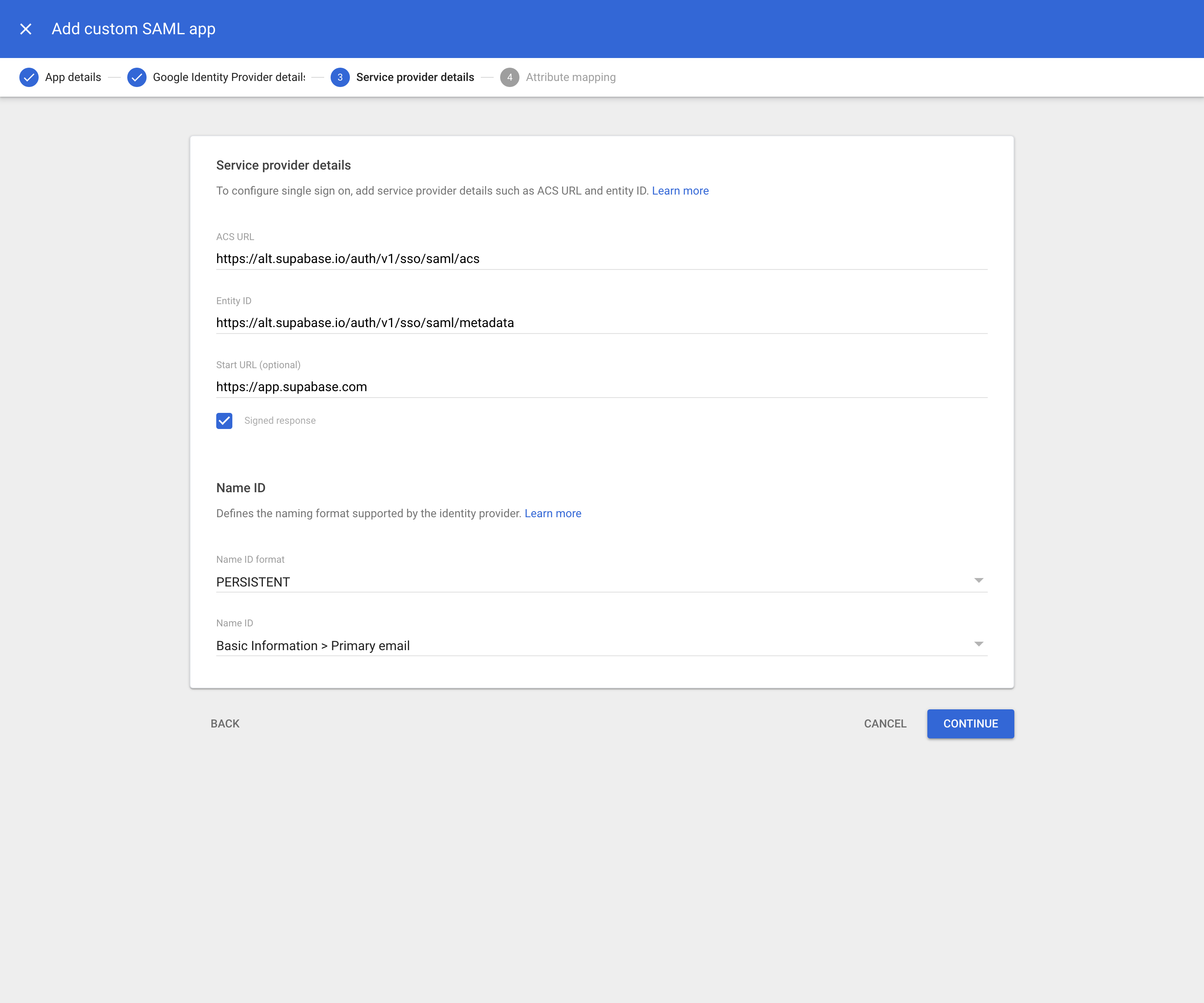
## Step 6: Configure attribute mapping \[#configure-attribute-mapping]
Attribute mappings allow Supabase to get information about your Google Workspace users on each login.
**A *Primary email* to `email` mapping is required.** Other mappings shown below are optional and configurable depending on your Google Workspace setup. If in doubt, replicate the same config as shown.
Any changes you make from this screen will be used later in [Step 10: Configure Attribute Mapping](#dashboard-configure-attributes).
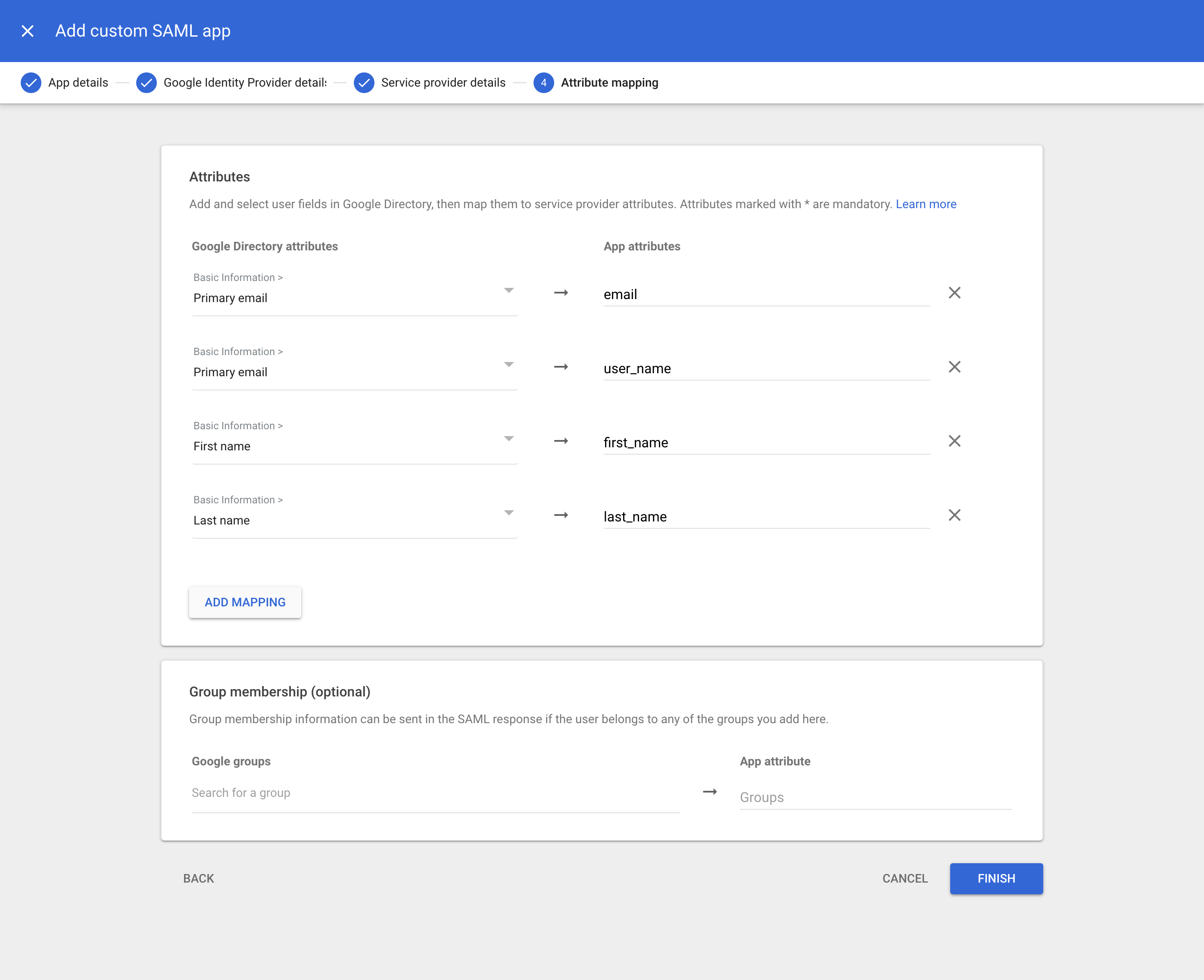
## Step 7: Configure user access \[#configure-user-access]
You can configure which Google Workspace user accounts will get access to Supabase. This is important if you wish to limit access to your software engineering teams.
You can configure this access by clicking on the *User access* card (or down-arrow). Follow the instructions on screen.
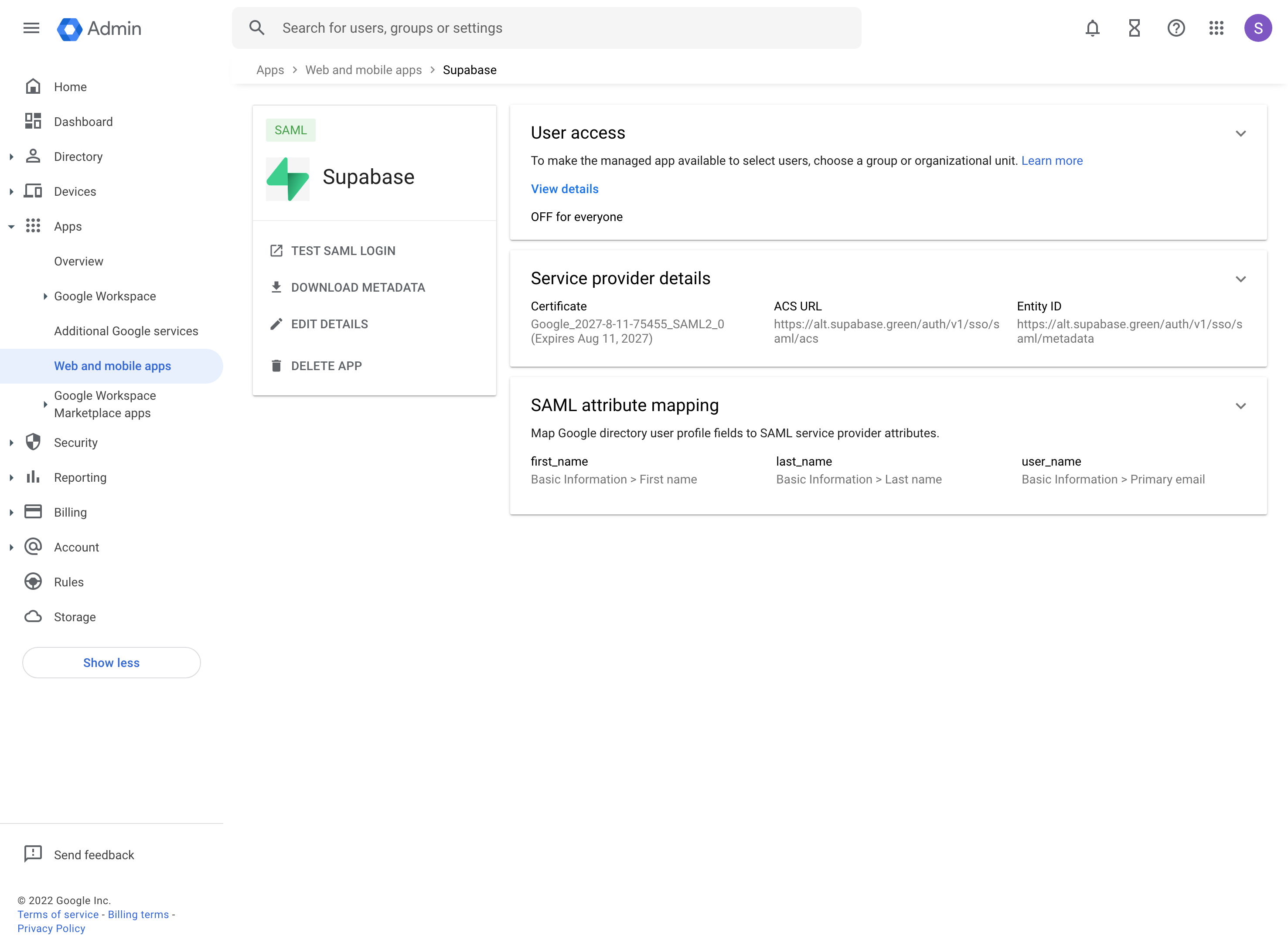
Changes from this step sometimes take a while to propagate across Google's systems. Wait at least 15 minutes before testing your changes.
## Step 8: Enable SSO in the Dashboard \[#dashboard-enable-sso]
1. Visit the [SSO tab](/dashboard/org/_/sso) under the Organization Settings page. 
2. Toggle **Enable Single Sign-On** to begin configuration. Once enabled, the configuration form appears. 
## Step 9: Configure domains \[#dashboard-configure-domain]
Enter one or more domains associated with your users email addresses (e.g., `supabase.com`).
These domains determine which users are eligible to sign in via SSO.

If your organization uses more than one email domain - for example, `supabase.com` for staff and `supabase.io` for contractors - you can add multiple domains here. All listed domains will be authorized for SSO sign-in.

We do not permit use of public domains like `gmail.com`, `yahoo.com`.
Each SSO provider can be configured with different email domains. For multi-environment setups (Dev/Staging/Prod), we recommend using IdP-initiated flow with multiple SAML apps under the same domain rather than domain-based routing. For more details, see the [Multiple SSO Providers guide](/docs/guides/platform/sso/multiple-providers).
## Step 10: Configure metadata \[#dashboard-configure-metadata]
Upload the metadata file you downloaded in [Step 6](#download-idp-metadata) into the Metadata Upload File field.

## Step 11: Configure attribute mapping \[#dashboard-configure-attributes]
Enter the SAML attributes you filled out in [Step 6](#configure-attribute-mapping) into the Attribute Mapping section.
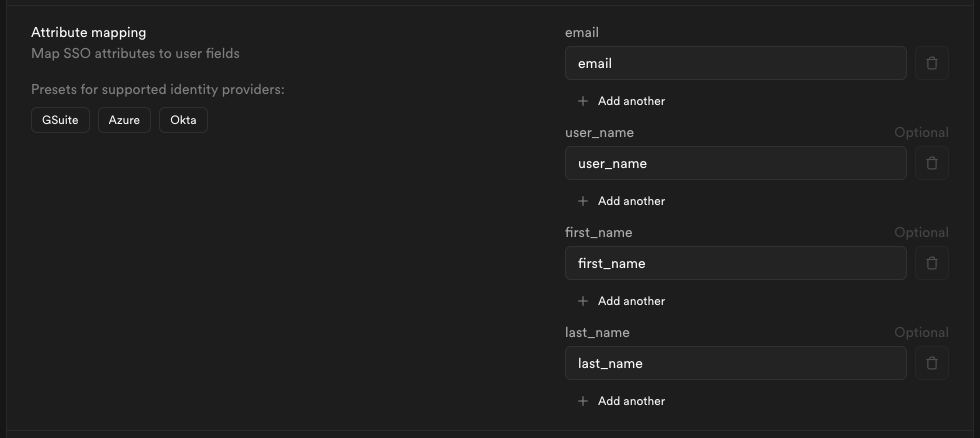
If you did not customize your settings you may save some time by clicking the **G Suite** preset.
## Step 12: Join organization on signup (optional) \[#dashboard-configure-autojoin]
**Recommended workflow:** Start with auto-join **disabled** to test your SSO configuration. Once SSO login is working correctly, enable auto-join if desired.
By default this setting is disabled, users logging in via SSO will not be added to your organization automatically.

Toggle this on if you want SSO-authenticated users to be **automatically added to your organization** when they log in via SSO. Auto-join applies on **every login**, not just first signup - this makes it safe to test SSO before enabling this feature.

When auto-join is enabled, you can choose the **default role** for new users:

We recommend choosing **Developer** as the default role (principle of least privilege) and promoting users individually as needed.
Visit [access-control](/docs/guides/platform/access-control) documentation for details about each role.
## Step 13: Save changes \[#dashboard-configure-save]
When you click **Save changes**, your new SSO configuration is applied immediately. From that moment, any user with an email address matching one of your configured domains who visits your organization's sign-in URL will be routed through the SSO flow.
**Next step: Test your SSO configuration**
Before rolling out SSO to your organization, we strongly recommend thorough testing. Visit our [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices) guide for:
* Step-by-step testing instructions
* How to verify auto-join works correctly
* Common issues and troubleshooting
* Security best practices
* Pre-launch checklist
# Understanding SSO Login Flows
When configuring SSO for your organization, you can choose between two different login flows: **identity provider (IdP)-initiated** and **service provider (SP)-initiated**. Understanding the difference helps you provide the best experience for your users.
Most enterprises use IdP-initiated flow for its simplicity and better user experience. Enable SP-initiated only if you need users to start their login journey at supabase.com.
See our [Choosing the Right Login Flow guide](/docs/guides/platform/sso/choosing-login-flow) for use case examples.
## Overview of login flows
### IdP-initiated (Identity Provider Initiated)
With IdP-initiated flow, users start their login journey from your identity provider (Okta, Azure AD, Google Workspace, etc.) and are directly authenticated into Supabase.
**User experience:**
1. User opens their identity provider dashboard (e.g., Okta homepage, Azure MyApps)
2. User clicks the Supabase app tile or bookmark
3. User is immediately logged into Supabase (if already authenticated with IdP)
**Key characteristics:**
* ✅ Simpler user experience - one click from IdP
* ✅ No domain configuration required
* ✅ Works automatically once SSO is enabled
* ✅ Better for intranet portals and employee app catalogs
* ✅ Default behavior in Supabase
### SP-initiated (Service Provider Initiated)
With SP-initiated flow, users start at supabase.com, enter their email address, and are redirected to your identity provider for authentication.
**User experience:**
1. User visits supabase.com and clicks "Sign in with SSO"
2. User enters their email address
3. User is redirected to their identity provider
4. After authenticating, user is redirected back to Supabase
**Key characteristics:**
* ✅ Familiar flow for users who bookmark supabase.com
* ✅ Supports domain-based automatic IdP routing
* ⚠️ Requires configuring email domains
* ⚠️ More steps in the login process
## Choosing between flows
### When to use IdP-initiated (recommended)
**Best for:**
* Organizations with established identity provider workflows
* Users who primarily access apps through their IdP dashboard
* Multiple SAML apps per domain (Dev, Staging, Prod environments)
* Simplifying user onboarding
**Common scenarios:**
* "Our team accesses all tools through Okta tiles"
* "We want the simplest possible login experience"
* "We need separate Dev and Prod SAML apps under the same domain"
* "Users should never need to remember supabase.com"
### When to use SP-initiated
**Best for:**
* Organizations where users bookmark supabase.com directly
* Migrating from password-based authentication
* Users unfamiliar with identity provider dashboards
**Common scenarios:**
* "Some users bookmark supabase.com and expect to start there"
* "We're transitioning from password auth to SSO"
* "Users need a consistent login page across all tools"
* "We want domain-based automatic IdP selection"
### When to enable both flows
You can enable both flows simultaneously to support different user preferences.
**Best for:**
* Large organizations with diverse user needs
* Gradual SSO migration with mixed authentication
* Supporting both technical and non-technical users
## Configuring login flows
### Enabling IdP-initiated flow (default)
IdP-initiated flow is automatically enabled when you configure SSO. No additional steps required.
1. Navigate to [the **SSO** settings](/dashboard/org/_/sso) section of the dashboard
2. Enable "Single Sign-On"
3. Configure your identity provider metadata and attribute mapping
4. Save your configuration
Users can now access Supabase through your IdP's app catalog.
With IdP-initiated flow, you don't need to configure email domains. Your identity provider handles all authentication routing.
### Enabling SP-initiated flow
To enable SP-initiated flow, you need to configure email domains:
1. Navigate to [the **SSO** settings](/dashboard/org/_/sso) section of the dashboard
2. Enable "Single Sign-On"
3. Toggle **Enable SP-initiated login** to "ON"
4. Add one or more email domains (e.g., `yourcompany.com`)
5. Configure your identity provider metadata and attribute mapping
6. Save your configuration
#### Email domain requirements
* At least one domain required when SP-initiated is enabled
* Domains must be verified through your identity provider
* Multiple domains supported (e.g., `company.com`, `subsidiary.com`)
* Users with matching email domains will be routed to your IdP
Only users with email addresses matching your configured domains can use SP-initiated login. Users with other domains cannot sign in via SSO at supabase.com (but can still use IdP-initiated flow if you configure it in your IdP).
### Switching between flows
You can change login flow configuration at any time:
#### To switch from SP-initiated to IdP-only
1. Navigate to [the **SSO** settings](/dashboard/org/_/sso) section of the dashboard
2. Toggle **Enable SP-initiated login** to "OFF"
3. Save changes
Existing users can continue signing in via IdP-initiated flow.
#### To switch from IdP-only to SP-initiated
1. Navigate to [the **SSO** settings](/dashboard/org/_/sso) section of the dashboard
2. Toggle **Enable SP-initiated login** to "ON"
3. Add required email domains
4. Save changes
## Technical details
### How IdP-initiated flow works
1. User clicks app tile in identity provider
2. IdP generates SAML assertion and POSTs to Supabase ACS URL
3. Supabase validates assertion and creates session
4. User is redirected to Supabase dashboard
**No domain lookup required** - The IdP assertion contains all necessary user information.
### How SP-initiated flow works
1. User enters email at supabase.com/sign-in-sso
2. Supabase matches email domain to configured SSO provider
3. Supabase generates SAML request and redirects to IdP
4. IdP authenticates user and generates SAML assertion
5. IdP POSTs assertion to Supabase ACS URL
6. Supabase validates assertion and creates session
**Domain matching is critical** - Without matching domains, users cannot complete SP-initiated flow.
## Multiple SAML apps per domain
One of the key advantages of IdP-initiated flow is supporting multiple SAML applications under the same domain.
### The problem with SP-initiated only
Many enterprises need separate SAML apps for different environments:
* Development SAML app
* Staging SAML app
* Production SAML app
**With SP-initiated flow only:** Each SAML app requires a unique domain. You'd need:
* `dev.company.com`
* `staging.company.com`
* `prod.company.com`
This is often impractical since all employees use `company.com` email addresses.
### The solution with IdP-initiated flow
**With IdP-initiated flow:** All SAML apps can use the same domain (`company.com`) because:
* Users access each app through different IdP tiles/bookmarks
* No domain-based routing is needed
* Each SAML app has its own unique ACS URL and metadata
#### Configuration in your IdP
* Create "Supabase Dev" SAML app → Points to dev org's ACS URL
* Create "Supabase Staging" SAML app → Points to staging org's ACS URL
* Create "Supabase Production" SAML app → Points to prod org's ACS URL
Users click the appropriate tile for the environment they need.
This is the recommended approach for enterprises with multiple environments. Configure each environment as IdP-initiated only (no domains needed).
## Common questions
### Can you use both flows simultaneously?
Yes! Enable SP-initiated login and configure domains. IdP-initiated flow continues to work automatically.
### What happens when you don't configure domains?
Without domains, only IdP-initiated flow is available. Users cannot start their login at supabase.com.
### Does the IdP require configuration?
For **IdP-initiated flow:** Configure the Supabase ACS URL and entity ID in your IdP. See our provider-specific guides:
* [Google Workspace](/docs/guides/platform/sso/gsuite)
* [Azure Active Directory](/docs/guides/platform/sso/azure)
* [Okta](/docs/guides/platform/sso/okta)
For **SP-initiated flow:** Same configuration, but also ensure your IdP accepts SAML requests from Supabase.
### What happens if a user tries SP-initiated with no matching domain?
They receive an error message indicating no SSO provider found for their email domain. They can still sign in using password or social auth (if they have a non-SSO account).
### Can you disable SP-initiated flow after enabling it?
Yes, toggle it off at any time. Existing users can continue using IdP-initiated flow.
### Which flow is more secure?
Both flows are equally secure when properly configured. Security depends on:
* Strong identity provider authentication policies
* Certificate management and rotation
* Attribute mapping configuration
* Regular security audits
See our [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices) guide for security recommendations.
## Next steps
* **Choose your login flow:** See [Choosing the Right Login Flow](/docs/guides/platform/sso/choosing-login-flow)
* **Configure your provider:** Follow our [provider-specific guides](/docs/guides/platform/sso#supported-providers)
* **Test thoroughly:** Review [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices)
* **Enable auto-join:** Configure [auto-join settings](/docs/guides/platform/sso#key-configuration-options) for seamless onboarding
# Multiple SSO Providers
Many enterprises need multiple single sign-on (SSO) providers configured within Supabase to support different environments, teams, or organizational structures. This guide explains when and how to set up multiple providers effectively.
## Why multiple SSO providers?
Common scenarios requiring multiple SSO providers include:
* **Multiple environments**: Separate Dev, Staging, and Production organizations
* **Team separation**: Different business units or departments
* **Migration**: Transitioning from one identity provider to another
* **Acquisitions**: Integrating subsidiaries with different identity systems
* **Testing**: Isolated test environments alongside production
## Key concept: IDP-initiated enables unlimited providers per domain
The traditional challenge with multiple SAML apps is domain conflicts. With SP-initiated flow only, each SAML app requires a unique email domain. Since all your employees use the same domain (e.g., `company.com`), this creates a problem.
**Solution:** Use identity provider (IdP)-initiated flow, which doesn't require domain configuration. You can create unlimited SAML apps under the same domain.
Configure each environment as IdP-initiated only (no domains). Users access each environment through different app tiles in your identity provider.
For technical details, see [the Understanding SSO Login Flows guide](/docs/guides/platform/sso/login-flows#multiple-saml-apps-per-domain).
## Use case 1: Multiple environments (dev/staging/prod)
This is the most common enterprise pattern and the primary use case for IDP-initiated flow.
### The challenge
You have three Supabase organizations:
* Development (`dev-org`)
* Staging (`staging-org`)
* Production (`prod-org`)
All employees use `company.com` email addresses. You need separate SSO configurations for each environment.
### The solution
Create three separate SAML apps in your identity provider, each pointing to a different Supabase organization.
#### In your identity provider (Okta, Azure AD, Google Workspace)
1. **Create "Supabase Dev" SAML app**
* Configure with Dev organization's ACS URL
* Assign developers and testers
* Deploy app tile labeled "Supabase Dev"
2. **Create "Supabase Staging" SAML app**
* Configure with Staging organization's ACS URL
* Assign QA team and release managers
* Deploy app tile labeled "Supabase Staging"
3. **Create "Supabase Production" SAML app**
* Configure with Production organization's ACS URL
* Assign production users only
* Deploy app tile labeled "Supabase Production"
#### In each Supabase organization
1. Navigate to [the **SSO** settings](/dashboard/org/_/sso) section of the dashboard
2. Enable **Single Sign-On**
3. Leave **Enable SP-initiated login** "OFF", this is critical
4. Configure metadata from the corresponding IDP app
5. Set up attribute mappings
6. Configure auto-join if desired
### Result
* Users click the appropriate app tile for the environment they need
* No domain conflicts (all apps use `company.com`)
* Clean isolation between environments
* Each environment can have different user assignments and roles
### Configuration example
Here's how the three configurations differ:
| Environment | Organization | IDP App Name | ACS URL |
| ----------- | ------------ | ------------------ | ------------------------------------ |
| Dev | `dev` | "Supabase Dev" | `https://...dev-org.../saml/acs` |
| Staging | `staging` | "Supabase Staging" | `https://...staging-org.../saml/acs` |
| Production | `prod` | "Supabase Prod" | `https://...prod-org.../saml/acs` |
#### Each organization
* SP-initiated: **OFF** (no domains configured)
* IDP-initiated: **ON** (automatic, no configuration needed)
* Auto-join: Your preference (typically enabled for dev, disabled for prod)
## Use case 2: Different teams or business units
Some organizations need to isolate teams within separate Supabase organizations.
### Example scenario
* Engineering team uses `engineering-org`
* Data team uses `data-org`
* Both teams have `company.com` emails
### Configuration approach
#### Option A: IDP-initiated with different app tiles
Create separate SAML apps in your IDP:
* "Supabase Engineering" → Points to `engineering-org`
* "Supabase Data" → Points to `data-org`
Assign appropriate users to each app. Users only see the tiles they're assigned to.
#### Option B: Both IDP and SP-initiated with role-based routing
Configure both organizations with SP-initiated enabled using the same domain:
* Both organizations add `company.com` as a domain
* Users can log in via SP-initiated at supabase.com
* System routes based on org membership (first match wins)
* Also provide IDP tiles for explicit routing
When multiple organizations use SP-initiated with the same domain, the first provider where the user is a member will be used. This can cause confusion. **IDP-initiated is recommended** for clarity.
## Use case 3: Migration from one IDP to another
When migrating from one identity provider to another, multiple providers help ensure a smooth transition.
### Migration workflow
#### Phase 1: Dual configuration
1. Configure new IDP as additional SSO provider
2. Keep existing IDP active
3. Test new IDP with small group
4. Both providers operational simultaneously
#### Phase 2: Gradual rollout
1. Migrate users in batches to new IDP
2. Update app tile assignments
3. Monitor for issues
4. Keep old IDP as fallback
#### Phase 3: Cutover
1. Move all users to new IDP
2. Verify no users depend on old IDP
3. Disable (don't delete) old IDP provider
4. Monitor for any issues
#### Phase 4: Cleanup
1. After verification period (1-2 weeks)
2. Delete old IDP provider
3. Update documentation
Always maintain at least one non-SSO owner account during migrations to ensure you never lose access to the organization.
## Use case 4: Acquisitions and subsidiaries
Organizations with multiple email domains need provider configurations for each domain.
### Example scenario
* Parent company: `parent.com`
* Subsidiary 1: `subsidiary1.com`
* Subsidiary 2: `subsidiary2.com`
All authenticate through the same central IDP but use different email domains.
### Configuration approach
#### Option A: Single provider with multiple domains (SP-initiated)
1. Enable SSO with SP-initiated flow
2. Add all domains: `parent.com`, `subsidiary1.com`, `subsidiary2.com`
3. Configure single IDP metadata
4. Users with any matching domain can log in via supabase.com
#### Option B: Separate providers per subsidiary (IDP-initiated)
1. Create separate SAML apps for each entity
2. Configure as IDP-initiated only
3. Assign users based on their subsidiary
4. More isolation, clearer organization boundaries
## Step-by-step setup guide
### For IDP-initiated multi-environment pattern
This is the recommended pattern for most enterprises.
#### Step 1: Plan your environments
Document:
* Organization names and slugs
* Environment purposes (dev, staging, prod)
* Which users need access to which environments
* Default roles for each environment
#### Step 2: Create SAML apps in your IDP
For each environment, follow your provider-specific guide to create a SAML app:
* [Okta setup guide](/docs/guides/platform/sso/okta)
* [Azure AD setup guide](/docs/guides/platform/sso/azure)
* [Google Workspace setup guide](/docs/guides/platform/sso/gsuite)
#### Naming convention example
* "Supabase - Production"
* "Supabase - Staging"
* "Supabase - Development"
Use consistent naming to help users identify the right environment.
#### Step 3: Configure each Supabase organization
For **each** organization:
1. Navigate to [the **SSO** settings](/dashboard/org/_/sso) section of the dashboard
2. Enable **Single Sign-On**
3. Verify **Enable SP-initiated login** is "OFF"
4. Upload or paste metadata from the corresponding IDP app
5. Configure attribute mappings:
* Email (required): Map to `email`
* Name (optional): Map to `name` or `displayName`
6. Configure auto-join settings:
* Dev: Usually enabled with "Developer" role
* Staging: Usually enabled with "Developer" role
* Prod: Usually disabled (explicit invitations only)
7. Save configuration
#### Step 4: Test each environment separately
For each environment:
1. Open your IDP dashboard (Okta, Azure, Google)
2. Click the corresponding app tile
3. Verify redirect to correct Supabase organization
4. Check that user information is populated correctly
5. Verify auto-join behavior (if enabled)
See [the SSO Testing and Best Practices guide](/docs/guides/platform/sso/testing-best-practices) for comprehensive testing procedures.
#### Step 5: Assign users in your IDP
Configure app assignments in your IDP:
* **Production**: Only production users (restrictive)
* **Staging**: QA team, release managers, senior engineers
* **Development**: All engineers and testers (permissive)
Users only see app tiles they're assigned to.
#### Step 6: Document and communicate
Create documentation for your team:
* Which app tile corresponds to which environment
* Access request process for each environment
* Naming conventions and organization structure
* Emergency access procedures (non-SSO owner account)
## User access management
### IDP app assignment strategies
#### Per-environment access control
Control who can access each environment by managing app assignments in your IDP:
```
Engineering Team:
├─ Supabase Dev (assigned) ✅
├─ Supabase Staging (assigned) ✅
└─ Supabase Prod (assigned) ✅
QA Team:
├─ Supabase Dev (assigned) ✅
├─ Supabase Staging (assigned) ✅
└─ Supabase Prod (NOT assigned) ❌
Contractors:
├─ Supabase Dev (assigned) ✅
├─ Supabase Staging (NOT assigned) ❌
└─ Supabase Prod (NOT assigned) ❌
```
### Role assignment patterns
#### Option 1: Different default roles per environment
* Dev: Auto-join with "Administrator" role (developers need full control)
* Staging: Auto-join with "Developer" role
* Prod: No auto-join, explicit invitations with "Read-only" or "Developer"
#### Option 2: Consistent roles, manual promotion
* All environments: Auto-join with "Developer" role
* Promote to "Administrator" or "Owner" manually as needed
* Provides consistent baseline, explicit elevation
#### Option 3: No auto-join, explicit control
* All environments: Auto-join disabled
* Send explicit invitations with appropriate roles
* Maximum control, more management overhead
Choose based on your organization's security posture and operational preferences.
## Best practices
### Naming conventions
#### IDP app names
Use consistent, descriptive names that clearly indicate the environment:
* ✅ "Supabase - Production"
* ✅ "Supabase Prod"
* ❌ "Supabase" (ambiguous)
* ❌ "SUPA\_PROD" (unclear abbreviation)
#### Supabase organization names
Match your IDP app names when possible:
* IDP app: "Supabase - Production" → Org: `acme-production`
* IDP app: "Supabase - Staging" → Org: `acme-staging`
* IDP app: "Supabase - Dev" → Org: `acme-development`
### Configuration synchronization
Keep critical settings synchronized across environments:
* **Attribute mappings**: Should be identical across all providers
* **Certificate settings**: Coordinate renewals across all environments
* **Safety accounts**: Each org needs a non-SSO owner account
#### Configuration drift checklist
* Attribute mappings match across environments
* Certificate expiration dates documented for all providers
* Non-SSO owner accounts exist in all organizations
* Auto-join settings are intentional (not accidental)
* Default roles appropriate for each environment
### Testing in lower environments first
Always test SSO changes in non-production environments:
1. **Make change in Dev environment**
2. **Test thoroughly** (see [testing guide](/docs/guides/platform/sso/testing-best-practices))
3. **Deploy to Staging** and verify
4. **Monitor for issues** (1-2 days)
5. **Deploy to Production** during low-usage period
6. **Monitor closely** after production deployment
### Security considerations
#### Environment isolation
* Never reuse metadata between environments (security risk)
* Each environment should have unique ACS URLs
* Verify IDP app assignments are correct (don't give prod access accidentally)
#### Access reviews
* Quarterly review of who has access to production
* Verify IDP app assignments are up to date
* Remove access for users who have changed roles
* Audit auto-join configurations (still appropriate?)
#### Break-glass access
Each organization must have at least one non-SSO owner account:
* Create dedicated "break-glass" accounts
* Store credentials in secure password manager
* Test these accounts regularly (quarterly)
* Document emergency access procedures
## Troubleshooting
### Users accessing the wrong environment
#### Symptom
User clicks "Supabase Prod" tile but sees the dev environment.
#### Causes
* Metadata configured incorrectly (swapped between environments)
* ACS URL points to wrong organization
* User has bookmarked the wrong organization
#### Solution
1. Verify ACS URL in IDP app configuration
2. Compare metadata in Supabase SSO settings
3. Check that organization slug matches expected environment
4. Have user clear browser cookies and try again
5. Verify user is clicking correct app tile
### Configuration drift between environments
#### Symptom
SSO works in dev but fails in staging or production.
#### Causes
* Attribute mappings differ between providers
* Certificate expired in one environment but not others
* Domain configuration inconsistent (if using SP-initiated)
#### Solution
1. Compare SSO configurations side-by-side
2. Check attribute mappings are identical
3. Verify certificate expiration dates
4. Test with same user account across all environments
5. Review IDP audit logs for authentication failures
### Users don't see expected app tiles
#### Symptom
User cannot find "Supabase Staging" tile in IDP dashboard.
#### Causes
* User not assigned to the app in IDP
* App not deployed/published in IDP
* User looking in wrong place (different IDP portal)
#### Solution
1. Verify app assignment in IDP admin console
2. Check app is published/active
3. Confirm user has logged out and back into IDP
4. Verify user is checking correct IDP portal (some organizations have multiple)
### Auto-join adding users to wrong organization
#### Symptom
User joins dev environment when they should join production.
#### Cause
User clicked wrong app tile, auto-join is enabled.
#### Prevention
* Disable auto-join in production (explicit invitations only)
* Use clear app tile naming
* Document which tile corresponds to which environment
* Consider using different IDP groups for different environments
#### Remediation
1. Remove user from incorrect organization
2. Send explicit invitation to correct organization
3. Educate user on correct app tile to use
4. Consider disabling auto-join to prevent recurrence
### Multiple organizations with same domain (SP-initiated confusion)
#### Symptom
With SP-initiated enabled and same domain in multiple organizations, users get routed to unexpected organization.
#### Cause
SP-initiated routing uses first matching provider.
#### Solution
* **Recommended:** Switch to IDP-initiated only (disable SP-initiated)
* Remove domain configuration from all but one organization
* Provide clear IDP app tiles for explicit routing
* Document which organization users should access via SP-initiated
## Migration from single to multiple providers
If you currently have a single SSO provider and need to add more:
### Phase 1: Planning
1. Decide which pattern to use (environments, teams, etc.)
2. Document new organization structure
3. Identify users for each environment
4. Plan user communication strategy
### Phase 2: Create new organizations
1. Create additional Supabase organizations
2. Configure projects within each organization
3. Migrate data if needed (see [project transfer](/docs/guides/platform/project-transfer))
### Phase 3: Configure SSO providers
1. Create additional SAML apps in your IDP
2. Configure SSO in each new organization
3. Start with auto-join disabled
4. Test with small group
### Phase 4: Migrate users
1. Communicate changes to users
2. Assign users to appropriate IDP apps
3. Test that users can access correct environments
4. Enable auto-join if desired
### Phase 5: Decommission old configuration (if applicable)
1. Migrate all users to new structure
2. Verify no one depends on old configuration
3. Disable old SSO provider
4. Monitor for issues
5. Delete after verification period
## Next steps
* **Configure your IDP:** Follow your [provider-specific guide](/docs/guides/platform/sso#supported-providers)
* **Test thoroughly:** Review [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices)
* **Understand login flows:** Read [Understanding SSO Login Flows](/docs/guides/platform/sso/login-flows)
* **Choose the right flow:** See [Choosing the Right Login Flow](/docs/guides/platform/sso/choosing-login-flow)
# Set Up SSO with Okta
This feature is only available on the [Team and Enterprise Plans](/pricing). If you are an existing Team or Enterprise Plan customer, continue with the setup below.
Looking for docs on how to add Single Sign-On support in your Supabase project? Head on over to [Single Sign-On with SAML 2.0 for Projects](/docs/guides/auth/enterprise-sso/auth-sso-saml).
Supabase supports single sign-on (SSO) using Okta.
## Step 1: Choose to create an app integration in the applications dashboard \[#create-app-integration]
Navigate to the Applications dashboard of the Okta admin console. Click *Create App Integration*.
## Step 2: Choose SAML 2.0 in the app integration dialog \[#create-saml-app]
Supabase supports the SAML 2.0 SSO protocol. Choose it from the *Create a new app integration* dialog.
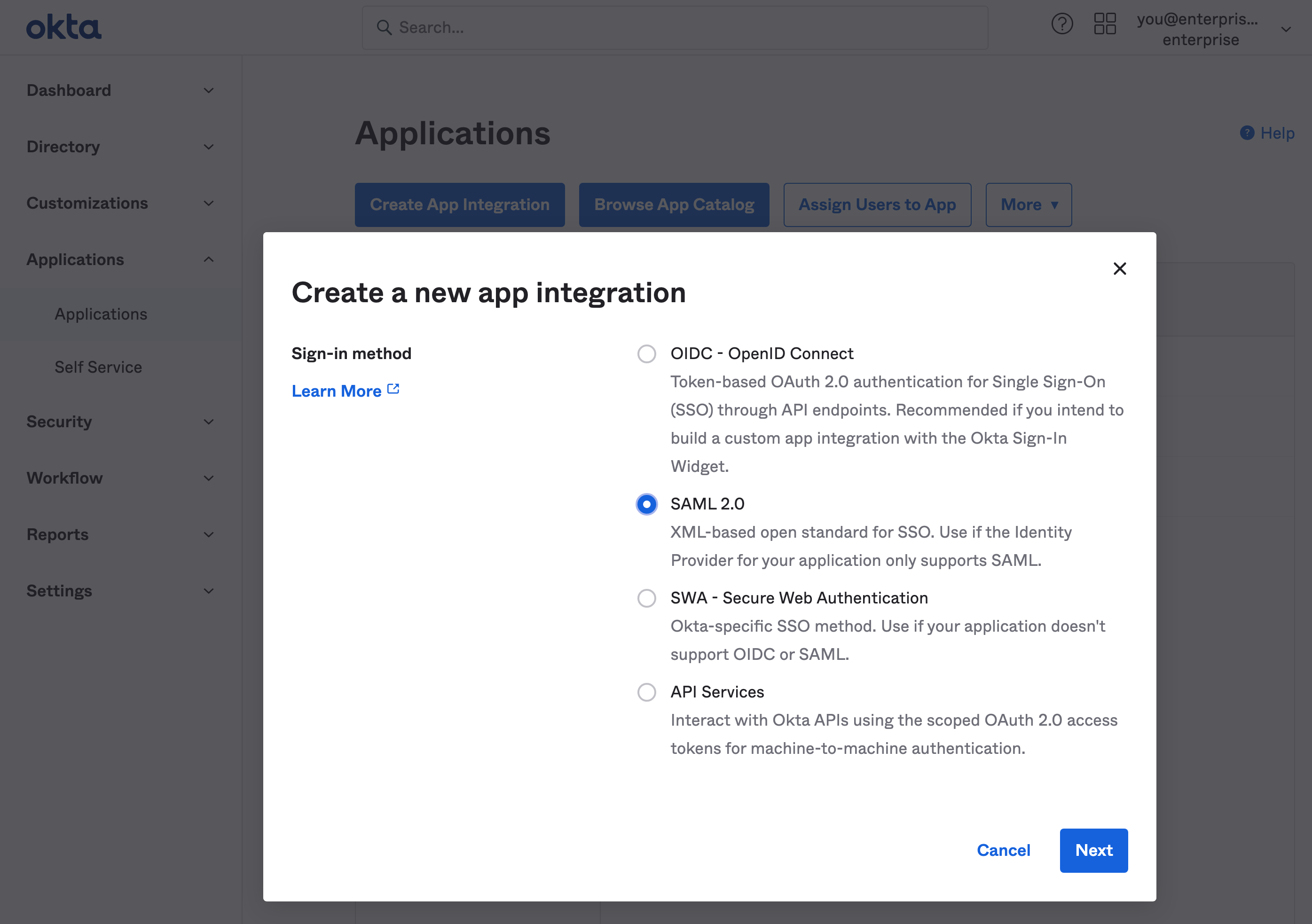
## Step 3: Fill out general settings \[#add-general-settings]
The information you enter here is for visibility into your Okta applications menu. You can choose any values you like. `Supabase` as a name works well for most use cases.
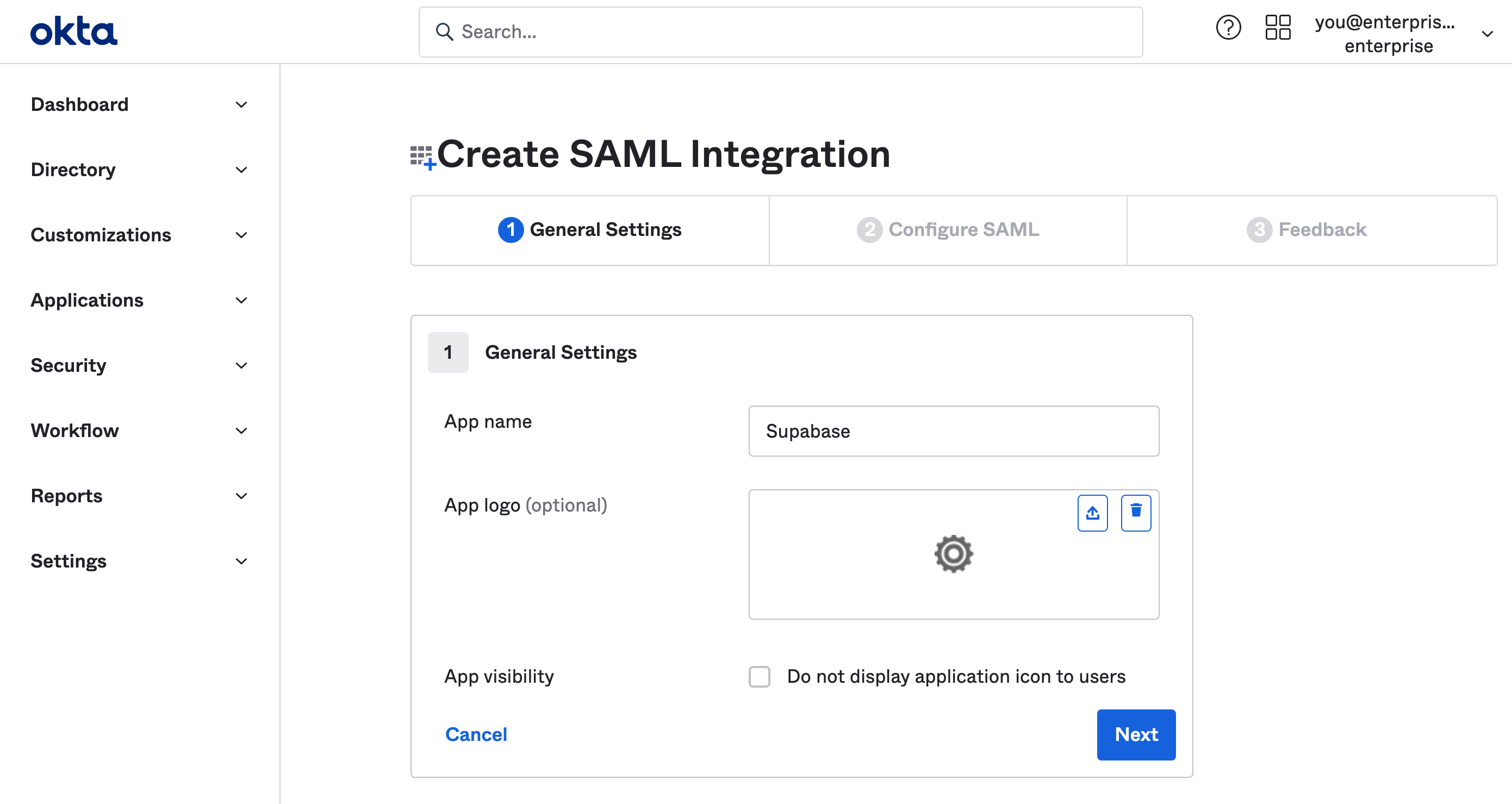
## Step 4: Fill out SAML settings \[#add-saml-settings]
These settings let Supabase use SAML 2.0 properly with your Okta application. Make sure you enter this information exactly as shown on in this table.
| Setting | Value |
| ---------------------------------------------- | --------------------------------------------------- |
| Single sign-on URL | `https://alt.supabase.io/auth/v1/sso/saml/acs` |
| Use this for Recipient URL and Destination URL | ✔️ |
| Audience URI (SP Entity ID) | `https://alt.supabase.io/auth/v1/sso/saml/metadata` |
| Default `RelayState` | `https://supabase.com/dashboard` |
| Name ID format | `EmailAddress` |
| Application username | Email |
| Update application username on | Create and update |
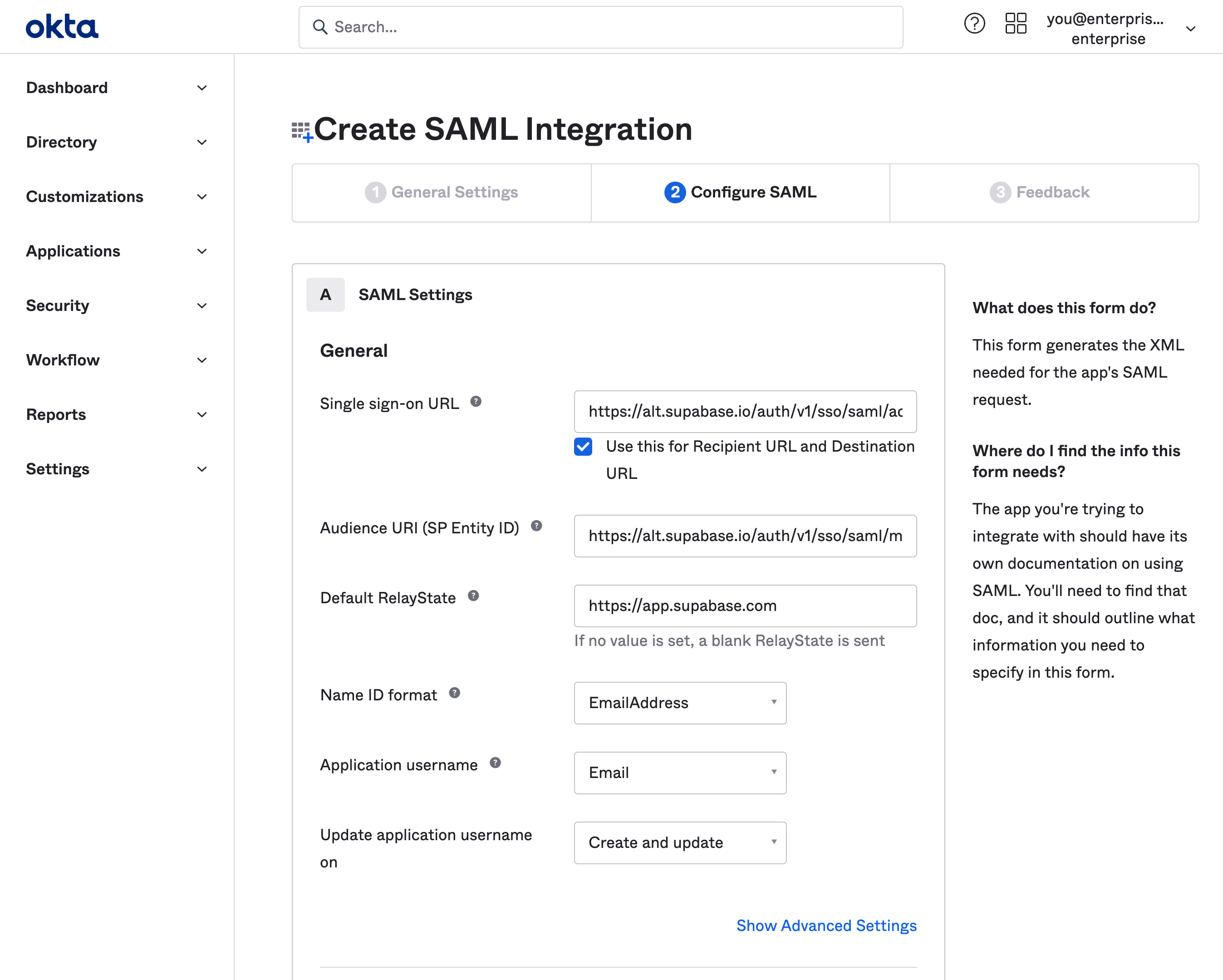
## Step 5: Fill out attribute statements \[#add-attribute-statements]
Attribute Statements allow Supabase to get information about your Okta users on each login.
**A `email` to `user.email` statement is required.** Other mappings shown below are optional and configurable depending on your Okta setup. If in doubt, replicate the same config as shown. You will use this mapping later in [Step 10](#dashboard-configure-attributes).
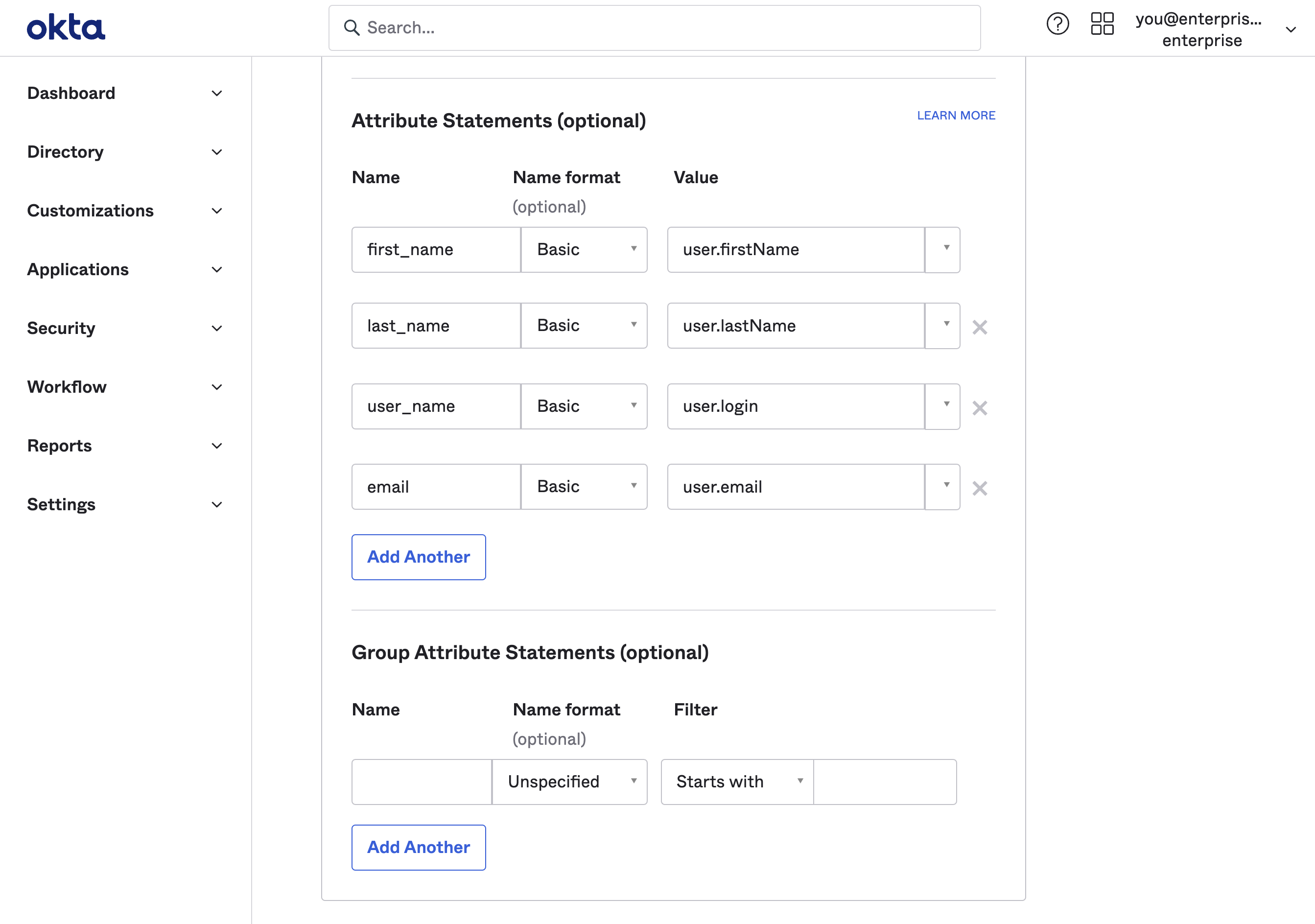
## Step 6: Obtain IdP metadata URL \[#idp-metadata-url]
Supabase needs to finalize enabling single sign-on with your Okta application.
To do this scroll down to the *SAML Signing Certificates* section on the *Sign On* tab of the *Supabase* application. Pick the *SHA-2* row with an *Active* status. Click on the *Actions* dropdown button and then on the *View IdP Metadata*.
This will open up the SAML 2.0 Metadata XML file in a new tab in your browser. You will need to enter this URL later in [Step 9](#dashboard-configure-metadata).
The link usually has this structure: `https://.okta.com/apps//sso/saml/metadata`
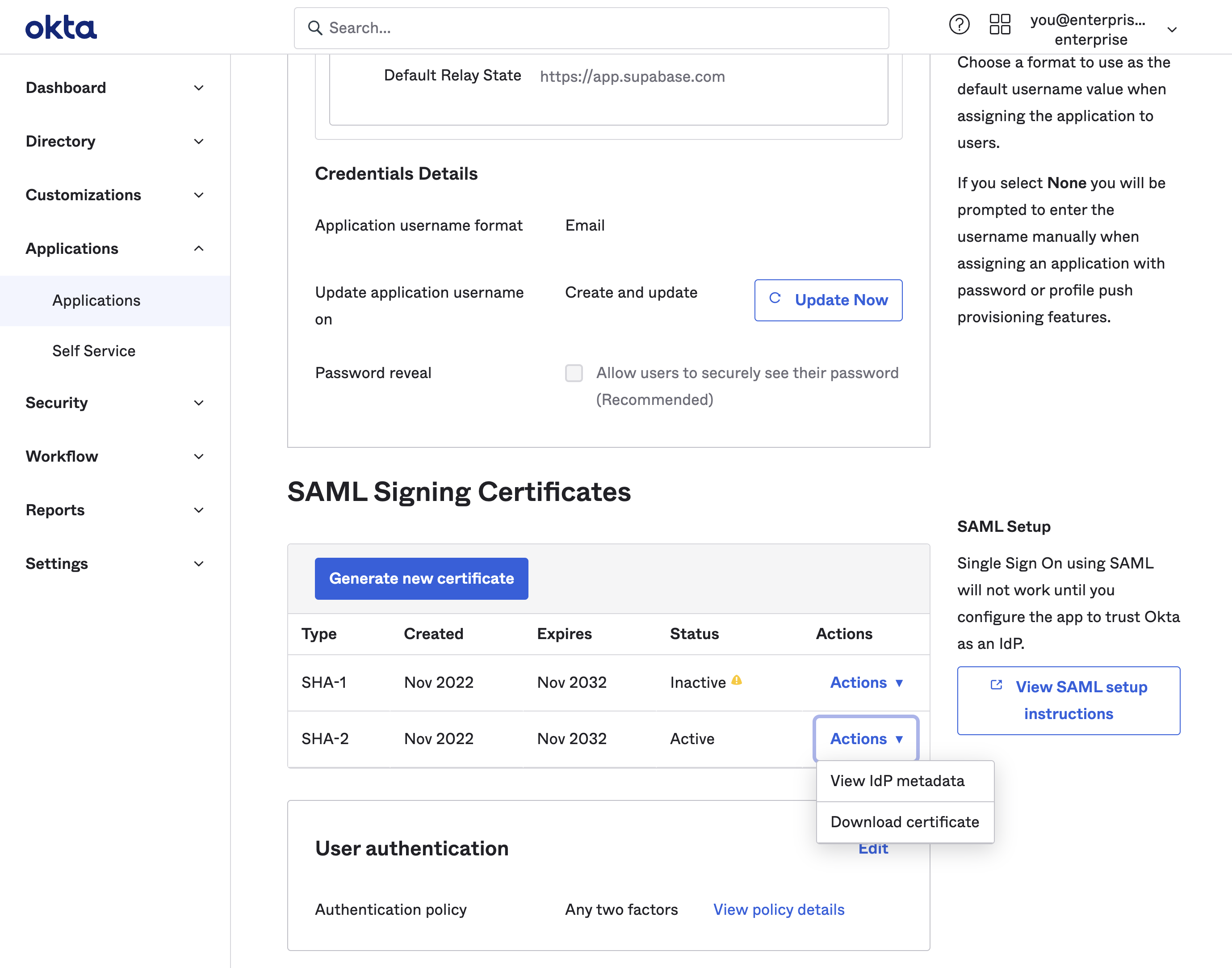
## Step 7: Enable SSO in the Dashboard \[#dashboard-enable-sso]
1. Visit the [SSO tab](/dashboard/org/_/sso) under the Organization Settings page. 
2. Toggle **Enable Single Sign-On** to begin configuration. Once enabled, the configuration form appears. 
## Step 8: Configure domains \[#dashboard-configure-domain]
Enter one or more domains associated with your users email addresses (e.g., `supabase.com`).
These domains determine which users are eligible to sign in via SSO.

If your organization uses more than one email domain - for example, `supabase.com` for staff and `supabase.io` for contractors - you can add multiple domains here. All listed domains will be authorized for SSO sign-in.

We do not permit use of public domains like `gmail.com`, `yahoo.com`.
Each SSO provider can be configured with different email domains. For multi-environment setups (Dev/Staging/Prod), we recommend using IdP-initiated flow with multiple SAML apps under the same domain rather than domain-based routing. For more details, see the [Multiple SSO Providers guide](/docs/guides/platform/sso/multiple-providers).
## Step 9: Configure metadata \[#dashboard-configure-metadata]
Enter the metadata URL you obtained from [Step 6](#idp-metadata-url) into the Metadata URL field:

## Step 10: Configure attribute mapping \[#dashboard-configure-attributes]
Enter the SAML attributes you filled out in [Step 5](#add-attribute-statements) into the Attribute Mapping section.
If you did not customize your settings you may save some time by clicking the **Okta** preset.
## Step 11: Join organization on signup (optional) \[#dashboard-configure-autojoin]
**Recommended workflow:** Start with auto-join **disabled** to test your SSO configuration. Once SSO login is working correctly, enable auto-join if desired.
By default this setting is disabled, users logging in via SSO will not be added to your organization automatically.

Toggle this on if you want SSO-authenticated users to be **automatically added to your organization** when they log in via SSO. Auto-join applies on **every login**, not just first signup - this makes it safe to test SSO before enabling this feature.

When auto-join is enabled, you can choose the **default role** for new users:

We recommend choosing **Developer** as the default role (principle of least privilege) and promoting users individually as needed.
Visit [access-control](/docs/guides/platform/access-control) documentation for details about each role.
## Step 12: Save changes \[#dashboard-configure-save]
When you click **Save changes**, your new SSO configuration is applied immediately. From that moment, any user with an email address matching one of your configured domains who visits your organization's sign-in URL will be routed through the SSO flow.
**Next step: Test your SSO configuration**
Before rolling out SSO to your organization, we strongly recommend thorough testing. Visit our [SSO Testing and Best Practices](/docs/guides/platform/sso/testing-best-practices) guide for:
* Step-by-step testing instructions
* How to verify auto-join works correctly
* Common issues and troubleshooting
* Security best practices
* Pre-launch checklist
**Testing in Okta sandbox:** If your organization has an Okta sandbox environment, consider testing your SSO configuration there first before applying to production.
# SSO Testing and Best Practices
After configuring your SSO provider, thorough testing is essential before rolling out to your organization. This guide covers testing procedures, troubleshooting common issues, and best practices for maintaining a secure SSO setup.
## Pre-configuration checklist
Before you begin testing, verify:
* Organization has Team or Enterprise plan
* Login flow type decided (IdP-initiated, SP-initiated, or both) - see [Choosing a Login Flow](/docs/guides/platform/sso/choosing-login-flow)
* Email domains identified (only required if using SP-initiated)
* Auto-join settings and default role are decided
* **At least one non-SSO owner account exists** (critical safety requirement)
* Certificate expiration dates are documented (especially for Google Workspace)
## Testing login flows
Before testing auto-join and other features, verify which login flows work for your SSO configuration. See [Understanding SSO Login Flows](/docs/guides/platform/sso/login-flows) for technical details.
### Testing IdP-initiated login
IdP-initiated login is always available and doesn't require domain configuration. This should be your primary test.
**Test procedure:**
1. **Access from identity provider:**
* Open your IdP dashboard (Okta, Azure AD, Google Workspace)
* Locate your Supabase app tile or bookmark
* Click the app tile
2. **Verify authentication:**
* If already authenticated with IdP: Immediate redirect to Supabase
* If not authenticated: Complete IdP login flow, then redirect
* Check you're logged into the correct organization
* Verify user profile information is populated correctly
3. **Confirm success:**
* No error messages appear
* Organization dashboard loads properly
* User attributes (name, email) mapped correctly
**Expected results:**
* ✅ Direct login from IdP with no intermediate steps
* ✅ Works regardless of domain configuration
* ✅ User information properly mapped from IdP
### Testing SP-initiated login
SP-initiated login requires domain configuration. Only test this if you've enabled SP-initiated flow.
If you haven't configured domains or have "Enable SP-initiated login" disabled, skip this test. SP-initiated will not work without domain configuration.
**Prerequisites:**
* "Enable SP-initiated login" toggle is **ON**
* At least one email domain configured
**Test procedure:**
1. **Start at Supabase:**
* Visit [Sign in with SSO](/dashboard/sign-in-sso)
* Or click "Sign in with SSO" from main sign-in page
2. **Enter email:**
* Use email with matching configured domain
* Click "Continue"
3. **Verify redirect chain:**
* Should redirect to your identity provider
* Complete authentication if needed
* Should redirect back to Supabase
* Check you're in correct organization
4. **Test domain matching:**
* Try email with non-matching domain
* Should receive error: "No SSO provider found"
* Confirms domain-based routing works
**Expected results:**
* ✅ Users with matching domains redirected to IdP
* ✅ Non-matching domains show clear error message
* ✅ Successful authentication redirects back to Supabase
### Testing without domains (IdP-initiated only)
This is a critical test for domainless providers, which enable multiple SAML apps per domain.
**Test scenario:**
You've configured SSO with:
* "Enable SP-initiated login" **OFF** (or no domains configured)
* IdP metadata configured
* Attribute mappings configured
**Test procedure:**
1. **Verify SP-initiated is unavailable:**
* Visit [Sign in with SSO](/dashboard/sign-in-sso)
* Enter your email address
* Expected: Error message "No SSO provider found"
* This is correct behavior (no domains = no SP-initiated)
2. **Verify IdP-initiated works:**
* Open IdP dashboard
* Click Supabase app tile
* Should successfully log in
* Verify correct organization access
3. **Confirm multi-environment pattern works (if applicable):**
* If you have multiple environments (Dev/Staging/Prod)
* Each should have separate app tile in IdP
* Click each tile individually
* Verify each routes to correct organization
**Expected results:**
* ✅ IdP-initiated login works perfectly
* ❌ SP-initiated login unavailable (expected)
* ✅ Multiple environments accessible via different tiles
* ✅ No domain conflicts between environments
**Multiple environments:** If you're setting up Dev/Staging/Prod, this domainless pattern is recommended. See [Multiple SSO Providers](/docs/guides/platform/sso/multiple-providers) for detailed configuration guidance.
### Login flow verification checklist
* IdP-initiated login works from IdP dashboard
* SP-initiated login works (if domains configured)
* SP-initiated properly blocked if no domains configured
* Domain matching works correctly for SP-initiated
* Non-matching domains show appropriate errors
* Multiple environments route correctly (if using multiple providers)
* Both flows work simultaneously (if both enabled)
## Testing SSO login flow
### Basic login test
1. **Navigate to the SSO sign-in page**:
* Visit [Sign in with SSO](/dashboard/sign-in-sso)
* Or click "Sign in with SSO" from the main Supabase sign-in page
2. **Enter your email address**:
* Use an email with a domain configured in your SSO settings
* Click "Continue"
3. **Verify redirect to identity provider**:
* You should be redirected to your identity provider (Okta, Azure AD, Google Workspace)
* If already signed in to your IdP, you may be automatically redirected back
* If not signed in, complete the IdP login flow
4. **Confirm successful sign-in**:
* You should be redirected back to Supabase dashboard
* Your profile should show your SSO identity
* Check that your user information is populated correctly
### Multi-user testing
Test with 2-3 additional users to verify:
* Users with matching email domains can sign in via SSO
* User attributes (name, email) are mapped correctly
* Users receive appropriate access to organization (if using auto-join)
* Users without matching domains cannot use SSO for this organization
## Testing auto-join
**Recent improvement:** Auto-join now applies on EVERY login, not just first signup. This resolves a common issue where org owners would test with auto-join disabled, enable it, then log in again expecting to auto-join.
### Recommended testing workflow
1. **Start with auto-join disabled**:
* Navigate to [SSO settings](/dashboard/org/_/sso)
* Ensure "Join organization on signup" is **disabled**
* Configure your SSO provider
* Test basic SSO login (see above)
2. **Enable auto-join after successful test**:
* Return to [SSO settings](/dashboard/org/_/sso)
* Toggle "Join organization on signup" to **enabled**
* Select default role (recommended: **Developer**)
* Click "Save changes"
3. **Test auto-join with your account**:
* **Log out completely** from Supabase
* Sign in again via SSO
* Verify you were automatically added to the organization
* Check you received the correct default role
4. **Test with additional users**:
* Have colleagues with matching email domains sign in via SSO
* They should automatically join the organization
* Verify they received the correct default role
* Check organization members list at `/dashboard/org/_/team`
5. **Test domain restrictions (if using SP-initiated)**:
* Try signing in with an email from a non-configured domain
* User should be able to sign in but will NOT see the organization
* This confirms domain-based access control is working
* Note: With IdP-initiated only, domain matching doesn't apply
6. **Test idempotency (prevents duplicate memberships)**:
* Log in again with an account that's already a member
* Verify no error occurs
* Check members list - should be no duplicate entry
* Confirm role hasn't changed unexpectedly
* Expected: Auto-join gracefully handles existing members
7. **Test with domainless (IdP-initiated only) configuration**:
This test is critical if you're using multiple environments under the same domain. See [Multiple SSO Providers](/docs/guides/platform/sso/multiple-providers) for details.
* If you configured SSO without domains (IdP-initiated only):
* Enable auto-join
* New user accesses via IdP app tile
* Verify auto-join works without domain check
* User automatically added to organization
* Correct role assigned
* Expected: Auto-join works for IdP-initiated regardless of email domain
8. **Test auto-join re-enablement**:
* Disable auto-join
* Have new user sign in via SSO
* Verify they are NOT added to organization
* Re-enable auto-join
* Same user logs out and logs in again
* Verify they ARE now added to organization
* Expected: Existing SSO users auto-join when feature is enabled
### Auto-join verification checklist
* Auto-join works when enabled
* Users receive correct default role
* Non-matching domains are excluded (if using SP-initiated with domains)
* Existing users auto-join on their next login (not just new signups)
* Auto-join can be disabled and re-enabled as needed
* Auto-join is idempotent (no duplicate memberships)
* Auto-join works with IdP-initiated only (no domains)
* Auto-join works with both IdP and SP-initiated flows
## Testing invitations
**Recent improvement:** You can now explicitly choose whether an invitation requires SSO or non-SSO authentication. Previously, this was inherited from the inviter's account type, which caused confusion.
### Creating and testing invitations
1. **Create SSO-required invitation**:
* Navigate to [organization team settings](/dashboard/org/_/team)
* Click "Invite" to create a new invitation
* Select **"Require SSO"** option
* Enter recipient email and select role
* Send invitation
* Recipient must log in via SSO to accept
2. **Create non-SSO invitation**:
* Create a new invitation
* Select **"Non-SSO"** option
* Send invitation
* Recipient can use password or social login to accept
3. **Test SSO mismatch scenario**:
* Create an SSO-required invitation
* Have recipient try to accept while logged in with a non-SSO account
* Error should display: "Invite token SSO provider does not match the one you are logged in with"
* Recipient should log out and sign in via SSO
* Can then successfully accept the invitation
### Common invitation scenarios
* **All-SSO organization**: Always select "Require SSO" for invitations
* **Mixed organization**: Choose based on recipient's authentication method
* **Transitioning to SSO**: Start with non-SSO users, gradually add SSO users, maintain non-SSO owner before removing old authentication methods
### Invitation verification checklist
* SSO-required invitations work correctly
* Non-SSO invitations work correctly
* SSO mismatch error message is clear
* Mixed authentication organization functions properly
* Invitations can be resent if needed
If you're configuring multiple SSO providers for different environments (dev/staging/prod), the testing steps outlined here apply to each provider individually. For advanced multi-provider configuration strategies, see the [Multiple SSO Providers guide](/docs/guides/platform/sso/multiple-providers).
## Testing SSO account restrictions
SSO accounts have specific restrictions to prevent accidental organization lockouts.
**Safety mechanism:** SSO accounts cannot delete SSO providers. This prevents scenarios where an SSO user could accidentally lock out the entire organization by deleting the SSO provider they use to authenticate.
### Testing SSO account deletion restrictions
1. **Log in with SSO account:**
* Authenticate via SSO (IdP or SP-initiated)
* Navigate to [SSO settings](/dashboard/org/_/sso)
* Verify you are an organization owner
2. **Attempt to delete SSO provider:**
* Try to delete the SSO provider
* **Expected:** Error message preventing deletion
* Error: "Only a non-SSO account may delete an SSO Provider"
* Deletion should be blocked
3. **Verify other SSO operations work:**
* SSO accounts CAN read SSO configuration
* SSO accounts CAN update SSO settings
* SSO accounts CAN disable (but not delete) SSO provider
* Only deletion is restricted
**Expected results:**
* ❌ SSO accounts cannot delete SSO providers
* ✅ Clear error message explains the restriction
* ✅ Other SSO management operations still work
### Testing with non-SSO owner account
1. **Log in with non-SSO owner:**
* Use password or social auth account
* Must be organization owner
* Navigate to [SSO settings](/dashboard/org/_/sso)
2. **Verify deletion capability:**
* Non-SSO owners CAN delete SSO providers
* Deletion subject to additional safety checks (see next section)
* System allows proceeding to deletion flow
**Expected results:**
* ✅ Non-SSO owners CAN access deletion functionality
* ✅ Safety checks still apply (non-SSO account requirement)
### SSO account restrictions checklist
* SSO accounts cannot delete SSO providers
* SSO accounts CAN update SSO settings
* SSO accounts CAN disable SSO providers
* Non-SSO owners CAN delete SSO providers
* Error messages clearly explain the restriction
* Restriction applies to all SSO accounts (not just certain roles)
## Common issues and troubleshooting
Based on customer pain points that previously required support intervention:
### Critical issues
#### "Enabled auto-join but users aren't automatically joining"
**Common workflow that causes this:**
1. Org owner tests SSO with auto-join disabled
2. Enables auto-join after testing
3. Logs in again expecting to auto-join but nothing happens
**Solution:**
* Auto-join now applies on **every login**, not just first signup
* To test: Enable auto-join, log out completely, log back in via SSO
* If still not working, verify domain configuration matches user email exactly
#### "Can't invite users with the right authentication type"
**Previous limitation:**
* Invitation type was inherited from inviter's account type
* Non-SSO owners couldn't send SSO invitations
* SSO owners couldn't send non-SSO invitations
**Solution:**
* When creating invitations, explicitly choose "Require SSO" or "Non-SSO"
* Mixed organizations are now fully supported
* Both SSO and non-SSO users can coexist in the same organization
#### "Invitation acceptance shows 'SSO provider mismatch' error"
**Cause:** User is logged in with wrong authentication method for the invitation
**Solution:**
1. Check if invitation requires SSO or non-SSO login
2. Log out completely
3. Sign in with the correct method (SSO or password/social)
4. Accept the invitation
5. Contact the person who sent the invitation if unsure about the type
#### "Deleted the SSO provider and now members can't log in"
**Recent safety improvements:**
* System now automatically removes all SSO members before deletion
* Must have at least one non-SSO owner before deletion is allowed
**Best practice:**
* Add a non-SSO owner account **before** deleting SSO provider
* Communicate to affected users before deletion
* Consider disabling rather than deleting if change is temporary
## Testing safe provider deletion
**Critical safety checks:** Deleting an SSO provider automatically removes ALL SSO members from the organization. The system enforces multiple safety checks to prevent complete organization lockout.
**Only test deletion in non-production environments or test organizations.** Do not test this in your actual production organization unless you fully understand the consequences.
### Understanding deletion behavior
When an SSO provider is deleted:
1. System verifies at least one non-SSO owner account exists
2. **All SSO members are automatically removed** from the organization
3. SSO provider configuration is deleted
4. Organization continues operating with remaining non-SSO members
This behavior prevents "orphaned" SSO accounts that can no longer authenticate.
### Test 1: Deletion without non-SSO accounts (should fail)
**Setup:**
* Organization with only SSO accounts
* All owners authenticate via SSO
* No password or social auth owners exist
**Test procedure:**
1. **Verify current state:**
* Check [team settings](/dashboard/org/_/team)
* Confirm all owners are SSO accounts
* No non-SSO owner exists
2. **Attempt deletion:**
* Navigate to [SSO settings](/dashboard/org/_/sso)
* Try to delete SSO provider
* **Expected:** Error preventing deletion
* Error message: "At least one non-SSO account is required to maintain organization access"
3. **Verify organization state:**
* SSO provider still exists
* All SSO members still have access
* No partial deletion occurred
**Expected result:** ❌ Deletion blocked with clear error message
### Test 2: Add non-SSO owner and retry deletion (should succeed)
**Warning:** This test WILL remove all SSO members. Only perform in test organizations.
**Setup:**
1. **Add non-SSO owner:**
* Create or invite a non-SSO user (password or social login)
* Promote to owner role
* **Critical:** Verify non-SSO owner can log in BEFORE deletion
* Store credentials securely
2. **Document SSO members:**
* Note current SSO member count
* Document SSO member email addresses (for verification)
**Test procedure:**
1. **Attempt deletion as non-SSO owner:**
* Log in with non-SSO owner account
* Navigate to [SSO settings](/dashboard/org/_/sso)
* Delete SSO provider
* Confirm deletion
2. **Verify deletion results:**
* All SSO members removed from organization
* Check [team settings](/dashboard/org/_/team)
* Only non-SSO members should remain
* SSO configuration completely removed
3. **Verify non-SSO access:**
* Non-SSO owner retains full access
* Organization remains functional
* Can invite new members (non-SSO invitations)
**Expected result:** ✅ Deletion succeeds, SSO members removed, non-SSO access preserved
### Test 3: Member removal during deletion
**Test in isolated environment with test accounts.**
**Setup:**
1. Create test organization
2. Enable SSO
3. Add multiple SSO members (3-5 test users)
4. Add at least one non-SSO owner
5. Document member list before deletion
**Test procedure:**
1. **Track members before deletion:**
* Note SSO member count (e.g., 5 SSO members)
* Note SSO member email addresses
* Document their roles
2. **Delete SSO provider:**
* Log in as non-SSO owner
* Delete SSO provider
* System may show member count being removed
3. **Verify member removal:**
* Check organization members list
* All SSO members should be gone
* Only non-SSO members remain
* Previous SSO users cannot access org
**Expected result:** All SSO members cleanly removed, no orphaned accounts
### Test 4: Mixed authentication scenario
**Setup:**
* Organization with both SSO and non-SSO members
* SSO members: employees (via SSO)
* Non-SSO members: contractors (password auth)
* Mixed owner types
**Test procedure:**
1. **Ensure non-SSO owner exists:**
* Verify at least one non-SSO owner
* Test their login before deletion
2. **Delete SSO provider:**
* System allows deletion (non-SSO owner exists)
* Confirm deletion
3. **Verify selective removal:**
* SSO members removed (employees)
* Non-SSO members retained (contractors)
* Organization still functional
* Non-SSO owners can manage organization
**Expected result:** ✅ Selective removal - only SSO members affected
### Safe deletion verification checklist
* Cannot delete without non-SSO owner account
* Error message clearly explains requirement
* Adding non-SSO owner enables deletion
* All SSO members removed upon deletion
* Non-SSO members unaffected by SSO provider deletion
* Organization remains accessible via non-SSO accounts
* SSO configuration completely removed after deletion
* Non-SSO owner account tested BEFORE deletion
### Best practices for safe deletion
**Before deleting SSO provider:**
1. **Create dedicated non-SSO owner account**
* Use password authentication
* **Test that this account can log in**
* Store credentials in secure password manager
* Verify owner permissions
2. **Communication plan:**
* Notify all SSO members before deletion
* Explain they will lose organization access
* Provide timeline for deletion
* Offer alternative access if needed (re-invite as non-SSO)
3. **Documentation:**
* Document which members will be removed
* Plan for re-adding users if needed
* Have rollback plan (reconfigure SSO if needed)
**After deletion:**
1. **Verify organization function:**
* Test non-SSO owner access
* Verify critical functionality works
* Check that SSO members removed
2. **User communication:**
* Confirm to users that deletion complete
* Provide instructions for alternative access
* Answer questions about regaining access
### Configuration issues
#### "SSO sign-in doesn't work at all"
Common causes:
* Metadata URL/file incorrect or expired
* Certificate expired (especially Google Workspace - check during setup)
* Attribute mapping misconfigured
* User not assigned to Supabase app in identity provider
* Email domain not configured in Supabase SSO settings
* User email domain doesn't match configured domains
**Troubleshooting steps:**
1. Verify metadata URL/file is accessible and current
2. Check certificate expiration date
3. Verify attribute mappings (email mapping is required)
4. Confirm user is assigned to app in IdP
5. Check domain configuration in Supabase matches user email
6. Review IdP logs for authentication errors
#### "Attribute mapping errors or missing user data"
**Requirements:**
* Email mapping to `email` is **required**
* Attribute keys must be spelled exactly as shown in provider
* Use provider presets (Okta, Azure, G Suite) to avoid errors
**Troubleshooting:**
1. Verify email attribute is mapped correctly
2. Check attribute names match your IdP configuration exactly
3. Test that mappings return expected user data
4. Use IdP test tools to see what attributes are being sent
#### "Cannot delete SSO provider"
**Error:** "At least one non-SSO account is required"
**Solution:**
1. Create or convert an existing member to a non-SSO owner account
2. Verify the non-SSO owner can log in
3. Then proceed with SSO provider deletion
**Why this is required:** Prevents complete organization lockout if SSO becomes unavailable
## Best practices
### Security and safety
#### CRITICAL: Maintain at least one non-SSO owner account
* **Required** to prevent complete organization lockout
* System enforces this when deleting SSO provider
* Create dedicated non-SSO owner **before** enabling SSO
* Store credentials securely in a password manager
* Verify this account can log in before critical changes
#### Monitor certificate expiration
* Set calendar reminders **30 days before** certificate expiration
* Especially important for Google Workspace (certificates shown during setup)
* Test SSO after certificate renewal
* Update metadata in Supabase after IdP certificate renewal
* Communicate planned renewal to team
#### Configure domains carefully
* Use specific corporate email domains only
* Public domains (gmail.com, yahoo.com, etc.) are automatically blocked
* Be cautious with domains you don't fully control
* Multiple domains supported for contractors/acquisitions
* Document which domains are configured and why
#### Regular access reviews
* Periodically review organization member list
* Verify auto-join role is still appropriate
* Check for orphaned or inactive accounts
* Coordinate with IT team on user access reviews
* Remove members who no longer need access
### Configuration and testing
#### Recommended SSO setup workflow
1. Create or verify non-SSO owner account exists
2. Configure SSO provider with auto-join **DISABLED**
3. Test SSO login with your own account
4. Verify attribute mappings are correct
5. Test with 2-3 additional users
6. Enable auto-join if desired
7. Test auto-join functionality thoroughly
8. Communicate SSO availability to team
#### Role selection for auto-join
* Default to **"Developer"** role (principle of least privilege)
* Avoid "Owner" or "Administrator" for auto-join
* Promote users individually as needed
* Review and document your access control strategy
* See [access control documentation](/docs/guides/platform/access-control) for role details
#### Attribute mapping
* Email mapping is **REQUIRED**
* Use provider presets (Okta, Azure, G Suite) when available
* Document custom mappings for future reference
* Test mappings return expected user data
* Keep mappings consistent across environments
#### Multi-environment strategy
* Consider separate providers for dev/staging/prod
* Test configuration changes in non-production first
* Keep provider configurations synchronized
* Document differences between environments
* See [Multiple SSO Providers guide](/docs/guides/platform/sso/multiple-providers) for details
### Operations and maintenance
#### Before making SSO changes
* Notify team members in advance
* Schedule during low-usage period if possible
* Have rollback plan ready
* Keep Supabase support contact information handy
* Document what you're changing and why
#### After SSO configuration changes
* Test login immediately
* Verify auto-join still works (if enabled)
* Check that invitations are working
* Confirm no users are locked out
* Monitor for support requests from team
#### Before deleting SSO provider
* Verify at least one non-SSO owner exists (system enforces)
* Understand that **all SSO members will be removed automatically**
* Communicate to affected users **before** deletion
* Consider disabling rather than deleting if temporary
* Have plan for users to regain access if needed
#### Coordinating with IT/Security team
* SSO changes may affect compliance requirements
* Certificate renewals require coordination
* User access reviews should include Supabase
* Incident response plans should consider SSO dependencies
* Document SSO configuration in your organization's runbook
## Final verification checklist
Before rolling out SSO to your organization:
**Authentication & Login Flows:**
* IdP-initiated login works from IdP dashboard
* SP-initiated login works (if domains configured)
* Appropriate login flow chosen for your use case
* Domain configuration correct (or intentionally empty for IdP-only)
* Multiple environments route correctly (if using multiple providers)
**Auto-Join Functionality:**
* Auto-join adds users to correct organization (if enabled)
* Auto-joined users receive correct default role
* Auto-join works on first login (not just signup)
* Existing users auto-join when feature enabled
* Auto-join is idempotent (no duplicate memberships)
* Auto-join works with IdP-initiated (no domains required)
* Non-matching domains excluded (if using SP-initiated)
**Invitations:**
* SSO-required invitations work correctly
* Non-SSO invitations work correctly
* Invitation types can be explicitly chosen
* SSO mismatch errors are clear
**Safety & Access Controls:**
* At least one non-SSO owner account exists
* Non-SSO owner account can log in successfully
* Non-SSO credentials stored securely
* SSO account deletion restrictions understood and tested
* Safe deletion behavior verified (if tested)
**Configuration:**
* Certificate expiration date documented with calendar reminders
* Team notified of SSO availability
* Login instructions provided (IdP tile and/or supabase.com)
* Rollback plan documented
* Support contact information available
**Testing Completed:**
* Tested with multiple user accounts
* Both login flows tested (if both enabled)
* Auto-join behavior verified
* SSO account restrictions confirmed
* Domain restrictions validated (if applicable)
* Multi-environment isolation verified (if using multiple providers)
## Need help?
If you encounter issues not covered in this guide, contact your Supabase support representative for assistance. When reaching out, include:
* Organization name and URL
* SSO provider type (Okta, Azure AD, Google Workspace, etc.)
* Specific error messages
* Steps you've already tried
* Whether the issue affects all users or specific individuals
# Getting started with Read Replicas
Deploy read-only databases across multiple regions, for lower latency and better resource management.
## Prerequisites
Read Replicas are available for all projects on the Pro, Team and Enterprise plans. Spin one up now over at the [Infrastructure Settings page](/dashboard/project/_/settings/infrastructure).
Projects must meet these requirements to use Read Replicas:
1. Running on AWS.
2. Running on at least a [Small compute add-on](/docs/guides/platform/compute-add-ons).
* Read Replicas are started on the same compute instance as the Primary to keep up with changes.
3. Running on Postgres 15+.
* For projects running on older versions of Postgres, you need to [upgrade to the latest platform version](/docs/guides/platform/migrating-and-upgrading-projects#pgupgrade).
4. Not using [legacy logical backups](/docs/guides/platform/backups#point-in-time-recovery)
* Physical backups are automatically enabled if using [Point in time recovery (PITR)](/docs/guides/platform/backups#point-in-time-recovery)
## Creating a Read Replica
To add a Read Replica, go to the [Database Replication page](/dashboard/project/_/database/replication) in your project dashboard.
You can also manage Read Replicas using the Management API (beta functionality):
```bash
# Get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
export PROJECT_REF="your-project-ref"
# Create a new Read Replica
curl -X POST "https://api.supabase.com/v1/projects/$PROJECT_REF/read-replicas/setup" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"read_replica_region": "us-east-1"
}'
# Delete a Read Replica
curl -X POST "https://api.supabase.com/v1/projects/$PROJECT_REF/read-replicas/remove" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"database_identifier": "abcdefghijklmnopqrst"
}'
```
Projects on an XL compute add-on or larger can create up to five Read Replicas. Projects on compute add-ons smaller than XL can create up to two Read Replicas. All Read Replicas inherit the compute size of their Primary database.
### Deploying a Read Replica
We deploy a Read Replica using a physical backup as a starting point, and a combination of write ahead logging (WAL) file archives and direct replication from the Primary database to catch up. Both components may take significant time to complete, depending on your specific workload.
The time to restore from a physical backup is dependent and directly related to the database size of your project. The time taken to catch up to the primary using WAL archives and direct replication is dependent on the level of activity on the Primary database. A more active database produces a larger number of WAL files that need to be processed.
Along with the progress of the deployment, the dashboard displays rough estimates for each component.
## Replication method details
We use a hybrid approach to replicate data from a Primary to its Read Replicas, combining the native methods of streaming replication and file-based log shipping.
### Streaming replication
Postgres generates a Write Ahead Log (WAL) as database changes occur. With streaming replication, these changes stream from the Primary to the Read Replica server. The WAL alone is sufficient to reconstruct the database to its current state.
This replication method is fast, since the Primary streams changes directly to the Read Replica. However, it faces challenges when the Read Replica can't keep up with the WAL changes from its Primary. This can happen when the Read Replica is too small, running on degraded hardware, or has a heavier workload running.
To address this, Postgres provides tunable configuration, like `wal_keep_size`, to adjust the WAL retained by the Primary. If the Read Replica fails to "catch up" before the WAL surpasses the `wal_keep_size` setting, it terminates the replication. Tuning is an art - the amount of WAL required varies for every situation.
### File-based log shipping
In this replication method, the Primary continuously buffers WAL changes to a local file and then sends the file to the Read Replica. If multiple Read Replicas are present, files could also be sent to an intermediary location accessible by all replicas.
The Read Replica then reads the WAL files and applies those changes. There is higher replication lag than streaming replication since the Primary buffers the changes locally first. It also means there is a small chance that WAL changes do not reach Read Replicas if the Primary goes down before the file is transferred. In these cases, if the Primary fails a Replica using streaming replication would (in most cases) be more up-to-date than a Replica using file-based log shipping.
### File-based log shipping meets streaming replication
We bring these two methods together to achieve quick, stable, and reliable replication. Each method addresses the limitations of the other. Streaming replication minimizes replication lag, while file-based log shipping provides a fallback. For file-based log shipping, we use our existing Point In Time Recovery (PITR) infrastructure. We regularly archive files from the Primary using [WAL-G](https://github.com/wal-g/wal-g), an open source archival and restoration tool, and ship the WAL files to off-site, durable cloud storage, such as S3.
We combine it with streaming replication to reduce replication lag. Once WAL-G files have been synced from S3, Read Replicas connect to the Primary and stream the WAL directly.
### Restart or compute add-on change behaviour
When you restart a project that utilizes Read Replicas, or change the compute add-on size, the Primary database gets restarted first. During this period, the Read Replicas remain available.
Once the Primary database has completed restarting (or resizing, in case of a compute add-on change) and become available for usage, all the Read Replicas are restarted (and resized, if needed) concurrently.
## Operations blocked by Read Replicas
### Project upgrades and data restorations
The following procedures require all Read Replicas for a project to be brought down before performing them:
1. [Project upgrades](/docs/guides/platform/migrating-and-upgrading-projects#pgupgrade)
2. [Data restorations](/docs/guides/platform/backups#pitr-restoration-process)
These operations need to complete before you can re-deploy Read Replicas.
### Monitoring replication lag
You can monitor replication lag for a specific Read Replica through a project dashboard on the [**Database Reports page**](/dashboard/project/_/observability/database). Read Replicas have an additional chart under **Replica Information** displaying historical replication lag in seconds.
You can see realtime replication lag in seconds on the [**Infrastructure Settings** page](/dashboard/project/_/settings/infrastructure). This is the value on top of the Read Replica.
There is no single threshold to indicate when you should address replication lag. It is dependent on the requirements of your project.
If you are already ingesting your [project's metrics](/docs/guides/platform/metrics#accessing-the-metrics-endpoint) into your own environment, you can also keep track of replication lag and set alarms with the `physical_replication_lag_physical_replica_lag_seconds` metric.
### Addressing high replication lag
Some common sources of high replication lag include:
1. **Exclusive locks on tables on the Primary**: Operations such as `drop table` and `reindex` take an access-exclusive lock on the table. This can result in increasing replication lag for the duration of the lock.
2. **Resource Constraints on the database**: Heavy utilization on the primary or the replica, if run on an under-resourced project, can result in high replication lag. This includes the characteristics of the disk being utilized (IOPS, Throughput).
3. **Long-running transactions on the Primary**: Transactions that run for a long-time on the primary can also result in high replication lag. You can use the `pg_stat_activity` view to identify and terminate such transactions if needed. `pg_stat_activity` is a live view, and does not offer historical data on transactions that might have been active for a long time in the past.
High replication lag can result in stale data returned for queries executed against the affected read replicas.
You can find additional resources on replication lag in [the Google documentation](https://cloud.google.com/sql/docs/postgres/replication/replication-lag), [the AWS documentation](https://repost.aws/knowledge-center/rds-postgresql-replication-lag), and [the several nines blog](https://severalnines.com/blog/what-look-if-your-postgresql-replication-lagging/).
## Troubleshooting
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### An "Init failed" status
The replica status "Init failed" in the dashboard indicates that the Read Replica has failed to deploy. Some possible scenarios as to why a Read Replica deployment may have failed are the following:
* An underlying instance failed to come up.
* A network issue leading to inability to connect to the Primary database.
* A possible incompatible database settings between the Primary and Read Replica databases.
* Platform issues.
* Very high active workloads combined with large (50+ GB) database sizes
It is safe to drop this failed Read Replica, and in the event of a transient issue, attempt to spin up another one. If spinning up Read Replicas for your project consistently fails, check the[status page](https://status.supabase.com) for any ongoing incidents, or [open a support ticket](/dashboard/support/new). To aid the investigation, do not bring down the recently failed Read Replica.
{/* supa-mdx-lint-enable-next-line Rule001HeadingCase */}
# Backup and Restore using the CLI
Learn how to backup and restore projects using the Supabase CLI
# Migrating the database
## Backup database using the CLI
Install the [Supabase CLI](/docs/guides/local-development/cli/getting-started).
Install [Docker Desktop](https://www.docker.com) for your platform.
On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session).
Use the [Session pooler](/dashboard/project/_?showConnect=true\&method=session) connection string by default. If your network supports [IPv6](https://test-ipv6.com/) or you have the [IPv4 add-on](/docs/guides/platform/ipv4-address) enabled, use the direct connection string.
Session pooler connection string:
```bash
postgresql://postgres.[PROJECT-REF]:[YOUR-PASSWORD]@aws-0-us-east-1.pooler.supabase.com:5432/postgres
```
Direct connection string:
```bash
postgresql://postgres.[PROJECT-REF]:[YOUR-PASSWORD]@db.[PROJECT-REF].supabase.com:5432/postgres
```
Reset the password in the [Database Settings](/dashboard/project/_/database/settings).
Replace `[YOUR-PASSWORD]` in the connection string with the database password.
Run these commands after replacing `[CONNECTION_STRING]` with your connection string from the previous steps:
```bash
supabase db dump --db-url [CONNECTION_STRING] -f roles.sql --role-only
```
```bash
supabase db dump --db-url [CONNECTION_STRING] -f schema.sql
```
```bash
supabase db dump --db-url [CONNECTION_STRING] -f data.sql --use-copy --data-only -x "storage.buckets_vectors" -x "storage.vector_indexes"
```
## Before you begin
Download and run the installation file for the latest version from the [Postgres installer download page](https://www.postgresql.org/download/windows/).
Add the Postgres binary to your system PATH.
In Control Panel, under the Advanced tab of System Properties, click Environment Variables. Edit the Path variable by adding the path to the SQL binary you just installed.
The path will look something like this, though it may differ slightly depending on your installed version:
```
C:\Program Files\PostgreSQL\17\bin
```
Open your terminal and run the following command:
```sh
psql --version
```
If you get an error that psql is not available or cannot be found, check that you have correctly added the binary to your system PATH. Also try restarting your terminal.
Install [Homebrew](https://brew.sh/).
Install Postgres via Homebrew by running the following command in your terminal:
```sh
brew install postgresql@17
```
Restart your terminal and run the following command:
```sh
psql --version
```
If you get an error that psql is not available or cannot be found then the PATH variable is likely either not correctly set or you need to restart your terminal.
You can add the Postgres installation path to your PATH variable by running the following command:
```sh
brew info postgresql@17
```
The above command will give an output like this:
```sh
If you need to have postgresql@17 first in your PATH, run:
echo 'export PATH="/opt/homebrew/opt/postgresql@17/bin:$PATH"' >> ~/.zshrc
```
Run the command mentioned and restart the terminal.
## Restore backup using CLI
Create a [new project](https://database.new)
In the new project:
* If Webhooks were used in the old database, enable [Database Webhooks](/dashboard/project/_/database/hooks).
* If any non-default extensions were used in the old database, enable the [Extensions](/dashboard/project/_/database/extensions).
Go to [the **Connect** panel](/dashboard/project/_?showConnect=true\&method=session) for the connection string.
Use the Session pooler connection string by default. If your ISP [supports IPv6](https://test-ipv6.com/), use the direct connection string.
Session pooler connection string:
```bash
postgresql://postgres.[PROJECT-REF]:[YOUR-PASSWORD]@aws-0-us-east-1.pooler.supabase.com:5432/postgres
```
Direct connection string:
```bash
postgresql://postgres.[PROJECT-REF]:[YOUR-PASSWORD]@db.[PROJECT-REF].supabase.com:5432/postgres
```
Replace `[YOUR-PASSWORD]` in the connection string with the database password. If you do not remember your password, you can reset it on [the **Database > Settings**](/dashboard/project/_/database/settings) page of the Dashboard.
Run these commands after replacing `[CONNECTION_STRING]` with your connection string from the previous steps:
```bash
psql \
--single-transaction \
--variable ON_ERROR_STOP=1 \
--file roles.sql \
--file schema.sql \
--command 'SET session_replication_role = replica' \
--file data.sql \
--dbname [CONNECTION_STRING]
```
If you use [column encryption](/docs/guides/database/column-encryption), copy the root encryption key to your new project using your [Personal Access Token](/dashboard/account/tokens).
You can restore the project using both the old and new project ref (the project ref is the value between "https://" and ".supabase.co" in the URL) instead of the URL.
```bash
export OLD_PROJECT_REF=""
export NEW_PROJECT_REF=""
export SUPABASE_ACCESS_TOKEN=""
curl "https://api.supabase.com/v1/projects/$OLD_PROJECT_REF/pgsodium" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" |
curl "https://api.supabase.com/v1/projects/$NEW_PROJECT_REF/pgsodium" \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-X PUT --json @-
```
If replication for Supabase Realtime was used in the old database, enable publication on [the **Database > Publications**](/dashboard/project/_/database/publications) section of the Dashboard on the tables necessary.
## Special considerations
#### Preserving migration history
If you were using Supabase CLI for managing migrations on your old database and would like to preserve the migration history in your newly restored project, you need to insert the migration records separately using the following commands.
```bash
supabase db dump --db-url "$OLD_DB_URL" -f history_schema.sql --schema supabase_migrations
supabase db dump --db-url "$OLD_DB_URL" -f history_data.sql --use-copy --data-only --schema supabase_migrations
psql \
--single-transaction \
--variable ON_ERROR_STOP=1 \
--file history_schema.sql \
--file history_data.sql \
--dbname "$NEW_DB_URL"
```
#### Schema changes to `auth` and `storage`
If you have modified the `auth` and `storage` schemas in your old project, such as adding triggers or Row Level Security(RLS) policies, you have to restore them separately. The Supabase CLI can help you diff the changes to these schemas using the following commands.
```bash
supabase link --project-ref "$OLD_PROJECT_REF"
supabase db diff --linked --schema auth,storage > changes.sql
```
## Troubleshooting notes
#### Disabling triggers during restore:
Setting `session_replication_role` to `replica` disables triggers during the migration, preventing columns from being double encrypted.
#### Custom roles require passwords
If you created any [custom roles](/dashboard/project/_/database/roles) with the `LOGIN` attribute, you must manually set their passwords in the new project. This can be done with the SQL command:
```sql
alter user "YOUR_USER" with password 'SOME_NEW_PASSWORD';
```
#### `supabase_admin` permission errors
If you encounter permission errors related to `supabase_admin` during restore:
* Open `schema.sql`
* Comment out any lines containing:
```sql
ALTER ... OWNER TO "supabase_admin"
```
#### `cli_login_postgres` role grant error
If you encounter the error:
```sh
ERROR: permission denied to grant role "postgres"
DETAIL: Only roles with the ADMIN option on role "postgres" may grant this role.
```
* Open `roles.sql`
* Comment out the line:
```sql
GRANT "postgres" TO "cli_login_postgres" WITH INHERIT FALSE GRANTED BY "supabase_admin";
```
#### `cli_login_postgres` role issues after cloning
The `cli_login_role` must be created by the `supabase_admin` role. If the migration process cloned over the role before the CLI could generate its own version, it may encounter the error:
```sh
"message":"Failed to create login role:
ERROR: 0LP01: role "postgres" is a member of role "cli_login_postgres"
```
To resolve the issue, drop the custom `cli_login_postgres` role. Then the CLI can recreate it with the right privileges:
```sql
DROP ROLE IF EXISTS cli_login_postgres;
```
# Migrating edge functions
## Steps (using the Supabase CLI):
With the Supabase CLI [Supabase CLI](/docs/guides/local-development/cli/getting-started), run:
```bash
supabase login
```
```bash
supabase functions list --project-ref your_project_ref
```
You can download an individual function with the following command:
```bash
supabase functions download YOUR_FUNCTION_NAME --project-ref your_project_ref
```
The command will not download [import maps](/docs/guides/functions/dependencies#using-import-maps-legacy) nor [deno.json](/docs/guides/functions/dependencies#using-denojson-recommended) files. If your edge functions rely on them for dependency management, you will have to add them back manually.
```bash
supabase functions deploy --project-ref your_target_project_ref
```
This deploys all functions within the `supabase/functions` to the target project. You can confirm by checking your Edge Functions on [the project dashboard](/dashboard/project/_/functions)
## Steps (using the Supabase Dashboard):
Dependencies defined through [import maps](/docs/guides/functions/dependencies#using-import-maps-legacy) and [deno.json](/docs/guides/functions/dependencies#using-denojson-recommended) files will need to be rewritten to rely on their [direct import paths](/docs/guides/functions/dependencies#importing-dependencies) when using this approach.
In the source project, navigate to **Edge Functions** from the side menu
Using the `Download` button, download your desired function as zip: 
In the target project, navigate to **Edge Functions** from the side menu
Click on the `Deploy a new function` button, select **Via Editor** operation
Drag and drop your downloaded function (the zip function from step 2) into the editor
Add your function name and click on the `Deploy function` button to deploy the function:
# Migrating storage objects
Using your preferred JavaScript package manager, create a new project with the `supabase` client package
```bash
npm init -y
npm install @supabase/supabase-js
```
```bash
pnpm init -y
pnpm install @supabase/supabase-js
```
```bash
yarn init -y
yarn add @supabase/supabase-js
```
```bash
bun init -y
bun install @supabase/supabase-js
```
Add the example script to it.
```js name=index.js
// npm install @supabase/supabase-js@2
const { createClient } = require('@supabase/supabase-js')
const OLD_PROJECT_URL = 'https://xxx.supabase.co'
const OLD_PROJECT_SERVICE_KEY = 'old-project-service-key-xxx'
const NEW_PROJECT_URL = 'https://yyy.supabase.co'
const NEW_PROJECT_SERVICE_KEY = 'new-project-service-key-yyy'
const oldSupabase = createClient(OLD_PROJECT_URL, OLD_PROJECT_SERVICE_KEY)
const newSupabase = createClient(NEW_PROJECT_URL, NEW_PROJECT_SERVICE_KEY)
function createLoadingAnimation(message) {
const readline = require('readline')
const frames = ['⠋', '⠙', '⠹', '⠸', '⠼', '⠴', '⠦', '⠧', '⠇', '⠏']
let i = 0
let timer
let stopped = false
const animate = () => {
if (stopped) return
process.stdout.write(`\r${frames[i]} ${message}`)
i = (i + 1) % frames.length
timer = setTimeout(animate, 80)
}
animate()
return {
stop: (finalMessage = '') => {
stopped = true
clearTimeout(timer)
readline.clearLine(process.stdout, 0)
readline.cursorTo(process.stdout, 0)
process.stdout.write(`✓ ${finalMessage || message}\n`)
},
}
}
/**
* Lists all files in a bucket, handling nested folders recursively.
*/
async function listAllFiles(bucket, path = '') {
const loader = createLoadingAnimation(`Listing files in '${bucket}${path ? '/' + path : ''}'...`)
try {
const { data, error } = await oldSupabase.storage.from(bucket).list(path, { limit: 1000 })
if (error) {
loader.stop(`Error listing files in '${bucket}${path ? '/' + path : ''}'`)
throw new Error(`❌ Error listing files in bucket '${bucket}': ${error.message}`)
}
if (!data || data.length === 0) {
loader.stop(`No files found in '${bucket}${path ? '/' + path : ''}'`)
return []
}
let files = []
for (const item of data) {
if (!item.metadata) {
loader.stop(`Found folder '${item.name}' in '${bucket}${path ? '/' + path : ''}'`)
const subFiles = await listAllFiles(bucket, `${path}${item.name}/`)
files = files.concat(subFiles)
} else {
files.push({ fullPath: `${path}${item.name}`, metadata: item.metadata })
}
}
loader.stop(`Found ${files.length} files in '${bucket}${path ? '/' + path : ''}'`)
return files
} catch (error) {
loader.stop()
throw error
}
}
/**
* Creates a bucket in the new Supabase project if it doesn't exist.
*/
async function ensureBucketExists(bucketName, options = {}) {
const { data: existingBucket, error: getBucketError } =
await newSupabase.storage.getBucket(bucketName)
if (getBucketError && !getBucketError.message.includes('not found')) {
throw new Error(`❌ Error checking if bucket '${bucketName}' exists: ${getBucketError.message}`)
}
if (!existingBucket) {
console.log(`🪣 Creating bucket '${bucketName}' in new project...`)
const { error } = await newSupabase.storage.createBucket(bucketName, options)
if (error) throw new Error(`❌ Failed to create bucket '${bucketName}': ${error.message}`)
console.log(`✅ Created bucket '${bucketName}'`)
} else {
console.log(`ℹ️ Bucket '${bucketName}' already exists in new project`)
}
}
/**
* Migrates a single file from the old project to the new one.
*/
async function migrateFile(sourceBucketName, targetBucketName, file) {
const loader = createLoadingAnimation(
`Migrating ${file.fullPath} in bucket '${sourceBucketName}' to '${targetBucketName}'...`
)
try {
const { data, error: downloadError } = await oldSupabase.storage
.from(sourceBucketName)
.download(file.fullPath)
if (downloadError) {
loader.stop(`Failed to migrate ${file.fullPath}: Download error`)
throw new Error(`Download failed: ${downloadError.message}`)
}
// Preserve all available metadata from the original file
const uploadOptions = {
upsert: true,
contentType: file.metadata?.mimetype,
cacheControl: file.metadata?.cacheControl,
}
const { error: uploadError } = await newSupabase.storage
.from(targetBucketName)
.upload(file.fullPath, data, uploadOptions)
if (uploadError) {
loader.stop(`Failed to migrate ${file.fullPath}: Upload error`)
throw new Error(`Upload failed: ${uploadError.message}`)
}
loader.stop(
`Migrated ${file.fullPath} in bucket '${sourceBucketName}' to '${targetBucketName}'`
)
return { success: true, path: file.fullPath }
} catch (err) {
console.error(
`❌ Error migrating ${file.fullPath} in bucket '${targetBucketName}':`,
err.message
)
return { success: false, path: file.fullPath, error: err.message }
}
}
function chunkArray(array, size) {
const chunks = []
for (let i = 0; i < array.length; i += size) {
chunks.push(array.slice(i, i + size))
}
return chunks
}
/**
* Migrates all buckets and files from the old Supabase project to the new one.
* Processes files in parallel within batches for efficiency.
*/
async function migrateBuckets() {
console.log('🔄 Starting Supabase Storage migration...')
console.log(`📦 Source project: ${OLD_PROJECT_URL}`)
console.log(`📦 Target project: ${NEW_PROJECT_URL}`)
const readline = require('readline').createInterface({
input: process.stdin,
output: process.stdout,
})
console.log(
'\n⚠️ WARNING: This migration may overwrite files in the target project if they have the same paths.'
)
console.log('⚠️ It is recommended to back up your target project before proceeding.')
const answer = await new Promise((resolve) => {
readline.question('Do you want to proceed with the migration? (yes/no): ', resolve)
})
readline.close()
if (answer.toLowerCase() !== 'yes') {
console.log('Migration canceled by user.')
return { canceled: true }
}
console.log('\n📦 Fetching all buckets from old project...')
const { data: oldBuckets, error: bucketListError } = await oldSupabase.storage.listBuckets()
if (bucketListError) throw new Error(`❌ Error fetching buckets: ${bucketListError.message}`)
console.log(`✅ Found ${oldBuckets.length} buckets to migrate.`)
const { data: existingBuckets, error: existingBucketsError } =
await newSupabase.storage.listBuckets()
if (existingBucketsError)
throw new Error(`❌ Error fetching existing buckets: ${existingBucketsError.message}`)
const existingBucketNames = existingBuckets.map((b) => b.name)
const conflictingBuckets = oldBuckets.filter((b) => existingBucketNames.includes(b.name))
let conflictStrategy = 2
if (conflictingBuckets.length > 0) {
console.log('\n⚠️ The following buckets already exist in the target project:')
conflictingBuckets.forEach((b) => console.log(` - ${b.name}`))
const conflictAnswer = await new Promise((resolve) => {
const rl = require('readline').createInterface({
input: process.stdin,
output: process.stdout,
})
rl.question(
'\nHow do you want to handle existing buckets?\n' +
'1. Skip existing buckets\n' +
'2. Merge files (may overwrite existing files)\n' +
'3. Rename buckets in target (add suffix "_migrated")\n' +
'4. Cancel migration\n' +
'Enter your choice (1-4): ',
(answer) => {
rl.close()
resolve(answer)
}
)
})
if (conflictAnswer === '4') {
console.log('Migration canceled by user.')
return { canceled: true }
}
conflictStrategy = parseInt(conflictAnswer)
if (isNaN(conflictStrategy) || conflictStrategy < 1 || conflictStrategy > 3) {
console.log('Invalid choice. Migration canceled.')
return { canceled: true }
}
}
const migrationStats = {
totalBuckets: oldBuckets.length,
processedBuckets: 0,
skippedBuckets: 0,
totalFiles: 0,
successfulFiles: 0,
failedFiles: 0,
failedFilesList: [],
}
for (const bucket of oldBuckets) {
const bucketName = bucket.name
console.log(`\n📁 Processing bucket: ${bucketName}`)
let targetBucketName = bucketName
if (existingBucketNames.includes(bucketName)) {
if (conflictStrategy === 1) {
console.log(`⏩ Skipping bucket '${bucketName}' as it already exists in target project`)
migrationStats.skippedBuckets++
continue
} else if (conflictStrategy === 3) {
targetBucketName = `${bucketName}_migrated`
console.log(`🔄 Renaming bucket to '${targetBucketName}' in target project`)
} else {
console.log(`🔄 Merging files into existing bucket '${bucketName}' in target project`)
}
}
// Preserve bucket configuration when creating in the new project
if (targetBucketName !== bucketName || !existingBucketNames.includes(bucketName)) {
await ensureBucketExists(targetBucketName, {
public: bucket.public,
fileSizeLimit: bucket.file_size_limit,
allowedMimeTypes: bucket.allowed_mime_types,
})
}
const files = await listAllFiles(bucketName)
console.log(`✅ Found ${files.length} files in bucket '${bucketName}'.`)
migrationStats.totalFiles += files.length
const batches = chunkArray(files, 10)
for (let i = 0; i < batches.length; i++) {
console.log(`\n🚀 Processing batch ${i + 1}/${batches.length} (${batches[i].length} files)`)
const results = await Promise.all(
batches[i].map((file) => migrateFile(bucketName, targetBucketName, file))
)
const batchSuccesses = results.filter((r) => r.success).length
const batchFailures = results.filter((r) => !r.success)
migrationStats.successfulFiles += batchSuccesses
migrationStats.failedFiles += batchFailures.length
migrationStats.failedFilesList.push(...batchFailures.map((f) => f.path))
console.log(
`✅ Completed batch ${i + 1}/${batches.length}: ${batchSuccesses} succeeded, ${batchFailures.length} failed`
)
}
migrationStats.processedBuckets++
console.log(`✅ Completed bucket '${bucketName}' migration`)
}
console.log('\n📊 Migration Summary:')
console.log(
`Buckets: ${migrationStats.processedBuckets}/${migrationStats.totalBuckets} processed, ${migrationStats.skippedBuckets} skipped`
)
console.log(
`Files: ${migrationStats.successfulFiles} succeeded, ${migrationStats.failedFiles} failed (${migrationStats.totalFiles} total)`
)
if (migrationStats.failedFiles > 0) {
console.log('\n⚠️ Failed files:')
migrationStats.failedFilesList.forEach((path) => console.log(` - ${path}`))
return migrationStats
}
return migrationStats
}
migrateBuckets()
.then((stats) => {
if (stats.failedFiles > 0) {
console.log(`\n⚠️ Migration completed with ${stats.failedFiles} failed files.`)
process.exit(1)
} else {
console.log('\n🎉 Migration completed successfully!')
process.exit(0)
}
})
.catch((err) => {
console.error('❌ Fatal error during migration:', err.message)
process.exit(1)
})
```
Get the [secret keys](/dashboard/project/_/settings/api-keys) or [service\_role keys](/dashboard/project/_/settings/api-keys/legacy) for both your new and old projects, then substitute them into the script.
From the [Data API settings](/dashboard/project/_/integrations/data_api/overview), copy your project URL and add it to the script as well.
```js name='index.js'
//rest of code
...
// add relevant details for old project
const OLD_PROJECT_URL = 'https://xxx.supabase.co'
const OLD_PROJECT_SERVICE_KEY = 'old-project-service-key-xxx'
// add relevant details for new project
const NEW_PROJECT_URL = 'https://yyy.supabase.co'
const NEW_PROJECT_SERVICE_KEY = 'new-project-service-key-yyy'
...
//rest of code
```
```bash
node index.js
```
```bash
bun index.js
```
## Resources
* [Connecting with PSQL](/docs/guides/database/psql)
# Restore Dashboard backup
Learn how to restore your dashboard backup to a new Supabase project
## Before you begin
Download and run the installation file for the latest version from the [Postgres installer download page](https://www.postgresql.org/download/windows/).
Add the Postgres binary to your system PATH.
In Control Panel, under the Advanced tab of System Properties, click Environment Variables. Edit the Path variable by adding the path to the SQL binary you just installed.
The path will look something like this, though it may differ slightly depending on your installed version:
```
C:\Program Files\PostgreSQL\17\bin
```
Open your terminal and run the following command:
```sh
psql --version
```
If you get an error that psql is not available or cannot be found, check that you have correctly added the binary to your system PATH. Also try restarting your terminal.
Install [Homebrew](https://brew.sh/).
Install Postgres via Homebrew by running the following command in your terminal:
```sh
brew install postgresql@17
```
Restart your terminal and run the following command:
```sh
psql --version
```
If you get an error that psql is not available or cannot be found then the PATH variable is likely either not correctly set or you need to restart your terminal.
You can add the Postgres installation path to your PATH variable by running the following command:
```sh
brew info postgresql@17
```
The above command will give an output like this:
```sh
If you need to have postgresql@17 first in your PATH, run:
echo 'export PATH="/opt/homebrew/opt/postgresql@17/bin:$PATH"' >> ~/.zshrc
```
Run the command mentioned and restart the terminal.
Create a new [Supabase project](https://database.new)
In your new project:
* If you were using Webhooks, enable [Database Webhooks](/dashboard/project/_/database/hooks).
* If you were using any extensions, enable the [Extensions](/dashboard/project/_/database/extensions).
* If you were using Replication for Realtime, enable [Publication](/dashboard/project/_/database/publications) where needed.
## Things to keep in mind
Here are some things that are not stored directly in your database and will require you to re-create or setup on the new project:
* Edge Functions
* Auth Settings and API keys
* Realtime settings
* Database extensions and settings
* Read Replicas
## Restore backup
On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true).
Use the [Session pooler](/dashboard/project/_?showConnect=true\&method=session) connection string by default. If your ISP supports IPv6 or you have the IPv4 add-on enabled, use the direct connection string.
Session pooler connection string:
```bash
postgresql://postgres.[PROJECT-REF]:[YOUR-PASSWORD]@aws-0-us-east-1.pooler.supabase.com:5432/postgres
```
Direct connection string:
```bash
postgresql://postgres.[PROJECT-REF]:[YOUR-PASSWORD]@db.[PROJECT-REF].supabase.com:5432/postgres
```
It can take a few minutes for the database password reset to take effect. Especially if multiple password resets are done.
Reset the password in the [Database Settings](/dashboard/project/_/database/settings).
Replace `[YOUR-PASSWORD]` in the connection string with the database password.
Get the relative file path of the downloaded backup file.
If the restore is done in the same directory as the downloaded backup, the file path would look like this:
`./backup_name.backup`
The backup file will be gzipped with a .gz extension. You will need to unzip the file to look like this:
`backup_name.backup`
```sql
psql -d [CONNECTION_STRING] -f /file/path
```
Replace `[CONNECTION_STRING]` with connection string from Steps 1 & 2.
Replace `/file/path` with the file path from Step 3.
Run the command with the replaced values to restore the backup to your new project.
## Migrate storage objects to new project's S3 storage
After restoring the backup, the buckets and files metadata will show up in the dashboard of the new project.
However, the storage files stored in the S3 buckets would not be present.
Use the following Google Colab script provided below to migrate your downloaded storage objects to your new project's S3 buckets.
[](https://colab.research.google.com/github/PLyn/supabase-storage-migrate/blob/main/Supabase_Storage_migration.ipynb)
This method requires uploading to Google Colab and then to the S3 buckets. This could add significant upload time if there are large storage objects.
## Common errors with the backup restore process
"**object already exists**"
"**constraint x for relation y already exists**"
"**Many other variations of errors**"
These errors are expected when restoring to a new Supabase project. The backup from the dashboard is a full dump which contains the CREATE commands for all schemas. This is by design as the full dump allows you to rebuild the entire database from scratch even outside of Supabase.
One side effect of this method is that a new Supabase project has these commands already applied to schemas like storage and auth. The errors from this are not an issue because it skips to the next command to run. Another side effect of this is that all triggers will run during the restoration process which is not ideal but generally is not a problem.
There are circumstances where this method can fail and if it does, you should reach out to Supabase support for help.
"**psql: error: connection to server at "aws-0-us-east-1.pooler.supabase.com" (44.216.29.125), port 5432 failed: received invalid response to GSSAPI negotiation:**"
You are possibly using psql and Postgres version 15 or lower. Completely remove the Postgres installation and install the latest version as per the instructions above to resolve this issue.
"**psql: error: connection to server at "aws-0-us-east-1.pooler.supabase.com" (44.216.29.125), port 5432 failed: error received from server in SCRAM exchange: Wrong password**"
If the database password was reset, it may take a few minutes for it to reflect. Try again after a few minutes if you did a password reset.
# Migrate from Amazon RDS to Supabase
Migrate your Amazon RDS MySQL or MS SQL database to Supabase.
This guide aims to exhibit the process of transferring your Amazon RDS database from any of these engines Postgres, MySQL or MS SQL to Supabase's Postgres database. Although Amazon RDS is a favored managed database service provided by AWS, it may not suffice for all use cases. Supabase, on the other hand, provides an excellent free and open source option that encompasses all the necessary backend features to develop a product: a Postgres database, authentication, instant APIs, edge functions, real-time subscriptions, and storage.
Supabase's core is Postgres, enabling the use of row-level security and providing access to over 40 Postgres extensions. By migrating from Amazon RDS to Supabase, you can leverage Postgres to its fullest potential and acquire all the features you need to complete your project.
## Retrieve your Amazon RDS database credentials \[#retrieve-rds-credentials]
1. Log in to your [Amazon RDS account](https://aws.amazon.com/rds/).
2. Select the region where your RDS database is located.
3. Navigate to the **Databases** tab.
4. Select the database that you want to migrate.
5. In the **Connectivity & Security** tab, note down the Endpoint and the port number.
6. In the **Configuration** tab, note down the Database name and the Username.
7. If you do not have the password, create a new one and note it down.
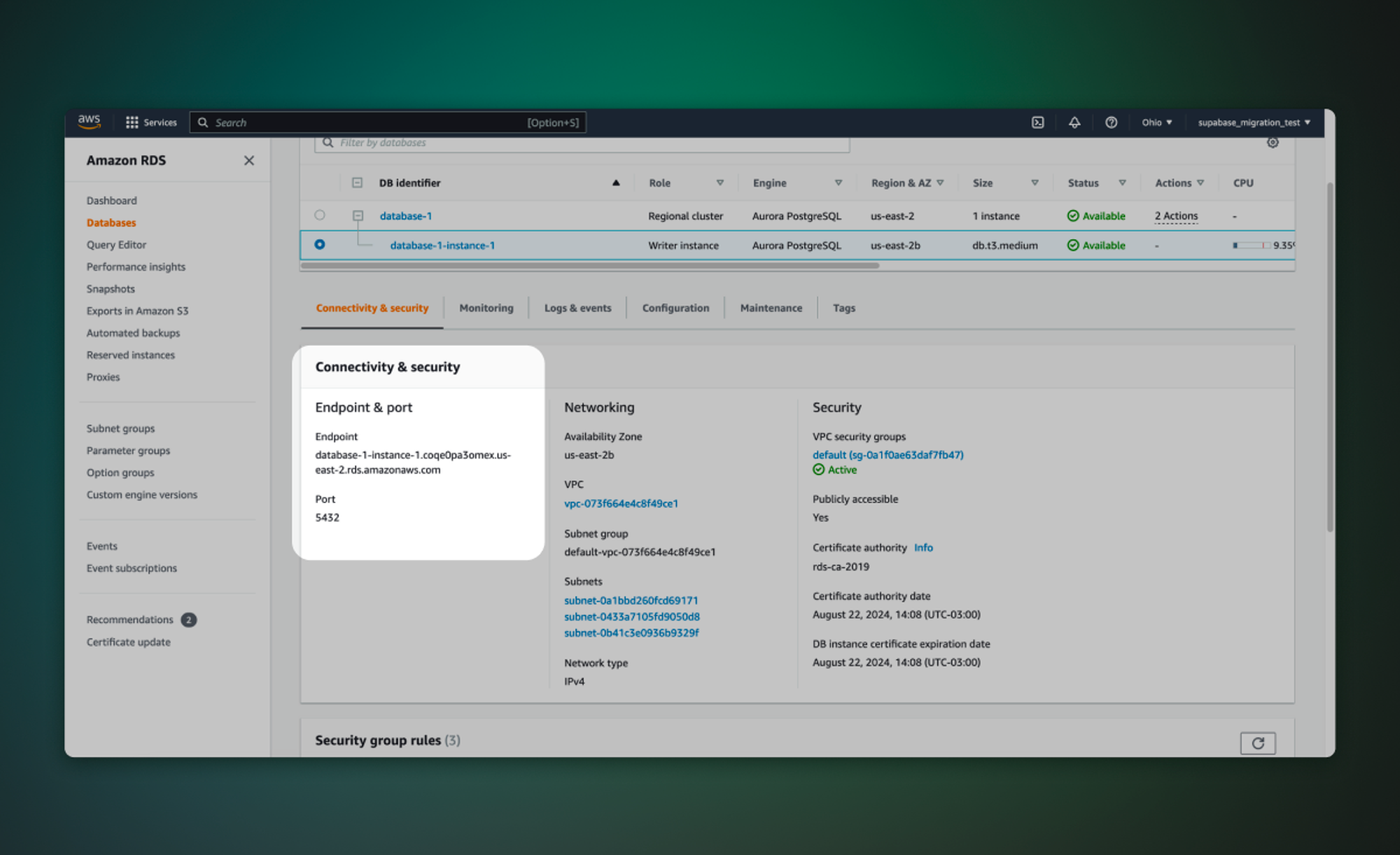
## Retrieve your Supabase host \[#retrieve-supabase-host]
1. If you're new to Supabase, [create a project](https://database.new). Make a note of your password, you will need this later. If you forget it, you can [reset it here](/dashboard/project/_/database/settings).
2. On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session)
3. Under the Session pooler, click on the View parameters under the connect string. Note your Host (`$SUPABASE_HOST`).
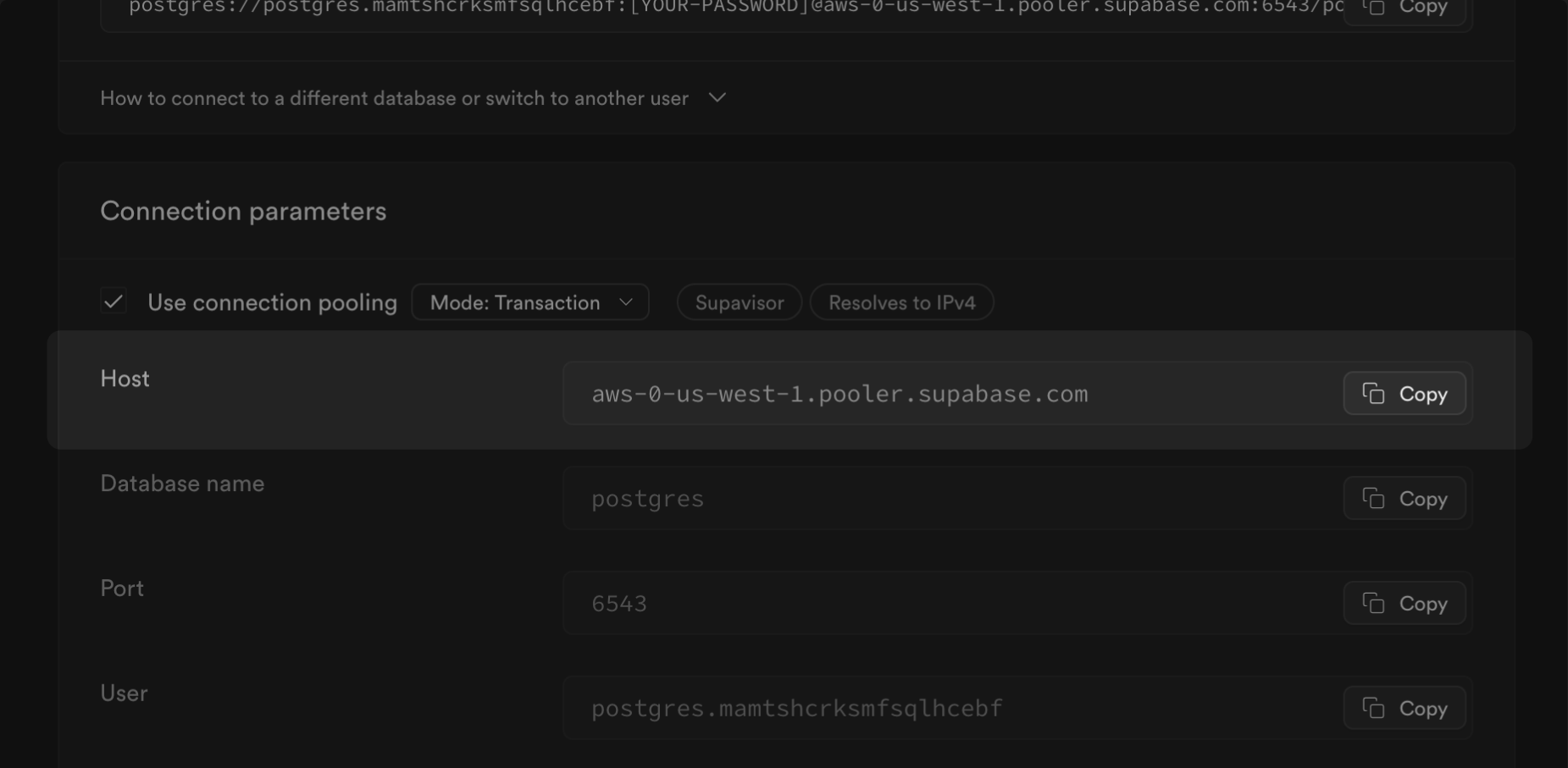
## Migrate the database
The fastest way to migrate your database is with the Supabase migration tool on
[Google Colab](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Amazon_RDS_to_Supabase.ipynb).
Alternatively, you can use [pgloader](https://github.com/dimitri/pgloader), a flexible and powerful data migration tool that supports a wide range of source database engines, including MySQL and MS SQL, and migrates the data to a Postgres database. For databases using the Postgres engine, we recommend using the [`pg_dump`](https://www.postgresql.org/docs/current/app-pgdump.html) and [psql](https://www.postgresql.org/docs/current/app-psql.html) command line tools, which are included in a full Postgres installation.
1. Select the Database Engine from the Source database in the dropdown
2. Set the environment variables (`HOST`, `USER`, `SOURCE_DB`,`PASSWORD`, `SUPABASE_URL`, and `SUPABASE_PASSWORD`) in the Colab notebook.
3. Run the first two steps in [the notebook](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Amazon_RDS_to_Supabase.ipynb) in order. The first sets engine and installs the necessary files.
4. Run the third step to start the migration. This will take a few minutes.
1. Install pgloader.
2. Create a configuration file (e.g., config.load).
For your destination, use your Supabase connection string with `Use connection pooling` enabled, and the mode set to `Session`. You can get the string from your [`Database Settings`](/dashboard/project/_/settings/general).
```sql
load database
from mysql://user:password@host/source_db
into postgres://postgres.xxxx:password@xxxx.pooler.supabase.com:5432/postgres
alter schema 'public' owner to 'postgres';
set wal_buffers = '64MB', max_wal_senders = 0, statement_timeout = 0, work_mem to '2GB';
```
3. Run the migration with pgloader
```bash
pgloader config.load
```
1. Install pgloader.
2. Create a configuration file (e.g., config.load).
```sql
LOAD DATABASE
FROM mssql://USER:PASSWORD@HOST/SOURCE_DB
INTO postgres://postgres.xxxx:password@xxxx.pooler.supabase.com:6543/postgres
ALTER SCHEMA 'public' OWNER TO 'postgres';
set wal_buffers = '64MB', max_wal_senders = 0, statement_timeout = 0, work_mem to '2GB';
```
3. Run the migration with pgloader
```bash
pgloader config.load
```
* If you're planning to migrate a database larger than 6 GB, we recommend [upgrading to at least a Large compute add-on](/docs/guides/platform/compute-add-ons). This will ensure you have the necessary resources to handle the migration efficiently.
* We strongly advise you to pre-provision the disk space you will need for your migration. On paid projects, you can do this by navigating to the [Compute and Disk Settings](/dashboard/project/_/settings/compute-and-disk) page. For more information on disk scaling and disk limits, check out our [disk settings](/docs/guides/platform/compute-and-disk#disk) documentation.
## Enterprise
[Contact us](https://forms.supabase.com/enterprise) if you need more help migrating your project.
# Migrate from Auth0 to Supabase Auth
Learn how to migrate your users from Auth0
You can migrate your users from Auth0 to Supabase Auth.
Changing authentication providers for a production app is an important operation. It can affect most aspects of your application. Prepare in advance by reading this guide, and develop a plan for handling the key migration steps and possible problems.
With advance planning, a smooth and safe Auth migration is possible.
## Before you begin
Before beginning, consider the answers to the following questions. They will help you need decide if you need to migrate, and which strategy to use:
* How do Auth provider costs scale as your user base grows?
* Does the new Auth provider provide all needed features? (for example, OAuth, password logins, Security Assertion Markup Language (SAML), Multi-Factor Authentication (MFA))
* Is downtime acceptable during the migration?
* What is your timeline to migrate before terminating the old Auth provider?
## Migration strategies
Depending on your evaluation, you may choose to go with one of the following strategies:
1. Rolling migration
2. One-off migration
| Strategy | Advantages | Disadvantages |
| -------- | ---------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Rolling | - 0 downtime
- Users may need to log in again
| - Need to maintain 2 different Auth services, which may be more costly in the short-term
- Need to maintain separate codepaths for the period of the migration
- Some existing users may be inactive and have not signed in with the new provider. This means that you eventually need to backfill these users. However, this is a much smaller-scale one-off migration with lower risks since these users are inactive.
|
| One-off | - No need to maintain 2 different auth services for an extended period of time
| - Some downtime
- Users will need to log in again. Risky for active users.
|
## Migration steps
Auth provider migrations require 2 main steps:
1. Export your user data from the old provider (Auth0)
2. Import the data into your new provider (Supabase Auth)
### Step 1: Export your user data
Auth0 provides two methods for exporting user data:
1. Use the [Auth0 data export feature](https://auth0.com/docs/troubleshoot/customer-support/manage-subscriptions/export-data)
2. Use the [Auth0 management API](https://auth0.com/docs/api/management/v2/users/get-users). This endpoint has a rate limit, so you may need to export your users in several batches.
To export password hashes and MFA factors, contact Auth0 support.
### Step 2: Import your users into Supabase Auth
The steps for importing your users depends on the login methods that you support.
See the following sections for how to import users with:
* [Password-based login](#password-based-methods)
* [Passwordless login](#passwordless-methods)
* [OAuth](#oauth)
#### Password-based methods
For users who sign in with passwords, we recommend a hybrid approach to reduce downtime:
1. For new users, use Supabase Auth for sign up.
2. Migrate existing users in a one-off migration.
##### Sign up new users
Sign up new users using Supabase Auth's [signin methods](/docs/guides/auth/passwords#signing-up-with-an-email-and-password).
##### Migrate existing users to Supabase Auth
Migrate existing users to Supabase Auth. This requires two main steps: first, check which users need to be migrated, then create their accounts using the Supabase admin endpoints.
1. Get your Auth 0 user export and password hash export lists.
2. Filter for users who use password login.
* Under the `identities` field in the user object, these users will have `auth0` as a provider. In the same identity object, you can find their Auth0 `user_id`.
* Check that the user has a corresponding password hash by comparing their Auth0 `user_id` to the `oid` field in the password hash export.
3. Use Supabase Auth's [admin create user](/docs/reference/javascript/auth-admin-createuser) method to recreate the user in Supabase Auth. If the user has a confirmed email address or phone number, set `email_confirm` or `phone_confirm` to `true`.
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const { data, error } = await supabase.auth.admin.createUser({
email: 'valid.email@supabase.io',
password_hash: '$2y$10$a9pghn27d7m0ltXvlX8LiOowy7XfFw0hW0G80OjKYQ1jaoejaA7NC',
email_confirm: true,
})
```
Supabase supports bcrypt and Argon2 password hashes.
If you have a plaintext password instead of a hash, you can provide that instead. Supabase Auth will handle hashing the password for you. (Passwords are **always** stored hashed.)
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const { data, error } = await supabase.auth.admin.createUser({
email: 'valid.email@supabase.io',
password: 'supersecurepassword123!',
})
```
4. To sign in your migrated users, use the Supabase Auth [sign in methods](/docs/reference/javascript/auth-signinwithpassword).
To check for edge cases where users aren't successfully migrated, use a fallback strategy. This ensures that users can continue to sign in seamlessly:
1. Try to sign in the user with Supabase Auth.
2. If the signin fails, try to sign in with Auth0.
3. If Auth0 signin succeeds, call the admin create user method again to create the user in Supabase Auth.
#### Passwordless methods
For passwordless signin via email or phone, check for users with verified email addresses or phone numbers. Create these users in Supabase Auth with `email_confirm` or `phone_confirm` set to `true`:
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const { data, error } = await supabase.auth.admin.createUser({
email: 'valid.email@supabase.io',
email_confirm: true,
})
```
Check your Supabase Auth [email configuration](/docs/guides/auth/auth-smtp) and configure your [email template](/dashboard/project/_/auth/templates) for use with magic links. See the [Email templates guide](/docs/guides/auth/auth-email-templates) to learn more.
Once you have imported your users, you can sign them in using the [`signInWithOtp`](/docs/reference/javascript/auth-signinwithotp) method.
#### OAuth
Configure your OAuth providers in Supabase by following the [Social login guides](/docs/guides/auth/social-login).
For both new and existing users, sign in the user using the [`signInWithOAuth`](/docs/reference/javascript/auth-signinwithoauth) method. This works without pre-migrating existing users, since the user always needs to sign in through the OAuth provider before being redirected to your service.
After the user has completed the OAuth flow successfully, you can check if the user is a new or existing user in Auth0 by mapping their social provider id to Auth0. Auth0 stores the social provider ID in the user ID, which has the format `provider_name|provider_id` (for example, `github|123456`). See the [Auth0 identity docs](https://auth0.com/docs/manage-users/user-accounts/identify-users) to learn more.
## Mapping between Auth0 and Supabase Auth
Each Auth provider has its own schema for tracking users and user information.
In Supabase Auth, your users are stored in your project's database under the `auth` schema. Every user has an identity (unless the user is an anonymous user), which represents the signin method they can use with Supabase. This is represented by the `auth.users` and `auth.identities` table.
See the [Users](/docs/guides/auth/users) and [Identities](/docs/guides/auth/identities) sections to learn more.
### Mapping user metadata and custom claims
Supabase Auth provides 2 fields which you can use to map user-specific metadata from Auth0:
* `auth.users.raw_user_meta_data` : For storing non-sensitive user metadata that the user can update (e.g full name, age, favorite color).
* `auth.users.raw_app_meta_data` : For storing non-sensitive user metadata that the user should not be able to update (e.g pricing plan, access control roles).
Both columns are accessible from the admin user methods. To create a user with custom metadata, you can use the following method:
```ts
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('your_project_url', 'your_supabase_api_key')
// ---cut---
const { data, error } = await supabase.auth.admin.createUser({
email: 'valid.email@supabase.io',
user_metadata: {
full_name: 'Foo Bar',
},
app_metadata: {
role: 'admin',
},
})
```
These fields will be exposed in the user's access token JWT so it is recommended not to store excessive metadata in these fields.
These fields are stored as columns in the `auth.users` table using the `jsonb` type. Both fields can be updated by using the admin [`updateUserById` method](/docs/reference/javascript/auth-admin-updateuserbyid). If you want to allow the user to update their own `raw_user_meta_data` , you can use the [`updateUser` method](/docs/reference/javascript/auth-updateuser).
If you have a lot of user-specific metadata to store, it is recommended to create your own table in a private schema that uses the user id as a foreign key:
```sql
create table private.user_metadata (
id int generated always as identity,
user_id uuid references auth.users(id) on delete cascade,
user_metadata jsonb
);
```
## Frequently Asked Questions (FAQ)
I have IDs assigned to existing users in my database, how can I maintain these IDs?} id="custom-user-id">
All users stored in Supabase Auth use the UUID V4 format as the ID. If your UUID format is identical, you can specify it in the admin create user method like this:
New users in Supabase Auth will always be created with a UUID V4 ID by default.
```ts
// specify a custom id
const { data, error } = await supabase.auth.admin.createUser({
id: 'e7f5ae65-376e-4d05-a18c-10a91295727a',
email: 'valid.email@supabase.io',
})
```
How can I allow my users to retain their existing password?} id="existing-password">
Supabase Auth never stores passwords as plaintext. Since Supabase Auth supports reading bcrypt and argon2 password hashes, you can import your users passwords if they use the same hashing algorithm. New users in Supabase Auth who use password-based sign-in methods will always use a bcrypt hash. Passwords are stored in the `auth.users.encrypted_password` column.
My users have multi-factor authentication (MFA) enabled, how do I make sure they don't have to set up MFA again?} id="mfa">
You can obtain an export of your users' MFA secrets by opening a support ticket with Auth0, similar to obtaining the export for password hashes. Supabase Auth only supports time-based one-time passwords (TOTP). Users who have TOTP-based factors may need to re-enroll using their choice of TOTP-based authenticator instead (e.g. 1Password / Google authenticator).
How do I migrate existing SAML Single Sign-On (SSO) connections?} id="saml">
Customers may need to link their identity provider with Supabase Auth separately, but their users should still be able to sign-in as per-normal after authenticating with their identity provider. For more information about SSO with SAML 2.0, you can check out [this guide](/docs/guides/auth/enterprise-sso/auth-sso-saml). If you want to migrate your existing SAML SSO connections from Auth0 to Supabase Auth, reach out to us via support.
How do I migrate my Auth0 organizations to Supabase?} id="migrate-org">
This isn't supported by Supabase Auth yet.
## Useful references
* [Migrating 125k users from Auth0 to Supabase](https://kevcodez.medium.com/migrating-125-000-users-from-auth0-to-supabase-81c0568de307)
* [Loper to Supabase migration](https://eigen.sh/posts/auth-migration)
# Migrate from Firebase Auth to Supabase
Migrate Firebase auth users to Supabase Auth.
Supabase provides several [tools](https://github.com/supabase-community/firebase-to-supabase/tree/main/auth) to help migrate auth users from a Firebase project to a Supabase project. There are two parts to the migration process:
* `firestoreusers2json` ([TypeScript](https://github.com/supabase-community/firebase-to-supabase/blob/main/auth/firestoreusers2json.ts), [JavaScript](https://github.com/supabase-community/firebase-to-supabase/blob/main/auth/firestoreusers2json.js)) exports users from an existing Firebase project to a `.json` file on your local system.
* `import_users` ([TypeScript](https://github.com/supabase-community/firebase-to-supabase/blob/main/auth/import_users.ts), [JavaScript](https://github.com/supabase-community/firebase-to-supabase/blob/main/auth/import_users.js)) imports users from a saved `.json` file into your Supabase project (inserting those users into the `auth.users` table of your `Postgres` database instance).
## Set up the migration tool \[#set-up-migration-tool]
1. Clone the [`firebase-to-supabase`](https://github.com/supabase-community/firebase-to-supabase) repository:
```bash
git clone https://github.com/supabase-community/firebase-to-supabase.git
```
2. In the `/auth` directory, create a file named `supabase-service.json` with the following contents:
```json
{
"host": "database.server.com",
"password": "secretpassword",
"user": "postgres",
"database": "postgres",
"port": 5432
}
```
3. On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session)
4. Under the Session pooler, click on the View parameters under the connect string. Replace the `Host` and `User` fields with the values shown.
5. Enter the password you used when you created your Supabase project in the `password` entry in the `supabase-service.json` file.
## Generate a Firebase private key \[#generate-firebase-private-key]
1. Log in to your [Firebase Console](https://console.firebase.google.com/project) and open your project.
2. Click the gear icon next to **Project Overview** in the sidebar and select **Project Settings**.
3. Click **Service Accounts** and select **Firebase Admin SDK**.
4. Click **Generate new private key**.
5. Rename the downloaded file to `firebase-service.json`.
## Save your Firebase password hash parameters \[#save-firebase-hash-parameters]
1. Log in to your [Firebase Console](https://console.firebase.google.com/project) and open your project.
2. Select **Authentication** (Build section) in the sidebar.
3. Select **Users** in the top menu.
4. At the top right of the users list, open the menu (3 dots) and click **Password hash parameters**.
5. Copy and save the parameters for `base64_signer_key`, `base64_salt_separator`, `rounds`, and `mem_cost`.
```text Sample
hash_config {
algorithm: SCRYPT,
base64_signer_key: XXXX/XXX+XXXXXXXXXXXXXXXXX+XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX==,
base64_salt_separator: Aa==,
rounds: 8,
mem_cost: 14,
}
```
## Command line options
### Dump Firestore users to a JSON file \[#dump-firestore-users]
`node firestoreusers2json.js [] []`
* `filename.json`: (optional) output filename (defaults to `./users.json`)
* `batchSize`: (optional) number of users to fetch in each batch (defaults to 100)
### Import JSON users file to Supabase Auth (Postgres: `auth.users`) \[#import-json-users-file]
`node import_users.js []`
* `path_to_json_file`: full local path and filename of JSON input file (of users)
* `batch_size`: (optional) number of users to process in a batch (defaults to 100)
## Notes
For more advanced migrations, including the use of a middleware server component for verifying a user's existing Firebase password and updating that password in your Supabase project the first time a user logs in, see the [`firebase-to-supabase` repo](https://github.com/supabase-community/firebase-to-supabase/tree/main/auth).
## Resources
* [Supabase vs Firebase](/alternatives/supabase-vs-firebase)
* [Firestore Data Migration](/docs/guides/migrations/firestore-data)
* [Firestore Storage Migration](/docs/guides/migrations/firebase-storage)
## Migrate to Supabase
[Contact us](https://forms.supabase.com/firebase-migration) if you need more help migrating your project.
# Migrated from Firebase Storage to Supabase
Migrate Firebase Storage files to Supabase Storage.
Supabase provides several [tools](https://github.com/supabase-community/firebase-to-supabase/tree/main/storage) to convert storage files from Firebase Storage to Supabase Storage. Conversion is a two-step process:
1. Files are downloaded from a Firebase storage bucket to a local filesystem.
2. Files are uploaded from the local filesystem to a Supabase storage bucket.
## Set up the migration tool \[#set-up-migration-tool]
1. Clone the [`firebase-to-supabase`](https://github.com/supabase-community/firebase-to-supabase) repository:
```bash
git clone https://github.com/supabase-community/firebase-to-supabase.git
```
2. In the `/storage` directory, rename [supabase-keys-sample.js](https://github.com/supabase-community/firebase-to-supabase/blob/main/storage/supabase-keys-sample.js) to `supabase-keys.js`.
3. Go to your Supabase project's [API settings](/dashboard/project/_/settings/api) in the Dashboard.
4. Copy the **Project URL** and update the `SUPABASE_URL` value in `supabase-keys.js`.
5. Under **Project API keys**, copy the **secret** key and update the `SUPABASE_KEY` value in `supabase-keys.js`.
## Generate a Firebase private key \[#generate-firebase-private-key]
1. Log in to your [Firebase Console](https://console.firebase.google.com/project) and open your project.
2. Click the gear icon next to **Project Overview** in the sidebar and select **Project Settings**.
3. Click **Service Accounts** and select **Firebase Admin SDK**.
4. Click **Generate new private key**.
5. Rename the downloaded file to `firebase-service.json`.
## Command line options
### Download Firestore Storage bucket to a local filesystem folder \[#download-firestore-storage-bucket]
`node download.js [] [] [] []`
* ``: The prefix of the files to download. To process the root bucket, use an empty prefix: "".
* ``: (optional) Name of subfolder for downloaded files. The selected folder is created as a subfolder of the current folder (e.g., `./downloads/`). The default is `downloads`.
* ``: (optional) The default is 100.
* ``: (optional) Stop after processing this many files. For no limit, use `0`.
* ``: (optional) Begin processing at this `pageToken`.
To process in batches using multiple command-line executions, you must use the same parameters with a new `` on subsequent calls. Use the token displayed on the last call to continue the process at a given point.
### Upload files to Supabase Storage bucket \[#upload-to-supabase-storage-bucket]
`node upload.js `
* ``: The prefix of the files to download. To process all files, use an empty prefix: "".
* ``: Name of subfolder of files to upload. The selected folder is read as a subfolder of the current folder (e.g., `./downloads/`). The default is `downloads`.
* ``: Name of the bucket to upload to.
If the bucket doesn't exist, it's created as a `non-public` bucket. You must set permissions on this new bucket in the [Supabase Dashboard](/dashboard/project/_/storage/buckets) before users can download any files.
## Resources
* [Supabase vs Firebase](/alternatives/supabase-vs-firebase)
* [Firestore Data Migration](/docs/guides/migrations/firestore-data)
* [Firebase Auth Migration](/docs/guides/migrations/firebase-auth)
## Migrate to Supabase
[Contact us](https://forms.supabase.com/firebase-migration) if you need more help migrating your project.
# Migrate from Firebase Firestore to Supabase
Migrate your Firebase Firestore database to a Supabase Postgres database.
Supabase provides several [tools](https://github.com/supabase-community/firebase-to-supabase/tree/main/firestore) to convert data from a Firebase Firestore database to a Supabase Postgres database. The process copies the entire contents of a single Firestore `collection` to a single Postgres `table`.
The Firestore `collection` is "flattened" and converted to a table with basic columns of one of the following types: `text`, `numeric`, `boolean`, or `jsonb`. If your structure is more complex, you can write a program to split the newly-created `json` file into multiple, related tables before you import your `json` file(s) to Supabase.
## Set up the migration tool \[#set-up-migration-tool]
1. Clone the [`firebase-to-supabase`](https://github.com/supabase-community/firebase-to-supabase) repository:
```bash
git clone https://github.com/supabase-community/firebase-to-supabase.git
```
2. In the `/firestore` directory, create a file named `supabase-service.json` with the following contents:
```json
{
"host": "database.server.com",
"password": "secretpassword",
"user": "postgres",
"database": "postgres",
"port": 5432
}
```
3. On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session)
4. Under the Session pooler, click on the View parameters under the connect string. Replace the `Host` and `User` fields with the values shown.
5. Enter the password you used when you created your Supabase project in the `password` entry in the `supabase-service.json` file.
## Generate a Firebase private key \[#generate-firebase-private-key]
1. Log in to your [Firebase Console](https://console.firebase.google.com/project) and open your project.
2. Click the gear icon next to **Project Overview** in the sidebar and select **Project Settings**.
3. Click **Service Accounts** and select **Firebase Admin SDK**.
4. Click **Generate new private key**.
5. Rename the downloaded file to `firebase-service.json`.
## Command line options
### List all Firestore collections
`node collections.js`
### Dump Firestore collection to JSON file
`node firestore2json.js [] []`
* `batchSize` (optional) defaults to 1000
* output filename is `.json`
* `limit` (optional) defaults to 0 (no limit)
#### Customize the JSON file with hooks
You can customize the way your JSON file is written using a [custom hook](#custom-hooks). A common use for this is to "flatten" the JSON file, or to split nested data into separate, related database tables. For example, you could take a Firestore document that looks like this:
```json Firestore
[{ "user": "mark", "score": 100, "items": ["hammer", "nail", "glue"] }]
```
And split it into two files (one table for users and one table for items):
```json Users
[{ "user": "mark", "score": 100 }]
```
```json Items
[
{ "user": "mark", "item": "hammer" },
{ "user": "mark", "item": "nail" },
{ "user": "mark", "item": "glue" }
]
```
### Import JSON file to Supabase (Postgres) \[#import-to-supabase]
`node json2supabase.js [] []`
* `` The full path of the file you created in the previous step (`Dump Firestore collection to JSON file `), such as `./my_collection.json`
* `[]` (optional) Is one of:
* `none` (default) No primary key is added to the table.
* `smallserial` Creates a key using `(id SMALLSERIAL PRIMARY KEY)` (autoincrementing 2-byte integer).
* `serial` Creates a key using `(id SERIAL PRIMARY KEY)` (autoincrementing 4-byte integer).
* `bigserial` Creates a key using `(id BIGSERIAL PRIMARY KEY)` (autoincrementing 8-byte integer).
* `uuid` Creates a key using `(id UUID PRIMARY KEY DEFAULT gen_random_uuid())` (randomly generated UUID).
* `firestore_id` Creates a key using `(id TEXT PRIMARY KEY)` (uses existing `firestore_id` random text as key).
* `[]` (optional) Name of primary key. Defaults to "id".
## Custom hooks
Hooks are used to customize the process of exporting a collection of Firestore documents to JSON. They can be used for:
* Customizing or modifying keys
* Calculating data
* Flattening nested documents into related SQL tables
### Write a custom hook
#### Create a `.js` file for your collection
If your Firestore collection is called `users`, create a file called `users.js` in the current folder.
#### Construct your `.js` file
The basic format of a hook file looks like this:
```js
module.exports = (collectionName, doc, recordCounters, writeRecord) => {
// modify the doc here
return doc
}
```
##### Parameters
* `collectionName`: The name of the collection you are processing.
* `doc`: The current document (JSON object) being processed.
* `recordCounters`: An internal object that keeps track of how many records have been processed in each collection.
* `writeRecord`: This function automatically handles the process of writing data to other JSON files (useful for "flatting" your document into separate JSON files to be written to separate database tables). `writeRecord` takes the following parameters:
* `name`: Name of the JSON file to write to.
* `doc`: The document to write to the file.
* `recordCounters`: The same `recordCounters` object that was passed to this hook (just passes it on).
### Examples
#### Add a new (unique) numeric key to a collection
```js
module.exports = (collectionName, doc, recordCounters, writeRecord) => {
doc.unique_key = recordCounter[collectionName] + 1
return doc
}
```
#### Add a timestamp of when this record was dumped from Firestore
```js
module.exports = (collectionName, doc, recordCounters, writeRecord) => {
doc.dump_time = new Date().toISOString()
return doc
}
```
#### Flatten JSON into separate files
Flatten the `users` collection into separate files:
```json
[
{
"uid": "abc123",
"name": "mark",
"score": 100,
"weapons": ["toothpick", "needle", "rock"]
},
{
"uid": "xyz789",
"name": "chuck",
"score": 9999999,
"weapons": ["hand", "foot", "head"]
}
]
```
The `users.js` hook file:
```js
module.exports = (collectionName, doc, recordCounters, writeRecord) => {
for (let i = 0; i < doc.weapons.length; i++) {
const weapon = {
uid: doc.uid,
weapon: doc.weapons[i],
}
writeRecord('weapons', weapon, recordCounters)
}
delete doc.weapons // moved to separate file
return doc
}
```
The result is two separate JSON files:
```json users.json
[
{ "uid": "abc123", "name": "mark", "score": 100 },
{ "uid": "xyz789", "name": "chuck", "score": 9999999 }
]
```
```json weapons.json
[
{ "uid": "abc123", "weapon": "toothpick" },
{ "uid": "abc123", "weapon": "needle" },
{ "uid": "abc123", "weapon": "rock" },
{ "uid": "xyz789", "weapon": "hand" },
{ "uid": "xyz789", "weapon": "foot" },
{ "uid": "xyz789", "weapon": "head" }
]
```
## Resources
* [Supabase vs Firebase](/alternatives/supabase-vs-firebase)
* [Firestore Storage Migration](/docs/guides/migrations/firebase-storage)
* [Firebase Auth Migration](/docs/guides/migrations/firebase-auth)
## Migrate to Supabase
[Contact us](https://forms.supabase.com/firebase-migration) if you need more help migrating your project.
# Migrate from Heroku to Supabase
Migrate your Heroku Postgres database to Supabase.
Supabase is one of the best [free alternatives to Heroku Postgres](/alternatives/supabase-vs-heroku-postgres). This guide shows how to migrate your Heroku Postgres database to Supabase. This migration requires the [pg\_dump](https://www.postgresql.org/docs/current/app-pgdump.html) and [psql](https://www.postgresql.org/docs/current/app-psql.html) CLI tools, which are installed automatically as part of the complete Postgres installation package.
Alternatively, use the [Heroku to Supabase migration tool](https://migrate.supabase.com/) to migrate in just a few clicks.
## Quick demo
## Retrieve your Heroku database credentials \[#retrieve-heroku-credentials]
1. Log in to your [Heroku account](https://heroku.com) and select the project you want to migrate.
2. Click **Resources** in the menu and select your **Heroku Postgres** database.
3. Click **Settings** in the menu.
4. Click **View Credentials** and save the following information:
* Host (`$HEROKU_HOST`)
* Database (`$HEROKU_DATABASE`)
* User (`$HEROKU_USER`)
* Password (`$HEROKU_PASSWORD`)
## Retrieve your Supabase connection string \[#retrieve-supabase-connection-string]
1. If you're new to Supabase, [create a project](/dashboard).
2. Get your project's Session pooler connection string from your project dashboard by clicking [Connect](/dashboard/project/_?showConnect=true\&method=session).
3. Replace \[YOUR-PASSWORD] in the connection string with your database password. You can reset your database password on the [Database Settings page](/dashboard/project/_/database/settings) if you do not have it.
## Export your Heroku database to a file \[#export-heroku-database]
Use `pg_dump` with your Heroku credentials to export your Heroku database to a file (e.g., `heroku_dump.sql`).
```bash
pg_dump --clean --if-exists --quote-all-identifiers \
-h $HEROKU_HOST -U $HEROKU_USER -d $HEROKU_DATABASE \
--no-owner --no-privileges > heroku_dump.sql
```
## Import the database to your Supabase project \[#import-database-to-supabase]
Use `psql` to import the Heroku database file to your Supabase project.
```bash
psql -d "$YOUR_CONNECTION_STRING" -f heroku_dump.sql
```
## Additional options
* To only migrate a single database schema, add the `--schema=PATTERN` parameter to your `pg_dump` command.
* To exclude a schema: `--exclude-schema=PATTERN`.
* To only migrate a single table: `--table=PATTERN`.
* To exclude a table: `--exclude-table=PATTERN`.
Run `pg_dump --help` for a full list of options.
* If you're planning to migrate a database larger than 6 GB, we recommend [upgrading to at least a Large compute add-on](/docs/guides/platform/compute-add-ons). This will ensure you have the necessary resources to handle the migration efficiently.
* We strongly advise you to pre-provision the disk space you will need for your migration. On paid projects, you can do this by navigating to the [Compute and Disk Settings](/dashboard/project/_/settings/compute-and-disk) page. For more information on disk scaling and disk limits, check out our [disk settings](/docs/guides/platform/compute-and-disk#disk) documentation.
## Enterprise
[Contact us](https://forms.supabase.com/enterprise) if you need more help migrating your project.
# Migrate from MSSQL to Supabase
Migrate your Microsoft SQL Server database to Supabase.
This guide aims to demonstrate the process of transferring your Microsoft SQL Server database to Supabase's Postgres database. Supabase is a powerful and open-source platform offering a wide range of backend features, including a Postgres database, authentication, instant APIs, edge functions, real-time subscriptions, and storage. Migrating your MSSQL database to Supabase's Postgres enables you to leverage Postgres's capabilities and access all the features you need for your project.
## Retrieve your MSSQL database credentials
Before you begin the migration, you need to collect essential information about your MSSQL database. Follow these steps:
1. Log in to your MSSQL database provider.
2. Locate and note the following database details:
* Hostname or IP address
* Database name
* Username
* Password
## Retrieve your Supabase host \[#retrieve-supabase-host]
1. If you're new to Supabase, [create a project](/dashboard).
Make a note of your password, you will need this later. If you forget it, you can [reset it here](/dashboard/project/_/database/settings).
2. On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session)
3. Under the Session pooler, click on the View parameters under the connect string. Note your Host (`$SUPABASE_HOST`).
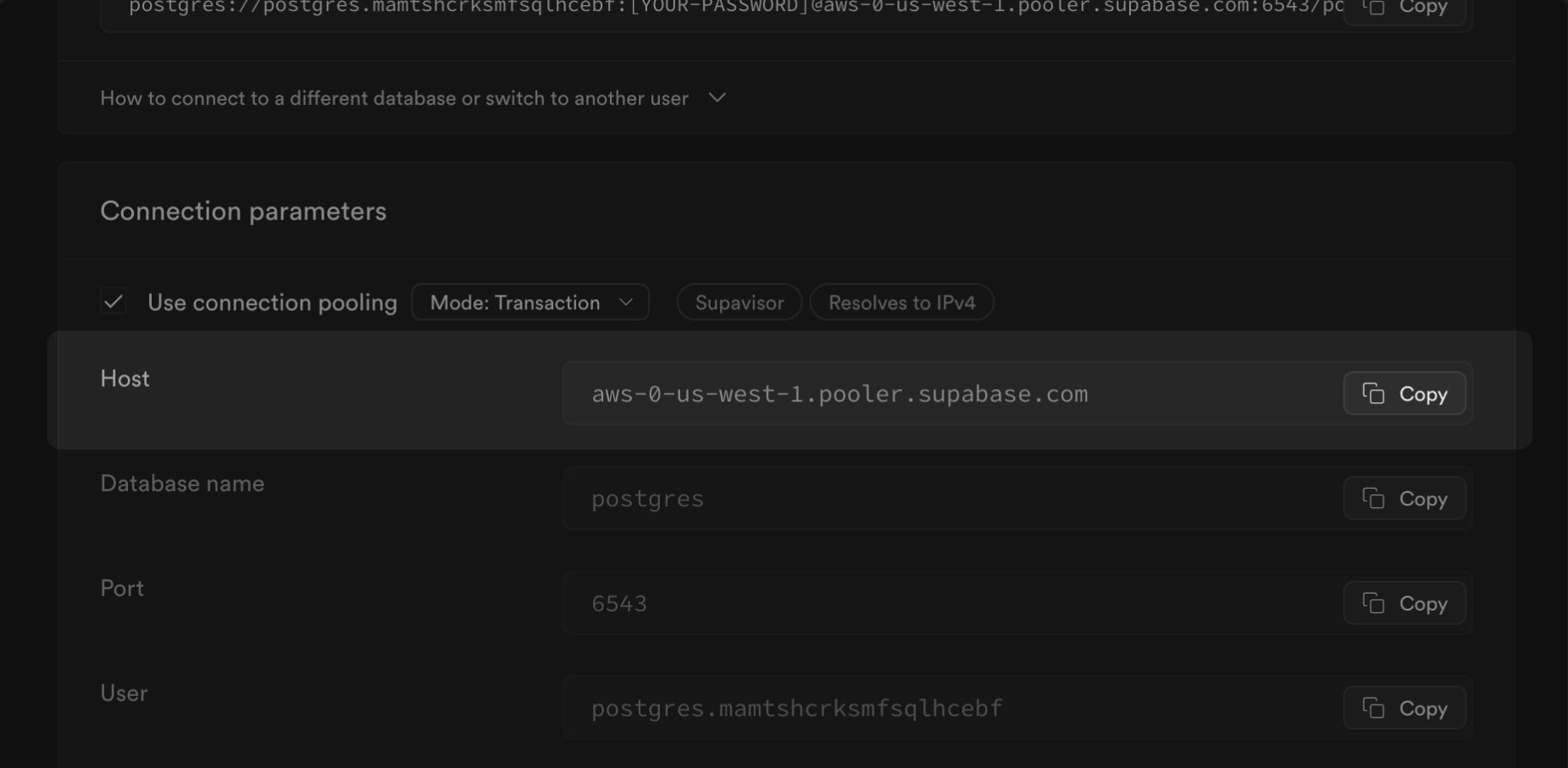
## Migrate the database
The fastest way to migrate your database is with the Supabase migration tool on
[Google Colab](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Amazon_RDS_to_Supabase.ipynb).
Alternatively, you can use [pgloader](https://github.com/dimitri/pgloader), a flexible and powerful data migration tool that supports a wide range of source database engines, including MySQL and MS SQL, and migrates the data to a Postgres database. For databases using the Postgres engine, we recommend using the [`pg_dump`](https://www.postgresql.org/docs/current/app-pgdump.html) and [psql](https://www.postgresql.org/docs/current/app-psql.html) command line tools, which are included in a full Postgres installation.
1. Select the Database Engine from the Source database in the dropdown.
2. Set the environment variables (`HOST`, `USER`, `SOURCE_DB`,`PASSWORD`, `SUPABASE_URL`, and `SUPABASE_PASSWORD`) in the Colab notebook.
3. Run the first two steps in [the notebook](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Amazon_RDS_to_Supabase.ipynb) in order. The first sets engine and installs the necessary files.
4. Run the third step to start the migration. This will take a few minutes.
1. Install pgloader.
2. Create a configuration file (e.g., config.load).
For your destination, use your Supabase connection string with `Use connection pooling` enabled, and the mode set to `Session`. You can get the string from your [`Database Settings`](/dashboard/project/_/settings/general).
```sql
LOAD DATABASE
FROM mssql://USER:PASSWORD@HOST/SOURCE_DB
INTO postgres://postgres.xxxx:password@xxxx.pooler.supabase.com:5432/postgres
ALTER SCHEMA 'public' OWNER TO 'postgres';
set wal_buffers = '64MB', max_wal_senders = 0, statement_timeout = 0, work_mem to '2GB';
```
3. Run the migration with pgloader
```bash
pgloader config.load
```
* If you're planning to migrate a database larger than 6 GB, we recommend [upgrading to at least a Large compute add-on](/docs/guides/platform/compute-add-ons). This will ensure you have the necessary resources to handle the migration efficiently.
* We strongly advise you to pre-provision the disk space you will need for your migration. On paid projects, you can do this by navigating to the [Compute and Disk Settings](/dashboard/project/_/settings/compute-and-disk) page. For more information on disk scaling and disk limits, check out our [disk settings](/docs/guides/platform/compute-and-disk#disk) documentation.
## Enterprise
[Contact us](https://forms.supabase.com/enterprise) if you need more help migrating your project.
# Migrate from MySQL to Supabase
Migrate your MySQL database to Supabase Postgres database.
This guide aims to exhibit the process of transferring your MySQL database to Supabase's Postgres database. Supabase is a robust and open-source platform offering a wide range of backend features, including a Postgres database, authentication, instant APIs, edge functions, real-time subscriptions, and storage. Migrating your MySQL database to Supabase's Postgres enables you to leverage Postgres's capabilities and access all the features you need for your project.
## Retrieve your MySQL database credentials
Before you begin the migration, you need to collect essential information about your MySQL database. Follow these steps:
1. Log in to your MySQL database provider.
2. Locate and note the following database details:
* Hostname or IP address
* Database name
* Username
* Password
## Retrieve your Supabase host \[#retrieve-supabase-host]
1. If you're new to Supabase, [create a project](/dashboard).
Make a note of your password, you will need this later. If you forget it, you can [reset it here](/dashboard/project/_/database/settings).
2. On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session)
3. Under the Session pooler, click on the View parameters under the connect string. Note your Host (`$SUPABASE_HOST`).
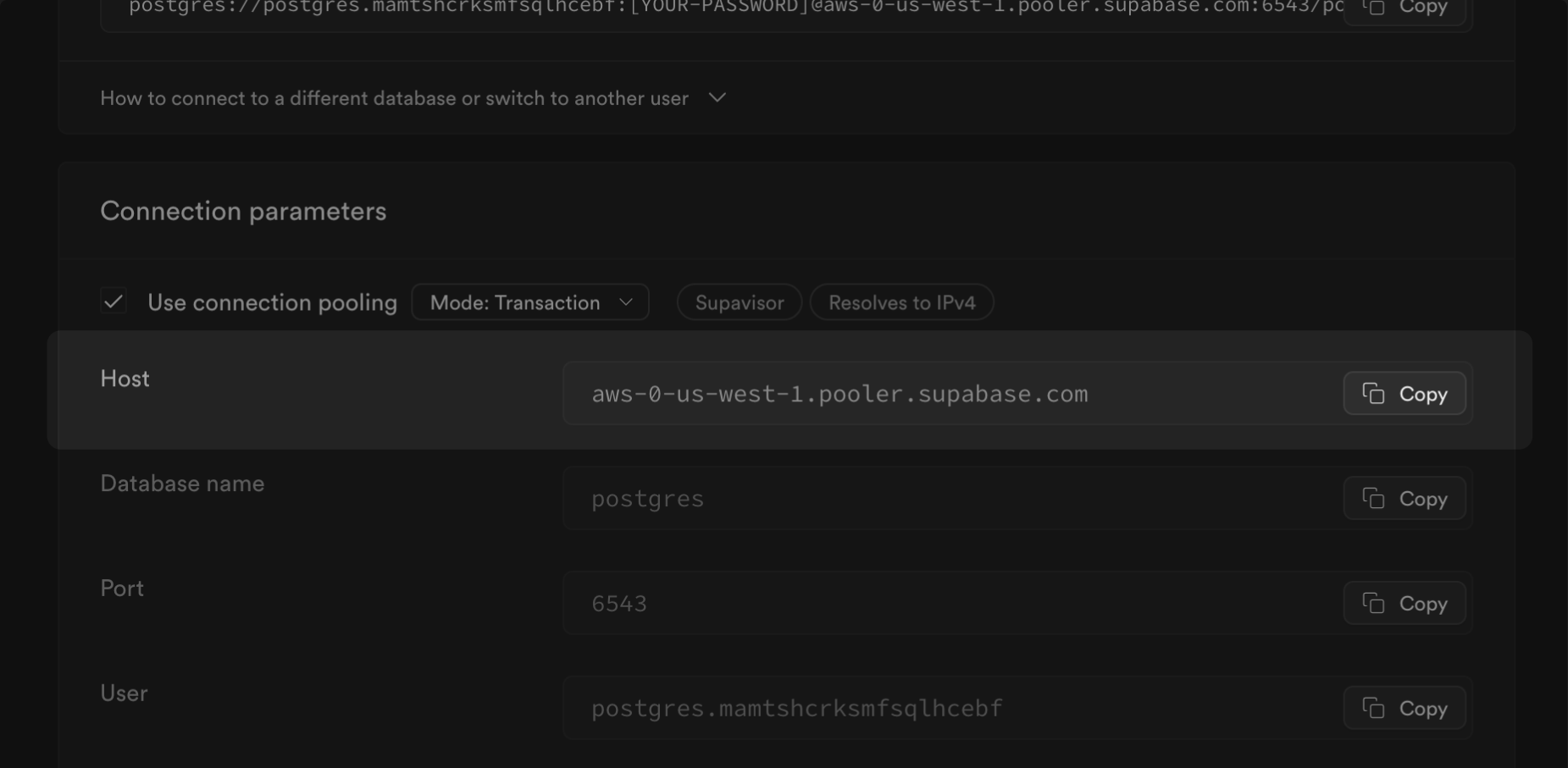
## Migrate the database
The fastest way to migrate your database is with the Supabase migration tool on
[Google Colab](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Amazon_RDS_to_Supabase.ipynb).
Alternatively, you can use [pgloader](https://github.com/dimitri/pgloader), a flexible and powerful data migration tool that supports a wide range of source database engines, including MySQL and MS SQL, and migrates the data to a Postgres database. For databases using the Postgres engine, we recommend using the [`pg_dump`](https://www.postgresql.org/docs/current/app-pgdump.html) and [psql](https://www.postgresql.org/docs/current/app-psql.html) command line tools, which are included in a full Postgres installation.
1. Select the Database Engine from the Source database in the dropdown
2. Set the environment variables (`HOST`, `USER`, `SOURCE_DB`,`PASSWORD`, `SUPABASE_URL`, and `SUPABASE_PASSWORD`) in the Colab notebook.
3. Run the first two steps in [the notebook](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Amazon_RDS_to_Supabase.ipynb) in order. The first sets engine and installs the necessary files.
4. Run the third step to start the migration. This will take a few minutes.
1. Install pgloader.
2. Create a configuration file (e.g., config.load).
For your destination, use your Supabase connection string with `Use connection pooling` enabled, and the mode set to `Session`. You can get the string from your [`Database Settings`](/dashboard/project/_/settings/general).
```sql
load database
from mysql://user:password@host/source_db
into postgres://postgres.xxxx:password@xxxx.pooler.supabase.com:5432/postgres
alter schema 'public' owner to 'postgres';
set wal_buffers = '64MB', max_wal_senders = 0, statement_timeout = 0, work_mem to '2GB';
```
3. Run the migration with pgloader
```bash
pgloader config.load
```
* If you're planning to migrate a database larger than 6 GB, we recommend [upgrading to at least a Large compute add-on](/docs/guides/platform/compute-add-ons). This will ensure you have the necessary resources to handle the migration efficiently.
* We strongly advise you to pre-provision the disk space you will need for your migration. On paid projects, you can do this by navigating to the [Compute and Disk Settings](/dashboard/project/_/settings/compute-and-disk) page. For more information on disk scaling and disk limits, check out our [disk settings](/docs/guides/platform/compute-and-disk#disk) documentation.
## Enterprise
[Contact us](https://forms.supabase.com/enterprise) if you need more help migrating your project.
# Migrate from Neon to Supabase
Migrate your existing Neon database to Supabase.
This guide demonstrates how to migrate your Neon database to Supabase to get the most out of Postgres while gaining access to all the features you need to build a project.
## Retrieve your Neon database credentials \[#retrieve-credentials]
1. Log in to your Neon Console [https://console.neon.tech/login](https://console.neon.tech/login).
2. Select **Projects** on the left.
3. Click on your project in the list.
4. From your Project Dashboard find your **Connection string** and click **Copy snippet** to copy it to the clipboard (do not check "pooled connection").
Example:
```bash
postgresql://neondb_owner:xxxxxxxxxxxxxxx-random-word-yyyyyyyy.us-west-2.aws.neon.tech/neondb?sslmode=require
```
## Set your `OLD_DB_URL` environment variable
Set the **OLD\_DB\_URL** environment variable at the command line using your Neon database credentials from the clipboard.
Example:
```bash
export OLD_DB_URL="postgresql://neondb_owner:xxxxxxxxxxxxxxx-random-word-yyyyyyyy.us-west-2.aws.neon.tech/neondb?sslmode=require"
```
## Retrieve your Supabase connection string \[#retrieve-supabase-connection-string]
1. If you're new to Supabase, [create a project](/dashboard).
Make a note of your password, you will need this later. If you forget it, you can [reset it here](/dashboard/project/_/database/settings).
2. On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session)
3. Under the Session pooler, click the **Copy** button to the right of your connection string to copy it to the clipboard.
## Set your `NEW_DB_URL` environment variable
Set the **NEW\_DB\_URL** environment variable at the command line using your Supabase connection string. You will need to replace `[YOUR-PASSWORD]` with your actual database password.
Example:
```bash
export NEW_DB_URL="postgresql://postgres.xxxxxxxxxxxxxxxxxxxx:[YOUR-PASSWORD]@aws-0-us-west-1.pooler.supabase.com:5432/postgres"
```
## Migrate the database
You will need the [pg\_dump](https://www.postgresql.org/docs/current/app-pgdump.html) and [psql](https://www.postgresql.org/docs/current/app-psql.html) command line tools, which are included in a full [Postgres installation](https://www.postgresql.org/download).
1. Export your database to a file in console
Use `pg_dump` with your Postgres credentials to export your database to a file (e.g., `dump.sql`).
```bash
pg_dump "$OLD_DB_URL" \
--clean \
--if-exists \
--quote-all-identifiers \
--no-owner \
--no-privileges \
> dump.sql
```
2. Import the database to your Supabase project
Use `psql` to import the Postgres database file to your Supabase project.
```bash
psql -d "$NEW_DB_URL" -f dump.sql
```
Additional options
* To only migrate a single database schema, add the `--schema=PATTERN` parameter to your `pg_dump` command.
* To exclude a schema: `--exclude-schema=PATTERN`.
* To only migrate a single table: `--table=PATTERN`.
* To exclude a table: `--exclude-table=PATTERN`.
Run `pg_dump --help` for a full list of options.
* If you're planning to migrate a database larger than 6 GB, we recommend [upgrading to at least a Large compute add-on](/docs/guides/platform/compute-add-ons). This will ensure you have the necessary resources to handle the migration efficiently.
* We strongly advise you to pre-provision the disk space you will need for your migration. On paid projects, you can do this by navigating to the [Compute and Disk Settings](/dashboard/project/_/settings/compute-and-disk) page. For more information on disk scaling and disk limits, check out our [disk settings](/docs/guides/platform/compute-and-disk#disk) documentation.
## Enterprise
[Contact us](https://forms.supabase.com/enterprise) if you need more help migrating your project.
# Migrate from Postgres to Supabase
Migrate your existing Postgres database to Supabase.
This is a guide for migrating your Postgres database to [Supabase](https://supabase.com).
Supabase is a robust and open-source platform. Supabase provides all the backend features developers need to build a product: a Postgres database, authentication, instant APIs, edge functions, real-time subscriptions, and storage. Postgres is the core of Supabase—for example, you can use row-level security, and there are more than 40 Postgres extensions available.
This guide demonstrates how to migrate your Postgres database to Supabase to get the most out of Postgres while gaining access to all the features you need to build a project.
This guide provides three methods for migrating your Postgres database to Supabase:
1. **Google Colab** - Guided notebook with copy-paste workflow
2. **Manual Dump/Restore** - CLI approach, works for all versions
3. **Logical Replication** - Minimal downtime, requires Postgres 10+
## Connection modes
Supabase provides the following connection modes:
* Direct connection
* Supavisor session mode
* Supavisor transaction mode
Use Supavisor session mode for the database migration tasks (pg\_dump/restore and logical replication).
## Method 1: Google Colab (easiest)
Supabase provides a Google Colab migration notebook for a guided migration experience:
[Supabase Migration Colab Notebook](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Migrate_Postgres_Supabase.ipynb)
This is ideal if you prefer a step-by-step, copy-paste workflow with minimal setup.
## Method 2: Manual dump/restore
This method works for all Postgres versions using CLI tools.
### Prerequisites
#### Source Postgres requirements
* Connection string with rights to run `pg_dump`
* No special settings required for dump/restore
* Network access from migration VM
#### Migration environment
* Cloud VM running Ubuntu in the same region as source or target database
* Postgres client tools matching your source database version
* tmux for session persistence
* Sufficient disk space (usually ~50% of source database size is enough, but varies case by case)
### Pre-Migration checklist
```sql
-- Check database size
select pg_size_pretty(pg_database_size(current_database())) as size;
-- Check Postgres version
select version();
-- List installed extensions
select * from pg_extension order by extname;
-- Check active connections
select count(*) from pg_stat_activity;
```
#### Check available extensions in Supabase
```sql
-- Connect to your Supabase database and check available extensions
SELECT name, comment FROM pg_available_extensions ORDER BY name;
-- Compare with source database extensions
SELECT extname FROM pg_extension ORDER BY extname;
-- Install needed extensions
CREATE EXTENSION IF NOT EXISTS extension_name;
```
### Step 1: Set up migration VM
For optimal performance, run the migration from a cloud VM, not your local machine. The VM should be in the same region as either your source or target database to optimize network performance. See the Resource Requirements table in Step 2 for VM sizing recommendations.
#### Set up Ubuntu VM
```bash
# Install Postgres client and tools
sudo apt update
sudo apt install software-properties-common
sudo sh -c 'echo "deb http://apt.Postgres.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.Postgres.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt update
sudo apt install Postgres-client-17 tmux htop iotop moreutils
# Start or attach to tmux session
tmux a -t migration || tmux new -s migration
```
### Step 2: Prepare Supabase project
1. Create a Supabase project at [supabase.com/dashboard](/dashboard)
2. Note your database password
3. Install required extensions via SQL or Dashboard
4. Get your connection string:
* Go to **Project → Settings → Database → Connection Pooling**
* Select **Session pooler** (port 5432) and copy the connection string
* Connection format: `Postgres://postgres.[ref]:[password]@aws-0-[region].pooler.supabase.com:5432/postgres`
**Important Notes**:
* **Users/roles are not migrated** - You'll need to recreate roles and privileges after import ([Supabase Roles Guide](/blog/postgres-roles-and-privileges))
* **Row Level Security (RLS) status on tables is not migrated** - You'll need to enable RLS for tables after migration.
**Resource Requirements**:
| Database Size | Recommended Compute | Recommended VM | Action Required |
| ------------- | ------------------- | ------------------------- | ----------------------------------------------- |
| \< 10 GB | Default | 2 vCPUs, 4 GB RAM | None |
| 10-100 GB | Default-Small | 4 vCPUs, 8 GB RAM | Consider compute upgrade |
| 100-500 GB | Large compute | 8 vCPUs, 16 GB RAM, NVMe | Upgrade compute before restore |
| 500 GB - 1 TB | XL compute | 16 vCPUs, 32 GB RAM, NVMe | Upgrade compute before restore |
| > 1 TB | Custom | Custom | [Contact support](/dashboard/support/new) first |
Also, you can temporarily increase compute size and/or disk IOPS and throughput via Settings → Compute and Disk if you want faster database restore (you can use larger -j for pg\_restore if you do so).
### Step 3: Create database dump
#### Set source database to read only mode for production migration
If doing a maintenance window migration, prevent data changes:
```sql
-- Connect to source database and run:
ALTER DATABASE your_database_name SET default_transaction_read_only = true;
```
For testing without a maintenance window, skip this step but use lower -j values.
#### Dump the database
```bash
# Determine number of parallel jobs based on:
# - Source database CPU cores (don't saturate production)
# - VM CPU cores
# - For testing without maintenance window: use lower values to be gentle
# - For production with maintenance window: can use higher values
DUMP_JOBS=4 # Adjust based on your setup
# Check available cores on VM
nproc
# Create dump with progress logging
pg_dump \
--host= \
--port= \
--username= \
--dbname= \
--jobs=$DUMP_JOBS \
--format=directory \
--no-owner \
--no-privileges \
--no-subscriptions \
--verbose \
--file=./db_dump 2>&1 | ts | tee -a dump.log
```
**Notes about dump flags**:
* `--no-owner --no-privileges`: Applied at dump time to prevent Supabase user management conflicts. While these could be used in pg\_restore instead, applying them during dump keeps the dump file cleaner and more portable.
* `--no-subscriptions`: Logical replication subscriptions won't work in the target
* The dump captures all data and schema but excludes ownership/privileges that would conflict with Supabase's managed environment
* To only migrate a single database schema, add the `--schema=PATTERN` parameter to your `pg_dump` command.
* To exclude a schema: `--exclude-schema=PATTERN`.
* To only migrate a single table: `--table=PATTERN`.
* To exclude a table: `--exclude-table=PATTERN`.
Run `pg_dump --help` for a full list of options.
#### Recommended parallelization (-j values)
| Database Size | Testing (no maintenance window) | Production (with maintenance window) | Limiting Factor |
| ------------- | ------------------------------- | ------------------------------------ | --------------- |
| \< 10 GB | 2 | 4 | Source CPU |
| 10-100 GB | 2-4 | 8 | Source CPU |
| 100-500 GB | 4 | 16 | Disk IOPS |
| 500 GB - 1 TB | 4-8 | 16-32 | Disk IOPS + CPU |
**Note**: For testing without a maintenance window, use lower -j values to avoid impacting production performance.
### Step 4: Restore to Supabase
#### Set connection and restore
```bash
# Set Supabase connection (Session Pooler on port 5432 or direct connection)
export SUPABASE_DB_URL="Postgres://postgres.[ref]:[password]@aws-0-[region].pooler.supabase.com:5432/postgres"
# Determine restore parallelization based on your Supabase compute size:
# Free tier: 2 cores → use -j 2
# Small compute: 2 cores → use -j 2
# Medium compute: 4 cores → use -j 4
# Large compute: 8 cores → use -j 8
# XL compute: 16 cores → use -j 16
RESTORE_JOBS=8 # Adjust based on your Supabase compute size
# Restore the dump (parallel mode)
# Note: -j cannot be used with --single-transaction
pg_restore \
--dbname="$SUPABASE_DB_URL" \
--jobs=$RESTORE_JOBS \
--format=directory \
--no-owner \
--no-privileges \
--verbose \
./db_dump 2>&1 | ts | tee -a restore.log
```
If restore fails with extension errors, check that errors are only extension-related.
### Step 5: Post-Migration tasks
#### Update statistics (important)
```bash
psql "$SUPABASE_DB_URL" -c "VACUUM VERBOSE ANALYZE;"
```
For Postgres 18+, pg\_dump includes statistics with `--with-statistics`, but you should still run VACUUM for optimal performance.
#### Verify migration
```sql
-- Check row counts
select schemaname, tablename, n_live_tup
from pg_stat_user_tables
order by n_live_tup desc
limit 20;
-- Verify data with application-specific queries
```
#### Re-enable writes on source (if keeping it)
```sql
ALTER DATABASE your_database_name SET default_transaction_read_only = false;
```
### Migration time estimates
| Database Size | Dump Time | Restore Time | Total Time |
| ------------- | --------- | ------------ | ----------- |
| 10 GB | ~5 min | ~10 min | ~15 min |
| 100 GB | ~30 min | ~45 min | ~1.5 hours |
| 500 GB | ~2 hours | ~3 hours | ~5 hours |
| 1 TB | ~4 hours | ~6 hours | ~10 hours |
*Times vary based on hardware, network, and parallelization settings*
### Important notes
1. **Region proximity matters**: VM should be in the same region as the source or target for best performance
2. **Downgrade migrations**: While technically possible in some cases, highly not recommended
3. **Testing without downtime**: Use lower `-j` values for pg\_dump to avoid impacting production
4. **For pg\_restore**: Can use full parallelization regardless of production impact
5. **Monitor resources**: Watch CPU, disk I/O with `htop`, `iotop`
6. **Disk I/O**: Often the bottleneck before network bandwidth
***
## Method 3: Logical replication
This method allows migration with minimal downtime using Postgres's logical replication feature. Requires Postgres 10+ on both source and target.
### When to use logical replication
* You need minimal downtime (minutes instead of hours)
* Source database is Postgres 10 or higher
* You can configure logical replication on the source
* Database has high write activity that can't be paused for long
### Source Postgres prerequisites
#### Access & privileges
* Connection string with rights to CREATE PUBLICATION and read tables
* Superuser or replication privileges recommended
#### Required settings for logical replication
* `wal_level = logical`
* `max_wal_senders ≥ 1`
* `max_replication_slots ≥ 1`
* Sufficient `max_connections` (current + 1 for subscription)
#### Replica identity
Every table receiving UPDATE/DELETE must have a replica identity (typically a PRIMARY KEY). For tables without one:
```sql
ALTER TABLE schema.table_name REPLICA IDENTITY FULL;
```
#### Non-Replicated items
* **DDL changes** (schema modifications)
* **Sequences** (need manual sync)
* **Large Objects (LOBs)** (use dump/restore or store in regular bytea columns)
Plan a schema freeze, sequence sync before cutover, and handle LOBs separately.
### Step 1: Configure source database
Edit Postgres configuration files:
#### Postgres.conf
```bash
# Set Supabase connection (Session Pooler on port 5432 or direct connection)
export SUPABASE_DB_URL="Postgres://postgres.[ref]:[password]@aws-0-[region].pooler.supabase.com:5432/postgres"
# Set WAL level to logical
wal_level = logical
# Ensure sufficient replication slots
max_replication_slots = 10
# Ensure sufficient WAL senders
max_wal_senders = 10
# Set appropriate max_connections (current connections + 1 for subscription)
max_connections = 200 # Adjust based on your needs
# Optional: Enable SSL for secure replication
ssl = on
# Allow connections from Supabase
listen_addresses = '*' # Or specific IP addresses
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
#### pg\_hba.conf
```bash
# Allow replication connections from Supabase
# Replace with actual Supabase IP range
host replication all md5
host all all md5
# With SSL:
hostssl replication all md5
hostssl all all md5
```
Restart Postgres:
```bash
sudo systemctl restart Postgres
sudo systemctl status Postgres
```
### Step 2: Verify configuration
```sql
-- Should return 'logical'
SHOW wal_level;
-- Check other parameters
SHOW max_replication_slots;
SHOW max_wal_senders;
-- Check current connections
SELECT count(*) FROM pg_stat_activity;
```
### Step 3: Check and set replica identity
```sql
-- Find tables without primary keys
SELECT n.nspname, c.relname
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_constraint pk ON pk.conrelid = c.oid AND pk.contype = 'p'
WHERE c.relkind = 'r'
AND pk.oid IS NULL
AND n.nspname NOT IN ('pg_catalog','information_schema');
-- For tables without a primary key, set REPLICA IDENTITY FULL
ALTER TABLE my_schema.my_table REPLICA IDENTITY FULL;
```
### Step 4: Export and restore schema only
```bash
# Export schema from source
pg_dump \
-h \
-U \
-p \
-d \
--schema-only \
--no-privileges \
--no-subscriptions \
--format=directory \
-f ./schema_dump
# Restore schema to Supabase (use Session Pooler)
pg_restore \
--dbname="$SUPABASE_DB_URL" \
--format=directory \
--schema-only \
--no-privileges \
--single-transaction \
--verbose \
./schema_dump
```
### Step 5: Create publication on source
```sql
-- Create publication for all tables
CREATE PUBLICATION supabase_migration FOR ALL TABLES;
-- Or for specific tables only (doesn't require superuser)
CREATE PUBLICATION supabase_migration FOR TABLE
schema1.table1,
schema1.table2,
public.table3;
-- Verify publication was created
SELECT * FROM pg_publication;
```
### Step 6: Create subscription on Supabase
Connect to your Supabase database:
```sql
-- Create subscription with SSL (recommended)
CREATE SUBSCRIPTION supabase_subscription
CONNECTION 'host= port= user= password= dbname= sslmode=require'
PUBLICATION supabase_migration;
-- Or without SSL (if source doesn't support it)
CREATE SUBSCRIPTION supabase_subscription
CONNECTION 'host= port= user= password= dbname= sslmode=disable'
PUBLICATION supabase_migration;
```
### Step 7: Monitor replication status
```sql
-- On Supabase (subscriber) - check subscription status
select * from pg_subscription_rel;
-- srsubstate = 'r' means ready (synchronized)
-- srsubstate = 'i' means initializing
-- srsubstate = 'd' means data is being copied
-- Overall subscription status
select * from pg_stat_subscription;
-- On source database - check replication status
select * from pg_stat_replication;
-- Check replication lag
select
slot_name,
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)) as lag_size
from pg_replication_slots;
```
Wait until all tables show `srsubstate = 'r'` (ready) status.
### Step 8: Synchronize sequences
After initial data sync is complete, but BEFORE switching to Supabase:
```bash
# Set source to read-only
psql -h -c "ALTER DATABASE SET default_transaction_read_only = true;"
# Export sequences from source
pg_dump \
-h \
-U \
-p \
-d \
--data-only \
--table='*_seq' \
--table='*_id_seq' > sequences.sql
# Import sequences to Supabase
psql "$SUPABASE_DB_URL" -f sequences.sql
```
### Step 9: Switch to Supabase
1. Ensure replication lag is zero:
```sql
-- On Supabase
select * from pg_stat_subscription;
-- Check that latest_end_lsn is current
```
2. Stop writes to the source database (if not already read-only)
3. Drop subscription on Supabase:
```sql
DROP SUBSCRIPTION supabase_subscription;
```
4. Update application connection strings to point to Supabase
5. Verify application functionality
### Step 10: Cleanup
On source database (after successful migration):
```sql
-- Remove publication
DROP PUBLICATION supabase_migration;
-- Check and remove any remaining replication slots
SELECT * FROM pg_replication_slots;
DROP REPLICATION SLOT slot_name; -- if any remain
-- The source database should remain read-only or be decommissioned
-- Do NOT re-enable writes to avoid a split-brain scenario!
```
### Troubleshooting logical replication
| Issue | Solution |
| ------------------------------------ | ------------------------------------------------------------------- |
| "could not connect to the publisher" | Check network connectivity, firewall rules, pg\_hba.conf |
| "role does not exist" | Ensure replication user exists on source with REPLICATION privilege |
| "publication does not exist" | Verify publication name and that it was created successfully |
| Replication lag growing | Check network bandwidth, source database load, add more WAL senders |
| Tables stuck in `i` state | Check for locks on source tables, verify table structure matches |
| "out of replication slots" | Increase max\_replication\_slots in Postgres.conf |
### Important limitations
* **DDL changes**: Schema modifications are not replicated - freeze schema during migration
* **Sequences**: Need manual synchronization before cutover
* **Large Objects (LOBs)**: Not replicated - use dump/restore or store in regular bytea columns
* **Custom types**: May need special handling
* **Users and roles**: Must be recreated manually on Supabase
For detailed restrictions, see [Postgres Logical Replication Restrictions](https://www.Postgres.org/docs/current/logical-replication-restrictions.html)
### When to use which method
**Use Dump/Restore when:**
* Downtime window is acceptable
* Source is Postgres \< 10
* Simpler process preferred
* Cannot configure logical replication on the source
**Use Logical Replication when:**
* Minimal downtime required
* Postgres 10+ on both sides
* Can modify source configuration
* Have replication privileges
## Getting help
* For databases > 150 GB: [Contact Supabase support](/dashboard/support/new) before starting
* [Supabase Dashboard Support](/dashboard/support/new)
* [Supabase Discord](https://discord.supabase.com)
* [Postgres Roles and Privileges Guide](/blog/postgres-roles-and-privileges)
* [Row Level Security Guide](/docs/guides/database/postgres/row-level-security)
# Migrate from Render to Supabase
Migrate your Render Postgres database to Supabase.
Render is a popular Web Hosting service in the online services category that also has a managed Postgres service. Render has a great developer experience, allowing users to deploy straight from GitHub or GitLab. This is the core of their product and they do it really well. However, when it comes to Postgres databases, it may not be the best option.
Supabase is one of the best free alternative to Render Postgres. Supabase provide all the backend features developers need to build a product: a Postgres database, authentication, instant APIs, edge functions, realtime subscriptions, and storage. Postgres is the core of Supabase—for example, you can use row-level security and there are more than 40 Postgres extensions available.
This guide demonstrates how to migrate from Render to Supabase to get the most out of Postgres while gaining access to all the features you need to build a project.
## Retrieve your Render database credentials \[#retrieve-render-credentials]
1. Log in to your [Render account](https://render.com) and select the project you want to migrate.
2. Click **Dashboard** in the menu and click in your **Postgres** database.
3. Scroll down in the **Info** tab.
4. Click on **PSQL Command** and edit it adding the content after `PSQL_COMMAND=`.
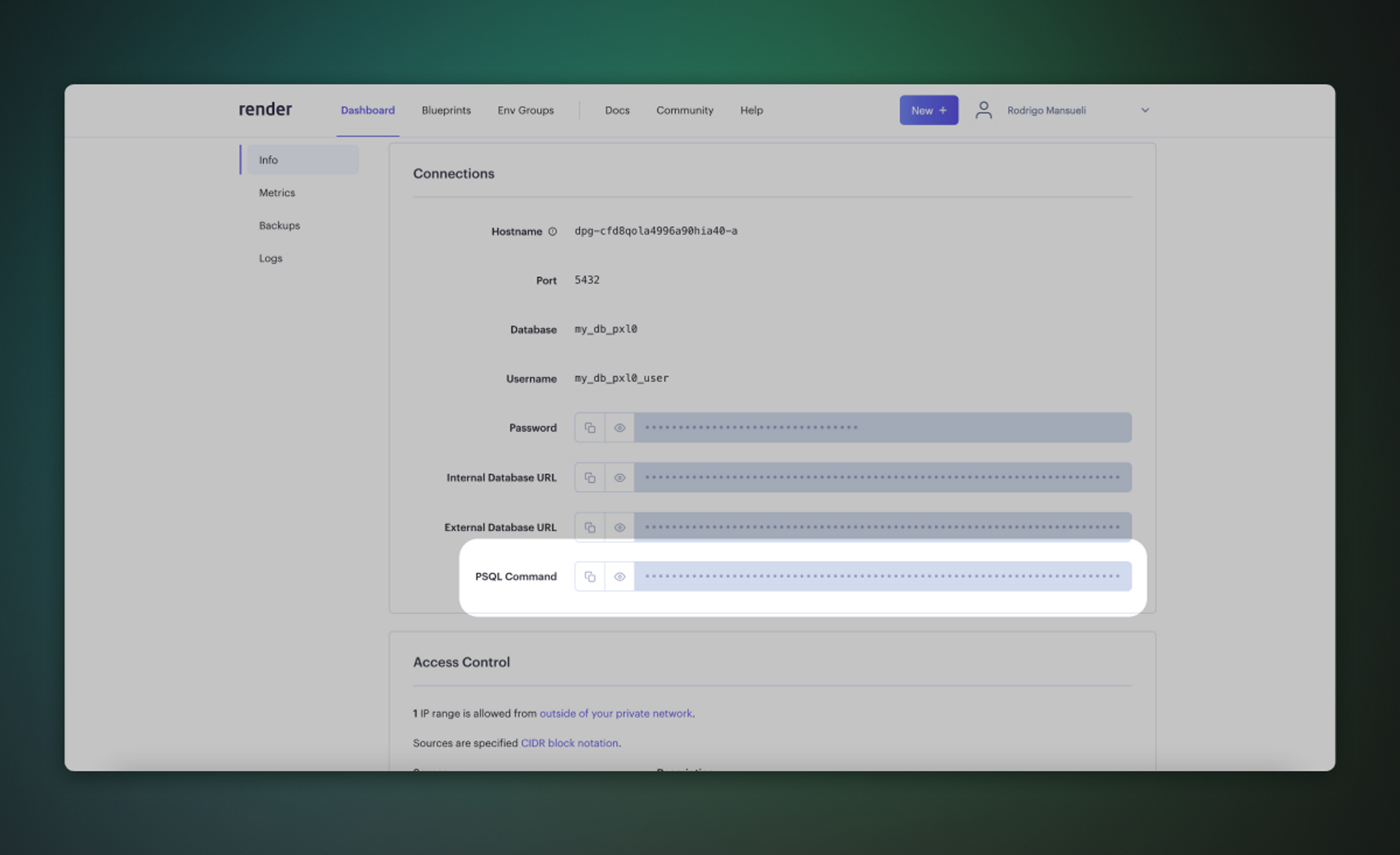
Example:
```bash
%env PSQL_COMMAND=PGPASSWORD=RgaMDfTS_password_FTPa7 psql -h dpg-a_server_in.oregon-postgres.render.com -U my_db_pxl0_user my_db_pxl0
```
## Retrieve your Supabase connection string \[#retrieve-supabase-connection-string]
1. If you're new to Supabase, [create a project](/dashboard).
Make a note of your password, you will need this later. If you forget it, you can [reset it here](/dashboard/project/_/database/settings).
2. On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session)
3. Under Session pooler, Copy the connection string and replace the password placeholder with your database password.
If you're in an [IPv6 environment](https://github.com/orgs/supabase/discussions/27034) or have the IPv4 Add-On, you can use the direct connection string instead of Supavisor in Session mode.
## Migrate the database
The fastest way to migrate your database is with the Supabase migration tool on [Google Colab](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Migrate_Postgres_Supabase.ipynb). Alternatively, you can use the [pg\_dump](https://www.postgresql.org/docs/current/app-pgdump.html) and [psql](https://www.postgresql.org/docs/current/app-psql.html) command line tools, which are included in a full Postgres installation.
1. Set the environment variables (`PSQL_COMMAND`, `SUPABASE_HOST`, `SUPABASE_PASSWORD`) in the Colab notebook.
2. Run the first two steps in [the notebook](https://colab.research.google.com/github/mansueli/Supa-Migrate/blob/main/Migrate_Postgres_Supabase.ipynb) in order. The first sets the variables and the second installs PSQL and the migration script.
3. Run the third step to start the migration. This will take a few minutes.
1. Export your Render database to a file in console
Use `pg_dump` with your Render credentials to export your Render database to a file (e.g., `render_dump.sql`).
```bash
pg_dump --clean --if-exists --quote-all-identifiers \
-h $RENDER_HOST -U $RENDER_USER -d $RENDER_DATABASE \
--no-owner --no-privileges > render_dump.sql
```
2. Import the database to your Supabase project
Use `psql` to import the Render database file to your Supabase project.
```bash
psql -d "$YOUR_CONNECTION_STRING" -f render_dump.sql
```
Additional options
* To only migrate a single database schema, add the `--schema=PATTERN` parameter to your `pg_dump` command.
* To exclude a schema: `--exclude-schema=PATTERN`.
* To only migrate a single table: `--table=PATTERN`.
* To exclude a table: `--exclude-table=PATTERN`.
Run `pg_dump --help` for a full list of options.
* If you're planning to migrate a database larger than 6 GB, we recommend [upgrading to at least a Large compute add-on](/docs/guides/platform/compute-add-ons). This will ensure you have the necessary resources to handle the migration efficiently.
* We strongly advise you to pre-provision the disk space you will need for your migration. On paid projects, you can do this by navigating to the [Compute and Disk Settings](/dashboard/project/_/settings/compute-and-disk) page. For more information on disk scaling and disk limits, check out our [disk settings](/docs/guides/platform/compute-and-disk#disk) documentation.
## Enterprise
[Contact us](https://forms.supabase.com/enterprise) if you need more help migrating your project.
# Migrate from Vercel Postgres to Supabase
Migrate your existing Vercel Postgres database to Supabase.
This guide demonstrates how to migrate your Vercel Postgres database to Supabase to get the most out of Postgres while gaining access to all the features you need to build a project.
## Retrieve your Vercel Postgres database credentials \[#retrieve-credentials]
1. Log in to your Vercel Dashboard [https://vercel.com/login](https://vercel.com/login).
2. Click on the **Storage** tab.
3. Click on your Postgres Database.
4. Under the **Quickstart** section, select **psql** then click **Show Secret** to reveal your database password.
5. Copy the string after `psql ` to the clipboard.
Example:
```bash
psql "postgres://default:xxxxxxxxxxxx@yy-yyyyy-yyyyyy-yyyyyyy.us-west-2.aws.neon.tech:5432/verceldb?sslmode=require"
```
Copy this part to your clipboard:
```bash
"postgres://default:xxxxxxxxxxxx@yy-yyyyy-yyyyyy-yyyyyyy.us-west-2.aws.neon.tech:5432/verceldb?sslmode=require"
```
## Set your `OLD_DB_URL` environment variable
Set the **OLD\_DB\_URL** environment variable at the command line using your Vercel Postgres Database credentials.
Example:
```bash
export OLD_DB_URL="postgres://default:xxxxxxxxxxxx@yy-yyyyy-yyyyyy-yyyyyyy.us-west-2.aws.neon.tech:5432/verceldb?sslmode=require"
```
## Retrieve your Supabase connection string \[#retrieve-supabase-connection-string]
1. If you're new to Supabase, [create a project](/dashboard).
Make a note of your password, you will need this later. If you forget it, you can [reset it here](/dashboard/project/_/database/settings).
2. On your project dashboard, click [Connect](/dashboard/project/_?showConnect=true\&method=session)
3. Under the Session pooler, click the **Copy** button to the right of your connection string to copy it to the clipboard.
## Set your `NEW_DB_URL` environment variable
Set the **NEW\_DB\_URL** environment variable at the command line using your Supabase connection string. You will need to replace `[YOUR-PASSWORD]` with your actual database password.
Example:
```bash
export NEW_DB_URL="postgresql://postgres.xxxxxxxxxxxxxxxxxxxx:[YOUR-PASSWORD]@aws-0-us-west-1.pooler.supabase.com:5432/postgres"
```
## Migrate the database
You will need the [pg\_dump](https://www.postgresql.org/docs/current/app-pgdump.html) and [psql](https://www.postgresql.org/docs/current/app-psql.html) command line tools, which are included in a full [Postgres installation](https://www.postgresql.org/download).
1. Export your database to a file in console
Use `pg_dump` with your Postgres credentials to export your database to a file (e.g., `dump.sql`).
```bash
pg_dump "$OLD_DB_URL" \
--clean \
--if-exists \
--quote-all-identifiers \
--no-owner \
--no-privileges \
> dump.sql
```
2. Import the database to your Supabase project
Use `psql` to import the Postgres database file to your Supabase project.
```bash
psql -d "$NEW_DB_URL" -f dump.sql
```
Additional options
* To only migrate a single database schema, add the `--schema=PATTERN` parameter to your `pg_dump` command.
* To exclude a schema: `--exclude-schema=PATTERN`.
* To only migrate a single table: `--table=PATTERN`.
* To exclude a table: `--exclude-table=PATTERN`.
Run `pg_dump --help` for a full list of options.
* If you're planning to migrate a database larger than 6 GB, we recommend [upgrading to at least a Large compute add-on](/docs/guides/platform/compute-add-ons). This will ensure you have the necessary resources to handle the migration efficiently.
* We strongly advise you to pre-provision the disk space you will need for your migration. On paid projects, you can do this by navigating to the [Compute and Disk Settings](/dashboard/project/_/settings/compute-and-disk) page. For more information on disk scaling and disk limits, check out our [disk settings](/docs/guides/platform/compute-and-disk#disk) documentation.
## Enterprise
[Contact us](https://forms.supabase.com/enterprise) if you need more help migrating your project.
# Enforce MFA on Organization
Supabase provides multi-factor authentication (MFA) enforcement on the organization level. With MFA enforcement, you can ensure that all organization members use MFA. Members cannot interact with your organization or your organization's projects without a valid MFA-backed session.
MFA enforcement is only available on the [Pro, Team and Enterprise plans](/pricing).
## Manage MFA enforcement
To enable MFA on an organization, visit the [security settings](/dashboard/org/_/security) page and toggle `Require MFA to access organization` on.
* Only organization **owners** can modify this setting
* The owner must have [MFA on their own account](/docs/guides/platform/multi-factor-authentication)
* Supabase recommends creating two distinct MFA apps on your user account
When MFA enforcement is enabled, users without MFA will immediately lose access all resources in the organization. The users will still be members of the organization and will regain their original permissions once they enable MFA on their account.
## Personal access tokens
Personal access tokens are not affected by MFA enforcement. Personal access tokens are designed for programmatic access and issuing of these require a valid Supabase session backed by MFA, if enabled on the account.
# Manage Advanced MFA Phone usage
## What you are charged for
You are charged for having the feature [Advanced Multi-Factor Authentication Phone](/docs/guides/auth/auth-mfa/phone) enabled for your project.
The Advanced MFA Phone add-on is **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
Additional charges apply for each SMS or WhatsApp message sent, depending on your third-party messaging provider (such as Twilio or MessageBird).
## How charges are calculated
MFA Phone is charged by the hour, meaning you are charged for the exact number of hours that the feature is enabled for a project. If the feature is enabled for part of an hour, you are still charged for the full hour.
### Example
Your billing cycle runs from January 1 to January 31. On January 10 at 4:30 PM, you enable the MFA Phone feature for your project. At the end of the billing cycle you are billed for 512 hours.
| Time Window | MFA Phone | Hours Billed | Description |
| ------------------------------------------- | --------- | ------------ | ------------------- |
| January 1, 00:00 AM - January 10, 4:00 PM | Disabled | 0 | |
| January 10, 04:00 PM - January 10, 4:30 PM | Disabled | 0 | |
| January 10, 04:30 PM - January 10, 5:00 PM | Enabled | 1 | full hour is billed |
| January 10, 05:00 PM - January 31, 23:59 PM | Enabled | 511 | |
### Usage on your invoice
Usage is shown as "Auth MFA Phone Hours" on your invoice.
## Pricing
## Pricing
per hour ( per month) for the first project.
per hour ( per month) for every additional project.
| Plan | Project 1 per month | Project 2 per month | Project 3 per month |
| ---------- | -------------------- | -------------------- | -------------------- |
| Pro | | | |
| Team | | | |
| Enterprise | Custom | Custom | Custom |
For a detailed breakdown of how charges are calculated, refer to [Manage Advanced MFA Phone usage](/docs/guides/platform/manage-your-usage/advanced-mfa-phone).
## Billing examples
### One project
The project has MFA Phone activated throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------- |
| Pro Plan | - | |
| Compute Hours Micro Project 1 | 744 | |
| MFA Phone Hours | 744 | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Multiple projects
All projects have MFA Phone activated throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------- |
| Pro Plan | - | |
| | | |
| Compute Hours Micro Project 1 | 744 | |
| MFA Phone Hours Project 1 | 744 | |
| | | |
| Compute Hours Micro Project 2 | 744 | |
| MFA Phone Hours Project 2 | 744 | |
| | | |
| Compute Hours Micro Project 3 | 744 | |
| MFA Phone Hours Project 3 | 744 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Add-on disabled after a day
Project add-ons are billed in arrears based on how many hours you used them.
If you remove the MFA Phone add-on, you are no longer billed from the time of removal onward.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | --------------------------- |
| Pro Plan | - | |
| | | |
| Compute Hours Micro Project 1 | 744 | |
| MFA Phone Hours Project 1 | 24 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
# Manage Branching usage
## What you are charged for
Each [Preview branch](/docs/guides/deployment/branching) is a separate environment with all Supabase services (Database, Auth, Storage, etc.). You're charged for usage within that environment—such as [Compute](/docs/guides/platform/manage-your-usage/compute), [Disk Size](/docs/guides/platform/manage-your-usage/disk-size), [Egress](/docs/guides/platform/manage-your-usage/egress), and [Storage](/docs/guides/platform/manage-your-usage/storage-size)—just like the project you branched from.
Usage by Preview branches counts toward your subscription plan's quota. Branches are **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
## How charges are calculated
Refer to individual [usage items](/docs/guides/platform/manage-your-usage) for details on how charges are calculated. Branching charges are the sum of all these items.
### Usage on your invoice
Compute incurred by Preview branches is shown as "Branching Compute Hours" on your invoice. Other usage items are not shown separately for branches and are rolled up into the project.
## Pricing
There is no fixed fee for a Preview branch. You only pay for the usage it incurs. A branch running on the default Micro Compute size starts at per hour.
## Billing examples
The project has a Preview branch "XYZ", that runs for 30 hours, incurring Compute and Egress costs. Disk Size usage remains within the 8 GB included in the subscription plan, so no additional charges apply.
| Line Item | Costs |
| ------------------------------ | -------------------------- |
| Pro Plan | |
| | |
| Compute Hours Small Project 1 | |
| Egress Project 1 | |
| Disk Size Project 1 | |
| | |
| Compute Hours Micro Branch XYZ | |
| Egress Branch XYZ | |
| Disk Size Branch XYZ | |
| | |
| **Subtotal** | **** |
| Compute Credits | - |
| **Total** | **** |
## View usage
You can view Branching usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Usage Summary section, you can see how many hours your Preview branches existed during the selected time period. Hover over "Branching Compute Hours" for a detailed breakdown.
## Optimize usage
* Merge Preview branches as soon as they are ready
* Delete Preview branches that are no longer in use
* Check whether your [persistent branches](/docs/guides/deployment/branching#persistent-branches) need to be defined as persistent, or if they can be ephemeral instead. Persistent branches will remain active even after the underlying PR is closed.
## FAQ
### Do Compute Credits apply to Branching Compute?
No, Compute Credits do not apply to Branching Compute.
# Manage Compute usage
## What you are charged for
Each project on the Supabase platform includes a dedicated Postgres instance running on its own server. You are charged for the [Compute](/docs/guides/platform/compute-and-disk#compute) resources of that server, independent of your database usage.
Paused projects do not count towards Compute usage. Compute Hours are **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
## How charges are calculated
Compute is charged by the hour, meaning you are charged for the exact number of hours that a project is running and, therefore, incurring Compute usage. If a project runs for part of an hour, you are still charged for the full hour.
Each project you launch increases your monthly Compute costs.
### Example
Your billing cycle runs from January 1 to January 31. On January 10 at 4:30 PM, you switch your project from the Micro Compute size to the Small Compute size. At the end of the billing cycle you are billed for 233 hours of Micro Compute size and 511 hours of Small Compute size.
| Time Window | Compute Size | Hours Billed | Description |
| ------------------------------------------- | ------------ | ------------ | ------------------- |
| January 1, 00:00 AM - January 10, 4:00 PM | Micro | 232 | |
| January 10, 04:00 PM - January 10, 4:30 PM | Micro | 1 | full hour is billed |
| January 10, 04:30 PM - January 10, 5:00 PM | Small | 1 | full hour is billed |
| January 10, 05:00 PM - January 31, 23:59 PM | Small | 511 | |
### Usage on your invoice
Usage is shown as "Compute Hours" on your invoice.
## Compute Credits
Paid plans include in Compute Credits, which cover one project running on the Micro/Nano Compute size or portions of other Compute sizes. Compute Credits are applied to your Compute costs and are provided to an organization each month. They reset monthly and do not accumulate.
## Pricing
| Compute Size | Hourly Price USD | Monthly Price USD |
| ------------ | ------------------------- | -------------------------------------------------------------------------------------------------------- |
| Nano\[^1] | | |
| Micro | | ~ |
| Small | | ~ |
| Medium | | ~ |
| Large | | ~ |
| XL | | ~ |
| 2XL | | ~ |
| 4XL | | ~ |
| 8XL | | ~ |
| 12XL | | ~ |
| 16XL | | ~ |
| >16XL | - | [Contact Us](/dashboard/support/new?category=sales\&subject=Enquiry%20about%20larger%20instance%20sizes) |
\[^1]: Compute resources on the Free Plan are subject to change.
In paid organizations, Nano Compute are billed at the same price as Micro Compute. It is recommended to upgrade your Project from Nano Compute to Micro Compute when it's convenient for you. Compute sizes are not auto-upgraded because of the downtime incurred. See [Supabase Pricing](/pricing) for more information. You cannot launch Nano instances on paid plans, only Micro and above - but you might have Nano instances after upgrading from Free Plan.
## Billing examples
### One project
The project runs on the same Compute size throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------ |
| Pro Plan | - | |
| Compute Hours Micro Project 1 | 744 | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Multiple projects
All projects run on the same Compute size throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------ |
| Pro Plan | - | |
| Compute Hours Micro Project 1 | 744 | |
| Compute Hours Micro Project 2 | 744 | |
| Compute Hours Micro Project 3 | 744 | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### One project on different Compute sizes
The project's Compute size changes throughout the billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------ |
| Pro Plan | - | |
| Compute Hours Micro Project 1 | 233 | |
| Compute Hours Small Project 1 | 511 | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Projects not running for full month
One project is running for the entire month, two other projects were launched and deleted within a few days.
We only bill for the hours while the project was running and billing stops once a project is deleted.
Compute is always billed in arrears when your billing cycle resets.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | --------------------------- |
| Pro Plan | - | |
| Compute Hours Micro Project 1 | 744 | |
| Compute Hours Micro Project 2 | 20 | |
| Compute Hours Micro Project 3 | 70 | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Compute usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Compute Hours section, you can see how many hours of a specific Compute size your projects have used during the selected time period. Hover over a specific date for a daily breakdown.
## Optimize usage
* Start out on a smaller Compute size, [create a report](/dashboard/project/_/observability) on the Dashboard to monitor your CPU and memory utilization, and upgrade the Compute size as needed
* Load test your application in staging to understand your Compute requirements
* [Transfer projects](/docs/guides/platform/project-transfer) to a Free Plan organization to reduce Compute usage
* Delete unused projects
## FAQ
### Do Compute Credits apply to line items other than Compute?
No, Compute Credits apply only to Compute and do not cover other line items, including Read Replica Compute and Branching Compute.
# Manage Custom Domain usage
## What you are charged for
You can configure a [custom domain](/docs/guides/platform/custom-domains) for a project by enabling the [Custom Domain add-on](/dashboard/project/_/settings/addons?panel=customDomain). You are charged for all custom domains configured across your projects.
Custom Domains are **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
## How charges are calculated
Custom domains are charged by the hour, meaning you are charged for the exact number of hours that a custom domain is active. If a custom domain is active for part of an hour, you are still charged for the full hour.
### Example
Your billing cycle runs from January 1 to January 31. On January 10 at 4:30 PM, you activate a custom domain for your project. At the end of the billing cycle you are billed for 512 hours.
| Time Window | Custom Domain Activated | Hours Billed | Description |
| ------------------------------------------- | ----------------------- | ------------ | ------------------- |
| January 1, 00:00 AM - January 10, 4:00 PM | No | 0 | |
| January 10, 04:00 PM - January 10, 4:30 PM | No | 0 | |
| January 10, 04:30 PM - January 10, 5:00 PM | Yes | 1 | full hour is billed |
| January 10, 05:00 PM - January 31, 23:59 PM | Yes | 511 | |
### Usage on your invoice
Usage is shown as "Custom Domain Hours" on your invoice.
## Pricing
per hour ( per month).
## Billing examples
### One project
The project has a custom domain activated throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------ |
| Pro Plan | - | |
| Compute Hours Micro Project 1 | 744 | |
| Custom Domain Hours | 744 | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Multiple projects
All projects have a custom domain activated throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------ |
| Pro Plan | - | |
| | | |
| Compute Hours Micro Project 1 | 744 | |
| Custom Domain Hours Project 1 | 744 | |
| | | |
| Compute Hours Micro Project 2 | 744 | |
| Custom Domain Hours Project 2 | 744 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Add-on disabled after a day
Project add-ons are billed in arrears based on how many hours you used them.
If you remove the custom domain add-on, you are no longer billed from the time of removal onward.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | --------------------------- |
| Pro Plan | - | |
| | | |
| Compute Hours Micro Project 1 | 744 | |
| Custom Domain Hours Project 1 | 24 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## Optimize usage
* Regularly check your projects and remove custom domains that are no longer needed
* Use free [Vanity subdomains](/docs/guides/platform/custom-domains#vanity-subdomains) where applicable
# Manage Disk IOPS usage
## What you are charged for
Each database has a dedicated disk, and you are charged for its provisioned disk IOPS. However, unless you explicitly opt in for additional IOPS, no charges apply.
Refer to our [disk guide](/docs/guides/platform/compute-and-disk#disk) for details on how disk IOPS, disk throughput, disk size, disk type and compute size interact, along with their limitations and constraints.
Disk IOPS Hours are **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
Launching a Read Replica creates an additional database with its own dedicated disk. Read Replicas inherit the primary database's disk IOPS settings. You are charged for the provisioned IOPS of the Read Replica. Refer to [Manage Read Replica usage](/docs/guides/platform/manage-your-usage/read-replicas) for details on billing.
## How charges are calculated
Disk IOPS is charged by IOPS-Hrs. 1 IOPS-Hr represents 1 IOPS being provisioned for 1 hour. For example, having 10 IOPS provisioned for 5 hours results in 50 IOPS-Hrs (10 IOPS × 5 hours).
### Usage on your invoice
Usage is shown as "Disk IOPS-Hrs" on your invoice.
## Pricing
Pricing depends on the [disk type](/docs/guides/platform/compute-and-disk#disk-types), with type gp3 being the default.
### General purpose disks (gp3)
per IOPS-Hr ( per IOPS per month). gp3 disks
come with a default IOPS of 3,000. You are only charged for provisioned IOPS exceeding these 3,000
IOPS.
| Plan | Included Disk IOPS | Over-Usage per IOPS per month | Over-Usage per IOPS-Hr |
| ---------- | ------------------ | ----------------------------- | ---------------------------- |
| Pro | 3,000 | | |
| Team | 3,000 | | |
| Enterprise | Custom | Custom | Custom |
### High performance disks (io2)
per IOPS-Hr ( per IOPS per month). Unlike general
purpose disks, high performance disks are billed from the first provisioned IOPS.
| Plan | Included Disk IOPS | Usage per IOPS per month | Usage per IOPS-Hr |
| ---------- | ------------------ | ------------------------ | -------------------------- |
| Pro | 0 | | |
| Team | 0 | | |
| Enterprise | Custom | Custom | Custom |
## Billing examples
### Gp3
Project 1 doesn't exceed the included IOPS, so no charges for IOPS apply. Project 2 exceeds the included IOPS by 600, incurring charges for this additional usage.
| Line Item | Units | Costs |
| ----------------------------- | ---------- | ---------------------------- |
| Pro Plan | 1 | |
| | | |
| Compute Hours Micro Project 1 | 744 hours | |
| Disk IOPS Project 1 | 3,000 IOPS | |
| | | |
| Compute Hours Large Project 2 | 744 hours | |
| Disk IOPS Project 2 | 3,600 IOPS | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Io2
This disk type is billed from the first IOPS provisioned, meaning for 8000 IOPS.
| Line Item | Units | Costs |
| ----------------------------- | ---------- | --------------------------- |
| Pro Plan | 1 | |
| Compute Hours Large Project 1 | 744 hours | |
| Disk IOPS Project 1 | 8,000 IOPS | |
| **Subtotal** | | **,087** |
| Compute Credits | | - |
| **Total** | | **,077** |
# Manage Disk size usage
## What you are charged for
Each database has a dedicated [disk](/docs/guides/platform/compute-and-disk#disk). You are charged for the provisioned disk size.
Disk size is not relevant for the Free Plan. Instead Free Plan customers are limited by [Database size](/docs/guides/platform/database-size).
## How charges are calculated
Disk size is charged by Gigabyte-Hours (GB-Hrs). 1 GB-Hr represents 1 GB being provisioned for 1 hour.
For example, having 10 GB provisioned for 5 hours results in 50 GB-Hrs (10 GB × 5 hours).
### Usage on your invoice
Usage is shown as "Disk Size GB-Hrs" on your invoice.
## Pricing
Pricing depends on the [disk type](/docs/guides/platform/compute-and-disk#disk-types), with gp3 being the default disk type.
### General purpose disks (gp3)
per GB-Hr ( per GB per month). The primary
database of your project gets provisioned with an 8 GB disk. You are only charged for provisioned
disk size exceeding these 8 GB.
| Plan | Included Disk Size | Over-Usage per GB per month | Over-Usage per GB-Hr |
| ---------- | ------------------ | --------------------------- | -------------------------- |
| Pro | 8 GB | | |
| Team | 8 GB | | |
| Enterprise | Custom | Custom | Custom |
Launching a Read Replica creates an additional database with its own dedicated disk. You are charged from the first byte of provisioned disk for the Read Replica. Refer to [Manage Read Replica usage](/docs/guides/platform/manage-your-usage/read-replicas) for details on billing.
### High performance disks (io2)
per GB-Hr ( per GB per month). Unlike general
purpose disks, high performance disks are billed from the first byte of provisioned disk.
| Plan | Included Disk size | Usage per GB per month | Usage per GB-Hr |
| ---------- | ------------------ | ----------------------- | -------------------------- |
| Pro | 0 GB | | |
| Team | 0 GB | | |
| Enterprise | Custom | Custom | Custom |
## Billing examples
### Gp3
Project 1 and 2 don't exceed the included disk size, so no charges for Disk size apply. Project 3 exceeds the included disk size by 42 GB, incurring charges for this additional usage.
| Line Item | Units | Costs |
| ----------------------------- | --------- | --------------------------- |
| Pro Plan | 1 | |
| | | |
| Compute Hours Micro Project 1 | 744 hours | |
| Disk Size Project 1 | 8 GB | |
| | | |
| Compute Hours Micro Project 2 | 744 hours | |
| Disk Size Project 2 | 8 GB | |
| | | |
| Compute Hours Micro Project 3 | 744 hours | |
| Disk Size Project 3 | 50 GB | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Io2
This disk type is billed from the first byte of provisioned disk, meaning for 66 GB across all projects.
| Line Item | Units | Costs |
| ----------------------------- | --------- | --------------------------- |
| Pro Plan | 1 | |
| | | |
| Compute Hours Micro Project 1 | 744 hours | |
| Disk Size Project 1 | 8 GB | |
| | | |
| Compute Hours Micro Project 2 | 744 hours | |
| Disk Size Project 2 | 8 GB | |
| | | |
| Compute Hours Micro Project 3 | 744 hours | |
| Disk Size Project 3 | 50 GB | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Disk size usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown.
In the Disk size section, you can see how much disk size your projects have provisioned.
### Disk size distribution
To see how your disk usage is distributed across Database, WAL, and System categories, refer to [Disk size distribution](/docs/guides/platform/database-size#disk-size-distribution).
## Reduce Disk size
To see how you can downsize your disk, refer to [Reducing disk size](/docs/guides/platform/database-size#reducing-disk-size)
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage Disk Throughput usage
## What you are charged for
Each database has a dedicated disk, and you are charged for its provisioned disk throughput. However, unless you explicitly opt in for additional throughput, no charges apply.
Refer to our [disk guide](/docs/guides/platform/compute-and-disk#disk) for details on how disk throughput, disk IOPS, disk size, disk type and compute size interact, along with their limitations and constraints.
Disk Throughput is **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
Launching a Read Replica creates an additional database with its own dedicated disk. Read Replicas inherit the primary database's disk throughput settings. You are charged for the provisioned throughput of the Read Replica.
## How charges are calculated
Disk throughput is charged by MB/s-Hrs (MB/s stands for megabytes per second). 1 MB/s-Hr represents disk throughput of 1 MB/s being provisioned for 1 hour. For example, having 10 MB/s provisioned for 5 hours results in 50 MB/s-Hrs (10 MB/s × 5 hours).
### Usage on your invoice
Usage is shown as "Disk Throughput MB/s-Hrs" on your invoice.
## Pricing
Pricing depends on the [disk type](/docs/guides/platform/compute-and-disk#disk-types), with type gp3 being the default.
### General purpose disks (gp3)
per MB/s-Hr ( per MB/s per month). gp3 disks come
with a baseline throughput of 125 MB/s. You are only charged for provisioned throughput exceeding
these 125 MB/s.
| Plan | Included Disk Throughput | Over-Usage per MB/s per month | Over-Usage per MB/s-Hr |
| ---------- | ------------------------ | ----------------------------- | ------------------------- |
| Pro | 125 MB/s | | |
| Team | 125 MB/s | | |
| Enterprise | Custom | Custom | Custom |
### High performance disks (io2)
There are no charges. Throughput scales with IOPS at no additional cost.
## Billing examples
### No additional throughput configured
| Line Item | Units | Costs |
| ----------------------------- | --------- | ------------------------ |
| Pro Plan | 1 | |
| | | |
| Compute Hours Micro Project 1 | 744 hours | |
| Disk Throughput Project 1 | 125 MB/s | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Additional throughput configured
| Line Item | Units | Costs |
| ----------------------------- | --------- | ---------------------------- |
| Pro Plan | 1 | |
| | | |
| Compute Hours Large Project 1 | 744 hours | |
| Disk Throughput Project 1 | 200 MB/s | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Additional throughput configured with Read Replica
| Line Item | Units | Costs |
| ----------------------------- | --------- | ---------------------------- |
| Pro Plan | 1 | |
| | | |
| Compute Hours Large Project 1 | 744 hours | |
| Disk Throughput Project 1 | 200 MB/s | |
| | | |
| Compute Hours Large Replica | 744 hours | |
| Disk Throughput Replica | 200 MB/s | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
# Manage Edge Function Invocations usage
## What you are charged for
You are charged for the number of times your functions get invoked, regardless of the response status code. Preflight (OPTIONS) requests are not billed.
## How charges are calculated
Edge Function Invocations are billed using Package pricing, with each package representing 1 million invocations. If your usage falls between two packages, you are billed for the next whole package.
### Example
For simplicity, let's assume a package size of 1 million and a charge of per package without a free quota.
| Invocations | Packages Billed | Costs |
| ----------- | --------------- | ------------------- |
| 999,999 | 1 | |
| 1,000,000 | 1 | |
| 1,000,001 | 2 | |
| 1,500,000 | 2 | |
### Usage on your invoice
Usage is shown as "Function Invocations" on your invoice.
## Pricing
per 1 million invocations. You are only charged for usage exceeding your
subscription plan's quota.
| Plan | Quota | Over-Usage |
| ---------- | --------- | --------------------------------------------- |
| Free | 500,000 | - |
| Pro | 2 million | per 1 million invocations |
| Team | 2 million | per 1 million invocations |
| Enterprise | Custom | Custom |
## Billing examples
### Within quota
The organization's function invocations are within the quota, so no charges apply.
| Line Item | Units | Costs |
| -------------------- | --------------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Function Invocations | 1,800,000 invocations | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's function invocations exceed the quota by 1.4 million, incurring charges for this additional usage.
| Line Item | Units | Costs |
| -------------------- | --------------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Function Invocations | 3,400,000 invocations | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Edge Function Invocations usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Edge Function Invocations section, you can see how many invocations your projects have had during the selected time period.
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage Egress usage
## What you are charged for
You are charged for the network data transmitted out of the system to a connected client. Egress is incurred by all services - Database, Auth, Storage, Edge Functions, Realtime and Log Drains.
### Database Egress
Data sent to the client when retrieving data stored in your database.
**Example:** A user views their order history in an online shop. The client application requests the database to retrieve the user's past orders. The order data is sent back to the client, contributing to Database Egress.
There are various ways to interact with your database, such as through the PostgREST API using one of the client SDKs or via the Supavisor connection pooler. On the Supabase Dashboard, Egress from the PostgREST API is labeled as **Database Egress**, while Egress through Supavisor is labeled as **Shared Pooler Egress**.
### Auth Egress
Data sent from Supabase Auth to the client while managing your application's users. This includes actions like signing in, signing out, or creating new users, e.g. via the JavaScript Client SDK.
**Example:** A user signs in to an online shop. The client application requests the Supabase Auth service to authenticate and authorize the user. The session data, including authentication tokens and user profile details, is sent back to the client, contributing to Auth Egress.
### Storage Egress
Data sent from Supabase Storage to the client when retrieving assets. This includes actions like downloading files, images, or other stored content, e.g. via the JavaScript Client SDK.
**Example:** A user downloads an invoice from an online shop. The client application requests Supabase Storage to retrieve the PDF file from the storage bucket. The file is sent back to the client, contributing to Storage Egress.
### Edge Functions Egress
Data sent to the client when executing Edge Functions.
**Example:** A user completes a checkout process in an online shop. The client application triggers an Edge Function to process the payment and confirm the order. The confirmation response, along with any necessary details, is sent back to the client, contributing to Edge Functions Egress.
### Realtime Egress
Data pushed to clients via Supabase Realtime for subscribed events.
**Example:** When a user views a product page in an online shop, their client subscribes to real-time inventory updates. As stock levels change, Supabase Realtime pushes updates to all subscribed clients, contributing to Realtime Egress.
### Shared pooler Egress
Data sent to the client when using the shared connection pooler (Supavisor) to access your database. When using the shared connection pooler, we do not count database egress, as this would otherwise count double (Database -> Shared Pooler + Shared Pooler -> Client).
**Example:** You are using our [shared connection pooler](/docs/guides/database/connecting-to-postgres#shared-pooler) and you query a list of invoices in your backend. The data returned from that query is contributing to Shared Pooler Egress.
### Log Drain Egress
Data pushed to the connected log drain.
**Example:** You set up a log drain, each log sent to the log drain is considered egress. You can toggle the GZIP option to reduce egress, in case your provider supports it.
### Cached Egress
Cached and uncached egress have independent quotas and independent pricing. Cached egress is egress that is served from our CDN via cache hits. Cached egress is typically incurred for storage through our [Smart CDN](/docs/guides/storage/cdn/smart-cdn).
## How charges are calculated
Egress is charged by gigabyte. Charges apply only for usage exceeding your subscription plan's quota. This quota is called the Unified Egress Quota because it can be used across all services (Database, Auth, Storage etc.).
### Usage on your invoice
Usage is shown as "Egress GB" and "Cached Egress GB" on your invoice.
## Pricing
per GB per month for uncached egress, per GB per month
for cached egress. You are only charged for usage exceeding your subscription plan's quota.
| Plan | Egress Quota (Uncached / Cached) | Over-Usage per month (Uncached / Cached) |
| ---------- | -------------------------------- | ------------------------------------------------------------- |
| Free | 5 GB / 5 GB | - |
| Pro | 250 GB / 250 GB | per GB / per GB |
| Team | 250 GB / 250 GB | per GB / per GB |
| Enterprise | Custom | Custom |
## Billing examples
### Within quota
The organization's Egress usage is within the quota, so no charges for Egress apply.
| Line Item | Units | Costs |
| ------------------- | --------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Egress | 200 GB | |
| Cached Egress | 230 GB | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's Egress usage exceeds the uncached egress quota by 50 GB and the cached egress quota by 550 GB, incurring charges for this additional usage.
| Line Item | Units | Costs |
| ------------------- | --------- | -------------------------- |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Egress | 300 GB | |
| Cached Egress | 800 GB | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
### Usage page
You can view Egress usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Total Egress section, you can see the usage for the selected time period. Hover over a specific date to view a breakdown by service. Note that this includes the cached egress.
Separately, you can see the cached egress right below:
### Custom report
1. On the [Observability page](/dashboard/project/_/observability), click **New custom report** in the left navigation menu
2. After creating a new report, add charts for one or more Supabase services by clicking **Add block**
## Debug usage
To better understand your Egress usage, identify what’s driving the most traffic. Check the most frequent database queries, or analyze the most requested API paths to pinpoint high-egress endpoints.
### Frequent database queries
On the Advisors [Query performance view](/dashboard/project/_/database/query-performance?preset=most_frequent\&sort=calls\&order=desc) you can see the most frequent queries and the average number of rows returned.
### Most requested API endpoints
In the [Logs Explorer](/dashboard/project/_/logs/explorer) you can access Edge Logs, and review the top paths to identify heavily queried endpoints. These logs currently do not include response byte data. That data will be available in the future too.
## Optimize usage
* Reduce the number of fields or entries selected when querying your database
* Reduce the number of queries or calls by optimizing client code or using caches
* For update or insert queries, configure your ORM or queries to not return the entire row if not needed
* When running manual backups through Supavisor, remove unneeded tables and/or reduce the frequency
* Refer to the [Storage Optimizations guide](/docs/guides/storage/production/scaling#egress) for tips on reducing Storage Egress
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage IPv4 usage
## What you are charged for
You can assign a dedicated [IPv4 address](/docs/guides/platform/ipv4-address) to a database by enabling the [IPv4 add-on](/dashboard/project/_/settings/addons?panel=ipv4). You are charged for all IPv4 addresses configured across your databases.
IPv4 Hours are **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
If the primary database has a dedicated IPv4 address configured, its Read Replicas are also assigned one, with charges for each.
## How charges are calculated
IPv4 addresses are charged by the hour, meaning you are charged for the exact number of hours that an IPv4 address is assigned to a database. If an address is assigned for part of an hour, you are still charged for the full hour.
### Example
Your billing cycle runs from January 1 to January 31. On January 10 at 4:30 PM, you enable the IPv4 add-on for your project. At the end of the billing cycle you are billed for 512 hours.
| Time Window | IPv4 add-on | Hours Billed | Description |
| ------------------------------------------- | ----------- | ------------ | ------------------- |
| January 1, 00:00 AM - January 10, 4:00 PM | Disabled | 0 | |
| January 10, 04:00 PM - January 10, 4:30 PM | Disabled | 0 | |
| January 10, 04:30 PM - January 10, 5:00 PM | Enabled | 1 | full hour is billed |
| January 10, 05:00 PM - January 31, 23:59 PM | Enabled | 511 | |
### Usage on your invoice
Usage is shown as "IPv4 Hours" on your invoice.
## Pricing
per hour ( per month).
## Billing examples
### One project
The project has the IPv4 add-on enabled throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------ |
| Pro Plan | - | |
| Compute Hours Micro Project 1 | 744 | |
| IPv4 Hours | 744 | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Multiple projects
All projects have the IPv4 add-on enabled throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------ |
| Pro Plan | - | |
| | | |
| Compute Hours Micro Project 1 | 744 | |
| IPv4 Hours Project 1 | 744 | |
| | | |
| Compute Hours Micro Project 2 | 744 | |
| IPv4 Hours Project 2 | 744 | |
| | | |
| Compute Hours Micro Project 3 | 744 | |
| IPv4 Hours Project 3 | 744 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### One project with Read Replicas
The project has two Read Replicas and the IPv4 add-on enabled throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------ |
| Pro Plan | - | |
| | | |
| Compute Hours Small Project 1 | 744 | |
| IPv4 Hours Project 1 | 744 | |
| | | |
| Compute Hours Small Replica 1 | 744 | |
| IPv4 Hours Replica 1 | 744 | |
| | | |
| Compute Hours Small Replica 2 | 744 | |
| IPv4 Hours Replica 2 | 744 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Add-on disabled after a day
Project add-ons are billed in arrears based on how many hours you used them.
If you remove the IPv4 add-on, you are no longer billed from the time of removal onward.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | --------------------------- |
| Pro Plan | - | |
| | | |
| Compute Hours Micro Project 1 | 744 | |
| IPv4 Hours Project 1 | 24 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## Optimize usage
To see whether your database actually needs a dedicated IPv4 address, refer to [When you need the IPv4 add-on](/docs/guides/platform/ipv4-address#when-you-need-the-ipv4-add-on).
# Manage Log Drain usage
## What you are charged for
You can configure log drains in the [project settings](/dashboard/project/_/settings/log-drains) to send logs to one or more destinations. You are charged for each log drain that is configured (referred to as [Log Drain Hours](/docs/guides/platform/manage-your-usage/log-drains#log-drain-hours)), the log events sent (referred to as [Log Drain Events](/docs/guides/platform/manage-your-usage/log-drains#log-drain-events)), and the [Egress](/docs/guides/platform/manage-your-usage/egress) incurred by the export—across all your projects.
Log Drains are **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
## Log Drain Hours
### How charges are calculated
You are charged by the hour, meaning you are charged for the exact number of hours that a log drain is configured for a project. If a log drain is configured for part of an hour, you are still charged for the full hour.
#### Example
Your billing cycle runs from January 1 to January 31. On January 10 at 4:30 PM, you configure a log drain for your project. At the end of the billing cycle you are billed for 512 hours.
| Time Window | Log Drain Configured | Hours Billed | Description |
| ------------------------------------------- | -------------------- | ------------ | ------------------- |
| January 1, 00:00 AM - January 10, 4:00 PM | No | 0 | |
| January 10, 04:00 PM - January 10, 4:30 PM | No | 0 | |
| January 10, 04:30 PM - January 10, 5:00 PM | Yes | 1 | full hour is billed |
| January 10, 05:00 PM - January 31, 23:59 PM | Yes | 511 | |
#### Usage on your invoice
Usage is shown as "Log Drain Hours" on your invoice.
### Pricing
Log Drains are available as a project Add-On for all Pro, Team and Enterprise users. Each Log Drain costs per hour ( per month).
## Log Drain Events
### How charges are calculated
Log Drain Events are billed using Package pricing, with each package representing 1 million events. If your usage falls between two packages, you are billed for the next whole package.
#### Example
| Events | Packages Billed | Costs |
| --------- | --------------- | --------------------- |
| 999,999 | 1 | |
| 1,000,000 | 1 | |
| 1,000,001 | 2 | |
| 1,500,000 | 2 | |
#### Usage on your invoice
Usage is shown as "Log Drain Events" on your invoice.
### Pricing
per 1 million events.
## Billing example
The project has two log drains configured throughout the entire billing cycle with 800,000 and 1.6 million events each. In this example we assume that the organization is exceeding its Unified Egress Quota, so charges for Egress apply.
| Line Item | Units | Costs |
| ----------------------------- | ------------------ | ---------------------------- |
| Team Plan | 1 | |
| | | |
| Compute Hours Micro Project 1 | 744 hours | |
| | | |
| Log Drain Hours Drain 1 | 744 hours | |
| Log Drain Events Drain 1 | 800,000 events | |
| Egress Drain 1 | 2 GB | |
| | | |
| Log Drain Hours Drain 2 | 744 hours | |
| Log Drain Events Drain 2 | 1.6 million events | |
| Egress Drain 2 | 4 GB | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Add-on disabled after a day
Project add-ons are billed in arrears based on how many hours you used them.
If you remove the log drain add-on, you are no longer billed from the time of removal onward.
| Line Item | Hours | Costs |
| ----------------------------- | -------- | --------------------------- |
| Pro Plan | - | |
| | | |
| Compute Hours Micro Project 1 | 744 | |
| | | |
| Log Drain Hours Drain 1 | 24 | |
| Log Drain Events Drain 1 | 0 events | |
| Egress Drain 1 | 0 GB | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Log Drain Events usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
# Manage Monthly Active SSO Users usage
## What you are charged for
You are charged for the number of distinct users who log in or refresh their token during the billing cycle using a SAML 2.0 compatible identity provider (e.g. Google Workspace, Microsoft Active Directory). Each unique user is counted only once per billing cycle, regardless of how many times they authenticate. These users are referred to as "SSO MAUs".
### Example
Your billing cycle runs from January 1 to January 31. Although User-1 was signed in multiple times, they are counted as a single SSO MAU for this billing cycle.
The SSO MAU count increases from 0 to 1.
```javascript
const { data, error } = await supabase.auth.signInWithSSO({
domain: 'company.com'
})
if (data?.url) {
// redirect User-1 to the identity provider's authentication flow
window.location.href = data.url
}
```
{' '}
```javascript
const { error } = await supabase.auth.signOut()
```
The SSO MAU count remains 1.
```javascript
const { data, error } = await supabase.auth.signInWithSSO({
domain: 'company.com'
})
if (data?.url) {
// redirect User-1 to the identity provider's authentication flow
window.location.href = data.url
}
```
## How charges are calculated
You are charged by SSO MAU.
### Usage on your invoice
Usage is shown as "Monthly Active SSO Users" on your invoice.
## Pricing
## Pricing
per SSO MAU. You are only charged for usage exceeding your subscription
plan's quota.
For a detailed breakdown of how charges are calculated, refer to [Manage Monthly Active SSO Users usage](/docs/guides/platform/manage-your-usage/monthly-active-users-sso).
The count resets at the start of each billing cycle.
| Plan | Quota | Over-Usage |
| ---------- | ------ | ----------------------------------- |
| Pro | 50 | per SSO MAU |
| Team | 50 | per SSO MAU |
| Enterprise | Custom | Custom |
## Billing examples
### Within quota
The organization's SSO MAU usage for the billing cycle is within the quota, so no charges apply.
| Line Item | Units | Costs |
| ------------------------ | ---------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Monthly Active SSO Users | 37 SSO MAU | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's SSO MAU usage for the billing cycle exceeds the quota by 10, incurring charges for this additional usage.
| Line Item | Units | Costs |
| ------------------------ | ---------- | --------------------------- |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Monthly Active SSO Users | 60 SSO MAU | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Monthly Active SSO Users usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Monthly Active SSO Users section, you can see the usage for the selected time period.
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage Monthly Active Third-Party Users usage
## What you are charged for
You are charged for the number of distinct users who log in or refresh their token during the billing cycle using a third-party authentication provider (Clerk, Firebase Auth, Auth0, AWS Cognito). Each unique user is counted only once per billing cycle, regardless of how many times they authenticate. These users are referred to as "Third-Party MAUs".
### Example
Your billing cycle runs from January 1 to January 31. Although User-1 was signed in multiple times, they are counted as a single SSO MAU for this billing cycle.
The Third-Party MAU count increases from 0 to 1.
The Third-Party MAU count remains 1.
## How charges are calculated
You are charged by Third-Party MAU.
### Usage on your invoice
Usage is shown as "Monthly Active Third-Party Users" on your invoice.
## Pricing
## Pricing
per Third-Party MAU. You are only charged for usage exceeding your
subscription plan's quota.
For a detailed breakdown of how charges are calculated, refer to [Manage Monthly Active Third-Party Users usage](/docs/guides/platform/manage-your-usage/monthly-active-users-third-party).
The count resets at the start of each billing cycle.
| Plan | Quota | Over-Usage |
| ---------- | ------- | --------------------------------------------- |
| Free | 50,000 | - |
| Pro | 100,000 | per Third-Party MAU |
| Team | 100,000 | per Third-Party MAU |
| Enterprise | Custom | Custom |
## Billing examples
### Within quota
The organization's Third-Party MAU usage for the billing cycle is within the quota, so no charges apply.
| Line Item | Units | Costs |
| -------------------------------- | ---------------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Monthly Active Third-Party Users | 37,000 Third-Party MAU | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's Third-Party MAU usage for the billing cycle exceeds the quota by 4950, incurring charges for this additional usage.
| Line Item | Units | Costs |
| -------------------------------- | ----------------------- | ---------------------------- |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Monthly Active Third-Party Users | 130,000 Third-Party MAU | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Monthly Active Third-Party Users usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage Monthly Active Users usage
## What you are charged for
You are charged for the number of distinct users who log in or refresh their token during the billing cycle (including Social Login with e.g. Google, Facebook, GitHub). Each unique user is counted only once per billing cycle, regardless of how many times they authenticate. These users are referred to as "MAUs".
### Example
Your billing cycle runs from January 1 to January 31. Although User-1 was signed in multiple times, they are counted as a single MAU for this billing cycle.
The MAU count increases from 0 to 1.
```javascript
const {data, error} = await supabase.auth.signInWithPassword({
email: 'user-1@email.com',
password: 'example-password-1',
})
```
{' '}
`javascript const {error} = await supabase.auth.signOut() `
The MAU count remains 1.
```javascript
const {data, error} = await supabase.auth.signInWithPassword({
email: 'user-1@email.com',
password: 'example-password-1',
})
```
## How charges are calculated
You are charged by MAU.
### Usage on your invoice
Usage is shown as "Monthly Active Users" on your invoice.
## Pricing
per MAU. You are only charged for usage exceeding your subscription plan's
quota.
The count resets at the start of each billing cycle.
| Plan | Quota | Over-Usage |
| ---------- | ------- | --------------------------------- |
| Free | 50,000 | - |
| Pro | 100,000 | per MAU |
| Team | 100,000 | per MAU |
| Enterprise | Custom | Custom |
## Billing examples
### Within quota
The organization's MAU usage for the billing cycle is within the quota, so no charges apply.
| Line Item | Units | Costs |
| -------------------- | ---------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Monthly Active Users | 23,000 MAU | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's MAU usage for the billing cycle exceeds the quota by 60,000, incurring charges for this additional usage.
| Line Item | Units | Costs |
| -------------------- | ----------- | ------------------------- |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Monthly Active Users | 160,000 MAU | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Monthly Active Users usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Monthly Active Users section, you can see the usage for the selected time period.
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage Point-in-Time Recovery usage
## What you are charged for
You can configure [Point-in-Time Recovery (PITR)](/docs/guides/platform/backups#point-in-time-recovery) for a project by enabling the [PITR add-on](/dashboard/project/_/settings/addons?panel=pitr). You are charged for every enabled PITR add-on across your projects.
Point-In-Time Recovery add-on is **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
## How charges are calculated
PITR is charged by the hour, meaning you are charged for the exact number of hours that PITR is active for a project. If PITR is active for part of an hour, you are still charged for the full hour.
### Example
Your billing cycle runs from January 1 to January 31. On January 10 at 4:30 PM, you activate PITR for your project. At the end of the billing cycle you are billed for 512 hours.
| Time Window | PITR Activated | Hours Billed | Description |
| ------------------------------------------- | -------------- | ------------ | ------------------- |
| January 1, 00:00 AM - January 10, 4:00 PM | No | 0 | |
| January 10, 04:00 PM - January 10, 4:30 PM | No | 0 | |
| January 10, 04:30 PM - January 10, 5:00 PM | Yes | 1 | full hour is billed |
| January 10, 05:00 PM - January 31, 23:59 PM | Yes | 511 | |
### Usage on your invoice
Usage is shown as "Point-in-time recovery Hours" on your invoice.
## Pricing
### Pricing
Pricing depends on the recovery retention period, which determines how many days back you can restore data to any chosen point of up to seconds in granularity.
| Recovery Retention Period in Days | Hourly Price USD | Monthly Price USD |
| --------------------------------- | ----------------------- | --------------------- |
| 7 | | |
| 14 | | |
| 28 | | |
For a detailed breakdown of how charges are calculated, refer to [Manage Point-in-Time Recovery usage](/docs/guides/platform/manage-your-usage/point-in-time-recovery).
## Billing examples
### One project
The project has PITR with a recovery retention period of 7 days activated throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------- |
| Pro Plan | - | |
| Compute Hours Small Project 1 | 744 | |
| 7-day PITR Hours Project 1 | 744 | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Multiple projects
All projects have PITR with a recovery retention period of 14 days activated throughout the entire billing cycle.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | ------------------------- |
| Pro Plan | - | |
| | | |
| Compute Hours Small Project 1 | 744 | |
| 14-day PITR Hours Project 1 | 744 | |
| | | |
| Compute Hours Small Project 2 | 744 | |
| 14-day PITR Hours Project 2 | 744 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Add-on disabled after a day
Project add-ons are billed in arrears based on how many hours you used them.
If you remove the PITR add-on, you are no longer billed from the time of removal onward.
| Line Item | Hours | Costs |
| ----------------------------- | ----- | --------------------------- |
| Pro Plan | - | |
| | | |
| Compute Hours Micro Project 1 | 744 | |
| 7-day PITR Hours Project 1 | 24 | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## Optimize usage
* Review your [backup frequency](/docs/guides/platform/backups#frequency-of-backups) needs to determine whether you require PITR or free Daily Backups are sufficient
* Regularly check your projects and disable PITR where no longer needed
* Consider disabling PITR for non-production databases
# Manage Read Replica usage
## What you are charged for
Each [Read Replica](/docs/guides/platform/read-replicas) is a dedicated database. You are charged for its resources, which are the following, and mirrored from the primary database:
* [Compute](/docs/guides/platform/compute-and-disk#compute)
* [Disk Size](/docs/guides/platform/database-size#disk-size)
* Provisioned [Disk IOPS](/docs/guides/platform/compute-and-disk#provisioned-disk-throughput-and-iops)
* Provisioned [Disk Throughput](/docs/guides/platform/compute-and-disk#provisioned-disk-throughput-and-iops)
* [IPv4](/docs/guides/platform/ipv4-address).
Read Replicas are **not** covered by the [Spend Cap](/docs/guides/platform/cost-control#spend-cap).
## How we calculate charges
Read Replica charges are the total of the charges listed below.
### Compute
Compute is charged by the hour, meaning you are charged for the exact number of hours that a Read Replica is running and, therefore, incurring Compute usage. If a Read Replica runs for part of an hour, you are still charged for the full hour.
Read Replicas run on the same Compute size as the primary database.
### Disk size
Read [the Manage Disk Size usage guide](/docs/guides/platform/manage-your-usage/disk-size) for details on how we calculate charges. The disk size of a Read Replica is 1.25x the size of the primary disk to account for WAL archives. With a Read Replica you go beyond your subscription plan's quota for Disk Size.
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Provisioned Disk IOPS (optional)
Read Replicas inherit any additional provisioned Disk IOPS from the primary database. Read the [Manage Disk IOPS usage guide](/docs/guides/platform/manage-your-usage/disk-iops) for details on how we calculate charges.
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Provisioned Disk Throughput (optional)
Read Replicas inherit any additional provisioned Disk Throughput from the primary database. Read the [Manage Disk Throughput usage guide](/docs/guides/platform/manage-your-usage/disk-throughput) for details on how we calculate charges.
{/* supa-mdx-lint-enable-next-line Rule001HeadingCase */}
### IPv4 (optional)
If the primary database has configured an IPv4 address add-on, its Read Replicas are also assigned one, with charges for each. Read the [Manage IPv4 usage guide](/docs/guides/platform/manage-your-usage/ipv4) for details on how we calculate charges.
### Usage on your invoice
Compute incurred by Read Replicas is shown as "Replica Compute Hours" on your invoice. Disk Size, Disk IOPS, Disk Throughput and IPv4 are not shown separately for Read Replicas and are rolled up into the project.
## Billing examples
### No additional resources configured
The project has one Read Replica, no IPv4, and no additional Disk IOPS and Disk Throughput configured.
| Line Item | Units | Costs |
| ----------------------------- | --------- | --------------------------- |
| Pro Plan | 1 | |
| | | |
| Compute Hours Small Project 1 | 744 hours | |
| Disk Size Project 1 | 8 GB | |
| | | |
| Compute Hours Small Replica | 744 hours | |
| Disk Size Replica | 10 GB | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Additional resources configured
The project has two Read Replicas, IPv4, and additional Disk IOPS and Disk Throughput configured.
| Line Item | Units | Costs |
| ----------------------------- | --------- | ---------------------------- |
| Pro Plan | 1 | |
| | | |
| Compute Hours Large Project 1 | 744 hours | |
| Disk Size Project 1 | 8 GB | |
| Disk IOPS Project 1 | 3600 | |
| Disk Throughput Project 1 | 200 MB/s | |
| IPv4 Hours Project 1 | 744 hours | |
| | | |
| Compute Hours Large Replica 1 | 744 hours | |
| Disk Size Replica 1 | 10 GB | |
| Disk IOPS Replica 1 | 3600 | |
| Disk Throughput Replica 1 | 200 MB/s | |
| IPv4 Hours Replica 1 | 744 hours | |
| | | |
| Compute Hours Large Replica 2 | 744 hours | |
| Disk Size Replica 2 | 10 GB | |
| Disk IOPS Replica 2 | 3600 | |
| Disk Throughput Replica 2 | 200 MB/s | |
| IPv4 Hours Replica 2 | 744 hours | |
| | | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## FAQ
### Do Compute Credits apply to Read Replica Compute?
No, Compute Credits do not apply to Read Replica Compute.
# Manage Realtime Messages usage
## What you are charged for
You are charged for the number of messages going through Supabase Realtime throughout the billing cycle. Includes database changes, Broadcast and Presence.
**Database changes**
Each database change counts as one message per client that listens to the event. For example, if a database change occurs and 5 clients listen to that database event, it counts as 5 messages.
**Broadcast**
Each broadcast message counts as one message sent plus one message per subscribed client that receives it. For example, if you broadcast a message and 4 clients listen to it, it counts as 5 messages—1 sent and 4 received.
## How charges are calculated
Realtime Messages are billed using Package pricing, with each package representing 1 million messages. If your usage falls between two packages, you are billed for the next whole package.
### Example
For simplicity, let's assume a package size of 1,000,000 and a charge of per package without quota.
| Messages | Packages Billed | Costs |
| --------- | --------------- | ---------------------- |
| 999,999 | 1 | |
| 1,000,000 | 1 | |
| 1,000,001 | 2 | |
| 1,500,000 | 2 | |
### Usage on your invoice
Usage is shown as "Realtime Messages" on your invoice.
## Pricing
per 1 million messages. You are only charged for usage exceeding your
subscription plan's quota.
| Plan | Quota | Over-Usage |
| ---------- | --------- | --------------------------------------------- |
| Free | 2 million | - |
| Pro | 5 million | per 1 million messages |
| Team | 5 million | per 1 million messages |
| Enterprise | Custom | Custom |
## Billing examples
### Within quota
The organization's Realtime messages are within the quota, so no charges apply.
| Line Item | Units | Costs |
| ------------------- | -------------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Realtime Messages | 1.8 million messages | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's Realtime messages exceed the quota by 3.5 million, incurring charges for this additional usage.
| Line Item | Units | Costs |
| ------------------- | -------------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Realtime Messages | 8.5 million messages | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Realtime Messages usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Realtime Messages section, you can see the usage for the selected time period.
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage Realtime Peak Connections usage
## What you are charged for
Realtime Peak Connections are measured by tracking the highest number of concurrent connections for each project during the billing cycle. Regardless of fluctuations, only the peak count per project is used for billing, and the totals from all projects are summed. Only successful connections are counted, connection attempts are not included.
### Example
For simplicity, this example assumes a billing cycle of only three days.
| Project | Peak Connections Day 1 | Peak Connections Day 2 | Peak Connections Day 3 |
| --------- | ---------------------- | ---------------------- | ---------------------- |
| Project A | 80 | 100 | 90 |
| Project B | 120 | 110 | 150 |
**Total billed connections:** 100 (Project A) + 150 (Project B) = **250 connections**
## How charges are calculated
Realtime Peak Connections are billed using Package pricing, with each package representing 1,000 peak connections. If your usage falls between two packages, you are billed for the next whole package.
### Example
For simplicity, let's assume a package size of 1,000 and a charge of per package with no quota.
| Peak Connections | Packages Billed | Costs |
| ---------------- | --------------- | -------------------- |
| 999 | 1 | |
| 1,000 | 1 | |
| 1,001 | 2 | |
| 1,500 | 2 | |
### Usage on your invoice
Usage is shown as "Realtime Peak Connections" on your invoice.
## Pricing
per 1,000 peak connections. You are only charged for usage exceeding your
subscription plan's quota.
| Plan | Quota | Over-Usage |
| ---------- | ------ | ----------------------------------------------- |
| Free | 200 | - |
| Pro | 500 | per 1,000 peak connections |
| Team | 500 | per 1,000 peak connections |
| Enterprise | Custom | Custom |
## Billing examples
### Within quota
The organization's connections are within the quota, so no charges apply.
| Line Item | Units | Costs |
| ------------------------- | --------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Realtime Peak Connections | 350 connections | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's connections exceed the quota by 1,200, incurring charges for this additional usage.
| Line Item | Units | Costs |
| ------------------------- | ----------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Realtime Peak Connections | 1,700 connections | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Realtime Peak Connections usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Realtime Peak Connections section, you can see the usage for the selected time period.
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage Storage Image Transformations usage
## What you are charged for
You are charged for the number of distinct images transformed during the billing period, regardless of how many transformations each image undergoes. We refer to these images as "origin" images.
### Example
With these four transformations applied to `image-1.jpg` and `image-2.jpg`, the origin images count is 2.
```javascript
supabase.storage.from('bucket').createSignedUrl('image-1.jpg', 60000, {
transform: {
width: 200,
height: 200,
},
})
```
```javascript
supabase.storage.from('bucket').createSignedUrl('image-2.jpg', 60000, {
transform: {
width: 400,
height: 300,
},
})
```
```javascript
supabase.storage.from('bucket').createSignedUrl('image-2.jpg', 60000, {
transform: {
width: 600,
height: 250,
},
})
```
```javascript
supabase.storage.from('bucket').download('image-2.jpg', {
transform: {
width: 800,
height: 300,
},
})
```
## How charges are calculated
Storage Image Transformations are billed using Package pricing, with each package representing 1000 origin images. If your usage falls between two packages, you are billed for the next whole package.
### Example
For simplicity, let's assume a package size of 1,000 and a charge of per package with no quota.
| Origin Images | Packages Billed | Costs |
| ------------- | --------------- | -------------------- |
| 999 | 1 | |
| 1,000 | 1 | |
| 1,001 | 2 | |
| 1,500 | 2 | |
### Usage on your invoice
Usage is shown as "Storage Image Transformations" on your invoice.
per 1,000 origin images. You are only charged for usage exceeding your
subscription plan's quota.
The count resets at the start of each billing cycle.
| Plan | Quota | Over-Usage |
| ---------- | ------ | ------------------------------------------- |
| Pro | 100 | per 1,000 origin images |
| Team | 100 | per 1,000 origin images |
| Enterprise | Custom | Custom |
For a detailed breakdown of how charges are calculated, refer to [Manage Storage Image Transformations usage](/docs/guides/platform/manage-your-usage/storage-image-transformations).
## Billing examples
### Within quota
The organization's number of origin images for the billing cycle is within the quota, so no charges apply.
| Line Item | Units | Costs |
| --------------------- | ---------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Image Transformations | 74 origin images | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's number of origin images for the billing cycle exceeds the quota by 750, incurring charges for this additional usage.
| Line Item | Units | Costs |
| --------------------- | ----------------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Image Transformations | 850 origin images | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
You can view Storage Image Transformations usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Storage Image Transformations section, you can see how many origin images were transformed during the selected time period.
## Optimize usage
* Pre-generate common variants – instead of transforming images on the fly, generate and store commonly used sizes in advance
* Optimize original image sizes – upload images in an optimized format and resolution to reduce the need for excessive transformations
* Leverage [Smart CDN](/docs/guides/storage/cdn/smart-cdn) caching or any other caching solution to serve transformed images efficiently and avoid unnecessary repeated transformations
* Control how long assets are stored in the browser using the `Cache-Control` header
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Manage Storage size usage
## What you are charged for
You are charged for the total size of all assets in your buckets.
## How charges are calculated
Storage size is charged by Gigabyte-Hours (GB-Hrs). 1 GB-Hr represents the use of 1 GB of storage for 1 hour.
For example, storing 10 GB of data for 5 hours results in 50 GB-Hrs (10 GB × 5 hours).
### Usage on your invoice
Usage is shown as "Storage Size GB-Hrs" on your invoice.
## Pricing
per GB-Hr ( per GB per month). You are only
charged for usage exceeding your subscription plan's quota.
| Plan | Quota in GB | Over-Usage per GB | Quota in GB-Hrs | Over-Usage per GB-Hr |
| ---------- | ----------- | ----------------------- | --------------- | ---------------------------- |
| Free | 1 | - | 744 | - |
| Pro | 100 | | 74,400 | |
| Team | 100 | | 74,400 | |
| Enterprise | Custom | Custom | Custom | Custom |
## Billing examples
### Within quota
The organization's Storage size usage is within the quota, so no charges for Storage size apply.
| Line Item | Units | Costs |
| ------------------- | --------- | ------------------------ |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Storage Size | 85 GB | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
### Exceeding quota
The organization's Storage size usage exceeds the quota by 257 GB, incurring charges for this additional usage.
| Line Item | Units | Costs |
| ------------------- | --------- | -------------------------- |
| Pro Plan | 1 | |
| Compute Hours Micro | 744 hours | |
| Storage Size | 357 GB | |
| **Subtotal** | | **** |
| Compute Credits | | - |
| **Total** | | **** |
## View usage
### Usage page
You can view Storage size usage on the [organization's usage page](/dashboard/org/_/usage). The page shows the usage of all projects by default. To view the usage for a specific project, select it from the dropdown. You can also select a different time period.
In the Storage size section, you can see how much storage your projects have used during the selected time period.
### SQL Editor
Since we designed Storage to work as an integrated part of your Postgres database on Supabase, you can query information about your Storage objects in the `storage` schema.
List files larger than 5 MB:
```sql
select
name,
bucket_id as bucket,
case
when (metadata->>'size')::int >= 1073741824 then
((metadata->>'size')::int / 1073741824.0)::numeric(10, 2) || ' GB'
when (metadata->>'size')::int >= 1048576 then
((metadata->>'size')::int / 1048576.0)::numeric(10, 2) || ' MB'
when (metadata->>'size')::int >= 1024 then
((metadata->>'size')::int / 1024.0)::numeric(10, 2) || ' KB'
else
(metadata->>'size')::int || ' bytes'
end as size
from
storage.objects
where
(metadata->>'size')::int > 1048576 * 5
order by (metadata->>'size')::int desc
```
List buckets with their total size:
```sql
select
bucket_id,
(sum((metadata->>'size')::int) / 1048576.0)::numeric(10, 2) as total_size_megabyte
from
storage.objects
group by
bucket_id
order by
total_size_megabyte desc;
```
## Optimize usage
* [Limit the upload size](/docs/guides/storage/production/scaling#limit-the-upload-size) for your buckets
* [Delete assets](/docs/guides/storage/management/delete-objects) that are no longer in use
## Exceeding Quotas
If you are on a paid plan and have [Spend Cap](/docs/guides/platform/cost-control#spend-cap) disabled or your organization is on Team Plan or above, you will pay for any overages.
When you are exceeding your quotas while being on a Free Plan or having [Spend Cap](/docs/guides/platform/cost-control#spend-cap) enabled, you will get a notification to your billing email address and put under a grace period. For more details, refer to our [Fair Use Policy](/docs/guides/platform/billing-faq#fair-use-policy).
# Account Setup
After purchasing a Supabase subscription on the AWS Marketplace, the next and final step is to link the newly purchased subscription to a Supabase organization. This can either be an existing organization or a newly created one.
An AWS Marketplace subscription is linked to exactly one Supabase organization. If you want to manage multiple organizations through the AWS Marketplace, you must purchase a separate marketplace subscription for each organization.
## Implications of linking a Supabase organization to a marketplace subscription
* The billing details from your AWS account, such as the billing address and tax ID, are used. These details are managed through the [AWS Billing and Cost Management console](https://console.aws.amazon.com/billing).
* The subscription plan is managed through the AWS Marketplace. You can read more about this in the [Manage your subscription](./manage-your-subscription#manage-your-subscription-plan) guide.
* Charges will come from AWS rather than Supabase, using the default payment method set in your AWS account.
* The [Spend Cap](/docs/guides/platform/cost-control#spend-cap) for the organization is disabled. The Spend Cap is not available for organizations managed through AWS.
* When you downgrade your plan to the Free Plan, all projects within the organization will be paused if you exceed the [free projects limit](/docs/guides/platform/billing-on-supabase#free-plan).
### Linking an existing Supabase organization
Linking an existing organization will result in the following:
* The organization will be upgraded or downgraded to the plan purchased on the AWS Marketplace.
* The organization’s billing cycle will be adjusted. The start date will be set to the date your marketplace subscription became active.
* The credit card you have on file with Supabase may receive a closing charge. This charge covers usage costs incurred up until the point when the marketplace subscription became active.
## Prerequisites for linking a Supabase organization to a marketplace subscription
* The Supabase user must have the Owner or Admin role
* There must be no overdue invoices within the organization
* The organization must not already be managed through another marketplace (e.g. Vercel Marketplace)
# AWS Marketplace FAQ
#### The payment for completing the subscription on the AWS Marketplace fails.
For more information on payment errors, refer to the [AWS documentation](https://docs.aws.amazon.com/marketplace/latest/buyerguide/buyer-paying-for-products.html#payment-methods).
#### How can the Spend Cap for an organization managed through the AWS Marketplace be enabled?
For organizations on the Pro Plan that are managed through the AWS Marketplace, the Spend Cap is not available.
In your AWS account, you can set up a budget for marketplace purchases (or for a specific marketplace product) and receive notifications once the budget is exceeded.
#### How to cancel your AWS Marketplace subscription
You can cancel your marketplace subscription within 48 hours of purchase. To do so, open a support ticket via the Supabase dashboard. After the 48-hour period, cancellation is no longer possible. If you cancel within the first 48 hours, the upfront charge for the fixed subscription fee will be refunded. Any usage costs incurred up to that point will not be refunded.
#### Does purchasing Supabase through the AWS Marketplace count toward your AWS spend commitment?
Yes, marketplace purchases do count toward the spend commitment.
# Getting Started
## Before you start
Depending on whether a Supabase organization is managed and billed through the AWS Marketplace or directly through the Supabase platform, there are differences. To help you make an informed decision about which approach is better suited for your needs, you can find an overview of these differences in the table below.
| Feature/Aspect | Managed via AWS Marketplace | Managed directly via Supabase platform |
| -------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Available Plans | Pro, Team, Enterprise | Free, Pro, Team, Enterprise |
| Mid-cycle downgrades | No | Yes |
| Cost Control | Spend Cap not available | Spend Cap available |
| Downgrade Behaviour | If a downgrade to the Free Plan causes you to exceed the [free projects limit](/docs/guides/platform/billing-on-supabase#free-plan), all projects will be paused. | If a downgrade to the Free Plan causes you to exceed the [free projects limit](/docs/guides/platform/billing-on-supabase#free-plan), you have the option to prevent pausing by transferring projects. |
| Invoicing | Separate invoices, one for fixed costs and one for usage costs | One invoice for both fixed costs and usage costs |
## Purchase Supabase through the AWS Marketplace
Purchasing Supabase through the AWS Marketplace involves two steps. First, you purchase the corresponding subscription on the marketplace. Then, to complete the setup, you must link this subscription to a Supabase organization on the Supabase platform.
For more details on completing the setup and what it means to link an organization, see our [Account Setup guide](./account-setup).
Go to the [Supabase product page on the AWS Marketplace](https://aws.amazon.com/marketplace/pp/prodview-zjciuce2qsb3q) and click "View purchase options".
Select the desired plan (Pro Plan or Team Plan) and configure whether the subscription should automatically renew after one month.
Disabling auto-renewal means that the subscription will be downgraded to the Free Plan after one month.
If the downgrade causes you to exceed the [free projects limit](/docs/guides/platform/billing-on-supabase#free-plan), **all** projects within the organization will be paused. We do not make the decision about which projects continue to run and which are paused. You must then decide which projects you want to keep active and manually reactivate them through the Supabase dashboard.
Click "Subscribe" at the bottom of the page.
After the payment has been confirmed and your marketplace subscription is active, click "Set up your account" to be redirected to the Supabase platform.
Complete the setup by linking a Supabase organization to the AWS Marketplace subscription.
# Invoices
## Where to find your invoices
You can view your invoices in the [AWS Billing and Cost Management console](https://console.aws.amazon.com/billing/home#/bills) under the "Bills" section.
## What invoices you get from AWS
You'll receive two invoices for your marketplace subscription.
### Invoice 1 - charge type "subscription"
* What for: The fixed subscription fee paid in advance
* When: At the time of subscription, and in subsequent months on the same day of the month the subscription was started
### Invoice 2 - charge type "usage"
* What for: Usage that exceeds the quota included in the plan, or usage not covered by the plan (e.g. Custom Domain add-on, IPv4 add-on, additionally provisioned Disk IOPS).
* When: No later than the third day of the month for the previous month. This is independent of your subscription’s billing cycle and instead covers the period from the first to the last day of the previous month.
## More information
* Detailed explanations of how each usage item is billed, independent of the AWS Marketplace. Refer to the [Manage Your Usage guide](../manage-your-usage).
# Manage your subscription
## Manage your subscription plan
Plan changes are not made on the Supabase dashboard, but instead through the AWS Marketplace. The easiest way to navigate to the corresponding page on the marketplace is through the Supabase dashboard.
1. On the [organization's billing page](/dashboard/org/_/billing), go to section **Subscription Plan**
2. Click **Change subscription plan**
3. On the side panel, follow the link to the AWS Marketplace
### Upgrade
You can upgrade your plan at any time. The new plan will be active immediately, and you will be charged a prorated amount for the remainder of the current billing cycle. The charge for the upgrade also factors in the upfront payment you have already made for your existing plan.
### Downgrade
Downgrades are only possible at the end of the billing cycle, not in the middle of a billing cycle.
#### Downgrade to the Free Plan
If you want your subscription to be downgraded to the Free Plan at the end of the current billing cycle, you need to disable auto-renewal for the marketplace subscription.
If the downgrade causes you to exceed the [free projects limit](/docs/guides/platform/billing-on-supabase#free-plan), **all** projects within the organization will be paused. We do not make the decision about which projects continue to run and which are paused. You must then decide which projects you want to keep active and manually reactivate them through the Supabase dashboard.
#### Downgrade to a paid plan
A downgrade to a paid plan (Pro Plan / Team Plan) involves two steps.
**Step 1:** Let the current subscription on the higher plan expire, meaning turn off auto-renewal
**Step 2:** Start a new subscription on the lower plan
## Manage your payment methods
You can manage your payment methods through the [AWS Billing and Cost Management console](https://console.aws.amazon.com/billing).
## Manage your billing details
You can manage billing details, such as the billing address or tax ID, through the [AWS Billing and Cost Management console](https://console.aws.amazon.com/billing).
# Customizing email templates
Customize local email templates via the config file.
You can customize the email templates for local development by [editing the `config.toml` file](/docs/guides/local-development/cli/config#auth-config).
## Configuring templates
You should provide a relative URL to the `content_path` parameter, pointing to an HTML file which contains the template. For example:
### Authentication email templates
```toml name=supabase/config.toml
[auth.email.template.invite]
subject = "You are invited to Acme Inc"
content_path = "./supabase/templates/invite.html"
```
```html name=supabase/templates/invite.html
Confirm your signup
Confirm your email
```
### Security notification email templates
```toml name=supabase/config.toml
[auth.email.notification.password_changed]
enabled = true
subject = "Your password has been changed"
content_path = "./templates/password_changed_notification.html"
```
```html name=templates/password_changed_notification.html
This is a confirmation that the password for your account {{ .Email }} has just been changed.
If you did not make this change, please contact support.
```
## Available authentication email templates
There are several authentication-related email templates which can be configured. Each template serves a specific authentication flow:
### `auth.email.template.invite`
**Default subject**: "You have been invited"
**When sent**: When a user is invited to join your application via email invitation
**Purpose**: Invite users who don't yet have an account to sign up
**Content**: Contains a link for the invited user to accept the invitation and create their account
### `auth.email.template.confirmation`
**Default subject**: "Confirm Your Signup"
**When sent**: When a user signs up and needs to verify their email address
**Purpose**: Ask users to confirm their email address after signing up
**Content**: Contains a confirmation link to verify the user's email address
### `auth.email.template.recovery`
**Default subject**: "Reset Your Password"
**When sent**: When a user requests a password reset
**Purpose**: Allow users to reset their password if they forget it
**Content**: Contains a link to reset the user's password
### `auth.email.template.magic_link`
**Default subject**: "Your Magic Link"
**When sent**: When a user requests a magic link for passwordless authentication
**Purpose**: Allow users to sign in via a one-time link sent to their email
**Content**: Contains a secure link that automatically logs the user in when clicked
### `auth.email.template.email_change`
**Default subject**: "Confirm Email Change"
**When sent**: When a user requests to change their email address
**Purpose**: Ask users to verify their new email address after changing it
**Content**: Contains a confirmation link to verify the new email address
### `auth.email.template.reauthentication`
**Default subject**: "Confirm Reauthentication"
**When sent**: When a user needs to re-authenticate for sensitive operations
**Purpose**: Ask users to re-authenticate before performing a sensitive action
**Content**: Contains a 6-digit OTP code for verification
## Available security notification email templates
There are several security notification email templates which can be configured. These emails are only sent to users if the respective security notifications have been enabled at the project-level:
### `auth.email.notification.password_changed`
**Default subject**: "Your password has been changed"
**When sent**: When a user's password is changed
**Purpose**: Notify users when their password has changed
**Content**: Confirms that the password for the account has been changed
### `auth.email.notification.email_changed`
**Default subject**: "Your email address has been changed"
**When sent**: When a user's email address is changed
**Purpose**: Notify users when their email address has changed
**Content**: Confirms the change from the old email to the new email address
### `auth.email.notification.phone_changed`
**Default subject**: "Your phone number has been changed"
**When sent**: When a user's phone number is changed
**Purpose**: Notify users when their phone number has changed
**Content**: Confirms the change from the old phone number to the new phone number
### `auth.email.notification.mfa_factor_enrolled`
**Default subject**: "A new MFA factor has been enrolled"
**When sent**: When a new MFA factor is added to the user's account
**Purpose**: Notify users when a new multi-factor authentication method has been added to their account
**Content**: Confirms that a new MFA factor type has been enrolled
### `auth.email.notification.mfa_factor_unenrolled`
**Default subject**: "An MFA factor has been unenrolled"
**When sent**: When an MFA factor is removed from the user's account
**Purpose**: Notify users when a multi-factor authentication method has been removed from their account
**Content**: Confirms that an MFA factor type has been unenrolled
### `auth.email.notification.identity_linked`
**Default subject**: "A new identity has been linked"
**When sent**: When a new identity is linked to the account
**Purpose**: Notify users when a new identity has been linked to their account
**Content**: Confirms that a new identity has been linked
### `auth.email.notification.identity_unlinked`
**Default subject**: "An identity has been unlinked"
**When sent**: When an identity has been unlinked from the account
**Purpose**: Notify users when an identity has been unlinked from their account
**Content**: Confirms that an identity has been unlinked
## Template variables
The templating system provides the following variables for use:
### `ConfirmationURL`
Contains the confirmation URL. For example, a signup confirmation URL would look like:
```
https://project-ref.supabase.co/auth/v1/verify?token={{ .TokenHash }}&type=email&redirect_to=https://example.com/path
```
**Usage**
```html
Click here to confirm: {{ .ConfirmationURL }}
```
### `Token`
Contains a 6-digit One-Time-Password (OTP) that can be used instead of the `ConfirmationURL`.
**Usage**
```html
Here is your one time password: {{ .Token }}
```
### `TokenHash`
Contains a hashed version of the `Token`. This is useful for constructing your own email link in the email template.
**Usage**
```html
Follow this link to confirm your user:
Confirm your email
```
### `SiteURL`
Contains your application's Site URL. This can be configured in your project's [authentication settings](/dashboard/project/_/auth/url-configuration).
**Usage**
```html
Visit here to log in.
```
### `RedirectTo`
Contains the redirect URL passed as the `redirectTo` option in the auth method call.
**Usage**
```html
Confirm your email
```
### `Data`
Contains metadata from `auth.users.user_metadata`. Use this to personalize the email message.
**Usage**
```html
Hello {{ .Data.first_name }}, please confirm your signup.
```
### `Email`
Contains the user's email address.
**Usage**
```html
A recovery request was sent to {{ .Email }}.
```
### `NewEmail`
Contains the new user's email address. This is only available in the `email_change` email template.
**Usage**
```html
You are requesting to update your email address to {{ .NewEmail }}.
```
### `OldEmail`
Contains the user's old email address. This is only available in the `email_changed_notification` email template.
**Usage**
```html
The email address for your account has been changed from {{ .OldEmail }} to {{ .Email }}.
```
### `Phone`
Contains the user's new phone number. This is only available in the `phone_changed_notification` email template.
**Usage**
```html
The phone number for your account has been changed from {{ .OldPhone }} to {{ .Phone }}.
```
### `OldPhone`
Contains the user's old phone number. This is only available in the `phone_changed_notification` email template.
**Usage**
```html
The phone number for your account has been changed from {{ .OldPhone }} to {{ .Phone }}.
```
### `Provider`
Contains the provider of the newly linked/unlinked identity. This is only available in the `identity_linked_notification` and `identity_unlinked_notification` email templates.
**Usage**
```html
A new identity ({{ .Provider }}) has been linked to your account.
```
### `FactorType`
Contains the type of the newly enrolled/unenrolled MFA factor. This is only available in the `mfa_factor_enrolled_notification` and `mfa_factor_unenrolled_notification` email templates.
**Usage**
```html
A new factor ({{ .FactorType }}) has been enrolled for your account.
```
## Deploying email templates
These settings are for local development. To apply the changes locally, stop and restart the Supabase containers:
```sh
supabase stop && supabase start
```
For hosted projects managed by Supabase, copy the templates into the [Email Templates](/dashboard/project/_/auth/templates) section of the Dashboard.
# Declarative database schemas
Manage your database schemas in one place and generate versioned migrations.
## Overview
Declarative schemas provide a developer-friendly way to maintain Files of SQL statements that track the evolution of your database schema over time.
They allow you to version control your database schema alongside your application code.
See the database migrations guide to learn more.
}>schema migrations.
[Migrations](/docs/guides/deployment/database-migrations) are traditionally managed imperatively (you provide the instructions on how exactly to change the database). This can lead to related information being scattered over multiple migration files. With declarative schemas, you instead declare the state you want your database to be in, and the instructions are generated for you.
## Schema migrations
Schema migrations are SQL statements written in Data Definition Language. They are versioned in your `supabase/migrations` directory to ensure schema consistency between local and remote environments.
### Declaring your schema
Create a SQL file in `supabase/schemas` directory that defines an `employees` table.
```sql name=supabase/schemas/employees.sql
create table "employees" (
"id" integer not null,
"name" text
);
```
Generate a migration file by diffing against your declared schema.
```bash name=Terminal
supabase db diff -f create_employees_table
```
Start the local database first. Then, apply the migration manually to see your schema changes in the local Dashboard.
```bash name=Terminal
supabase start
supabase migration up
```
### Updating your schema
Edit `supabase/schemas/employees.sql` file to add a new column to `employees` table.
```sql name=supabase/schemas/employees.sql
create table "employees" (
"id" integer not null,
"name" text,
"age" smallint not null
);
```
Some entities like views and enums expect columns to be declared in a specific order. To avoid messy diffs, always append new columns to the end of the table.
Diff existing migrations against your declared schema.
```bash name=Terminal
supabase db diff -f add_age
```
Verify that the generated migration contain a single incremental change.
```sql name=supabase/migrations/_add_age.sql
alter table "public"."employees" add column "age" smallint not null;
```
Start the database locally and apply the pending migration.
```bash name=Terminal
supabase migration up
```
### Deploying your schema changes
[Log in](/docs/reference/cli/supabase-login) via the Supabase CLI.
```bash name=Terminal
supabase login
```
Follow the on-screen prompts to [link](/docs/reference/cli/supabase-link) your remote project.
```bash name=Terminal
supabase link
```
[Push](/docs/reference/cli/supabase-db-push) your changes to the remote database.
```bash name=Terminal
supabase db push
```
### Managing dependencies
As your database schema evolves, you will probably start using more advanced entities like views and functions. These entities are notoriously verbose to manage using plain migrations because the entire body must be recreated whenever there is a change. Using declarative schema, you can now edit them in-place so it’s much easier to review.
```sql name=supabase/schemas/employees.sql
create table "employees" (
"id" integer not null,
"name" text,
"age" smallint not null
);
create view "profiles" as
select id, name from "employees";
create function "get_age"(employee_id integer) RETURNS smallint
LANGUAGE "sql"
AS $$
select age
from employees
where id = employee_id;
$$;
```
Your schema files are run in lexicographic order by default. The order is important when you have foreign keys between multiple tables as the parent table must be created first. For example, your `supabase` directory may end up with the following structure.
```bash
.
└── supabase/
├── schemas/
│ ├── employees.sql
│ └── managers.sql
└── migrations/
├── 20241004112233_create_employees_table.sql
├── 20241005112233_add_employee_age.sql
└── 20241006112233_add_managers_table.sql
```
For small projects with only a few tables, the default schema order may be sufficient. However, as your project grows, you might need more control over the order in which schemas are applied. To specify a custom order for applying the schemas, you can declare them explicitly in `config.toml`. Any glob patterns will evaluated, deduplicated, and sorted in lexicographic order. For example, the following pattern ensures `employees.sql` is always executed first.
```toml name=supabase/config.toml
[db.migrations]
schema_paths = [
"./schemas/employees.sql",
"./schemas/*.sql",
]
```
### Pulling in your production schema
To set up declarative schemas on a existing project, you can pull in your production schema by running:
```bash name=Terminal
supabase db dump > supabase/schemas/prod.sql
```
From there, you can start breaking down your schema into smaller files and generate migrations. You can do this all at once, or incrementally as you make changes to your schema.
### Rolling back a schema change
During development, you may want to rollback a migration to keep your new schema changes in a single migration file. This can be done by resetting your local database to a previous version.
```bash name=Terminal
supabase db reset --version 20241005112233
```
After a reset, you can [edit the schema](#updating-your-schema) and regenerate a new migration file. Note that you should not reset a version that's already deployed to production.
If you need to rollback a migration that's already deployed, you should first revert changes to the schema files. Then you can generate a new migration file containing the down migration. This ensures your production migrations are always rolling forward.
SQL statements generated in a down migration are usually destructive. You must review them carefully to avoid unintentional data loss.
## Known caveats
The `migra` diff tool used for generating schema diff is capable of tracking most database changes. However, there are edge cases where it can fail.
If you need to use any of the entities below, remember to add them through [versioned migrations](/docs/guides/deployment/database-migrations) instead.
### Data manipulation language
* DML statements such as `insert`, `update`, `delete`, etc., are not captured by schema diff
### View ownership
* [view owner and grants](https://github.com/djrobstep/migra/issues/160#issuecomment-1702983833)
* [security invoker on views](https://github.com/djrobstep/migra/issues/234)
* [materialized views](https://github.com/djrobstep/migra/issues/194)
* doesn’t recreate views when altering column type
### RLS policies
* [alter policy statements](https://github.com/djrobstep/schemainspect/blob/master/schemainspect/pg/obj.py#L228)
* [column privileges](https://github.com/djrobstep/schemainspect/pull/67)
### Other entities
* schema privileges are not tracked because each schema is diffed separately
* [comments are not tracked](https://github.com/djrobstep/migra/issues/69)
* [partitions are not tracked](https://github.com/djrobstep/migra/issues/186)
* [`alter publication ... add table ...`](https://github.com/supabase/cli/issues/883)
* [create domain statements are ignored](https://github.com/supabase/cli/issues/2137)
* [grant statements are duplicated from default privileges](https://github.com/supabase/cli/issues/1864)
# Managing config and secrets
The Supabase CLI uses a `config.toml` file to manage local configuration. This file is located in the `supabase` directory of your project.
## Config reference
The `config.toml` file is automatically created when you run `supabase init`.
There are a wide variety of options available, which can be found in the [CLI Config Reference](/docs/guides/cli/config).
For example, to enable the "Apple" OAuth provider for local development, you can append the following information to `config.toml`:
```toml
[auth.external.apple]
enabled = false
client_id = ""
secret = ""
redirect_uri = "" # Overrides the default auth redirectUrl.
```
## Using secrets inside config.toml
You can reference environment variables within the `config.toml` file using the `env()` function. This will detect any values stored in an `.env` file at the root of your project directory. This is particularly useful for storing sensitive information like API keys, and any other values that you don't want to check into version control.
```
.
├── .env
├── .env.example
└── supabase
└── config.toml
```
Do NOT commit your `.env` into git. Be sure to configure your `.gitignore` to exclude this file.
For example, if your `.env` contained the following values:
```bash
GITHUB_CLIENT_ID=""
GITHUB_SECRET=""
```
Then you would reference them inside of our `config.toml` like this:
```toml
[auth.external.github]
enabled = true
client_id = "env(GITHUB_CLIENT_ID)"
secret = "env(GITHUB_SECRET)"
redirect_uri = "" # Overrides the default auth redirectUrl.
```
### Going further
For more advanced secrets management workflows, including:
* **Using dotenvx for encrypted secrets**: Learn how to securely manage environment variables across different branches and environments
* **Branch-specific secrets**: Understand how to manage secrets for different deployment environments
* **Encrypted configuration values**: Use encrypted values directly in your `config.toml`
See the [Managing secrets for branches](/docs/guides/deployment/branching#managing-secrets-for-branches) section in our branching documentation, or check out the [dotenvx example repository](https://github.com/supabase/supabase/blob/master/examples/slack-clone/nextjs-slack-clone-dotenvx/README.md) for a complete implementation.
# Local development with schema migrations
Develop locally with the Supabase CLI and schema migrations.
Supabase is a flexible platform that lets you decide how you want to build your projects. You can use the Dashboard directly to get up and running quickly, or use a proper local setup. We suggest you work locally and deploy your changes to a linked project on the [Supabase Platform](https://app.supabase.io/).
Develop locally using the CLI to run a local Supabase stack. You can use the integrated Studio Dashboard to make changes, then capture your changes in schema migration files, which can be saved in version control.
Alternatively, if you're comfortable with migration files and SQL, you can write your own migrations and push them to the local database for testing before sharing your changes.
## Database migrations
Database changes are managed through "migrations." Database migrations are a common way of tracking changes to your database over time.
For this guide, we'll create a table called `employees` and see how we can make changes to it.
To get started, generate a [new migration](/docs/reference/cli/supabase-migration-new) to store the SQL needed to create our `employees` table
```bash name=Terminal
supabase migration new create_employees_table
```
This creates a new migration: supabase/migrations/\
\_create\_employees\_table.sql.
To that file, add the SQL to create this `employees` table
```sql name=20250101000000_create_employees_table.sql
create table employees (
id bigint primary key generated always as identity,
name text,
email text,
created_at timestamptz default now()
);
```
Now that you have a migration file, you can run this migration and create the `employees` table.
Use the `reset` command here to reset the database to the current migrations
```bash name=Terminal
supabase db reset
```
Now you can visit your new `employees` table in the Dashboard.
Next, modify your `employees` table by adding a column for department. Create a new migration file for that.
```bash name=Terminal
supabase migration new add_department_to_employees_table
```
This creates a new migration file: supabase/migrations/\
\_add\_department\_to\_employees\_table.sql.
To that file, add the SQL to create a new department column
```sql name=20250101000001_add_department_to_employees_table.sql
alter table if exists public.employees
add department text default 'Hooli';
```
### Add sample data
Now that you are managing your database with migrations scripts, it would be great have some seed data to use every time you reset the database.
For this, you can create a seed script in `supabase/seed.sql`.
Insert data into your `employees` table with your `supabase/seed.sql` file.
```sql name=supabase/seed.sql
insert into public.employees
(name)
values
('Erlich Bachman'),
('Richard Hendricks'),
('Monica Hall');
```
Reset your database (apply current migrations), and populate with seed data
```bash name=Terminal
supabase db reset
```
You should now see the `employees` table, along with your seed data in the Dashboard! All of your database changes are captured in code, and you can reset to a known state at any time, complete with seed data.
### Diffing changes
This workflow is great if you know SQL and are comfortable creating tables and columns. If not, you can still use the Dashboard to create tables and columns, and then use the CLI to diff your changes and create migrations.
Create a new table called `cities`, with columns `id`, `name` and `population`. To see the corresponding SQL for this, you can use the `supabase db diff --schema public` command. This will show you the SQL that will be run to create the table and columns. The output of `supabase db diff` will look something like this:
```
Diffing schemas: public
Finished supabase db diff on branch main.
create table "public"."cities" (
"id" bigint primary key generated always as identity,
"name" text,
"population" bigint
);
```
Alternately, you can view your table definitions directly from the Table Editor:
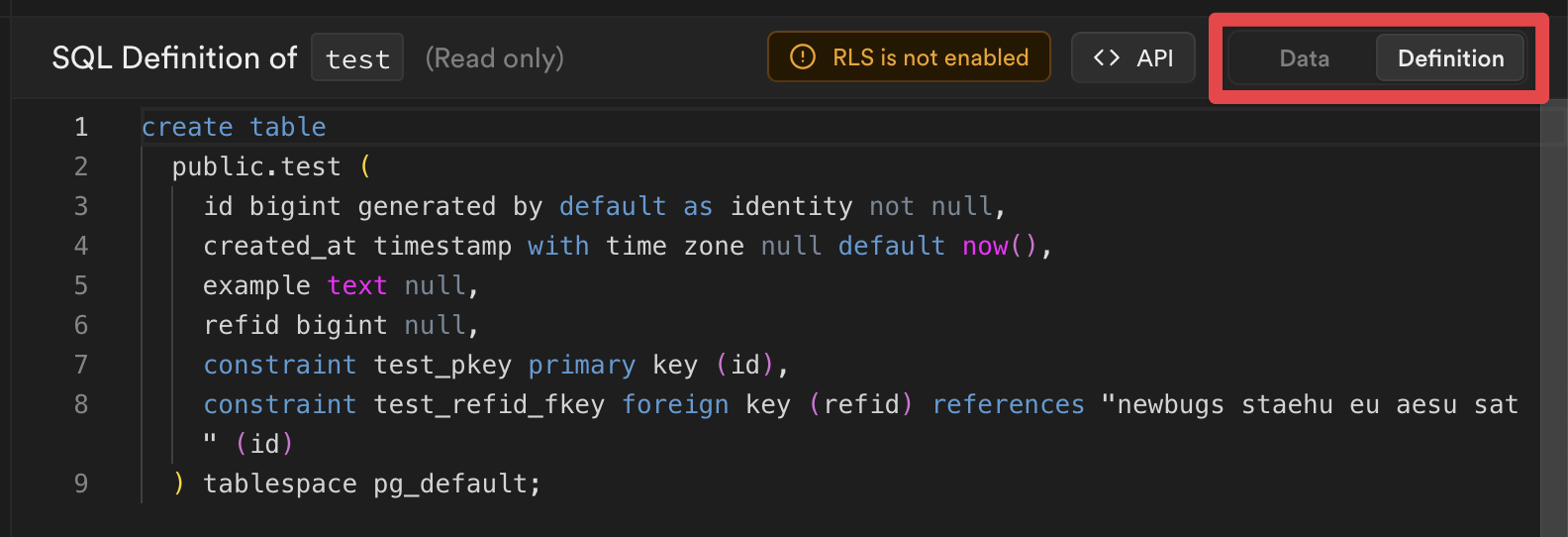
You can then copy this SQL into a new migration file, and run `supabase db reset` to apply the changes.
The last step is deploying these changes to a live Supabase project.
## Deploy your project
You've been developing your project locally, making changes to your tables via migrations. It's time to deploy your project to the Supabase Platform and start scaling up to millions of users! Head over to [Supabase](/dashboard) and create a new project to deploy to.
### Log in to the Supabase CLI
```bash name=Terminal
supabase login
```
```bash name=npx
npx supabase login
```
### Link your project
Associate your project with your remote project using [`supabase link`](/docs/reference/cli/usage#supabase-link).
```bash
supabase link --project-ref
# You can get from your project's dashboard URL: https://supabase.com/dashboard/project/
supabase db pull
# Capture any changes that you have made to your remote database before you went through the steps above
# If you have not made any changes to the remote database, skip this step
```
`supabase/migrations` is now populated with a migration in `_remote_schema.sql`.
This migration captures any changes required for your local database to match the schema of your remote Supabase project.
Review the generated migration file and once happy, apply the changes to your local instance:
```bash
# To apply the new migration to your local database:
supabase migration up
# To reset your local database completely:
supabase db reset
```
There are a few commands required to link your project. We are in the process of consolidating these commands into a single command. Bear with us!
### Deploy database changes
Deploy any local database migrations using [`db push`](/docs/reference/cli/usage#supabase-db-push):
```sh
supabase db push
```
Visiting your live project on [Supabase](/dashboard), you'll see a new `employees` table, complete with the `department` column you added in the second migration above.
### Deploy Edge Functions
If your project uses Edge Functions, you can deploy these using [`functions deploy`](/docs/reference/cli/usage#supabase-functions-deploy):
```sh
supabase functions deploy
```
### Use Auth locally
To use Auth locally, update your project's `supabase/config.toml` file that gets created after running `supabase init`. Add any providers you want, and set enabled to `true`.
```bash supabase/config.toml
[auth.external.github]
enabled = true
client_id = "env(SUPABASE_AUTH_GITHUB_CLIENT_ID)"
secret = "env(SUPABASE_AUTH_GITHUB_SECRET)"
redirect_uri = "http://localhost:54321/auth/v1/callback"
```
As a best practice, any secret values should be loaded from environment variables. You can add them to `.env` file in your project's root directory for the CLI to automatically substitute them.
```bash .env
SUPABASE_AUTH_GITHUB_CLIENT_ID="redacted"
SUPABASE_AUTH_GITHUB_SECRET="redacted"
```
For these changes to take effect, you need to run `supabase stop` and `supabase start` again.
If you have additional triggers or RLS policies defined on your `auth` schema, you can pull them as a migration file locally.
```bash
supabase db pull --schema auth
```
### Sync storage buckets
Your RLS policies on storage buckets can be pulled locally by specifying `storage` schema. For example,
```bash
supabase db pull --schema storage
```
The buckets and objects themselves are rows in the storage tables so they won't appear in your schema. You can instead define them via `supabase/config.toml` file. For example,
```bash supabase/config.toml
[storage.buckets.images]
public = false
file_size_limit = "50MiB"
allowed_mime_types = ["image/png", "image/jpeg"]
objects_path = "./images"
```
This will upload files from `supabase/images` directory to a bucket named `images` in your project with one command.
```bash
supabase seed buckets
```
### Sync any schema with `--schema`
You can synchronize your database with a specific schema using the `--schema` option as follows:
```bash
supabase db pull --schema
```
Using `--schema`
If the local `supabase/migrations` directory is empty, the `db pull` command will ignore the `--schema` parameter.
To fix this, you can pull twice:
```bash
supabase db pull
supabase db pull --schema
```
## Limitations and considerations
The local development environment is not as feature-complete as the Supabase Platform. Here are some of the differences:
* You cannot update your project settings in the Dashboard. This must be done using the local config file.
* The CLI version determines the local version of Studio used, so make sure you keep your local [Supabase CLI up to date](https://github.com/supabase/cli#getting-started). We're constantly adding new features and bug fixes.
# Restoring a downloaded backup locally
Restore a backup of a remote database on a local instance to inspect and extract data
If your paused project has exceeded its [restoring time limit](/docs/guides/platform/upgrading#time-limits), you can download a backup from the dashboard and restore it to your local development environment. This might be useful for inspecting and extracting data from your paused project.
If you want to restore your backup to a hosted Supabase project, follow the [Migrating within Supabase guide](/docs/guides/platform/migrating-within-supabase) instead.
## Downloading your backup
First, download your project's backup file from dashboard and identify its backup image version (following the `PG:` prefix):
## Restoring your backup
Given Postgres version `15.6.1.115`, start Postgres locally with `db_cluster.backup` being the path to your backup file.
```sh
supabase init
echo '15.6.1.115' > supabase/.temp/postgres-version
supabase db start --from-backup db_cluster.backup
```
Note that the earliest Supabase Postgres version that supports a local restore is `15.1.0.55`. If your hosted project was running on earlier versions, you will likely run into errors during restore. Before submitting any support ticket, make sure you have attached the error logs from `supabase_db_*` docker container.
Once your local database starts up successfully, you can connect using psql to verify that all your data is restored.
```sh
psql 'postgresql://postgres:postgres@localhost:54322/postgres'
```
If you want to use other services like Auth, Storage, and Studio dashboard together with your restored database, restart the local development stack.
```sh
supabase stop
supabase start
```
A Postgres database started with Supabase CLI is not production ready and should not be used outside of local development.
# Seeding your database
Populate your database with initial data for reproducible environments across local and testing.
## What is seed data?
Seeding is the process of populating a database with initial data, typically used to provide sample or default records for testing and development purposes. You can use this to create "reproducible environments" for local development, staging, and production.
## Using seed files
Seed files are executed the first time you run `supabase start` and every time you run `supabase db reset`. Seeding occurs *after* all database migrations have been completed. As a best practice, only include data insertions in your seed files, and avoid adding schema statements.
By default, if no specific configuration is provided, the system will look for a seed file matching the pattern `supabase/seed.sql`. This maintains backward compatibility with earlier versions, where the seed file was placed in the `supabase` folder.
You can add any SQL statements to this file. For example:
```sql
insert into countries
(name, code)
values
('United States', 'US'),
('Canada', 'CA'),
('Mexico', 'MX');
```
If you want to manage multiple seed files or organize them across different folders, you can configure additional paths or glob patterns in your `config.toml` (see the [next section](#splitting-up-your-seed-file) for details).
### Splitting up your seed file
For better modularity and maintainability, you can split your seed data into multiple files. For example, you can organize your seeds by table and include files such as `countries.sql` and `cities.sql`. Configure them in `config.toml` like so:
```toml supabase/config.toml
[db.seed]
enabled = true
sql_paths = ['./countries.sql', './cities.sql']
```
Or to include all `.sql` files under a specific folder you can do:
```toml supabase/config.toml
[db.seed]
enabled = true
sql_paths = ['./seeds/*.sql']
```
The CLI processes seed files in the order they are declared in the `sql_paths` array. If a glob pattern is used and matches multiple files, those files are sorted in lexicographic order to ensure consistent execution. Additionally:
* The base folder for the pattern matching is `supabase` so `./countries.sql` will search for `supabase/countries.sql`
* Files matched by multiple patterns will be deduplicated to prevent redundant seeding.
* If a pattern does not match any files, a warning will be logged to help you troubleshoot potential configuration issues.
## Generating seed data
You can generate seed data for local development using [Snaplet](https://github.com/snaplet/seed).
To use Snaplet, you need to have Node.js and npm installed. You can add Node.js to your project by running `npm init -y` in your project directory.
If this is your first time using Snaplet to seed your project, you'll need to set up Snaplet with the following command:
```bash
npx @snaplet/seed init
```
This command will analyze your database and its structure, and then generate a JavaScript client which can be used to define exactly how your data should be generated using code. The `init` command generates a configuration file, `seed.config.ts` and an example script, `seed.ts`, as a starting point.
During `init` if you are not using an Object Relational Mapper (ORM) or your ORM is not in the supported list, choose `node-postgres`.
In most cases you only want to generate data for specific schemas or tables. This is defined with `select`. Here is an example `seed.config.ts` configuration file:
```ts
export default defineConfig({
adapter: async () => {
const client = new Client({
connectionString: 'postgresql://postgres:postgres@localhost:54322/postgres',
})
await client.connect()
return new SeedPg(client)
},
// We only want to generate data for the public schema
select: ['!*', 'public.*'],
})
```
Suppose you have a database with the following schema:
You can use the seed script example generated by Snaplet `seed.ts` to define the values you want to generate. For example:
* A `Post` with the title `"There is a lot of snow around here!"`
* The `Post.createdBy` user with an email address ending in `"@acme.org"`
* Three `Post.comments` from three different users.
```ts seed.ts
import { createSeedClient } from '@snaplet/seed'
import { copycat } from '@snaplet/copycat'
async function main() {
const seed = await createSeedClient({ dryRun: true })
await seed.Post([
{
title: 'There is a lot of snow around here!',
createdBy: {
email: (ctx) =>
copycat.email(ctx.seed, {
domain: 'acme.org',
}),
},
Comment: (x) => x(3),
},
])
process.exit()
}
main()
```
Running `npx tsx seed.ts > supabase/seed.sql` generates the relevant SQL statements inside your `supabase/seed.sql` file:
```sql
-- The `Post.createdBy` user with an email address ending in `"@acme.org"`
INSERT INTO "User" (name, email) VALUES ("John Snow", "snow@acme.org")
--- A `Post` with the title `"There is a lot of snow around here!"`
INSERT INTO "Post" (title, content, createdBy) VALUES (
"There is a lot of snow around here!",
"Lorem ipsum dolar",
1)
--- Three `Post.Comment` from three different users.
INSERT INTO "User" (name, email) VALUES ("Stephanie Shadow", "shadow@domain.com")
INSERT INTO "Comment" (text, userId, postId) VALUES ("I love cheese", 2, 1)
INSERT INTO "User" (name, email) VALUES ("John Rambo", "rambo@trymore.dev")
INSERT INTO "Comment" (text, userId, postId) VALUES ("Lorem ipsum dolar sit", 3, 1)
INSERT INTO "User" (name, email) VALUES ("Steven Plank", "s@plank.org")
INSERT INTO "Comment" (text, userId, postId) VALUES ("Actually, that's not correct...", 4, 1)
```
Whenever your database structure changes, you will need to regenerate `@snaplet/seed` to keep it in sync with the new structure. You can do this by running:
```bash
npx @snaplet/seed sync
```
You can further enhance your seed script by using Large Language Models to generate more realistic data. To enable this feature, set one of the following environment variables in your `.env` file:
```plaintext
OPENAI_API_KEY=
GROQ_API_KEY=
```
After setting the environment variables, run the following commands to sync and generate the seed data:
```bash
npx @snaplet/seed sync
npx tsx seed.ts > supabase/seed.sql
```
For more information, check out Snaplet's [seed documentation](https://snaplet-seed.netlify.app/seed/integrations/supabase)
# Testing Overview
Testing is a critical part of database development, especially when working with features like Row Level Security (RLS) policies. This guide provides a comprehensive approach to testing your Supabase database.
## Testing approaches
### Database unit testing with pgTAP
[pgTAP](https://pgtap.org) is a unit testing framework for Postgres that allows testing:
* Database structure: tables, columns, constraints
* Row Level Security (RLS) policies
* Functions and procedures
* Data integrity
This example demonstrates setting up and testing RLS policies for a simple todo application:
1. Create a test table with RLS enabled:
```sql
-- Create a simple todos table
create table todos (
id uuid primary key default gen_random_uuid(),
task text not null,
user_id uuid references auth.users not null,
completed boolean default false
);
-- Enable RLS
alter table todos enable row level security;
-- Create a policy
create policy "Users can only access their own todos"
on todos for all -- this policy applies to all operations
to authenticated
using ((select auth.uid()) = user_id);
```
2. Set up your testing environment:
```bash
# Create a new test for our policies using supabase cli
supabase test new todos_rls.test
```
3. Write your RLS tests:
```sql
begin;
-- install tests utilities
-- install pgtap extension for testing
create extension if not exists pgtap with schema extensions;
-- Start declare we'll have 4 test cases in our test suite
select plan(4);
-- Setup our testing data
-- Set up auth.users entries
insert into auth.users (id, email) values
('123e4567-e89b-12d3-a456-426614174000', 'user1@test.com'),
('987fcdeb-51a2-43d7-9012-345678901234', 'user2@test.com');
-- Create test todos
insert into public.todos (task, user_id) values
('User 1 Task 1', '123e4567-e89b-12d3-a456-426614174000'),
('User 1 Task 2', '123e4567-e89b-12d3-a456-426614174000'),
('User 2 Task 1', '987fcdeb-51a2-43d7-9012-345678901234');
-- as User 1
set local role authenticated;
set local request.jwt.claim.sub = '123e4567-e89b-12d3-a456-426614174000';
-- Test 1: User 1 should only see their own todos
select results_eq(
'select count(*) from todos',
ARRAY[2::bigint],
'User 1 should only see their 2 todos'
);
-- Test 2: User 1 can create their own todo
select lives_ok(
$$insert into todos (task, user_id) values ('New Task', '123e4567-e89b-12d3-a456-426614174000'::uuid)$$,
'User 1 can create their own todo'
);
-- as User 2
set local request.jwt.claim.sub = '987fcdeb-51a2-43d7-9012-345678901234';
-- Test 3: User 2 should only see their own todos
select results_eq(
'select count(*) from todos',
ARRAY[1::bigint],
'User 2 should only see their 1 todo'
);
-- Test 4: User 2 cannot modify User 1's todo
SELECT results_ne(
$$ update todos set task = 'Hacked!' where user_id = '123e4567-e89b-12d3-a456-426614174000'::uuid returning 1 $$,
$$ values(1) $$,
'User 2 cannot modify User 1 todos'
);
select * from finish();
rollback;
```
4. Run the tests:
```bash
supabase test db
psql:todos_rls.test.sql:4: NOTICE: extension "pgtap" already exists, skipping
./todos_rls.test.sql .. ok
All tests successful.
Files=1, Tests=6, 0 wallclock secs ( 0.01 usr + 0.00 sys = 0.01 CPU)
Result: PASS
```
### Application-Level testing
Testing through application code provides end-to-end verification. Unlike database-level testing with pgTAP, application-level tests cannot use transactions for isolation.
Application-level tests should not rely on a clean database state, as resetting the database before each test can be slow and makes tests difficult to parallelize.
Instead, design your tests to be independent by using unique user IDs for each test case.
Here's an example using TypeScript that mirrors the pgTAP tests above:
```typescript
import crypto from 'crypto'
import { createClient } from '@supabase/supabase-js'
import { beforeAll, describe, expect, it } from 'vitest'
describe('Todos RLS', () => {
// Generate unique IDs for this test suite to avoid conflicts with other tests
const USER_1_ID = crypto.randomUUID()
const USER_2_ID = crypto.randomUUID()
const supabase = createClient(process.env.SUPABASE_URL!, process.env.SUPABASE_PUBLISHABLE_KEY!)
beforeAll(async () => {
// Setup test data specific to this test suite
const adminSupabase = createClient(process.env.SUPABASE_URL!, process.env.SUPABASE_SECRET_KEY!)
// Create test users with unique IDs
await adminSupabase.auth.admin.createUser({
id: USER_1_ID,
email: `user1-${USER_1_ID}@test.com`,
password: 'password123',
// We want the user to be usable right away without email confirmation
email_confirm: true,
})
await adminSupabase.auth.admin.createUser({
id: USER_2_ID,
email: `user2-${USER_2_ID}@test.com`,
password: 'password123',
email_confirm: true,
})
// Create initial todos
await adminSupabase.from('todos').insert([
{ task: 'User 1 Task 1', user_id: USER_1_ID },
{ task: 'User 1 Task 2', user_id: USER_1_ID },
{ task: 'User 2 Task 1', user_id: USER_2_ID },
])
})
it('should allow User 1 to only see their own todos', async () => {
// Sign in as User 1
await supabase.auth.signInWithPassword({
email: `user1-${USER_1_ID}@test.com`,
password: 'password123',
})
const { data: todos } = await supabase.from('todos').select('*')
expect(todos).toHaveLength(2)
todos?.forEach((todo) => {
expect(todo.user_id).toBe(USER_1_ID)
})
})
it('should allow User 1 to create their own todo', async () => {
await supabase.auth.signInWithPassword({
email: `user1-${USER_1_ID}@test.com`,
password: 'password123',
})
const { error } = await supabase.from('todos').insert({ task: 'New Task', user_id: USER_1_ID })
expect(error).toBeNull()
})
it('should allow User 2 to only see their own todos', async () => {
// Sign in as User 2
await supabase.auth.signInWithPassword({
email: `user2-${USER_2_ID}@test.com`,
password: 'password123',
})
const { data: todos } = await supabase.from('todos').select('*')
expect(todos).toHaveLength(1)
todos?.forEach((todo) => {
expect(todo.user_id).toBe(USER_2_ID)
})
})
it('should prevent User 2 from modifying User 1 todos', async () => {
await supabase.auth.signInWithPassword({
email: `user2-${USER_2_ID}@test.com`,
password: 'password123',
})
// Attempt to update the todos we shouldn't have access to
// result will be a no-op
await supabase.from('todos').update({ task: 'Hacked!' }).eq('user_id', USER_1_ID)
// Log back in as User 1 to verify their todos weren't changed
await supabase.auth.signInWithPassword({
email: `user1-${USER_1_ID}@test.com`,
password: 'password123',
})
// Fetch User 1's todos
const { data: todos } = await supabase.from('todos').select('*')
// Verify that none of the todos were changed to "Hacked!"
expect(todos).toBeDefined()
todos?.forEach((todo) => {
expect(todo.task).not.toBe('Hacked!')
})
})
})
```
#### Test isolation strategies
For application-level testing, consider these approaches for test isolation:
1. **Unique Identifiers**: Generate unique IDs for each test suite to prevent data conflicts
2. **Cleanup After Tests**: If necessary, clean up created data in an `afterAll` or `afterEach` hook
3. **Isolated Data Sets**: Use prefixes or namespaces in data to separate test cases
### Continuous integration testing
Set up automated database testing in your CI pipeline:
1. Create a GitHub Actions workflow `.github/workflows/db-tests.yml`:
```yaml
name: Database Tests
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Supabase CLI
uses: supabase/setup-cli@v1
- name: Start Supabase
run: supabase start
- name: Run Tests
run: supabase test db
```
## Best practices
1. **Test Data Setup**
* Use begin and rollback to ensure test isolation
* Create realistic test data that covers edge cases
* Use different user roles and permissions in tests
2. **RLS Policy Testing**
* Test Create, Read, Update, Delete operations
* Test with different user roles: anonymous and authenticated
* Test edge cases and potential security bypasses
* Always test negative cases: what users should not be able to do
3. **CI/CD Integration**
* Run tests automatically on every pull request
* Include database tests in deployment pipeline
* Keep test runs fast using transactions
## Real-World examples
For more complex, real-world examples of database testing, check out:
* [Database Tests Example Repository](https://github.com/usebasejump/basejump/tree/main/supabase/tests/database) - A production-grade example of testing RLS policies
* [RLS Guide and Best Practices](https://github.com/orgs/supabase/discussions/14576)
## Troubleshooting
Common issues and solutions:
1. **Test Failures Due to RLS**
* Ensure you've set the correct role `set local role authenticated;`
* Verify JWT claims are set `set local "request.jwt.claims"`
* Check policy definitions match your test assumptions
2. **CI Pipeline Issues**
* Verify Supabase CLI is properly installed
* Ensure database migrations are run before tests
* Check for proper test isolation using transactions
## Additional resources
* [pgTAP Documentation](https://pgtap.org)
* [Supabase CLI Reference](/docs/reference/cli/supabase-test)
* [pgTAP Supabase reference](/docs/guides/database/extensions/pgtap?queryGroups=database-method\&database-method=sql#testing-rls-policies)
* [Database testing reference](/docs/guides/database/testing)
# Advanced pgTAP Testing
While basic pgTAP provides excellent testing capabilities, you can enhance the testing workflow using database development tools and helper packages. This guide covers advanced testing techniques using database.dev and community-maintained test helpers.
## Using database.dev
[Database.dev](https://database.dev) is a package manager for Postgres that allows installation and use of community-maintained packages, including testing utilities.
### Setting up dbdev
To use database development tools and packages, install some prerequisites:
```sql
create extension if not exists http with schema extensions;
create extension if not exists pg_tle;
drop extension if exists "supabase-dbdev";
select pgtle.uninstall_extension_if_exists('supabase-dbdev');
select
pgtle.install_extension(
'supabase-dbdev',
resp.contents ->> 'version',
'PostgreSQL package manager',
resp.contents ->> 'sql'
)
from extensions.http(
(
'GET',
'https://api.database.dev/rest/v1/'
|| 'package_versions?select=sql,version'
|| '&package_name=eq.supabase-dbdev'
|| '&order=version.desc'
|| '&limit=1',
array[
('apiKey', 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJzdXBhYmFzZSIsInJlZiI6InhtdXB0cHBsZnZpaWZyYndtbXR2Iiwicm9sZSI6ImFub24iLCJpYXQiOjE2ODAxMDczNzIsImV4cCI6MTk5NTY4MzM3Mn0.z2CN0mvO2No8wSi46Gw59DFGCTJrzM0AQKsu_5k134s')::extensions.http_header
],
null,
null
)
) x,
lateral (
select
((row_to_json(x) -> 'content') #>> '{}')::json -> 0
) resp(contents);
create extension "supabase-dbdev";
select dbdev.install('supabase-dbdev');
-- Drop and recreate the extension to ensure a clean installation
drop extension if exists "supabase-dbdev";
create extension "supabase-dbdev";
```
### Installing test helpers
The Test Helpers package provides utilities that simplify testing Supabase-specific features:
```sql
select dbdev.install('basejump-supabase_test_helpers');
create extension if not exists "basejump-supabase_test_helpers" version '0.0.6';
```
## Test helper benefits
The test helpers package provides several advantages over writing raw pgTAP tests:
1. **Simplified User Management**
* Create test users with `tests.create_supabase_user()`
* Switch contexts with `tests.authenticate_as()`
* Retrieve user IDs using `tests.get_supabase_uid()`
2. **Row Level Security (RLS) Testing Utilities**
* Verify RLS status with `tests.rls_enabled()`
* Test policy enforcement
* Simulate different user contexts
3. **Reduced Boilerplate**
* No need to manually insert auth.users
* Simplified JWT claim management
* Clean test setup and cleanup
## Schema-wide Row Level Security testing
When working with Row Level Security, it's crucial to ensure that RLS is enabled on all tables that need it. Create a simple test to verify RLS is enabled across an entire schema:
```sql
begin;
select plan(1);
-- Verify RLS is enabled on all tables in the public schema
select tests.rls_enabled('public');
select * from finish();
rollback;
```
## Test file organization
When working with multiple test files that share common setup requirements, it's beneficial to create a single "pre-test" file that handles the global environment setup. This approach reduces duplication and ensures consistent test environments.
### Creating a pre-test hook
Since pgTAP test files are executed in alphabetical order, create a setup file that runs first by using a naming convention like `000-setup-tests-hooks.sql`:
```bash
supabase test new 000-setup-tests-hooks
```
This setup file should contain:
1. All shared extensions and dependencies
2. Common test utilities
3. A simple always green test to verify the setup
Here's an example setup file:
```sql
-- install tests utilities
-- install pgtap extension for testing
create extension if not exists pgtap with schema extensions;
/*
---------------------
---- install dbdev ----
----------------------
Requires:
- pg_tle: https://github.com/aws/pg_tle
- pgsql-http: https://github.com/pramsey/pgsql-http
*/
create extension if not exists http with schema extensions;
create extension if not exists pg_tle;
drop extension if exists "supabase-dbdev";
select pgtle.uninstall_extension_if_exists('supabase-dbdev');
select
pgtle.install_extension(
'supabase-dbdev',
resp.contents ->> 'version',
'PostgreSQL package manager',
resp.contents ->> 'sql'
)
from extensions.http(
(
'GET',
'https://api.database.dev/rest/v1/'
|| 'package_versions?select=sql,version'
|| '&package_name=eq.supabase-dbdev'
|| '&order=version.desc'
|| '&limit=1',
array[
('apiKey', 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJzdXBhYmFzZSIsInJlZiI6InhtdXB0cHBsZnZpaWZyYndtbXR2Iiwicm9sZSI6ImFub24iLCJpYXQiOjE2ODAxMDczNzIsImV4cCI6MTk5NTY4MzM3Mn0.z2CN0mvO2No8wSi46Gw59DFGCTJrzM0AQKsu_5k134s')::extensions.http_header
],
null,
null
)
) x,
lateral (
select
((row_to_json(x) -> 'content') #>> '{}')::json -> 0
) resp(contents);
create extension "supabase-dbdev";
select dbdev.install('supabase-dbdev');
drop extension if exists "supabase-dbdev";
create extension "supabase-dbdev";
-- Install test helpers
select dbdev.install('basejump-supabase_test_helpers');
create extension if not exists "basejump-supabase_test_helpers" version '0.0.6';
-- Verify setup with a no-op test
begin;
select plan(1);
select ok(true, 'Pre-test hook completed successfully');
select * from finish();
rollback;
```
### Benefits
This approach provides several advantages:
* Reduces code duplication across test files
* Ensures consistent test environment setup
* Makes it easier to maintain and update shared dependencies
* Provides immediate feedback if the setup process fails
Your subsequent test files (`001-auth-tests.sql`, `002-rls-tests.sql`) can focus solely on their specific test cases, knowing that the environment is properly configured.
## Example: Advanced RLS testing
Here's a complete example using test helpers to verify RLS policies putting it all together:
```sql
begin;
-- Assuming 000-setup-tests-hooks.sql file is present to use tests helpers
select plan(4);
-- Set up test data
-- Create test supabase users
select tests.create_supabase_user('user1@test.com');
select tests.create_supabase_user('user2@test.com');
-- Create test data
insert into public.todos (task, user_id) values
('User 1 Task 1', tests.get_supabase_uid('user1@test.com')),
('User 1 Task 2', tests.get_supabase_uid('user1@test.com')),
('User 2 Task 1', tests.get_supabase_uid('user2@test.com'));
-- Test as User 1
select tests.authenticate_as('user1@test.com');
-- Test 1: User 1 should only see their own todos
select results_eq(
'select count(*) from todos',
ARRAY[2::bigint],
'User 1 should only see their 2 todos'
);
-- Test 2: User 1 can create their own todo
select lives_ok(
$$insert into todos (task, user_id) values ('New Task', tests.get_supabase_uid('user1@test.com'))$$,
'User 1 can create their own todo'
);
-- Test as User 2
select tests.authenticate_as('user2@test.com');
-- Test 3: User 2 should only see their own todos
select results_eq(
'select count(*) from todos',
ARRAY[1::bigint],
'User 2 should only see their 1 todo'
);
-- Test 4: User 2 cannot modify User 1's todo
SELECT results_ne(
$$ update todos set task = 'Hacked!' where user_id = tests.get_supabase_uid('user1@test.com') returning 1 $$,
$$ values(1) $$,
'User 2 cannot modify User 1 todos'
);
select * from finish();
rollback;
```
## Not another todo app: Testing complex organizations
Todo apps are great for learning, but this section explores testing a more realistic scenario: a multi-tenant content publishing platform. This example demonstrates testing complex permissions, plan restrictions, and content management.
### System overview
This demo app implements:
* Organizations with tiered plans (free/pro/enterprise)
* Role-based access (owner/admin/editor/viewer)
* Content management (posts/comments)
* Premium content restrictions
* Plan-based limitations
### What makes this complex?
1. **Layered Permissions**
* Role hierarchies affect access rights
* Plan types influence user capabilities
* Content state (draft/published) affects permissions
2. **Business Rules**
* Free plan post limits
* Premium content visibility
* Cross-organization security
### Testing focus areas
When writing tests, verify:
* Organization member access control
* Content visibility across roles
* Plan limitation enforcement
* Cross-organization data isolation
#### 1. App schema definitions
The app schema tables are defined like this:
```sql
create table public.profiles (
id uuid references auth.users(id) primary key,
username text unique not null,
full_name text,
bio text,
created_at timestamptz default now(),
updated_at timestamptz default now()
);
create table public.organizations (
id bigint primary key generated always as identity,
name text not null,
slug text unique not null,
plan_type text not null check (plan_type in ('free', 'pro', 'enterprise')),
max_posts int not null default 5,
created_at timestamptz default now()
);
create table public.org_members (
org_id bigint references public.organizations(id) on delete cascade,
user_id uuid references auth.users(id) on delete cascade,
role text not null check (role in ('owner', 'admin', 'editor', 'viewer')),
created_at timestamptz default now(),
primary key (org_id, user_id)
);
create table public.posts (
id bigint primary key generated always as identity,
title text not null,
content text not null,
author_id uuid references public.profiles(id) not null,
org_id bigint references public.organizations(id),
status text not null check (status in ('draft', 'published', 'archived')),
is_premium boolean default false,
scheduled_for timestamptz,
category text,
view_count int default 0,
published_at timestamptz,
created_at timestamptz default now(),
updated_at timestamptz default now()
);
create table public.comments (
id bigint primary key generated always as identity,
post_id bigint references public.posts(id) on delete cascade,
author_id uuid references public.profiles(id),
content text not null,
is_deleted boolean default false,
created_at timestamptz default now(),
updated_at timestamptz default now()
);
```
#### 2. Grant role privileges
Grant the necessary privileges for each role, ensuring the principle of least privilege is followed:
```sql
-- Grant the privileges that roles need
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.profiles TO authenticated;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.profiles TO service_role;
GRANT SELECT ON public.organizations TO anon;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.organizations TO authenticated;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.organizations TO service_role;
GRANT SELECT ON public.org_members TO anon;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.org_members TO authenticated;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.org_members TO service_role;
GRANT SELECT ON public.posts TO anon;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.posts TO authenticated;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.posts TO service_role;
GRANT SELECT ON public.comments TO anon;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.comments TO authenticated;
GRANT SELECT, INSERT, UPDATE, DELETE ON public.comments TO service_role;
```
#### 3. RLS policies declaration
Now to setup the RLS policies for each tables:
```sql
-- Create a private schema to store all security definer functions utils
-- As such functions should never be in an API exposed schema
create schema if not exists private;
-- Helper function for role checks
create or replace function private.get_user_org_role(org_id bigint, user_id uuid)
returns text
set search_path = ''
as $$
select role from public.org_members
where org_id = $1 and user_id = $2;
-- Note the use of security definer to avoid RLS checking recursion issue
-- see: https://supabase.com/docs/guides/database/postgres/row-level-security#use-security-definer-functions
$$ language sql security definer;
-- Helper utils to check if an org is below the max post limit
create or replace function private.can_add_post(org_id bigint)
returns boolean
set search_path = ''
as $$
select (select count(*)
from public.posts p
where p.org_id = $1) < o.max_posts
from public.organizations o
where o.id = $1
$$ language sql security definer;
-- Enable RLS for all tables
alter table public.profiles enable row level security;
alter table public.organizations enable row level security;
alter table public.org_members enable row level security;
alter table public.posts enable row level security;
alter table public.comments enable row level security;
-- Profiles policies
create policy "Public profiles are viewable by everyone"
on public.profiles for select using (true);
create policy "Users can insert their own profile"
on public.profiles for insert with check ((select auth.uid()) = id);
create policy "Users can update their own profile"
on public.profiles for update using ((select auth.uid()) = id)
with check ((select auth.uid()) = id);
-- Organizations policies
create policy "Public org info visible to all"
on public.organizations for select using (true);
create policy "Org management restricted to owners"
on public.organizations for all using (
private.get_user_org_role(id, (select auth.uid())) = 'owner'
);
-- Org Members policies
create policy "Members visible to org members"
on public.org_members for select using (
private.get_user_org_role(org_id, (select auth.uid())) is not null
);
create policy "Member management restricted to admins and owners"
on public.org_members for all using (
private.get_user_org_role(org_id, (select auth.uid())) in ('owner', 'admin')
);
-- Posts policies
create policy "Complex post visibility"
on public.posts for select using (
-- Published non-premium posts are visible to all
(status = 'published' and not is_premium)
or
-- Premium posts visible to org members only
(status = 'published' and is_premium and
private.get_user_org_role(org_id, (select auth.uid())) is not null)
or
-- All posts visible to editors and above
private.get_user_org_role(org_id, (select auth.uid())) in ('owner', 'admin', 'editor')
);
create policy "Post creation rules"
on public.posts for insert with check (
-- Must be org member with appropriate role
private.get_user_org_role(org_id, (select auth.uid())) in ('owner', 'admin', 'editor')
and
-- Check org post limits for free plans
(
(select o.plan_type != 'free'
from organizations o
where o.id = org_id)
or
(select private.can_add_post(org_id))
)
);
create policy "Post update rules"
on public.posts for update using (
exists (
select 1
where
-- Editors can update non-published posts
(private.get_user_org_role(org_id, (select auth.uid())) = 'editor' and status != 'published')
or
-- Admins and owners can update any post
private.get_user_org_role(org_id, (select auth.uid())) in ('owner', 'admin')
)
);
-- Comments policies
create policy "Comments on published posts are viewable by everyone"
on public.comments for select using (
exists (
select 1 from public.posts
where id = post_id
and status = 'published'
)
and not is_deleted
);
create policy "Authenticated users can create comments"
on public.comments for insert with check ((select auth.uid()) = author_id);
create policy "Users can update their own comments"
on public.comments for update using (author_id = (select auth.uid()));
```
#### 4. Test cases:
Now everything is setup, let's write RLS test cases, note that each section could be in its own test:
```sql
-- Assuming we already have: 000-setup-tests-hooks.sql file we can use tests helpers
begin;
-- Declare total number of tests
select plan(10);
-- Create test users
select tests.create_supabase_user('org_owner', 'owner@test.com');
select tests.create_supabase_user('org_admin', 'admin@test.com');
select tests.create_supabase_user('org_editor', 'editor@test.com');
select tests.create_supabase_user('premium_user', 'premium@test.com');
select tests.create_supabase_user('free_user', 'free@test.com');
select tests.create_supabase_user('scheduler', 'scheduler@test.com');
select tests.create_supabase_user('free_author', 'free_author@test.com');
-- Create profiles for test users
insert into profiles (id, username, full_name)
values
(tests.get_supabase_uid('org_owner'), 'org_owner', 'Organization Owner'),
(tests.get_supabase_uid('org_admin'), 'org_admin', 'Organization Admin'),
(tests.get_supabase_uid('org_editor'), 'org_editor', 'Organization Editor'),
(tests.get_supabase_uid('premium_user'), 'premium_user', 'Premium User'),
(tests.get_supabase_uid('free_user'), 'free_user', 'Free User'),
(tests.get_supabase_uid('scheduler'), 'scheduler', 'Scheduler User'),
(tests.get_supabase_uid('free_author'), 'free_author', 'Free Author');
-- First authenticate as service role to bypass RLS for initial setup
select tests.authenticate_as_service_role();
-- Create test organizations and setup data
with new_org as (
insert into organizations (name, slug, plan_type, max_posts)
values
('Test Org', 'test-org', 'pro', 100),
('Premium Org', 'premium-org', 'enterprise', 1000),
('Schedule Org', 'schedule-org', 'pro', 100),
('Free Org', 'free-org', 'free', 2)
returning id, slug
),
-- Setup members and posts
member_setup as (
insert into org_members (org_id, user_id, role)
select
org.id,
user_id,
role
from new_org org cross join (
values
(tests.get_supabase_uid('org_owner'), 'owner'),
(tests.get_supabase_uid('org_admin'), 'admin'),
(tests.get_supabase_uid('org_editor'), 'editor'),
(tests.get_supabase_uid('premium_user'), 'viewer'),
(tests.get_supabase_uid('scheduler'), 'editor'),
(tests.get_supabase_uid('free_author'), 'editor')
) as members(user_id, role)
where org.slug = 'test-org'
or (org.slug = 'premium-org' and role = 'viewer')
or (org.slug = 'schedule-org' and role = 'editor')
or (org.slug = 'free-org' and role = 'editor')
)
-- Setup initial posts
insert into posts (title, content, org_id, author_id, status, is_premium, scheduled_for)
select
title,
content,
org.id,
author_id,
status,
is_premium,
scheduled_for
from new_org org cross join (
values
('Premium Post', 'Premium content', tests.get_supabase_uid('premium_user'), 'published', true, null),
('Free Post', 'Free content', tests.get_supabase_uid('premium_user'), 'published', false, null),
('Future Post', 'Future content', tests.get_supabase_uid('scheduler'), 'published', false, '2024-01-02 12:00:00+00'::timestamptz)
) as posts(title, content, author_id, status, is_premium, scheduled_for)
where org.slug in ('premium-org', 'schedule-org');
-- Test owner privileges
select tests.authenticate_as('org_owner');
select lives_ok(
$$
update organizations
set name = 'Updated Org'
where id = (select id from organizations limit 1)
$$,
'Owner can update organization'
);
-- Test admin privileges
select tests.authenticate_as('org_admin');
select results_eq(
$$select count(*) from org_members$$,
ARRAY[6::bigint],
'Admin can view all members'
);
-- Test editor restrictions
select tests.authenticate_as('org_editor');
select throws_ok(
$$
insert into org_members (org_id, user_id, role)
values (
(select id from organizations limit 1),
(select tests.get_supabase_uid('org_editor')),
'viewer'
)
$$,
'42501',
'new row violates row-level security policy for table "org_members"',
'Editor cannot manage members'
);
-- Premium Content Access Tests
select tests.authenticate_as('premium_user');
select results_eq(
$$select count(*) from posts where org_id = (select id from organizations where slug = 'premium-org')$$,
ARRAY[3::bigint],
'Premium user can see all posts'
);
select tests.clear_authentication();
select results_eq(
$$select count(*) from posts where org_id = (select id from organizations where slug = 'premium-org')$$,
ARRAY[2::bigint],
'Anonymous users can only see free posts'
);
-- Time-Based Publishing Tests
select tests.authenticate_as('scheduler');
select tests.freeze_time('2024-01-01 12:00:00+00'::timestamptz);
select results_eq(
$$select count(*) from posts where scheduled_for > now() and org_id = (select id from organizations where slug = 'schedule-org')$$,
ARRAY[1::bigint],
'Can see scheduled posts'
);
select tests.freeze_time('2024-01-02 13:00:00+00'::timestamptz);
select results_eq(
$$select count(*) from posts where scheduled_for < now() and org_id = (select id from organizations where slug = 'schedule-org')$$,
ARRAY[1::bigint],
'Can see posts after schedule time'
);
select tests.unfreeze_time();
-- Plan Limit Tests
select tests.authenticate_as('free_author');
select lives_ok(
$$
insert into posts (title, content, org_id, author_id, status)
select 'Post 1', 'Content 1', id, auth.uid(), 'draft'
from organizations where slug = 'free-org' limit 1
$$,
'First post creates successfully'
);
select lives_ok(
$$
insert into posts (title, content, org_id, author_id, status)
select 'Post 2', 'Content 2', id, auth.uid(), 'draft'
from organizations where slug = 'free-org' limit 1
$$,
'Second post creates successfully'
);
select throws_ok(
$$
insert into posts (title, content, org_id, author_id, status)
select 'Post 3', 'Content 3', id, auth.uid(), 'draft'
from organizations where slug = 'free-org' limit 1
$$,
'42501',
'new row violates row-level security policy for table "posts"',
'Cannot exceed free plan post limit'
);
select * from finish();
rollback;
```
## Additional resources
* [Test Helpers Documentation](https://database.dev/basejump/supabase_test_helpers)
* [Test Helpers Reference](https://github.com/usebasejump/supabase-test-helpers)
* [Row Level Security Writing Guide](https://usebasejump.com/blog/testing-on-supabase-with-pgtap)
* [Database.dev Package Registry](https://database.dev)
* [Row Level Security Performance and Best Practices](https://github.com/orgs/supabase/discussions/14576)
# Supabase CLI
Develop locally, deploy to the Supabase Platform, and set up CI/CD workflows
The Supabase CLI enables you to run the entire Supabase stack locally, on your machine or in a CI environment. With just two commands, you can set up and start a new local project:
1. `supabase init` to create a new local project
2. `supabase start` to launch the Supabase services
## Installing the Supabase CLI
Install the CLI with [Homebrew](https://brew.sh):
```sh
brew install supabase/tap/supabase
```
Install the CLI with [Scoop](https://scoop.sh):
```powershell
scoop bucket add supabase https://github.com/supabase/scoop-bucket.git
scoop install supabase
```
The CLI is available through [Homebrew](https://brew.sh) and Linux packages.
#### Homebrew
```sh
brew install supabase/tap/supabase
```
#### Linux packages
Linux packages are provided in [Releases](https://github.com/supabase/cli/releases).
To install, download the `.apk`/`.deb`/`.rpm` file depending on your package manager
and run one of the following:
* `sudo apk add --allow-untrusted <...>.apk`
* `sudo dpkg -i <...>.deb`
* `sudo rpm -i <...>.rpm`
Run the CLI by prefixing each command with `npx` or `bunx`:
```sh
npx supabase --help
```
The Supabase CLI requires **Node.js 20 or later** when run via `npx` or `npm`. Older Node.js versions, such as 16, are not supported and fail to start the CLI.
Installing the Supabase CLI globally using `npm install -g supabase` is **not supported**.
For global usage, install the CLI via Homebrew, Scoop, or the standalone binary.
Alternatively, you can run the CLI using `npx supabase` or install it locally as a dev dependency.
You can also install the CLI as dev dependency via [npm](https://www.npmjs.com/package/supabase):
```sh
npm install supabase --save-dev
```
Global installation using `npm install -g supabase` is not supported. For global CLI usage, install via [Homebrew](/docs/guides/local-development/cli/getting-started?queryGroups=platform\&platform=macos), [Scoop](/docs/guides/local-development/cli/getting-started?queryGroups=platform\&platform=windows), or the [standalone binary](/docs/guides/local-development/cli/getting-started?queryGroups=platform\&platform=linux).
## Beta channel
Pre-release CLI builds ship from the development branch (`X.Y.Z-beta.N` versions). Use the npm `beta` dist-tag, or install `supabase-beta` via Homebrew / Scoop (separate packages from stable).
```sh
brew install supabase/tap/supabase-beta
brew link --overwrite supabase-beta
```
```powershell
scoop bucket add supabase https://github.com/supabase/scoop-bucket.git
scoop install supabase-beta
```
#### Homebrew
```sh
brew install supabase/tap/supabase-beta
brew link --overwrite supabase-beta
```
#### Linux packages
Beta builds are attached to [GitHub pre-releases](https://github.com/supabase/cli/releases). Download the `.apk`, `.deb`, or `.rpm` for your platform and install with the same commands as [Linux packages](#linux-packages) above.
Install as a dev dependency:
```sh
npm install supabase@beta --save-dev
```
Or run without installing:
```sh
npx supabase@beta --help
```
## Updating the Supabase CLI
When a new [version](https://github.com/supabase/cli/releases) is released, you can update the CLI using the same methods.
```sh
brew upgrade supabase
```
Beta channel:
```sh
brew upgrade supabase-beta
```
```powershell
scoop update supabase
```
Beta channel:
```powershell
scoop update supabase-beta
```
#### Homebrew
```sh
brew upgrade supabase
```
Beta channel:
```sh
brew upgrade supabase-beta
```
#### Linux package manager
1. Download the latest package from the [Supabase CLI releases page](https://github.com/supabase/cli/releases/latest)
2. Install the package using the same commands as the [initial installation](#linux-packages):
* `sudo apk add --allow-untrusted <...>.apk`
* `sudo dpkg -i <...>.deb`
* `sudo rpm -i <...>.rpm`
If you have installed the CLI as dev dependency via [npm](https://www.npmjs.com/package/supabase), you can update it with:
```sh
npm update supabase --save-dev
```
Beta channel (`supabase@beta`):
```sh
npm update supabase@beta --save-dev
```
If you have any Supabase containers running locally, stop them and delete their data volumes before proceeding with the upgrade. This ensures that Supabase managed services can apply new migrations on a clean state of the local database.
Remember to save any local schema and data changes before stopping because the `--no-backup` flag will delete them.
```sh
supabase db diff -f my_schema
supabase db dump --local --data-only > supabase/seed.sql
supabase stop --no-backup
```
## Running Supabase locally
The Supabase CLI uses Docker containers to manage the local development stack. Follow the official guide to install and configure [Docker Desktop](https://docs.docker.com/desktop):
Alternately, you can use a different container tool that offers Docker compatible APIs.
* [Rancher Desktop](https://rancherdesktop.io/) (macOS, Windows, Linux)
* [Podman](https://podman.io/) (macOS, Windows, Linux)
* [OrbStack](https://orbstack.dev/) (macOS)
* [colima](https://github.com/abiosoft/colima) (macOS)
Inside the folder where you want to create your project, run:
```bash
supabase init
```
This will create a new `supabase` folder. It's safe to commit this folder to your version control system.
Now, to start the Supabase stack, run:
```bash
supabase start
```
This takes time on your first run because the CLI needs to download the Docker images to your local machine. The CLI includes the entire Supabase toolset, and a few additional images that are useful for local development (like a local SMTP server and a database diff tool).
## Access your project's services
Once all of the Supabase services are running, you'll see output containing your local Supabase credentials. It should look like this, with urls and keys that you'll use in your local project:
```
Started supabase local development setup.
╭──────────────────────────────────────╮
│ 🔧 Development Tools │
├─────────┬────────────────────────────┤
│ Studio │ http://127.0.0.1:54323 │
│ Mailpit │ http://127.0.0.1:54324 │
│ MCP │ http://127.0.0.1:54321/mcp │
╰─────────┴────────────────────────────╯
╭──────────────────────────────────────────────────────╮
│ 🌐 APIs │
├────────────────┬─────────────────────────────────────┤
│ Project URL │ http://127.0.0.1:54321 │
│ REST │ http://127.0.0.1:54321/rest/v1 │
│ GraphQL │ http://127.0.0.1:54321/graphql/v1 │
│ Edge Functions │ http://127.0.0.1:54321/functions/v1 │
╰────────────────┴─────────────────────────────────────╯
╭───────────────────────────────────────────────────────────────╮
│ ⛁ Database │
├─────┬─────────────────────────────────────────────────────────┤
│ URL │ postgresql://postgres:postgres@127.0.0.1:54322/postgres │
╰─────┴─────────────────────────────────────────────────────────╯
╭──────────────────────────────────────────────────────────────╮
│ 🔑 Authentication Keys │
├─────────────┬────────────────────────────────────────────────┤
│ Publishable │ sb_publishable_... │
│ Secret │ sb_secret_... │
╰─────────────┴────────────────────────────────────────────────╯
```
```sh
# Default URL:
http://localhost:54323
```
The local development environment includes Supabase Studio, a graphical interface for working with your database.
```sh
# Default URL:
postgresql://postgres:postgres@localhost:54322/postgres
```
The local Postgres instance can be accessed through [`psql`](https://www.postgresql.org/docs/current/app-psql.html) or any other Postgres client, such as [pgAdmin](https://www.pgadmin.org/). For example:
```bash
psql 'postgresql://postgres:postgres@localhost:54322/postgres'
```
To access the database from an edge function in your local Supabase setup, replace `localhost` with `host.docker.internal`.
```sh
# Default URL:
http://localhost:54321
```
If you are accessing these services without the client libraries, you may need to pass the client keys as an `Authorization` header. Learn more about [JWT headers](/docs/learn/auth-deep-dive/auth-deep-dive-jwts).
```sh
curl 'http://localhost:54321/rest/v1/' \
-H "apikey: sb_publishable_..."
http://localhost:54321/rest/v1/ # REST (PostgREST)
http://localhost:54321/realtime/v1/ # Realtime
http://localhost:54321/storage/v1/ # Storage
http://localhost:54321/auth/v1/ # Auth (GoTrue)
```
`sb_publishable_...` is the publishable key output when you run the command `supabase start`.
Local logs rely on the Supabase Analytics Server which accesses the docker logging driver by either volume mounting `/var/run/docker.sock` domain socket on Linux and macOS, or exposing `tcp://localhost:2375` daemon socket on Windows. These settings must be configured manually after [installing](/docs/guides/cli/getting-started#installing-the-supabase-cli) the Supabase CLI.
For advanced logs analysis using the Logs Explorer, it is advised to use the BigQuery backend instead of the default Postgres backend. Read about the steps [here](/docs/reference/self-hosting-analytics/introduction#bigquery).
All logs will be stored in the local database under the `_analytics` schema.
## Stopping local services
When you are finished working on your Supabase project, you can stop the stack (without resetting your local database):
```bash
supabase stop
```
## Telemetry
The Supabase CLI collects telemetry data about general usage. Participating in this program is optional, and you can opt out at any time.
### How to opt out
You can disable telemetry by running:
```bash
supabase telemetry disable
```
You can check the current status and re-enable with:
```bash
supabase telemetry status
supabase telemetry enable
```
You can also opt out using the `SUPABASE_TELEMETRY_DISABLED=1` environment variable. The broader `DO_NOT_TRACK=1` convention is also respected.
## Learn more
* [CLI configuration](/docs/guides/local-development/cli/config)
* [CLI reference](/docs/reference/cli)
# Testing and linting
Using the CLI to test your Supabase project.
The Supabase CLI provides a set of tools to help you test and lint your Postgres database and Edge\` Functions.
## Testing your database
The Supabase CLI provides Postgres linting using the `supabase test db` command.
{/* prettier-ignore */}
```markdown
supabase test db --help
Tests local database with pgTAP
Usage:
supabase test db [flags]
```
This is powered by the [pgTAP](/docs/guides/database/extensions/pgtap) extension. You can find a full guide to writing and running tests in the [Testing your database](/docs/guides/database/testing) section.
### Test helpers
Our friends at [Basejump](https://usebasejump.com/) have created a useful set of Database [Test Helpers](https://github.com/usebasejump/supabase-test-helpers), with an accompanying [blog post](https://usebasejump.com/blog/testing-on-supabase-with-pgtap).
### Running database tests in CI
Use our GitHub Action to [automate your database tests](/docs/guides/deployment/ci/testing).
## Testing your Edge Functions
Edge Functions are powered by Deno, which provides a [native set of testing tools](https://deno.land/manual@v1.35.3/basics/testing). We extend this functionality in the Supabase CLI. You can find a detailed guide in the [Edge Functions section](/docs/guides/functions/unit-test).
## Testing Auth emails
The Supabase CLI uses [Mailpit](https://github.com/axllent/mailpit) to capture emails sent from your local machine. This is useful for testing emails sent from Supabase Auth.
### Accessing Mailpit
By default, Mailpit is available at [localhost:54324](http://localhost:54324) when you run `supabase start`. Open this URL in your browser to view the emails.
### Going into production
The "default" email provided by Supabase is only for development purposes. It is [heavily restricted](/docs/guides/platform/going-into-prod#auth-rate-limits) to ensure that it is not used for spam. Before going into production, you must configure your own email provider. This is as simple as enabling a new SMTP credentials in your [project settings](/dashboard/project/_/auth/smtp).
## Linting your database
The Supabase CLI provides Postgres linting using the `supabase db lint` command:
{/* prettier-ignore */}
```markdown
supabase db lint --help
Checks local database for typing error
Usage:
supabase db lint [flags]
Flags:
--level [ warning | error ] Error level to emit. (default warning)
--linked Lints the linked project for schema errors.
-s, --schema strings List of schema to include. (default all)
```
This is powered by [plpgsql\_check](https://github.com/okbob/plpgsql_check), which leverages the internal Postgres parser/evaluator so you see any errors that would occur at runtime. It provides the following features:
* validates you are using the correct types for function parameters
* identifies unused variables and function arguments
* detection of dead code (any code after an `RETURN` command)
* detection of missing `RETURN` commands with your Postgres function
* identifies unwanted hidden casts, which can be a performance issue
* checks `EXECUTE` statements against SQL injection vulnerability
Check the Reference Docs for [more information](/docs/reference/cli/supabase-db-lint).
# Build a Supabase Integration
This guide steps through building a Supabase Integration using OAuth2 and the management API, allowing you to manage users' organizations and projects on their behalf.
Using OAuth2.0 you can retrieve an access and refresh token that grant your application full access to the [Management API](/docs/reference/api/introduction) on behalf of the user.
## Create an OAuth app
1. In your organization's settings, navigate to the [**OAuth Apps**](/dashboard/org/_/apps) tab.
2. In the upper-right section of the page, click **Add application**.
3. Fill in the required details and click **Confirm**.
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
## Show a "Connect Supabase" button
In your user interface, add a "Connect Supabase" button to kick off the OAuth flow. Follow the design guidelines outlined in our [brand assets](/brand-assets).
## Implementing the OAuth 2.0 flow
Once you've published your OAuth App on Supabase, you can use the OAuth 2.0 protocol get authorization from Supabase users to manage their organizations and projects.
You can use your preferred OAuth2 client or follow the steps below. You can see an example implementation in TypeScript using Supabase Edge Functions [on our GitHub](https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/connect-supabase).
### Redirecting to the authorize URL
Within your app's UI, redirect the user to [`https://api.supabase.com/v1/oauth/authorize`](https://api.supabase.com/api/v1#tag/oauth/GET/v1/oauth/authorize). Make sure to include all required query parameters such as:
* `client_id`: Your client id from the app creation above.
* `redirect_uri`: The URL where Supabase will redirect the user to after providing consent.
* `response_type`: Set this to `code`.
* `state`: Information about the state of your app. Note that `redirect_uri` and `state` together cannot exceed 4kB in size.
* `organization_slug`: The slug of the organization you want to connect to. This is optional, but if provided, it will pre-select the organization for the user.
* \[Recommended] PKCE: We strongly recommend using the PKCE flow for increased security. Generate a random value before taking the user to the authorize endpoint. This value is called code verifier. Hash it with SHA256 and include it as the `code_challenge` parameter, while setting `code_challenge_method` to `S256`. In the next step, you would need to provide the code verifier to get the first access and refresh token.
* \[Deprecated] `scope`: Scopes are configured when you create your OAuth app. Read the [docs](/docs/guides/platform/oauth-apps/oauth-scopes) for more details.
```ts
router.get('/connect-supabase/login', async (ctx) => {
// Construct the URL for the authorization redirect and get a PKCE codeVerifier.
const { uri, codeVerifier } = await oauth2Client.code.getAuthorizationUri()
console.log(uri.toString())
// console.log: https://api.supabase.com/v1/oauth/authorize?response_type=code&client_id=7673bde9-be72-4d75-bd5e-b0dba2c49b38&redirect_uri=http%3A%2F%2Flocalhost%3A54321%2Ffunctions%2Fv1%2Fconnect-supabase%2Foauth2%2Fcallback&scope=all&code_challenge=jk06R69S1bH9dD4td8mS5kAEFmEbMP5P0YrmGNAUVE0&code_challenge_method=S256
// Store the codeVerifier in the user session (cookie).
ctx.state.session.flash('codeVerifier', codeVerifier)
// Redirect the user to the authorization endpoint.
ctx.response.redirect(uri)
})
```
Find the full example on [GitHub](https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/connect-supabase).
### Handling the callback
Once the user consents to providing API access to your OAuth App, Supabase will redirect the user to the `redirect_uri` provided in the previous step. The URL will contain these query parameters:
* `code`: An authorization code you should exchange with Supabase to get the access and refresh token.
* `state`: The value you provided in the previous step, to help you associate the request with the user. The `state` property returned here should be compared to the `state` you sent previously.
Exchange the authorization code for an access and refresh token by calling [`POST https://api.supabase.com/v1/oauth/token`](https://api.supabase.com/api/v1#tag/oauth/POST/v1/oauth/token) with the following query parameters as content-type `application/x-www-form-urlencoded`:
* `grant_type`: The value `authorization_code`.
* `code`: The `code` returned in the previous step.
* `redirect_uri`: This must be exactly the same URL used in the first step.
* (Recommended) `code_verifier`: If you used the PKCE flow in the first step, include the code verifier as `code_verifier`.
If your application need to support dynamically generated Redirect URLs, check out [Handling Dynamic Redirect URLs](#handling-dynamic-redirect-urls) section below.
As per OAuth2 spec, provide the client id and client secret as basic auth header:
* `client_id`: The unique client ID identifying your OAuth App.
* `client_secret`: The secret that authenticates your OAuth App to Supabase.
```ts
router.get('/connect-supabase/oauth2/callback', async (ctx) => {
// Make sure the codeVerifier is present for the user's session.
const codeVerifier = ctx.state.session.get('codeVerifier') as string
if (!codeVerifier) throw new Error('No codeVerifier!')
// Exchange the authorization code for an access token.
const tokens = await fetch(config.tokenUri, {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
Accept: 'application/json',
Authorization: `Basic ${btoa(`${config.clientId}:${config.clientSecret}`)}`,
},
body: new URLSearchParams({
grant_type: 'authorization_code',
code: ctx.request.url.searchParams.get('code') || '',
redirect_uri: config.redirectUri,
code_verifier: codeVerifier,
}),
}).then((res) => res.json())
console.log('tokens', tokens)
// Store the tokens in your DB for future use.
ctx.response.body = 'Success'
})
```
Find the full example on [GitHub](https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/connect-supabase).
## Refreshing an access token
You can use the [`POST /v1/oauth/token`](https://api.supabase.com/api/v1#tag/oauth/POST/v1/oauth/token) endpoint to refresh an access token using the refresh token returned at the end of the previous section.
If the user has revoked access to your application, you will not be able to refresh a token. Furthermore, access tokens will stop working. Make sure you handle HTTP Unauthorized errors when calling any Supabase API.
## Calling the Management API
Refer to [the Management API reference](/docs/reference/api/introduction#authentication) to learn more about authentication with the Management API.
### Use the JavaScript (TypeScript) SDK
For convenience, when working with JavaScript/TypeScript, you can use the [supabase-management-js](https://github.com/supabase-community/supabase-management-js#supabase-management-js) library.
```ts
import { SupabaseManagementAPI } from 'supabase-management-js'
const client = new SupabaseManagementAPI({ accessToken: '' })
```
## Integration recommendations
There are a couple common patterns you can consider adding to your integration that can facilitate a great user experience.
### Store API keys in env variables
Some integrations, e.g. like [Cloudflare Workers](/partners/integrations/cloudflare-workers) provide convenient access to the API URL and API keys to allow user to speed up development.
Using the management API, you can retrieve a project's API credentials using the [`/projects/{ref}/api-keys` endpoint](https://api.supabase.com/api/v1#/projects/getProjectApiKeys).
### Pre-fill database connection details
If your integration directly connects to the project's database, you can pref-fill the Postgres connection details for the user, it follows this schema:
```
postgresql://postgres:[DB-PASSWORD]@db.[REF].supabase.co:5432/postgres
```
Note that you cannot retrieve the database password via the management API, so for the user's existing projects you will need to collect their database password in your UI.
### Create new projects
Use the [`/v1/projects` endpoint](https://api.supabase.com/api/v1#/projects/createProject) to create a new project.
When creating a new project, you can either ask the user to provide a database password, or you can generate a secure password for them. In any case, make sure to securely store the database password on your end which will allow you to construct the Postgres URI.
### Configure custom Auth SMTP
You can configure the user's [custom SMTP settings](/docs/guides/auth/auth-smtp) using the [`/config/auth` endpoint](https://api.supabase.com/api/v1#/projects%20config/updateV1AuthConfig).
### Handling dynamic redirect URLs
To handle multiple, dynamically generated redirect URLs within the same OAuth app, you can leverage the `state` query parameter. When starting the OAuth process, include the desired, encoded redirect URL in the `state` parameter.
Once authorization is complete, we will sends the `state` value back to your app. You can then verify its integrity and extract the correct redirect URL, decoding it and redirecting the user to the correct URL.
## Current limitations
Only some features are available until we roll out fine-grained access control. If you need full database access, you will need to prompt the user for their database password.
# Supabase Partner Integration Guide
Integrate Supabase with your platform or product.
This guide assumes you have already followed [the Build a Supabase Integration guide](/docs/guides/integrations/build-a-supabase-oauth-integration) and have a working OAuth client.
When a Supabase user clicks the **Install Integration** button in the Dashboard, they are redirected to your system to begin the OAuth flow. You can implement this redirect in one of two ways:
* **[Simple redirect](#method-1-simple-redirect)**: Easier to build, but your system cannot verify that the incoming user was sent by Supabase.
* **[Signed redirect](#method-2-signed-redirect)**: More work to build, but cryptographically verifies that the redirect originated from Supabase. **Recommended for production integrations.**
Pick the method that fits your security requirements, then follow the matching section below.
## Method 1: Simple redirect
In this method, you implement a single `GET` endpoint. Supabase redirects the user to this endpoint when they click **Install Integration**, and your endpoint kicks off the OAuth flow.
>Browser: Clicks "Install Integration"
Browser->>Partner: "Connect to Partner" Click Handler Page
Partner->>Browser: Redirect to Supabase Authorization Page
Browser->>Supabase: Request Authorization
Supabase->>Browser: Redirect to Consent Screen
Browser->>User: Display Consent Screen
User->>Browser: Gives Consent
Browser->>Supabase: Submit User Consent
Supabase->>Browser: Redirect to Partner With Authorization Code
Browser->>Partner: Submit Authorization Code
Partner->>Supabase: Exchange Authorization Code for Token
Supabase->>Partner: Return Token
Partner->>Supabase: Request Management API Resources
Supabase->>Partner: Return Resources
Partner->>Browser: Ok 200, OAuth Flow Complete
Browser->>User: Display "Integration Installed" Message`}
/>
### Step 1: Implement the redirect endpoint
Expose a `GET` endpoint at any URL you control:
```
GET https:///?project_id=&organization_slug=
```
Supabase will append the following query parameters to the URL when redirecting:
| Param | Description |
| ------------------- | ---------------------------------------------------------------------------------------------- |
| `project_id` | Supabase project ref of the project where the user clicked the **Install Integration** button. |
| `organization_slug` | Supabase organization slug where the user clicked the **Install Integration** button. |
Save these parameters in your system. You can use them to fetch project or organization details, or to pre-select a project or organization in your UI once the OAuth flow is complete.
Your endpoint may ask the user to sign up, sign in, or perform other setup tasks on your website. Once those are complete, immediately [redirect to the Supabase authorization URL](/docs/guides/integrations/build-a-supabase-oauth-integration#redirecting-to-the-authorize-url) without further user interaction. This starts the OAuth flow.
### Step 2: Share your endpoint with Supabase
Send Supabase the URL of your endpoint so we can configure the **Install Integration** button to redirect there.
## Method 2: Signed redirect
In this method, Supabase signs a JWT before redirecting the user. You verify the signature, generate a one-time redirect record, and return its URL to Supabase. Supabase then redirects the user to that URL. This guarantees that any redirect your system handles originated from Supabase.
You will implement two endpoints:
1. A `POST` endpoint that validates the signed JWT and returns a unique redirect URL.
2. A `GET` endpoint that handles the user once they are redirected to that URL.
>Browser: Clicks "Install Integration"
Browser->>Supabase: Request Redirect URL Generation
Supabase->>Partner: Send Signed JWT
Partner->>Partner: Validate JWT
Partner->>Partner: Generate Unique Redirect URL
Partner->>Supabase: Return Redirect URL
Supabase->>Browser: Redirect to the Redirect URL
Browser->>Partner: Visit Redirect URL
Partner->>Partner: Validate Redirect Record
Partner->>Browser: Optional User Actions
Browser->>User: User Performs Optional Actions
User->>Browser: User Optional Actions Complete
Browser->>Partner: User Optional Actions Complete
Partner->>Browser: Redirect to Supabase Authorization Page
Browser->>Supabase: Request Authorization
Supabase->>Browser: Redirect to Consent Screen
Browser->>User: Display Consent Screen
User->>Browser: Gives Consent
Browser->>Supabase: Submit User Consent
Supabase->>Browser: Redirect to Partner With Authorization Code
Browser->>Partner: Submit Authorization Code
Partner->>Supabase: Exchange Authorization Code for Token
Supabase->>Partner: Return Token
Partner->>Supabase: Request Management API Resources
Supabase->>Partner: Return Resources
Partner->>Browser: Ok 200, OAuth Flow Complete
Browser->>User: Display "Integration Installed" Message`}
/>
### Step 1: Exchange public keys with Supabase
Supabase generates two key-pairs, one for staging, one for production, and shares the public keys with you. Save both public keys and their key IDs in your system. The keys are PEM-encoded EC P-256.
Example:
```
===============Staging==================
Key ID: pik_3038669348a3ea75dbaf0655
Public Key:
-----BEGIN PUBLIC KEY-----
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEnj3NmwrLPPH/3isvpS601ndQP9Mk
zqppdLDV9YfmoF4wavTyb9UTVE5pJ0fukpo5aOoNb4fBZgESsedIUoEn8Q==
-----END PUBLIC KEY-----
==============Production================
Key ID: pik_89e80ddbca9df41b97e28986
Public Key:
-----BEGIN PUBLIC KEY-----
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEWCGhwtFWn4jpWZNeyZpTlaAdq/tD
/yBaN0gFPpS8LTFiCPFgnWKbVe3RfExXh7bEhcrEUdWycmYvwrNklWWHRA==
-----END PUBLIC KEY-----
```
Look up the correct public key by the `kid` field in the JWT header.
Storing keys by ID enables zero-downtime key rotation. When Supabase rotates keys, we share new key-pairs and start signing JWTs with the new key ID. Your system picks the correct key based on `kid` without any code changes.
In future, we plan to publish keys at a `.../.well-known/jwks.json` URL and fully automate key rotation. For now this is done manually.
### Step 2: Implement the redirect record endpoint
This endpoint receives the signed JWT from Supabase and returns a one-time redirect URL.
Host the endpoint at any URL and path you control. Do not require authentication on this endpoint, but apply rate limiting to prevent abuse.
```
POST https:///
Content-Type: application/json
```
#### Request body
```json
{
"token": ""
}
```
#### JWT fields
The token is a JWT signed with the ES256 private key.
**Protected header (JOSE header)**
| Field | Required | Description |
| ----- | -------- | ---------------------------------------------------------------------------------------------------------- |
| `alg` | Yes | Always `ES256` — the only signing algorithm currently supported. |
| `kid` | Yes | The key ID identifying the key pair. Use this to pick the correct public key when verifying the signature. |
**Payload (claims)**
| Claim | Required | Description |
| ------------------- | -------- | ----------------------------------------------------------------------------------------------------------------- |
| `iss` | Yes | Always `supabase`. |
| `aud` | Yes | A unique string identifying the audience of this JWT. Usually a URL. |
| `iat` | Yes | Issued-at timestamp (seconds since epoch). |
| `exp` | Yes | Expiry timestamp — at most 5 minutes after `iat`. |
| `organization_slug` | No | The Supabase organization the user is connecting from. Use to pre-select the org during the OAuth consent screen. |
| `project_id` | No | The Supabase project ref the user wants to connect. Use to pre-select a Supabase project in your UI. |
**Signature**
The header and claims are signed with the EC P-256 private key.
#### Validation
When you receive a request:
1. Read the `kid` field from the JWT header and look up the matching public key.
2. Verify the JWT signature with that public key.
3. Verify that `alg` is `ES256`.
4. Verify that `iss` is `supabase`.
5. Verify that `aud` matches the value you agreed with Supabase.
6. Verify that the current time is between `iat` and `exp`.
If any check fails, return `401 Unauthorized`.
If validation succeeds, generate a UUID to identify this redirect record (also called an integration record), save it in your system with an expiry (typically 1 hour), and return it in the response. The expiry prevents records from accumulating and limits the window in which a leaked record can be used.
#### Response body
```json
{
"integrationId": "",
"redirectUrl": "https:////",
"expiresAt": ""
}
```
| Field | Description |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------ |
| `integrationId` | A UUID uniquely identifying the redirect record. |
| `redirectUrl` | The URL the user will be redirected to. Must contain the `integrationId` somewhere in its path so you can retrieve the record on redirect. |
| `expiresAt` | The time when the redirect record expires (typically 1 hour from creation). The user must begin the flow before this time. |
### Step 3: Implement the redirect handler endpoint
This is the `GET` endpoint at the `redirectUrl` you returned in the previous step. The redirect record's UUID must be in its path.
When a user arrives at this endpoint:
1. Extract the redirect record UUID from the URL path.
2. Look it up in your system. If it doesn't exist or has expired, return `401 Unauthorized`.
3. Optionally, walk the user through any setup required on your side — for example, signing up, signing in, or configuring your system so the integration will work.
4. Redirect the user to the [Supabase authorization URL](/docs/guides/integrations/build-a-supabase-oauth-integration#redirecting-to-the-authorize-url) to start the OAuth flow.
If you need the user to perform setup steps on your site, design the experience as a wizard that ends by redirecting to the Supabase authorization URL. This minimizes the chance of users getting distracted, navigating elsewhere on your site, and abandoning the OAuth flow.
### Step 4: Share your details with Supabase
Send Supabase the following so we can configure the **Install Integration** button:
* The URL of your redirect record endpoint ([Step 2](#step-2-implement-the-redirect-record-endpoint)).
* The URL pattern of your redirect handler endpoint ([Step 3](#step-3-implement-the-redirect-handler-endpoint)).
* The `aud` claim value you want Supabase to send in the signed JWT.
Ask Supabase for the public keys and key IDs for the staging and production environments.
# Supabase for Platforms
Use Supabase as a platform for your own business and tools.
Supabase is a [Platform as a Service](https://en.wikipedia.org/wiki/Platform_as_a_service) (PaaS) that can be managed programmatically. You can use it to offer the key primitives to your own users, such as [Database](/docs/guides/database/overview), [Auth](/docs/guides/auth), [Edge Functions](/docs/guides/functions), [Storage](/docs/guides/storage), and [Realtime](/docs/guides/realtime). Supabase is commonly used as a platform by AI Builders and frameworks needing a backend.
This document will guide you on best practices when using Supabase for your own platform and assumes that Supabase projects are in a Supabase organization that you own. If you want to instead interact with projects that your users own, navigate to [OAuth integration](/docs/guides/integrations/build-a-supabase-oauth-integration) for more details.
## Overview
All features of Supabase can be managed through the [Management API](/docs/reference/api/introduction) or the [remote MCP Server](/docs/guides/getting-started/mcp).
## Launching projects
Management API endpoints:
* Create project: [`POST /v1/projects`](https://api.supabase.com/api/v1#tag/projects/post/v1/projects)
* Get smart region selection codes: [`GET /v1/projects/available-regions`](https://api.supabase.com/api/v1#tag/projects/get/v1/projects/available-regions)
* Check service health: [`GET /v1/projects/{ref}/health`](https://api.supabase.com/api/v1#tag/projects/get/v1/projects/\{ref}/health)
We recommend:
* **a *very* secure password for each database**. Do not reuse the same password across databases.
* **storing the encrypted version of the password**. Once you set the password during project creation, there is no way to programmatically change the password but you can do so manually in the Supabase Dashboard.
* **using smart region selection to ensure there's enough capacity**. The available smart region codes are `americas`, `emea`, and `apac` and you can make a request to [`GET /v1/projects/available-regions`](https://api.supabase.com/api/v1#tag/projects/get/v1/projects/available-regions) for region details.
* **using an appropriate instance size**. Scale to zero pricing only applies to Nano instances, make sure to not pass in a `desired_instance_size` when creating a project. >= Micro instances are not able to scale to zero.
* **make sure that the services are `ACTIVE_HEALTHY` after project creation**. After creating project, confirm the service that you want to make a request to has a status of `ACTIVE_HEALTHY` by polling [`GET /v1/projects/{ref}/health`](https://api.supabase.com/api/v1#tag/projects/get/v1/projects/\{ref}/health). For example, before making a request to set an Auth configuration confirm that the Auth service has a status of `ACTIVE_HEALTHY`.
```sh
curl https://api.supabase.com/v1/projects \
--request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer YOUR_SECRET_TOKEN" \
--data '{
"name": "Todo App",
"organization_slug": "aaaabbbbccccddddeeee",
"db_pass": "SUPER_SECURE_PASSWORD",
"region_selection": {
"type": "smartGroup",
"code": "americas"
},
"desired_instance_size": "micro"
}'
```
### Nano compute instance
Only select customers have access to scale to zero pricing on Nano instances. Submit this [form](/solutions/ai-builders#talk-to-partnerships-team) to get access.
### Recommended API keys
Management API endpoints:
* Get the API keys: [`GET /v1/projects/{ref}/api-keys`](https://api.supabase.com/api/v1#tag/secrets/get/v1/projects/\{ref}/api-keys)
* Enable the API keys: [`POST /v1/projects/{ref}/api-keys`](https://api.supabase.com/api/v1#tag/secrets/post/v1/projects/\{ref}/api-keys)
We are in the process of migrating away from our legacy API keys `anon` and `service_role` and towards API keys `publishable` and `secret`.
You can learn more by navigating to [Upcoming changes to Supabase API Keys #29260](https://github.com/orgs/supabase/discussions/29260).
Get the API keys by making a [`GET /v1/projects/{ref}/api-keys`](https://api.supabase.com/api/v1#tag/secrets/get/v1/projects/\{ref}/api-keys) request.
```sh
curl 'https://api.supabase.com/v1/projects/{ref}/api-keys?reveal=true' \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN'
```
If the response includes `"publishable"` and `"secret"` keys then you're all set and you should only use those from now on.
Otherwise, enable the API keys by making two [`POST /v1/projects/{ref}/api-keys`](https://api.supabase.com/api/v1#tag/secrets/post/v1/projects/\{ref}/api-keys) requests, one for `publishable` and another for `secret`.
```sh
curl 'https://api.supabase.com/v1/projects/{ref}/api-keys' \
--request POST \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--data '{
"type": "publishable",
"name": "default"
}'
```
```sh
curl 'https://api.supabase.com/v1/projects/{ref}/api-keys?reveal=true' \
--request POST \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--data '{
"type": "secret",
"name": "default",
"secret_jwt_template": {
"role": "service_role"
}
}'
```
## Changing compute sizes
Management API endpoint: [`PATCH /v1/projects/{ref}/billing/addons`](https://api.supabase.com/api/v1#tag/billing/patch/v1/projects/\{ref}/billing/addons)
You can upgrade and downgrade compute sizes by making requests to [`PATCH /v1/projects/{ref}/billing/addons`](https://api.supabase.com/api/v1#tag/billing/patch/v1/projects/\{ref}/billing/addons).
```sh
curl 'https://api.supabase.com/v1/projects/{ref}/billing/addons' \
--request PATCH \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--data '{
"addon_type": "compute_instance",
"addon_variant": "ci_small"
}'
```
## Configuration changes
Management API endpoints:
* Auth: [`PATCH /v1/projects/{ref}/config/auth`](https://api.supabase.com/api/v1#tag/auth/patch/v1/projects/\{ref}/config/auth)
* Data API (PostgREST): [`PATCH /v1/projects/{ref}/postgrest`](https://api.supabase.com/api/v1#tag/rest/patch/v1/projects/\{ref}/postgrest)
* Edge Functions:
* [`PATCH /v1/projects/{ref}/functions/{function_slug}`](https://api.supabase.com/api/v1#tag/edge-functions/patch/v1/projects/\{ref}/functions/\{function_slug})
* [`PUT /v1/projects/{ref}/functions`](https://api.supabase.com/api/v1#tag/edge-functions/put/v1/projects/\{ref}/functions)
* Storage: [`PATCH /v1/projects/{ref}/config/storage`](https://api.supabase.com/api/v1#tag/storage/patch/v1/projects/\{ref}/config/storage)
* Realtime: [`PATCH /v1/projects/{ref}/config/realtime`](https://api.supabase.com/api/v1#tag/realtime-config/patch/v1/projects/\{ref}/config/realtime)
You can manage the configuration of all services using the Management API.
## Development workflow
Supabase is a *stateful* service: we store data. If anything breaks in production, you can't "roll back" to a point in time because doing so might cause your users to lose any data that their production environment received since the last checkpoint.
Because of this, it's important that you adopt a development workflow on behalf of your users:
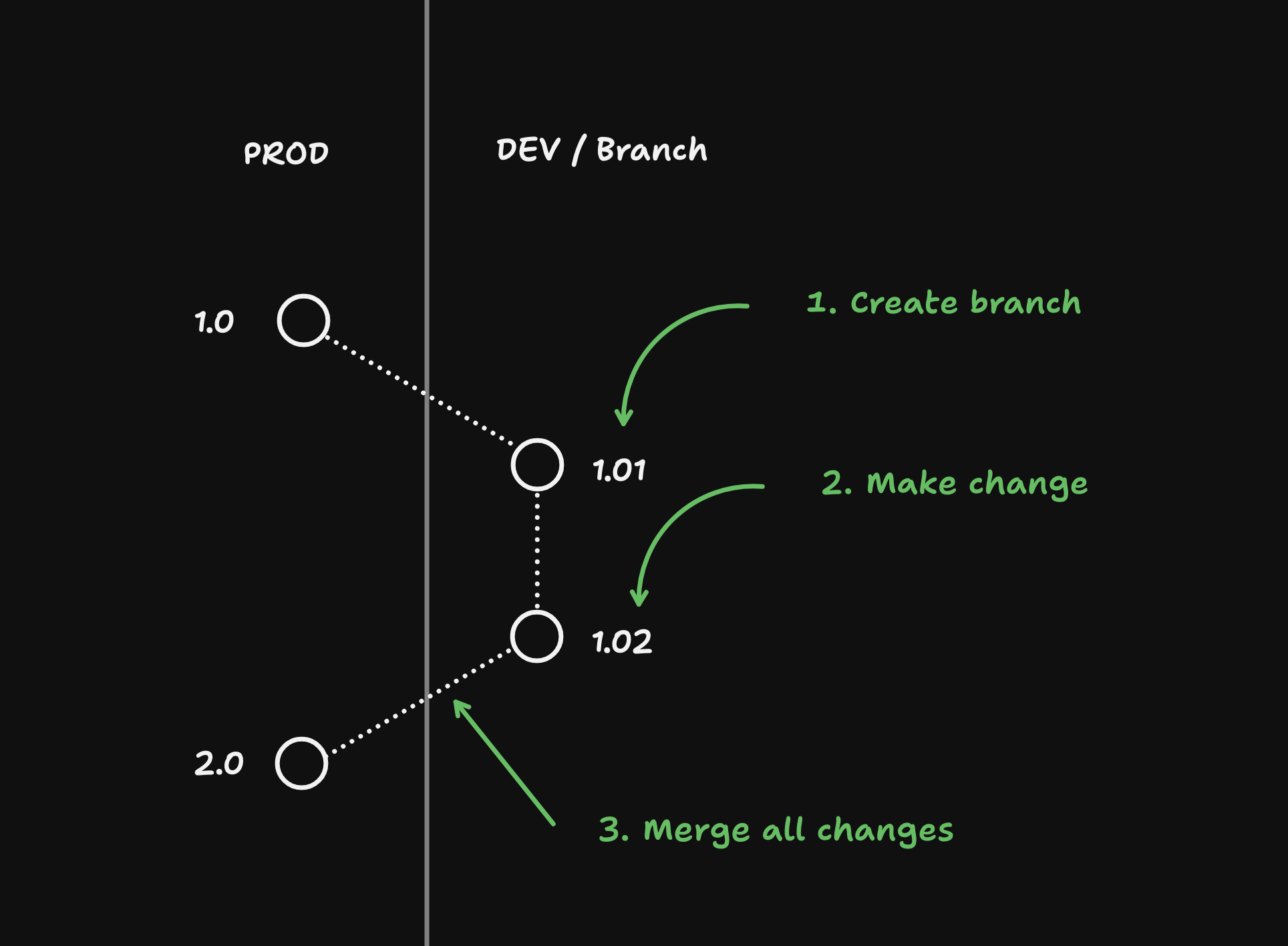
### Creating a `DEV` branch
Management API endpoint: [`POST /v1/projects/{ref}/branches`](https://api.supabase.com/api/v1#tag/environments/post/v1/projects/\{ref}/branches)
After launching a project, it's important that all changes happen on a development branch. Branches can be treated like ephemeral servers: if anything goes wrong you can either revert the changes or destroy the branch and create a new one based off of production.
```sh
curl 'https://api.supabase.com/v1/projects/{ref}/branches' \
--request POST \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--data '{
"branch_name": "DEV",
"secrets": {
"STRIPE_SECRET_KEY":"sk_test_123..."
"STRIPE_PUBLISHABLE_KEY":"pk_test_123..."
}
}'
```
### Make database changes
Management API endpoint: [`POST /v1/projects/{ref}/database/migrations`](https://api.supabase.com/api/v1#tag/database/post/v1/projects/\{ref}/database/migrations)
Only select customers have access to database migrations endpoint. Submit this [form](/solutions/ai-builders#talk-to-partnerships-team) to get access.
For this example we will create a todos table using the [`POST /v1/projects/{ref}/database/migrations`](https://api.supabase.com/api/v1#tag/database/post/v1/projects/\{ref}/database/migrations) endpoint.
```sql
create table public.todos (
id serial primary key,
task text not null
);
alter table public.todos
enable row level security;
```
This endpoint will automatically create a migration inside the `supabase_migrations` schema and run the migration. If the schema migration fails, the changes will be rolled back.
```sh
curl https://api.supabase.com/v1/projects/{ref}/database/migrations \
--request POST \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--header 'Content-Type: application/json' \
--data '{
"query": "create table public.todos (id serial primary key, task text not null); grant select on public.todos to anon; grant select, insert, update, delete on public.todos to authenticated; grant select, insert, update, delete on public.todos to service_role; alter table public.todos enable row level security;",
"name": "Create a todos table"
}'
```
### Create a restore point
Only select customers have access to restore points. Submit this [form](/solutions/ai-builders#talk-to-partnerships-team) to get access.
After every change you make to the database, it's a good idea to create a restore point. This will allow you to roll back the database if you decide to go in a different direction.
Beware that only database changes are captured when creating a restore point.
```sh
curl https://api.supabase.com/v1/projects/{ref}/database/backups/restore-point \
--request POST \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--header 'Content-Type: application/json' \
--data '{
"name": "abcdefg"
}'
```
### Reverting changes
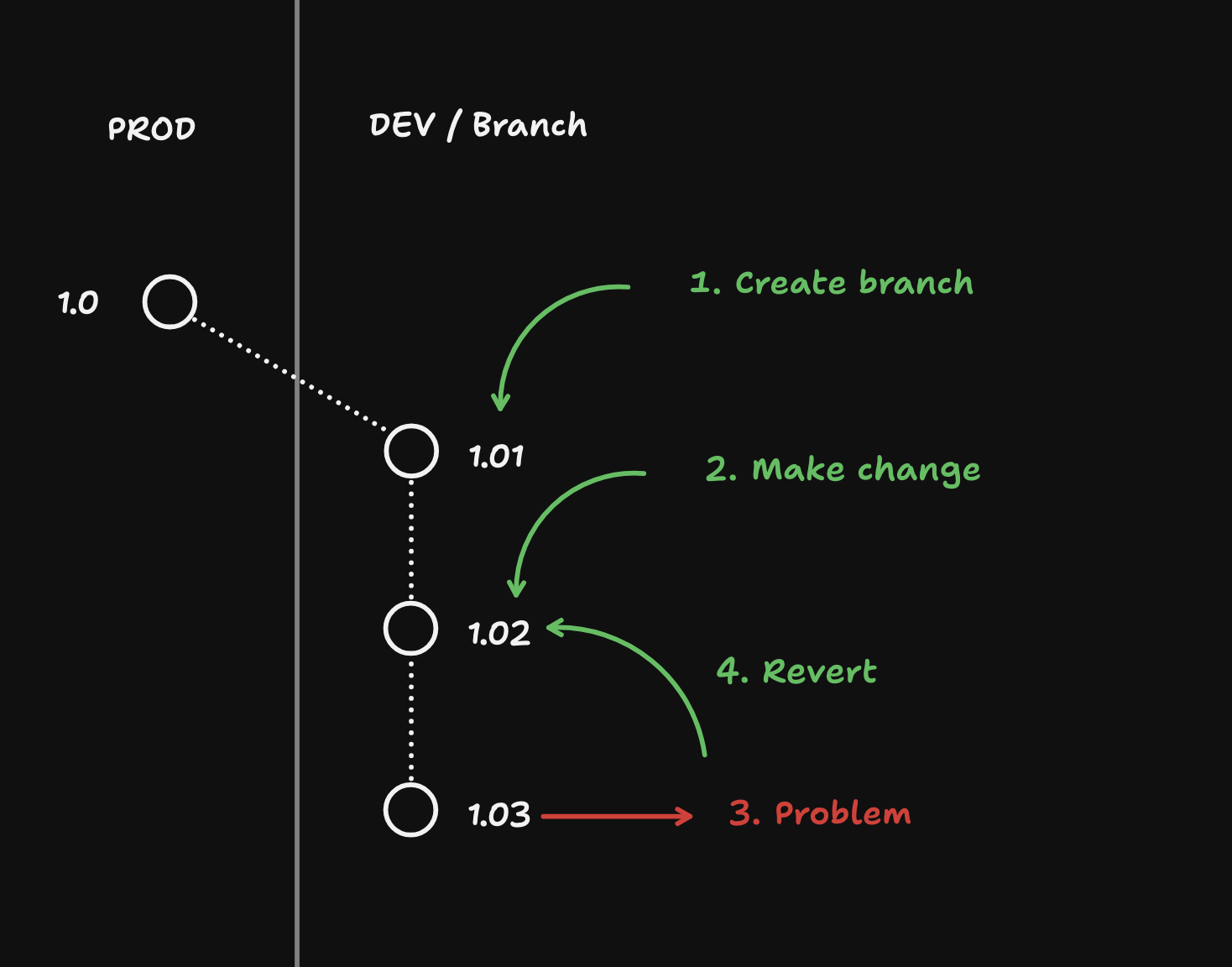
Only select customers have access to restore points. Submit this [form](/solutions/ai-builders#talk-to-partnerships-team) to get access.
After creating restore points, you are able to revert back to any restore point that you want.
```sh
curl https://api.supabase.com/v1/projects/{ref}/database/backups/undo \
--request POST \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--header 'Content-Type: application/json' \
--data '{
"name": "abcdefg"
}'
```
When you revert changes, you are undo-ing all database changes since the specified restore point, including:
* Schema changes
* Any seed data that you inserted
* Any test users who have signed up (and auth tokens for sign ins)
* Pointers to files in Supabase Storage.
It will not affect:
* Configuration changes
* Any secrets that have been added
* Storage objects themselves
* Any deployed Edge Functions
### Add seed data
It's important that the data in development branches is NOT production data, especially for non-developers who don't understand the implications of working with data. Security and side-effects (e.g. emailing all production users) are two reasons why this is important.
It's common in `DEV` branches to "seed" data. This is basically test data for users. Let's insert the following seed to our new todos table:
```sql
insert into todos (task)
values
('Task 1'),
('Task 2'),
('Task 3');
```
You can use the `POST /database/query` endpoint to add data:
```sh
curl https://api.supabase.com/v1/projects/{branch_ref}/database/query \
--request POST \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--header 'Content-Type: application/json' \
--data-binary @- <
Before transferring the project to your user's org, make sure to remove any custom configuration that you do not want your user's project to retain.
## Platform kit
Docs: [https://supabase.com/ui/docs/platform/platform-kit](https://supabase.com/ui/docs/platform/platform-kit)
We've created Platform Kit, a collection of UI components that interact with Management API, as a lightweight version of Supabase Dashboard that you can embed directly in your app so your users never have to leave in order to interact with the project.
## Debugging projects
Management API endpoint: [`GET /v1/projects/{ref}/analytics/endpoints/logs.all`](https://api.supabase.com/api/v1#tag/analytics/get/v1/projects/\{ref}/analytics/endpoints/logs.all)
When you need to debug a project, you can query the project's logs to see if there are any errors and address them accordingly.
```sh
curl 'https://api.supabase.com/v1/projects/{ref}/analytics/endpoints/logs.all' \
--get \
--header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
--data-urlencode 'sql=SELECT datetime(timestamp), status_code, path, event_message
FROM edge_logs
CROSS JOIN UNNEST(metadata) AS metadata
CROSS JOIN UNNEST(response) AS response
WHERE status_code >= 400
ORDER BY timestamp DESC
LIMIT 100' \
--data-urlencode 'iso_timestamp_start=2025-03-23T00:00:00Z' \
--data-urlencode 'iso_timestamp_end=2025-03-23T01:00:00Z'
```
# Supabase Marketplace
The Supabase Marketplace brings together all the tools you need to extend your Supabase project. This includes:
* [Experts](/partners/experts) - partners to help you build and support your Supabase project.
* [Integrations](/partners/integrations) - extend your projects with external Auth, Caching, Hosting, and Low-code tools.
## Build an integration
Supabase provides several integration points:
* The [Postgres connection](/docs/guides/database/connecting-to-postgres). Anything that works with Postgres also works with Supabase projects.
* The [Project REST API](/docs/guides/api#rest-api-overview) & client libraries.
* The [Project GraphQL API](/docs/guides/api#graphql-api-overview).
* The [Platform API](/docs/reference/api).
## List your integration
[Apply to the Partners program](/partners/integrations#become-a-partner) to list your integration in the Partners marketplace and in the Supabase docs.
Integrations are assessed on the following criteria:
* **Business viability**
While we welcome everyone to built an integration, we only list companies that are deemed to be long-term viable. This includes an official business registration and bank account, meaningful revenue, or Venture Capital backing. We require this criteria to ensure the health of the marketplace.
* **Compliance**
Integrations should not infringe on the Supabase brand/trademark. In short, you cannot use "Supabase" in the name. As the listing appears on the Supabase domain, we don't want to mislead developers into thinking that an integration is an official product.
* **Service Level Agreements**
All listings are required to have their own Terms and Conditions, Privacy Policy, and Acceptable Use Policy, and the company must have resources to meet their SLAs.
* **Maintainability**
All integrations are required to be maintained and functional with Supabase, and the company may be assessed on your ability to remain functional over a long time horizon.
# Vercel Marketplace
## Overview
The Vercel Marketplace is a feature that allows you to manage third-party resources, such as Supabase, directly from the Vercel platform. This integration offers a seamless experience with unified billing, streamlined authentication, and easy access management for your team.
When you create an organization and projects through Vercel Marketplace, they function just like those created directly within Supabase. However, the billing is handled through your Vercel account, and you can manage your resources directly from the Vercel dashboard or CLI. Additionally, environment variables are automatically synchronized, making them immediately available for your connected projects.
For more information, see [Introducing the Vercel Marketplace](https://vercel.com/blog/introducing-the-vercel-marketplace) blog post.
Vercel Marketplace is currently in Public Alpha. If you encounter any issues or have feature requests, [contact support](/dashboard/support/new).
## Quickstart
### Via template
Deploy a Next.js app with Supabase Vercel Storage now
Uses the Next.js Supabase Starter Template

### Via Vercel Marketplace
Details coming soon..
### Connecting to Supabase project
Supabase Projects created via Vercel Marketplace are automatically synchronized with connected Vercel projects. This synchronization includes setting essential environment variables, such as:
```
POSTGRES_URL
POSTGRES_PRISMA_URL
POSTGRES_URL_NON_POOLING
POSTGRES_USER
POSTGRES_HOST
POSTGRES_PASSWORD
POSTGRES_DATABASE
SUPABASE_SECRET_KEY
SUPABASE_PUBLISHABLE_KEY
SUPABASE_URL
SUPABASE_JWT_SECRET
NEXT_PUBLIC_SUPABASE_PUBLISHABLE_KEY
NEXT_PUBLIC_SUPABASE_URL
```
These variables ensure your applications can connect securely to the database and interact with Supabase APIs.
## Studio support
Accessing Supabase Studio is simple through the Vercel dashboard. You can open Supabase Studio from either the Integration installation page or the Vercel Storage page.
Depending on your entry point, you'll either land on the Supabase dashboard homepage or be redirected to the corresponding Supabase Project.
Supabase Studio provides tools such as:
* **SQL Editor:** Run SQL queries against your database.
* **Table Editor:** Create, edit, and delete tables and columns.
* **Log Explorer:** Inspect real-time logs for your database.
* **Postgres Upgrades:** Upgrade your Postgres instance to the latest version.
* **Compute Upgrades:** Scale the compute resources allocated to your database.
## Permissions
There is a direct one-to-one relationship between a Supabase Organization and a Vercel team. Installing the integration or launching your first Supabase Project through Vercel triggers the creation of a corresponding Supabase Organization if one doesn’t already exist.
When Vercel users interact with Supabase, they are automatically assigned Supabase accounts. New users get a Supabase account linked to their primary email, while existing users have their Vercel and Supabase accounts linked.
* The user who initiates the creation of a Vercel Storage database is assigned the `owner` role in the new Supabase organization.
* Subsequent users are assigned roles based on their Vercel role, such as `developer` for `member` and `owner` for `owner`.
Role management is handled directly in the Vercel dashboard, and changes are synchronized with Supabase.
Note: you can invite non-Vercel users to your Supabase Organization, but their permissions won't be synchronized with Vercel.
## Pricing
Pricing for databases created through Vercel Marketplace is identical to those created directly within Supabase. Detailed pricing information is available on the [Supabase pricing page](/pricing).
The [usage page](/dashboard/org/_/usage) tracks the usage of your Vercel databases, with this information sent to Vercel for billing, which appears on your Vercel invoice.
Note: Supabase Organization billing cycle is separate from Vercel's. Plan changes will reset the billing cycle to the day of the change, with the initial billing cycle starting the day you install the integration.
## Limitations
When using Vercel Marketplace, the following limitations apply:
* Projects can only be created via the Vercel dashboard.
* Organizations cannot be removed manually; they are removed only if you uninstall the Vercel Marketplace Integration.
* Owners cannot be added manually within the Supabase dashboard.
* Invoices and payments must be managed through the Vercel dashboard, not the Supabase dashboard.
* [Custom Domains](/docs/guides/platform/custom-domains) are not supported, and we always use the base `SUPABASE_URL` for the Vercel environment variables.
# Scopes for your OAuth App
Scopes let you specify the level of access your integration needs
Scopes are only available for OAuth apps. Check out [**our guide**](/docs/guides/platform/oauth-apps/build-a-supabase-integration) to learn how to build an OAuth app integration.
Scopes restrict access to the specific [Supabase Management API endpoints](/docs/reference/api/introduction) for OAuth tokens. All scopes can be specified as read and/or write.
Scopes are set when you [create an OAuth app](/docs/guides/platform/oauth-apps/build-a-supabase-integration#create-an-oauth-app) in the Supabase Dashboard.
You can update scopes of your OAuth app at any time, but existing OAuth app users will need to re-authorize your app via the [OAuth flow](/docs/guides/integrations/build-a-supabase-integration#implementing-the-oauth-20-flow) to apply the new scopes.
## Available scopes
| Name | Type | Description |
| ---------------- | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `Auth` | `Read` | Retrieve a project's auth configuration
Retrieve a project's SAML SSO providers |
| `Auth` | `Write` | Update a project's auth configuration
Create, update, or delete a project's SAML SSO providers |
| `Database` | `Read` | Retrieve the database configuration
Retrieve the pooler configuration
Retrieve SQL snippets
Check if the database is in read-only mode
Retrieve a database's SSL enforcement configuration
Retrieve a database's schema typescript types |
| `Database` | `Write` | Create a SQL query
Enable database webhooks on the project
Update the project's database configuration
Update the pooler configuration
Update a database's SSL enforcement configuration
Disable read-only mode for 15mins
Create a PITR backup for a database |
| `Domains` | `Read` | Retrieve the custom domains for a project
Retrieve the vanity subdomain configuration for a project |
| `Domains` | `Write` | Activate, initialize, reverify, or delete the custom domain for a project
Activate, delete or check the availability of a vanity subdomain for a project |
| `Edge Functions` | `Read` | Retrieve information about a project's edge functions |
| `Edge Functions` | `Write` | Create, update, or delete an edge function |
| `Environment` | `Read` | Retrieve branches in a project |
| `Environment` | `Write` | Create, update, or delete a branch |
| `Organizations` | `Read` | Retrieve an organization's metadata
Retrieve all members in an organization |
| `Organizations` | `Write` | N/A |
| `Projects` | `Read` | Retrieve a project's metadata
Check if a project's database is eligible for upgrade
Retrieve a project's network restrictions
Retrieve a project's network bans |
| `Projects` | `Write` | Create a project
Upgrade a project's database
Remove a project's network bans
Update a project's network restrictions |
| `Rest` | `Read` | Retrieve a project's PostgREST configuration |
| `Rest` | `Write` | Update a project's PostgREST configuration |
| `Secrets` | `Read` | Retrieve a project's API keys
Retrieve a project's secrets
Retrieve a project's pgsodium config |
| `Secrets` | `Write` | Create or update a project's secrets
Update a project's pgsodium configuration |
| `Storage` | `Read` | Retrieve a project's storage buckets. |
| | | |
# Understanding API keys
Supabase gives you fine-grained control over which application components are allowed to access your project through API keys.
In most cases, you can get the correct key from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true), but if you want a specific key, you can find all keys in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard:
API keys provide the first layer of authentication for data access. Auth then builds upon that. This chart covers the differences:
| Responsibility | Question | Answer |
| ---------------------------------- | ---------------------------------- | -------------------------------------------------- |
| API keys | **What** is accessing the project? | Web page, mobile app, server, Edge Function... |
| [Supabase Auth](/docs/guides/auth) | **Who** is accessing the project? | Monica, Jian Yang, Gavin, Dinesh, Laurie, Fiona... |
## Overview
An API key authenticates an application component to give it access to Supabase services. An application component might be a web page, a mobile app, or a server. The API key *does not* distinguish between users, only between applications.
There are 4 types of API keys that you can use with Supabase:
| Type | Format | Privileges | Availability | Use |
| ---------------------------------------------------------- | ---------------------------------------------------------------- | ---------- | --------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Publishable key | `sb_publishable_...` | Low | Platform | Safe to expose online: web page, mobile or desktop app, GitHub actions, CLIs, source code. |
| Secret keys | `sb_secret_...` | Elevated | Platform | **Only use in backend components of your app:** servers, already secured APIs (admin panels), [Edge Functions](/docs/guides/functions), microservices, etc. They provide *full access* to your project's data, bypassing [Row Level Security](/docs/guides/database/postgres/row-level-security). |
| `anon` | JWT (long lived) | Low | Platform, CLI | Legacy version of publishable keys. |
| `service_role` | JWT (long lived) | Elevated | Platform, CLI | Legacy version of secret keys. |
Supabase has changed the way keys work to improve project security and developer experience. You can read [the full announcement](https://github.com/orgs/supabase/discussions/29260).
`anon` and `service_role` keys are based on the project's JWT secret. They are generated when your project is created and you can only change them when you rotate the JWT secret. This can cause significant issues in production applications. **You should now use the `sb_publishable_xxx` and `sb_secret_xxx` keys instead**.
You can still find legacy keys in the **Legacy anon, service\_role API keys** tab of the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard:
## Publishable keys
Publishable keys identify the public components of your application. Public components run in environments where it is impossible to secure any secrets. These include:
* Web pages, where the key is bundled in source code.
* Mobile or desktop applications, where the key is bundled inside the compiled packages or executables.
* CLI, scripts, tools, or other pre-built executables.
* Other publicly available APIs that return the key without prior additional authorization.
These environments are always considered public because anyone can retrieve the key from the source code or build artifacts.
### Interaction with Supabase Auth
Using a publishable key does not mean that your user is anonymous. You can authenticate your application with the publishable key, while your user is authenticated (via Supabase Auth) with their personal JWT:
| Key | User logged in via Supabase Auth | Postgres role used for RLS, etc. |
| --------------- | -------------------------------- | -------------------------------- |
| Publishable key | No | `anon` |
| Publishable key | Yes | `authenticated` |
### Security considerations
Publishable keys are not intended to protect from the following, since key retrieval is always possible from a public component:
* Static or dynamic code analysis and reverse engineering attempts.
* Use of the Network inspector in the browser.
* Cross-site request forgery, cross-site scripting, phishing attacks.
* Man-in-the-middle attacks.
When using a publishable key, access to your project's data is guarded by Postgres via the built-in `anon` and `authenticated` roles. For full protection make sure:
* You have enabled Row Level Security on all tables.
* You regularly review your Row Level Security policies for permissions granted to the `anon` and `authenticated` roles.
* You do not modify the role's attributes without understanding the changes you are making.
Your project's [Security Advisor](/dashboard/project/_/advisors/security) constantly checks for common security problems with the built-in Postgres roles. Make sure you carefully review each finding before dismissing it.
## What secret keys allow access to
Unlike publishable keys, secret keys allow elevated access to your project's data. It is meant to be used only in secure, developer-controlled components of your application, such as:
* Servers that implement prior authorization themselves, such as Edge Functions, microservices, traditional or specialized web servers.
* Periodic jobs, queue processors, topic subscribers.
* Admin and back-office tools, with prior authorization checks only.
* Data processing pipelines, such as for analytics, reports, backups, or database synchronization.
Never expose your secret keys publicly. Your data is at risk. **Do not:**
* Add it to web pages, public documents, source code, bundle in executables or packages for mobile, desktop or CLI apps.
* Send over chat applications, email or SMS to your peers.
* Never use in a browser, even on `localhost`.
* Do not pass in URLs or query params, as these are often logged.
* Be careful passing them in request headers without prior log sanitization.
* Take extra care logging even potentially **invalid API keys**. Simple typos might reveal the real key in the future.
* Reveal, copy, use or manipulate on hardware devices without full disk encryption and which you do not directly own or control (such as public computers, friend's laptop, etc.)
Ensure you handle them with care and using [secure coding practices](https://owasp.org/www-project-secure-coding-practices-quick-reference-guide/stable-en/).
Secret keys authorize access to your project's data via the built-in `service_role` Postgres role. By design, this role has full access to your project's data. It also uses the [`BYPASSRLS` attribute](https://www.postgresql.org/docs/current/ddl-rowsecurity.html#:~:text=BYPASSRLS), skipping any and all Row Level Security policies you attach.
The secret key is an improvement over the old JWT-based `service_role` key, and we recommend using it where possible. It adds more checks to prevent misuse, specifically:
* You cannot use a secret key in the browser (matches on the `User-Agent` header) and it will always reply with HTTP 401 Unauthorized.
* You don't need to have any secret keys if you are not using them.
### Best practices for handling secret keys
Below are some starting guidelines on how to securely work with secret keys:
* Always work with secret keys on computers you fully own or control.
* Use secure & encrypted send tools to share API keys with others (often provided by good password managers), but prefer the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard instead.
* Prefer encrypting them when stored in files or environment variables.
* Do not add in source control, especially for CI scripts and tools. Prefer using the tool's native secrets capability instead.
* Prefer using a separate secret key for each separate backend component of your application, so that if one is found to be vulnerable or to have leaked the key you will only need to change it and not all.
* Even though a secret key will always return HTTP 401 Unauthorized error when used in a browser, it does not mean that attackers will not use it with other tools. Delete immediately!
* If you must include them in logs, log the first few random characters (but never more than 6).
* If you wish to log or store which valid API key was used, store it as a SHA256 hash.
### What to do if a secret key or `service_role` has been leaked or compromised?
Don't rush if this has happened, or you are suspecting it has. Make sure you have fully considered the situation and have remediated the root cause of the suspicion or vulnerability **first**. Consider using the [OWASP Risk Rating Methodology](https://owasp.org/www-community/OWASP_Risk_Rating_Methodology) as an easy way to identify the severity of the incident and to plan your next steps.
To rotate a secret key (`sb_secret_...`), use the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard to create a new secret API key, then replace it with the compromised key. Once all components are using the new key, delete the compromised one.
**Deleting a secret key is irreversible and once done it will be gone forever.**
If you are still using the JWT-based `service_role` key, replace the `service_role` key with a new secret key instead. Follow the guide from above as if you are rotating an existing secret key.
## Known limitations and compatibility differences
As the publishable and secret keys are no longer JWT-based, there are some known limitations and compatibility differences that you may need to plan for:
* You cannot send a publishable or secret key in the `Authorization: Bearer ...` header, except if the value exactly equals the `apikey` header. In this case, your request will be forwarded down to your project's database, but will be rejected as the value is not a JWT.
* Edge Functions **only support JWT verification** via the `anon` and `service_role` JWT-based API keys. You will need to use the `--no-verify-jwt` option when using publishable and secret keys. The Supabase platform does not verify the `apikey` header when using Edge Functions in this way. Implement your own `apikey`-header authorization logic inside the Edge Function code itself.
* Public Realtime connections are limited to 24 hours in duration, unless the connection is upgraded and further maintained with user-level authentication via Supabase Auth or a supported Third-Party Auth provider.
# Architecture
Supabase is open source. We choose open source tools which are scalable and make them simple to use.
Supabase is not a 1-to-1 mapping of Firebase. While we are building many of the features that Firebase offers, we are not going about it the same way:
our technological choices are quite different; everything we use is open source; and wherever possible, we use and support existing tools rather than developing from scratch.
Most notably, we use Postgres rather than a NoSQL store. This choice was deliberate. We believe that no other database offers the functionality required to compete with Firebase, while maintaining the scalability required to go beyond it.
## Choose your comfort level
Our goal at Supabase is to make *all* of Postgres easy to use. That doesn’t mean you have to use all of it. If you’re a Postgres veteran, you’ll probably love the tools that we offer. If you’ve never used Postgres before, then start smaller and grow into it. If you just want to treat Postgres like a simple table-store, that’s perfectly fine.
## Architecture
Each Supabase project consists of several tools:
### Postgres (database)
Postgres is the core of Supabase. We do not abstract the Postgres database—you can access it and use it with full privileges. We provide tools which make Postgres as easy to use as Firebase.
* Official Docs: [postgresql.org/docs](https://www.postgresql.org/docs/current/index.html)
* Source code: [github.com/postgres/postgres](https://github.com/postgres/postgres) (mirror)
{/* supa-mdx-lint-disable-next-line Rule004ExcludeWords */}
* License: [PostgreSQL License](https://www.postgresql.org/about/licence/)- Language: C
### Studio (dashboard)
An open source Dashboard for managing your database and services.
* Official Docs: [Supabase docs](/docs)
* Source code: [github.com/supabase/supabase](https://github.com/supabase/supabase/tree/master/apps/studio)
* License: [Apache 2](https://github.com/supabase/supabase/blob/master/LICENSE)
* Language: TypeScript
### GoTrue (Auth)
A JWT-based API for managing users and issuing access tokens. This integrates with Postgres's Row Level Security and the API servers.
* Official Docs: [Supabase Auth reference docs](/docs/reference/auth)
* Source code: [github.com/supabase/gotrue](https://github.com/supabase/gotrue)
* License: [MIT](https://github.com/supabase/gotrue/blob/master/LICENSE)
* Language: Go
### PostgREST (API)
A standalone web server that turns your Postgres database directly into a RESTful API.
We use this with our [`pg_graphql`](https://github.com/supabase/pg_graphql) extension to provide a GraphQL API.
* Official Docs: [postgrest.org](https://postgrest.org/)
* Source code: [github.com/PostgREST/postgrest](https://github.com/PostgREST/postgrest)
* License: [MIT](https://github.com/PostgREST/postgrest/blob/main/LICENSE)
* Language: Haskell
### Realtime (API & multiplayer)
A scalable WebSocket engine for managing user Presence, broadcasting messages, and streaming database changes.
* Official Docs: [Supabase Realtime docs](/docs/guides/realtime)
* Source code: [github.com/supabase/realtime](https://github.com/supabase/realtime)
* License: [Apache 2](https://github.com/supabase/realtime/blob/main/LICENSE)
* Language: Elixir
### Storage API (large file storage)
An S3-compatible object storage service that stores metadata in Postgres.
* Official Docs: [Supabase Storage reference docs](/docs/reference/storage)
* Source code: [github.com/supabase/storage-api](https://github.com/supabase/storage-api)
* License: [Apache 2.0](https://github.com/supabase/storage-api/blob/master/LICENSE)
* Language: Node.js / TypeScript
### Deno (Edge Functions)
A modern runtime for JavaScript and TypeScript.
* Official Docs: [Deno documentation](https://deno.land/)
* Source code: [Deno source code](https://github.com/denoland/deno)
* License: [MIT](https://github.com/denoland/deno/blob/main/LICENSE.md)
* Language: TypeScript / Rust
### `postgres-meta` (database management)
A RESTful API for managing your Postgres. Fetch tables, add roles, and run queries.
* Official Docs: [supabase.github.io/postgres-meta](https://supabase.github.io/postgres-meta/)
* Source code: [github.com/supabase/postgres-meta](https://github.com/supabase/postgres-meta)
* License: [Apache 2.0](https://github.com/supabase/postgres-meta/blob/master/LICENSE)
* Language: Node.js / TypeScript
### Supavisor
A cloud-native, multi-tenant Postgres connection pooler.
* Official Docs: [Supavisor GitHub Pages](https://supabase.github.io/supavisor/)
* Source code: [`supabase/supavisor`](https://github.com/supabase/supavisor)
* License: [Apache 2.0](https://github.com/supabase/supavisor/blob/main/LICENSE)
* Language: Elixir
### Kong (API gateway)
A cloud-native API gateway, built on top of NGINX.
* Official Docs: [docs.konghq.com](https://docs.konghq.com/)
* Source code: [github.com/kong/kong](https://github.com/kong/kong)
* License: [Apache 2.0](https://github.com/Kong/kong/blob/master/LICENSE)
* Language: Lua
## Product principles
It is our goal to provide an architecture that any large-scale company would design for themselves,
and then provide tooling around that architecture that is easy-to-use for indie-developers and small teams.
We use a series of principles to ensure that scalability and usability are never mutually exclusive:
### Everything works in isolation
Each system must work as a standalone tool with as few moving parts as possible.
The litmus test for this is: "Can a user run this product with nothing but a Postgres database?"
### Everything is integrated
Supabase is composable. Even though every product works in isolation, each product on the platform needs to 10x the other products.
For integration, each tool should expose an API and Webhooks.
### Everything is extensible
We're deliberate about adding a new tool, and prefer instead to extend an existing one.
This is the opposite of many cloud providers whose product offering expands into niche use-cases. We provide *primitives* for developers, which allow them to achieve any goal.
Less, but better.
### Everything is portable
To avoid lock-in, we make it easy to migrate in and out. Our cloud offering is compatible with our self-hosted product.
We use existing standards to increase portability (like `pg_dump` and CSV files). If a new standard emerges which competes with a "Supabase" approach, we will deprecate the approach in favor of the standard.
This forces us to compete on user experience. We aim to be the best Postgres hosting service.
### Play the long game
We sacrifice short-term wins for long-term gains. For example, it is tempting to run a fork of Postgres with additional functionality which only our customers need.
Instead, we prefer to support efforts to upstream missing functionality so that the entire community benefits. This has the additional benefit of ensuring portability and longevity.
### Build for developers
"Developers" are a specific profile of user: they are *builders*.
When assessing impact as a function of effort, developers have a large efficiency due to the type of products and systems they can build.
As the profile of a developer changes over time, Supabase will continue to evolve the product to fit this evolving profile.
### Support existing tools
Supabase supports existing tools and communities wherever possible. Supabase is more like a "community of communities" - each tool typically has its own community which we work with.
Open source is something we approach [collaboratively](/blog/supabase-series-b#giving-back): we employ maintainers, sponsor projects, invest in businesses, and develop our own open source tools.
# Features
This is a non-exhaustive list of features that Supabase provides for every project.
## Database
### Postgres database
Every project is a full Postgres database. [Docs](/docs/guides/database).
### Vector database
Store vector embeddings right next to the rest of your data. [Docs](/docs/guides/ai).
### Auto-generated REST API via PostgREST
RESTful APIs are auto-generated from your database, without a single line of code. [Docs](/docs/guides/api#rest-api-overview).
### Auto-generated GraphQL API via pg\_graphql
Fast GraphQL APIs using our custom Postgres GraphQL extension. [Docs](/docs/guides/graphql/api).
### Database webhooks
Send database changes to any external service using Webhooks. [Docs](/docs/guides/database/webhooks).
### Secrets and encryption
Encrypt sensitive data and store secrets using our Postgres extension, Supabase Vault. [Docs](/docs/guides/database/vault).
### Replication
Automatically replicate your database to external destinations like data warehouses and analytics platforms. Read [the external replication documentation](/docs/guides/database/replication/external-replication-setup) for more details.
## Platform
### Database backups
Projects are backed up daily with the option to upgrade to Point in Time recovery. [Docs](/docs/guides/platform/backups).
### Custom domains
White-label the Supabase APIs to create a branded experience for your users. [Docs](/docs/guides/platform/custom-domains).
### Network restrictions
Restrict IP ranges that can connect to your database. [Docs](/docs/guides/platform/network-restrictions).
### SSL enforcement
Enforce Postgres clients to connect via SSL. [Docs](/docs/guides/platform/ssl-enforcement).
### Branching
Use Supabase Branches to test and preview changes. [Docs](/docs/guides/platform/branching).
### Terraform provider
Manage Supabase infrastructure via Terraform, an Infrastructure as Code tool. [Docs](/docs/guides/platform/terraform).
### Read replicas
Deploy read-only databases across multiple regions, for lower latency and better resource management. [Docs](/docs/guides/platform/read-replicas).
### Log drains
Export Supabase logs to 3rd party providers and external tooling. [Docs](/docs/guides/platform/log-drains).
## Studio
### Studio Single Sign-On
Login to the Supabase dashboard via SSO. [Docs](/docs/guides/platform/sso).
## Realtime
### Postgres changes
Receive your database changes through WebSockets. [Docs](/docs/guides/realtime/postgres-changes).
### Broadcast
Send messages between connected users through WebSockets. [Docs](/docs/guides/realtime/broadcast).
### Presence
Synchronize shared state across your users, including online status and typing indicators. [Docs](/docs/guides/realtime/presence).
## Auth
### Email login
Build email logins for your application or website. [Docs](/docs/guides/auth/auth-email).
### Social login
Provide social logins - everything from Apple, to GitHub, to Slack. [Docs](/docs/guides/auth/social-login).
### Phone logins
Provide phone logins using a third-party SMS provider. [Docs](/docs/guides/auth/phone-login).
### Passwordless login
Build passwordless logins via magic links for your application or website. [Docs](/docs/guides/auth/auth-magic-link).
### Authorization via Row Level Security
Control the data each user can access with Postgres Policies. [Docs](/docs/guides/database/postgres/row-level-security).
### CAPTCHA protection
Add CAPTCHA to your sign-in, sign-up, and password reset forms. [Docs](/docs/guides/auth/auth-captcha).
### Server-Side Auth
Helpers for implementing user authentication in popular server-side languages and frameworks like Next.js, SvelteKit and Remix. [Docs](/docs/guides/auth/server-side).
## Storage
### File storage
Supabase Storage makes it simple to store and serve files. [Docs](/docs/guides/storage).
### Content Delivery Network
Cache large files using the Supabase CDN. [Docs](/docs/guides/storage/cdn/fundamentals).
### Smart Content Delivery Network
Automatically revalidate assets at the edge via the Smart CDN. [Docs](/docs/guides/storage/cdn/smart-cdn).
### Image transformations
Transform images on the fly. [Docs](/docs/guides/storage/serving/image-transformations).
### Resumable uploads
Upload large files using resumable uploads. [Docs](/docs/guides/storage/uploads/resumable-uploads).
### S3 compatibility
Interact with Storage from tool which supports the S3 protocol. [Docs](/docs/guides/storage/s3/compatibility).
## Edge Functions
### Deno Edge Functions
Globally distributed TypeScript functions to execute custom business logic. [Docs](/docs/guides/functions).
### Regional invocations
Execute an Edge Function in a region close to your database. [Docs](/docs/guides/functions/regional-invocation).
### NPM compatibility
Edge functions natively support NPM modules and Node built-in APIs. [Link](/blog/edge-functions-node-npm).
## Project management
### CLI
Use our CLI to develop your project locally and deploy to the Supabase Platform. [Docs](/docs/reference/cli).
### Management API
Manage your projects programmatically. [Docs](/docs/reference/api).
## Client libraries
Official client libraries for [JavaScript](/docs/reference/javascript/start), [Flutter](/docs/reference/dart/initializing) and [Swift](/docs/reference/swift/introduction).
Unofficial libraries are supported by the community.
## Feature status
Supabase Features are in 4 different states - Private Alpha, Public Alpha, Beta and Generally Available.
### Private alpha
Features are initially launched as a private alpha to gather feedback from the community. To join our early access program, send an email to [product-ops@supabase.io](mailto:product-ops@supabase.io).
### Public alpha
The alpha stage indicates that the API might change in the future, not that the service isn’t stable. Even though the [uptime Service Level Agreement](/sla) does not cover products in Alpha, we do our best to have the service as stable as possible.
### Beta
Features in Beta are tested by an external penetration tester for security issues. The API is guaranteed to be stable and there is a strict communication process for breaking changes.
### Generally available
In addition to the Beta requirements, features in GA are covered by the [uptime SLA](/sla).
| Product | Feature | Stage | Available on self-hosted |
| -------------- | -------------------------- | --------------- | ------------------------------------------- |
| Database | Postgres | `GA` | ✅ |
| Database | Vector Database | `GA` | ✅ |
| Database | Auto-generated Rest API | `GA` | ✅ |
| Database | Auto-generated GraphQL API | `GA` | ✅ |
| Database | Webhooks | `beta` | ✅ |
| Database | Vault | `public alpha` | ✅ |
| Database | Replication | `private alpha` | N/A |
| Platform | | `GA` | ✅ |
| Platform | Point-in-Time Recovery | `GA` | 🚧 [wal-g](https://github.com/wal-g/wal-g) |
| Platform | Custom Domains | `GA` | N/A |
| Platform | Network Restrictions | `GA` | N/A |
| Platform | SSL enforcement | `GA` | N/A |
| Platform | Branching | `beta` | N/A |
| Platform | Terraform Provider | `public alpha` | N/A |
| Platform | Read Replicas | `GA` | N/A |
| Platform | Log Drains | `public alpha` | ✅ |
| Platform | MCP | `public alpha` | ✅ |
| Platform | PrivateLink | `beta` | N/A |
| Studio | | `GA` | ✅ |
| Studio | SSO | `GA` | ✅ |
| Studio | Column Privileges | `public alpha` | ✅ |
| Realtime | Postgres Changes | `GA` | ✅ |
| Realtime | Broadcast | `GA` | ✅ |
| Realtime | Presence | `GA` | ✅ |
| Realtime | Broadcast Authorization | `public beta` | ✅ |
| Realtime | Presence Authorization | `public beta` | ✅ |
| Realtime | Broadcast from Database | `public beta` | ✅ |
| Storage | | `GA` | ✅ |
| Storage | CDN | `GA` | 🚧 [Cloudflare](https://www.cloudflare.com) |
| Storage | Smart CDN | `GA` | 🚧 [Cloudflare](https://www.cloudflare.com) |
| Storage | Image Transformations | `GA` | ✅ |
| Storage | Resumable Uploads | `GA` | ✅ |
| Storage | S3 compatibility | `GA` | ✅ |
| Edge Functions | | `GA` | ✅ |
| Edge Functions | Regional Invocations | `GA` | ✅ |
| Edge Functions | NPM compatibility | `GA` | ✅ |
| Auth | | `GA` | ✅ |
| Auth | Email login | `GA` | ✅ |
| Auth | Social login | `GA` | ✅ |
| Auth | Phone login | `GA` | ✅ |
| Auth | Passwordless login | `GA` | ✅ |
| Auth | SSO with SAML | `GA` | ✅ |
| Auth | Authorization via RLS | `GA` | ✅ |
| Auth | CAPTCHA protection | `GA` | ✅ |
| Auth | Server-side Auth | `beta` | ✅ |
| Auth | Third-Party Auth | `GA` | ✅ |
| Auth | Hooks | `beta` | ✅ |
| CLI | | `GA` | ✅ Works with self-hosted |
| Management API | | `GA` | N/A |
| Client Library | JavaScript | `GA` | N/A |
| Client Library | Flutter | `GA` | N/A |
| Client Library | Swift | `GA` | N/A |
| Client Library | Python | `beta` | N/A |
* ✅ = Fully Available
* 🚧 = Available, but requires external tools or configuration
# Build a User Management App with Angular
This tutorial demonstrates how to build a basic user management app. The app authenticates and identifies the user, stores their profile information in the database, and allows the user to log in, update their profile details, and upload a profile photo. The app uses:
* [Supabase Database](/docs/guides/database) - a Postgres database for storing your user data and [Row Level Security](/docs/guides/auth#row-level-security) so data is protected and users can only access their own information.
* [Supabase Auth](/docs/guides/auth) - allow users to sign up and log in.
* [Supabase Storage](/docs/guides/storage) - allow users to upload a profile photo.
If you get stuck while working through this guide, you can find the [full example on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/angular-user-management).
## Project setup
Before you start building you need to set up the Database and API. You can do this by starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. [Create a new project](/dashboard) in the Supabase Dashboard.
2. Enter your project details.
3. Wait for the new database to launch.
### Set up the database schema
Now set up the database schema. You can use the "User Management Starter" quickstart in the SQL Editor, or you can copy/paste the SQL from below and run it.
1. Go to the [SQL Editor](/dashboard/project/_/sql) page in the Dashboard.
2. Click **User Management Starter** under the **Community > Quickstarts** tab.
3. Click **Run**.
You can pull the database schema down to your local project by running the `db pull` command. Read the [local development docs](/docs/guides/cli/local-development#link-your-project) for detailed instructions.
```bash
supabase link --project-ref
# You can get from your project's dashboard URL: https://supabase.com/dashboard/project/
supabase db pull
```
When working locally you can run the following command to create a new migration file:
```bash
supabase migration new user_management_starter
```
```sql
-- Create a table for public profiles
create table profiles (
id uuid references auth.users not null primary key,
updated_at timestamp with time zone,
username text unique,
full_name text,
avatar_url text,
website text,
constraint username_length check (char_length(username) >= 3)
);
-- Grant the privileges roles need
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE ON public.profiles TO authenticated;
-- Set up Row Level Security (RLS)
-- See https://supabase.com/docs/guides/database/postgres/row-level-security for more details.
alter table profiles
enable row level security;
create policy "Public profiles are viewable by everyone." on profiles
for select using (true);
create policy "Users can insert their own profile." on profiles
for insert with check ((select auth.uid()) = id);
create policy "Users can update own profile." on profiles
for update using ((select auth.uid()) = id);
-- This trigger automatically creates a profile entry when a new user signs up via Supabase Auth.
-- See https://supabase.com/docs/guides/auth/managing-user-data#using-triggers for more details.
create function public.handle_new_user()
returns trigger
set search_path = ''
as $$
begin
insert into public.profiles (id, full_name, avatar_url)
values (new.id, new.raw_user_meta_data->>'full_name', new.raw_user_meta_data->>'avatar_url');
return new;
end;
$$ language plpgsql security definer;
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
-- Set up Storage!
insert into storage.buckets (id, name)
values ('avatars', 'avatars');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage/security/access-control#policy-examples for more details.
create policy "Avatar images are publicly accessible." on storage.objects
for select using (bucket_id = 'avatars');
create policy "Anyone can upload an avatar." on storage.objects
for insert with check (bucket_id = 'avatars');
create policy "Anyone can update their own avatar." on storage.objects
for update using ((select auth.uid()) = owner) with check (bucket_id = 'avatars');
```
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=ionicangular).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=ionicangular), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
## Building the app
Start with building the Angular app from scratch.
### Initialize an Angular app
Use the [Angular CLI](https://angular.io/cli) to initialize an app called `supabase-angular` setting some defaults that you can change to suit your needs:
```bash
npx ng new supabase-angular --routing false --style css --standalone false --ssr false
cd supabase-angular
```
Install [supabase-js](https://github.com/supabase/supabase-js):
```bash
npm install @supabase/supabase-js
```
Create a `src/environments` directory and save API URL and key that you copied [earlier](#get-api-details) as environment variables in a new `src/environments/environment.ts` file.
The application exposes these variables in the browser, and that's fine as Supabase enables [Row Level Security](/docs/guides/database/postgres/row-level-security) by default on all tables.
```typescript name=src/environments/environment.ts
export const environment = {
production: false,
supabaseUrl: 'YOUR_SUPABASE_URL',
supabasePublishableKey: 'YOUR_SUPABASE_PUBLISHABLE_KEY',
}
```
With the API credentials in place, create a `SupabaseService` with `ng g s supabase` and add the following code to initialize the Supabase client and implement functions to communicate with the Supabase API.
```typescript name=src/app/supabase.service.ts
import { Injectable } from '@angular/core'
import { AuthChangeEvent, createClient, Session, SupabaseClient, User } from '@supabase/supabase-js'
import { environment } from '../environments/environment'
export interface Profile {
id?: string
username: string
website: string
avatar_url: string
}
@Injectable({
providedIn: 'root',
})
export class SupabaseService {
private supabase: SupabaseClient
constructor() {
this.supabase = createClient(environment.supabaseUrl, environment.supabasePublishableKey)
}
async getUser(): Promise {
const { data, error } = await this.supabase.auth.getUser()
if (error) {
return null
}
return data.user
}
profile(user: User) {
return this.supabase
.from('profiles')
.select(`username, website, avatar_url`)
.eq('id', user.id)
.single()
}
authChanges(callback: (event: AuthChangeEvent, session: Session | null) => void) {
return this.supabase.auth.onAuthStateChange(callback)
}
signIn(email: string) {
return this.supabase.auth.signInWithOtp({ email })
}
signOut() {
return this.supabase.auth.signOut()
}
updateProfile(profile: Profile) {
const update = {
...profile,
updated_at: new Date(),
}
return this.supabase.from('profiles').upsert(update)
}
downLoadImage(path: string) {
return this.supabase.storage.from('avatars').download(path)
}
uploadAvatar(filePath: string, file: File) {
return this.supabase.storage.from('avatars').upload(filePath, file)
}
}
```
Optionally, update `src/styles.css` to style the app. You can find the full contents of this file [in the example repository](https://github.com/supabase/supabase/tree/master/examples/user-management/angular-user-management/src/styles.css).
### Set up a login component
You need an Angular component to manage logins and sign ups. The component uses [Magic Links](/docs/guides/auth/auth-email-passwordless#with-magic-link), so users can sign in with their email without using passwords.
You can customize other emails sent out to new users, including the email's looks, content, and query parameters from [the **Authentication > Email**](/dashboard/project/_/auth/templates) section of the Dashboard.
Create an `AuthComponent` with the `ng g c auth` Angular CLI command and add the following code.
```typescript name=src/app/auth/auth.component.ts
import { Component } from '@angular/core'
import { FormBuilder, FormGroup } from '@angular/forms'
import { SupabaseService } from '../supabase.service'
@Component({
selector: 'app-auth',
templateUrl: './auth.component.html',
styleUrls: ['./auth.component.css'],
standalone: false,
})
export class AuthComponent {
loading = false
signInForm: FormGroup
constructor(
private readonly supabase: SupabaseService,
private readonly formBuilder: FormBuilder
) {
this.signInForm = this.formBuilder.group({
email: '',
})
}
async onSubmit(): Promise {
try {
this.loading = true
const email = this.signInForm.value.email as string
const { error } = await this.supabase.signIn(email)
if (error) throw error
alert('Check your email for the login link!')
} catch (error) {
if (error instanceof Error) {
alert(error.message)
}
} finally {
this.signInForm.reset()
this.loading = false
}
}
}
```
```
```
### Account page
Users also need a way to edit their profile details and manage their accounts after signing in. Create an `AccountComponent` with the `ng g c account` Angular CLI command and add the following code.
```typescript name=src/app/account/account.component.ts
import { Component, Input, OnInit } from '@angular/core'
import { FormBuilder, FormGroup } from '@angular/forms'
import { User } from '@supabase/supabase-js'
import { Profile, SupabaseService } from '../supabase.service'
@Component({
selector: 'app-account',
templateUrl: './account.component.html',
styleUrls: ['./account.component.css'],
standalone: false,
})
export class AccountComponent implements OnInit {
loading = false
profile!: Profile
updateProfileForm!: FormGroup
// ...
@Input()
user!: User
constructor(
private readonly supabase: SupabaseService,
private formBuilder: FormBuilder
) {
this.updateProfileForm = this.formBuilder.group({
username: '',
website: '',
avatar_url: '',
})
}
async ngOnInit(): Promise {
await this.getProfile()
const { username, website, avatar_url } = this.profile
this.updateProfileForm.patchValue({
username,
website,
avatar_url,
})
}
async getProfile() {
try {
this.loading = true
const { data: profile, error, status } = await this.supabase.profile(this.user)
if (error && status !== 406) {
throw error
}
if (profile) {
this.profile = profile
}
} catch (error) {
if (error instanceof Error) {
alert(error.message)
}
} finally {
this.loading = false
}
}
async updateProfile(): Promise {
try {
this.loading = true
const username = this.updateProfileForm.value.username as string
const website = this.updateProfileForm.value.website as string
const avatar_url = this.updateProfileForm.value.avatar_url as string
const { error } = await this.supabase.updateProfile({
id: this.user.id,
username,
website,
avatar_url,
})
if (error) throw error
} catch (error) {
if (error instanceof Error) {
alert(error.message)
}
} finally {
this.loading = false
}
}
async signOut() {
await this.supabase.signOut()
}
}
```
```
```
## Profile photos
Add a way for users to upload a profile photo. Supabase configures every project with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
Create an `AvatarComponent` with the `ng g c avatar` Angular CLI command and add the following code.
```typescript name=src/app/avatar/avatar.component.ts
import { Component, EventEmitter, Input, Output } from '@angular/core'
import { SafeResourceUrl, DomSanitizer } from '@angular/platform-browser'
import { SupabaseService } from '../supabase.service'
@Component({
selector: 'app-avatar',
templateUrl: './avatar.component.html',
styleUrls: ['./avatar.component.css'],
standalone: false,
})
export class AvatarComponent {
_avatarUrl: SafeResourceUrl | undefined
uploading = false
@Input()
set avatarUrl(url: string | null) {
if (url) {
this.downloadImage(url)
}
}
@Output() upload = new EventEmitter()
constructor(
private readonly supabase: SupabaseService,
private readonly dom: DomSanitizer
) {}
async downloadImage(path: string) {
try {
const { data } = await this.supabase.downLoadImage(path)
if (data instanceof Blob) {
this._avatarUrl = this.dom.bypassSecurityTrustResourceUrl(URL.createObjectURL(data))
}
} catch (error) {
if (error instanceof Error) {
console.error('Error downloading image: ', error.message)
}
}
}
async uploadAvatar(event: any) {
try {
this.uploading = true
if (!event.target.files || event.target.files.length === 0) {
throw new Error('You must select an image to upload.')
}
const file = event.target.files[0]
const fileExt = file.name.split('.').pop()
const filePath = `${Math.random()}.${fileExt}`
await this.supabase.uploadAvatar(filePath, file)
this.upload.emit(filePath)
} catch (error) {
if (error instanceof Error) {
alert(error.message)
}
} finally {
this.uploading = false
}
}
}
```
```
```
### Update the Account component
With the Avatar component created, update `AccountComponent` to include it:
```typescript name=src/app/account/account.component.ts
import { Component, Input, OnInit } from '@angular/core'
import { FormBuilder, FormGroup } from '@angular/forms'
import { User } from '@supabase/supabase-js'
import { Profile, SupabaseService } from '../supabase.service'
@Component({
selector: 'app-account',
templateUrl: './account.component.html',
styleUrls: ['./account.component.css'],
standalone: false,
})
export class AccountComponent implements OnInit {
loading = false
profile!: Profile
updateProfileForm!: FormGroup
get avatarUrl() {
return this.updateProfileForm.value.avatar_url as string
}
async updateAvatar(event: string): Promise {
this.updateProfileForm.patchValue({
avatar_url: event,
})
await this.updateProfile()
}
@Input()
user!: User
constructor(
private readonly supabase: SupabaseService,
private formBuilder: FormBuilder
) {
this.updateProfileForm = this.formBuilder.group({
username: '',
website: '',
avatar_url: '',
})
}
async ngOnInit(): Promise {
await this.getProfile()
const { username, website, avatar_url } = this.profile
this.updateProfileForm.patchValue({
username,
website,
avatar_url,
})
}
async getProfile() {
try {
this.loading = true
const { data: profile, error, status } = await this.supabase.profile(this.user)
if (error && status !== 406) {
throw error
}
if (profile) {
this.profile = profile
}
} catch (error) {
if (error instanceof Error) {
alert(error.message)
}
} finally {
this.loading = false
}
}
async updateProfile(): Promise {
try {
this.loading = true
const username = this.updateProfileForm.value.username as string
const website = this.updateProfileForm.value.website as string
const avatar_url = this.updateProfileForm.value.avatar_url as string
const { error } = await this.supabase.updateProfile({
id: this.user.id,
username,
website,
avatar_url,
})
if (error) throw error
} catch (error) {
if (error instanceof Error) {
alert(error.message)
}
} finally {
this.loading = false
}
}
async signOut() {
await this.supabase.signOut()
}
}
```
```
```
You also need to change `app.module.ts` to include the `ReactiveFormsModule` from the `@angular/forms` package.
```typescript name=src/app/app.module.ts
import { NgModule } from '@angular/core'
import { BrowserModule } from '@angular/platform-browser'
import { ReactiveFormsModule } from '@angular/forms'
import { AppComponent } from './app.component'
import { AuthComponent } from './auth/auth.component'
import { AccountComponent } from './account/account.component'
import { AvatarComponent } from './avatar/avatar.component'
@NgModule({
declarations: [AppComponent, AuthComponent, AccountComponent, AvatarComponent],
imports: [BrowserModule, ReactiveFormsModule],
providers: [],
bootstrap: [AppComponent],
})
export class AppModule {}
```
### Launch!
With all the components in place, change the contents of `AppComponent` to include the new components and Auth logic:
The Supabase Auth SDK contains three different functions for authenticating user access to applications:
### Summary of the methods
* Use [`getClaims`](/docs/reference/javascript/auth-getclaims) to protect pages and user data. It reads the access token from storage and verifies it. Locally via the [WebCrypto API](https://developer.mozilla.org/en-US/docs/Web/API/Web_Crypto_API) and a cached JWKS endpoint when the project uses asymmetric signing keys (the default for new projects), or by calling `getUser` solely to validate when symmetric keys are in use. The returned claims always come from decoding the JWT, not from a user lookup.
* [`getUser`](/docs/reference/javascript/auth-getuser) makes a network call to the project's Auth instance to get the user record, which includes the most up-to-date information about the user at the cost of a network call.
* [`getSession`](/docs/reference/javascript/auth-getsession) when you need the raw session (the access token, refresh token, and expiry). For example to forward the access token to another service. The session is loaded directly from local storage and isn't re-validated against the Auth server, so the embedded user object shouldn't be trusted on its own when storage is shared with the client (cookies, request headers). To verify identity, validate the access token with `getClaims`, or call `getUser` for a fresh, server-confirmed user record.
**In summary**: use `getClaims` to verify identity (typically for protecting pages and data), `getUser` when you need an up-to-date user record from the Auth server, and `getSession` when you need the access or refresh token directly, but don't rely on the user object it returns for authorization decisions.
```typescript name=src/app/app.component.ts
import { Component, OnInit } from '@angular/core'
import { User } from '@supabase/supabase-js'
import { SupabaseService } from './supabase.service'
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css'],
standalone: false,
})
export class AppComponent implements OnInit {
constructor(private readonly supabase: SupabaseService) {}
title = 'angular-user-management'
user: User | null = null
async ngOnInit() {
this.user = await this.supabase.getUser()
this.supabase.authChanges(async () => {
this.user = await this.supabase.getUser()
})
}
}
```
```
```
Now run the application in a terminal:
```bash
npm run start
```
Open the browser to [localhost:4200](http://localhost:4200) and you should see the completed app.
At this stage you have a fully functional application!
# Build a User Management App with Expo React Native
This tutorial demonstrates how to build a basic user management app. The app authenticates and identifies the user, stores their profile information in the database, and allows the user to log in, update their profile details, and upload a profile photo. The app uses:
* [Supabase Database](/docs/guides/database) - a Postgres database for storing your user data and [Row Level Security](/docs/guides/auth#row-level-security) so data is protected and users can only access their own information.
* [Supabase Auth](/docs/guides/auth) - allow users to sign up and log in.
* [Supabase Storage](/docs/guides/storage) - allow users to upload a profile photo.
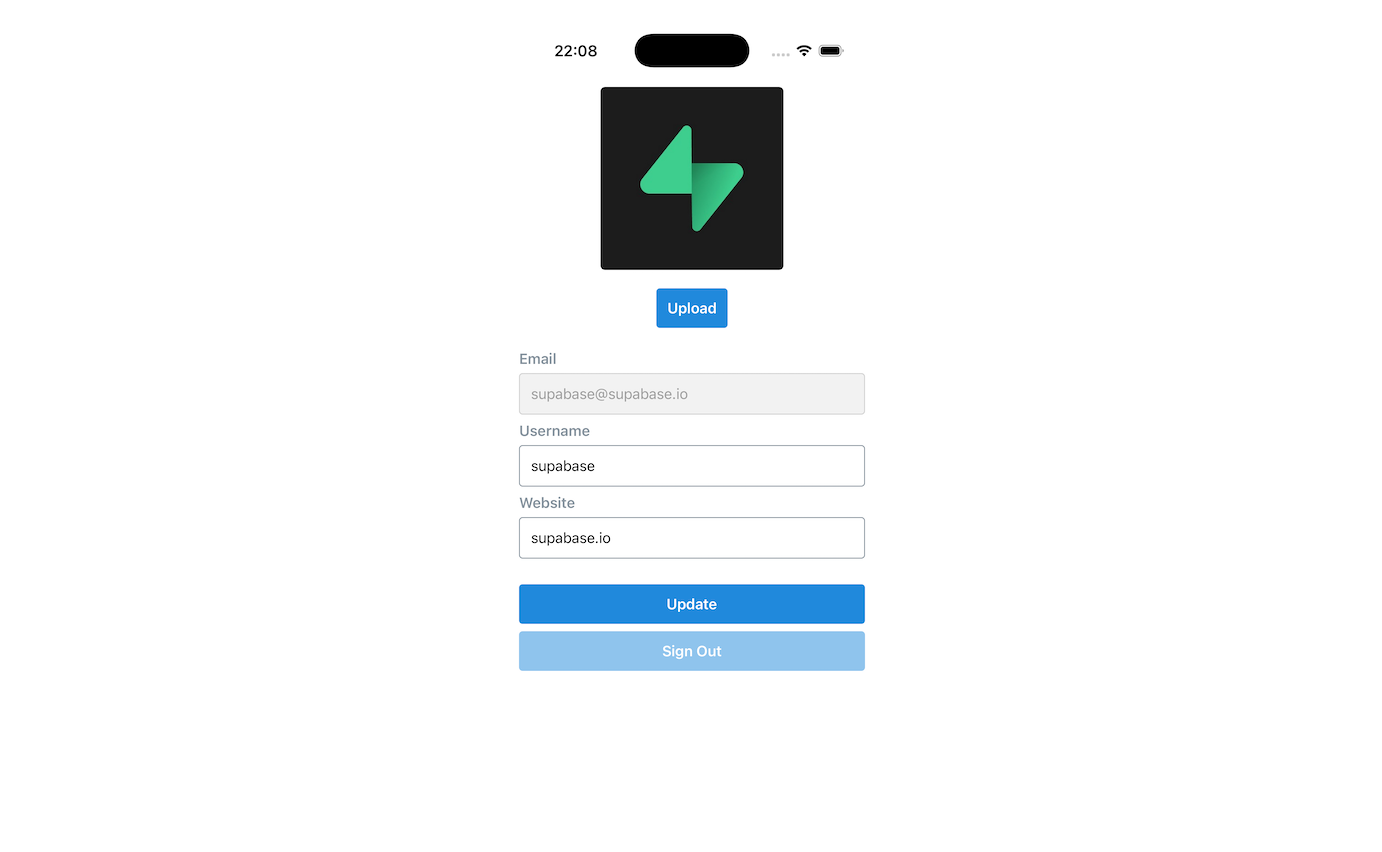
If you get stuck while working through this guide, refer to the [full example on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/expo-user-management).
## Project setup
Before you start building you need to set up the Database and API. You can do this by starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. [Create a new project](/dashboard) in the Supabase Dashboard.
2. Enter your project details.
3. Wait for the new database to launch.
### Set up the database schema
Now set up the database schema. You can use the "User Management Starter" quickstart in the SQL Editor, or you can copy/paste the SQL from below and run it.
1. Go to the [SQL Editor](/dashboard/project/_/sql) page in the Dashboard.
2. Click **User Management Starter** under the **Community > Quickstarts** tab.
3. Click **Run**.
You can pull the database schema down to your local project by running the `db pull` command. Read the [local development docs](/docs/guides/cli/local-development#link-your-project) for detailed instructions.
```bash
supabase link --project-ref
# You can get from your project's dashboard URL: https://supabase.com/dashboard/project/
supabase db pull
```
When working locally you can run the following command to create a new migration file:
```bash
supabase migration new user_management_starter
```
```sql
-- Create a table for public profiles
create table profiles (
id uuid references auth.users not null primary key,
updated_at timestamp with time zone,
username text unique,
full_name text,
avatar_url text,
website text,
constraint username_length check (char_length(username) >= 3)
);
-- Grant the privileges roles need
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE ON public.profiles TO authenticated;
-- Set up Row Level Security (RLS)
-- See https://supabase.com/docs/guides/database/postgres/row-level-security for more details.
alter table profiles
enable row level security;
create policy "Public profiles are viewable by everyone." on profiles
for select using (true);
create policy "Users can insert their own profile." on profiles
for insert with check ((select auth.uid()) = id);
create policy "Users can update own profile." on profiles
for update using ((select auth.uid()) = id);
-- This trigger automatically creates a profile entry when a new user signs up via Supabase Auth.
-- See https://supabase.com/docs/guides/auth/managing-user-data#using-triggers for more details.
create function public.handle_new_user()
returns trigger
set search_path = ''
as $$
begin
insert into public.profiles (id, full_name, avatar_url)
values (new.id, new.raw_user_meta_data->>'full_name', new.raw_user_meta_data->>'avatar_url');
return new;
end;
$$ language plpgsql security definer;
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
-- Set up Storage!
insert into storage.buckets (id, name)
values ('avatars', 'avatars');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage/security/access-control#policy-examples for more details.
create policy "Avatar images are publicly accessible." on storage.objects
for select using (bucket_id = 'avatars');
create policy "Anyone can upload an avatar." on storage.objects
for insert with check (bucket_id = 'avatars');
create policy "Anyone can update their own avatar." on storage.objects
for update using ((select auth.uid()) = owner) with check (bucket_id = 'avatars');
```
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=exporeactnative).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=exporeactnative), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
## Building the app
Start by building the React Native app from scratch.
### Initialize a React Native app
Use [`expo`](https://docs.expo.dev/get-started/create-a-new-app/) to initialize
an app called `expo-user-management`:
```bash
npx create-expo-app -t expo-template-blank-typescript expo-user-management
cd expo-user-management
```
Then install the additional dependencies:
```bash
npx expo install @supabase/supabase-js @react-native-async-storage/async-storage
```
Now create a helper file to initialize the Supabase client using the API URL and the key that you copied [earlier](#get-api-details).
These variables are safe to expose in your Expo app since Supabase has
[Row Level Security](/docs/guides/database/postgres/row-level-security) enabled on your Database.
```typescript name=lib/supabase.ts
import { createClient } from '@supabase/supabase-js'
import AsyncStorage from '@react-native-async-storage/async-storage'
const supabaseUrl = process.env.EXPO_PUBLIC_SUPABASE_URL!
const supabasePublishableKey = process.env.EXPO_PUBLIC_SUPABASE_PUBLISHABLE_KEY!
export const supabase = createClient(supabaseUrl, supabasePublishableKey, {
auth: {
storage: AsyncStorage as any,
autoRefreshToken: true,
persistSession: true,
detectSessionInUrl: false,
},
})
```
If you wish to encrypt the user's session information, you can use `aes-js` and store the encryption key in [Expo SecureStore](https://docs.expo.dev/versions/latest/sdk/securestore). The [`aes-js` library](https://github.com/ricmoo/aes-js) is a reputable JavaScript-only implementation of the AES encryption algorithm in CTR mode. A new 256-bit encryption key is generated using the `react-native-get-random-values` library. This key is stored inside Expo's SecureStore, while the value is encrypted and placed inside AsyncStorage.
Make sure that:
* You keep the `expo-secure-storage`, `aes-js` and `react-native-get-random-values` libraries up-to-date.
* Choose the correct [`SecureStoreOptions`](https://docs.expo.dev/versions/latest/sdk/securestore/#securestoreoptions) for your app's needs. E.g. [`SecureStore.WHEN_UNLOCKED`](https://docs.expo.dev/versions/latest/sdk/securestore/#securestorewhen_unlocked) regulates when the data can be accessed.
* Carefully consider optimizations or other modifications to the above example, as those can lead to introducing subtle security vulnerabilities.
Install the necessary dependencies in the root of your Expo project:
```bash
npm install @supabase/supabase-js
npm install @react-native-async-storage/async-storage
npm install aes-js react-native-get-random-values
npm install --save-dev @types/aes-js
npx expo install expo-secure-store
```
Implement a `LargeSecureStore` class to pass in as Auth storage for the `supabase-js` client:
```ts name=lib/supabase.ts
import { createClient } from "@supabase/supabase-js";
import AsyncStorage from "@react-native-async-storage/async-storage";
import * as SecureStore from 'expo-secure-store';
import * as aesjs from 'aes-js';
import 'react-native-get-random-values';
// As Expo's SecureStore does not support values larger than 2048
// bytes, an AES-256 key is generated and stored in SecureStore, while
// it is used to encrypt/decrypt values stored in AsyncStorage.
class LargeSecureStore {
private async _encrypt(key: string, value: string) {
const encryptionKey = crypto.getRandomValues(new Uint8Array(256 / 8));
const cipher = new aesjs.ModeOfOperation.ctr(encryptionKey, new aesjs.Counter(1));
const encryptedBytes = cipher.encrypt(aesjs.utils.utf8.toBytes(value));
await SecureStore.setItemAsync(key, aesjs.utils.hex.fromBytes(encryptionKey));
return aesjs.utils.hex.fromBytes(encryptedBytes);
}
private async _decrypt(key: string, value: string) {
const encryptionKeyHex = await SecureStore.getItemAsync(key);
if (!encryptionKeyHex) {
return encryptionKeyHex;
}
const cipher = new aesjs.ModeOfOperation.ctr(aesjs.utils.hex.toBytes(encryptionKeyHex), new aesjs.Counter(1));
const decryptedBytes = cipher.decrypt(aesjs.utils.hex.toBytes(value));
return aesjs.utils.utf8.fromBytes(decryptedBytes);
}
async getItem(key: string) {
const encrypted = await AsyncStorage.getItem(key);
if (!encrypted) { return encrypted; }
return await this._decrypt(key, encrypted);
}
async removeItem(key: string) {
await AsyncStorage.removeItem(key);
await SecureStore.deleteItemAsync(key);
}
async setItem(key: string, value: string) {
const encrypted = await this._encrypt(key, value);
await AsyncStorage.setItem(key, encrypted);
}
}
const supabaseUrl = YOUR_REACT_NATIVE_SUPABASE_URL
const supabasePublishableKey = YOUR_REACT_NATIVE_SUPABASE_PUBLISHABLE_KEY
export const supabase = createClient(supabaseUrl, supabasePublishableKey, {
auth: {
storage: new LargeSecureStore(),
autoRefreshToken: true,
persistSession: true,
detectSessionInUrl: false,
},
});
```
### App styling
You can use the following `StyleSheet` component in `styles/styles.ts` to add style to the app:
```typescript name=styles/styles.ts
import { StyleSheet } from 'react-native'
export const appStyles = StyleSheet.create({
container: {
marginTop: 40,
padding: 12,
},
verticallySpaced: {
paddingTop: 4,
paddingBottom: 4,
alignSelf: 'stretch',
},
mt20: {
marginTop: 20,
},
label: {
fontSize: 16,
fontWeight: '600',
color: '#86939e',
marginBottom: 6,
},
input: {
borderWidth: 1,
borderColor: '#86939e',
borderRadius: 4,
padding: 12,
fontSize: 16,
},
inputDisabled: {
backgroundColor: '#f2f2f2',
borderColor: '#d1d1d1',
color: '#9e9e9e',
},
button: {
backgroundColor: '#2089dc',
borderRadius: 4,
padding: 12,
alignItems: 'center',
},
buttonDisabled: {
opacity: 0.5,
},
buttonText: {
color: '#fff',
fontSize: 16,
fontWeight: '600',
},
avatarContainer: {
alignItems: 'center',
justifyContent: 'center',
marginTop: 20,
},
avatar: {
borderRadius: 5,
overflow: 'hidden',
maxWidth: '100%',
marginBottom: 20,
},
image: {
objectFit: 'cover',
paddingTop: 0,
},
noImage: {
backgroundColor: '#333',
borderWidth: 1,
borderStyle: 'solid',
borderColor: 'rgb(200, 200, 200)',
borderRadius: 5,
},
})
```
### Set up a login component
Set up a React Native component to manage logins and sign ups.
Users should be able to sign in with their email and password.
```tsx name=components/Auth.tsx
import React, { useState } from 'react'
import { Alert, Text, TextInput, TouchableOpacity, View } from 'react-native'
import { supabase } from '../lib/supabase'
import { appStyles } from '../styles/styles'
export default function Auth() {
const [email, setEmail] = useState('')
const [password, setPassword] = useState('')
const [loading, setLoading] = useState(false)
const styles = appStyles
async function signInWithEmail() {
setLoading(true)
const { error } = await supabase.auth.signInWithPassword({
email: email,
password: password,
})
if (error) Alert.alert(error.message)
setLoading(false)
}
async function signUpWithEmail() {
setLoading(true)
const { error } = await supabase.auth.signUp({
email: email,
password: password,
})
if (error) Alert.alert(error.message)
setLoading(false)
}
return (
Email
setEmail(text)}
value={email}
placeholder="email@address.com"
autoCapitalize="none"
style={styles.input}
/>
Password
setPassword(text)}
value={password}
secureTextEntry={true}
placeholder="Password"
autoCapitalize="none"
style={styles.input}
/>
signInWithEmail()}
disabled={loading}
>
Sign in
signUpWithEmail()}
disabled={loading}
>
Sign up
)
}
```
By default Supabase Auth requires email verification before a session is created for the users. To support email verification you need to [implement deep link handling](/docs/guides/auth/native-mobile-deep-linking?platform=react-native)!
While testing, you can disable email confirmation in your [project's email auth provider settings](/dashboard/project/_/auth/providers).
### Account page
After a user signs in, let them edit their profile details and manage their account.
Create a new component for that called `Account.tsx`.
```tsx name=components/Account.tsx
import { useState, useEffect } from 'react'
import { supabase } from '../lib/supabase'
import { View, Alert, TextInput, Text, TouchableOpacity } from 'react-native'
import Avatar from './Avatar'
// ...
export default function Account({ userId, email }: { userId: string; email?: string }) {
const [loading, setLoading] = useState(true)
const [username, setUsername] = useState('')
const [website, setWebsite] = useState('')
const [avatarUrl, setAvatarUrl] = useState('')
const styles = appStyles
useEffect(() => {
if (userId) getProfile()
}, [userId])
async function getProfile() {
try {
setLoading(true)
let { data, error, status } = await supabase
.from('profiles')
.select(`username, website, avatar_url`)
.eq('id', userId)
.single()
if (error && status !== 406) {
throw error
}
if (data) {
setUsername(data.username)
setWebsite(data.website)
setAvatarUrl(data.avatar_url)
}
} catch (error) {
if (error instanceof Error) {
Alert.alert(error.message)
}
} finally {
setLoading(false)
}
}
async function updateProfile({
username,
website,
avatar_url,
}: {
username: string
website: string
avatar_url: string
}) {
try {
setLoading(true)
const updates = {
id: userId,
username,
website,
avatar_url,
updated_at: new Date(),
}
let { error } = await supabase.from('profiles').upsert(updates)
if (error) {
throw error
}
} catch (error: any) {
Alert.alert(error.message)
} finally {
setLoading(false)
}
}
return (
{/* ... */}
Email
Username
setUsername(text)}
style={styles.input}
/>
Website
setWebsite(text)}
style={styles.input}
/>
updateProfile({ username, website, avatar_url: avatarUrl })}
disabled={loading}
>
{loading ? 'Loading ...' : 'Update'}
supabase.auth.signOut()}>
Sign Out
)
}
```
### Launch!
Now that you have all the components in place, update `App.tsx`:
```tsx name=App.tsx
import { useState, useEffect } from 'react'
import { supabase } from './lib/supabase'
import Auth from './components/Auth'
import Account from './components/Account'
import { View } from 'react-native'
export default function App() {
const [userId, setUserId] = useState(null)
const [email, setEmail] = useState(undefined)
useEffect(() => {
supabase.auth.getClaims().then(({ data: { claims } }) => {
if (claims) {
setUserId(claims.sub)
setEmail(claims.email)
}
})
supabase.auth.onAuthStateChange(async (_event, _session) => {
const {
data: { claims },
} = await supabase.auth.getClaims()
if (claims) {
setUserId(claims.sub)
setEmail(claims.email)
} else {
setUserId(null)
setEmail(undefined)
}
})
}, [])
return {userId ? : }
}
```
Once that's done, run this in a terminal window:
```bash
npm start
```
And then press the appropriate key for the environment you want to test the app in and you should see the completed app.
## Bonus: Profile photos
Every Supabase project is configured with [Storage](/docs/guides/storage) for managing large files like
photos and videos.
### Additional dependency installation
You need an image picker that works on the environment you are building the project for, this example uses `expo-image-picker`.
```bash
npx expo install expo-image-picker
```
### Create an upload widget
Create an avatar for the user so that they can upload a profile photo.
Start by creating a new component:
```tsx name=components/Avatar.tsx
import { useState, useEffect } from 'react'
import { supabase } from '../lib/supabase'
import { View, Alert, Image, Text, TouchableOpacity } from 'react-native'
import * as ImagePicker from 'expo-image-picker'
import { appStyles } from '../styles/styles'
interface Props {
size: number
url: string | null
onUpload: (filePath: string) => void
}
export default function Avatar({ url, size = 150, onUpload }: Props) {
const [uploading, setUploading] = useState(false)
const [avatarUrl, setAvatarUrl] = useState(null)
const avatarSize = { height: size, width: size }
const styles = appStyles
useEffect(() => {
if (url) downloadImage(url)
}, [url])
async function downloadImage(path: string) {
try {
const { data, error } = await supabase.storage.from('avatars').download(path)
if (error) {
throw error
}
const fr = new FileReader()
fr.readAsDataURL(data)
fr.onload = () => {
setAvatarUrl(fr.result as string)
}
} catch (error: any) {
console.log('Error downloading image: ', error.message)
}
}
async function uploadAvatar() {
try {
setUploading(true)
const result = await ImagePicker.launchImageLibraryAsync({
mediaTypes: ImagePicker.MediaTypeOptions.Images, // Restrict to only images
allowsMultipleSelection: false, // Can only select one image
allowsEditing: true, // Allows the user to crop / rotate their photo before uploading it
quality: 1,
exif: false, // We don't want nor need that data.
})
if (result.canceled || !result.assets || result.assets.length === 0) {
console.log('User cancelled image picker.')
return
}
const image = result.assets[0]
console.log('Got image', image)
if (!image.uri) {
throw new Error('No image uri!') // Realistically, this should never happen, but just in case...
}
const arraybuffer = await fetch(image.uri).then((res) => res.arrayBuffer())
const fileExt = image.uri?.split('.').pop()?.toLowerCase() ?? 'jpeg'
const path = `${Date.now()}.${fileExt}`
const { data, error: uploadError } = await supabase.storage
.from('avatars')
.upload(path, arraybuffer, {
contentType: image.mimeType ?? 'image/jpeg',
})
if (uploadError) {
throw uploadError
}
onUpload(data.path)
} catch (error: any) {
if (error) {
Alert.alert(error.message)
} else {
throw error
}
} finally {
setUploading(false)
}
}
return (
{avatarUrl ? (
) : (
)}
{uploading ? 'Uploading ...' : 'Upload'}
)
}
```
### Add the new widget
And then add the widget to the Account page:
```tsx name=components/Account.tsx
import { useState, useEffect } from 'react'
import { supabase } from '../lib/supabase'
import { View, Alert, TextInput, Text, TouchableOpacity } from 'react-native'
import Avatar from './Avatar'
import { appStyles } from '../styles/styles'
export default function Account({ userId, email }: { userId: string; email?: string }) {
const [loading, setLoading] = useState(true)
const [username, setUsername] = useState('')
const [website, setWebsite] = useState('')
const [avatarUrl, setAvatarUrl] = useState('')
const styles = appStyles
useEffect(() => {
if (userId) getProfile()
}, [userId])
async function getProfile() {
try {
setLoading(true)
let { data, error, status } = await supabase
.from('profiles')
.select(`username, website, avatar_url`)
.eq('id', userId)
.single()
if (error && status !== 406) {
throw error
}
if (data) {
setUsername(data.username)
setWebsite(data.website)
setAvatarUrl(data.avatar_url)
}
} catch (error) {
if (error instanceof Error) {
Alert.alert(error.message)
}
} finally {
setLoading(false)
}
}
async function updateProfile({
username,
website,
avatar_url,
}: {
username: string
website: string
avatar_url: string
}) {
try {
setLoading(true)
const updates = {
id: userId,
username,
website,
avatar_url,
updated_at: new Date(),
}
let { error } = await supabase.from('profiles').upsert(updates)
if (error) {
throw error
}
} catch (error: any) {
Alert.alert(error.message)
} finally {
setLoading(false)
}
}
return (
{
setAvatarUrl(url)
updateProfile({ username, website, avatar_url: url })
}}
/>
Email
Username
setUsername(text)}
style={styles.input}
/>
Website
setWebsite(text)}
style={styles.input}
/>
updateProfile({ username, website, avatar_url: avatarUrl })}
disabled={loading}
>
{loading ? 'Loading ...' : 'Update'}
supabase.auth.signOut()}>
Sign Out
)
}
```
Now run the prebuild command to get the application working on your chosen platform.
```bash
npx expo prebuild
```
At this stage you have a fully functional application!
# Build a User Management App with Flutter
This tutorial demonstrates how to build a basic user management app. The app authenticates and identifies the user, stores their profile information in the database, and allows the user to log in, update their profile details, and upload a profile photo. The app uses:
* [Supabase Database](/docs/guides/database) - a Postgres database for storing your user data and [Row Level Security](/docs/guides/auth#row-level-security) so data is protected and users can only access their own information.
* [Supabase Auth](/docs/guides/auth) - allow users to sign up and log in.
* [Supabase Storage](/docs/guides/storage) - allow users to upload a profile photo.
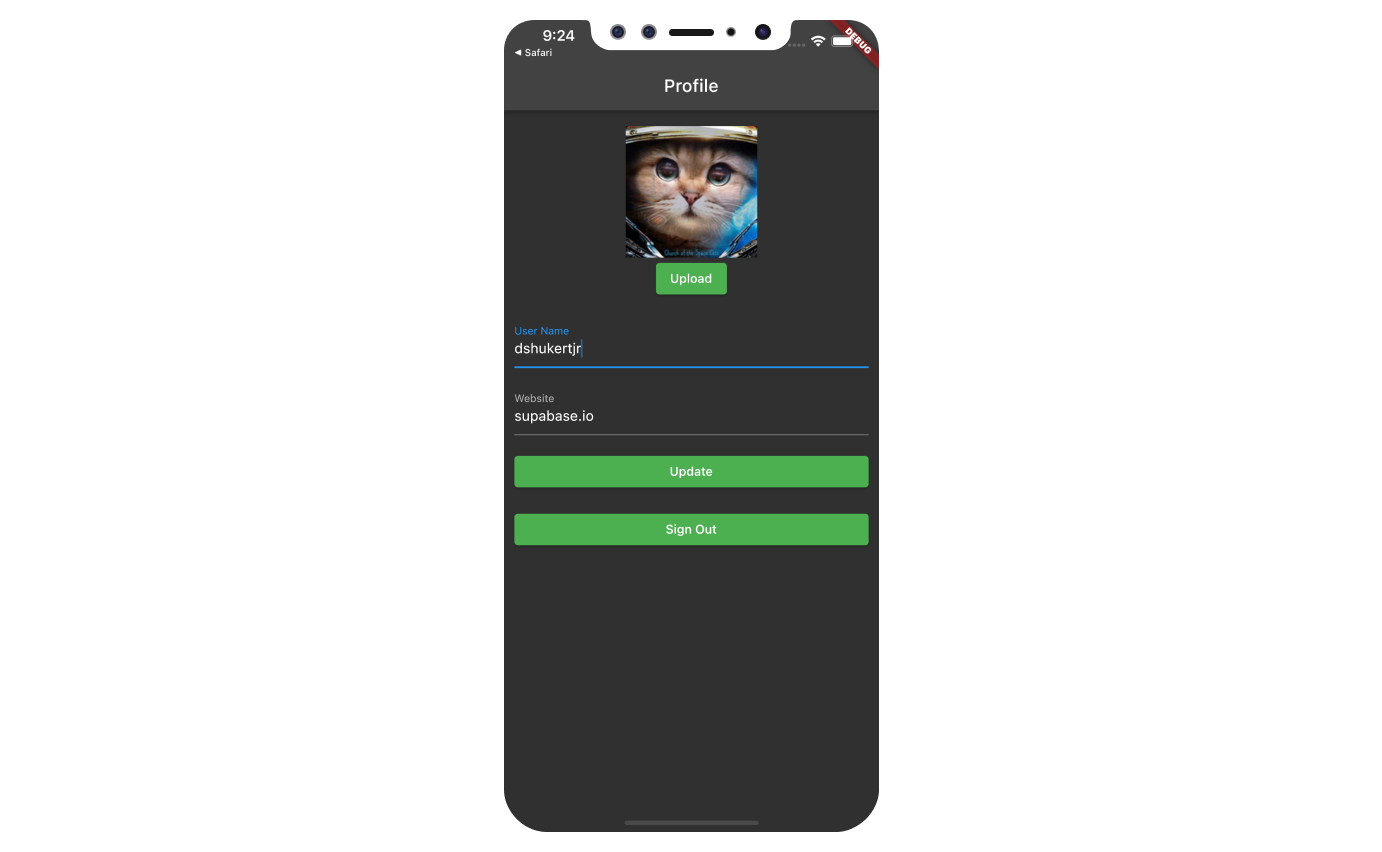
If you get stuck while working through this guide, refer to the [full example on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/flutter-user-management).
## Project setup
Before you start building you need to set up the Database and API. You can do this by starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. [Create a new project](/dashboard) in the Supabase Dashboard.
2. Enter your project details.
3. Wait for the new database to launch.
### Set up the database schema
Now set up the database schema. You can use the "User Management Starter" quickstart in the SQL Editor, or you can copy/paste the SQL from below and run it.
1. Go to the [SQL Editor](/dashboard/project/_/sql) page in the Dashboard.
2. Click **User Management Starter** under the **Community > Quickstarts** tab.
3. Click **Run**.
You can pull the database schema down to your local project by running the `db pull` command. Read the [local development docs](/docs/guides/cli/local-development#link-your-project) for detailed instructions.
```bash
supabase link --project-ref
# You can get from your project's dashboard URL: https://supabase.com/dashboard/project/
supabase db pull
```
When working locally you can run the following command to create a new migration file:
```bash
supabase migration new user_management_starter
```
```sql
-- Create a table for public profiles
create table profiles (
id uuid references auth.users not null primary key,
updated_at timestamp with time zone,
username text unique,
full_name text,
avatar_url text,
website text,
constraint username_length check (char_length(username) >= 3)
);
-- Grant the privileges roles need
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE ON public.profiles TO authenticated;
-- Set up Row Level Security (RLS)
-- See https://supabase.com/docs/guides/database/postgres/row-level-security for more details.
alter table profiles
enable row level security;
create policy "Public profiles are viewable by everyone." on profiles
for select using (true);
create policy "Users can insert their own profile." on profiles
for insert with check ((select auth.uid()) = id);
create policy "Users can update own profile." on profiles
for update using ((select auth.uid()) = id);
-- This trigger automatically creates a profile entry when a new user signs up via Supabase Auth.
-- See https://supabase.com/docs/guides/auth/managing-user-data#using-triggers for more details.
create function public.handle_new_user()
returns trigger
set search_path = ''
as $$
begin
insert into public.profiles (id, full_name, avatar_url)
values (new.id, new.raw_user_meta_data->>'full_name', new.raw_user_meta_data->>'avatar_url');
return new;
end;
$$ language plpgsql security definer;
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
-- Set up Storage!
insert into storage.buckets (id, name)
values ('avatars', 'avatars');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage/security/access-control#policy-examples for more details.
create policy "Avatar images are publicly accessible." on storage.objects
for select using (bucket_id = 'avatars');
create policy "Anyone can upload an avatar." on storage.objects
for insert with check (bucket_id = 'avatars');
create policy "Anyone can update their own avatar." on storage.objects
for update using ((select auth.uid()) = owner) with check (bucket_id = 'avatars');
```
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=flutter).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=flutter), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
## Building the app
Let's start building the Flutter app from scratch.
### Initialize a Flutter app
We can use [`flutter create`](https://flutter.dev/docs/get-started/test-drive) to initialize
an app called `supabase_quickstart`:
```bash
flutter create supabase_quickstart
```
Then let's install the only additional dependency: [`supabase_flutter`](https://pub.dev/packages/supabase_flutter)
Copy and paste the following line in your pubspec.yaml to install the package:
```yaml
supabase_flutter: ^2.0.0
```
Run `flutter pub get` to install the dependencies.
### Setup deep links
Now that we have the dependencies installed let's setup deep links.
Setting up deep links is required to bring back the user to the app when they click on the magic link to sign in.
We can setup deep links with just a minor tweak on our Flutter application.
We have to use `io.supabase.flutterquickstart` as the scheme. In this example, we will use `login-callback` as the host for our deep link, but you can change it to whatever you would like.
First, add `io.supabase.flutterquickstart://login-callback/` as a new [redirect URL](/dashboard/project/_/auth/url-configuration) in the Dashboard.
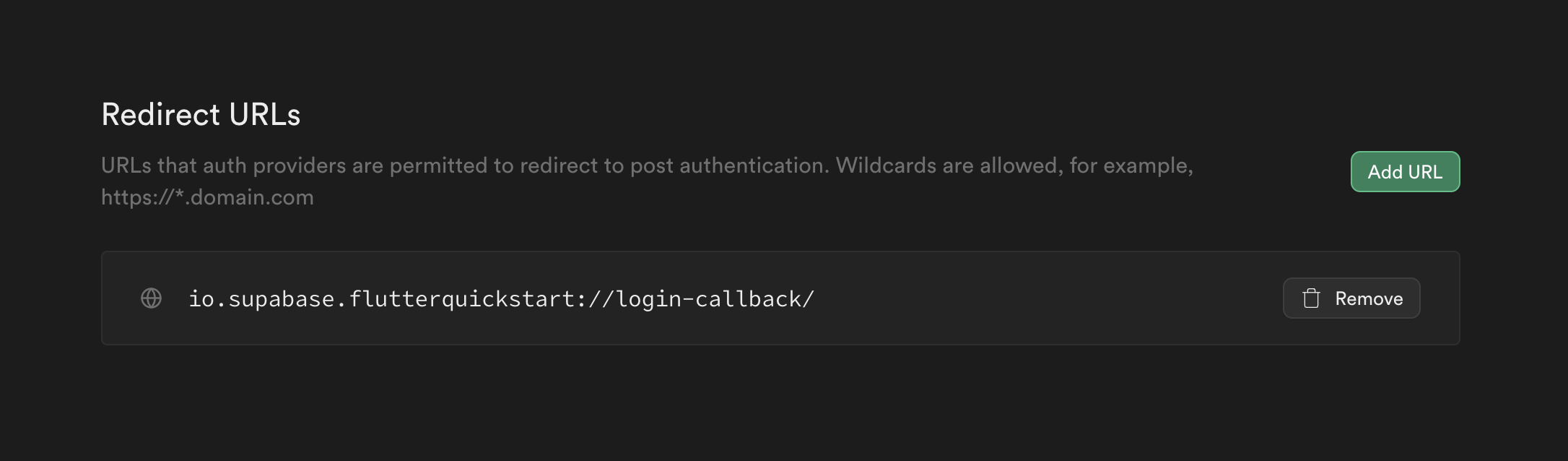
That is it on Supabase's end and the rest are platform specific settings:
Edit the `ios/Runner/Info.plist` file.
Add `CFBundleURLTypes` to enable deep linking:
```xml name=ios/Runner/Info.plist"
CFBundleURLTypes
CFBundleTypeRole
Editor
CFBundleURLSchemes
io.supabase.flutterquickstart
```
Edit the `android/app/src/main/AndroidManifest.xml` file.
Add an intent-filter to enable deep linking:
```xml name=android/app/src/main/AndroidManifest.xml
```
Supabase redirects do not work with Flutter's [default URL strategy](https://docs.flutter.dev/ui/navigation/url-strategies).
We can switch to the path URL strategy as follows:
```dart
import 'package:flutter_web_plugins/url_strategy.dart';
void main() {
usePathUrlStrategy();
runApp(ExampleApp());
}
```
### Main function
Now that we have deep links ready let's initialize the Supabase client inside our `main` function with the API credentials that you copied [earlier](#get-the-api-keys). These variables will be exposed on the app, and that's completely fine since we have [Row Level Security](/docs/guides/auth#row-level-security) enabled on our Database.
```dart name=lib/main.dart
import 'package:flutter/material.dart';
import 'package:supabase_flutter/supabase_flutter.dart';
Future main() async {
await Supabase.initialize(
url: 'YOUR_SUPABASE_URL',
publishableKey: 'YOUR_SUPABASE_PUBLISHABLE_KEY',
);
runApp(const MyApp());
}
final supabase = Supabase.instance.client;
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return const MaterialApp(title: 'Supabase Flutter');
}
}
extension ContextExtension on BuildContext {
void showSnackBar(String message, {bool isError = false}) {
ScaffoldMessenger.of(this).showSnackBar(
SnackBar(
content: Text(message),
backgroundColor: isError
? Theme.of(this).colorScheme.error
: Theme.of(this).snackBarTheme.backgroundColor,
),
);
}
}
```
Notice that we have a `showSnackBar` extension method that we will use to show snack bars in the app. You could define this method in a separate file and import it where needed, but for simplicity, we will define it here.
### Set up a login page
Let's create a Flutter widget to manage logins and sign ups. We will use Magic Links, so users can sign in with their email without using passwords.
Notice that this page sets up a listener on the user's auth state using `onAuthStateChange`. A new event will fire when the user comes back to the app by clicking their magic link, which this page can catch and redirect the user accordingly.
```dart name=lib/pages/login_page.dart
import 'dart:async';
import 'package:flutter/foundation.dart';
import 'package:flutter/material.dart';
import 'package:supabase_flutter/supabase_flutter.dart';
import 'package:supabase_quickstart/main.dart';
import 'package:supabase_quickstart/pages/account_page.dart';
class LoginPage extends StatefulWidget {
const LoginPage({super.key});
@override
State createState() => _LoginPageState();
}
class _LoginPageState extends State {
bool _isLoading = false;
bool _redirecting = false;
late final TextEditingController _emailController = TextEditingController();
late final StreamSubscription _authStateSubscription;
Future _signIn() async {
try {
setState(() {
_isLoading = true;
});
await supabase.auth.signInWithOtp(
email: _emailController.text.trim(),
emailRedirectTo:
kIsWeb ? null : 'io.supabase.flutterquickstart://login-callback/',
);
if (mounted) {
context.showSnackBar('Check your email for a login link!');
_emailController.clear();
}
} on AuthException catch (error) {
if (mounted) context.showSnackBar(error.message, isError: true);
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
} finally {
if (mounted) {
setState(() {
_isLoading = false;
});
}
}
}
@override
void initState() {
_authStateSubscription = supabase.auth.onAuthStateChange.listen(
(data) {
if (_redirecting) return;
final session = data.session;
if (session != null) {
_redirecting = true;
Navigator.of(context).pushReplacement(
MaterialPageRoute(builder: (context) => const AccountPage()),
);
}
},
onError: (error) {
if (error is AuthException) {
context.showSnackBar(error.message, isError: true);
} else {
context.showSnackBar('Unexpected error occurred', isError: true);
}
},
);
super.initState();
}
@override
void dispose() {
_emailController.dispose();
_authStateSubscription.cancel();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: const Text('Sign In')),
body: ListView(
padding: const EdgeInsets.symmetric(vertical: 18, horizontal: 12),
children: [
const Text('Sign in via the magic link with your email below'),
const SizedBox(height: 18),
TextFormField(
controller: _emailController,
decoration: const InputDecoration(labelText: 'Email'),
),
const SizedBox(height: 18),
ElevatedButton(
onPressed: _isLoading ? null : _signIn,
child: Text(_isLoading ? 'Sending...' : 'Send Magic Link'),
),
],
),
);
}
}
```
### Set up account page
After a user is signed in we can allow them to edit their profile details and manage their account.
Let's create a new widget called `account_page.dart` for that.
```dart name=lib/pages/account_page.dart"
import 'package:flutter/material.dart';
import 'package:supabase_flutter/supabase_flutter.dart';
import 'package:supabase_quickstart/main.dart';
import 'package:supabase_quickstart/pages/login_page.dart';
class AccountPage extends StatefulWidget {
const AccountPage({super.key});
@override
State createState() => _AccountPageState();
}
class _AccountPageState extends State {
final _usernameController = TextEditingController();
final _websiteController = TextEditingController();
String? _avatarUrl;
var _loading = true;
/// Called once a user id is received within `onAuthenticated()`
Future _getProfile() async {
setState(() {
_loading = true;
});
try {
final userId = supabase.auth.currentSession!.user.id;
final data =
await supabase.from('profiles').select().eq('id', userId).single();
_usernameController.text = (data['username'] ?? '') as String;
_websiteController.text = (data['website'] ?? '') as String;
_avatarUrl = (data['avatar_url'] ?? '') as String;
} on PostgrestException catch (error) {
if (mounted) context.showSnackBar(error.message, isError: true);
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
} finally {
if (mounted) {
setState(() {
_loading = false;
});
}
}
}
/// Called when user taps `Update` button
Future _updateProfile() async {
setState(() {
_loading = true;
});
final userName = _usernameController.text.trim();
final website = _websiteController.text.trim();
final user = supabase.auth.currentUser;
final updates = {
'id': user!.id,
'username': userName,
'website': website,
'updated_at': DateTime.now().toIso8601String(),
};
try {
await supabase.from('profiles').upsert(updates);
if (mounted) context.showSnackBar('Successfully updated profile!');
} on PostgrestException catch (error) {
if (mounted) context.showSnackBar(error.message, isError: true);
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
} finally {
if (mounted) {
setState(() {
_loading = false;
});
}
}
}
Future _signOut() async {
try {
await supabase.auth.signOut();
} on AuthException catch (error) {
if (mounted) context.showSnackBar(error.message, isError: true);
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
} finally {
if (mounted) {
Navigator.of(context).pushReplacement(
MaterialPageRoute(builder: (_) => const LoginPage()),
);
}
}
}
@override
void initState() {
super.initState();
_getProfile();
}
@override
void dispose() {
_usernameController.dispose();
_websiteController.dispose();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: const Text('Profile')),
body: ListView(
padding: const EdgeInsets.symmetric(vertical: 18, horizontal: 12),
children: [
TextFormField(
controller: _usernameController,
decoration: const InputDecoration(labelText: 'User Name'),
),
const SizedBox(height: 18),
TextFormField(
controller: _websiteController,
decoration: const InputDecoration(labelText: 'Website'),
),
const SizedBox(height: 18),
ElevatedButton(
onPressed: _loading ? null : _updateProfile,
child: Text(_loading ? 'Saving...' : 'Update'),
),
const SizedBox(height: 18),
TextButton(onPressed: _signOut, child: const Text('Sign Out')),
],
),
);
}
}
```
### Launch!
Now that we have all the components in place, let's update `lib/main.dart`.
The `home` of the `MaterialApp`, meaning the initial page shown to the user, will be the `LoginPage` if the user is not authenticated, and the `AccountPage` if the user is authenticated.
We also included some theming to make the app look a bit nicer.
```dart name=lib/main.dart
import 'package:flutter/material.dart';
import 'package:supabase_flutter/supabase_flutter.dart';
import 'package:supabase_quickstart/pages/account_page.dart';
import 'package:supabase_quickstart/pages/login_page.dart';
Future main() async {
await Supabase.initialize(
url: 'YOUR_SUPABASE_URL',
publishableKey: 'YOUR_SUPABASE_PUBLISHABLE_KEY',
);
runApp(const MyApp());
}
final supabase = Supabase.instance.client;
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Supabase Flutter',
theme: ThemeData.dark().copyWith(
primaryColor: Colors.green,
textButtonTheme: TextButtonThemeData(
style: TextButton.styleFrom(
foregroundColor: Colors.green,
),
),
elevatedButtonTheme: ElevatedButtonThemeData(
style: ElevatedButton.styleFrom(
foregroundColor: Colors.white,
backgroundColor: Colors.green,
),
),
),
home: supabase.auth.currentSession == null
? const LoginPage()
: const AccountPage(),
);
}
}
extension ContextExtension on BuildContext {
void showSnackBar(String message, {bool isError = false}) {
ScaffoldMessenger.of(this).showSnackBar(
SnackBar(
content: Text(message),
backgroundColor: isError
? Theme.of(this).colorScheme.error
: Theme.of(this).snackBarTheme.backgroundColor,
),
);
}
}
```
Once that's done, run this in a terminal window to launch on Android or iOS:
```bash
flutter run
```
Or for web, run the following command to launch it on `localhost:3000`
```bash
flutter run -d web-server --web-hostname localhost --web-port 3000
```
And then open the browser to [localhost:3000](http://localhost:3000) and you should see the completed app.
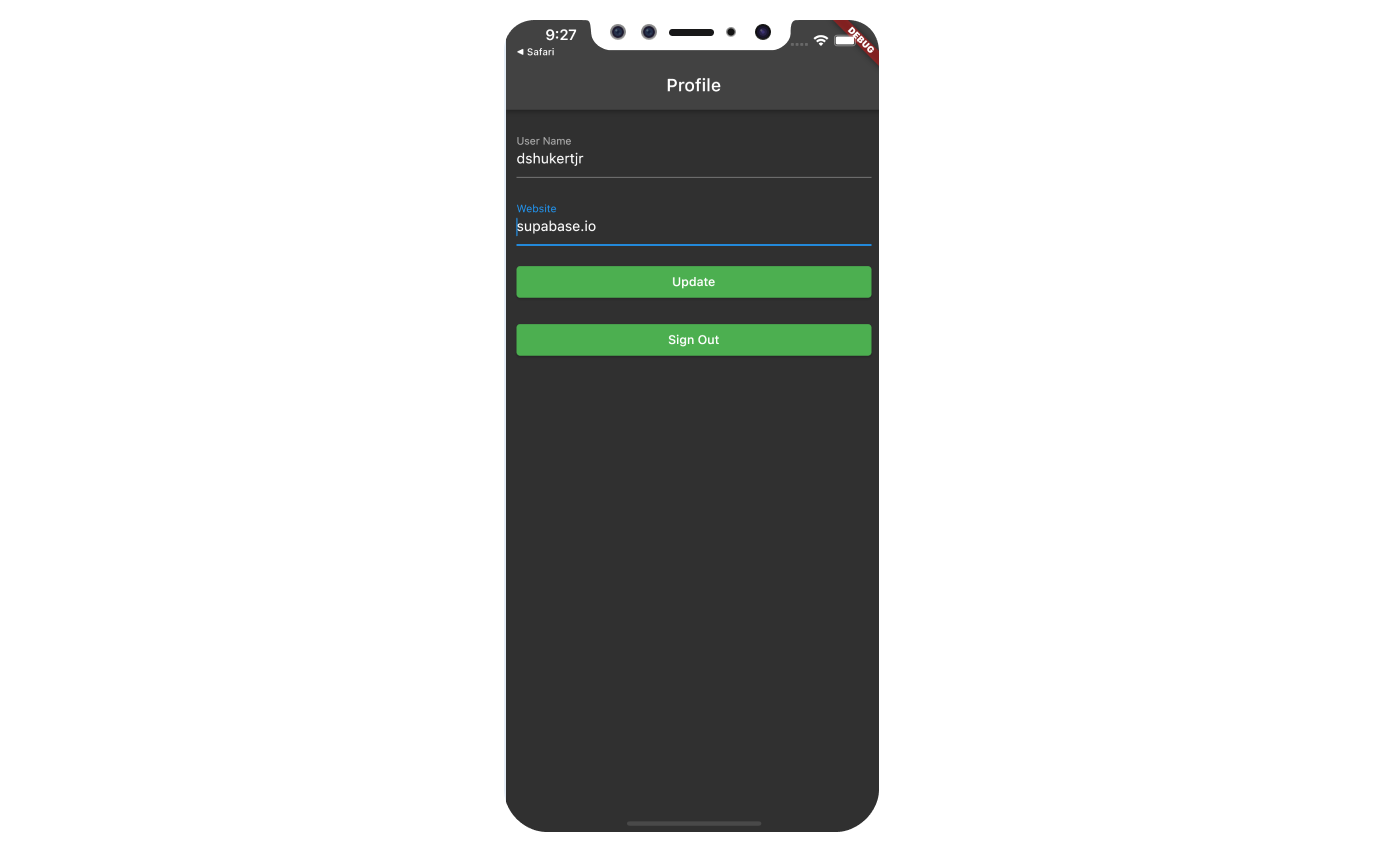
## Bonus: Profile photos
Every Supabase project is configured with [Storage](/docs/guides/storage) for managing large files like
photos and videos.
### Making sure we have a public bucket
We will be storing the image as a publicly sharable image.
Make sure your `avatars` bucket is set to public, and if it is not, change the publicity by clicking the dot menu that appears when you hover over the bucket name.
You should see an orange `Public` badge next to your bucket name if your bucket is set to public.
### Adding image uploading feature to account page
We will use [`image_picker`](https://pub.dev/packages/image_picker) plugin to select an image from the device.
Add the following line in your pubspec.yaml file to install `image_picker`:
```yaml
image_picker: ^1.0.5
```
Using [`image_picker`](https://pub.dev/packages/image_picker) requires some additional preparation depending on the platform.
Follow the instruction on README.md of [`image_picker`](https://pub.dev/packages/image_picker) on how to set it up for the platform you are using.
Once you are done with all of the above, it is time to dive into coding.
### Create an upload widget
Let's create an avatar for the user so that they can upload a profile photo.
We can start by creating a new component:
```dart name=lib/components/avatar.dart
import 'package:flutter/material.dart';
import 'package:image_picker/image_picker.dart';
import 'package:supabase_flutter/supabase_flutter.dart';
import 'package:supabase_quickstart/main.dart';
class Avatar extends StatefulWidget {
const Avatar({
super.key,
required this.imageUrl,
required this.onUpload,
});
final String? imageUrl;
final void Function(String) onUpload;
@override
State createState() => _AvatarState();
}
class _AvatarState extends State {
bool _isLoading = false;
@override
Widget build(BuildContext context) {
return Column(
children: [
if (widget.imageUrl == null || widget.imageUrl!.isEmpty)
Container(
width: 150,
height: 150,
color: Colors.grey,
child: const Center(
child: Text('No Image'),
),
)
else
Image.network(
widget.imageUrl!,
width: 150,
height: 150,
fit: BoxFit.cover,
),
ElevatedButton(
onPressed: _isLoading ? null : _upload,
child: const Text('Upload'),
),
],
);
}
Future _upload() async {
final picker = ImagePicker();
final imageFile = await picker.pickImage(
source: ImageSource.gallery,
maxWidth: 300,
maxHeight: 300,
);
if (imageFile == null) {
return;
}
setState(() => _isLoading = true);
try {
final bytes = await imageFile.readAsBytes();
final fileExt = imageFile.path.split('.').last;
final fileName = '${DateTime.now().toIso8601String()}.$fileExt';
final filePath = fileName;
await supabase.storage.from('avatars').uploadBinary(
filePath,
bytes,
fileOptions: FileOptions(contentType: imageFile.mimeType),
);
final imageUrlResponse = await supabase.storage
.from('avatars')
.createSignedUrl(filePath, 60 * 60 * 24 * 365 * 10);
widget.onUpload(imageUrlResponse);
} on StorageException catch (error) {
if (mounted) {
context.showSnackBar(error.message, isError: true);
}
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
}
setState(() => _isLoading = false);
}
}
```
### Add the new widget
And then we can add the widget to the Account page as well as some logic to update the `avatar_url` whenever the user uploads a new avatar.
```dart name=lib/pages/account_page.dart
import 'package:flutter/material.dart';
import 'package:supabase_flutter/supabase_flutter.dart';
import 'package:supabase_quickstart/components/avatar.dart';
import 'package:supabase_quickstart/main.dart';
import 'package:supabase_quickstart/pages/login_page.dart';
class AccountPage extends StatefulWidget {
const AccountPage({super.key});
@override
State createState() => _AccountPageState();
}
class _AccountPageState extends State {
final _usernameController = TextEditingController();
final _websiteController = TextEditingController();
String? _avatarUrl;
var _loading = true;
/// Called once a user id is received within `onAuthenticated()`
Future _getProfile() async {
setState(() {
_loading = true;
});
try {
final userId = supabase.auth.currentSession!.user.id;
final data =
await supabase.from('profiles').select().eq('id', userId).single();
_usernameController.text = (data['username'] ?? '') as String;
_websiteController.text = (data['website'] ?? '') as String;
_avatarUrl = (data['avatar_url'] ?? '') as String;
} on PostgrestException catch (error) {
if (mounted) context.showSnackBar(error.message, isError: true);
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
} finally {
if (mounted) {
setState(() {
_loading = false;
});
}
}
}
/// Called when user taps `Update` button
Future _updateProfile() async {
setState(() {
_loading = true;
});
final userName = _usernameController.text.trim();
final website = _websiteController.text.trim();
final user = supabase.auth.currentUser;
final updates = {
'id': user!.id,
'username': userName,
'website': website,
'updated_at': DateTime.now().toIso8601String(),
};
try {
await supabase.from('profiles').upsert(updates);
if (mounted) context.showSnackBar('Successfully updated profile!');
} on PostgrestException catch (error) {
if (mounted) context.showSnackBar(error.message, isError: true);
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
} finally {
if (mounted) {
setState(() {
_loading = false;
});
}
}
}
Future _signOut() async {
try {
await supabase.auth.signOut();
} on AuthException catch (error) {
if (mounted) context.showSnackBar(error.message, isError: true);
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
} finally {
if (mounted) {
Navigator.of(context).pushReplacement(
MaterialPageRoute(builder: (_) => const LoginPage()),
);
}
}
}
/// Called when image has been uploaded to Supabase storage from within Avatar widget
Future _onUpload(String imageUrl) async {
try {
final userId = supabase.auth.currentUser!.id;
await supabase.from('profiles').upsert({
'id': userId,
'avatar_url': imageUrl,
});
if (mounted) {
const SnackBar(
content: Text('Updated your profile image!'),
);
}
} on PostgrestException catch (error) {
if (mounted) context.showSnackBar(error.message, isError: true);
} catch (error) {
if (mounted) {
context.showSnackBar('Unexpected error occurred', isError: true);
}
}
if (!mounted) {
return;
}
setState(() {
_avatarUrl = imageUrl;
});
}
@override
void initState() {
super.initState();
_getProfile();
}
@override
void dispose() {
_usernameController.dispose();
_websiteController.dispose();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: const Text('Profile')),
body: ListView(
padding: const EdgeInsets.symmetric(vertical: 18, horizontal: 12),
children: [
Avatar(
imageUrl: _avatarUrl,
onUpload: _onUpload,
),
const SizedBox(height: 18),
TextFormField(
controller: _usernameController,
decoration: const InputDecoration(labelText: 'User Name'),
),
const SizedBox(height: 18),
TextFormField(
controller: _websiteController,
decoration: const InputDecoration(labelText: 'Website'),
),
const SizedBox(height: 18),
ElevatedButton(
onPressed: _loading ? null : _updateProfile,
child: Text(_loading ? 'Saving...' : 'Update'),
),
const SizedBox(height: 18),
TextButton(onPressed: _signOut, child: const Text('Sign Out')),
],
),
);
}
}
```
Congratulations, you've built a fully functional user management app using Flutter and Supabase!
## See also
* [Flutter Tutorial: building a Flutter chat app](/blog/flutter-tutorial-building-a-chat-app)
* [Flutter Tutorial - Part 2: Authentication and Authorization with RLS](/blog/flutter-authentication-and-authorization-with-rls)
# Build a User Management App with Ionic Angular
This tutorial demonstrates how to build a basic user management app. The app authenticates and identifies the user, stores their profile information in the database, and allows the user to log in, update their profile details, and upload a profile photo. The app uses:
* [Supabase Database](/docs/guides/database) - a Postgres database for storing your user data and [Row Level Security](/docs/guides/auth#row-level-security) so data is protected and users can only access their own information.
* [Supabase Auth](/docs/guides/auth) - allow users to sign up and log in.
* [Supabase Storage](/docs/guides/storage) - allow users to upload a profile photo.
If you get stuck while working through this guide, refer to the [full example on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/ionic-angular-user-management).
## Project setup
Before you start building you need to set up the Database and API. You can do this by starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. [Create a new project](/dashboard) in the Supabase Dashboard.
2. Enter your project details.
3. Wait for the new database to launch.
### Set up the database schema
Now set up the database schema. You can use the "User Management Starter" quickstart in the SQL Editor, or you can copy/paste the SQL from below and run it.
1. Go to the [SQL Editor](/dashboard/project/_/sql) page in the Dashboard.
2. Click **User Management Starter** under the **Community > Quickstarts** tab.
3. Click **Run**.
You can pull the database schema down to your local project by running the `db pull` command. Read the [local development docs](/docs/guides/cli/local-development#link-your-project) for detailed instructions.
```bash
supabase link --project-ref
# You can get from your project's dashboard URL: https://supabase.com/dashboard/project/
supabase db pull
```
When working locally you can run the following command to create a new migration file:
```bash
supabase migration new user_management_starter
```
```sql
-- Create a table for public profiles
create table profiles (
id uuid references auth.users not null primary key,
updated_at timestamp with time zone,
username text unique,
full_name text,
avatar_url text,
website text,
constraint username_length check (char_length(username) >= 3)
);
-- Grant the privileges roles need
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE ON public.profiles TO authenticated;
-- Set up Row Level Security (RLS)
-- See https://supabase.com/docs/guides/database/postgres/row-level-security for more details.
alter table profiles
enable row level security;
create policy "Public profiles are viewable by everyone." on profiles
for select using (true);
create policy "Users can insert their own profile." on profiles
for insert with check ((select auth.uid()) = id);
create policy "Users can update own profile." on profiles
for update using ((select auth.uid()) = id);
-- This trigger automatically creates a profile entry when a new user signs up via Supabase Auth.
-- See https://supabase.com/docs/guides/auth/managing-user-data#using-triggers for more details.
create function public.handle_new_user()
returns trigger
set search_path = ''
as $$
begin
insert into public.profiles (id, full_name, avatar_url)
values (new.id, new.raw_user_meta_data->>'full_name', new.raw_user_meta_data->>'avatar_url');
return new;
end;
$$ language plpgsql security definer;
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
-- Set up Storage!
insert into storage.buckets (id, name)
values ('avatars', 'avatars');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage/security/access-control#policy-examples for more details.
create policy "Avatar images are publicly accessible." on storage.objects
for select using (bucket_id = 'avatars');
create policy "Anyone can upload an avatar." on storage.objects
for insert with check (bucket_id = 'avatars');
create policy "Anyone can update their own avatar." on storage.objects
for update using ((select auth.uid()) = owner) with check (bucket_id = 'avatars');
```
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=ionicangular).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=ionicangular), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
## Building the app
Start building the Angular app from scratch.
### Initialize an Ionic Angular app
Use the [Ionic CLI](https://ionicframework.com/docs/cli) to initialize
an app called `supabase-ionic-angular`:
```bash
npm install -g @ionic/cli
ionic start supabase-ionic-angular blank --type angular
cd supabase-ionic-angular
```
Install the only additional dependency: [supabase-js](https://github.com/supabase/supabase-js)
```bash
npm install @supabase/supabase-js
```
And finally, save the environment variables in the `src/environments/environment.ts` file.
All you need are the API URL and the key that you copied [earlier](#get-api-details).
These variables will be exposed on the browser, and that's fine as [Row Level Security](/docs/guides/auth#row-level-security) is enabled on the Database.
```typescript name=src/environments/environment.ts
// This file can be replaced during build by using the `fileReplacements` array.
// `ng build --prod` replaces `environment.ts` with `environment.prod.ts`.
// The list of file replacements can be found in `angular.json`.
export const environment = {
production: false,
supabaseUrl: '',
supabasePublishableKey: '',
}
/*
* For easier debugging in development mode, you can import the following file
* to ignore zone related error stack frames such as `zone.run`, `zoneDelegate.invokeTask`.
*
* This import should be commented out in production mode because it will have a negative impact
* on performance if an error is thrown.
*/
// import 'zone.js/dist/zone-error'; // Included with Angular CLI.
```
Now that you have the API credentials in place, create a `SupabaseService` with `ionic g s supabase` to initialize the Supabase client and implement functions to communicate with the Supabase API.
```typescript name=src/app/supabase.service.ts
import { Injectable } from '@angular/core'
import { LoadingController, ToastController } from '@ionic/angular'
import { AuthChangeEvent, createClient, Session, SupabaseClient } from '@supabase/supabase-js'
import { environment } from '../environments/environment'
export interface Profile {
username: string
website: string
avatar_url: string
}
@Injectable({
providedIn: 'root',
})
export class SupabaseService {
private supabase: SupabaseClient
constructor(
private loadingCtrl: LoadingController,
private toastCtrl: ToastController
) {
this.supabase = createClient(environment.supabaseUrl, environment.supabasePublishableKey)
}
get user() {
return this.supabase.auth.getUser().then(({ data }) => data?.user)
}
get session() {
return this.supabase.auth.getClaims().then(async ({ data }) => {
if (!data?.claims) {
return null
}
const { data: userData } = await this.supabase.auth.getUser()
return userData?.user ? ({ user: userData.user } as Session) : null
})
}
get profile() {
return this.user
.then((user) => user?.id)
.then((id) =>
this.supabase.from('profiles').select(`username, website, avatar_url`).eq('id', id).single()
)
}
authChanges(callback: (event: AuthChangeEvent, session: Session | null) => void) {
return this.supabase.auth.onAuthStateChange(callback)
}
signIn(email: string) {
return this.supabase.auth.signInWithOtp({ email })
}
signOut() {
return this.supabase.auth.signOut()
}
async updateProfile(profile: Profile) {
const user = await this.user
const update = {
...profile,
id: user?.id,
updated_at: new Date(),
}
return this.supabase.from('profiles').upsert(update)
}
downLoadImage(path: string) {
return this.supabase.storage.from('avatars').download(path)
}
uploadAvatar(filePath: string, file: File) {
return this.supabase.storage.from('avatars').upload(filePath, file)
}
async createNotice(message: string) {
const toast = await this.toastCtrl.create({ message, duration: 5000 })
await toast.present()
}
createLoader() {
return this.loadingCtrl.create()
}
}
```
### Set up a login route
Set up a route to manage logins and signups. Use Magic Links so users can sign in with their email without using passwords.
Create a `LoginPage` with the `ionic g page login` Ionic CLI command.
```typescript name=src/app/login/login.page.ts
import { Component, OnInit } from '@angular/core'
import { SupabaseService } from '../supabase.service'
@Component({
selector: 'app-login',
standalone: false,
templateUrl: './login.page.html',
styleUrls: ['./login.page.scss'],
})
export class LoginPage {
email = ''
constructor(private readonly supabase: SupabaseService) {}
async handleLogin(event: any) {
event.preventDefault()
const loader = await this.supabase.createLoader()
await loader.present()
try {
const { error } = await this.supabase.signIn(this.email)
if (error) {
throw error
}
await loader.dismiss()
await this.supabase.createNotice('Check your email for the login link!')
} catch (error: any) {
await loader.dismiss()
await this.supabase.createNotice(error.error_description || error.message)
}
}
}
```
```
Login
Supabase + Ionic Angular
Sign in via magic link with your email below
```
### Account page
After a user is signed in, allow them to edit their profile details and manage their account.
Create an `AccountComponent` with `ionic g page account` Ionic CLI command.
```typescript name=src/app/account/account.page.ts
import { Component, OnInit } from '@angular/core'
import { Router } from '@angular/router'
import { Profile, SupabaseService } from '../supabase.service'
@Component({
selector: 'app-account',
standalone: false,
templateUrl: './account.page.html',
styleUrls: ['./account.page.scss'],
})
export class AccountPage implements OnInit {
profile: Profile = {
username: '',
avatar_url: '',
website: '',
}
email = ''
constructor(
private readonly supabase: SupabaseService,
private router: Router
) {}
ngOnInit() {
this.getEmail()
this.getProfile()
}
async getEmail() {
this.email = await this.supabase.user.then((user) => user?.email || '')
}
async getProfile() {
try {
const { data: profile, error, status } = await this.supabase.profile
if (error && status !== 406) {
throw error
}
if (profile) {
this.profile = profile
}
} catch (error: any) {
alert(error.message)
}
}
async updateProfile(avatar_url: string = '') {
const loader = await this.supabase.createLoader()
await loader.present()
try {
const { error } = await this.supabase.updateProfile({ ...this.profile, avatar_url })
if (error) {
throw error
}
await loader.dismiss()
await this.supabase.createNotice('Profile updated!')
} catch (error: any) {
await loader.dismiss()
await this.supabase.createNotice(error.message)
}
}
async signOut() {
console.log('testing?')
await this.supabase.signOut()
this.router.navigate(['/'], { replaceUrl: true })
}
}
```
```
Account
// ...
Log Out
```
### Launch!
Now that you have all the components in place, update `AppComponent`:
```typescript name=src/app/app.component.ts
import { Component } from '@angular/core'
import { Router } from '@angular/router'
import { SupabaseService } from './supabase.service'
@Component({
selector: 'app-root',
standalone: false,
templateUrl: 'app.component.html',
styleUrls: ['app.component.scss'],
})
export class AppComponent {
constructor(
private supabase: SupabaseService,
private router: Router
) {
this.supabase.authChanges((_, session) => {
console.log(session)
if (session?.user) {
this.router.navigate(['/account'])
}
})
}
}
```
Then update the `AppRoutingModule`
```typescript name=src/app/app-routing.module.ts
import { NgModule } from '@angular/core'
import { PreloadAllModules, RouterModule, Routes } from '@angular/router'
const routes: Routes = [
{
path: '',
loadChildren: () => import('./login/login.module').then((m) => m.LoginPageModule),
},
{
path: 'account',
loadChildren: () => import('./account/account.module').then((m) => m.AccountPageModule),
},
]
@NgModule({
imports: [RouterModule.forRoot(routes, { preloadingStrategy: PreloadAllModules })],
exports: [RouterModule],
})
export class AppRoutingModule {}
```
Once that's done, run this in a terminal window:
```bash
ionic serve
```
And the browser automatically opens to show the app.
## Bonus: Profile photos
Every Supabase project is configured with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
Let's create an avatar for the user so that they can upload a profile photo.
First, install two packages in order to interact with the user's camera.
```bash
npm install @ionic/pwa-elements @capacitor/camera
```
[Capacitor](https://capacitorjs.com) is a cross-platform native runtime from Ionic that enables web apps to be deployed through the app store and provides access to native device API.
Ionic PWA elements is a companion package that polyfills certain browser APIs that provide no user interface with custom Ionic UI.
With those packages installed, update `main.ts` to include an additional bootstrapping call for the Ionic PWA Elements.
```typescript name=src/main.ts
import { enableProdMode } from '@angular/core'
import { platformBrowserDynamic } from '@angular/platform-browser-dynamic'
import { AppModule } from './app/app.module'
import { environment } from './environments/environment'
import { defineCustomElements } from '@ionic/pwa-elements/loader'
defineCustomElements(window)
if (environment.production) {
enableProdMode()
}
platformBrowserDynamic()
.bootstrapModule(AppModule)
.catch((err) => console.log(err))
```
Then create an `AvatarComponent` with this Ionic CLI command:
```bash
ionic g component avatar --module=/src/app/account/account.module.ts --create-module
```
```typescript name=src/app/avatar/avatar.component.ts
import { Component, EventEmitter, Input, OnInit, Output } from '@angular/core'
import { DomSanitizer, SafeResourceUrl } from '@angular/platform-browser'
import { SupabaseService } from '../supabase.service'
import { Camera, CameraResultType } from '@capacitor/camera'
import { addIcons } from 'ionicons'
import { person } from 'ionicons/icons'
@Component({
selector: 'app-avatar',
standalone: false,
templateUrl: './avatar.component.html',
styleUrls: ['./avatar.component.scss'],
})
export class AvatarComponent {
_avatarUrl: SafeResourceUrl | undefined
uploading = false
@Input()
set avatarUrl(url: string | undefined) {
if (url) {
this.downloadImage(url)
}
}
@Output() upload = new EventEmitter()
constructor(
private readonly supabase: SupabaseService,
private readonly dom: DomSanitizer
) {
addIcons({ person })
}
async downloadImage(path: string) {
try {
const { data, error } = await this.supabase.downLoadImage(path)
if (error) {
throw error
}
this._avatarUrl = this.dom.bypassSecurityTrustResourceUrl(URL.createObjectURL(data!))
} catch (error: any) {
console.error('Error downloading image: ', error.message)
}
}
async uploadAvatar() {
const loader = await this.supabase.createLoader()
try {
const photo = await Camera.getPhoto({
resultType: CameraResultType.DataUrl,
})
const file = await fetch(photo.dataUrl!)
.then((res) => res.blob())
.then((blob) => new File([blob], 'my-file', { type: `image/${photo.format}` }))
const fileName = `${Math.random()}-${new Date().getTime()}.${photo.format}`
await loader.present()
const { error } = await this.supabase.uploadAvatar(fileName, file)
if (error) {
throw error
}
this.upload.emit(fileName)
} catch (error: any) {
this.supabase.createNotice(error.message)
} finally {
loader.dismiss()
}
}
}
```
```
```
```
:host {
display: block;
margin: auto;
min-height: 150px;
.avatar_wrapper {
margin: 16px auto 16px;
border-radius: 50%;
overflow: hidden;
height: 150px;
aspect-ratio: 1/1;
background: var(--ion-color-step-50);
border: thick solid var(--ion-color-step-200);
&:hover {
cursor: pointer;
}
ion-icon.no-avatar {
width: 100%;
height: 115%;
}
}
img {
display: block;
object-fit: cover;
width: 100%;
height: 100%;
}
}
```
### Update the account page
With the Avatar component created, update the account page template to include it:
```
Account
Log Out
```
At this stage, you have a fully functional application!
## See also
* [Authentication in Ionic Angular with Supabase](/blog/authentication-in-ionic-angular)
# Build a User Management App with Ionic React
This tutorial demonstrates how to build a basic user management app. The app authenticates and identifies the user, stores their profile information in the database, and allows the user to log in, update their profile details, and upload a profile photo. The app uses:
* [Supabase Database](/docs/guides/database) - a Postgres database for storing your user data and [Row Level Security](/docs/guides/auth#row-level-security) so data is protected and users can only access their own information.
* [Supabase Auth](/docs/guides/auth) - allow users to sign up and log in.
* [Supabase Storage](/docs/guides/storage) - allow users to upload a profile photo.

If you get stuck while working through this guide, refer to the [full example on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/ionic-react-user-management).
## Project setup
Before you start building you need to set up the Database and API. You can do this by starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. [Create a new project](/dashboard) in the Supabase Dashboard.
2. Enter your project details.
3. Wait for the new database to launch.
### Set up the database schema
Now set up the database schema. You can use the "User Management Starter" quickstart in the SQL Editor, or you can copy/paste the SQL from below and run it.
1. Go to the [SQL Editor](/dashboard/project/_/sql) page in the Dashboard.
2. Click **User Management Starter** under the **Community > Quickstarts** tab.
3. Click **Run**.
You can pull the database schema down to your local project by running the `db pull` command. Read the [local development docs](/docs/guides/cli/local-development#link-your-project) for detailed instructions.
```bash
supabase link --project-ref
# You can get from your project's dashboard URL: https://supabase.com/dashboard/project/
supabase db pull
```
When working locally you can run the following command to create a new migration file:
```bash
supabase migration new user_management_starter
```
```sql
-- Create a table for public profiles
create table profiles (
id uuid references auth.users not null primary key,
updated_at timestamp with time zone,
username text unique,
full_name text,
avatar_url text,
website text,
constraint username_length check (char_length(username) >= 3)
);
-- Grant the privileges roles need
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE ON public.profiles TO authenticated;
-- Set up Row Level Security (RLS)
-- See https://supabase.com/docs/guides/database/postgres/row-level-security for more details.
alter table profiles
enable row level security;
create policy "Public profiles are viewable by everyone." on profiles
for select using (true);
create policy "Users can insert their own profile." on profiles
for insert with check ((select auth.uid()) = id);
create policy "Users can update own profile." on profiles
for update using ((select auth.uid()) = id);
-- This trigger automatically creates a profile entry when a new user signs up via Supabase Auth.
-- See https://supabase.com/docs/guides/auth/managing-user-data#using-triggers for more details.
create function public.handle_new_user()
returns trigger
set search_path = ''
as $$
begin
insert into public.profiles (id, full_name, avatar_url)
values (new.id, new.raw_user_meta_data->>'full_name', new.raw_user_meta_data->>'avatar_url');
return new;
end;
$$ language plpgsql security definer;
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
-- Set up Storage!
insert into storage.buckets (id, name)
values ('avatars', 'avatars');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage/security/access-control#policy-examples for more details.
create policy "Avatar images are publicly accessible." on storage.objects
for select using (bucket_id = 'avatars');
create policy "Anyone can upload an avatar." on storage.objects
for insert with check (bucket_id = 'avatars');
create policy "Anyone can update their own avatar." on storage.objects
for update using ((select auth.uid()) = owner) with check (bucket_id = 'avatars');
```
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=ionicreact).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=ionicreact), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
## Building the app
Start building the React app from scratch.
### Initialize an Ionic React app
Use the [Ionic CLI](https://ionicframework.com/docs/cli) to initialize
an app called `supabase-ionic-react`:
```bash
npm install -g @ionic/cli
ionic start supabase-ionic-react blank --type react
cd supabase-ionic-react
```
Install the only additional dependency: [supabase-js](https://github.com/supabase/supabase-js)
```bash
npm install @supabase/supabase-js
```
Save the environment variables in a `.env`. You need the API URL and the key that you copied [earlier](#get-api-details).
```bash name=.env
VITE_SUPABASE_URL=YOUR_SUPABASE_URL
VITE_SUPABASE_KEY=YOUR_SUPABASE_KEY
```
With the API credentials in place, create a helper file to initialize the Supabase client. These variables will be exposed
in the browser, which is safe because they use a restricted publishable key and the SQL quickstart enables [Row Level Security](/docs/guides/auth#row-level-security) on the `profiles` table.
```typescript name=src/supabaseClient.ts
import { createClient } from '@supabase/supabase-js'
const supabaseUrl = import.meta.env.VITE_SUPABASE_URL
const supabasePublishableKey = import.meta.env.VITE_SUPABASE_PUBLISHABLE_KEY
if (!supabaseUrl || !supabasePublishableKey) {
throw new Error(
'Missing Supabase environment variables: VITE_SUPABASE_URL and VITE_SUPABASE_PUBLISHABLE_KEY must be set.'
)
}
export const supabase = createClient(supabaseUrl, supabasePublishableKey)
```
### Set up a login route
Set up a React component to manage logins and sign ups which uses Magic Links, so users can sign in with their email without using passwords.
```tsx name=src/pages/Login.tsx
import { useState } from 'react'
import type React from 'react'
import {
IonButton,
IonContent,
IonHeader,
IonInput,
IonItem,
IonList,
IonPage,
IonTitle,
IonToolbar,
useIonToast,
useIonLoading,
} from '@ionic/react'
import { supabase } from '../supabaseClient'
export function LoginPage() {
const [email, setEmail] = useState('')
const [showLoading, hideLoading] = useIonLoading()
const [showToast] = useIonToast()
const handleLogin = async (e: React.FormEvent) => {
e.preventDefault()
await showLoading()
try {
const { error } = await supabase.auth.signInWithOtp({ email })
if (error) throw error
await showToast({ message: 'Check your email for the login link!' })
} catch (e: any) {
await showToast({ message: e.error_description || e.message, duration: 5000 })
} finally {
await hideLoading()
}
}
return (
Login
Supabase + Ionic React
Sign in via magic link with your email below
)
}
```
### Account page
After a user signs in, they should be able to edit their profile details and manage their account.
Create a new component for that called `Account.tsx`.
```tsx name=src/pages/Account.tsx
import {
IonButton,
IonContent,
IonHeader,
IonInput,
IonItem,
IonLabel,
IonPage,
IonTitle,
IonToolbar,
useIonLoading,
useIonToast,
useIonRouter,
} from '@ionic/react'
import { useEffect, useState } from 'react'
// ...
import { supabase } from '../supabaseClient'
export function AccountPage() {
const [showLoading, hideLoading] = useIonLoading()
const [showToast] = useIonToast()
const router = useIonRouter()
const [email, setEmail] = useState('')
const [profile, setProfile] = useState({
username: '',
website: '',
avatar_url: '',
})
useEffect(() => {
getProfile()
}, [])
const getProfile = async () => {
await showLoading()
try {
const { data: authData } = await supabase.auth.getClaims()
if (!authData?.claims) throw new Error('No user logged in')
const { claims } = authData
setEmail(claims.email as string)
const { data, error, status } = await supabase
.from('profiles')
.select(`username, website, avatar_url`)
.eq('id', claims.sub)
.single()
if (error && status !== 406) {
throw error
}
if (data) {
setProfile({
username: data.username,
website: data.website,
avatar_url: data.avatar_url,
})
}
} catch (error: any) {
showToast({ message: error.message, duration: 5000 })
} finally {
await hideLoading()
}
}
const signOut = async () => {
await supabase.auth.signOut()
router.push('/', 'forward', 'replace')
}
const updateProfile = async (e?: any, avatar_url?: string) => {
e?.preventDefault()
await showLoading()
try {
const { data } = await supabase.auth.getClaims()
if (!data?.claims) throw new Error('No user logged in')
const { claims } = data
const updates = {
id: claims.sub,
...profile,
...(avatar_url !== undefined ? { avatar_url } : {}),
updated_at: new Date(),
}
const { error } = await supabase.from('profiles').upsert(updates)
if (error) {
throw error
}
// Ensure local profile state reflects the updated avatar URL
if (avatar_url !== undefined) {
setProfile((prev) => ({
...prev,
avatar_url,
}))
}
if (avatar_url !== undefined) {
setProfile((current) => ({
...current,
avatar_url,
}))
}
} catch (error: any) {
showToast({ message: error.message, duration: 5000 })
} finally {
await hideLoading()
}
}
return (
Account
{/* ... */}
Log Out
)
}
```
### Launch!
Now that you have all the components in place, update `App.tsx`:
```tsx name=src/App.tsx
import { Redirect, Route } from 'react-router-dom'
import { IonApp, IonRouterOutlet, setupIonicReact } from '@ionic/react'
import { IonReactRouter } from '@ionic/react-router'
import { supabase } from './supabaseClient'
import '@ionic/react/css/ionic.bundle.css'
/* Theme variables */
import './theme/variables.css'
import { LoginPage } from './pages/Login'
import { AccountPage } from './pages/Account'
import { useEffect, useState } from 'react'
import type { FC } from 'react'
setupIonicReact()
const App: FC = () => {
const [claims, setClaims] = useState(null)
useEffect(() => {
supabase.auth.getClaims().then(({ data }) => {
if (data) {
setClaims(data.claims)
}
})
const {
data: { subscription },
} = supabase.auth.onAuthStateChange(() => {
supabase.auth.getClaims().then(({ data }) => {
if (data) {
setClaims(data.claims)
}
})
})
return () => subscription.unsubscribe()
}, [])
return (
{
return claims ? :
}}
/>
(claims ? : )}
/>
)
}
export default App
```
Once that's done, run this in a terminal window:
```bash
ionic serve
```
Then open your browser to the URL printed by `ionic serve` (by default, [http://localhost:8100](http://localhost:8100)) and you should see the completed app.
## Bonus: Profile photos
Every Supabase project is configured with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
First install two packages in order to interact with the user's camera.
```bash
npm install @ionic/pwa-elements @capacitor/camera
```
[Capacitor](https://capacitorjs.com) is a cross platform native runtime from Ionic that enables web apps to be deployed through the app store and provides access to native device API.
Ionic PWA elements is a companion package that will polyfill certain browser APIs that provide no user interface with custom Ionic UI.
With those packages installed update `index.tsx` to include an additional bootstrapping call for the Ionic PWA Elements.
```tsx name=src/index.tsx
import React from 'react'
import { createRoot } from 'react-dom/client'
import App from './App'
import { defineCustomElements } from '@ionic/pwa-elements/loader'
defineCustomElements(window)
const container = document.getElementById('root')
const root = createRoot(container!)
root.render(
)
```
Then create an `AvatarComponent`.
```tsx name=src/components/Avatar.tsx
import { IonIcon } from '@ionic/react'
import { person } from 'ionicons/icons'
import { Camera, CameraResultType } from '@capacitor/camera'
import { useEffect, useState } from 'react'
import { supabase } from '../supabaseClient'
import './Avatar.css'
export function Avatar({
url,
onUpload,
}: {
url: string
onUpload: (file: string) => Promise
}) {
const [avatarUrl, setAvatarUrl] = useState()
useEffect(() => {
if (url) {
downloadImage(url)
}
}, [url])
const uploadAvatar = async () => {
try {
const photo = await Camera.getPhoto({
resultType: CameraResultType.DataUrl,
})
const file = await fetch(photo.dataUrl!)
.then((res) => res.blob())
.then((blob) => new File([blob], 'my-file', { type: `image/${photo.format}` }))
const fileName = `${Math.random()}-${new Date().getTime()}.${photo.format}`
const { error: uploadError } = await supabase.storage.from('avatars').upload(fileName, file)
if (uploadError) {
throw uploadError
}
await onUpload(fileName)
} catch (error) {
console.log(error)
}
}
const downloadImage = async (path: string) => {
try {
const { data, error } = await supabase.storage.from('avatars').download(path)
if (error) {
throw error
}
const url = URL.createObjectURL(data)
setAvatarUrl(url)
} catch (error: any) {
console.log('Error downloading image: ', error.message)
}
}
useEffect(() => {
return () => {
if (avatarUrl) {
URL.revokeObjectURL(avatarUrl)
}
}
}, [avatarUrl])
return (
)
}
```
### Add the new widget
And then add the widget to the Account page:
```tsx name=src/pages/Account.tsx
import {
IonButton,
IonContent,
IonHeader,
IonInput,
IonItem,
IonLabel,
IonPage,
IonTitle,
IonToolbar,
useIonLoading,
useIonToast,
useIonRouter,
} from '@ionic/react'
import { useEffect, useState } from 'react'
import { Avatar } from '../components/Avatar'
import { supabase } from '../supabaseClient'
export function AccountPage() {
const [showLoading, hideLoading] = useIonLoading()
const [showToast] = useIonToast()
const router = useIonRouter()
const [email, setEmail] = useState('')
const [profile, setProfile] = useState({
username: '',
website: '',
avatar_url: '',
})
useEffect(() => {
getProfile()
}, [])
const getProfile = async () => {
await showLoading()
try {
const { data: authData } = await supabase.auth.getClaims()
if (!authData?.claims) throw new Error('No user logged in')
const { claims } = authData
setEmail(claims.email as string)
const { data, error, status } = await supabase
.from('profiles')
.select(`username, website, avatar_url`)
.eq('id', claims.sub)
.single()
if (error && status !== 406) {
throw error
}
if (data) {
setProfile({
username: data.username,
website: data.website,
avatar_url: data.avatar_url,
})
}
} catch (error: any) {
showToast({ message: error.message, duration: 5000 })
} finally {
await hideLoading()
}
}
const signOut = async () => {
await supabase.auth.signOut()
router.push('/', 'forward', 'replace')
}
const updateProfile = async (e?: any, avatar_url?: string) => {
e?.preventDefault()
await showLoading()
try {
const { data } = await supabase.auth.getClaims()
if (!data?.claims) throw new Error('No user logged in')
const { claims } = data
const updates = {
id: claims.sub,
...profile,
...(avatar_url !== undefined ? { avatar_url } : {}),
updated_at: new Date(),
}
const { error } = await supabase.from('profiles').upsert(updates)
if (error) {
throw error
}
// Ensure local profile state reflects the updated avatar URL
if (avatar_url !== undefined) {
setProfile((prev) => ({
...prev,
avatar_url,
}))
}
if (avatar_url !== undefined) {
setProfile((current) => ({
...current,
avatar_url,
}))
}
} catch (error: any) {
showToast({ message: error.message, duration: 5000 })
} finally {
await hideLoading()
}
}
return (
Account
updateProfile(undefined, fileName)}
>
Log Out
)
}
```
At this stage you have a fully functional application!
# Build a User Management App with Ionic Vue
This tutorial demonstrates how to build a basic user management app. The app authenticates and identifies the user, stores their profile information in the database, and allows the user to log in, update their profile details, and upload a profile photo. The app uses:
* [Supabase Database](/docs/guides/database) - a Postgres database for storing your user data and [Row Level Security](/docs/guides/auth#row-level-security) so data is protected and users can only access their own information.
* [Supabase Auth](/docs/guides/auth) - allow users to sign up and log in.
* [Supabase Storage](/docs/guides/storage) - allow users to upload a profile photo.

If you get stuck while working through this guide, refer to the [full example on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/ionic-vue-user-management).
## Project setup
Before you start building you need to set up the Database and API. You can do this by starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. [Create a new project](/dashboard) in the Supabase Dashboard.
2. Enter your project details.
3. Wait for the new database to launch.
### Set up the database schema
Now set up the database schema. You can use the "User Management Starter" quickstart in the SQL Editor, or you can copy/paste the SQL from below and run it.
1. Go to the [SQL Editor](/dashboard/project/_/sql) page in the Dashboard.
2. Click **User Management Starter** under the **Community > Quickstarts** tab.
3. Click **Run**.
You can pull the database schema down to your local project by running the `db pull` command. Read the [local development docs](/docs/guides/cli/local-development#link-your-project) for detailed instructions.
```bash
supabase link --project-ref
# You can get from your project's dashboard URL: https://supabase.com/dashboard/project/
supabase db pull
```
When working locally you can run the following command to create a new migration file:
```bash
supabase migration new user_management_starter
```
```sql
-- Create a table for public profiles
create table profiles (
id uuid references auth.users not null primary key,
updated_at timestamp with time zone,
username text unique,
full_name text,
avatar_url text,
website text,
constraint username_length check (char_length(username) >= 3)
);
-- Grant the privileges roles need
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE ON public.profiles TO authenticated;
-- Set up Row Level Security (RLS)
-- See https://supabase.com/docs/guides/database/postgres/row-level-security for more details.
alter table profiles
enable row level security;
create policy "Public profiles are viewable by everyone." on profiles
for select using (true);
create policy "Users can insert their own profile." on profiles
for insert with check ((select auth.uid()) = id);
create policy "Users can update own profile." on profiles
for update using ((select auth.uid()) = id);
-- This trigger automatically creates a profile entry when a new user signs up via Supabase Auth.
-- See https://supabase.com/docs/guides/auth/managing-user-data#using-triggers for more details.
create function public.handle_new_user()
returns trigger
set search_path = ''
as $$
begin
insert into public.profiles (id, full_name, avatar_url)
values (new.id, new.raw_user_meta_data->>'full_name', new.raw_user_meta_data->>'avatar_url');
return new;
end;
$$ language plpgsql security definer;
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
-- Set up Storage!
insert into storage.buckets (id, name)
values ('avatars', 'avatars');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage/security/access-control#policy-examples for more details.
create policy "Avatar images are publicly accessible." on storage.objects
for select using (bucket_id = 'avatars');
create policy "Anyone can upload an avatar." on storage.objects
for insert with check (bucket_id = 'avatars');
create policy "Anyone can update their own avatar." on storage.objects
for update using ((select auth.uid()) = owner) with check (bucket_id = 'avatars');
```
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=vuejs).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=vuejs), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
## Building the app
Start by building the Vue app from scratch.
### Initialize an Ionic Vue app
Use the [Ionic CLI](https://ionicframework.com/docs/cli) to initialize an app called `supabase-ionic-vue`:
```bash
npm install -g @ionic/cli
ionic start supabase-ionic-vue blank --type vue
cd supabase-ionic-vue
```
Install the only additional dependency: [supabase-js](https://github.com/supabase/supabase-js)
```bash
npm install @supabase/supabase-js
```
Save the environment variables in a `.env` file, including the API URL and key that you copied [earlier](#get-api-details).
```bash name=.env
VUE_APP_SUPABASE_URL=YOUR_SUPABASE_URL
VUE_APP_SUPABASE_KEY=YOUR_SUPABASE_KEY
```
With the API credentials in place, create a helper file to initialize the Supabase client. These variables will be exposed on the browser, and that's fine since Supabase enables [Row Level Security](/docs/guides/auth#row-level-security) on Databases by default.
```typescript name=src/supabase.ts
import { createClient } from '@supabase/supabase-js'
const supabaseUrl = process.env.VUE_APP_SUPABASE_URL
const supabasePublishableKey = process.env.VUE_APP_SUPABASE_PUBLISHABLE_KEY
if (!supabaseUrl) {
throw new Error(
'Environment variable VUE_APP_SUPABASE_URL is not set. Please define it before starting the application.'
)
}
if (!supabasePublishableKey) {
throw new Error(
'Environment variable VUE_APP_SUPABASE_PUBLISHABLE_KEY is not set. Please define it before starting the application.'
)
}
export const supabase = createClient(supabaseUrl, supabasePublishableKey)
```
### Set up a login route
Create a Vue component to manage logins and sign ups that uses Magic Links, so users can sign in with their email without using passwords.
```
Login
Supabase + Ionic Vue
Sign in via magic link with your email below
{{ email }}
```
### Account page
After a user has signed in, let them edit their profile details and manage their account with a new component called `Account.vue`.
```
Account
// ...
Log Out
```
### Launch!
With all the components in place, update `App.vue` and the app routes:
```typescript name=src/router/index.ts
import { createRouter, createWebHistory } from '@ionic/vue-router'
import { RouteRecordRaw } from 'vue-router'
import LoginPage from '../views/Login.vue'
import AccountPage from '../views/Account.vue'
const routes: Array = [
{
path: '/',
name: 'Login',
component: LoginPage,
},
{
path: '/account',
name: 'Account',
component: AccountPage,
},
]
const router = createRouter({
history: createWebHistory(process.env.BASE_URL),
routes,
})
export default router
```
```
```
Once that's done, run this in a terminal window:
```bash
ionic serve
```
And then open the browser to [localhost:8100](http://localhost:8100) and you should see the completed app.
## Bonus: Profile photos
Every Supabase project is configured with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
First install two packages to interact with the user's camera.
```bash
npm install @ionic/pwa-elements @capacitor/camera
```
[Capacitor](https://capacitorjs.com) is a cross-platform native runtime from Ionic that enables you to deploy web apps to app stores and provides access to native device API.
Ionic PWA elements is a companion package that polyfills certain browser APIs that provide no user interface with custom Ionic UI.
With those packages installed, update `main.ts` to include an additional bootstrapping call for the Ionic PWA Elements.
```typescript name=src/main.ts
import { createApp } from 'vue'
import App from './App.vue'
import router from './router'
import { IonicVue } from '@ionic/vue'
/* Core CSS required for Ionic components to work properly */
import '@ionic/vue/css/ionic.bundle.css'
/* Theme variables */
import './theme/variables.css'
import { defineCustomElements } from '@ionic/pwa-elements/loader'
defineCustomElements(window)
const app = createApp(App).use(IonicVue).use(router)
router.isReady().then(() => {
app.mount('#app')
})
```
Then create an `AvatarComponent`.
```
```
### Add the new widget
And then add the widget to the Account page:
```
Account
Log Out
```
At this stage you have a fully functional application!
# Build a Product Management Android App with Jetpack Compose
This tutorial demonstrates how to build a basic product management app. The app demonstrates management operations, photo upload, account creation and authentication using:
* [Supabase Database](/docs/guides/database) - a Postgres database for storing your user data and [Row Level Security](/docs/guides/auth#row-level-security) so data is protected and users can only access their own information.
* [Supabase Auth](/docs/guides/auth) - users log in through magic links sent to their email (without having to set up a password).
* [Supabase Storage](/docs/guides/storage) - users can upload a profile photo.
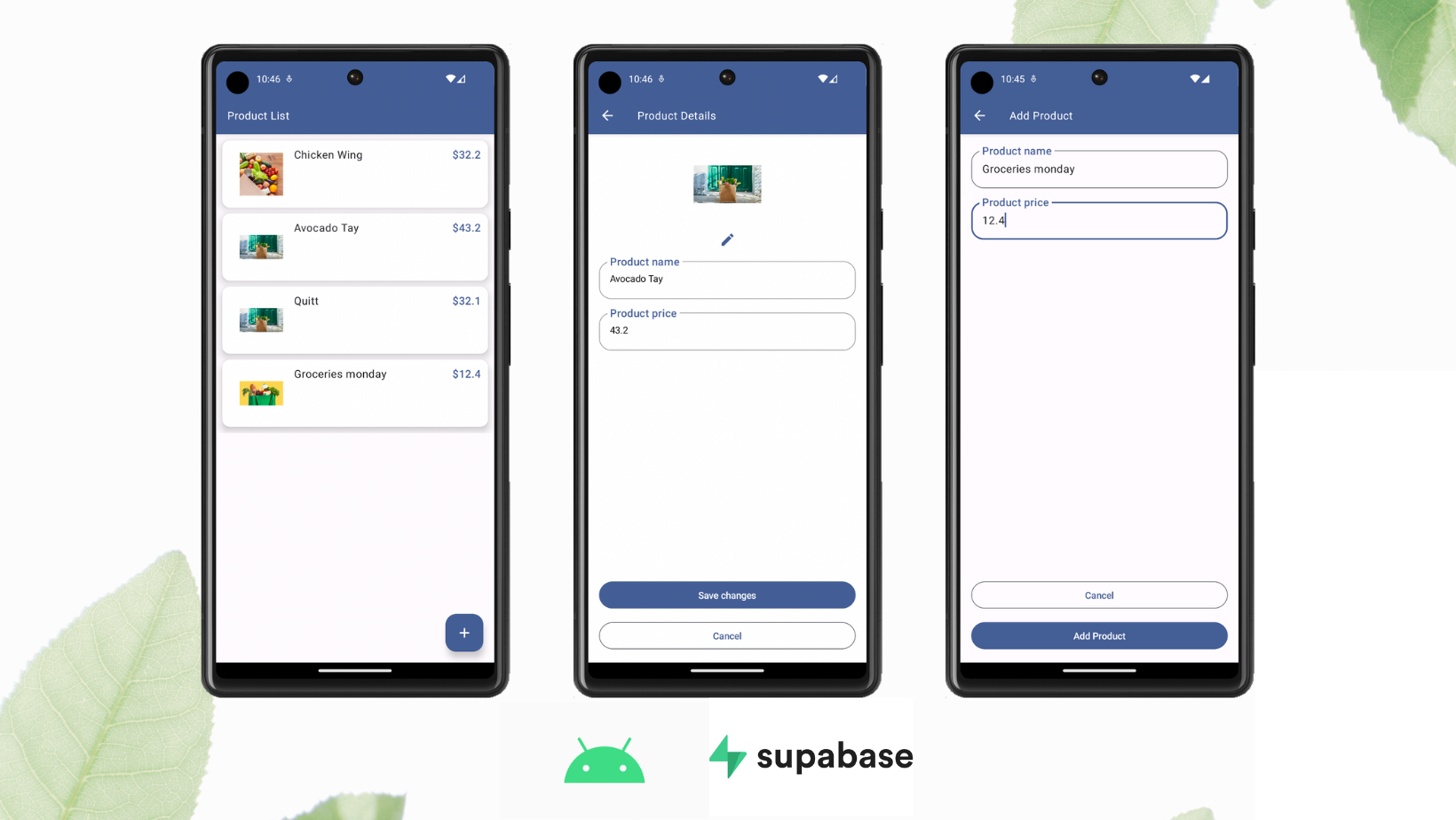
If you get stuck while working through this guide, refer to the [full example on GitHub](https://github.com/hieuwu/product-sample-supabase-kt).
## Project setup
Before we start building we're going to set up our Database and API. This is as simple as starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. [Create a new project](https://app.supabase.com) in the Supabase Dashboard.
2. Enter your project details.
3. Wait for the new database to launch.
### Set up the database schema
Now we are going to set up the database schema. You can just copy/paste the SQL from below and run it yourself.
{/*
1. Go to the [SQL Editor](https://app.supabase.com/project/_/sql) page in the Dashboard.
2. Click **Product Management**.
3. Click **Run**.
*/}
```sql
-- Create a table for public profiles
create table
public.products (
id uuid not null default gen_random_uuid (),
name text not null,
price real not null,
image text null,
constraint products_pkey primary key (id)
) tablespace pg_default;
-- Set up Storage!
insert into storage.buckets (id, name)
values ('Product Image', 'Product Image');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage/security/access-control#policy-examples for more details.
CREATE POLICY "Enable read access for all users" ON "storage"."objects"
AS PERMISSIVE FOR SELECT
TO public
USING (true)
CREATE POLICY "Enable insert for all users" ON "storage"."objects"
AS PERMISSIVE FOR INSERT
TO authenticated, anon
WITH CHECK (true)
CREATE POLICY "Enable update for all users" ON "storage"."objects"
AS PERMISSIVE FOR UPDATE
TO public
USING (true)
WITH CHECK (true)
```
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=androidkotlin).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=androidkotlin), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
### Set up Google authentication
From the [Google Console](https://console.developers.google.com/apis/library), create a new project and add OAuth2 credentials.
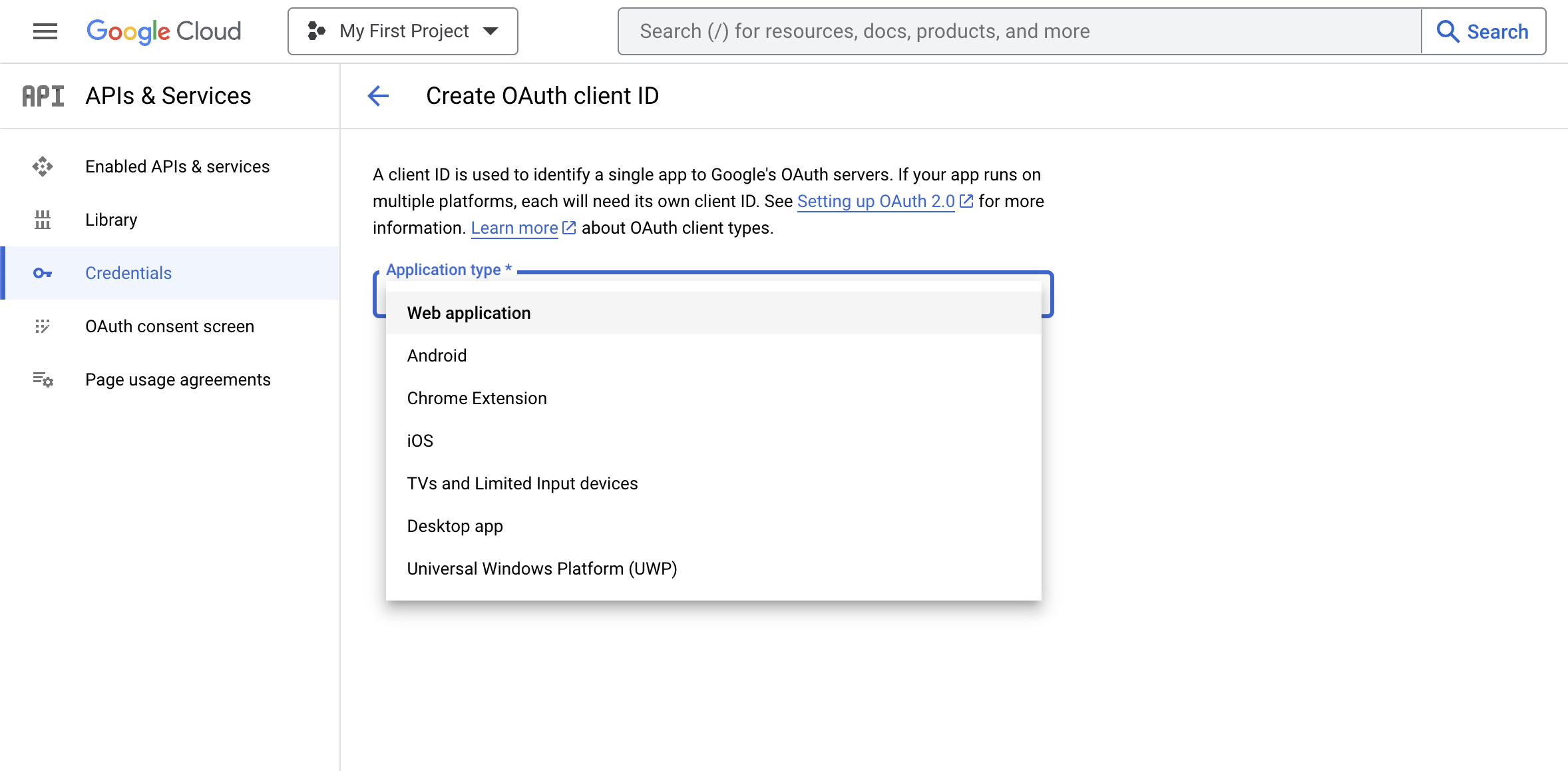
In your [Supabase Auth settings](https://app.supabase.com/project/_/auth/providers) enable Google as a provider and set the required credentials as outlined in the [auth docs](/docs/guides/auth/social-login/auth-google).
## Building the app
### Create new Android project
Open Android Studio > New Project > Base Activity (Jetpack Compose).
### Set up API key and secret securely
#### Create local environment secret
Create or edit the `local.properties` file at the root (same level as `build.gradle`) of your project.
> **Note**: Do not commit this file to your source control, for example, by adding it to your `.gitignore` file!
```kotlin
SUPABASE_PUBLISHABLE_KEY=YOUR_SUPABASE_PUBLISHABLE_KEY
SUPABASE_URL=YOUR_SUPABASE_URL
```
#### Read and set value to `BuildConfig`
In your `build.gradle` (app) file, create a `Properties` object and read the values from your `local.properties` file by calling the `buildConfigField` method:
```kotlin
defaultConfig {
applicationId "com.example.manageproducts"
minSdkVersion 22
targetSdkVersion 33
versionCode 5
versionName "1.0"
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
// Set value part
Properties properties = new Properties()
properties.load(project.rootProject.file("local.properties").newDataInputStream())
buildConfigField("String", "SUPABASE_PUBLISHABLE_KEY", "\"${properties.getProperty("SUPABASE_PUBLISHABLE_KEY")}\"")
buildConfigField("String", "SECRET", "\"${properties.getProperty("SECRET")}\"")
buildConfigField("String", "SUPABASE_URL", "\"${properties.getProperty("SUPABASE_URL")}\"")
}
```
#### Use value from `BuildConfig`
Read the value from `BuildConfig`:
```kotlin
val url = BuildConfig.SUPABASE_URL
val apiKey = BuildConfig.SUPABASE_PUBLISHABLE_KEY
```
### Set up Supabase dependencies
In the `build.gradle` (app) file, add these dependencies then press "Sync now." Replace the dependency version placeholders `$supabase_version` and `$ktor_version` with their respective latest versions.
```kotlin
implementation "io.github.jan-tennert.supabase:postgrest-kt:$supabase_version"
implementation "io.github.jan-tennert.supabase:storage-kt:$supabase_version"
implementation "io.github.jan-tennert.supabase:auth-kt:$supabase_version"
implementation "io.ktor:ktor-client-android:$ktor_version"
implementation "io.ktor:ktor-client-core:$ktor_version"
implementation "io.ktor:ktor-utils:$ktor_version"
```
Also in the `build.gradle` (app) file, add the plugin for serialization. The version of this plugin should be the same as your Kotlin version.
```kotlin
plugins {
...
id 'org.jetbrains.kotlin.plugin.serialization' version '$kotlin_version'
...
}
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Set up Hilt for dependency injection
In the `build.gradle` (app) file, add the following:
```kotlin
implementation "com.google.dagger:hilt-android:$hilt_version"
annotationProcessor "com.google.dagger:hilt-compiler:$hilt_version"
implementation("androidx.hilt:hilt-navigation-compose:1.0.0")
```
Create a new `ManageProductApplication.kt` class extending Application with `@HiltAndroidApp` annotation:
```kotlin
// ManageProductApplication.kt
@HiltAndroidApp
class ManageProductApplication: Application()
```
Open the `AndroidManifest.xml` file, update name property of Application tag:
```xml
```
Create the `MainActivity`:
```kotlin
@AndroidEntryPoint
class MainActivity : ComponentActivity() {
//This will come later
}
```
{/* supa-mdx-lint-disable-next-line Rule001HeadingCase */}
### Provide Supabase instances with Hilt
To make the app easier to test, create a `SupabaseModule.kt` file as follows:
```kotlin
@InstallIn(SingletonComponent::class)
@Module
object SupabaseModule {
@Provides
@Singleton
fun provideSupabaseClient(): SupabaseClient {
return createSupabaseClient(
supabaseUrl = BuildConfig.SUPABASE_URL,
supabaseKey = BuildConfig.SUPABASE_PUBLISHABLE_KEY
) {
install(Postgrest)
install(Auth) {
flowType = FlowType.PKCE
scheme = "app"
host = "supabase.com"
}
install(Storage)
}
}
@Provides
@Singleton
fun provideSupabaseDatabase(client: SupabaseClient): Postgrest {
return client.postgrest
}
@Provides
@Singleton
fun provideSupabaseAuth(client: SupabaseClient): Auth {
return client.auth
}
@Provides
@Singleton
fun provideSupabaseStorage(client: SupabaseClient): Storage {
return client.storage
}
}
```
### Create a data transfer object
Create a `ProductDto.kt` class and use annotations to parse data from Supabase:
```kotlin
@Serializable
data class ProductDto(
@SerialName("name")
val name: String,
@SerialName("price")
val price: Double,
@SerialName("image")
val image: String?,
@SerialName("id")
val id: String,
)
```
Create a Domain object in `Product.kt` expose the data in your view:
```kotlin
data class Product(
val id: String,
val name: String,
val price: Double,
val image: String?
)
```
### Implement repositories
Create a `ProductRepository` interface and its implementation named `ProductRepositoryImpl`. This holds the logic to interact with data sources from Supabase. Do the same with the `AuthenticationRepository`.
Create the Product Repository:
```kotlin
interface ProductRepository {
suspend fun createProduct(product: Product): Boolean
suspend fun getProducts(): List?
suspend fun getProduct(id: String): ProductDto
suspend fun deleteProduct(id: String)
suspend fun updateProduct(
id: String, name: String, price: Double, imageName: String, imageFile: ByteArray
)
}
```
```kotlin
class ProductRepositoryImpl @Inject constructor(
private val postgrest: Postgrest,
private val storage: Storage,
) : ProductRepository {
override suspend fun createProduct(product: Product): Boolean {
return try {
withContext(Dispatchers.IO) {
val productDto = ProductDto(
name = product.name,
price = product.price,
)
postgrest.from("products").insert(productDto)
true
}
true
} catch (e: java.lang.Exception) {
throw e
}
}
override suspend fun getProducts(): List? {
return withContext(Dispatchers.IO) {
val result = postgrest.from("products")
.select().decodeList()
result
}
}
override suspend fun getProduct(id: String): ProductDto {
return withContext(Dispatchers.IO) {
postgrest.from("products").select {
filter {
eq("id", id)
}
}.decodeSingle()
}
}
override suspend fun deleteProduct(id: String) {
return withContext(Dispatchers.IO) {
postgrest.from("products").delete {
filter {
eq("id", id)
}
}
}
}
override suspend fun updateProduct(
id: String,
name: String,
price: Double,
imageName: String,
imageFile: ByteArray
) {
withContext(Dispatchers.IO) {
if (imageFile.isNotEmpty()) {
val imageUrl =
storage.from("Product%20Image").upload(
path = "$imageName.png",
data = imageFile,
upsert = true
)
postgrest.from("products").update({
set("name", name)
set("price", price)
set("image", buildImageUrl(imageFileName = imageUrl))
}) {
filter {
eq("id", id)
}
}
} else {
postgrest.from("products").update({
set("name", name)
set("price", price)
}) {
filter {
eq("id", id)
}
}
}
}
}
// Because I named the bucket as "Product Image" so when it turns to an url, it is "%20"
// For better approach, you should create your bucket name without space symbol
private fun buildImageUrl(imageFileName: String) =
"${BuildConfig.SUPABASE_URL}/storage/v1/object/public/${imageFileName}".replace(" ", "%20")
}
```
Create the Authentication Repository:
```kotlin
interface AuthenticationRepository {
suspend fun signIn(email: String, password: String): Boolean
suspend fun signUp(email: String, password: String): Boolean
suspend fun signInWithGoogle(): Boolean
}
```
```kotlin
class AuthenticationRepositoryImpl @Inject constructor(
private val auth: Auth
) : AuthenticationRepository {
override suspend fun signIn(email: String, password: String): Boolean {
return try {
auth.signInWith(Email) {
this.email = email
this.password = password
}
true
} catch (e: Exception) {
false
}
}
override suspend fun signUp(email: String, password: String): Boolean {
return try {
auth.signUpWith(Email) {
this.email = email
this.password = password
}
true
} catch (e: Exception) {
false
}
}
override suspend fun signInWithGoogle(): Boolean {
return try {
auth.signInWith(Google)
true
} catch (e: Exception) {
false
}
}
}
```
### Implement screens
To navigate screens, use the AndroidX navigation library. For routes, implement a `Destination` interface:
```kotlin
interface Destination {
val route: String
val title: String
}
object ProductListDestination : Destination {
override val route = "product_list"
override val title = "Product List"
}
object ProductDetailsDestination : Destination {
override val route = "product_details"
override val title = "Product Details"
const val productId = "product_id"
val arguments = listOf(navArgument(name = productId) {
type = NavType.StringType
})
fun createRouteWithParam(productId: String) = "$route/${productId}"
}
object AddProductDestination : Destination {
override val route = "add_product"
override val title = "Add Product"
}
object AuthenticationDestination: Destination {
override val route = "authentication"
override val title = "Authentication"
}
object SignUpDestination: Destination {
override val route = "signup"
override val title = "Sign Up"
}
```
This will help later for navigating between screens.
Create a `ProductListViewModel`:
```kotlin
@HiltViewModel
class ProductListViewModel @Inject constructor(
private val productRepository: ProductRepository,
) : ViewModel() {
private val _productList = MutableStateFlow?>(listOf())
val productList: Flow?> = _productList
private val _isLoading = MutableStateFlow(false)
val isLoading: Flow = _isLoading
init {
getProducts()
}
fun getProducts() {
viewModelScope.launch {
val products = productRepository.getProducts()
_productList.emit(products?.map { it -> it.asDomainModel() })
}
}
fun removeItem(product: Product) {
viewModelScope.launch {
val newList = mutableListOf().apply { _productList.value?.let { addAll(it) } }
newList.remove(product)
_productList.emit(newList.toList())
// Call api to remove
productRepository.deleteProduct(id = product.id)
// Then fetch again
getProducts()
}
}
private fun ProductDto.asDomainModel(): Product {
return Product(
id = this.id,
name = this.name,
price = this.price,
image = this.image
)
}
}
```
Create the `ProductListScreen.kt`:
```kotlin
@OptIn(ExperimentalMaterial3Api::class, ExperimentalMaterialApi::class)
@Composable
fun ProductListScreen(
modifier: Modifier = Modifier,
navController: NavController,
viewModel: ProductListViewModel = hiltViewModel(),
) {
val isLoading by viewModel.isLoading.collectAsState(initial = false)
val swipeRefreshState = rememberSwipeRefreshState(isRefreshing = isLoading)
SwipeRefresh(state = swipeRefreshState, onRefresh = { viewModel.getProducts() }) {
Scaffold(
topBar = {
TopAppBar(
backgroundColor = MaterialTheme.colorScheme.primary,
title = {
Text(
text = stringResource(R.string.product_list_text_screen_title),
color = MaterialTheme.colorScheme.onPrimary,
)
},
)
},
floatingActionButton = {
AddProductButton(onClick = { navController.navigate(AddProductDestination.route) })
}
) { padding ->
val productList = viewModel.productList.collectAsState(initial = listOf()).value
if (!productList.isNullOrEmpty()) {
LazyColumn(
modifier = modifier.padding(padding),
contentPadding = PaddingValues(5.dp)
) {
itemsIndexed(
items = productList,
key = { _, product -> product.name }) { _, item ->
val state = rememberDismissState(
confirmStateChange = {
if (it == DismissValue.DismissedToStart) {
// Handle item removed
viewModel.removeItem(item)
}
true
}
)
SwipeToDismiss(
state = state,
background = {
val color by animateColorAsState(
targetValue = when (state.dismissDirection) {
DismissDirection.StartToEnd -> MaterialTheme.colorScheme.primary
DismissDirection.EndToStart -> MaterialTheme.colorScheme.primary.copy(
alpha = 0.2f
)
null -> Color.Transparent
}
)
Box(
modifier = modifier
.fillMaxSize()
.background(color = color)
.padding(16.dp),
) {
Icon(
imageVector = Icons.Filled.Delete,
contentDescription = null,
tint = MaterialTheme.colorScheme.primary,
modifier = modifier.align(Alignment.CenterEnd)
)
}
},
dismissContent = {
ProductListItem(
product = item,
modifier = modifier,
onClick = {
navController.navigate(
ProductDetailsDestination.createRouteWithParam(
item.id
)
)
},
)
},
directions = setOf(DismissDirection.EndToStart),
)
}
}
} else {
Text("Product list is empty!")
}
}
}
}
@Composable
private fun AddProductButton(
modifier: Modifier = Modifier,
onClick: () -> Unit,
) {
FloatingActionButton(
modifier = modifier,
onClick = onClick,
containerColor = MaterialTheme.colorScheme.primary,
contentColor = MaterialTheme.colorScheme.onPrimary
) {
Icon(
imageVector = Icons.Filled.Add,
contentDescription = null,
)
}
}
```
Create the `ProductDetailsViewModel.kt`:
```kotlin
@HiltViewModel
class ProductDetailsViewModel @Inject constructor(
private val productRepository: ProductRepository,
savedStateHandle: SavedStateHandle,
) : ViewModel() {
private val _product = MutableStateFlow(null)
val product: Flow = _product
private val _name = MutableStateFlow("")
val name: Flow = _name
private val _price = MutableStateFlow(0.0)
val price: Flow = _price
private val _imageUrl = MutableStateFlow("")
val imageUrl: Flow = _imageUrl
init {
val productId = savedStateHandle.get(ProductDetailsDestination.productId)
productId?.let {
getProduct(productId = it)
}
}
private fun getProduct(productId: String) {
viewModelScope.launch {
val result = productRepository.getProduct(productId).asDomainModel()
_product.emit(result)
_name.emit(result.name)
_price.emit(result.price)
}
}
fun onNameChange(name: String) {
_name.value = name
}
fun onPriceChange(price: Double) {
_price.value = price
}
fun onSaveProduct(image: ByteArray) {
viewModelScope.launch {
productRepository.updateProduct(
id = _product.value?.id,
price = _price.value,
name = _name.value,
imageFile = image,
imageName = "image_${_product.value.id}",
)
}
}
fun onImageChange(url: String) {
_imageUrl.value = url
}
private fun ProductDto.asDomainModel(): Product {
return Product(
id = this.id,
name = this.name,
price = this.price,
image = this.image
)
}
}
```
Create the `ProductDetailsScreen.kt`:
```kotlin
@OptIn(ExperimentalCoilApi::class)
@SuppressLint("UnusedMaterialScaffoldPaddingParameter")
@Composable
fun ProductDetailsScreen(
modifier: Modifier = Modifier,
viewModel: ProductDetailsViewModel = hiltViewModel(),
navController: NavController,
productId: String?,
) {
val snackBarHostState = remember { SnackbarHostState() }
val coroutineScope = rememberCoroutineScope()
Scaffold(
snackbarHost = { SnackbarHost(snackBarHostState) },
topBar = {
TopAppBar(
navigationIcon = {
IconButton(onClick = {
navController.navigateUp()
}) {
Icon(
imageVector = Icons.Filled.ArrowBack,
contentDescription = null,
tint = MaterialTheme.colorScheme.onPrimary
)
}
},
backgroundColor = MaterialTheme.colorScheme.primary,
title = {
Text(
text = stringResource(R.string.product_details_text_screen_title),
color = MaterialTheme.colorScheme.onPrimary,
)
},
)
}
) {
val name = viewModel.name.collectAsState(initial = "")
val price = viewModel.price.collectAsState(initial = 0.0)
var imageUrl = Uri.parse(viewModel.imageUrl.collectAsState(initial = null).value)
val contentResolver = LocalContext.current.contentResolver
Column(
modifier = modifier
.padding(16.dp)
.fillMaxSize()
) {
val galleryLauncher =
rememberLauncherForActivityResult(ActivityResultContracts.GetContent())
{ uri ->
uri?.let {
if (it.toString() != imageUrl.toString()) {
viewModel.onImageChange(it.toString())
}
}
}
Image(
painter = rememberImagePainter(imageUrl),
contentScale = ContentScale.Fit,
contentDescription = null,
modifier = Modifier
.padding(16.dp, 8.dp)
.size(100.dp)
.align(Alignment.CenterHorizontally)
)
IconButton(modifier = modifier.align(alignment = Alignment.CenterHorizontally),
onClick = {
galleryLauncher.launch("image/*")
}) {
Icon(
imageVector = Icons.Filled.Edit,
contentDescription = null,
tint = MaterialTheme.colorScheme.primary
)
}
OutlinedTextField(
label = {
Text(
text = "Product name",
color = MaterialTheme.colorScheme.primary,
style = MaterialTheme.typography.titleMedium
)
},
maxLines = 2,
shape = RoundedCornerShape(32),
modifier = modifier.fillMaxWidth(),
value = name.value,
onValueChange = {
viewModel.onNameChange(it)
},
)
Spacer(modifier = modifier.height(12.dp))
OutlinedTextField(
label = {
Text(
text = "Product price",
color = MaterialTheme.colorScheme.primary,
style = MaterialTheme.typography.titleMedium
)
},
maxLines = 2,
shape = RoundedCornerShape(32),
modifier = modifier.fillMaxWidth(),
value = price.value.toString(),
keyboardOptions = KeyboardOptions(keyboardType = KeyboardType.Number),
onValueChange = {
viewModel.onPriceChange(it.toDouble())
},
)
Spacer(modifier = modifier.weight(1f))
Button(
modifier = modifier.fillMaxWidth(),
onClick = {
if (imageUrl.host?.contains("supabase") == true) {
viewModel.onSaveProduct(image = byteArrayOf())
} else {
val image = uriToByteArray(contentResolver, imageUrl)
viewModel.onSaveProduct(image = image)
}
coroutineScope.launch {
snackBarHostState.showSnackbar(
message = "Product updated successfully !",
duration = SnackbarDuration.Short
)
}
}) {
Text(text = "Save changes")
}
Spacer(modifier = modifier.height(12.dp))
OutlinedButton(
modifier = modifier
.fillMaxWidth(),
onClick = {
navController.navigateUp()
}) {
Text(text = "Cancel")
}
}
}
}
private fun getBytes(inputStream: InputStream): ByteArray {
val byteBuffer = ByteArrayOutputStream()
val bufferSize = 1024
val buffer = ByteArray(bufferSize)
var len = 0
while (inputStream.read(buffer).also { len = it } != -1) {
byteBuffer.write(buffer, 0, len)
}
return byteBuffer.toByteArray()
}
private fun uriToByteArray(contentResolver: ContentResolver, uri: Uri): ByteArray {
if (uri == Uri.EMPTY) {
return byteArrayOf()
}
val inputStream = contentResolver.openInputStream(uri)
if (inputStream != null) {
return getBytes(inputStream)
}
return byteArrayOf()
}
```
Create a `AddProductScreen`:
```kotlin
@SuppressLint("UnusedMaterial3ScaffoldPaddingParameter")
@OptIn(ExperimentalMaterial3Api::class)
@Composable
fun AddProductScreen(
modifier: Modifier = Modifier,
navController: NavController,
viewModel: AddProductViewModel = hiltViewModel(),
) {
Scaffold(
topBar = {
TopAppBar(
navigationIcon = {
IconButton(onClick = {
navController.navigateUp()
}) {
Icon(
imageVector = Icons.Filled.ArrowBack,
contentDescription = null,
tint = MaterialTheme.colorScheme.onPrimary
)
}
},
backgroundColor = MaterialTheme.colorScheme.primary,
title = {
Text(
text = stringResource(R.string.add_product_text_screen_title),
color = MaterialTheme.colorScheme.onPrimary,
)
},
)
}
) { padding ->
val navigateAddProductSuccess =
viewModel.navigateAddProductSuccess.collectAsState(initial = null).value
val isLoading =
viewModel.isLoading.collectAsState(initial = null).value
if (isLoading == true) {
LoadingScreen(message = "Adding Product",
onCancelSelected = {
navController.navigateUp()
})
} else {
SuccessScreen(
message = "Product added",
onMoreAction = {
viewModel.onAddMoreProductSelected()
},
onNavigateBack = {
navController.navigateUp()
})
}
}
}
```
Create the `AddProductViewModel.kt`:
```kotlin
@HiltViewModel
class AddProductViewModel @Inject constructor(
private val productRepository: ProductRepository,
) : ViewModel() {
private val _isLoading = MutableStateFlow(false)
val isLoading: Flow = _isLoading
private val _showSuccessMessage = MutableStateFlow(false)
val showSuccessMessage: Flow = _showSuccessMessage
fun onCreateProduct(name: String, price: Double) {
if (name.isEmpty() || price <= 0) return
viewModelScope.launch {
_isLoading.value = true
val product = Product(
id = UUID.randomUUID().toString(),
name = name,
price = price,
)
productRepository.createProduct(product = product)
_isLoading.value = false
_showSuccessMessage.emit(true)
}
}
}
```
Create a `SignUpViewModel`:
```kotlin
@HiltViewModel
class SignUpViewModel @Inject constructor(
private val authenticationRepository: AuthenticationRepository
) : ViewModel() {
private val _email = MutableStateFlow("")
val email: Flow = _email
private val _password = MutableStateFlow("")
val password = _password
fun onEmailChange(email: String) {
_email.value = email
}
fun onPasswordChange(password: String) {
_password.value = password
}
fun onSignUp() {
viewModelScope.launch {
authenticationRepository.signUp(
email = _email.value,
password = _password.value
)
}
}
}
```
Create the `SignUpScreen.kt`:
```kotlin
@Composable
fun SignUpScreen(
modifier: Modifier = Modifier,
navController: NavController,
viewModel: SignUpViewModel = hiltViewModel()
) {
val snackBarHostState = remember { SnackbarHostState() }
val coroutineScope = rememberCoroutineScope()
Scaffold(
snackbarHost = { androidx.compose.material.SnackbarHost(snackBarHostState) },
topBar = {
TopAppBar(
navigationIcon = {
IconButton(onClick = {
navController.navigateUp()
}) {
Icon(
imageVector = Icons.Filled.ArrowBack,
contentDescription = null,
tint = MaterialTheme.colorScheme.onPrimary
)
}
},
backgroundColor = MaterialTheme.colorScheme.primary,
title = {
Text(
text = "Sign Up",
color = MaterialTheme.colorScheme.onPrimary,
)
},
)
}
) { paddingValues ->
Column(
modifier = modifier
.padding(paddingValues)
.padding(20.dp)
) {
val email = viewModel.email.collectAsState(initial = "")
val password = viewModel.password.collectAsState()
OutlinedTextField(
label = {
Text(
text = "Email",
color = MaterialTheme.colorScheme.primary,
style = MaterialTheme.typography.titleMedium
)
},
maxLines = 1,
shape = RoundedCornerShape(32),
modifier = modifier.fillMaxWidth(),
value = email.value,
onValueChange = {
viewModel.onEmailChange(it)
},
)
OutlinedTextField(
label = {
Text(
text = "Password",
color = MaterialTheme.colorScheme.primary,
style = MaterialTheme.typography.titleMedium
)
},
maxLines = 1,
shape = RoundedCornerShape(32),
modifier = modifier
.fillMaxWidth()
.padding(top = 12.dp),
value = password.value,
onValueChange = {
viewModel.onPasswordChange(it)
},
)
val localSoftwareKeyboardController = LocalSoftwareKeyboardController.current
Button(modifier = modifier
.fillMaxWidth()
.padding(top = 12.dp),
onClick = {
localSoftwareKeyboardController?.hide()
viewModel.onSignUp()
coroutineScope.launch {
snackBarHostState.showSnackbar(
message = "Create account successfully. Sign in now!",
duration = SnackbarDuration.Long
)
}
}) {
Text("Sign up")
}
}
}
}
```
Create a `SignInViewModel`:
```kotlin
@HiltViewModel
class SignInViewModel @Inject constructor(
private val authenticationRepository: AuthenticationRepository
) : ViewModel() {
private val _email = MutableStateFlow("")
val email: Flow = _email
private val _password = MutableStateFlow("")
val password = _password
fun onEmailChange(email: String) {
_email.value = email
}
fun onPasswordChange(password: String) {
_password.value = password
}
fun onSignIn() {
viewModelScope.launch {
authenticationRepository.signIn(
email = _email.value,
password = _password.value
)
}
}
fun onGoogleSignIn() {
viewModelScope.launch {
authenticationRepository.signInWithGoogle()
}
}
}
```
Create the `SignInScreen.kt`:
```kotlin
@OptIn(ExperimentalMaterial3Api::class, ExperimentalComposeUiApi::class)
@Composable
fun SignInScreen(
modifier: Modifier = Modifier,
navController: NavController,
viewModel: SignInViewModel = hiltViewModel()
) {
val snackBarHostState = remember { SnackbarHostState() }
val coroutineScope = rememberCoroutineScope()
Scaffold(
snackbarHost = { androidx.compose.material.SnackbarHost(snackBarHostState) },
topBar = {
TopAppBar(
navigationIcon = {
IconButton(onClick = {
navController.navigateUp()
}) {
Icon(
imageVector = Icons.Filled.ArrowBack,
contentDescription = null,
tint = MaterialTheme.colorScheme.onPrimary
)
}
},
backgroundColor = MaterialTheme.colorScheme.primary,
title = {
Text(
text = "Login",
color = MaterialTheme.colorScheme.onPrimary,
)
},
)
}
) { paddingValues ->
Column(
modifier = modifier
.padding(paddingValues)
.padding(20.dp)
) {
val email = viewModel.email.collectAsState(initial = "")
val password = viewModel.password.collectAsState()
androidx.compose.material.OutlinedTextField(
label = {
Text(
text = "Email",
color = MaterialTheme.colorScheme.primary,
style = MaterialTheme.typography.titleMedium
)
},
maxLines = 1,
shape = RoundedCornerShape(32),
modifier = modifier.fillMaxWidth(),
value = email.value,
onValueChange = {
viewModel.onEmailChange(it)
},
)
androidx.compose.material.OutlinedTextField(
label = {
Text(
text = "Password",
color = MaterialTheme.colorScheme.primary,
style = MaterialTheme.typography.titleMedium
)
},
maxLines = 1,
shape = RoundedCornerShape(32),
modifier = modifier
.fillMaxWidth()
.padding(top = 12.dp),
value = password.value,
onValueChange = {
viewModel.onPasswordChange(it)
},
)
val localSoftwareKeyboardController = LocalSoftwareKeyboardController.current
Button(modifier = modifier
.fillMaxWidth()
.padding(top = 12.dp),
onClick = {
localSoftwareKeyboardController?.hide()
viewModel.onGoogleSignIn()
}) {
Text("Sign in with Google")
}
Button(modifier = modifier
.fillMaxWidth()
.padding(top = 12.dp),
onClick = {
localSoftwareKeyboardController?.hide()
viewModel.onSignIn()
coroutineScope.launch {
snackBarHostState.showSnackbar(
message = "Sign in successfully !",
duration = SnackbarDuration.Long
)
}
}) {
Text("Sign in")
}
OutlinedButton(modifier = modifier
.fillMaxWidth()
.padding(top = 12.dp), onClick = {
navController.navigate(SignUpDestination.route)
}) {
Text("Sign up")
}
}
}
}
```
### Implement the `MainActivity`
In the `MainActivity` you created earlier, show your newly created screens:
```kotlin
@AndroidEntryPoint
class MainActivity : ComponentActivity() {
@Inject
lateinit var supabaseClient: SupabaseClient
@OptIn(ExperimentalMaterial3Api::class)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
ManageProductsTheme {
// A surface container using the 'background' color from the theme
val navController = rememberNavController()
val currentBackStack by navController.currentBackStackEntryAsState()
val currentDestination = currentBackStack?.destination
Scaffold { innerPadding ->
NavHost(
navController,
startDestination = ProductListDestination.route,
Modifier.padding(innerPadding)
) {
composable(ProductListDestination.route) {
ProductListScreen(
navController = navController
)
}
composable(AuthenticationDestination.route) {
SignInScreen(
navController = navController
)
}
composable(SignUpDestination.route) {
SignUpScreen(
navController = navController
)
}
composable(AddProductDestination.route) {
AddProductScreen(
navController = navController
)
}
composable(
route = "${ProductDetailsDestination.route}/{${ProductDetailsDestination.productId}}",
arguments = ProductDetailsDestination.arguments
) { navBackStackEntry ->
val productId =
navBackStackEntry.arguments?.getString(ProductDetailsDestination.productId)
ProductDetailsScreen(
productId = productId,
navController = navController,
)
}
}
}
}
}
}
}
```
### Create the success screen
To handle OAuth and OTP signins, create a new activity to handle the deep link you set in `AndroidManifest.xml`:
```xml
```
Then create the `DeepLinkHandlerActivity`:
```kotlin
@AndroidEntryPoint
class DeepLinkHandlerActivity : ComponentActivity() {
@Inject
lateinit var supabaseClient: SupabaseClient
private lateinit var callback: (String, String) -> Unit
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
supabaseClient.handleDeeplinks(intent = intent,
onSessionSuccess = { userSession ->
Log.d("LOGIN", "Log in successfully with user info: ${userSession.user}")
userSession.user?.apply {
callback(email ?: "", createdAt.toString())
}
})
setContent {
val navController = rememberNavController()
val emailState = remember { mutableStateOf("") }
val createdAtState = remember { mutableStateOf("") }
LaunchedEffect(Unit) {
callback = { email, created ->
emailState.value = email
createdAtState.value = created
}
}
ManageProductsTheme {
Surface(
modifier = Modifier.fillMaxSize(),
color = MaterialTheme.colorScheme.background
) {
SignInSuccessScreen(
modifier = Modifier.padding(20.dp),
navController = navController,
email = emailState.value,
createdAt = createdAtState.value,
onClick = { navigateToMainApp() }
)
}
}
}
}
private fun navigateToMainApp() {
val intent = Intent(this, MainActivity::class.java).apply {
flags = Intent.FLAG_ACTIVITY_CLEAR_TOP
}
startActivity(intent)
}
}
```
# Build a User Management App with Next.js
UI components built on shadcn/ui that connect to Supabase via a single command.
This tutorial demonstrates how to build a basic user management app. The app authenticates and identifies the user, stores their profile information in the database, and allows the user to log in, update their profile details, and upload a profile photo. The app uses:
* [Supabase Database](/docs/guides/database) - a Postgres database for storing your user data and [Row Level Security](/docs/guides/auth#row-level-security) so data is protected and users can only access their own information.
* [Supabase Auth](/docs/guides/auth) - allow users to sign up and log in.
* [Supabase Storage](/docs/guides/storage) - allow users to upload a profile photo.

If you get stuck while working through this guide, you can find the [full example on GitHub](https://github.com/supabase/supabase/tree/master/examples/user-management/nextjs-user-management).
## Project setup
Before you start building you need to set up the Database and API. You can do this by starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. [Create a new project](/dashboard) in the Supabase Dashboard.
2. Enter your project details.
3. Wait for the new database to launch.
### Set up the database schema
Now set up the database schema. You can use the "User Management Starter" quickstart in the SQL Editor, or you can copy/paste the SQL from below and run it.
1. Go to the [SQL Editor](/dashboard/project/_/sql) page in the Dashboard.
2. Click **User Management Starter** under the **Community > Quickstarts** tab.
3. Click **Run**.
You can pull the database schema down to your local project by running the `db pull` command. Read the [local development docs](/docs/guides/cli/local-development#link-your-project) for detailed instructions.
```bash
supabase link --project-ref
# You can get from your project's dashboard URL: https://supabase.com/dashboard/project/
supabase db pull
```
When working locally you can run the following command to create a new migration file:
```bash
supabase migration new user_management_starter
```
```sql
-- Create a table for public profiles
create table profiles (
id uuid references auth.users not null primary key,
updated_at timestamp with time zone,
username text unique,
full_name text,
avatar_url text,
website text,
constraint username_length check (char_length(username) >= 3)
);
-- Grant the privileges roles need
GRANT SELECT ON public.profiles TO anon;
GRANT SELECT, INSERT, UPDATE ON public.profiles TO authenticated;
-- Set up Row Level Security (RLS)
-- See https://supabase.com/docs/guides/database/postgres/row-level-security for more details.
alter table profiles
enable row level security;
create policy "Public profiles are viewable by everyone." on profiles
for select using (true);
create policy "Users can insert their own profile." on profiles
for insert with check ((select auth.uid()) = id);
create policy "Users can update own profile." on profiles
for update using ((select auth.uid()) = id);
-- This trigger automatically creates a profile entry when a new user signs up via Supabase Auth.
-- See https://supabase.com/docs/guides/auth/managing-user-data#using-triggers for more details.
create function public.handle_new_user()
returns trigger
set search_path = ''
as $$
begin
insert into public.profiles (id, full_name, avatar_url)
values (new.id, new.raw_user_meta_data->>'full_name', new.raw_user_meta_data->>'avatar_url');
return new;
end;
$$ language plpgsql security definer;
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
-- Set up Storage!
insert into storage.buckets (id, name)
values ('avatars', 'avatars');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage/security/access-control#policy-examples for more details.
create policy "Avatar images are publicly accessible." on storage.objects
for select using (bucket_id = 'avatars');
create policy "Anyone can upload an avatar." on storage.objects
for insert with check (bucket_id = 'avatars');
create policy "Anyone can update their own avatar." on storage.objects
for update using ((select auth.uid()) = owner) with check (bucket_id = 'avatars');
```
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=nextjs).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=nextjs), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
## Building the app
Start building the Next.js app from scratch.
### Initialize a Next.js app
Use [`create-next-app`](https://nextjs.org/docs/getting-started) to initialize an app called `supabase-nextjs`:
```bash
npx create-next-app@latest --ts --use-npm supabase-nextjs
cd supabase-nextjs
```
Install [supabase-js](https://github.com/supabase/supabase-js):
```bash
npm install @supabase/supabase-js
```
Save the environment variables in a `.env.local` file at the root of the project, and paste the API URL and the key that you copied [earlier](#get-api-details).
The application exposes these variables in the browser, and that's fine as Supabase enables [Row Level Security](/docs/guides/database/postgres/row-level-security) by default on all tables.
```bash .env.local
NEXT_PUBLIC_SUPABASE_URL=YOUR_SUPABASE_URL
NEXT_PUBLIC_SUPABASE_PUBLISHABLE_KEY=YOUR_SUPABASE_PUBLISHABLE_KEY
```
### App styling (optional)
An optional step is to update the CSS file `app/globals.css` to make the app look better.
You can find the full contents of this file [in the example repository](https://raw.githubusercontent.com/supabase/supabase/master/examples/user-management/nextjs-user-management/app/globals.css).
### Supabase Server-Side Auth package
Next.js is a versatile framework offering pre-rendering at build time (SSG), server-side rendering at request time (SSR), API routes, and proxy edge-functions.
To better integrate with the framework, we've created the `@supabase/ssr` package for Server-Side Auth. It has all the functionalities to quickly configure your Supabase project to use cookies for storing user sessions. Read the [Next.js Server-Side Auth guide](/docs/guides/auth/server-side/creating-a-client?queryGroups=package-manager\&package-manager=npm\&queryGroups=framework\&framework=nextjs) for more information.
Install the package for Next.js.
```bash
npm install @supabase/ssr
```
### Supabase utilities
There are two different types of clients in Supabase:
1. **Client Component client** - To access Supabase from Client Components, which run in the browser.
2. **Server Component client** - To access Supabase from Server Components, Server Actions, and Route Handlers, which run only on the server.
We recommend creating the following utilities files for creating clients, and organize them within `lib/supabase` at the root of the project.
Create a `client.ts` and a `server.ts` with the following code for client-side Supabase and server-side Supabase, respectively.
```typescript name=lib/supabase/client.ts
import { createBrowserClient } from '@supabase/ssr'
export function createClient() {
// Create a supabase client on the browser with project's credentials
return createBrowserClient(
process.env.NEXT_PUBLIC_SUPABASE_URL!,
process.env.NEXT_PUBLIC_SUPABASE_PUBLISHABLE_KEY!
)
}
```
```typescript name=lib/supabase/server.ts
import { createServerClient } from '@supabase/ssr'
import { cookies } from 'next/headers'
export async function createClient() {
const cookieStore = await cookies()
// Create a server's supabase client with newly configured cookie,
// which could be used to maintain user's session
return createServerClient(
process.env.NEXT_PUBLIC_SUPABASE_URL!,
process.env.NEXT_PUBLIC_SUPABASE_PUBLISHABLE_KEY!,
{
cookies: {
getAll() {
return cookieStore.getAll()
},
setAll(cookiesToSet, _headers) {
try {
cookiesToSet.forEach(({ name, value, options }) =>
cookieStore.set(name, value, options)
)
} catch {
// The `setAll` method was called from a Server Component.
// This can be ignored if you have proxy refreshing
// user sessions.
}
},
},
}
)
}
```
### Next.js proxy
Since Server Components can't write cookies, you need [Proxy](https://nextjs.org/docs/app/getting-started/proxy) to refresh expired Auth tokens and store them.
You accomplish this by:
* Refreshing the Auth token with the call to `supabase.auth.getClaims`.
* Passing the refreshed Auth token to Server Components through `request.cookies.set`, so they don't attempt to refresh the same token themselves.
* Passing the refreshed Auth token to the browser, so it replaces the old token. This is done with `response.cookies.set`.
You could also add a matcher, so that the Proxy only runs on routes that access Supabase. For more information, read [the Next.js matcher documentation](https://nextjs.org/docs/app/api-reference/file-conventions/proxy#matcher).
Be careful when protecting pages. The server gets the user session from the cookies, which anyone can spoof.
The Supabase Auth SDK contains three different functions for authenticating user access to applications:
### Summary of the methods
* Use [`getClaims`](/docs/reference/javascript/auth-getclaims) to protect pages and user data. It reads the access token from storage and verifies it. Locally via the [WebCrypto API](https://developer.mozilla.org/en-US/docs/Web/API/Web_Crypto_API) and a cached JWKS endpoint when the project uses asymmetric signing keys (the default for new projects), or by calling `getUser` solely to validate when symmetric keys are in use. The returned claims always come from decoding the JWT, not from a user lookup.
* [`getUser`](/docs/reference/javascript/auth-getuser) makes a network call to the project's Auth instance to get the user record, which includes the most up-to-date information about the user at the cost of a network call.
* [`getSession`](/docs/reference/javascript/auth-getsession) when you need the raw session (the access token, refresh token, and expiry). For example to forward the access token to another service. The session is loaded directly from local storage and isn't re-validated against the Auth server, so the embedded user object shouldn't be trusted on its own when storage is shared with the client (cookies, request headers). To verify identity, validate the access token with `getClaims`, or call `getUser` for a fresh, server-confirmed user record.
**In summary**: use `getClaims` to verify identity (typically for protecting pages and data), `getUser` when you need an up-to-date user record from the Auth server, and `getSession` when you need the access or refresh token directly, but don't rely on the user object it returns for authorization decisions.
Create a `proxy.ts` file at the project root and another one within the `lib/supabase` folder. The `lib/supabase` file contains the logic for updating the session. The `proxy.ts` file uses this, which is a Next.js convention.
```typescript name=proxy.ts
import { type NextRequest } from 'next/server'
import { updateSession } from '@/lib/supabase/proxy'
export async function proxy(request: NextRequest) {
// update user's auth session
return await updateSession(request)
}
export const config = {
matcher: [
/*
* Match all request paths except for the ones starting with:
* - _next/static (static files)
* - _next/image (image optimization files)
* - favicon.ico (favicon file)
* Feel free to modify this pattern to include more paths.
*/
'/((?!_next/static|_next/image|favicon.ico|.*\\.(?:svg|png|jpg|jpeg|gif|webp)$).*)',
],
}
```
```typescript name=lib/supabase/proxy.ts
import { createServerClient } from '@supabase/ssr'
import { NextResponse, type NextRequest } from 'next/server'
export async function updateSession(request: NextRequest) {
let supabaseResponse = NextResponse.next({
request,
})
const supabase = createServerClient(
process.env.NEXT_PUBLIC_SUPABASE_URL!,
process.env.NEXT_PUBLIC_SUPABASE_PUBLISHABLE_KEY!,
{
cookies: {
getAll() {
return request.cookies.getAll()
},
setAll(cookiesToSet, headers) {
cookiesToSet.forEach(({ name, value }) => request.cookies.set(name, value))
supabaseResponse = NextResponse.next({
request,
})
cookiesToSet.forEach(({ name, value, options }) =>
supabaseResponse.cookies.set(name, value, options)
)
Object.entries(headers).forEach(([key, value]) =>
supabaseResponse.headers.set(key, value)
)
},
},
}
)
// Do not run code between createServerClient and
// supabase.auth.getClaims(). A simple mistake could make it very hard to debug
// issues with users being randomly logged out.
// IMPORTANT: If you remove getClaims() and you use server-side rendering
// with the Supabase client, your users may be randomly logged out.
await supabase.auth.getClaims()
return supabaseResponse
}
```
### Set up a login page
#### Login and signup form
To add login/signup page for your application, create a new folder named `login`, containing a `page.tsx` file with the following code for a login/signup form:
```tsx name=app/login/page.tsx
import { login, signup } from './actions'
export default function LoginPage() {
return (
)
}
```
Create the login/signup actions to hook up the form to the function which does the following:
* Retrieve the user's information.
* Send that information to Supabase as a signup request, which in turns sends a confirmation email. It uses [Magic Links](/docs/guides/auth/auth-email-passwordless#with-magic-link), so users can sign in with their email without using passwords.
* Handle any error that arises.
Create the `action.ts` file in the `app/login` folder, which contains the login and signup functions and the `error/page.tsx` file, which displays an error message if the login or signup fails.
```typescript name=app/login/actions.ts
'use server'
import { revalidatePath } from 'next/cache'
import { redirect } from 'next/navigation'
import { createClient } from '@/lib/supabase/server'
export async function login(formData: FormData) {
const supabase = await createClient()
// type-casting here for convenience
// in practice, you should validate your inputs
const data = {
email: formData.get('email') as string,
password: formData.get('password') as string,
}
const { error } = await supabase.auth.signInWithPassword(data)
if (error) {
redirect('/error')
}
revalidatePath('/', 'layout')
redirect('/account')
}
export async function signup(formData: FormData) {
const supabase = await createClient()
// type-casting here for convenience
// in practice, you should validate your inputs
const data = {
email: formData.get('email') as string,
password: formData.get('password') as string,
}
const { error } = await supabase.auth.signUp(data)
if (error) {
redirect('/error')
}
revalidatePath('/', 'layout')
redirect('/account')
}
```
```tsx name=app/error/page.tsx
export default function ErrorPage() {
return Sorry, something went wrong
}
```
The `cookies` method is called before any calls to Supabase, which takes fetch calls out of Next.js's caching. This is important for authenticated data fetches, to ensure that users get access only to their own data.
Read the Next.js docs to learn more about [opting out of data caching](https://nextjs.org/docs/app/building-your-application/data-fetching/fetching-caching-and-revalidating#opting-out-of-data-caching).
#### Email template
Before proceeding, change the email template to support a server-side authentication flow that sends a token hash:
* Go to the [Auth templates](/dashboard/project/_/auth/templates) page in your dashboard.
* Select the **Confirm signup** template.
* Change `{{ .ConfirmationURL }}` to `{{ .SiteURL }}/auth/confirm?token_hash={{ .TokenHash }}&type=email`.
You can customize other emails sent out to new users, including the email's looks, content, and query parameters from [the **Authentication > Email**](/dashboard/project/_/auth/templates) section of the Dashboard.
#### Confirmation endpoint
As you are working in a server-side rendering (SSR) environment, you need to create a server endpoint responsible for exchanging the `token_hash` for a session.
The code performs the following steps:
* Retrieves the code sent back from the Supabase Auth server using the `token_hash` query parameter.
* Exchanges this code for a session, which you store in your chosen storage mechanism (in this case, cookies).
* Finally, redirects the user to the `account` page.
```typescript name=app/auth/confirm/route.ts
import { type EmailOtpType } from '@supabase/supabase-js'
import { type NextRequest, NextResponse } from 'next/server'
import { createClient } from '@/lib/supabase/server'
// Creating a handler to a GET request to route /auth/confirm
export async function GET(request: NextRequest) {
const { searchParams } = new URL(request.url)
const token_hash = searchParams.get('token_hash')
const type = searchParams.get('type') as EmailOtpType | null
const next = '/account'
// Create redirect link without the secret token
const redirectTo = request.nextUrl.clone()
redirectTo.pathname = next
redirectTo.searchParams.delete('token_hash')
redirectTo.searchParams.delete('type')
if (token_hash && type) {
const supabase = await createClient()
const { error } = await supabase.auth.verifyOtp({
type,
token_hash,
})
if (!error) {
redirectTo.searchParams.delete('next')
return NextResponse.redirect(redirectTo)
}
}
// return the user to an error page with some instructions
redirectTo.pathname = '/error'
return NextResponse.redirect(redirectTo)
}
```
### Account page
After a user signs in, they need a way to edit their profile details and manage their accounts.
Create a new component for that called `AccountForm` within the `app/account` folder.
```tsx name=app/account/account-form.tsx
'use client'
import { useCallback, useEffect, useState } from 'react'
import { createClient } from '@/lib/supabase/client'
import Avatar from './avatar'
// ...
export default function AccountForm({ claims }: { claims: Claims | null }) {
const supabase = createClient()
const [loading, setLoading] = useState(true)
const [fullname, setFullname] = useState(null)
const [username, setUsername] = useState(null)
const [website, setWebsite] = useState(null)
const [avatar_url, setAvatarUrl] = useState(null)
const getProfile = useCallback(async () => {
try {
if (!claims?.sub) {
setLoading(false)
return
}
setLoading(true)
const { data, error, status } = await supabase
.from('profiles')
.select(`full_name, username, website, avatar_url`)
.eq('id', claims.sub)
.single()
if (error && status !== 406) {
console.log(error)
throw error
}
if (data) {
setFullname(data.full_name)
setUsername(data.username)
setWebsite(data.website)
setAvatarUrl(data.avatar_url)
}
} catch (error) {
alert('Error loading user data!')
} finally {
setLoading(false)
}
}, [claims, supabase])
useEffect(() => {
getProfile()
}, [claims, getProfile])
async function updateProfile({
username,
website,
avatar_url,
}: {
username: string | null
fullname: string | null
website: string | null
avatar_url: string | null
}) {
try {
if (!claims?.sub) {
alert('You must be logged in to update your profile')
return
}
setLoading(true)
const { error } = await supabase.from('profiles').upsert({
id: claims.sub,
full_name: fullname,
username,
website,
avatar_url,
updated_at: new Date().toISOString(),
})
// ...
return (
)
}
```
Create an account page for the `AccountForm` component you just created
```tsx name=app/account/page.tsx
import AccountForm from './account-form'
import { createClient } from '@/lib/supabase/server'
export default async function Account() {
const supabase = await createClient()
const { data: claimsData } = await supabase.auth.getClaims()
return
}
```
### Sign out
Create a route handler to handle the sign out from the server side, making sure to check if the user is logged in first.
```typescript name=app/auth/signout/route.ts
import { createClient } from '@/lib/supabase/server'
import { revalidatePath } from 'next/cache'
import { type NextRequest, NextResponse } from 'next/server'
export async function POST(req: NextRequest) {
const supabase = await createClient()
// Check if a user's logged in
const { data: claimsData } = await supabase.auth.getClaims()
if (claimsData?.claims) {
await supabase.auth.signOut()
}
revalidatePath('/', 'layout')
return NextResponse.redirect(new URL('/login', req.url), {
status: 302,
})
}
```
## Profile photos
Next, add a way for users to upload a profile photo. Supabase configures every project with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
Start by creating a new component:
```tsx name=app/account/avatar.tsx
'use client'
import React, { useEffect, useState } from 'react'
import { createClient } from '@/lib/supabase/client'
import Image from 'next/image'
export default function Avatar({
uid,
url,
size,
onUpload,
}: {
uid: string | null
url: string | null
size: number
onUpload: (url: string) => void
}) {
const supabase = createClient()
const [avatarUrl, setAvatarUrl] = useState(url)
const [uploading, setUploading] = useState(false)
useEffect(() => {
async function downloadImage(path: string) {
try {
const { data, error } = await supabase.storage.from('avatars').download(path)
if (error) {
throw error
}
const url = URL.createObjectURL(data)
setAvatarUrl(url)
} catch (error) {
console.log('Error downloading image: ', error)
}
}
if (url) downloadImage(url)
}, [url, supabase])
const uploadAvatar: React.ChangeEventHandler = async (event) => {
try {
setUploading(true)
if (!event.target.files || event.target.files.length === 0) {
throw new Error('You must select an image to upload.')
}
const file = event.target.files[0]
const fileExt = file.name.split('.').pop()
const filePath = `${uid}-${Math.random()}.${fileExt}`
const { error: uploadError } = await supabase.storage.from('avatars').upload(filePath, file)
if (uploadError) {
throw uploadError
}
onUpload(filePath)
} catch (error) {
alert('Error uploading avatar!')
} finally {
setUploading(false)
}
}
return (
{avatarUrl ? (
) : (
)}
Supabase + React
Sign in via magic link with your email below
)
}
```
### Account page
After a user signs in, they need a way to edit their profile details and manage their accounts.
Create a new component called `src/Account.jsx` and add the following code:
```jsx name=src/Account.jsx
import { useState, useEffect } from 'react'
import { supabase } from './supabaseClient'
// ...
export default function Account({ user }) {
const [loading, setLoading] = useState(true)
const [username, setUsername] = useState(null)
const [website, setWebsite] = useState(null)
const [avatar_url, setAvatarUrl] = useState(null)
useEffect(() => {
let ignore = false
async function getProfile() {
setLoading(true)
const { data, error } = await supabase
.from('profiles')
.select(`username, website, avatar_url`)
.eq('id', user.id)
.single()
if (!ignore) {
if (error) {
console.warn(error)
} else if (data) {
setUsername(data.username)
setWebsite(data.website)
setAvatarUrl(data.avatar_url)
}
}
setLoading(false)
}
getProfile()
return () => {
ignore = true
}
}, [user])
async function updateProfile(event, avatarUrl) {
event.preventDefault()
setLoading(true)
const updates = {
id: user.id,
username,
website,
avatar_url: avatarUrl,
updated_at: new Date(),
}
const { error } = await supabase.from('profiles').upsert(updates)
if (error) {
alert(error.message)
} else {
setAvatarUrl(avatarUrl)
}
setLoading(false)
}
return (
)
}
```
## Profile photos
Add a way for users to upload a profile photo. Supabase configures every project with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
Create `src/Avatar.jsx` and add the following code:
```jsx name=src/Avatar.jsx
import { useEffect, useState } from 'react'
import { supabase } from './supabaseClient'
export default function Avatar({ url, size, onUpload }) {
const [avatarUrl, setAvatarUrl] = useState(null)
const [uploading, setUploading] = useState(false)
useEffect(() => {
if (url) downloadImage(url)
}, [url])
async function downloadImage(path) {
try {
const { data, error } = await supabase.storage.from('avatars').download(path)
if (error) {
throw error
}
const url = URL.createObjectURL(data)
setAvatarUrl(url)
} catch (error) {
console.log('Error downloading image: ', error.message)
}
}
async function uploadAvatar(event) {
try {
setUploading(true)
if (!event.target.files || event.target.files.length === 0) {
throw new Error('You must select an image to upload.')
}
const file = event.target.files[0]
const fileExt = file.name.split('.').pop()
const fileName = `${Math.random()}.${fileExt}`
const filePath = `${fileName}`
let { error: uploadError } = await supabase.storage.from('avatars').upload(filePath, file)
if (uploadError) {
throw uploadError
}
onUpload(event, filePath)
} catch (error) {
alert(error.message)
} finally {
setUploading(false)
}
}
return (
{avatarUrl ? (

) : (
)}
Supabase + RedwoodJS
Sign in via magic link with your email below
setEmail(e.target.value)}
/>
)
}
export default Auth
```
### Set up an account component
After a user is signed in we can allow them to edit their profile details and manage their account.
Let's create a new component for that called `Account.js`.
```bash
yarn rw g component account
✔ Generating component files...
✔ Successfully wrote file `./web/src/components/Account/Account.test.js`
✔ Successfully wrote file `./web/src/components/Account/Account.stories.js`
✔ Successfully wrote file `./web/src/components/Account/Account.js`
```
And then update the file to contain:
```jsx name=web/src/components/Account/Account.js
import { useState, useEffect } from 'react'
import { useAuth } from '@redwoodjs/auth'
const Account = () => {
const { client: supabase, currentUser, logOut } = useAuth()
const [loading, setLoading] = useState(true)
const [username, setUsername] = useState(null)
const [website, setWebsite] = useState(null)
const [avatar_url, setAvatarUrl] = useState(null)
useEffect(() => {
getProfile()
}, [supabase.auth.session])
async function getProfile() {
try {
setLoading(true)
const user = supabase.auth.user()
const { data, error, status } = await supabase
.from('profiles')
.select(`username, website, avatar_url`)
.eq('id', user.id)
.single()
if (error && status !== 406) {
throw error
}
if (data) {
setUsername(data.username)
setWebsite(data.website)
setAvatarUrl(data.avatar_url)
}
} catch (error) {
alert(error.message)
} finally {
setLoading(false)
}
}
async function updateProfile({ username, website, avatar_url }) {
try {
setLoading(true)
const user = supabase.auth.user()
const updates = {
id: user.id,
username,
website,
avatar_url,
updated_at: new Date(),
}
const { error } = await supabase.from('profiles').upsert(updates, {
returning: 'minimal', // Don't return the value after inserting
})
if (error) {
throw error
}
alert('Updated profile!')
} catch (error) {
alert(error.message)
} finally {
setLoading(false)
}
}
return (
Supabase + RedwoodJS
Your profile
)
}
export default Account
```
You'll see the use of `useAuth()` several times. Redwood's `useAuth` hook provides convenient ways to access
`logIn`, `logOut`, `currentUser`, and access the `supabase` authenticate client. We'll use it to get an instance
of the Supabase client to interact with your API.
### Update home page
With all the components in place, update your `HomePage` page to use them:
```jsx name=web/src/pages/HomePage/HomePage.js
import { useAuth } from '@redwoodjs/auth'
import { MetaTags } from '@redwoodjs/web'
import Account from 'src/components/Account'
import Auth from 'src/components/Auth'
const HomePage = () => {
const { isAuthenticated } = useAuth()
return (
<>
{!isAuthenticated ? : }
)
}
export default HomePage
```
What we're doing here is showing the sign in form if you aren't logged in and your account profile if you are.
## Profile photos
Next, add a way for users to upload a profile photo. Supabase configures every project with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
Let's create an avatar for the user so that they can upload a profile photo. We can start by creating a new component:
```bash
yarn rw g component avatar
✔ Generating component files...
✔ Successfully wrote file `./web/src/components/Avatar/Avatar.test.js`
✔ Successfully wrote file `./web/src/components/Avatar/Avatar.stories.js`
✔ Successfully wrote file `./web/src/components/Avatar/Avatar.js`
```
Now, update your Avatar component to contain the following widget:
```jsx name=web/src/components/Avatar/Avatar.js
import { useEffect, useState } from 'react'
import { useAuth } from '@redwoodjs/auth'
const Avatar = ({ url, size, onUpload }) => {
const { client: supabase } = useAuth()
const [avatarUrl, setAvatarUrl] = useState(null)
const [uploading, setUploading] = useState(false)
useEffect(() => {
if (url) downloadImage(url)
}, [url])
async function downloadImage(path) {
try {
const { data, error } = await supabase.storage.from('avatars').download(path)
if (error) {
throw error
}
const url = URL.createObjectURL(data)
setAvatarUrl(url)
} catch (error) {
console.log('Error downloading image: ', error.message)
}
}
async function uploadAvatar(event) {
try {
setUploading(true)
if (!event.target.files || event.target.files.length === 0) {
throw new Error('You must select an image to upload.')
}
const file = event.target.files[0]
const fileExt = file.name.split('.').pop()
const fileName = `${Math.random()}.${fileExt}`
const filePath = `${fileName}`
const { error: uploadError } = await supabase.storage.from('avatars').upload(filePath, file)
if (uploadError) {
throw uploadError
}
onUpload(filePath)
} catch (error) {
alert(error.message)
} finally {
setUploading(false)
}
}
return (
{avatarUrl ? (
) : (
)}
Supabase + Refine
Sign in via magic link with your email below
)
}
```
The [`useLogin()`](https://refine.dev/docs/api-reference/core/hooks/authentication/useLogin/) Refine auth hook to grab the `mutate: login` method to use inside `handleLogin()` function and `isLoading` state for the form submission. The `useLogin()` hook conveniently offers access to `authProvider.login` method for authenticating the user with OTP.
### Account page
After a user is signed in, allow them to edit their profile details and manage their account.
Create a new component for that in `src/components/account.tsx`.
```tsx name=src/components/account.tsx
import { BaseKey, useGetIdentity, useLogout } from '@refinedev/core'
import { useForm } from '@refinedev/react-hook-form'
// ...
interface IUserIdentity {
id?: BaseKey
username: string
name: string
}
export interface IProfile {
id?: string
username?: string
website?: string
avatar_url?: string
}
export default function Account() {
const { data: userIdentity } = useGetIdentity()
const { mutate: logOut } = useLogout()
const {
refineCore: { formLoading, query, onFinish },
register,
control,
handleSubmit,
} = useForm({
refineCoreProps: {
resource: 'profiles',
action: 'edit',
id: userIdentity?.id,
redirect: false,
onMutationError: (data) => alert(data?.message),
},
})
return (
)
}
```
This uses three Refine hooks, namely the [`useGetIdentity()`](https://refine.dev/docs/api-reference/core/hooks/authentication/useGetIdentity/), [`useLogOut()`](https://refine.dev/docs/api-reference/core/hooks/authentication/useLogout/) and [`useForm()`](https://refine.dev/docs/packages/documentation/react-hook-form/useForm/) hooks.
`useGetIdentity()` is a auth hook that gets the identity of the authenticated user. It grabs the current user by invoking the `authProvider.getIdentity` method under the hood.
`useLogOut()` is also an auth hook. It calls the `authProvider.logout` method to end the session.
`useForm()`, in contrast, is a data hook that exposes a series of useful objects that serve the edit form. For example, grabbing the `onFinish` function to submit the form with the `handleSubmit` event handler. It also uses `formLoading` property to present state changes of the submitted form.
The `useForm()` hook is a higher-level hook built on top of Refine's `useForm()` core hook. It fully supports form state management, field validation and submission using React Hook Form. Behind the scenes, it invokes the `dataProvider.getOne` method to get the user profile data from the Supabase `/profiles` endpoint and also invokes `dataProvider.update` method when `onFinish()` is called.
## Profile photos
Next, add a way for users to upload a profile photo. Supabase configures every project with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
Add a new component:
Create and edit `src/components/avatar.tsx`:
```tsx name=src/components/avatar.tsx
import { useEffect, useState } from 'react'
import { supabaseClient } from '../utility/supabaseClient'
type TAvatarProps = {
url?: string
size: number
onUpload: (filePath: string) => void
}
export default function Avatar({ url, size, onUpload }: TAvatarProps) {
const [avatarUrl, setAvatarUrl] = useState('')
const [uploading, setUploading] = useState(false)
useEffect(() => {
if (url) downloadImage(url)
}, [url])
async function downloadImage(path: string) {
try {
const { data, error } = await supabaseClient.storage.from('avatars').download(path)
if (error) {
throw error
}
const url = URL.createObjectURL(data)
setAvatarUrl(url)
} catch (error: any) {
console.log('Error downloading image: ', error?.message)
}
}
async function uploadAvatar(event: React.ChangeEvent) {
try {
setUploading(true)
if (!event.target.files || event.target.files.length === 0) {
throw new Error('You must select an image to upload.')
}
const file = event.target.files[0]
const fileExt = file.name.split('.').pop()
const fileName = `${Math.random()}.${fileExt}`
const filePath = `${fileName}`
const { error: uploadError } = await supabaseClient.storage
.from('avatars')
.upload(filePath, file)
if (uploadError) {
throw uploadError
}
onUpload(filePath)
} catch (error: any) {
alert(error.message)
} finally {
setUploading(false)
}
}
return (
{avatarUrl ? (
) : (
)}
{avatarUrl() ? (
!})
) : (
)}
{#if avatarUrl}
{:else}
{/if}
{#if !session}
{:else}
{/if}
{@render children()}
```
### Set up a login page
Create a magic link login/signup page for your application by updating the `routes/+page.svelte` file:
```svelte name=src/routes/+page.svelte
User Management
```
Create a `src/routes/+page.server.ts` file that handles the magic link form when submitted.
```typescript name=src/routes/+page.server.ts
// src/routes/+page.server.ts
import { fail, redirect } from '@sveltejs/kit'
import type { Actions, PageServerLoad } from './$types'
export const load: PageServerLoad = async ({ url, locals: { supabase } }) => {
const { data, error } = await supabase.auth.getClaims()
// if the user is already logged in return them to the account page
if (!error && data?.claims) {
redirect(303, '/account')
}
return { url: url.origin }
}
export const actions: Actions = {
default: async (event) => {
const {
url,
request,
locals: { supabase },
} = event
const formData = await request.formData()
const email = formData.get('email') as string
const validEmail = /^[\w-\.+]+@([\w-]+\.)+[\w-]{2,8}$/.test(email)
if (!validEmail) {
return fail(400, { errors: { email: 'Please enter a valid email address' }, email })
}
const { error } = await supabase.auth.signInWithOtp({ email })
if (error) {
return fail(400, {
success: false,
email,
message: `There was an issue, Please contact support.`,
})
}
return {
success: true,
message: 'Please check your email for a magic link to log into the website.',
}
},
}
```
#### Email template
Change the email template to support a server-side authentication flow.
Before proceeding, change the email template to support sending a token hash:
* Go to the [**Auth** > **Emails**](/dashboard/project/_/auth/templates) page in the project dashboard.
* Select the **Confirm signup** template.
* Change `{{ .ConfirmationURL }}` to `{{ .SiteURL }}/auth/confirm?token_hash={{ .TokenHash }}&type=email`.
* Repeat the previous step for **Magic link** template.
You can also customize emails sent out to new users, including the email's looks, content, and query parameters. Check out the [settings of your project](/dashboard/project/_/auth/templates).
#### Confirmation endpoint
As this is a server-side rendering (SSR) environment, you need to create a server endpoint responsible for exchanging the `token_hash` for a session.
The following code snippet performs the following steps:
* Retrieves the `token_hash` sent back from the Supabase Auth server using the `token_hash` query parameter.
* Exchanges this `token_hash` for a session, which you store in storage (in this case, cookies).
* Finally, redirect the user to the `account` page or the `error` page.
```typescript name=src/routes/auth/confirm/+server.ts
// src/routes/auth/confirm/+server.js
import type { EmailOtpType } from '@supabase/supabase-js'
import { redirect } from '@sveltejs/kit'
import type { RequestHandler } from './$types'
export const GET: RequestHandler = async ({ url, locals: { supabase } }) => {
const token_hash = url.searchParams.get('token_hash')
const type = url.searchParams.get('type') as EmailOtpType | null
const next = url.searchParams.get('next') ?? '/account'
/**
* Clean up the redirect URL by deleting the Auth flow parameters.
*
* `next` is preserved for now, because it's needed in the error case.
*/
const redirectTo = new URL(url)
redirectTo.pathname = next
redirectTo.searchParams.delete('token_hash')
redirectTo.searchParams.delete('type')
if (token_hash && type) {
const { error } = await supabase.auth.verifyOtp({ type, token_hash })
if (!error) {
redirectTo.searchParams.delete('next')
redirect(303, redirectTo)
}
}
redirectTo.pathname = '/auth/error'
redirect(303, redirectTo)
}
```
#### Authentication error page
If there is an error with confirming the token, redirect the user to an error page.
```svelte name=src/routes/auth/error/+page.svelte
Login error
```
#### Account page
After a user signs in, they need to be able to edit their profile details page.
Create a new `src/routes/account/+page.svelte` file with the content below.
```svelte name=src/routes/account/+page.svelte
```
Now, create the associated `src/routes/account/+page.server.ts` file that handles loading data from the server through the `load` function
and handle all form actions through the `actions` object.
```typescript name=src/routes/account/+page.server.ts
import { fail, redirect } from '@sveltejs/kit'
import type { Actions, PageServerLoad } from './$types'
export const load: PageServerLoad = async ({ locals: { supabase } }) => {
const { data: claimsData, error } = await supabase.auth.getClaims()
if (error || !claimsData?.claims) {
redirect(303, '/')
}
const { claims } = claimsData
const { data: profile } = await supabase
.from('profiles')
.select(`username, full_name, website, avatar_url`)
.eq('id', claims.sub)
.single()
return { claims, profile }
}
export const actions: Actions = {
update: async ({ request, locals: { supabase } }) => {
const formData = await request.formData()
const fullName = formData.get('fullName') as string
const username = formData.get('username') as string
const website = formData.get('website') as string
const avatarUrl = formData.get('avatarUrl') as string
const { data: claimsData, error: claimsError } = await supabase.auth.getClaims()
if (claimsError || !claimsData?.claims) {
return fail(401, { fullName, username, website, avatarUrl })
}
const { error } = await supabase.from('profiles').upsert({
id: claimsData.claims.sub,
full_name: fullName,
username,
website,
avatar_url: avatarUrl,
updated_at: new Date(),
})
if (error) {
return fail(500, {
fullName,
username,
website,
avatarUrl,
})
}
return {
fullName,
username,
website,
avatarUrl,
}
},
signout: async ({ locals: { supabase } }) => {
await supabase.auth.signOut()
redirect(303, '/')
},
}
```
## Profile photos
Next, add a way for users to upload a profile photo. Supabase configures every project with [Storage](/docs/guides/storage) for managing large files like photos and videos.
### Create an upload widget
Start by creating a new component called `Avatar.svelte` in the `src/routes/account` directory:
```svelte name=src/routes/account/Avatar.svelte
{#if avatarUrl}
{:else}
{/if}
{instruments?.map((instrument) => (
- {instrument.name}
))}
```
Run the development server, go to [http://localhost:4321/instruments](http://localhost:4321/instruments) in your browser of choice to check the list of instruments.
```bash name=Terminal
npm run dev
```
## Next steps
* Set up [Auth](/docs/guides/auth) for your app
* [Insert more data](/docs/guides/database/import-data) into your database
* Upload and serve static files using [Storage](/docs/guides/storage)
# Use Supabase with Expo React Native
Learn how to create a Supabase project, add some sample data to your database, and query the data from an Expo app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Create a minimal Expo app using the `create-expo-app` command with the blank TypeScript template.
UI components built on shadcn/ui that connect to Supabase via a single command.
```bash name=Terminal
npx create-expo-app my-app --template blank-typescript
```
The fastest way to get started is to use the `@supabase/supabase-js` client library which provides a convenient interface for working with Supabase from a React Native app.
Navigate to the Expo app and install `supabase-js` along with the required dependencies for secure storage and URL handling.
```bash name=Terminal
cd my-app && npx expo install @supabase/supabase-js react-native-url-polyfill expo-sqlite
```
Create a `.env` file in the root of your project and populate it with your Supabase connection variables.
Expo requires environment variables to be prefixed with `EXPO_PUBLIC_` to be accessible in your app code.
```text name=.env
EXPO_PUBLIC_SUPABASE_URL=
EXPO_PUBLIC_SUPABASE_PUBLISHABLE_KEY=
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=\&framework=).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=\&framework=), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Create a helper file at `lib/supabase.ts` to initialize the Supabase client using the environment variables.
The code below uses Expo's localStorage polyfill to persist authentication sessions.
```ts name=lib/supabase.ts
import 'react-native-url-polyfill/auto'
import { createClient } from '@supabase/supabase-js'
import 'expo-sqlite/localStorage/install';
const supabaseUrl = process.env.EXPO_PUBLIC_SUPABASE_URL
const supabasePublishableKey = process.env.EXPO_PUBLIC_SUPABASE_PUBLISHABLE_KEY
export const supabase = createClient(supabaseUrl, supabasePublishableKey, {
auth: {
storage: localStorage,
autoRefreshToken: true,
persistSession: true,
detectSessionInUrl: false,
},
})
```
Replace the contents of `App.tsx` with the following code to fetch and display the instruments from your database.
Use `useEffect` to fetch the data when the component mounts and display the query result using React Native components.
```tsx name=App.tsx
import { useEffect, useState } from 'react'
import { StyleSheet, View, FlatList, Text } from 'react-native'
import { supabase } from './lib/supabase'
export default function App() {
const [instruments, setInstruments] = useState([])
useEffect(() => {
getInstruments()
}, [])
async function getInstruments() {
const { data } = await supabase.from('instruments').select()
setInstruments(data)
}
return (
item.id.toString()}
renderItem={({ item }) => (
{item.name}
)}
/>
)
}
const styles = StyleSheet.create({
container: {
flex: 1,
backgroundColor: '#fff',
paddingTop: 50,
paddingHorizontal: 16,
},
item: {
padding: 16,
borderBottomWidth: 1,
borderBottomColor: '#ccc',
},
})
```
Run the development server and scan the QR code with the Expo Go app on your phone, or press `i` for iOS simulator or `a` for Android emulator.
```bash name=Terminal
npx expo start
```
## Next steps
* Set up [Auth](/docs/guides/auth) for your app
* [Insert more data](/docs/guides/database/import-data) into your database
* Upload and serve static files using [Storage](/docs/guides/storage)
# Use Supabase with Python
Learn how to create a Supabase project, add some sample data to your database, and query the data from a Python app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Create a new directory for your Python app and set up a virtual environment.
```bash name=Terminal
mkdir my-app && cd my-app
python3 -m venv venv
source venv/bin/activate
```
The fastest way to get started is to use Flask for the web framework and the `supabase-py` client library which provides a convenient interface for working with Supabase from a Python app.
Install both packages using pip.
```bash name=Terminal
pip install flask supabase
```
Create a `.env` file in your project root and populate it with your Supabase connection variables:
```text name=.env
SUPABASE_URL=
SUPABASE_PUBLISHABLE_KEY=
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=\&framework=).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=\&framework=), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Install the `python-dotenv` package to load environment variables:
```bash
pip install python-dotenv
```
Create an `app.py` file and add a route that fetches data from your `instruments` table using the Supabase client.
```python name=app.py
import os
from flask import Flask
from supabase import create_client, Client
from dotenv import load_dotenv
load_dotenv()
app = Flask(__name__)
supabase: Client = create_client(
os.environ.get("SUPABASE_URL"),
os.environ.get("SUPABASE_PUBLISHABLE_KEY")
)
@app.route('/')
def index():
response = supabase.table('instruments').select("*").execute()
instruments = response.data
html = 'Instruments
'
for instrument in instruments:
html += f'- {instrument["name"]}
'
html += '
'
return html
if __name__ == '__main__':
app.run(debug=True)
```
Run the Flask development server, go to [http://localhost:5000](http://localhost:5000) in a browser and you should see the list of instruments.
```bash name=Terminal
python app.py
```
## Next steps
* Set up [Auth](/docs/guides/auth) for your app
* [Insert more data](/docs/guides/database/import-data) into your database
* Upload and serve static files using [Storage](/docs/guides/storage)
# Use Supabase with Flutter
Learn how to create a Supabase project, add some sample data to your database, and query the data from a Flutter app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Create a Flutter app using the `flutter create` command. You can skip this step if you already have a working app.
```bash name=Terminal
flutter create my_app
```
The fastest way to get started is to use the [`supabase_flutter`](https://pub.dev/packages/supabase_flutter) client library which provides a convenient interface for working with Supabase from a Flutter app.
Open the `pubspec.yaml` file inside your Flutter app and add `supabase_flutter` as a dependency.
```yaml name=pubspec.yaml
supabase_flutter: ^2.0.0
```
Open `lib/main.dart` and edit the main function to initialize Supabase using your project URL and publishable key:
```dart name=lib/main.dart
import 'package:supabase_flutter/supabase_flutter.dart';
Future main() async {
WidgetsFlutterBinding.ensureInitialized();
await Supabase.initialize(
url: 'YOUR_SUPABASE_URL',
anonKey: 'YOUR_SUPABASE_PUBLISHABLE_KEY',
);
runApp(MyApp());
}
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=flutter).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=flutter), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Use a `FutureBuilder` to fetch the data when the home page loads and display the query result in a `ListView`.
Replace the default `MyApp` and `MyHomePage` classes with the following code.
```dart name=lib/main.dart
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return const MaterialApp(
title: 'Instruments',
home: HomePage(),
);
}
}
class HomePage extends StatefulWidget {
const HomePage({super.key});
@override
State createState() => _HomePageState();
}
class _HomePageState extends State {
final _future = Supabase.instance.client
.from('instruments')
.select();
@override
Widget build(BuildContext context) {
return Scaffold(
body: FutureBuilder(
future: _future,
builder: (context, snapshot) {
if (!snapshot.hasData) {
return const Center(child: CircularProgressIndicator());
}
final instruments = snapshot.data!;
return ListView.builder(
itemCount: instruments.length,
itemBuilder: ((context, index) {
final instrument = instruments[index];
return ListTile(
title: Text(instrument['name']),
);
}),
);
},
),
);
}
}
```
Run your app on a platform of your choosing! By default an app should launch in your web browser.
Note that `supabase_flutter` is compatible with web, iOS, Android, macOS, and Windows apps.
Running the app on macOS requires additional configuration to [set the entitlements](https://docs.flutter.dev/development/platform-integration/macos/building#setting-up-entitlements).
```bash name=Terminal
flutter run
```
## Setup deep links
Many sign in methods require deep links to redirect the user back to your app after authentication. Read more about setting deep links up for all platforms (including web) in the [Flutter Mobile Guide](/docs/guides/getting-started/tutorials/with-flutter#setup-deep-links).
## Going to production
### Android
In production, your Android app needs explicit permission to use the internet connection on the user's device which is required to communicate with Supabase APIs.
To do this, add the following line to the `android/app/src/main/AndroidManifest.xml` file.
```xml
```
# Use Supabase with Hono
Learn how to create a Supabase project, add some sample data to your database, secure it with auth, and query the data from a Hono app.
Bootstrap the Hono example app from the Supabase Samples using the CLI.
```bash name=Terminal
npx supabase@latest bootstrap hono
```
The `package.json` file in the project includes the necessary dependencies, including `@supabase/supabase-js` and `@supabase/ssr` to help with server-side auth.
```bash name=Terminal
npm install
```
Copy the `.env.example` file to `.env` and update the values with your Supabase project URL and publishable key.
Lastly, [enable anonymous sign-ins](/dashboard/project/_/auth/providers) in the Auth settings.
```bash name=Terminal
cp .env.example .env
```
{/* TODO: Not ideal for frameworks that have no entry in Connect */}
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Start the app, go to [http://localhost:5173](http://localhost:5173).
Learn how [server side auth](/docs/guides/auth/server-side/creating-a-client?queryGroups=framework\&framework=hono) works with Hono.
```bash name=Terminal
npm run dev
```
## Next steps
* Learn how [server side auth](/docs/guides/auth/server-side/creating-a-client?queryGroups=framework\&framework=hono) works with Hono.
* [Insert more data](/docs/guides/database/import-data) into your database
* Upload and serve static files using [Storage](/docs/guides/storage)
# Use Supabase with iOS and SwiftUI
Learn how to create a Supabase project, add some sample data to your database, and query the data from an iOS app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Open Xcode > New Project > iOS > App. You can skip this step if you already have a working app.
Add the [supabase-swift](https://github.com/supabase/supabase-swift) package to your app using the Swift Package Manager.
In Xcode, navigate to **File > Add Package Dependencies...** and enter the repository URL `https://github.com/supabase/supabase-swift` in the search bar. For detailed instructions, see Apple's [tutorial on adding package dependencies](https://developer.apple.com/documentation/xcode/adding-package-dependencies-to-your-app).
Make sure to add `Supabase` product package as a dependency to your application target.
Create a new `Supabase.swift` file add a new Supabase instance using your project URL and publishable key:
```swift name=Supabase.swift
import Supabase
let supabase = SupabaseClient(
supabaseURL: URL(string: "YOUR_SUPABASE_URL")!,
supabaseKey: "YOUR_SUPABASE_PUBLISHABLE_KEY"
)
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=swift).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=swift), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Create a decodable struct to deserialize the data from the database.
Add the following code to a new file named `Instrument.swift`.
```swift name=Instrument.swift
struct Instrument: Decodable, Identifiable {
let id: Int
let name: String
}
```
Use a `task` to fetch the data from the database and display it using a `List`.
Replace the default `ContentView` with the following code.
```swift name=ContentView.swift
import SwiftUI
struct ContentView: View {
@State var instruments: [Instrument] = []
var body: some View {
List(instruments) { instrument in
Text(instrument.name)
}
.overlay {
if instruments.isEmpty {
ProgressView()
}
}
.task {
do {
instruments = try await supabase.from("instruments").select().execute().value
} catch {
dump(error)
}
}
}
}
```
Run the app on a simulator or a physical device by hitting `Cmd + R` on Xcode.
## Setting up deep links
If you want to implement authentication features like magic links or OAuth, you need to set up deep links to redirect users back to your app. For instructions on configuring custom URL schemes for your iOS app, see the [deep linking guide](/docs/guides/auth/native-mobile-deep-linking?platform=swift).
## Next steps
* Learn how to build a complete user management app with authentication in the [Swift tutorial](/docs/guides/getting-started/tutorials/with-swift)
* Explore the [supabase-swift](https://github.com/supabase/supabase-swift) library on GitHub
# Use Supabase with Android Kotlin
Learn how to create a Supabase project, add some sample data to your database, and query the data from an Android Kotlin app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Open Android Studio > New > New Android Project.
Open `build.gradle.kts` (app) file and add the serialization plug, Ktor client, and Supabase client.
Replace the version placeholders `$kotlin_version` with the Kotlin version of the project, and `$supabase_version` and `$ktor_version` with the respective latest versions.
The latest supabase-kt version can be found [here](https://github.com/supabase-community/supabase-kt/releases) and Ktor version can be found [here](https://ktor.io/docs/welcome.html).
```kotlin
plugins {
...
kotlin("plugin.serialization") version "$kotlin_version"
}
...
dependencies {
...
implementation(platform("io.github.jan-tennert.supabase:bom:$supabase_version"))
implementation("io.github.jan-tennert.supabase:postgrest-kt")
implementation("io.ktor:ktor-client-android:$ktor_version")
}
```
Add the following line to the `AndroidManifest.xml` file under the `manifest` tag and outside the `application` tag.
```xml
...
...
```
You can create a Supabase client whenever you need to perform an API call.
For the sake of simplicity, we will create a client in the `MainActivity.kt` file at the top just below the imports.
Replace the `supabaseUrl` and `supabaseKey` with your own:
```kotlin
import ...
val supabase = createSupabaseClient(
supabaseUrl = "https://xyzcompany.supabase.co",
supabaseKey = "your_publishable_key"
) {
install(Postgrest)
}
...
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=androidkotlin).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=mobiles\&framework=androidkotlin), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Create a serializable data class to represent the data from the database.
Add the following below the `createSupabaseClient` function in the `MainActivity.kt` file.
```kotlin
@Serializable
data class Instrument(
val id: Int,
val name: String,
)
```
Use `LaunchedEffect` to fetch data from the database and display it in a `LazyColumn`.
Replace the default `MainActivity` class with the following code.
Note that we are making a network request from our UI code. In production, you should probably use a `ViewModel` to separate the UI and data fetching logic.
```kotlin
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
SupabaseTutorialTheme {
// A surface container using the 'background' color from the theme
Surface(
modifier = Modifier.fillMaxSize(),
color = MaterialTheme.colorScheme.background
) {
InstrumentsList()
}
}
}
}
}
@Composable
fun InstrumentsList() {
var instruments by remember { mutableStateOf>(listOf()) }
LaunchedEffect(Unit) {
withContext(Dispatchers.IO) {
instruments = supabase.from("instruments")
.select().decodeList()
}
}
LazyColumn {
items(
instruments,
key = { instrument -> instrument.id },
) { instrument ->
Text(
instrument.name,
modifier = Modifier.padding(8.dp),
)
}
}
}
```
Run the app on an emulator or a physical device by clicking the `Run app` button in Android Studio.
# Use Supabase with Laravel
Learn how to create a PHP Laravel project, connect it to your Supabase Postgres database, and configure user authentication.
Make sure your PHP and Composer versions are up to date, then use `composer create-project` to scaffold a new Laravel project.
See the [Laravel docs](https://laravel.com/docs/10.x/installation#creating-a-laravel-project) for more details.
```bash name=Terminal
composer create-project laravel/laravel example-app
```
Install [Laravel Breeze](https://laravel.com/docs/10.x/starter-kits#laravel-breeze), a simple implementation of all of Laravel's [authentication features](https://laravel.com/docs/10.x/authentication).
```bash name=Terminal
composer require laravel/breeze --dev
php artisan breeze:install
```
Go to [database.new](https://database.new) and create a new Supabase project. Save your database password securely.
When your project is up and running, navigate to your project dashboard and click on [Connect](/dashboard/project/_?showConnect=true\&method=session).
Look for the Session Pooler connection string and copy the string. You will need to replace the Password with your saved database password. You can reset your database password in your [Database Settings](/dashboard/project/_/database/settings) if you do not have it.
If you're in an [IPv6 environment](https://github.com/orgs/supabase/discussions/27034) or have the IPv4 Add-On, you can use the direct connection string instead of Supavisor in Session mode.
```bash name=.env
DB_CONNECTION=pgsql
DB_URL=postgres://postgres.xxxx:password@xxxx.pooler.supabase.com:5432/postgres
```
By default Laravel uses the `public` schema. We recommend changing this as Supabase exposes the `public` schema as a [data API](/docs/guides/api).
You can change the schema of your Laravel application by modifying the `search_path` variable `app/config/database.php`.
The schema you specify in `search_path` has to exist on Supabase. You can create a new schema from the [Table Editor](/dashboard/project/_/editor).
```php name=app/config/database.php
'pgsql' => [
'driver' => 'pgsql',
'url' => env('DB_URL'),
'host' => env('DB_HOST', '127.0.0.1'),
'port' => env('DB_PORT', '5432'),
'database' => env('DB_DATABASE', 'laravel'),
'username' => env('DB_USERNAME', 'root'),
'password' => env('DB_PASSWORD', ''),
'charset' => env('DB_CHARSET', 'utf8'),
'prefix' => '',
'prefix_indexes' => true,
'search_path' => 'laravel',
'sslmode' => 'prefer',
],
```
Laravel ships with database migration files that set up the required tables for Laravel Authentication and User Management.
Note: Laravel does not use Supabase Auth but rather implements its own authentication system!
```bash name=Terminal
php artisan migrate
```
Run the development server. Go to [http://127.0.0.1:8000](http://127.0.0.1:8000) in a browser to see your application. You can also navigate to [http://127.0.0.1:8000/register](http://127.0.0.1:8000/register) and [http://127.0.0.1:8000/login](http://127.0.0.1:8000/login) to register and log in users.
```bash name=Terminal
php artisan serve
```
# Use Supabase with Next.js
Learn how to create a Supabase project, add some sample data, and query from a Next.js app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Use the `create-next-app` command and the `with-supabase` template, to create a Next.js app pre-configured with:
* [Cookie-based Auth](/docs/guides/auth/server-side/creating-a-client?queryGroups=package-manager\&package-manager=npm\&queryGroups=framework\&framework=nextjs\&queryGroups=environment\&environment=server)
* [TypeScript](https://www.typescriptlang.org/)
* [Tailwind CSS](https://tailwindcss.com/)
UI components built on shadcn/ui that connect to Supabase via a single command.
```bash
npx create-next-app -e with-supabase
```
Rename `.env.example` to `.env.local` and populate with your Supabase connection variables:
```text name=.env.local
NEXT_PUBLIC_SUPABASE_URL=
NEXT_PUBLIC_SUPABASE_PUBLISHABLE_KEY=
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=nextjs).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=nextjs), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Create a new file at `app/instruments/page.tsx` and populate with the following.
This selects all the rows from the `instruments` table in Supabase and render them on the page.
```ts name=app/instruments/page.tsx
import { createClient } from "@/lib/supabase/server";
import { Suspense } from "react";
async function InstrumentsData() {
const supabase = await createClient();
const { data: instruments } = await supabase.from("instruments").select();
return {JSON.stringify(instruments, null, 2)};
}
export default function Instruments() {
return (
Loading instruments...}>
);
}
```
Run the development server, go to [http://localhost:3000/instruments](http://localhost:3000/instruments) in a browser and you should see the list of instruments.
```bash Terminal
npm run dev
```
## Next steps
* Set up [Auth](/docs/guides/auth) for your app
* [Insert more data](/docs/guides/database/import-data) into your database
* Upload and serve static files using [Storage](/docs/guides/storage)
# Use Supabase with Nuxt
Learn how to create a Supabase project, add some sample data to your database, and query the data from a Nuxt app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
* Create a Nuxt app using the `npx nuxi` command.
UI components built on shadcn/ui that connect to Supabase via a single command.
```bash name=Terminal
npx nuxi@latest init my-app
```
The fastest way to get started is to use the `supabase-js` client library which provides a convenient interface for working with Supabase from a Nuxt app.
Navigate to the Nuxt app and install `supabase-js`.
```bash name=Terminal
cd my-app && npm install @supabase/supabase-js
```
Create a `.env` file and populate with your Supabase connection variables:
```text name=.env.local
SUPABASE_URL=
SUPABASE_PUBLISHABLE_KEY=
```
```ts name=nuxt.config.tsx
export default defineNuxtConfig({
runtimeConfig: {
public: {
supabaseUrl: process.env.SUPABASE_URL,
supabasePublishableKey: process.env.SUPABASE_PUBLISHABLE_KEY,
},
},
});
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=nuxt).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=nuxt), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
In `app.vue`, create a Supabase client using your config values and replace the existing content with the following code.
```vue name=app.vue
```
Start the app, navigate to [http://localhost:3000](http://localhost:3000) in the browser, open the browser console, and you should see the list of instruments.
```bash name=Terminal
npm run dev
```
The community-maintained [@nuxtjs/supabase](https://supabase.nuxtjs.org/) module provides an alternate DX for working with Supabase in Nuxt.
# Use Supabase with React
Learn how to create a Supabase project, add some sample data to your database, and query the data from a React app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
* Create a React app using a [Vite](https://vitejs.dev/guide/) template.
UI components built on shadcn/ui that connect to Supabase via a single command.
```bash name=Terminal
npm create vite@latest my-app -- --template react
```
The fastest way to get started is to use the `supabase-js` client library which provides a convenient interface for working with Supabase from a React app.
Navigate to the React app and install `supabase-js`.
```bash name=Terminal
cd my-app && npm install @supabase/supabase-js
```
Create a `.env.local` file and populate with your Supabase connection variables:
```text name=.env.local
VITE_SUPABASE_URL=
VITE_SUPABASE_PUBLISHABLE_KEY=
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=react).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=react), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Replace the contents of `App.jsx` to add a `getInstruments` function to fetch the data and display the query result to the page using a Supabase client.
```js name=src/App.jsx
import { useEffect, useState } from "react";
import { createClient } from "@supabase/supabase-js";
const supabase = createClient(import.meta.env.VITE_SUPABASE_URL, import.meta.env.VITE_SUPABASE_PUBLISHABLE_KEY);
function App() {
const [instruments, setInstruments] = useState([]);
useEffect(() => {
getInstruments();
}, []);
async function getInstruments() {
const { data, error } = await supabase.from("instruments").select();
if (error) {
console.error(error);
return;
}
setInstruments(data);
}
return (
{instruments.map((instrument) => (
- {instrument.name}
))}
);
}
export default App;
```
Run the development server, go to [http://localhost:5173](http://localhost:5173) in a browser and you should see the list of instruments.
```bash name=Terminal
npm run dev
```
## Next steps
* Set up [Auth](/docs/guides/auth) for your app
* [Insert more data](/docs/guides/database/import-data) into your database
* Upload and serve static files using [Storage](/docs/guides/storage)
# Use Supabase with RedwoodJS
Learn how to create a Supabase project, add some sample data to your database using Prisma migration and seeds, and query the data from a RedwoodJS app.
[Create a new project](/dashboard) in the Supabase Dashboard.
Be sure to make note of the Database Password you used as you will need this later to connect to your database.
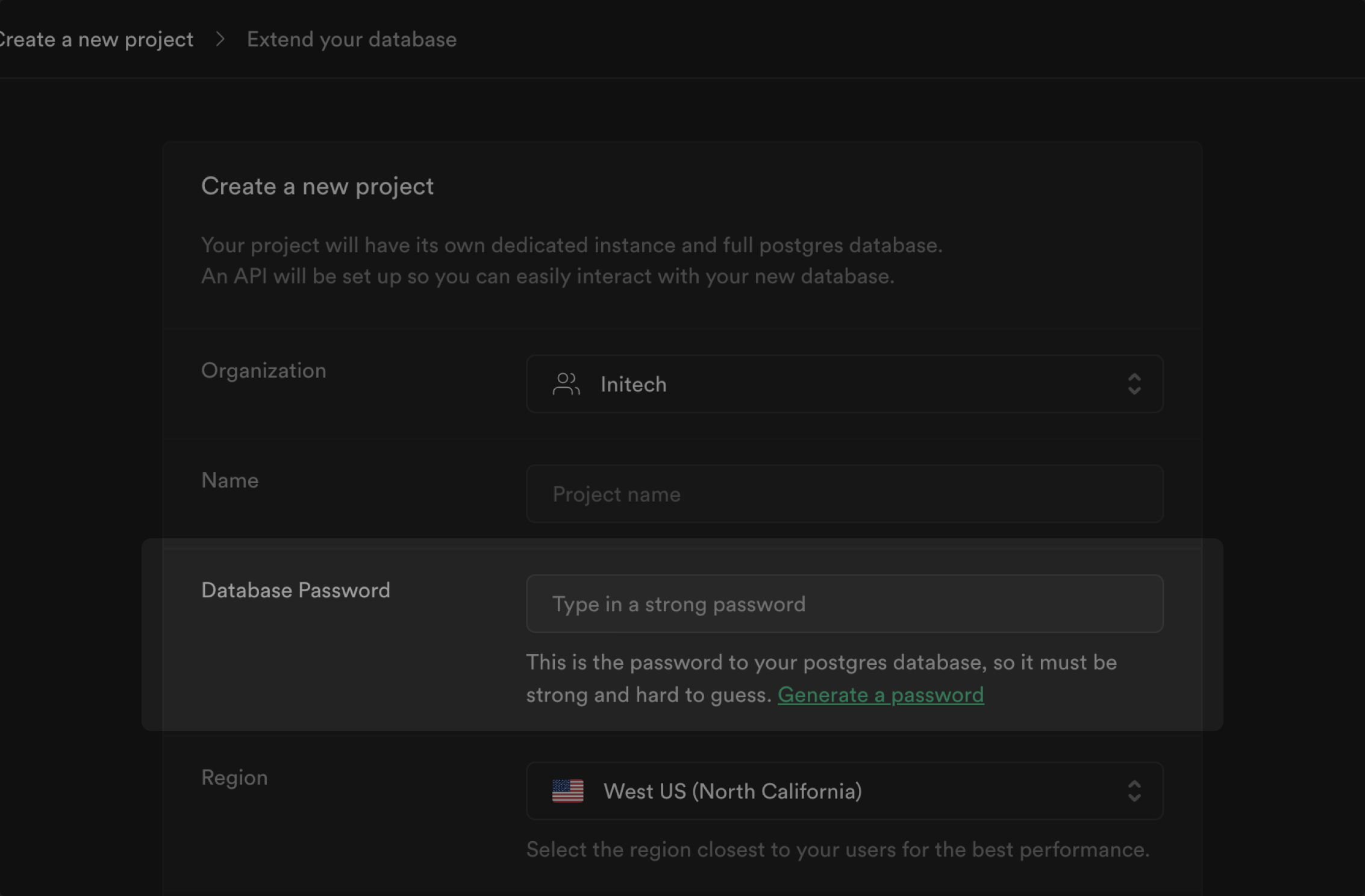
Open the project [**Connect** panel](/dashboard/project/_?showConnect=true). This quickstart connects using the [**Transaction pooler**](/dashboard/project/_?showConnect=true\&method=transaction) and [**Session pooler**](/dashboard/project/_?showConnect=true\&method=session) mode. Transaction mode is used for application queries and Session mode is used for running migrations with Prisma.
To do this, set the connection mode to `Transaction` in the [Database Settings page](/dashboard/project/_/database/settings) and copy the connection string and append `?pgbouncer=true&&connection_limit=1`. `pgbouncer=true` disables Prisma from generating prepared statements. This is required since our connection pooler does not support prepared statements in transaction mode yet. The `connection_limit=1` parameter is only required if you are using Prisma from a serverless environment. This is the Transaction mode connection string.
To get the Session mode connection pooler string, change the port of the connection string from the dashboard to 5432.
You will need the Transaction mode connection string and the Session mode connection string to setup environment variables in Step 5.
You can copy and paste these connection strings from the Supabase Dashboard when needed in later steps.
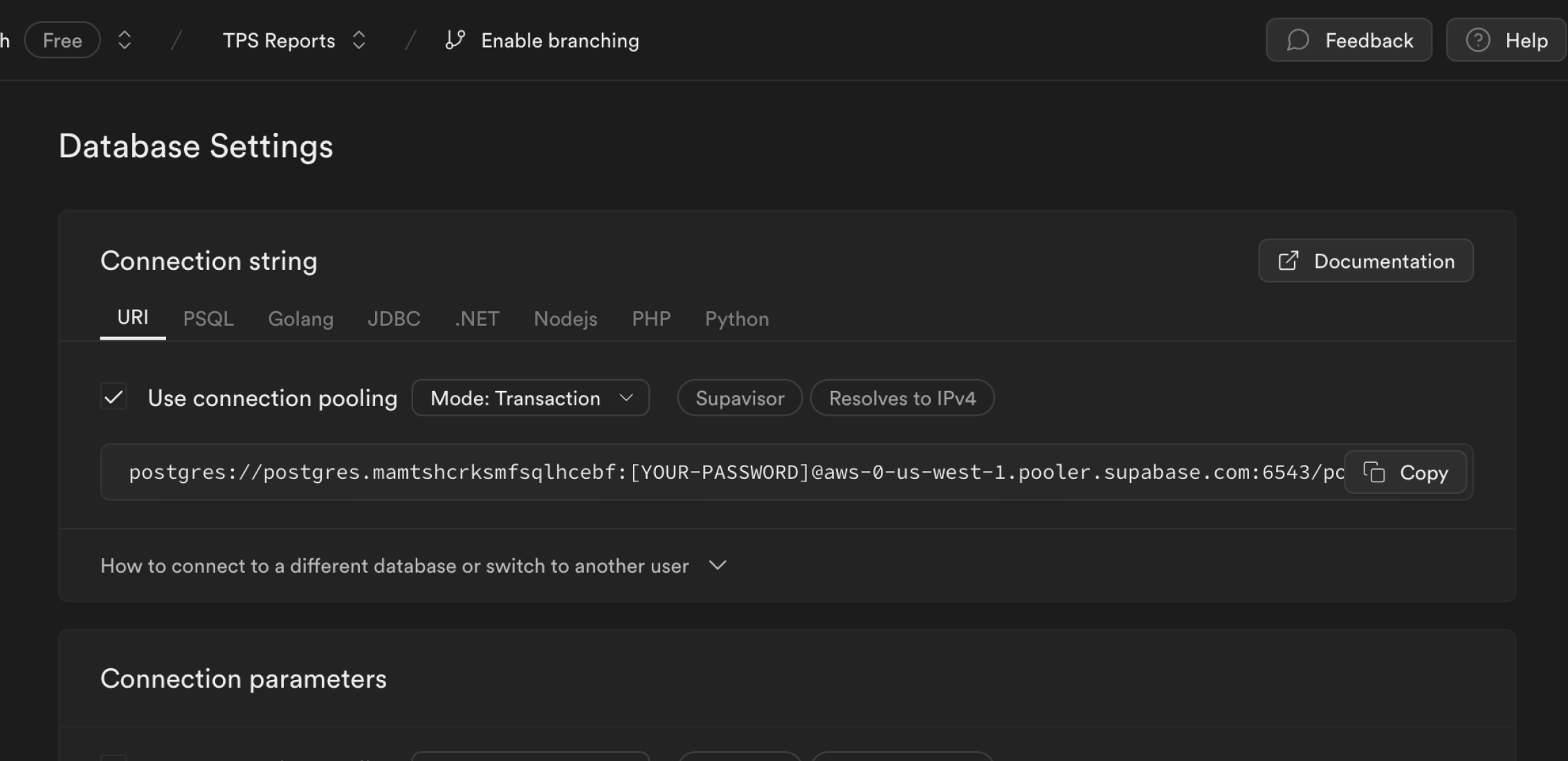
Create a RedwoodJS app with TypeScript.
The [`yarn` package manager](https://yarnpkg.com) is required to create a RedwoodJS app. You will use it to run RedwoodJS commands later.
While TypeScript is recommended, If you want a JavaScript app, omit the `--ts` flag.
```bash name=Terminal
yarn create redwood-app my-app --ts
```
You'll develop your app, manage database migrations, and run your app in VS Code.
```bash name=Terminal
cd my-app
code .
```
In your `.env` file, add the following environment variables for your database connection:
* The `DATABASE_URL` should use the Transaction mode connection string you copied in Step 1.
* The `DIRECT_URL` should use the Session mode connection string you copied in Step 1.
```bash name=.env
# Transaction mode connection string used for migrations
DATABASE_URL="postgres://postgres.[project-ref]:[db-password]@xxx.pooler.supabase.com:6543/postgres?pgbouncer=true&connection_limit=1"
# Session mode connection string — used by Prisma Client
DIRECT_URL="postgres://postgres.[project-ref]:[db-password]@xxx.pooler.supabase.com:5432/postgres"
```
By default, RedwoodJS ships with a SQLite database, but we want to use Postgres.
Update your Prisma schema file `api/db/schema.prisma` to use your Supabase Postgres database connection environment variables you setup in Step 5.
```prisma name=api/db/schema.prisma
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
directUrl = env("DIRECT_URL")
}
```
Create the Instrument model in `api/db/schema.prisma` and then run `yarn rw prisma migrate dev` from your terminal to apply the migration.
```prisma name=api/db/schema.prisma
model Instrument {
id Int @id @default(autoincrement())
name String @unique
}
```
Let's seed the database with a few instruments.
Update the file `scripts/seeds.ts` to contain the following code:
```ts name=scripts/seed.ts
import type { Prisma } from '@prisma/client'
import { db } from 'api/src/lib/db'
export default async () => {
try {
const data: Prisma.InstrumentCreateArgs['data'][] = [
{ name: 'dulcimer' },
{ name: 'harp' },
{ name: 'guitar' },
]
console.log('Seeding instruments ...')
const instruments = await db.instrument.createMany({ data })
console.log('Done.', instruments)
} catch (error) {
console.error(error)
}
}
```
Run the seed database command to populate the `Instrument` table with the instruments you just created.
The reset database command `yarn rw prisma db reset` will recreate the tables and will also run the seed script.
```bash name=Terminal
yarn rw prisma db seed
```
Now, we'll use RedwoodJS generators to scaffold a CRUD UI for the `Instrument` model.
```bash name=Terminal
yarn rw g scaffold instrument
```
Start the app via `yarn rw dev`. A browser will open to the RedwoodJS Splash page.

Click on `/instruments` to visit [http://localhost:8910/instruments](http://localhost:8910/instruments) where should see the list of instruments.
You may now edit, delete, and add new books using the scaffolded UI.
# Use Supabase with Refine
Learn how to create a Supabase project, add some sample data to your database, and query the data from a Refine app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Create a [Refine](https://github.com/refinedev/refine) app using the [create refine-app](https://refine.dev/docs/getting-started/quickstart/).
The `refine-supabase` preset adds `@refinedev/supabase` supplementary package that supports Supabase in a Refine app. `@refinedev/supabase` out-of-the-box includes the Supabase dependency: [supabase-js](https://github.com/supabase/supabase-js).
```bash name=Terminal
npm create refine-app@latest -- --preset refine-supabase my-app
```
You will develop your app, connect to the Supabase backend and run the Refine app in VS Code.
```bash name=Terminal
cd my-app
code .
```
Start the app, go to [http://localhost:5173](http://localhost:5173) in a browser, and you should be greeted with the Refine Welcome page.
```bash name=Terminal
npm run dev
```

You now have to update the `supabaseClient` with the `SUPABASE_URL` and `SUPABASE_KEY` of your Supabase API. The `supabaseClient` is used in auth provider and data provider methods that allow the Refine app to connect to your Supabase backend.
```ts name=src/utility/supabaseClient.ts
import { createClient } from "@refinedev/supabase";
const SUPABASE_URL = YOUR_SUPABASE_URL;
const SUPABASE_KEY = YOUR_SUPABASE_KEY
export const supabaseClient = createClient(SUPABASE_URL, SUPABASE_KEY, {
db: {
schema: "public",
},
auth: {
persistSession: true,
},
});
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=refine).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=refine), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
You have to then configure resources and define pages for `instruments` resource.
Use the following command to automatically add resources and generate code for pages for `instruments` using Refine Inferencer.
This defines pages for `list`, `create`, `show` and `edit` actions inside the `src/pages/instruments/` directory with `` component.
The `` component depends on `@refinedev/react-table` and `@refinedev/react-hook-form` packages. In order to avoid errors, you should install them as dependencies with `npm install @refinedev/react-table @refinedev/react-hook-form`.
The `` is a Refine Inferencer component that automatically generates necessary code for the `list`, `create`, `show` and `edit` pages.
More on [how the Inferencer works is available in the docs here](https://refine.dev/docs/packages/documentation/inferencer/).
```bash name=Terminal
npm run refine create-resource instruments
```
Add routes for the `list`, `create`, `show`, and `edit` pages.
You should remove the `index` route for the Welcome page presented with the `` component.
```tsx name=src/App.tsx
import { Refine } from "@refinedev/core";
import { RefineKbar, RefineKbarProvider } from "@refinedev/kbar";
import routerProvider, {
DocumentTitleHandler,
NavigateToResource,
UnsavedChangesNotifier,
} from "@refinedev/react-router";
import { dataProvider, liveProvider } from "@refinedev/supabase";
import { BrowserRouter, Route, Routes } from "react-router-dom";
import "./App.css";
import authProvider from "./authProvider";
import { supabaseClient } from "./utility";
import { InstrumentsCreate, InstrumentsEdit, InstrumentsList, InstrumentsShow } from "./pages/instruments";
function App() {
return (
}
/>
} />
} />
} />
} />
);
}
export default App;
```
Now you should be able to see the instruments pages along the `/instruments` routes. You may now edit and add new instruments using the Inferencer generated UI.
The Inferencer auto-generated code gives you a good starting point on which to keep building your `list`, `create`, `show` and `edit` pages. They can be obtained by clicking the `Show the auto-generated code` buttons in their respective pages.
# Use Supabase with Ruby on Rails
Learn how to create a Rails project and connect it to your Supabase Postgres database.
Make sure your Ruby and Rails versions are up to date, then use `rails new` to scaffold a new Rails project. Use the `-d=postgresql` flag to set it up for Postgres.
Go to the [Rails docs](https://guides.rubyonrails.org/getting_started.html) for more details.
```bash name=Terminal
rails new blog -d=postgresql
```
Go to [database.new](https://database.new) and create a new Supabase project. Save your database password securely.
When your project is up and running, navigate to your project dashboard and click on [Connect](/dashboard/project/_?showConnect=true\&method=session).
Look for the Session Pooler connection string and copy the string. You will need to replace the Password with your saved database password. You can reset your database password in your [Database Settings](/dashboard/project/_/database/settings) if you do not have it.
If you're in an [IPv6 environment](https://github.com/orgs/supabase/discussions/27034) or have the IPv4 Add-On, you can use the direct connection string instead of Supavisor in Session mode.
```bash name=Terminal
export DATABASE_URL=postgres://postgres.xxxx:password@xxxx.pooler.supabase.com:5432/postgres
```
Rails includes Active Record as the ORM as well as database migration tooling which generates the SQL migration files for you.
Create an example `Article` model and generate the migration files.
```bash name=Terminal
bin/rails generate model Article title:string body:text
bin/rails db:migrate
```
You can use the included Rails console to interact with the database. For example, you can create new entries or list all entries in a Model's table.
```bash name=Terminal
bin/rails console
```
```rb name=irb
article = Article.new(title: "Hello Rails", body: "I am on Rails!")
article.save # Saves the entry to the database
Article.all
```
Run the development server. Go to [http://127.0.0.1:3000](http://127.0.0.1:3000) in a browser to see your application running.
```bash name=Terminal
bin/rails server
```
# Use Supabase with SolidJS
Learn how to create a Supabase project, add some sample data to your database, and query the data from a SolidJS app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Create a SolidJS app using the `degit` command.
```bash name=Terminal
npx degit solidjs/templates/js my-app
```
The fastest way to get started is to use the `supabase-js` client library which provides a convenient interface for working with Supabase from a SolidJS app.
Navigate to the SolidJS app and install `supabase-js`.
```bash name=Terminal
cd my-app && npm install @supabase/supabase-js
```
Create a `.env.local` file and populate with your Supabase connection variables:
```text name=.env.local
VITE_SUPABASE_URL=
VITE_SUPABASE_PUBLISHABLE_KEY=
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=solidjs).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=solidjs), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
In `App.jsx`, create a Supabase client to fetch the instruments data.
Add a `getInstruments` function to fetch the data and display the query result to the page.
```jsx name=src/App.jsx
import { createClient } from "@supabase/supabase-js";
import { createResource, For } from "solid-js";
const supabase = createClient('https://.supabase.co', '');
async function getInstruments() {
const { data } = await supabase.from("instruments").select();
return data;
}
function App() {
const [instruments] = createResource(getInstruments);
return (
{(instrument) => - {instrument.name}
}
);
}
export default App;
```
Start the app and go to [http://localhost:3000](http://localhost:3000) in a browser and you should see the list of instruments.
```bash name=Terminal
npm run dev
```
# Use Supabase with SvelteKit
Learn how to create a Supabase project, add some sample data to your database, and query the data from a SvelteKit app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
Create a SvelteKit app using the `npm create` command.
```bash name=Terminal
npx sv create my-app
```
The fastest way to get started is to use the `supabase-js` client library which provides a convenient interface for working with Supabase from a SvelteKit app.
Navigate to the SvelteKit app and install `supabase-js`.
```bash name=Terminal
cd my-app && npm install @supabase/supabase-js
```
Create a `.env` file at the root of your project and populate with your Supabase connection variables:
```text name=.env
PUBLIC_SUPABASE_URL=
PUBLIC_SUPABASE_PUBLISHABLE_KEY=
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=sveltekit).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=sveltekit), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Create a `src/lib` directory in your SvelteKit app, create a file called `supabaseClient.js` and add the following code to initialize the Supabase client:
```js name=src/lib/supabaseClient.js
import { createClient } from '@supabase/supabase-js';
import { PUBLIC_SUPABASE_URL, PUBLIC_SUPABASE_PUBLISHABLE_KEY } from '$env/static/public';
export const supabase = createClient(PUBLIC_SUPABASE_URL, PUBLIC_SUPABASE_PUBLISHABLE_KEY)
```
```ts name=src/lib/supabaseClient.ts
import { createClient } from '@supabase/supabase-js';
import { PUBLIC_SUPABASE_URL, PUBLIC_SUPABASE_PUBLISHABLE_KEY } from '$env/static/public';
export const supabase = createClient(PUBLIC_SUPABASE_URL, PUBLIC_SUPABASE_PUBLISHABLE_KEY)
```
Use `load` method to fetch the data server-side and display the query results as a simple list.
Create `+page.server.js` file in the `src/routes` directory with the following code.
```js name=src/routes/+page.server.js
import { supabase } from "$lib/supabaseClient";
export async function load() {
const { data } = await supabase.from("instruments").select();
return {
instruments: data ?? [],
};
}
```
```ts name=src/routes/+page.server.ts
import type { PageServerLoad } from './$types';
import { supabase } from '$lib/supabaseClient';
type Instrument = {
id: number;
name: string;
};
export const load: PageServerLoad = async () => {
const { data, error } = await supabase.from('instruments').select<'instruments', Instrument>();
if (error) {
console.error('Error loading instruments:', error.message);
return { instruments: [] };
}
return {
instruments: data ?? [],
};
};
```
Replace the existing content in your `+page.svelte` file in the `src/routes` directory with the following code.
```svelte name=src/routes/+page.svelte
{#each data.instruments as instrument}
- {instrument.name}
{/each}
```
Start the app and go to [http://localhost:5173](http://localhost:5173) in a browser and you should see the list of instruments.
```bash name=Terminal
npm run dev
```
## Next steps
* Set up [Auth](/docs/guides/auth) for your app
* [Insert more data](/docs/guides/database/import-data) into your database
* Upload and serve static files using [Storage](/docs/guides/storage)
# Use Supabase with TanStack Start
Learn how to create a Supabase project, add some sample data to your database, and query the data from a TanStack Start app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
* Create a TanStack Start app using the official CLI.
UI components built on shadcn/ui that connect to Supabase via a single command.
```bash name=Terminal
npm create @tanstack/start@latest my-app -- --package-manager npm --toolchain biome
```
The fastest way to get started is to use the `supabase-js` client library which provides a convenient interface for working with Supabase from a TanStack Start app.
Navigate to the TanStack Start app and install `supabase-js`.
```bash name=Terminal
cd my-app && npm install @supabase/supabase-js
```
Create a `.env` file in the root of your project and populate with your Supabase connection variables:
```text name=.env
VITE_SUPABASE_URL=
VITE_SUPABASE_PUBLISHABLE_KEY=
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=\&framework=).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=\&framework=), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Create a new file at `src/utils/supabase.ts` to initialize the Supabase client.
```ts name=src/utils/supabase.ts
import { createClient } from "@supabase/supabase-js";
export const supabase = createClient(
import.meta.env.VITE_SUPABASE_URL,
import.meta.env.VITE_SUPABASE_PUBLISHABLE_KEY
);
```
Replace the contents of `src/routes/index.tsx` with the following code to add a loader function that fetches the instruments data and displays it on the page.
```tsx name=src/routes/index.tsx
import { createFileRoute } from '@tanstack/react-router'
import { supabase } from '../utils/supabase'
export const Route = createFileRoute('/')({
loader: async () => {
const { data: instruments } = await supabase.from('instruments').select()
return { instruments }
},
component: Home,
})
function Home() {
const { instruments } = Route.useLoaderData()
return (
{instruments?.map((instrument) => (
- {instrument.name}
))}
)
}
```
Run the development server, go to [http://localhost:3000](http://localhost:3000) in a browser and you should see the list of instruments.
```bash name=Terminal
npm run dev
```
## Next steps
* Set up [Auth](/docs/guides/auth) for your app
* [Insert more data](/docs/guides/database/import-data) into your database
* Upload and serve static files using [Storage](/docs/guides/storage)
# Use Supabase with Vue
Learn how to create a Supabase project, add some sample data to your database, and query the data from a Vue app.
Go to [database.new](https://database.new) and create a new Supabase project.
Alternatively, you can create a project using the Management API:
```bash
# First, get your access token from https://supabase.com/dashboard/account/tokens
export SUPABASE_ACCESS_TOKEN="your-access-token"
# List your organizations to get the organization ID
curl -H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
https://api.supabase.com/v1/organizations
# Create a new project (replace with your organization ID)
curl -X POST https://api.supabase.com/v1/projects \
-H "Authorization: Bearer $SUPABASE_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"organization_id": "",
"name": "My Project",
"region": "us-east-1",
"db_pass": ""
}'
```
When your project is up and running, go to the [**Table Editor**](/dashboard/project/_/editor) section of the Dashboard, create a new table and insert some data. Then in the [**Integrations > Data API**](/dashboard/project/_/integrations/data_api/settings) section of the Dashboard, expose the specific tables or functions you want to access. To automatically grant access for new tables and functions in `public`, enable **Default privileges for new entities**.
Alternatively, you can run the following snippet in your project's [SQL Editor](/dashboard/project/_/sql/new).
This creates an `instruments` table with some sample data, sets a secure baseline by setting only the privileges each Postgres role needs, and adds [Row Level Security (RLS)](/docs/guides/database/postgres/row-level-security) for enhanced security for database data by default.
```sql SQL_EDITOR
-- Create the table
create table instruments (
id bigint primary key generated always as identity,
name text not null
);
-- Insert sample data into the table
insert into instruments (name)
values
('violin'),
('viola'),
('cello');
-- Grant the privileges the role needs, which is read access
grant select on public.instruments to anon;
-- Enable row level security for the table
alter table instruments enable row level security;
```
Create an RLS policy to make the data in your table publicly readable:
```sql SQL_EDITOR
-- Create a policy to allow the anon role to read from the instruments table
create policy "public can read instruments"
on public.instruments
for select to anon
using (true);
```
* Create a Vue app using the `npm init` command.
UI components built on shadcn/ui that connect to Supabase via a single command.
```sh name=Terminal
npm init vue@latest my-app
```
The fastest way to get started is to use the `supabase-js` client library which provides a convenient interface for working with Supabase from a Vue app.
Navigate to the Vue app and install `supabase-js`.
```bash name=Terminal
cd my-app && npm install @supabase/supabase-js
```
Create a `.env.local` file and populate with your Supabase connection variables:
```text name=.env.local
VITE_SUPABASE_URL=
VITE_SUPABASE_PUBLISHABLE_KEY=
```
{/* TODO: How to completely consolidate partials? */}
### Get API details
Now that you've created some database tables, you are ready to insert data using the auto-generated API.
To do this, you need to get the Project URL and key from [the project **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=vue).
[Read the API keys docs](/docs/guides/getting-started/api-keys) for a full explanation of all key types and their uses.
Supabase is changing the way keys work to improve project security and developer experience. You can [read the full announcement on GitHub](https://github.com/orgs/supabase/discussions/29260).
The older `anon` and `service_role` keys will work until the end of 2026 but **we strongly encourage switching to and using** the new publishable (`sb_publishable_xxx`) and secret (`sb_secret_xxx`) keys now.
In most cases, you can get keys from [the Project's **Connect** dialog](/dashboard/project/_?showConnect=true\&connectTab=frameworks\&framework=vue), but if you want a specific key, you can find them in the [**Settings > API Keys**](/dashboard/project/_/settings/api-keys/) section of the Dashboard.
* **For legacy keys**, copy the `anon` key for client-side operations and the `service_role` key for server-side operations from the **Legacy API Keys** tab.
* **For new keys**, open the **API Keys** tab, if you don't have a publishable key already, click **Create new API Keys**, and copy the value from the **Publishable key** section.
Create a `/src/lib` directory in your Vue app, create a file called `supabaseClient.js` and add the following code to initialize the Supabase client:
```js name=src/lib/supabaseClient.js
import { createClient } from '@supabase/supabase-js'
const supabaseUrl = import.meta.env.VITE_SUPABASE_URL
const supabasePublishableKey = import.meta.env.VITE_SUPABASE_PUBLISHABLE_KEY
export const supabase = createClient(supabaseUrl, supabasePublishableKey)
```
Replace the existing content in your `App.vue` file with the following code.
```vue name=src/App.vue
```
Start the app and go to [http://localhost:5173](http://localhost:5173) in a browser and you should see the list of instruments.
```bash name=Terminal
npm run dev
```
# Running AI Models
Run AI models in Edge Functions using the built-in Supabase AI API.
Edge Functions have a built-in API for running AI models. You can use this API to generate embeddings, build conversational workflows, and do other AI related tasks in your Edge Functions.
This allows you to:
* Generate text embeddings without external dependencies
* Run Large Language Models via Ollama or Llamafile
* Build conversational AI workflows
***
## Setup
There are no external dependencies or packages to install to enable the API.
Create a new inference session:
```ts
const model = new Supabase.ai.Session('model-name')
```
To get type hints and checks for the API, import types from `functions-js`:
```ts
import 'jsr:@supabase/functions-js/edge-runtime.d.ts'
```
### Running a model inference
Once the session is instantiated, you can call it with inputs to perform inferences:
```ts
// For embeddings (gte-small model)
const embeddings = await model.run('Hello world', {
mean_pool: true,
normalize: true,
})
// For text generation (non-streaming)
const response = await model.run('Write a haiku about coding', {
stream: false,
timeout: 30,
})
// For streaming responses
const stream = await model.run('Tell me a story', {
stream: true,
mode: 'ollama',
})
```
***
## Generate text embeddings
Generate text embeddings using the built-in [`gte-small`](https://huggingface.co/Supabase/gte-small) model:
`gte-small` model exclusively caters to English texts, and any lengthy texts will be truncated to a maximum of 512 tokens. While you can provide inputs longer than 512 tokens, truncation may affect the accuracy.
```ts
const model = new Supabase.ai.Session('gte-small')
Deno.serve(async (req: Request) => {
const params = new URL(req.url).searchParams
const input = params.get('input')
const output = await model.run(input, { mean_pool: true, normalize: true })
return new Response(JSON.stringify(output), {
headers: {
'Content-Type': 'application/json',
Connection: 'keep-alive',
},
})
})
```
***
## Using Large Language Models (LLM)
Inference via larger models is supported via [Ollama](https://ollama.com/) and [Mozilla Llamafile](https://github.com/Mozilla-Ocho/llamafile). In the first iteration, you can use it with a self-managed Ollama or [Llamafile server](https://www.docker.com/blog/a-quick-guide-to-containerizing-llamafile-with-docker-for-ai-applications/).
We are progressively rolling out support for the hosted solution. To sign up for early access, fill out [this form](https://forms.supabase.com/supabase.ai-llm-early-access).
***
## Running locally
[Install Ollama](https://github.com/ollama/ollama?tab=readme-ov-file#ollama) and pull the Mistral model
```bash
ollama pull mistral
```
```bash
ollama serve
```
Set a function secret called `AI_INFERENCE_API_HOST` to point to the Ollama server
```bash
echo "AI_INFERENCE_API_HOST=http://host.docker.internal:11434" >> supabase/functions/.env
```
```bash
supabase functions new ollama-test
```
```ts supabase/functions/ollama-test/index.ts
import 'jsr:@supabase/functions-js/edge-runtime.d.ts'
const session = new Supabase.ai.Session('mistral')
Deno.serve(async (req: Request) => {
const params = new URL(req.url).searchParams
const prompt = params.get('prompt') ?? ''
// Get the output as a stream
const output = await session.run(prompt, { stream: true })
const headers = new Headers({
'Content-Type': 'text/event-stream',
Connection: 'keep-alive',
})
// Create a stream
const stream = new ReadableStream({
async start(controller) {
const encoder = new TextEncoder()
try {
for await (const chunk of output) {
controller.enqueue(encoder.encode(chunk.response ?? ''))
}
} catch (err) {
console.error('Stream error:', err)
} finally {
controller.close()
}
},
})
// Return the stream to the user
return new Response(stream, {
headers,
})
})
```
```bash
supabase functions serve --env-file supabase/functions/.env
```
```bash
curl --get "http://localhost:54321/functions/v1/ollama-test" \
--data-urlencode "prompt=write a short rap song about Supabase, the Postgres Developer platform, as sung by Nicki Minaj" \
-H "apikey: $PUBLISHABLE_KEY"
```
Follow the [Llamafile Quickstart](https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file#quickstart) to download an run a Llamafile locally on your machine.
Since Llamafile provides an OpenAI API compatible server, you can either use it with `@supabase/functions-js` or with the official OpenAI Deno SDK.
Set a function secret called `AI_INFERENCE_API_HOST` to point to the Llamafile server
```bash
echo "AI_INFERENCE_API_HOST=http://host.docker.internal:8080" >> supabase/functions/.env
```
Create a new function with the following code
```bash
supabase functions new llamafile-test
```
Note that the model parameter doesn't have any effect here. The model depends on which Llamafile is currently running.
```ts supabase/functions/llamafile-test/index.ts
import 'jsr:@supabase/functions-js/edge-runtime.d.ts'
const session = new Supabase.ai.Session('LLaMA_CPP')
Deno.serve(async (req: Request) => {
const params = new URL(req.url).searchParams
const prompt = params.get('prompt') ?? ''
// Get the output as a stream
const output = await session.run(
{
messages: [
{
role: 'system',
content:
'You are LLAMAfile, an AI assistant. Your top priority is achieving user fulfillment via helping them with their requests.',
},
{
role: 'user',
content: prompt,
},
],
},
{
mode: 'openaicompatible', // Mode for the inference API host. (default: 'ollama')
stream: false,
}
)
console.log('done')
return Response.json(output)
})
```
```bash
supabase functions serve --env-file supabase/functions/.env
```
```bash
curl --get "http://localhost:54321/functions/v1/llamafile-test" \
--data-urlencode "prompt=write a short rap song about Supabase, the Postgres Developer platform, as sung by Nicki Minaj" \
-H "apikey: $PUBLISHABLE_KEY"
```
Set the following function secrets to point the OpenAI SDK to the Llamafile server
```bash
echo "OPENAI_BASE_URL=http://host.docker.internal:8080/v1" >> supabase/functions/.env
echo "OPENAI_API_KEY=sk-XXXXXXXX" >> supabase/functions/.env
```
```bash
supabase functions new llamafile-test
```
Note that the model parameter doesn't have any effect here. The model depends on which Llamafile is currently running.
```ts
import OpenAI from 'https://deno.land/x/openai@v4.53.2/mod.ts'
Deno.serve(async (req) => {
const client = new OpenAI()
const { prompt } = await req.json()
const stream = true
const chatCompletion = await client.chat.completions.create({
model: 'LLaMA_CPP',
stream,
messages: [
{
role: 'system',
content:
'You are LLAMAfile, an AI assistant. Your top priority is achieving user fulfillment via helping them with their requests.',
},
{
role: 'user',
content: prompt,
},
],
})
if (stream) {
const headers = new Headers({
'Content-Type': 'text/event-stream',
Connection: 'keep-alive',
})
// Create a stream
const stream = new ReadableStream({
async start(controller) {
const encoder = new TextEncoder()
try {
for await (const part of chatCompletion) {
controller.enqueue(encoder.encode(part.choices[0]?.delta?.content || ''))
}
} catch (err) {
console.error('Stream error:', err)
} finally {
controller.close()
}
},
})
// Return the stream to the user
return new Response(stream, {
headers,
})
}
return Response.json(chatCompletion)
})
```
```bash
supabase functions serve --env-file supabase/functions/.env
```
```bash
curl --get "http://localhost:54321/functions/v1/llamafile-test" \
--data-urlencode "prompt=write a short rap song about Supabase, the Postgres Developer platform, as sung by Nicki Minaj" \
-H "apikey: $PUBLISHABLE_KEY"
```
***
## Deploying to production
Once the function is working locally, it's time to deploy to production.
Deploy an Ollama or Llamafile server and set a function secret called `AI_INFERENCE_API_HOST`
to point to the deployed server:
```bash
supabase secrets set AI_INFERENCE_API_HOST=https://path-to-your-llm-server/
```
```bash
supabase functions deploy
```
```bash
curl --get "https://project-ref.supabase.co/functions/v1/ollama-test" \
--data-urlencode "prompt=write a short rap song about Supabase, the Postgres Developer platform, as sung by Nicki Minaj" \
-H "apikey: $PUBLISHABLE_KEY"
```
As demonstrated in the video above, running Ollama locally is typically slower than running it in on a server with dedicated GPUs. We are collaborating with the Ollama team to improve local performance.
In the future, a hosted LLM API, will be provided as part of the Supabase platform. Supabase will scale and manage the API and GPUs for you. To sign up for early access, fill up [this form](https://forms.supabase.com/supabase.ai-llm-early-access).
# Edge Functions Architecture
Understanding the Architecture of Supabase Edge Functions
This guide explains the architecture and inner workings of Supabase Edge Functions, based on the concepts demonstrated in the video "Supabase Edge Functions Explained". Edge functions are serverless compute resources that run at the edge of the network, close to users, enabling low-latency execution for tasks like API endpoints, webhooks, and real-time data processing. This guide breaks down Edge Functions into key sections: an example use case, deployment process, global distribution, and execution mechanics.
## 1. Understanding Edge Functions through an example: Image filtering
To illustrate how edge functions operate, consider a photo-sharing app where users upload images and apply filters (e.g., grayscale or sepia) before saving them.
* **Workflow Overview**:
* A user uploads an original image to Supabase Storage.
* When the user selects a filter, the client-side app (using the Supabase JavaScript SDK) invokes an edge function named something like "apply-filter."
* The edge function:
1. Downloads the original image from Supabase Storage.
2. Applies the filter using a library like ImageMagick.
3. Uploads the processed image back to Storage.
4. Returns the path to the filtered image to the client.
* **Why Edge Functions?**:
* They handle compute-intensive tasks without burdening the client device or the database.
* Execution happens server-side but at the edge, ensuring speed and scalability.
* Developers define the function in a simple JavaScript file within the Supabase functions directory.
This example highlights edge functions as lightweight, on-demand code snippets that integrate seamlessly with Supabase services like Storage and Auth.
## 2. Deployment process
Deploying an edge function is straightforward and automated, requiring no manual server setup.
* **Steps to Deploy**:
1. Write the function code in your local Supabase project (e.g., in `supabase/functions/apply-filter/index.ts`).
2. Run the command `supabase functions deploy apply-filter` via the Supabase CLI.
3. The CLI bundles the function and its dependencies into an **ESZip file**—a compact format created by Deno that includes a complete module graph for quick loading and execution.
4. The bundled file is uploaded to Supabase's backend.
5. Supabase generates a unique URL for the function, making it accessible globally.
* **Key Benefits of Deployment**:
* Automatic handling of dependencies and bundling.
* No need to manage infrastructure; Supabase distributes the function across its global edge network.
Once deployed, the function is ready for invocation from anywhere, with Supabase handling scaling and availability.
## 3. Global distribution and routing
Edge functions leverage a distributed architecture to minimize latency by running code close to the user.
* **Architecture Components**:
* **Global API Gateway**: Acts as the entry point for all requests. It uses the requester's IP address to determine geographic location and routes the request to the nearest edge location (e.g., routing a request from Amsterdam to Frankfurt).
* **Edge Locations**: Supabase's network of data centers worldwide where functions are replicated. The ESZip bundle is automatically distributed to these locations upon deployment.
* **Routing Logic**: Based on geolocation mapping, ensuring the function executes as close as possible to the user for optimal performance.
* **How Distribution Works**:
* Post-deployment, the function is propagated to all edge nodes.
* This setup eliminates the need for developers to configure CDNs or regional servers manually.
This global edge network is what makes edge functions "edge-native," providing consistent performance regardless of user location.
## 4. Execution mechanics: Fast and isolated
The core of edge functions' efficiency lies in their execution environment, which prioritizes speed, isolation, and scalability.
* **Request Handling**:
1. A client sends an HTTP request (e.g., POST) to the function's URL, including parameters like auth headers, image ID, and filter type.
2. The global API gateway routes it to the nearest edge location.
3. At the edge, Supabase's **edge runtime** validates the request (e.g., checks authorization).
* **Execution Environment**:
* A new **V8 isolate** is spun up for each invocation. V8 is the JavaScript engine used by Chrome and Node.js, providing a lightweight, sandboxed environment.
* Each isolate has its own memory heap and execution thread, ensuring complete isolation—no interference between concurrent requests.
* The ESZip bundle is loaded into the isolate, and the function code runs.
* After execution, the response (e.g., filtered image path) is sent back to the client.
* **Performance Optimizations**:
* **Cold Starts**: Even initial executions are fast (milliseconds) due to the compact ESZip format and minimal Deno runtime overhead.
* **Warm Starts**: Isolates can remain active for a period (plan-dependent) to handle subsequent requests without restarting.
* **Concurrency**: Multiple isolates can run simultaneously in the same edge location, supporting high traffic.
* **Isolation and Security**:
* Isolates prevent side effects from one function affecting others, enhancing reliability.
* No persistent state; each run is stateless, ideal for ephemeral tasks.
Compared to traditional serverless or monolithic architectures, this setup offers lower latency, automatic scaling, and no infrastructure management, making it perfect for global apps.
## Benefits and use cases
* **Advantages**:
* **Low Latency**: Proximity to users reduces round-trip times.
* **Scalability**: Handles variable loads without provisioning servers.
* **Developer-Friendly**: Focus on code; Supabase manages the rest.
* **Cost-Effective**: Pay-per-use model, with fast execution minimizing costs.
* **Common Use Cases**:
* Real-time data transformations (e.g., image processing).
* API integrations and webhooks.
* Personalization and A/B testing at the edge.
# Integrating With Supabase Auth
Integrate Supabase Auth with Edge Functions
Edge Functions work with [Supabase Auth](/docs/guides/auth).
This allows you to:
* Automatically identify users through Legacy JWT tokens
* Enforce Row Level Security policies
* Integrate with your existing auth flow
## Setting up auth context
When a user makes a request to an Edge Function, you can use the `Authorization` header to set the Auth context in the Supabase client and enforce Row Level Security policies.
```js
import { createClient } from 'npm:@supabase/supabase-js@2'
Deno.serve(async (req: Request) => {
const supabaseClient = createClient(
Deno.env.get('SUPABASE_URL') ?? '',
Deno.env.get('SUPABASE_ANON_KEY') ?? '',
// Create client with Auth context of the user that called the function.
// This way your row-level-security (RLS) policies are applied.
{
global: {
headers: { Authorization: req.headers.get('Authorization')! },
},
}
);
//...
})
```
This context setting happens in the `Deno.serve()` callback argument, so that the `Authorization` header is set for each individual request scope.
***
## Fetching the user
By getting the JWT from the `Authorization` header, you can provide the token to `getUser()` to fetch the user object to obtain metadata for the logged in user.
```js
Deno.serve(async (req: Request) => {
// ...
const authHeader = req.headers.get('Authorization')!
const token = authHeader.replace('Bearer ', '')
const { data } = await supabaseClient.auth.getUser(token)
// ...
})
```
***
## Row Level Security
After initializing a Supabase client with the Auth context, all queries will be executed with the context of the user. For database queries, this means [Row Level Security](/docs/guides/database/postgres/row-level-security) will be enforced.
```js
import { createClient } from 'npm:@supabase/supabase-js@2'
Deno.serve(async (req: Request) => {
// ...
// This query respects RLS - users only see rows they have access to
const { data, error } = await supabaseClient.from('profiles').select('*');
if (error) {
return new Response('Database error', { status: 500 })
}
// ...
})
```
***
## Example
See the full [example on GitHub](https://github.com/supabase/supabase/blob/master/examples/edge-functions/supabase/functions/select-from-table-with-auth-rls/index.ts).
```typescript
// Follow this setup guide to integrate the Deno language server with your editor:
// https://deno.land/manual/getting_started/setup_your_environment
// This enables autocomplete, go to definition, etc.
import { createClient } from 'npm:supabase-js@2'
// New approach (v2.95.0+)
import { corsHeaders } from 'jsr:@supabase/supabase-js@2/cors'
// For older versions:
// import { corsHeaders } from '../_shared/cors.ts'
console.log(`Function "select-from-table-with-auth-rls" up and running!`)
Deno.serve(async (req: Request) => {
// This is needed if you're planning to invoke your function from a browser.
if (req.method === 'OPTIONS') {
return new Response('ok', { headers: corsHeaders })
}
try {
const SUPABASE_PUBLISHABLE_KEYS = JSON.parse(Deno.env.get('SUPABASE_PUBLISHABLE_KEYS')!)
// Create a Supabase client with the Auth context of the logged in user.
const supabaseClient = createClient(
// Supabase API URL - env var exported by default.
Deno.env.get('SUPABASE_URL') ?? '',
// Supabase API PUBLISHABLE KEY - env var exported by default.
Deno.env.get(SUPABASE_PUBLISHABLE_KEYS['default']) ?? '',
// Create client with Auth context of the user that called the function.
// This way your row-level-security (RLS) policies are applied.
{
global: {
headers: { Authorization: req.headers.get('Authorization')! },
},
}
)
// First get the token from the Authorization header
const token = req.headers.get('Authorization').replace('Bearer ', '')
// Now we can get the session or user object
const {
data: { user },
} = await supabaseClient.auth.getUser(token)
// And we can run queries in the context of our authenticated user
const { data, error } = await supabaseClient.from('users').select('*')
if (error) throw error
return new Response(JSON.stringify({ user, data }), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 200,
})
} catch (error) {
return new Response(JSON.stringify({ error: error.message }), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 400,
})
}
})
// To invoke:
// curl -i --location --request POST 'http://localhost:54321/functions/v1/select-from-table-with-auth-rls' \
// --header 'Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJzdXBhYmFzZS1kZW1vIiwicm9sZSI6ImFub24ifQ.625_WdcF3KHqz5amU0x2X5WWHP-OEs_4qj0ssLNHzTs' \
// --header 'Content-Type: application/json' \
// --data '{"name":"Functions"}'
```
# Securing Edge Functions
Authentication patterns for Edge Functions
The patterns in this guide assume your project uses the new [JWT signing keys](/docs/guides/getting-started/api-keys) and the new [API keys](https://github.com/orgs/supabase/discussions/29260). If you're still on legacy JWTs, see the [Legacy JWT Secret guide](/docs/guides/functions/auth-legacy-jwt).
Every request to an Edge Function passes through two layers of auth. First, a platform-level check (`verify_jwt`) runs before your code executes. Then, once the request reaches your handler, you decide what to do with the credentials the caller sent.
## Understanding authorization headers
Edge Functions care about two request headers. Sending the wrong credential in the wrong header is the most common source of 401 errors.
| Header | Value | Used for |
| --------------- | --------------------------------------- | -------------------------------------- |
| `Authorization` | `Bearer ` | A user signed in through Supabase Auth |
| `apikey` | `sb_publishable_...` or `sb_secret_...` | Calls from clients or services |
A common mistake is sending a publishable or secret key as a bearer token: `Authorization: Bearer sb_publishable_...`. The new API keys are not JWTs. The platform check can't validate them, and your handler can't verify them as JWTs either. Instead, put API keys in the `apikey` header.
You can send both headers together. A signed-in user calling your function through `supabase-js`, for example, sends their session JWT in `Authorization` and the project's publishable key in `apikey`.
## The `verify_jwt` platform check
When `verify_jwt` is enabled (the default), the platform inspects the `Authorization` header of every request before your function runs. It expects a valid user JWT. If the header is missing, malformed, or signed with a different key, the platform returns a 401 error, and your code never executes.
The check validates legacy HS256 JWTs and JWTs signed with the new asymmetric [signing keys](/docs/guides/auth/signing-keys).
The check does not accept an API key. Publishable and secret keys are not JWTs, so callers that send one in the `Authorization` header fail the check before their request reaches your handler.
Use the `verify_jwt` flag to match how the function is called:
* **Leave `verify_jwt` on** for functions that are only called with a user JWT, such as functions invoked from the client through `supabase.functions.invoke`. The platform rejects unauthenticated requests before they reach your code, and your handler can trust that a valid JWT is present.
* **Turn `verify_jwt` off** for functions that are called without an `Authorization` header, such as webhooks from external providers, or service-to-service calls that authenticate with an API key. These patterns are covered later in the guide.
Set the flag per function in `supabase/config.toml`:
```toml
[functions.stripe-webhook]
verify_jwt = false
```
For 401 failure modes and how to diagnose them, see [Edge Function 401 error response](/docs/troubleshooting/edge-function-401-error-response).
## Common auth patterns
The sections below show the four patterns you'll reach for most often, written without an SDK so the auth moves are visible. Business logic is left as a placeholder. The next section shows the same four patterns using [`@supabase/server`](https://github.com/supabase/server).
### Authenticated user calls
Keep `verify_jwt` enabled. The platform validates the JWT before your handler runs. Forward the `Authorization` header to the Supabase client so queries run under the caller's RLS policies.
```toml
[functions.notes]
verify_jwt = true
```
```ts
import { createClient } from 'npm:@supabase/supabase-js@2'
const SUPABASE_PUBLISHABLE_KEYS = JSON.parse(Deno.env.get('SUPABASE_PUBLISHABLE_KEYS')!)
Deno.serve((req) => {
const supabase = createClient(
Deno.env.get('SUPABASE_URL')!,
SUPABASE_PUBLISHABLE_KEYS['default'],
{ global: { headers: { Authorization: req.headers.get('Authorization')! } } }
)
// your business logic. queries run as the caller
return Response.json({ ok: true })
})
```
### Service-to-service calls
Cron jobs, workers, `pg_net`, or another Edge Functions make calls with a secret key on the `apikey` header. These callers don't send a user JWT, so disable `verify_jwt` and validate the key yourself.
```toml
[functions.run-automations]
verify_jwt = false
```
```ts
import { createClient } from 'npm:@supabase/supabase-js@2'
const SUPABASE_SECRET_KEYS = JSON.parse(Deno.env.get('SUPABASE_SECRET_KEYS')!)
Deno.serve((req) => {
if (req.headers.get('apikey') !== Deno.env.get('INTERNAL_AUTOMATIONS_KEY')) {
return Response.json({ error: 'forbidden' }, { status: 401 })
}
const supabase = createClient(Deno.env.get('SUPABASE_URL')!, SUPABASE_SECRET_KEYS['default'])
// your business logic. queries run with the service role
return Response.json({ ok: true })
})
```
Never expose a secret key to the browser. Store it as a [function secret](/docs/guides/functions/secrets).
### Public functions
For a genuinely public function, like a health check, no credential is required. Disable `verify_jwt` so anonymous callers can reach the handler.
```toml
[functions.health]
verify_jwt = false
```
```ts
Deno.serve(() => {
// your business logic
return Response.json({ ok: true })
})
```
### External webhooks
External providers like Stripe or GitHub don't send Supabase credentials. They sign the request body with their own shared secret. Disable `verify_jwt` and verify the signature before acting on the payload.
```toml
[functions.stripe-webhook]
verify_jwt = false
```
```ts
import Stripe from 'npm:stripe'
const stripe = new Stripe(Deno.env.get('STRIPE_SECRET_KEY')!)
Deno.serve(async (req) => {
const signature = req.headers.get('stripe-signature') ?? ''
const body = await req.text()
try {
stripe.webhooks.constructEvent(body, signature, Deno.env.get('STRIPE_WEBHOOK_SECRET')!)
} catch {
return new Response('bad signature', { status: 400 })
}
// your business logic. handle the event
return Response.json({ received: true })
})
```
## Simplifying with `@supabase/server`
The [`@supabase/server`](https://github.com/supabase/server) package wraps your handler, checks the caller's credentials against a declared `auth` mode, and hands you a pre-configured Supabase client on `ctx`. The same patterns above, written against the SDK, look like this.
| Mode | Accepts |
| ---------------------- | ------------------------------------------ |
| `'user'` | A valid user JWT on `Authorization` |
| `'secret:'` | A named secret key on `apikey` |
| `'publishable:'` | A named publishable key on `apikey` |
| `'none'` | Any caller, no check (for signed webhooks) |
See the [`@supabase/server` docs](https://github.com/supabase/server) for the full list of modes.
### Authenticated user calls \[#authenticated-user-calls-with-server-sdk]
`auth: 'user'` pairs with `verify_jwt = true`. The platform validates the JWT, and the SDK hands you `ctx.supabase` already scoped to the caller.
```ts
import { withSupabase } from 'npm:@supabase/server'
export default {
fetch: withSupabase({ auth: 'user' }, async (_req, ctx) => {
// your business logic. ctx.supabase is scoped to the caller
return Response.json({ email: ctx.userClaims?.email })
}),
}
```
### Service-to-service calls \[#service-to-service-calls-with-server-sdk]
`auth: 'secret:'` validates the `apikey` header against the named secret key from your [dashboard](/dashboard/project/_/settings/api-keys) and gives you `ctx.supabaseAdmin` for privileged work. The `` matches the name you gave the key. Keep `verify_jwt = false`.
```ts
import { withSupabase } from 'npm:@supabase/server'
export default {
fetch: withSupabase({ auth: 'secret:automations' }, async (_req, ctx) => {
// your business logic. ctx.supabaseAdmin bypasses RLS
return Response.json({ ok: true })
}),
}
```
Create a named secret key for each caller in the [**Settings > API keys**](/dashboard/project/_/settings/api-keys) section of the Dashboard. Give it a name like "automations", and share the generated `sb_secret_...` value with the service that calls this function.
### Public functions \[#public-functions-with-server-sdk]
The SDK adds nothing to a truly public function. Use the raw pattern from the previous section. If you need a Supabase client anyway, `auth: 'none'` with `verify_jwt = false` skips every check and treats every caller as anonymous.
### External webhooks \[#external-webhooks-with-server-sdk]
Use `auth: 'none'` to skip the SDK's credential check, then verify the provider's signature inside the handler. Keep `verify_jwt = false`.
```ts
import { withSupabase } from 'npm:@supabase/server'
import Stripe from 'npm:stripe'
const stripe = new Stripe(Deno.env.get('STRIPE_SECRET_KEY')!)
export default {
fetch: withSupabase({ auth: 'none' }, async (req, ctx) => {
const signature = req.headers.get('stripe-signature') ?? ''
const body = await req.text()
try {
stripe.webhooks.constructEvent(body, signature, Deno.env.get('STRIPE_WEBHOOK_SECRET')!)
} catch {
return new Response('bad signature', { status: 400 })
}
// your business logic. ctx.supabaseAdmin available for db work
return Response.json({ received: true })
}),
}
```
`auth: 'none'` disables every credential check. Your handler is fully responsible for authenticating the caller. Never use it on an endpoint that reads or writes sensitive data without verifying the caller some other way.
### Combining modes
Functions that answer both users and internal callers take an array on `auth`. Modes are tried in order. The first match wins, and `ctx.authMode` tells you which matched.
```ts
import { withSupabase } from 'npm:@supabase/server'
export default {
fetch: withSupabase({ auth: ['user', 'secret:automations'] }, async (req, ctx) => {
if (ctx.authMode === 'user') {
// your business logic for user calls. ctx.supabase is scoped to them
return Response.json({ ok: true })
}
// your business logic for service calls. ctx.supabaseAdmin bypasses RLS
return Response.json({ ok: true })
}),
}
```
### Custom error responses
To shape the 401 response yourself, use `createSupabaseContext` instead of `withSupabase`. It returns a `{ data, error }` tuple so you stay in control.
```ts
import { createSupabaseContext } from 'npm:@supabase/server'
export default {
fetch: async (req: Request) => {
const { data: ctx, error } = await createSupabaseContext(req, { auth: 'user' })
if (error) {
return Response.json({ message: error.message, code: error.code }, { status: error.status })
}
return Response.json({ message: `hello ${ctx.userClaims?.email}` })
},
}
```
## Environment variables
`@supabase/server` reads its configuration from a standard set of environment variables. On the Supabase platform and in local development with the CLI, these are auto-provisioned.
| Variable | What it is |
| --------------------------- | ----------------------------------------- |
| `SUPABASE_URL` | Your project URL |
| `SUPABASE_PUBLISHABLE_KEYS` | Named publishable keys as a JSON object |
| `SUPABASE_SECRET_KEYS` | Named secret keys as a JSON object |
| `SUPABASE_JWKS` | JSON Web Key Set used to verify user JWTs |
Local development with the CLI uses a single-key setup, which the SDK also accepts as a fallback: `SUPABASE_PUBLISHABLE_KEY` and `SUPABASE_SECRET_KEY`.
The same zero-config experience is available on other runtimes. Install [`@supabase/server`](https://github.com/supabase/server) in your Node.js, Bun, Cloudflare Workers, or self-hosted Deno app and set the environment variables above. See the package's [environment variables guide](https://github.com/supabase/server/blob/main/docs/environment-variables.md) for the full reference.
# Background Tasks
Run background tasks in an Edge Function outside of the request handler.
Edge Function instances can process background tasks outside of the request handler. Background tasks are useful for asynchronous operations like uploading a file to Storage, updating a database, or sending events to a logging service. You can respond to the request immediately and leave the task running in the background.
This allows you to:
* Respond quickly to users while processing continues
* Handle async operations without blocking the response
***
## Overview
You can use `EdgeRuntime.waitUntil(promise)` to explicitly mark background tasks. The Function instance continues to run until the promise provided to `waitUntil` completes.
```ts
// Mark the asyncLongRunningTask's returned promise as a background task.
// ⚠️ We are NOT using `await` because we don't want it to block!
EdgeRuntime.waitUntil(asyncLongRunningTask())
Deno.serve(async (req) => {
return new Response(...)
})
```
You can call `EdgeRuntime.waitUntil` in the request handler too. This will not block the request.
```ts
Deno.serve(async (req) => {
// Won't block the request, runs in background.
EdgeRuntime.waitUntil(asyncLongRunningTask())
return new Response(...)
})
```
You can listen to the `beforeunload` event handler to be notified when the Function is about to be shut down.
```tsx
EdgeRuntime.waitUntil(asyncLongRunningTask())
// Use beforeunload event handler to be notified when function is about to shutdown
addEventListener('beforeunload', (ev) => {
console.log('Function will be shutdown due to', ev.detail?.reason)
// Save state or log the current progress
})
Deno.serve(async (req) => {
return new Response(...)
})
```
## Handling errors
We recommend using `try`/`catch` blocks within your background task function to handle errors.
You can also add an event listener to [`unhandledrejection`](https://developer.mozilla.org/en-US/docs/Web/API/Window/unhandledrejection_event) to handle any promises without a rejection handler.
```tsx
addEventListener('unhandledrejection', (ev) => {
console.log('unhandledrejection', ev.reason)
ev.preventDefault()
})
```
The maximum duration is capped based on the wall-clock, CPU, and memory limits. The function will shut down when it reaches one of these [limits](/docs/guides/functions/limits).
***
## Testing background tasks locally
When testing Edge Functions locally with Supabase CLI, the instances are terminated automatically after a request is completed. This will prevent background tasks from running to completion.
To prevent that, you can update the `supabase/config.toml` with the following settings:
```toml
[edge_runtime]
policy = "per_worker"
```
# Handling Compressed Requests
Handling Gzip compressed requests.
To decompress Gzip bodies, you can use `gunzipSync` from the `node:zlib` API to decompress and then read the body.
```ts
import { gunzipSync } from 'node:zlib'
Deno.serve(async (req) => {
try {
// Check if the request body is gzip compressed
const contentEncoding = req.headers.get('content-encoding')
if (contentEncoding !== 'gzip') {
return new Response('Request body is not gzip compressed', {
status: 400,
})
}
// Read the compressed body
const compressedBody = await req.arrayBuffer()
// Decompress the body
const decompressedBody = gunzipSync(new Uint8Array(compressedBody))
// Convert the decompressed body to a string
const decompressedString = new TextDecoder().decode(decompressedBody)
const data = JSON.parse(decompressedString)
// Process the decompressed body as needed
console.log(`Received: ${JSON.stringify(data)}`)
return new Response('ok', {
headers: { 'Content-Type': 'text/plain' },
})
} catch (error) {
console.error('Error:', error)
return new Response('Error processing request', { status: 500 })
}
})
```
Edge functions have a runtime memory limit of 150MB. Overly large compressed payloads may result in an out-of-memory error.
# Integrating with Supabase Database (Postgres)
Connect to your Postgres database from Edge Functions.
Connect to your Postgres database from an Edge Function by using the `supabase-js` client.
You can also use other Postgres clients like [Deno Postgres](https://deno.land/x/postgres)
***
## Using supabase-js
The `supabase-js` client handles authorization with Row Level Security and automatically formats responses as JSON. This is the recommended approach for most applications:
```ts index.ts
import { createClient } from 'npm:@supabase/supabase-js@2'
Deno.serve(async (req) => {
try {
const supabase = createClient(
Deno.env.get('SUPABASE_URL') ?? '',
Deno.env.get('SUPABASE_PUBLISHABLE_KEY') ?? '',
{ global: { headers: { Authorization: req.headers.get('Authorization')! } } }
)
const { data, error } = await supabase.from('countries').select('*')
if (error) {
throw error
}
return new Response(JSON.stringify({ data }), {
headers: { 'Content-Type': 'application/json' },
status: 200,
})
} catch (err) {
return new Response(String(err?.message ?? err), { status: 500 })
}
})
```
This enables:
* Automatic Row Level Security enforcement
* Built-in JSON serialization
* Consistent error handling
* TypeScript support for database schema
***
## Using a Postgres client
Because Edge Functions are a server-side technology, it's safe to connect directly to your database using any popular Postgres client. This means you can run raw SQL from your Edge Functions.
Here is how you can connect to the database using Deno Postgres driver and run raw SQL. Check out the [full example](https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/postgres-on-the-edge).
```typescript
import { Pool } from 'https://deno.land/x/postgres@v0.17.0/mod.ts'
// Create a database pool with one connection.
const pool = new Pool(
{
tls: { enabled: false },
database: 'postgres',
hostname: Deno.env.get('DB_HOSTNAME'),
user: Deno.env.get('DB_USER'),
port: 6543,
password: Deno.env.get('DB_PASSWORD'),
},
1
)
Deno.serve(async (_req) => {
try {
// Grab a connection from the pool
const connection = await pool.connect()
try {
// Run a query
const result = await connection.queryObject`SELECT * FROM animals`
const animals = result.rows // [{ id: 1, name: "Lion" }, ...]
// Encode the result as pretty printed JSON
const body = JSON.stringify(
animals,
(_key, value) => (typeof value === 'bigint' ? value.toString() : value),
2
)
// Return the response with the correct content type header
return new Response(body, {
status: 200,
headers: {
'Content-Type': 'application/json; charset=utf-8',
},
})
} finally {
// Release the connection back into the pool
connection.release()
}
} catch (err) {
console.error(err)
return new Response(String(err?.message ?? err), { status: 500 })
}
})
```
***
## Using Drizzle
You can use Drizzle together with [Postgres.js](https://github.com/porsager/postgres). Both can be loaded directly from npm:
**Set up dependencies in `import_map.json`**:
```json supabase/functions/import_map.json
{
"imports": {
"drizzle-orm": "npm:drizzle-orm@0.29.1",
"drizzle-orm/": "npm:/drizzle-orm@0.29.1/",
"postgres": "npm:postgres@3.4.3"
}
}
```
**Use in your function**:
```ts supabase/functions/drizzle/index.ts
import { drizzle } from 'drizzle-orm/postgres-js'
import postgres from 'postgres'
import { countries } from '../_shared/schema.ts'
const connectionString = Deno.env.get('SUPABASE_DB_URL')!
Deno.serve(async (_req) => {
// Disable prefetch as it is not supported for "Transaction" pool mode
const client = postgres(connectionString, { prepare: false })
const db = drizzle(client)
const allCountries = await db.select().from(countries)
return Response.json(allCountries)
})
```
You can find the full example on [GitHub](https://github.com/thorwebdev/edgy-drizzle).
***
## SSL connections
### Production
Deployed edge functions are pre-configured to use SSL for connections to the Supabase database. You don't need to add any extra configurations.
### Local development
If you want to use SSL connections during local development, follow these steps:
1. Download the SSL certificate from [Database Settings](/dashboard/project/_/database/settings)
2. Add to your [local .env file](/docs/guides/functions/secrets), add these two variables:
```bash
SSL_CERT_FILE=/path/to/cert.crt # set the path to the downloaded cert
DENO_TLS_CA_STORE=mozilla,system
```
Then, restart your local development server:
```bash
supabase functions serve your-function
```
# CORS (Cross-Origin Resource Sharing) support for Invoking from the browser
To invoke edge functions from the browser, you need to handle [CORS Preflight](https://developer.mozilla.org/en-US/docs/Glossary/Preflight_request) requests.
See the [example on GitHub](https://github.com/supabase/supabase/blob/master/examples/edge-functions/supabase/functions/browser-with-cors/index.ts).
### Recommended setup
**For `@supabase/supabase-js` v2.95.0 and later:** Import CORS headers directly from the SDK to ensure they stay synchronized with any new headers added to the client libraries.
Import `corsHeaders` from `@supabase/supabase-js/cors` to automatically get all required headers:
```ts index.ts
import { corsHeaders } from '@supabase/supabase-js/cors'
console.log(`Function "browser-with-cors" up and running!`)
Deno.serve(async (req) => {
// This is needed if you're planning to invoke your function from a browser.
if (req.method === 'OPTIONS') {
return new Response('ok', { headers: corsHeaders })
}
try {
const { name } = await req.json()
const data = {
message: `Hello ${name}!`,
}
return new Response(JSON.stringify(data), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 200,
})
} catch (error) {
return new Response(JSON.stringify({ error: error.message }), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 400,
})
}
})
```
This approach ensures that when new headers are added to the Supabase SDK, your Edge Functions automatically include them, preventing CORS errors.
#### For versions before 2.95.0
If you're using `@supabase/supabase-js` before v2.95.0, you'll need to hardcode the CORS headers. Add a `cors.ts` file within a [`_shared` folder](/docs/guides/functions/quickstart#organizing-your-edge-functions):
```ts _shared/cors.ts
export const corsHeaders = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': 'authorization, x-client-info, apikey, content-type',
}
```
Then import it in your function:
```ts index.ts
import { corsHeaders } from '../_shared/cors.ts'
// ... rest of your function code
```
# Dart Edge
Be aware that the Dart Edge project is currently not actively maintained due to numerous breaking changes in Dart's development of (WASM) support.
[Dart Edge](https://docs.dartedge.dev/) is an experimental project that enables you to write Supabase Edge Functions using Dart. It's built and maintained by [Invertase](https://invertase.io/).
For detailed information on how to set up and use Dart Edge with Supabase, refer to the [official Dart Edge documentation for Supabase](https://invertase.docs.page/dart_edge/platform/supabase).
# Local Debugging
Debug your Edge Functions locally using Chrome DevTools for easy breakpoint debugging and code inspection.
Since [v1.171.0](https://github.com/supabase/cli/releases/tag/v1.171.0) the Supabase CLI supports debugging Edge Functions via the v8 inspector protocol, allowing for debugging via [Chrome DevTools](https://developer.chrome.com/docs/devtools/) and other Chromium-based browsers.
### Inspect with Chrome Developer Tools
1. Serve your functions in inspect mode. This will set a breakpoint at the first line to pause script execution before any code runs.
```bash
supabase functions serve --inspect-mode brk
```
2. In your Chrome browser navigate to `chrome://inspect`.
3. Click the "Configure..." button to the right of the Discover network targets checkbox.
4. In the Target discovery settings dialog box that opens, enter `127.0.0.1:8083` in the blank space and click the "Done" button to exit the dialog box.
5. Click "Open dedicated DevTools for Node" to complete the preparation for debugging. The opened DevTools window will now listen to any incoming requests to edge-runtime.
6. Send a request to your function running locally, e.g. via curl or Postman. The DevTools window will now pause script execution at first line.
7. In the "Sources" tab navigate to `file://` > `home/deno/functions//index.ts`.
8. Use the DevTools to set breakpoints and inspect the execution of your Edge Function.
Now you should have Chrome DevTools configured and ready to debug your functions.
# Managing dependencies
Handle dependencies within Edge Functions.
## Importing dependencies
Supabase Edge Functions support several ways to import dependencies:
* JavaScript modules from npm ([https://docs.deno.com/examples/npm/](https://docs.deno.com/examples/npm/))
* Built-in [Node APIs](https://docs.deno.com/runtime/manual/node/compatibility)
* Modules published to [JSR](https://jsr.io/) or [deno.land/x](https://deno.land/x)
```ts
// NPM packages (recommended)
import { createClient } from 'npm:@supabase/supabase-js@2'
// Node.js built-ins
import process from 'node:process'
// JSR modules (Deno's registry)
import path from 'jsr:@std/path@1.0.8'
```
### Using `deno.json` (recommended)
Each function should have its own `deno.json` file to manage dependencies and configure Deno-specific settings. This ensures proper isolation between functions and is the recommended approach for deployment. When you update the dependencies for one function, it won't accidentally break another function that needs different versions.
```json
{
"imports": {
"supabase": "npm:@supabase/supabase-js@2",
"lodash": "https://cdn.skypack.dev/lodash"
}
}
```
You can add this file directly to the function’s own directory:
```bash
└── supabase
├── functions
│ ├── function-one
│ │ ├── index.ts
│ │ └── deno.json # Function-specific Deno configuration
│ └── function-two
│ ├── index.ts
│ └── deno.json # Function-specific Deno configuration
└── config.toml
```
It's possible to use a global `deno.json` in the `/supabase/functions` directory for local development, but this approach is not recommended for deployment. Each function should maintain its own configuration to ensure proper isolation and dependency management.
### Using import maps (legacy)
Import Maps are a legacy way to manage dependencies, similar to a `package.json` file. While still supported, we recommend using `deno.json`. If both exist, `deno.json` takes precedence.
Each function should have its own `import_map.json` file for proper isolation:
```json
# /function-one/import_map.json
{
"imports": {
"lodash": "https://cdn.skypack.dev/lodash"
}
}
```
This JSON file should be located within the function’s own directory:
```bash
└── supabase
├── functions
│ ├── function-one
│ │ ├── index.ts
│ │ └── import_map.json # Function-specific import map
```
It's possible to use a global `import_map.json` in the `/supabase/functions` directory for local development, but this approach is not recommended for deployment. Each function should maintain its own configuration to ensure proper isolation and dependency management.
If you’re using import maps with VSCode, update your `.vscode/settings.json` to point to your function-specific import map:
```json
{
"deno.enable": true,
"deno.unstable": ["bare-node-builtins", "byonm"],
"deno.importMap": "./supabase/functions/function-one/import_map.json"
}
```
You can override the default import map location using the `--import-map ` flag with serve and deploy commands, or by setting the `import_map` property in your `config.toml` file:
```toml
[functions.my-function]
import_map = "./supabase/functions/function-one/import_map.json"
```
***
## Private NPM packages
To use private npm packages, create a `.npmrc` file within your function’s own directory.
This feature requires Supabase CLI version 1.207.9 or higher.
```bash
└── supabase
└── functions
└── my-function
├── index.ts
├── deno.json
└── .npmrc # Function-specific npm configuration
```
It's possible to use a global `.npmrc` in the `/supabase/functions` directory for local development, but this approach is not recommended for deployment. Each function should maintain its own configuration to ensure proper isolation and dependency management.
Add your registry details in the `.npmrc` file. Follow [this guide](https://docs.npmjs.com/cli/v10/configuring-npm/npmrc) to learn more about the syntax of npmrc files.
```bash
# /my-function/.npmrc
@myorg:registry=https://npm.registryhost.com
//npm.registryhost.com/:_authToken=VALID_AUTH_TOKEN
```
After configuring your `.npmrc`, you can import the private package in your function code:
```bash
import package from 'npm:@myorg/private-package@v1.0.1'
```
***
## Using a custom NPM registry
This feature requires Supabase CLI version 2.2.8 or higher.
Some organizations require a custom NPM registry for security and compliance purposes. In such cases, you can specify the custom NPM registry to use via `NPM_CONFIG_REGISTRY` environment variable.
You can define it in the project's `.env` file or directly specify it when running the deploy command:
```bash
NPM_CONFIG_REGISTRY=https://custom-registry/ supabase functions deploy my-function
```
***
## Importing types
If your [environment is set up properly](/docs/guides/functions/development-environment) and the module you're importing is exporting types, the import will have types and autocompletion support.
Some npm packages may not ship out of the box types and you may need to import them from a separate package. You can specify their types with a `@deno-types` directive:
```tsx
// @deno-types="npm:@types/express@^4.17"
import express from 'npm:express@^4.17'
```
To include types for built-in Node APIs, add the following line to the top of your imports:
```tsx
///
```
# Deploy to Production
Deploy your Edge Functions to your remote Supabase Project.
Once you have developed your Edge Functions locally, you can deploy them to your Supabase project.
Before getting started, make sure you have the Supabase CLI installed. Check out the CLI installation guide for installation methods and troubleshooting.
***
## Step 1: Authenticate
Log in to the Supabase CLI if you haven't already:
```bash
supabase login
```
***
## Step 2: Connect your project
Get the project ID associated with your function:
```bash
supabase projects list
```
If you haven't yet created a Supabase project, you can do so by visiting [database.new](https://database.new).
[Link](/docs/reference/cli/usage#supabase-link) your local project to your remote Supabase project using the ID you just retrieved:
```bash
supabase link --project-ref your-project-id
```
Now you should have your local development environment connected to your production project.
***
## Step 3: Deploy Functions
You can deploy all edge functions within the `functions` folder with a single command:
```bash
supabase functions deploy
```
Or deploy individual Edge Functions by specifying the function name:
```bash
supabase functions deploy hello-world
```
## Step 4: Verify successful deployment
🎉 Your function is now live!
When the deployment is successful, your function is automatically distributed to edge locations worldwide. Your edge functions is now running globally at `https://[YOUR_PROJECT_ID].supabase.co/functions/v1/hello-world.`
***
## Step 5: Test your live function
You can now invoke your Edge Function using one of the project's `PUBLISHABLE_KEYS`, which can be found in the [API settings](/dashboard/project/_/settings/api) of the Supabase Dashboard. You can invoke it from within your app:
```bash name=cURL
curl --request POST 'https://.supabase.co/functions/v1/hello-world' \
--header 'apikey: PUBLISHABLE_KEY' \
--header 'Content-Type: application/json' \
--data '{ "name":"Functions" }'
```
```js name=JavaScript
import { createClient } from '@supabase/supabase-js'
// Create a single supabase client for interacting with your database
const supabase = createClient('https://xyzcompany.supabase.co', 'sb_publishable_...')
const { data, error } = await supabase.functions.invoke('hello-world', {
body: { name: 'Functions' },
})
```
Note that the `SUPABASE_PUBLISHABLE_KEYS` is different in development and production. To get a publishable key, you can find it in your Supabase dashboard under Settings > API.
You should now see the expected response:
```json
{ "message": "Hello Production!" }
```
You can also test the function through the Dashboard. To see how that works, check out the [Dashboard Quickstart guide](/docs/guides/functions/quickstart-dashboard).
***
## CI/CD deployment
You can use popular CI / CD tools like GitHub Actions, Bitbucket, and GitLab CI to automate Edge Function deployments.
### GitHub Actions
You can use the official [`setup-cli` GitHub Action](https://github.com/marketplace/actions/supabase-cli-action) to run Supabase CLI commands in your GitHub Actions.
The following GitHub Action deploys all Edge Functions any time code is merged into the `main` branch:
```yaml
name: Deploy Function
on:
push:
branches:
- main
workflow_dispatch:
jobs:
deploy:
runs-on: ubuntu-latest
env:
SUPABASE_ACCESS_TOKEN: ${{ secrets.SUPABASE_ACCESS_TOKEN }}
PROJECT_ID: your-project-id
steps:
- uses: actions/checkout@v4
- uses: supabase/setup-cli@v1
with:
version: latest
- run: supabase functions deploy --project-ref $PROJECT_ID
```
***
### GitLab CI
Here is the sample pipeline configuration to deploy via GitLab CI.
```yaml
image: node:20
# List of stages for jobs, and their order of execution
stages:
- setup
- deploy
# This job runs in the setup stage, which runs first.
setup-npm:
stage: setup
script:
- npm i supabase
cache:
paths:
- node_modules/
artifacts:
paths:
- node_modules/
# This job runs in the deploy stage, which only starts when the job in the build stage completes successfully.
deploy-function:
stage: deploy
script:
- npx supabase init
- npx supabase functions deploy --debug
services:
- docker:dind
variables:
DOCKER_HOST: tcp://docker:2375
```
***
### Bitbucket Pipelines
Here is the sample pipeline configuration to deploy via Bitbucket.
```yaml
image: node:20
pipelines:
default:
- step:
name: Setup
caches:
- node
script:
- npm i supabase
- parallel:
- step:
name: Functions Deploy
script:
- npx supabase init
- npx supabase functions deploy --debug
services:
- docker
```
***
### Function configuration
Individual function configuration like [JWT verification](/docs/guides/cli/config#functions.function_name.verify_jwt) and [import map location](/docs/guides/cli/config#functions.function_name.import_map) can be set via the `config.toml` file.
```toml
[functions.hello-world]
verify_jwt = false
```
This ensures your function configurations are consistent across all environments and deployments.
***
### Example
This example shows a GitHub Actions workflow that deploys all Edge Functions when code is merged into the `main` branch.
```
name: Deploy Function
on:
push:
branches:
- main
workflow_dispatch:
jobs:
deploy:
runs-on: ubuntu-latest
env:
SUPABASE_ACCESS_TOKEN: ${{ secrets.SUPABASE_ACCESS_TOKEN }}
SUPABASE_PROJECT_ID: ${{ secrets.SUPABASE_PROJECT_ID }}
steps:
- uses: actions/checkout@v3
- uses: supabase/setup-cli@v1
with:
version: latest
- run: supabase functions deploy --project-ref $SUPABASE_PROJECT_ID
```
# Development Environment
Set up your local development environment for Edge Functions.
Before getting started, make sure you have the Supabase CLI installed. Check out the [CLI installation guide](/docs/guides/cli) for installation methods and troubleshooting.
***
## Step 1: Install Deno CLI
The Supabase CLI doesn't use the standard Deno CLI to serve functions locally. Instead, it uses its own Edge Runtime to keep the development and production environment consistent.
You can follow the [Deno guide](https://deno.com/manual@v1.32.5/getting_started/setup_your_environment) for setting up your development environment with your favorite editor/IDE.
The benefit of installing Deno separately is that you can use the Deno LSP to improve your editor's autocompletion, type checking, and testing. You can also use Deno's built-in tools such as `deno fmt`, `deno lint`, and `deno test`.
After installing, you should have Deno installed and available in your terminal. Verify with `deno --version`
***
## Step 2: Set up your editor
Set up your editor environment for proper TypeScript support, autocompletion, and error detection.
### VSCode/Cursor (recommended)
1. **Install the Deno extension** from the VSCode marketplace
2. **Option 1: Auto-generate (easiest)**
When running `supabase init`, select `y` when prompted "Generate VS Code settings for Deno? \[y/N]"
3. **Option 2: Manual setup**
Create a `.vscode/settings.json` in your project root:
```json
{
"deno.enablePaths": ["./supabase/functions"],
"deno.importMap": "./supabase/functions/import_map.json"
}
```
This configuration enables the Deno language server only for the `supabase/functions` folder, while using VSCode's built-in JavaScript/TypeScript language server for all other files.
***
### Multi-root workspaces
The standard `.vscode/settings.json` setup works perfectly for projects where your Edge Functions live alongside your main application code. However, you might need multi-root workspaces if your development setup involves:
* **Multiple repositories:** Edge Functions in one repo, main app in another
* **Microservices:** Several services you need to develop in parallel
For this development workflow, create `edge-functions.code-workspace`:
```
{
"folders": [
{
"name": "project-root",
"path": "./"
},
{
"name": "test-client",
"path": "app"
},
{
"name": "supabase-functions",
"path": "supabase/functions"
}
],
"settings": {
"files.exclude": {
"node_modules/": true,
"app/": true,
"supabase/functions/": true
},
"deno.importMap": "./supabase/functions/import_map.json"
}
}
```
You can find the complete example on [GitHub](https://github.com/supabase/supabase/tree/master/examples/edge-functions).
***
## Recommended project structure
It's recommended to organize your functions according to the following structure:
```bash
└── supabase
├── functions
│ ├── import_map.json # Top-level import map
│ ├── _shared # Shared code (underscore prefix)
│ │ ├── supabaseAdmin.ts # Supabase client with SECRET key
│ │ ├── supabaseClient.ts # Supabase client with PUBLISHABLE key
│ │ └── cors.ts # Reusable CORS headers
│ ├── function-one # Use hyphens for function names
│ │ └── index.ts
│ └── function-two
│ └── index.ts
├── tests
│ ├── function-one-test.ts
│ └── function-two-test.ts
├── migrations
└── config.toml
```
* **Use "fat functions"**. Develop few, large functions by combining related functionality. This minimizes cold starts.
* **Name functions with hyphens (`-`)**. This is the most URL-friendly approach
* **Store shared code in `_shared`**. Store any shared code in a folder prefixed with an underscore (`_`).
* **Separate tests**. Use a separate folder for [Unit Tests](/docs/guides/functions/unit-test) that includes the name of the function followed by a `-test` suffix.
***
## Essential CLI commands
Get familiar with the most commonly used CLI commands for developing and deploying Edge Functions.
### `supabase start`
This command spins up your entire Supabase stack locally: database, auth, storage, and Edge Functions runtime. You're developing against the exact same environment you'll deploy to.
### `supabase functions serve [function-name]`
Develop a specific function with hot reloading. Your functions run at `http://localhost:54321/functions/v1/[function-name]`. When you save your file, you’ll see the changes instantly without having to wait.
Alternatively, use `supabase functions serve` to serve all functions at once.
### `supabase functions deploy hello-world`
Deploy the function when you’re ready
# Development tips
Tips for getting started with Edge Functions.
Here are a few recommendations when you first start developing Edge Functions.
### Using HTTP methods
Edge Functions support `GET`, `POST`, `PUT`, `PATCH`, `DELETE`, and `OPTIONS`. A Function can be designed to perform different actions based on a request's HTTP method. See the [example on building a RESTful service](https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/restful-tasks) to learn how to handle different HTTP methods in your Function.
HTML content is not supported. `GET` requests that return `text/html` will be rewritten to `text/plain`.
### Naming Edge Functions
We recommend using hyphens to name functions because hyphens are the most URL-friendly of all the naming conventions (snake\_case, camelCase, PascalCase).
### Organizing your Edge Functions
We recommend developing "fat functions". This means that you should develop few large functions, rather than many small functions. One common pattern when developing Functions is that you need to share code between two or more Functions. To do this, you can store any shared code in a folder prefixed with an underscore (`_`). We also recommend a separate folder for [Unit Tests](/docs/guides/functions/unit-test) including the name of the function followed by a `-test` suffix.
We recommend this folder structure:
```bash
└── supabase
├── functions
│ ├── import_map.json # A top-level import map to use across functions.
│ ├── _shared
│ │ ├── supabaseAdmin.ts # Supabase client with SECRET key.
│ │ └── supabaseClient.ts # Supabase client with PUBLISHABLE key.
│ │ └── cors.ts # Reusable CORS headers.
│ ├── function-one # Use hyphens to name functions.
│ │ └── index.ts
│ └── function-two
│ │ └── index.ts
│ └── tests
│ └── function-one-test.ts
│ └── function-two-test.ts
├── migrations
└── config.toml
```
### Using config.toml
Individual function configuration like [JWT verification](/docs/guides/cli/config#functions.function_name.verify_jwt) and [import map location](/docs/guides/cli/config#functions.function_name.import_map) can be set via the `config.toml` file.
```toml supabase/config.toml
[functions.hello-world]
verify_jwt = false
import_map = './import_map.json'
```
### Not using TypeScript
When you create a new Edge Function, it will use TypeScript by default. However, it is possible to write and deploy Edge Functions using pure JavaScript.
Save your Function as a JavaScript file (e.g. `index.js`) and then update the `supabase/config.toml` as follows:
`entrypoint` is available only in Supabase CLI version 1.215.0 or higher.
```toml supabase/config.toml
[functions.hello-world]
# other entries
entrypoint = './functions/hello-world/index.js' # path must be relative to config.toml
```
You can use any `.ts`, `.js`, `.tsx`, `.jsx` or `.mjs` file as the `entrypoint` for a Function.
### Error handling
The `supabase-js` library provides several error types that you can use to handle errors that might occur when invoking Edge Functions:
```js
import { FunctionsHttpError, FunctionsRelayError, FunctionsFetchError } from '@supabase/supabase-js'
const { data, error } = await supabase.functions.invoke('hello', {
headers: { 'my-custom-header': 'my-custom-header-value' },
body: { foo: 'bar' },
})
if (error instanceof FunctionsHttpError) {
const errorMessage = await error.context.json()
console.log('Function returned an error', errorMessage)
} else if (error instanceof FunctionsRelayError) {
console.log('Relay error:', error.message)
} else if (error instanceof FunctionsFetchError) {
console.log('Fetch error:', error.message)
}
```
### Database Functions vs Edge Functions
For data-intensive operations we recommend using [Database Functions](/docs/guides/database/functions), which are executed within your database and can be called remotely using the [REST and GraphQL API](/docs/guides/api).
For use-cases which require low-latency we recommend [Edge Functions](/docs/guides/functions), which are globally-distributed and can be written in TypeScript.
# File Storage
Use persistent and ephemeral file storage
Edge Functions provides two flavors of file storage:
* Persistent - backed by S3 protocol, can read/write from any S3 compatible bucket, including Supabase Storage
* Ephemeral - You can read and write files to the `/tmp` directory. Only suitable for temporary operations
You can use file storage to:
* Handle complex file transformations and workflows
* Do data migrations between projects
* Process user uploaded files and store them
* Unzip archives and process contents before saving to database
***
## Persistent Storage
The persistent storage option is built on top of the S3 protocol. It allows you to mount any S3-compatible bucket, including Supabase Storage Buckets, as a directory for your Edge Functions.
You can perform operations such as reading and writing files to the mounted buckets as you would in a POSIX file system.
To access an S3 bucket from Edge Functions, you must set the following for environment variables in Edge Function Secrets.
* `S3FS_ENDPOINT_URL`
* `S3FS_REGION`
* `S3FS_ACCESS_KEY_ID`
* `S3FS_SECRET_ACCESS_KEY`
[Follow this guide](/docs/guides/storage/s3/authentication) to enable and create an access key for Supabase Storage S3.
To access a file path in your mounted bucket from your Edge Function, use the prefix `/s3/YOUR-BUCKET-NAME`.
```tsx
// read from S3 bucket
const data = await Deno.readFile('/s3/my-bucket/results.csv')
// make a directory
await Deno.mkdir('/s3/my-bucket/sub-dir')
// write to S3 bucket
await Deno.writeTextFile('/s3/my-bucket/demo.txt', 'hello world')
```
## Ephemeral storage
Ephemeral storage will reset on each function invocation. This means the files you write during an invocation can only be read within the same invocation.
You can use [Deno File System APIs](https://docs.deno.com/api/deno/file-system) or the [`node:fs`](https://docs.deno.com/api/node/fs/) module to access the `/tmp` path.
```tsx
Deno.serve(async (req) => {
if (req.headers.get('content-type') !== 'application/zip') {
return new Response('file must be a zip file', {
status: 400,
})
}
const uploadId = crypto.randomUUID()
await Deno.writeFile('/tmp/' + uploadId, req.body)
// E.g. extract and process the zip file
const zipFile = await Deno.readFile('/tmp/' + uploadId)
// You could use a zip library to extract contents
const extracted = await extractZip(zipFile)
// Or process the file directly
console.log(`Processing zip file: ${uploadId}, size: ${zipFile.length} bytes`)
})
```
***
## Common use cases
### Archive processing with background tasks
You can use ephemeral storage with [Background Tasks](/docs/guides/functions/background-tasks) to handle large file processing operations that exceed memory limits.
Imagine you have a Photo Album application that accepts photo uploads as zip files. A streaming implementation will run into memory limit errors with zip files exceeding 100MB, as it retains all archive files in memory simultaneously.
You can write the zip file to ephemeral storage first, then use a background task to extract and upload files to Supabase Storage. This way, you only read parts of the zip file to the memory.
```tsx
import { BlobWriter, ZipReader } from 'https://deno.land/x/zipjs/index.js'
import { createClient } from 'jsr:@supabase/supabase-js@2'
const SUPABASE_SECRET_KEYS = JSON.parse(Deno.env.get('SUPABASE_SECRET_KEYS')!)
// If you want to use a different api key, change 'default' to your preferred key name
const supabase = createClient(Deno.env.get('SUPABASE_URL')!, SUPABASE_SECRET_KEYS['default'])
async function processZipFile(uploadId: string, filepath: string) {
const file = await Deno.open(filepath, { read: true })
const zipReader = new ZipReader(file.readable)
const entries = await zipReader.getEntries()
await supabase.storage.createBucket(uploadId, { public: false })
await Promise.all(
entries.map(async (entry) => {
if (entry.directory) return
// Read file entry from temp storage
const blobWriter = new BlobWriter()
const blob = await entry.getData(blobWriter)
// Upload to permanent storage
await supabase.storage.from(uploadId).upload(entry.filename, blob)
console.log('uploaded', entry.filename)
})
)
await zipReader.close()
}
Deno.serve(async (req) => {
const uploadId = crypto.randomUUID()
const filepath = `/tmp/${uploadId}.zip`
// Write zip to ephemeral storage
await Deno.writeFile(filepath, req.body)
// Process in background to avoid memory limits
EdgeRuntime.waitUntil(processZipFile(uploadId, filepath))
return new Response(JSON.stringify({ uploadId }), {
headers: { 'Content-Type': 'application/json' },
})
})
```
### Image manipulation
Custom image manipulation workflows using [`magick-wasm`](/docs/guides/functions/examples/image-manipulation).
```tsx
Deno.serve(async (req) => {
// Save uploaded image to temp storage
const imagePath = `/tmp/input-${crypto.randomUUID()}.jpg`
await Deno.writeFile(imagePath, req.body)
// Process image with magick-wasm
const processedPath = `/tmp/output-${crypto.randomUUID()}.jpg`
// ... image manipulation logic
// Read processed image and return
const processedImage = await Deno.readFile(processedPath)
return new Response(processedImage, {
headers: { 'Content-Type': 'image/jpeg' },
})
})
```
***
## Using synchronous file APIs
You can safely use the following synchronous Deno APIs (and their Node counterparts) *during initial script evaluation*:
* Deno.statSync
* Deno.removeSync
* Deno.writeFileSync
* Deno.writeTextFileSync
* Deno.readFileSync
* Deno.readTextFileSync
* Deno.mkdirSync
* Deno.makeTempDirSync
* Deno.readDirSync
**Keep in mind** that the sync APIs are available only during initial script evaluation and aren’t supported in callbacks like HTTP handlers or `setTimeout`.
```tsx
Deno.statSync('...') // ✅
setTimeout(() => {
Deno.statSync('...') // 💣 ERROR! Deno.statSync is blocklisted on the current context
})
Deno.serve(() => {
Deno.statSync('...') // 💣 ERROR! Deno.statSync is blocklisted on the current context
})
```
***
## Limits
There are no limits on S3 buckets you mount for Persistent storage.
Ephemeral Storage:
* Free projects: Up to 256MB of ephemeral storage
* Paid projects: Up to 512MB of ephemeral storage
# Error Handling
Implement proper error responses and client-side handling to create reliable applications.
## Error handling
Implementing the right error responses and client-side handling helps with debugging and makes your functions much easier to maintain in production.
Within your Edge Functions, return proper HTTP status codes and error messages:
```tsx
Deno.serve(async (req) => {
try {
// Your function logic here
const result = await processRequest(req)
return new Response(JSON.stringify(result), {
headers: { 'Content-Type': 'application/json' },
status: 200,
})
} catch (error) {
console.error('Function error:', error)
return new Response(JSON.stringify({ error: error.message }), {
headers: { 'Content-Type': 'application/json' },
status: 500,
})
}
})
```
**Best practices for function errors:**
* Use the right HTTP status code for each situation. Return `400` for bad user input, 404 when something doesn't exist, 500 for server errors, etc. This helps with debugging and lets client apps handle different error types appropriately.
* Include helpful error messages in the response body
* Log errors to the console for debugging (visible in the Logs tab)
***
## Client-side error handling
Within your client-side code, an Edge Function can throw three types of errors:
* **`FunctionsHttpError`**: Your function executed but returned an error (4xx/5xx status)
* **`FunctionsRelayError`**: Network issue between client and Supabase
* **`FunctionsFetchError`**: Function couldn't be reached at all
```jsx
import { FunctionsHttpError, FunctionsRelayError, FunctionsFetchError } from '@supabase/supabase-js'
const { data, error } = await supabase.functions.invoke('hello', {
headers: { 'my-custom-header': 'my-custom-header-value' },
body: { foo: 'bar' },
})
if (error instanceof FunctionsHttpError) {
const errorMessage = await error.context.json()
console.log('Function returned an error', errorMessage)
} else if (error instanceof FunctionsRelayError) {
console.log('Relay error:', error.message)
} else if (error instanceof FunctionsFetchError) {
console.log('Fetch error:', error.message)
}
```
Make sure to handle the errors properly. Functions that fail silently are hard to debug, functions with clear error messages get fixed fast.
***
## Error monitoring
You can see the production error logs in the Logs tab of your Supabase Dashboard.
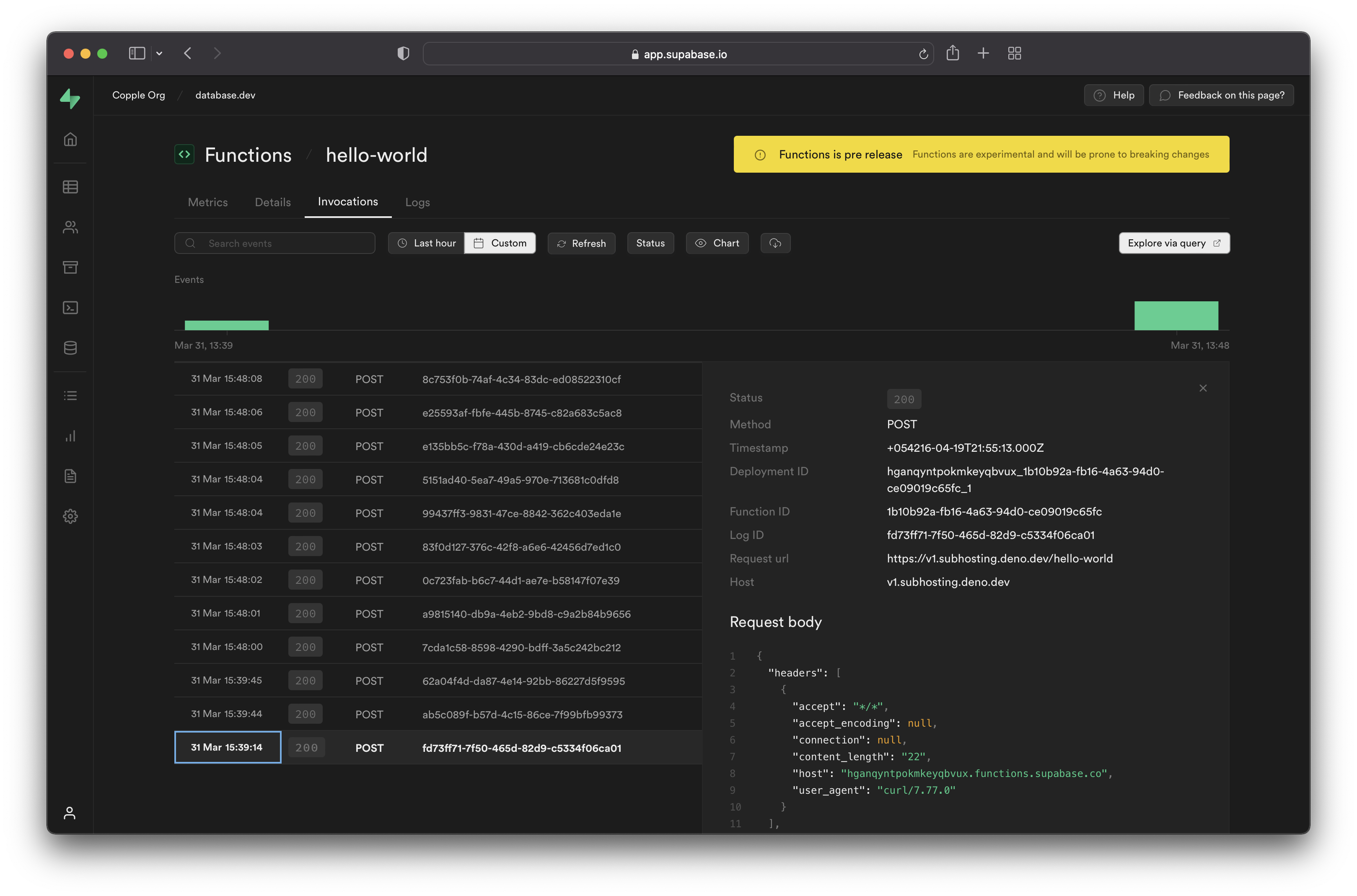
For more information on Logging, check out [this guide](/docs/guides/functions/logging).
# Function Configuration
Configure individual function behavior. Customize authentication, dependencies, and other settings per function.
## Configuration
By default, all your Edge Functions have the same settings. In real applications, however, you might need different behaviors between functions.
For example:
* **Stripe webhooks** need to be publicly accessible (Stripe doesn't have your user tokens)
* **User profile APIs** should require authentication
* **Some functions** might need special dependencies or different file types
To enable these per-function rules, create `supabase/config.toml` in your project root:
```toml
# Disables authentication for the Stripe webhook.
[functions.stripe-webhook]
verify_jwt = false
# Custom dependencies for this specific function
[functions.image-processor]
import_map = './functions/image-processor/import_map.json'
# Custom entrypoint for legacy function using JavaScript
[functions.legacy-processor]
entrypoint = './functions/legacy-processor/index.js
```
This configuration tell Supabase that the `stripe-webhook` function doesn't require a valid JWT, the `image-processor` function uses a custom import map, and `legacy-processor` uses a custom entrypoint.
You set these rules once and never worry about them again. Deploy your functions knowing that the security and behavior is exactly what each endpoint needs.
To see more general `config.toml` options, check out [this guide](/docs/guides/local-development/managing-config).
***
## Skipping authorization checks
By default, Edge Functions require a valid JWT in the authorization header. If you want to use Edge Functions without Authorization checks (commonly used for Stripe webhooks), you can configure this in your `config.toml`:
```toml
[functions.stripe-webhook]
verify_jwt = false
```
You can also pass the `--no-verify-jwt` flag when serving your Edge Functions locally:
```bash
supabase functions serve hello-world --no-verify-jwt
```
Be careful when using this flag, as it will allow anyone to invoke your Edge Function without a valid JWT. The Supabase client libraries automatically handle authorization.
***
## Custom entrypoints
`entrypoint` is available only in Supabase CLI version 1.215.0 or higher.
When you create a new Edge Function, it will use TypeScript by default. However, it is possible to write and deploy Edge Functions using pure JavaScript.
Save your Function as a JavaScript file (e.g. `index.js`) update the `supabase/config.toml` :
```toml
[functions.hello-world]
entrypoint = './index.js' # path must be relative to config.toml
```
You can use any `.ts`, `.js`, `.tsx`, `.jsx` or `.mjs` file as the entrypoint for a Function.
# Routing
Handle different request types in a single function to create efficient APIs.
## Overview
Edge Functions support **`GET`, `POST`, `PUT`, `PATCH`, `DELETE`, and `OPTIONS`**. This means you can build complete REST APIs in a single function:
```tsx
Deno.serve(async (req) => {
const { method, url } = req
const { pathname } = new URL(url)
// Route based on method and path
if (method === 'GET' && pathname === '/users') {
return getAllUsers()
} else if (method === 'POST' && pathname === '/users') {
return createUser(req)
}
return new Response('Not found', { status: 404 })
})
```
Edge Functions allow you to build APIs without needing separate functions for each endpoint. This reduces cold starts and simplifies deployment while keeping your code organized.
HTML content is not supported. `GET` requests that return `text/html` will be rewritten to `text/plain`. Edge Functions are designed for APIs and data processing, not serving web pages. Use Supabase for your backend API and your favorite frontend framework for HTML.
***
## Example
Here's a full example of a RESTful API built with Edge Functions.
```typescript index.ts
// Follow this setup guide to integrate the Deno language server with your editor:
// https://deno.land/manual/getting_started/setup_your_environment
// This enables autocomplete, go to definition, etc.
import { createClient, SupabaseClient } from 'npm:supabase-js@2'
// New approach (v2.95.0+)
import { corsHeaders } from 'jsr:@supabase/supabase-js@2/cors'
// For older versions, use hardcoded headers:
// const corsHeaders = {
// 'Access-Control-Allow-Origin': '*',
// 'Access-Control-Allow-Headers': 'authorization, x-client-info, apikey, content-type',
// 'Access-Control-Allow-Methods': 'POST, GET, OPTIONS, PUT, DELETE',
// }
interface Task {
name: string
status: number
}
async function getTask(supabaseClient: SupabaseClient, id: string) {
const { data: task, error } = await supabaseClient.from('tasks').select('*').eq('id', id)
if (error) throw error
return new Response(JSON.stringify({ task }), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 200,
})
}
async function getAllTasks(supabaseClient: SupabaseClient) {
const { data: tasks, error } = await supabaseClient.from('tasks').select('*')
if (error) throw error
return new Response(JSON.stringify({ tasks }), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 200,
})
}
async function deleteTask(supabaseClient: SupabaseClient, id: string) {
const { error } = await supabaseClient.from('tasks').delete().eq('id', id)
if (error) throw error
return new Response(JSON.stringify({}), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 200,
})
}
async function updateTask(supabaseClient: SupabaseClient, id: string, task: Task) {
const { error } = await supabaseClient.from('tasks').update(task).eq('id', id)
if (error) throw error
return new Response(JSON.stringify({ task }), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 200,
})
}
async function createTask(supabaseClient: SupabaseClient, task: Task) {
const { error } = await supabaseClient.from('tasks').insert(task)
if (error) throw error
return new Response(JSON.stringify({ task }), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 200,
})
}
Deno.serve(async (req) => {
const { url, method } = req
// This is needed if you're planning to invoke your function from a browser.
if (method === 'OPTIONS') {
return new Response('ok', { headers: corsHeaders })
}
try {
const SUPABASE_PUBLISHABLE_KEYS = JSON.parse(Deno.env.get('SUPABASE_PUBLISHABLE_KEYS')!)
// Create a Supabase client with the Auth context of the logged in user.
const supabaseClient = createClient(
// Supabase API URL - env var exported by default.
Deno.env.get('SUPABASE_URL') ?? '',
// Supabase publishable key - env var exported by default.
Deno.env.get(SUPABASE_PUBLISHABLE_KEYS['default']) ?? '',
// Create client with Auth context of the user that called the function.
// This way your row-level-security (RLS) policies are applied.
{
global: {
headers: { Authorization: req.headers.get('Authorization')! },
},
}
)
// For more details on URLPattern, check https://developer.mozilla.org/en-US/docs/Web/API/URL_Pattern_API
const taskPattern = new URLPattern({ pathname: '/restful-tasks/:id' })
const matchingPath = taskPattern.exec(url)
const id = matchingPath ? matchingPath.pathname.groups.id : null
let task = null
if (method === 'POST' || method === 'PUT') {
const body = await req.json()
task = body.task
}
// call relevant method based on method and id
switch (true) {
case id && method === 'GET':
return getTask(supabaseClient, id as string)
case id && method === 'PUT':
return updateTask(supabaseClient, id as string, task)
case id && method === 'DELETE':
return deleteTask(supabaseClient, id as string)
case method === 'POST':
return createTask(supabaseClient, task)
case method === 'GET':
return getAllTasks(supabaseClient)
default:
return getAllTasks(supabaseClient)
}
} catch (error) {
console.error(error)
return new Response(JSON.stringify({ error: error.message }), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
status: 400,
})
}
})
```
# Type-Safe SQL with Kysely
Supabase Edge Functions can [connect directly to your Postgres database](/docs/guides/functions/connect-to-postgres) to execute SQL queries. [Kysely](https://github.com/kysely-org/kysely#kysely) is a type-safe and autocompletion-friendly typescript SQL query builder.
Combining Kysely with Deno Postgres gives you a convenient developer experience for interacting directly with your Postgres database.
## Code
Find the example on [GitHub](https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/kysely-postgres)
Get your database connection credentials from the project's [**Connect** panel](/dashboard/project/_/?showConnect=true) and store them in an `.env` file:
```bash .env
DB_HOSTNAME=
DB_PASSWORD=
DB_SSL_CERT="-----BEGIN CERTIFICATE-----
GET YOUR CERT FROM YOUR PROJECT DASHBOARD
-----END CERTIFICATE-----"
```
Create a `DenoPostgresDriver.ts` file to manage the connection to Postgres via [deno-postgres](https://deno-postgres.com/):
```ts DenoPostgresDriver.ts
import { Pool, PoolClient } from 'https://deno.land/x/postgres@v0.17.0/mod.ts'
import {
CompiledQuery,
DatabaseConnection,
Driver,
PostgresCursorConstructor,
QueryResult,
TransactionSettings,
} from 'https://esm.sh/kysely@0.23.4'
import { freeze, isFunction } from 'https://esm.sh/kysely@0.23.4/dist/esm/util/object-utils.js'
import { extendStackTrace } from 'https://esm.sh/kysely@0.23.4/dist/esm/util/stack-trace-utils.js'
export interface PostgresDialectConfig {
pool: Pool | (() => Promise)
cursor?: PostgresCursorConstructor
onCreateConnection?: (connection: DatabaseConnection) => Promise
}
const PRIVATE_RELEASE_METHOD = Symbol()
export class PostgresDriver implements Driver {
readonly #config: PostgresDialectConfig
readonly #connections = new WeakMap()
#pool?: Pool
constructor(config: PostgresDialectConfig) {
this.#config = freeze({ ...config })
}
async init(): Promise {
this.#pool = isFunction(this.#config.pool) ? await this.#config.pool() : this.#config.pool
}
async acquireConnection(): Promise {
const client = await this.#pool!.connect()
let connection = this.#connections.get(client)
if (!connection) {
connection = new PostgresConnection(client, {
cursor: this.#config.cursor ?? null,
})
this.#connections.set(client, connection)
// The driver must take care of calling `onCreateConnection` when a new
// connection is created. The `pg` module doesn't provide an async hook
// for the connection creation. We need to call the method explicitly.
if (this.#config?.onCreateConnection) {
await this.#config.onCreateConnection(connection)
}
}
return connection
}
async beginTransaction(
connection: DatabaseConnection,
settings: TransactionSettings
): Promise {
if (settings.isolationLevel) {
await connection.executeQuery(
CompiledQuery.raw(`start transaction isolation level ${settings.isolationLevel}`)
)
} else {
await connection.executeQuery(CompiledQuery.raw('begin'))
}
}
async commitTransaction(connection: DatabaseConnection): Promise {
await connection.executeQuery(CompiledQuery.raw('commit'))
}
async rollbackTransaction(connection: DatabaseConnection): Promise {
await connection.executeQuery(CompiledQuery.raw('rollback'))
}
async releaseConnection(connection: PostgresConnection): Promise {
connection[PRIVATE_RELEASE_METHOD]()
}
async destroy(): Promise {
if (this.#pool) {
const pool = this.#pool
this.#pool = undefined
await pool.end()
}
}
}
interface PostgresConnectionOptions {
cursor: PostgresCursorConstructor | null
}
class PostgresConnection implements DatabaseConnection {
#client: PoolClient
#options: PostgresConnectionOptions
constructor(client: PoolClient, options: PostgresConnectionOptions) {
this.#client = client
this.#options = options
}
async executeQuery(compiledQuery: CompiledQuery): Promise> {
try {
const result = await this.#client.queryObject(compiledQuery.sql, [
...compiledQuery.parameters,
])
if (
result.command === 'INSERT' ||
result.command === 'UPDATE' ||
result.command === 'DELETE'
) {
const numAffectedRows = BigInt(result.rowCount || 0)
return {
numUpdatedOrDeletedRows: numAffectedRows,
numAffectedRows,
rows: result.rows ?? [],
} as any
}
return {
rows: result.rows ?? [],
}
} catch (err) {
throw extendStackTrace(err, new Error())
}
}
async *streamQuery(
_compiledQuery: CompiledQuery,
chunkSize: number
): AsyncIterableIterator> {
if (!this.#options.cursor) {
throw new Error(
"'cursor' is not present in your postgres dialect config. It's required to make streaming work in postgres."
)
}
if (!Number.isInteger(chunkSize) || chunkSize <= 0) {
throw new Error('chunkSize must be a positive integer')
}
// stream not available
return null
}
[PRIVATE_RELEASE_METHOD](): void {
this.#client.release()
}
}
```
Create an `index.ts` file to execute a query on incoming requests:
```ts index.ts
import { Pool } from 'https://deno.land/x/postgres@v0.17.0/mod.ts'
import {
Generated,
Kysely,
PostgresAdapter,
PostgresIntrospector,
PostgresQueryCompiler,
} from 'https://esm.sh/kysely@0.23.4'
import { PostgresDriver } from './DenoPostgresDriver.ts'
console.log(`Function "kysely-postgres" up and running!`)
interface AnimalTable {
id: Generated
animal: string
created_at: Date
}
// Keys of this interface are table names.
interface Database {
animals: AnimalTable
}
// Create a database pool with one connection.
const pool = new Pool(
{
tls: { caCertificates: [Deno.env.get('DB_SSL_CERT')!] },
database: 'postgres',
hostname: Deno.env.get('DB_HOSTNAME'),
user: 'postgres',
port: 5432,
password: Deno.env.get('DB_PASSWORD'),
},
1
)
// You'd create one of these when you start your app.
const db = new Kysely({
dialect: {
createAdapter() {
return new PostgresAdapter()
},
createDriver() {
return new PostgresDriver({ pool })
},
createIntrospector(db: Kysely) {
return new PostgresIntrospector(db)
},
createQueryCompiler() {
return new PostgresQueryCompiler()
},
},
})
Deno.serve(async (_req) => {
try {
// Run a query
const animals = await db.selectFrom('animals').select(['id', 'animal', 'created_at']).execute()
// Neat, it's properly typed \o/
console.log(animals[0].created_at.getFullYear())
// Encode the result as pretty printed JSON
const body = JSON.stringify(
animals,
(key, value) => (typeof value === 'bigint' ? value.toString() : value),
2
)
// Return the response with the correct content type header
return new Response(body, {
status: 200,
headers: {
'Content-Type': 'application/json; charset=utf-8',
},
})
} catch (err) {
console.error(err)
return new Response(String(err?.message ?? err), { status: 500 })
}
})
```
# Limits
Limits applied Edge Functions in Supabase's hosted platform.
## Runtime limits
* Maximum Memory: 256MB
* Maximum Duration (Wall clock limit):
This is the duration an Edge Function worker will stay active. During this period, a worker can serve multiple requests or process background tasks.
* Free plan: 150s
* Paid plans: 400s
* Maximum CPU Time: 2s (Amount of actual time spent on the CPU per request - does not include async I/O.)
* Request idle timeout: 150s (If an Edge Function doesn't send a response before the timeout, 504 Gateway Timeout will be returned)
## Platform limits
* Maximum Function Size: 20MB (After bundling using CLI)
* Maximum no. of Functions per project:
* Free: 100
* Pro: 500
* Team: 1000
* Enterprise: Unlimited
* Maximum log message length: 10,000 characters
* Log event threshold: 100 events per 10 seconds
* Recursive/Nested Function Calling: ~5000 requests per minute [more details](/docs/guides/functions/recursive-functions)
### Secrets
* Maximum number of secrets per project: **100**
* Secret name length: up to **256** characters
* Maximum secret size: **48 KiB** (**24,576** characters)
* Names must NOT start with the prefix `SUPABASE_` (this prefix is reserved).
## Other limits & restrictions
* Outgoing connections to ports `25` and `587` are not allowed.
* Serving of HTML content is only supported with [custom domains](/docs/reference/cli/supabase-domains) (Otherwise `GET` requests that return `text/html` will be rewritten to `text/plain`).
* Web Worker API (or Node `vm` API) are not available.
* Static files cannot be deployed using the API flag. You need to build them with [Docker on the CLI](/docs/guides/functions/quickstart#step-6-deploy-to-production).
* Node Libraries that require multithreading are not supported. Examples: [`libvips`](https://github.com/libvips/libvips), [sharp](https://github.com/lovell/sharp).
# Logging
Monitor your Edge Functions with logging to track execution, debug issues, and optimize performance.
Logs are provided for each function invocation, locally and in hosted environments.
***
## Accessing logs
### Production
Access logs from the Functions section of your Dashboard:
1. Navigate to the [Functions section](/dashboard/project/_/functions) of the Dashboard
2. Select your function from the list
3. Choose your log view:
* **Invocations:** Request/Response data including headers, body, status codes, and execution duration. Filter by date, time, or status code.
* **Logs:** Platform events, uncaught exceptions, and custom log messages. Filter by timestamp, level, or message content.

### Development
When [developing locally](/docs/guides/functions/quickstart) you will see error messages and console log statements printed to your local terminal window.
***
## Log event types
### Automatic logs
Your functions automatically capture several types of events:
* **Uncaught exceptions**: Uncaught exceptions thrown by a function during execution are automatically logged. You can see the error message and stack trace in the Logs tool.
* **Custom log events**: You can use `console.log`, `console.error`, and `console.warn` in your code to emit custom log events. These events also appear in the Logs tool.
* **Boot and Shutdown Logs**: The Logs tool extends its coverage to include logs for the boot and shutdown of functions.
### Custom logs
You can add your own log messages using standard console methods:
```js
Deno.serve(async (req) => {
try {
const { name } = await req.json()
if (!name) {
// Log a warning message
console.warn('Empty name parameter received')
}
// Log a message
console.log(`Processing request for: ${name}`)
const data = {
message: `Hello ${name || 'Guest'}!`,
}
return new Response(JSON.stringify(data), {
headers: { 'Content-Type': 'application/json' },
})
} catch (error) {
// Log an error message
console.error(`Request processing failed: ${error.message}`)
return new Response(JSON.stringify({ error: 'Internal Server Error' }), {
status: 500,
headers: { 'Content-Type': 'application/json' },
})
}
})
```
A custom log message can contain up to 10,000 characters. A function can log up to 100 events within a 10 second period.
***
## Logging tips
### Logging request headers
When debugging Edge Functions, a common mistake is to try to log headers to the developer console via code like this:
```ts index.ts
// ❌ This doesn't work as expected
Deno.serve(async (req) => {
console.log(`Headers: ${JSON.stringify(req.headers)}`) // Outputs: "{}"
})
```
The `req.headers` object appears empty because Headers objects don't store data in enumerable JavaScript properties, making them opaque to `JSON.stringify()`.
Instead, you have to convert headers to a plain object first, for example using `Object.fromEntries`.
```ts index.ts
// ✅ This works correctly
Deno.serve(async (req) => {
const headersObject = Object.fromEntries(req.headers)
const headersJson = JSON.stringify(headersObject, null, 2)
console.log(`Request headers:\n${headersJson}`)
})
```
This results in something like:
```json
Request headers: {
"accept": "*/*",
"accept-encoding": "gzip",
"authorization": "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJzdXBhYmFzZSIsInJlZiI6InN1cGFuYWNobyIsInJvbGUiOiJhbm9uIiwieW91IjoidmVyeSBzbmVha3ksIGh1aD8iLCJpYXQiOjE2NTQ1NDA5MTYsImV4cCI6MTk3MDExNjkxNn0.cwBbk2tq-fUcKF1S0jVKkOAG2FIQSID7Jjvff5Do99Y",
"cdn-loop": "cloudflare; subreqs=1",
"cf-ew-via": "15",
"cf-ray": "8597a2fcc558a5d7-GRU",
"cf-visitor": "{\"scheme\":\"https\"}",
"cf-worker": "supabase.co",
"content-length": "20",
"content-type": "application/x-www-form-urlencoded",
"host": "edge-runtime.supabase.com",
"my-custom-header": "abcd",
"user-agent": "curl/8.4.0",
"x-deno-subhost": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiIsImtpZCI6InN1cGFiYXNlIn0.eyJkZXBsb3ltZW50X2lkIjoic3VwYW5hY2hvX2M1ZGQxMWFiLTFjYmUtNDA3NS1iNDAxLTY3ZTRlZGYxMjVjNV8wMDciLCJycGNfcm9vdCI6Imh0dHBzOi8vc3VwYWJhc2Utb3JpZ2luLmRlbm8uZGV2L3YwLyIsImV4cCI6MTcwODYxMDA4MiwiaWF0IjoxNzA4NjA5MTgyfQ.-fPid2kEeEM42QHxWeMxxv2lJHZRSkPL-EhSH0r_iV4",
"x-forwarded-host": "edge-runtime.supabase.com",
"x-forwarded-port": "443",
"x-forwarded-proto": "https"
}
```
# Pricing
per 1 million invocations. You are only charged for usage exceeding your
subscription plan's quota.
| Plan | Quota | Over-Usage |
| ---------- | --------- | --------------------------------------------- |
| Free | 500,000 | - |
| Pro | 2 million | per 1 million invocations |
| Team | 2 million | per 1 million invocations |
| Enterprise | Custom | Custom |
For a detailed explanation of how charges are calculated, refer to [Manage Edge Function Invocations usage](/docs/guides/platform/manage-your-usage/edge-function-invocations).
# Getting Started with Edge Functions (Dashboard)
Learn how to create, test, and deploy your first Edge Function using the Supabase Dashboard.
Supabase allows you to create Supabase Edge Functions directly from the Supabase Dashboard, making it easy to deploy functions without needing to set up a local development environment. The Edge Functions editor in the Dashboard has built-in syntax highlighting and type-checking for Deno and Supabase-specific APIs.
This guide will walk you through creating, testing, and deploying your first Edge Function using the Supabase Dashboard. You'll have a working function running globally in under 10 minutes.
You can also create and deploy functions using the Supabase CLI. Check out our [CLI Quickstart guide](/docs/guides/functions/quickstart).
You'll need a Supabase project to get started. If you don't have one yet, create a new project at [database.new](https://database.new/).
***
## Step 1: Navigate to the Edge Functions tab
Navigate to your Supabase project dashboard and locate the Edge Functions section:
1. Go to your [Supabase Dashboard](/dashboard)
2. Select your project
3. In the left sidebar, click on **Edge Functions**
You'll see the Edge Functions overview page where you can manage all your functions.
***
## Step 2: Create your first function
Click the **"Deploy a new function"** button and select **"Via Editor"** to create a function directly in the dashboard.
The dashboard offers several pre-built templates for common use cases, such as Stripe Webhooks, OpenAI proxying, uploading files to Supabase Storage, and sending emails.
For this guide, we’ll select the **"Hello World"** template. If you’d rather start from scratch, you can ignore the pre-built templates.
***
## Step 3: Customize your function code
The dashboard will load your chosen template in the code editor. Here's what the "Hello World" template looks like:
If needed, you can modify this code directly in the browser editor. The function accepts a JSON payload with a `name` field and returns a greeting message.
***
## Step 4: Deploy your function
Once you're happy with your function code:
1. Click the **"Deploy function"** button at the bottom of the editor
2. Wait for the deployment to complete (usually takes 10-30 seconds)
3. You'll see a success message when deployment is finished
🚀 Your function is now automatically distributed to edge locations worldwide, running at `https://YOUR_PROJECT_ID.supabase.co/functions/v1/hello-world`
***
## Step 5: Test your function
Supabase has built-in tools for testing your Edge Functions from the Dashboard. You can execute your Edge Function with different request payloads, headers, and query parameters. The built-in tester returns the response status, headers, and body.
On your function's details page:
1. Click the **"Test"** button
2. Configure your test request:
* **HTTP Method**: POST (or whatever your function expects)
* **Headers**: Add any required headers like `Content-Type: application/json`
* **Query Parameters**: Add URL parameters if needed
* **Request Body**: Add your JSON payload
* **Authorization**: Change the authorization token (anon key or user key)
Click **"Send Request"** to test your function.
In this example, we successfully tested our Hello World function by sending a JSON payload with a name field, and received the expected greeting message back.
***
## Step 6: Get your function URL and keys
Your function is now live at:
```
https://YOUR_PROJECT_ID.supabase.co/functions/v1/hello-world
```
To invoke this Edge Function from within your application, you'll need API keys. Navigate to **Settings > API Keys** in your dashboard to find:
* **Publishable Keys** - For client-side requests (safe to use in browsers with RLS enabled)
* **Secret Keys** - For server-side requests (keep this secret! bypasses RLS)
***
If you’d like to update the deployed function code, click on the function you want to edit, modify the code as needed, then click Deploy updates. This will overwrite the existing deployment with the newly edited function code.
There is currently **no version control** for edits! The Dashboard's Edge Function editor currently does not support version control, versioning, or rollbacks. We recommend using it only for quick testing and prototypes.
***
## Usage
Now that your function is deployed, you can invoke it from within your app:
```jsx
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://[YOUR_PROJECT_ID].supabase.co', 'YOUR_PUBLISHABLE_KEY')
const { data, error } = await supabase.functions.invoke('hello-world', {
body: { name: 'JavaScript' },
})
console.log(data) // { message: "Hello JavaScript!" }
```
```jsx
const response = await fetch('https://[YOUR_PROJECT_ID].supabase.co/functions/v1/hello-world', {
method: 'POST',
headers: {
Authorization: 'Bearer YOUR_PUBLISHABLE_KEY',
'Content-Type': 'application/json',
},
body: JSON.stringify({ name: 'Fetch' }),
})
const data = await response.json()
console.log(data) // { message: "Hello Fetch!" }
```
***
## Deploy via Assistant
You can also use Supabase's AI Assistant to generate and deploy functions automatically.
Go to your project > **Deploy a new function** > **Via AI Assistant**.
Describe what you want your function to do in the prompt
Click **Deploy** and the Assistant will create and deploy the function for you.
***
## Download Edge Functions
Now that your function is deployed, you can access it from your local development environment. To use your Edge Function code within your local development environment, you can download your function source code either through the dashboard, or the CLI.
### Dashboard
1. Go to your function's page
2. In the top right corner, click the **"Download"** button
### CLI
Before getting started, make sure you have the **Supabase CLI installed**. Check out the [CLI installation guide](/docs/guides/cli) for installation methods and troubleshooting.
```bash
# Link your project to your local environment
supabase link --project-ref [project-ref]
# List all functions in the linked project
supabase functions list
# Download a function
supabase functions download hello-world
```
At this point, your function has been downloaded to your local environment. Make the required changes, and redeploy when you're ready.
```bash
# Run a function locally
supabase functions serve hello-world
# Redeploy when you're ready with your changes
supabase functions deploy hello-world
```
# Getting Started with Edge Functions
Learn how to create, test, and deploy your first Edge Function using the Supabase CLI.
This guide walks you through creating, testing locally, deploying, and invoking a Supabase Edge Function using the CLI. By the end, you'll have a working function running on Supabase's global edge network.
You can also create and deploy functions directly from the Supabase Dashboard. Read [the Dashboard Quickstart guide](/docs/guides/functions/quickstart-dashboard) for more information.
Supabase Edge Functions **only** supports creating functions in TypeScript with [the Deno runtime](https://deno.com/). This is because Deno was designed with extensibility in mind and its Rust codebase offers a modern developer experience, memory safety, and other features ideal for running edge functions.
## Prerequisites
* Make sure you have the Supabase CLI installed and configured. Read [the CLI installation guide](/docs/guides/cli) for installation methods and troubleshooting.
* Running and testing Supabase Edge Functions locally requires [Docker](https://www.docker.com/) or a Docker-compatible runtime.
## Step 1: Create or configure your project
If you don't have a project yet, initialize a new Supabase project in your current directory.
```bash
mkdir my-edge-functions-project
cd my-edge-functions-project
supabase init
```
If you already have a project locally, navigate to your project directory. If you haven't configured the project for Supabase yet, make sure to run the `supabase init` command.
```bash
cd your-existing-project
supabase init # Initialize Supabase, if you haven't already
```
After this step, you should have a project directory with a `supabase` folder containing a `config.toml` file.
## Step 2: Create your first function
Within your project, generate a new Edge Function with a basic template:
```bash
supabase functions new hello-world
```
{/* TODO: Link to parameter documentation */}
When an HTTP request is sent to Edge Functions, you can use Supabase Auth to secure endpoints. By default, the `supabase functions new` command adds handling a valid publishable or secret key to the basic template. However, you can change this behavior with the `--auth` flag when creating a new function.
This creates a new function at `supabase/functions/hello-world/index.ts` with this starter code:
```tsx
export default {
fetch: withSupabase({ auth: ['publishable', 'secret'] }, async (req, ctx) => {
const { name } = await req.json()
return Response.json({
message: `Hello ${name}!`,
})
}),
}
```
This function accepts a JSON payload with a `name` field and returns a greeting message.
The `supabase functions new` command also optionally creates Deno configuration for VSCode.
## Step 3: Test your function locally
After starting Docker, start the local development server to test your function:
```bash
supabase start # Start all Supabase services
supabase functions serve hello-world
```
On first use, the `supabase start` command downloads Docker images, and starts all Supabase services locally, which can take a few minutes.
Your function is now running at [`http://localhost:54321/functions/v1/hello-world`](http://localhost:54321/functions/v1/hello-world). Hot reloading is enabled, which means that the server automatically reloads when you save changes to your function code. Keep this terminal window open.
### Function not starting locally?
* Make sure Docker is running
* Run `supabase stop` then `supabase start` to restart services
### Port already in use?
* Check what's running with `supabase status`
* Stop other Supabase instances with `supabase stop`
## Step 4: Send a test request
Open a new terminal and test your function with curl. You can find your local Publishable key, by running `supabase status`, or you can find the complete `curl` command already in `functions/hello-world/index.ts`.
```bash
curl -i --location --request POST 'http://127.0.0.1:54321/functions/v1/hello-world' \
--header 'apiKey: ' \
--data '{"name":"Functions"}'
```
After running this curl command, you should see:
```json
{ "message": "Hello Functions!" }
```
You can also try different inputs. Change `"Functions"` to `"World"` in the curl command and run it again to see the response change.
After this step, you should have successfully tested your Edge Function locally and received a JSON response with your greeting message.
## Step 5: Connect to your Supabase project
To deploy your function globally, you need to connect your local project to a Supabase project.
Create one at [database.new](https://database.new/).
First, login to the CLI if you haven't already, and authenticate with Supabase. This opens your browser to authenticate with Supabase; complete the login process in your browser.
```bash
supabase login
```
Next, list your Supabase projects to find your project ID:
```bash
supabase projects list
```
Next, copy your project ID from the output, then connect your local project to your remote Supabase project. Replace `YOUR_PROJECT_ID` with the ID from the previous step.
```bash
supabase link --project-ref [YOUR_PROJECT_ID]
```
After this step, you should have your local project authenticated and linked to your remote Supabase project. You can verify this by running `supabase status`.
## Step 6: Deploy to production
Deploy your function to Supabase's global edge network:
```bash
supabase functions deploy hello-world
```
If you want to deploy all functions, run the `deploy` command without specifying a function name:
```bash
supabase functions deploy
```
The CLI automatically falls back to API-based deployment if Docker isn't available. You can also explicitly use API deployment with the `--use-api` flag:
```bash
supabase functions deploy hello-world --use-api
```
When the deployment is successful, your function is automatically distributed to edge locations worldwide.
Now, you should have your Edge Function deployed and running globally at `https://[YOUR_PROJECT_ID].supabase.co/functions/v1/hello-world`.
## Step 7: Test your live function
🎉 Your function is now live! Test it with your project's publishable key that you can find in the **Settings > API Keys** section of the [Dashboard](/dashboard/project/_/settings/api-keys):
```bash
curl --request POST 'https://[YOUR_PROJECT_ID].supabase.co/functions/v1/hello-world' \
--header 'apikey: ' \
--header 'Content-Type: application/json' \
--data '{"name":"Production"}'
```
**Expected response:**
```json
{ "message": "Hello Production!" }
```
## Usage
Now that your function is deployed, you can invoke it from within an app:
```jsx
import { createClient } from '@supabase/supabase-js'
const supabase = createClient('https://[YOUR_PROJECT_ID].supabase.co', 'YOUR_PUBLISHABLE_KEY')
const { data, error } = await supabase.functions.invoke('hello-world', {
body: { name: 'JavaScript' },
})
console.log(data) // { message: "Hello JavaScript!" }
```
```jsx
const response = await fetch('https://[YOUR_PROJECT_ID].supabase.co/functions/v1/hello-world', {
method: 'POST',
headers: {
apikey: '',
'Content-Type': 'application/json',
},
body: JSON.stringify({ name: 'Fetch' }),
})
const data = await response.json()
console.log(data)
```
# Recursive / Nested Function Calls
Understanding rate limits when Edge Functions invoke each other
Edge Functions can call other Edge Functions using `fetch()`. This enables powerful patterns like function chaining, fan-out/fan-in workflows, and recursive processing. To protect platform stability and prevent runaway amplification, Supabase rate limits these internal function-to-function calls.
## What gets rate limited
Rate limiting applies to **outbound `fetch()` calls** made by your Edge Functions to other Edge Functions within your project. This includes:
* **Direct recursion**: A function calling itself
* **Function chaining**: Function A calling Function B
* **Circular calls**: Function A calling Function B, which calls Function A
* **Fan-out patterns**: A function calling multiple other functions concurrently
Inbound requests to your Edge Functions and requests to external APIs (e.g., Stripe, OpenAI) are **not** subject to this rate limit. Only outbound calls from one Edge Function to another Edge Function are counted.
## Rate limit budget
Each request chain has a budget of at least **5,000 requests per minute**. In busier regions, this budget may be higher. All function-to-function calls within the same request chain share this budget.
For example, if Function A calls Function B, and Function B calls Function C, all three calls count toward the same budget pool.
## Handling rate limit errors
When the rate limit is exceeded, calling another Edge Function throws a `RateLimitError`. This error includes a `retryAfterMs` property indicating how long to wait (in milliseconds) before retrying. You should catch this error and handle it gracefully:
```typescript
import { createClient } from 'jsr:@supabase/supabase-js@2'
const SUPABASE_PUBLISHABLE_KEYS = JSON.parse(Deno.env.get('SUPABASE_PUBLISHABLE_KEYS')!)
const supabase = createClient(
Deno.env.get('SUPABASE_URL')!,
// If you want to use a different api key, change 'default' to your preferred key name
SUPABASE_PUBLISHABLE_KEYS['default']
)
Deno.serve(async (req) => {
try {
const { data, error } = await supabase.functions.invoke('other-function', {
body: { foo: 'bar' },
})
if (error) throw error
return new Response(JSON.stringify(data), {
headers: { 'Content-Type': 'application/json' },
})
} catch (err) {
if (err instanceof Deno.errors.RateLimitError) {
// Use retryAfterMs to tell the client when to retry
const retryAfterSeconds = Math.ceil(err.retryAfterMs / 1000)
return new Response(
JSON.stringify({ error: 'Service temporarily unavailable. Please retry later.' }),
{
status: 429,
headers: {
'Content-Type': 'application/json',
'Retry-After': retryAfterSeconds.toString(),
},
}
)
}
throw err
}
})
```
```typescript
const SUPABASE_PUBLISHABLE_KEYS = JSON.parse(Deno.env.get('SUPABASE_PUBLISHABLE_KEYS')!)
// If you want to use a different api key, change 'default' to your preferred key name
const SUPABASE_DEFAULT_PUBLISHABLE_KEY = SUPABASE_PUBLISHABLE_KEYS['default']
Deno.serve(async (req) => {
try {
const response = await fetch(`${Deno.env.get('SUPABASE_URL')}/functions/v1/other-function`, {
method: 'POST',
headers: {
Authorization: `Bearer ${SUPABASE_DEFAULT_PUBLISHABLE_KEY}`,
'Content-Type': 'application/json',
},
body: JSON.stringify({ foo: 'bar' }),
})
return response
} catch (err) {
if (err instanceof Deno.errors.RateLimitError) {
// Use retryAfterMs to tell the client when to retry
const retryAfterSeconds = Math.ceil(err.retryAfterMs / 1000)
return new Response(
JSON.stringify({ error: 'Service temporarily unavailable. Please retry later.' }),
{
status: 429,
headers: {
'Content-Type': 'application/json',
'Retry-After': retryAfterSeconds.toString(),
},
}
)
}
throw err
}
})
```
You can also use `retryAfterMs` to implement automatic retries within your function:
```typescript
import { createClient } from 'jsr:@supabase/supabase-js@2'
const SUPABASE_PUBLISHABLE_KEYS = JSON.parse(Deno.env.get('SUPABASE_PUBLISHABLE_KEYS')!)
const supabase = createClient(
Deno.env.get('SUPABASE_URL')!,
// If you want to use a different api key, change 'default' to your preferred key name
SUPABASE_PUBLISHABLE_KEYS['default']
)
async function invokeWithRetry(functionName: string, payload: object, maxRetries = 3) {
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
const { data, error } = await supabase.functions.invoke(functionName, {
body: payload,
})
if (error) throw error
return data
} catch (err) {
if (err instanceof Deno.errors.RateLimitError && attempt < maxRetries - 1) {
// Wait for the recommended duration before retrying
await new Promise((resolve) => setTimeout(resolve, err.retryAfterMs))
continue
}
throw err
}
}
}
```
```typescript
async function fetchWithRetry(url: string, options: RequestInit, maxRetries = 3) {
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
return await fetch(url, options)
} catch (err) {
if (err instanceof Deno.errors.RateLimitError && attempt < maxRetries - 1) {
// Wait for the recommended duration before retrying
await new Promise((resolve) => setTimeout(resolve, err.retryAfterMs))
continue
}
throw err
}
}
}
```
## Tips for avoiding rate limits
### 1. Batch operations instead of individual calls
Instead of calling a function once per item, batch multiple items into a single call:
```typescript
// ❌ Avoid: One call per item
for (const item of items) {
await supabase.functions.invoke('process-item', { body: item })
}
// ✅ Better: Batch items into one call
await supabase.functions.invoke('process-items', { body: { items } })
```
### 2. Limit recursion depth
If your function is recursive, set a maximum depth to prevent unbounded call chains:
```typescript
Deno.serve(async (req) => {
const { depth = 0, data } = await req.json()
if (depth >= 5) {
// Stop recursion at max depth
return new Response(JSON.stringify({ result: data }))
}
// Process and recurse with incremented depth
const processed = processData(data)
const { data: result } = await supabase.functions.invoke('my-function', {
body: { depth: depth + 1, data: processed },
})
return new Response(JSON.stringify(result))
})
```
### 3. Use queues for large workloads
For processing large datasets, consider using [Supabase Queues](/docs/guides/queues) instead of recursive function calls. Queues handle backpressure automatically and are better suited for high-volume workloads.
### 4. Use shared libraries instead of separate functions
Instead of creating separate Edge Functions that call each other, create a shared library of functions and import them directly. This avoids HTTP overhead and rate limits entirely:
```typescript
// supabase/functions/_shared/transform.ts
export function validate(data: any) {
// validation logic
}
export function transform(data: any) {
// transformation logic
}
export async function save(data: any) {
// save logic
}
```
```typescript
// supabase/functions/process-data/index.ts
import { validate, transform, save } from '../_shared/transform.ts'
Deno.serve(async (req) => {
const data = await req.json()
const validated = validate(data)
const transformed = transform(validated)
const result = await save(transformed)
return new Response(JSON.stringify(result))
})
```
### 5. Add delays for non-urgent processing
If immediate processing isn't required, add delays between calls to spread the load:
```typescript
async function processWithDelay(items: any[]) {
for (const item of items) {
await supabase.functions.invoke('process-item', { body: item })
await new Promise((resolve) => setTimeout(resolve, 100)) // 100ms delay
}
}
```
## Common patterns and their impact
| Pattern | Budget consumption | Recommendation |
| ------------------------------- | ------------------ | ----------------- |
| Simple chain (A to B to C) | Low | Generally safe |
| Fan-out (A to B, C, D, E) | Moderate | Limit concurrency |
| Deep recursion (A to A to A...) | High | Set max depth |
| Unbounded loops | Very high | Avoid, use queues |
## Increasing rate limits
Currently, all plans have the same rate limit budget. We are working on introducing custom limits for different use cases.
If you need a higher rate limit for your project, [contact support](/dashboard/support/new) with details about your use case.
# Regional Invocations
Execute Edge Functions in specific regions for optimal performance.
Edge Functions automatically execute in the region closest to the user making the request. This reduces network latency and provides faster responses.
However, if your function performs intensive database or storage operations, executing in the same region as your database often provides better performance:
* **Bulk database operations:** Adding or editing many records
* **File uploads:** Processing large files or multiple uploads
* **Complex queries:** Operations requiring multiple database round trips
***
## Available regions
The following regions are supported:
**Asia Pacific:**
* `ap-northeast-1` (Tokyo)
* `ap-northeast-2` (Seoul)
* `ap-south-1` (Mumbai)
* `ap-southeast-1` (Singapore)
* `ap-southeast-2` (Sydney)
**North America:**
* `ca-central-1` (Canada Central)
* `us-east-1` (N. Virginia)
* `us-west-1` (N. California)
* `us-west-2` (Oregon)
**Europe:**
* `eu-central-1` (Frankfurt)
* `eu-west-1` (Ireland)
* `eu-west-2` (London)
* `eu-west-3` (Paris)
**South America:**
* `sa-east-1` (São Paulo)
***
## Usage
You can specify the region programmatically using the Supabase Client library, or using the `x-region` HTTP header.
```js name=JavaScript
import { createClient, FunctionRegion } from '@supabase/supabase-js'
const { data, error } = await supabase.functions.invoke('function-name', {
...
region: FunctionRegion.UsEast1, // Execute in us-east-1 region
})
```
```bash name=cURL
curl --request POST 'https://.supabase.co/functions/v1/function-name' \
--header 'x-region: us-east-1' # Execute in us-east-1 region
```
In case you cannot add the `x-region` header to the request (e.g.: CORS requests, Webhooks), you can use `forceFunctionRegion` query parameter.
You can verify the execution region by looking at the `x-sb-edge-region` HTTP header in the response. You can also find it as metadata in [Edge Function Logs](/docs/guides/functions/logging).
***
## Region runtime information
Functions have access to the following environment variables:
SB\_REGION: The AWS region function was invoked
This is useful if you have read replicate and want to Postgres connect to a different replicate according of the Region.
***
## Region outages
When you explicitly specify a region via the `x-region` header, requests will NOT be automatically
re-routed to another region.
During outages, consider temporarily changing to a different region.
Test your function's performance with and without regional specification to determine if the benefits outweigh automatic region selection.
# Handling Routing in Functions
Handle custom routing within Edge Functions.
Usually, an Edge Function is written to perform a single action (e.g. write a record to the database). However, if your app's logic is split into multiple Edge Functions, requests to each action may seem slower.
Each Edge Function needs to be booted before serving a request (known as cold starts). If an action is performed less frequently (e.g. deleting a record), there is a high chance of that function experiencing a cold start.
One way to reduce cold starts and increase performance is to combine multiple actions into a single Edge Function. This way only one instance needs to be booted and it can handle multiple requests to different actions.
This allows you to:
* Reduce cold starts by combining multiple actions into one function
* Build complete REST APIs in a single function
* Improve performance by keeping one instance warm for multiple endpoints
***
For example, we can use a single Edge Function to create a typical CRUD API (create, read, update, delete records).
To combine multiple endpoints into a single Edge Function, you can use web application frameworks such as [Express](https://expressjs.com/), [Oak](https://oakserver.github.io/oak/), or [Hono](https://hono.dev).
***
## Basic routing example
Here's a simple hello world example using some popular web frameworks:
```ts
Deno.serve(async (req) => {
if (req.method === 'GET') {
return new Response('Hello World!')
}
const { name } = await req.json()
if (name) {
return new Response(`Hello ${name}!`)
}
return new Response('Hello World!')
})
```
```ts
import express from 'npm:express@4.18.2'
const app = express()
app.use(express.json())
// If you want a payload larger than 100kb, then you can tweak it here:
// app.use( express.json({ limit : "300kb" }));
const port = 3000
app.get('/hello-world', (req, res) => {
res.send('Hello World!')
})
app.post('/hello-world', (req, res) => {
const { name } = req.body
res.send(`Hello ${name}!`)
})
app.listen(port, () => {
console.log(`Example app listening on port ${port}`)
})
```
```ts
import { Application } from 'jsr:@oak/oak@15/application'
import { Router } from 'jsr:@oak/oak@15/router'
const router = new Router()
router.get('/hello-world', (ctx) => {
ctx.response.body = 'Hello world!'
})
router.post('/hello-world', async (ctx) => {
const { name } = await ctx.request.body.json()
ctx.response.body = `Hello ${name}!`
})
const app = new Application()
app.use(router.routes())
app.use(router.allowedMethods())
app.listen({ port: 3000 })
```
```ts
import { Hono } from 'jsr:@hono/hono'
const app = new Hono()
app.post('/hello-world', async (c) => {
const { name } = await c.req.json()
return new Response(`Hello ${name}!`)
})
app.get('/hello-world', (c) => {
return new Response('Hello World!')
})
Deno.serve(app.fetch)
```
Within Edge Functions, paths should always be prefixed with the function name (in this case `hello-world`).
***
## Using route parameters
You can use route parameters to capture values at specific URL segments (e.g. `/tasks/:taskId/notes/:noteId`).
Keep in mind paths must be prefixed by function name. Route parameters can only be used after the function name prefix.
```ts
interface Task {
id: string
name: string
}
let tasks: Task[] = []
const router = new Map Promise>()
async function getAllTasks(): Promise {
return new Response(JSON.stringify(tasks))
}
async function getTask(id: string): Promise {
const task = tasks.find((t) => t.id === id)
if (task) {
return new Response(JSON.stringify(task))
} else {
return new Response('Task not found', { status: 404 })
}
}
async function createTask(req: Request): Promise {
const id = Math.random().toString(36).substring(7)
const task = { id, name: '' }
tasks.push(task)
return new Response(JSON.stringify(task), { status: 201 })
}
async function updateTask(id: string, req: Request): Promise {
const index = tasks.findIndex((t) => t.id === id)
if (index !== -1) {
tasks[index] = { ...tasks[index] }
return new Response(JSON.stringify(tasks[index]))
} else {
return new Response('Task not found', { status: 404 })
}
}
async function deleteTask(id: string): Promise {
const index = tasks.findIndex((t) => t.id === id)
if (index !== -1) {
tasks.splice(index, 1)
return new Response('Task deleted successfully')
} else {
return new Response('Task not found', { status: 404 })
}
}
Deno.serve(async (req) => {
const url = new URL(req.url)
const method = req.method
// Extract the last part of the path as the command
const command = url.pathname.split('/').pop()
// Assuming the last part of the path is the task ID
const id = command
try {
switch (method) {
case 'GET':
if (id) {
return getTask(id)
} else {
return getAllTasks()
}
case 'POST':
return createTask(req)
case 'PUT':
if (id) {
return updateTask(id, req)
} else {
return new Response('Bad Request', { status: 400 })
}
case 'DELETE':
if (id) {
return deleteTask(id)
} else {
return new Response('Bad Request', { status: 400 })
}
default:
return new Response('Method Not Allowed', { status: 405 })
}
} catch (error) {
return new Response(`Internal Server Error: ${error}`, { status: 500 })
}
})
```
```ts
import express from 'npm:express@4.18.2'
const app = express()
app.use(express.json())
app.get('/tasks', async (req, res) => {
// return all tasks
})
app.post('/tasks', async (req, res) => {
// create a task
})
app.get('/tasks/:id', async (req, res) => {
const id = req.params.id
const task = {} // get task
res.json(task)
})
app.patch('/tasks/:id', async (req, res) => {
const id = req.params.id
// modify task
})
app.delete('/tasks/:id', async (req, res) => {
const id = req.params.id
// delete task
})
```
```ts
import { Application } from 'jsr:@oak/oak/application'
import { Router } from 'jsr:@oak/oak/router'
const router = new Router()
let tasks: { [id: string]: any } = {}
router
.get('/tasks', (ctx) => {
ctx.response.body = Object.values(tasks)
})
.post('/tasks', async (ctx) => {
const body = ctx.request.body()
const { name } = await body.value
const id = Math.random().toString(36).substring(7)
tasks[id] = { id, name }
ctx.response.body = tasks[id]
})
.get('/tasks/:id', (ctx) => {
const id = ctx.params.id
const task = tasks[id]
if (task) {
ctx.response.body = task
} else {
ctx.response.status = 404
ctx.response.body = 'Task not found'
}
})
.patch('/tasks/:id', async (ctx) => {
const id = ctx.params.id
const body = ctx.request.body()
const updates = await body.value
const task = tasks[id]
if (task) {
tasks[id] = { ...task, ...updates }
ctx.response.body = tasks[id]
} else {
ctx.response.status = 404
ctx.response.body = 'Task not found'
}
})
.delete('/tasks/:id', (ctx) => {
const id = ctx.params.id
if (tasks[id]) {
delete tasks[id]
ctx.response.body = 'Task deleted successfully'
} else {
ctx.response.status = 404
ctx.response.body = 'Task not found'
}
})
const app = new Application()
app.use(router.routes())
app.use(router.allowedMethods())
app.listen({ port: 3000 })
```
```ts
import { Hono } from 'jsr:@hono/hono'
// You can set the basePath with Hono
const functionName = 'tasks'
const app = new Hono().basePath(`/${functionName}`)
// /tasks/id
app.get('/:id', async (c) => {
const id = c.req.param('id')
const task = {} // Fetch task by id here
if (task) {
return new Response(JSON.stringify(task))
} else {
return new Response('Task not found', { status: 404 })
}
})
app.patch('/:id', async (c) => {
const id = c.req.param('id')
const body = await c.req.body()
const updates = body.value
const task = {} // Fetch task by id here
if (task) {
Object.assign(task, updates)
return new Response(JSON.stringify(task))
} else {
return new Response('Task not found', { status: 404 })
}
})
app.delete('/:id', async (c) => {
const id = c.req.param('id')
const task = {} // Fetch task by id here
if (task) {
// Delete task
return new Response('Task deleted successfully')
} else {
return new Response('Task not found', { status: 404 })
}
})
Deno.serve(app.fetch)
```
***
{/* supa-mdx-lint-disable Rule001HeadingCase */}
## URL Patterns API
If you prefer not to use a web framework, you can directly use [URL Pattern API](https://developer.mozilla.org/en-US/docs/Web/API/URL_Pattern_API) within your Edge Functions to implement routing.
This works well for small apps with only a couple of routes:
```typescript restful-tasks/index.ts
// ...
}
)
// For more details on URLPattern, check https://developer.mozilla.org/en-US/docs/Web/API/URL_Pattern_API
const taskPattern = new URLPattern({ pathname: '/restful-tasks/:id' })
const matchingPath = taskPattern.exec(url)
const id = matchingPath ? matchingPath.pathname.groups.id : null
let task = null
if (method === 'POST' || method === 'PUT') {
const body = await req.json()
task = body.task
}
// call relevant method based on method and id
switch (true) {
case id && method === 'GET':
return getTask(supabaseClient, id as string)
case id && method === 'PUT':
return updateTask(supabaseClient, id as string, task)
case id && method === 'DELETE':
return deleteTask(supabaseClient, id as string)
case method === 'POST':
return createTask(supabaseClient, task)
case method === 'GET':
// ...
```
# Scheduling Edge Functions
The hosted Supabase Platform supports the [`pg_cron` extension](/docs/guides/database/extensions/pgcron), a recurring job scheduler in Postgres.
In combination with the [`pg_net` extension](/docs/guides/database/extensions/pgnet), this allows us to invoke Edge Functions periodically on a set schedule.
To access the auth token securely for your Edge Function call, we recommend storing them in [Supabase Vault](/docs/guides/database/vault).
## Examples
### Invoke an Edge Function every minute
Store `project_url` and `publishable_key` in Supabase Vault:
```sql
select vault.create_secret('https://project-ref.supabase.co', 'project_url');
select vault.create_secret('YOUR_SUPABASE_PUBLISHABLE_KEY', 'publishable_key');
```
Make a POST request to a Supabase Edge Function every minute:
```sql
select
cron.schedule(
'invoke-function-every-minute',
'* * * * *', -- every minute
$$
select
net.http_post(
url:= (select decrypted_secret from vault.decrypted_secrets where name = 'project_url') || '/functions/v1/function-name',
headers:=jsonb_build_object(
'Content-type', 'application/json',
'Authorization', 'Bearer ' || (select decrypted_secret from vault.decrypted_secrets where name = 'publishable_key')
),
body:=concat('{"time": "', now(), '"}')::jsonb
) as request_id;
$$
);
```
## Resources
* [`pg_net` extension](/docs/guides/database/extensions/pgnet)
* [`pg_cron` extension](/docs/guides/database/extensions/pgcron)
# Environment Variables
Manage sensitive data securely across environments.
## Default secrets
Edge Functions have access to these secrets by default:
* `SUPABASE_URL`: The API gateway for your Supabase project
* `SUPABASE_DB_URL`: The URL for your Postgres database. You can use this to connect directly to your database
* `SUPABASE_PUBLISHABLE_KEYS`: The `publishable` keys JSON dictionary for your Supabase API. This is safe to use in a browser when you have Row Level Security enabled
* `SUPABASE_SECRET_KEYS`: The `secret` keys JSON dictionary for your Supabase API. This is safe to use in Edge Functions, but it should NEVER be used in a browser. This key will bypass Row Level Security
* `SUPABASE_JWKS`: The JSON Web Key Set used to verify user JWTs. Same value served at `https://.supabase.co/auth/v1/.well-known/jwks.json`
Legacy keys:
* `SUPABASE_ANON_KEY`: The `anon` key for your Supabase API. This is safe to use in a browser when you have Row Level Security enabled
* `SUPABASE_SERVICE_ROLE_KEY`: The `service_role` key for your Supabase API. This is safe to use in Edge Functions, but it should NEVER be used in a browser. This key will bypass Row Level Security
In a hosted environment, functions have access to the following environment variables:
* `SB_REGION`: The region function was invoked
* `SB_EXECUTION_ID`: A UUID of function instance ([isolate](/docs/guides/functions/architecture#4-execution-mechanics-fast-and-isolated))
* `DENO_DEPLOYMENT_ID`: Version of the function code (`{project_ref}_{function_id}_{version}`)
***
## Accessing environment variables
You can access environment variables using Deno's built-in handler, and passing it the name of the environment variable you’d like to access.
```js
Deno.env.get('NAME_OF_SECRET')
```
For example, in a function:
```ts
import { createClient } from 'npm:@supabase/supabase-js@2'
const SUPABASE_PUBLISHABLE_KEYS = JSON.parse(Deno.env.get('SUPABASE_PUBLISHABLE_KEYS')!)
// For user-facing operations (respects RLS)
const supabase = createClient(
Deno.env.get('SUPABASE_URL')!,
// If you want to use a different api key, change 'default' to your preferred key name
SUPABASE_PUBLISHABLE_KEYS['default']
)
const SUPABASE_SECRET_KEYS = JSON.parse(Deno.env.get('SUPABASE_SECRET_KEYS')!)
// For admin operations (bypasses RLS)
const supabaseAdmin = createClient(
Deno.env.get('SUPABASE_URL')!,
// If you want to use a different api key, change 'default' to your preferred key name
SUPABASE_SECRET_KEYS['default']
)
```
***
### Local secrets
In development, you can load environment variables in two ways:
1. Through an `.env` file placed at `supabase/functions/.env`, which is automatically loaded on `supabase start`
2. Through the `--env-file` option for `supabase functions serve`. This allows you to use custom file names like `.env.local` to distinguish between different environments.
```bash
supabase functions serve --env-file .env.local
```
Never check your `.env` files into Git! Instead, add the path to this file to your `.gitignore`.
We can automatically access the secrets in our Edge Functions through Deno’s handler
```tsx
const secretKey = Deno.env.get('STRIPE_SECRET_KEY')
```
Now we can invoke our function locally. If you're using the default `.env` file at `supabase/functions/.env`, it's automatically loaded:
```bash
supabase functions serve hello-world
```
Or you can specify a custom `.env` file with the `--env-file` flag:
```bash
supabase functions serve hello-world --env-file .env.local
```
This is useful for managing different environments (development, staging, etc.).
***
### Production secrets
You will also need to set secrets for your production Edge Functions. You can do this via the Dashboard or using the CLI.
**Using the Dashboard**:
1. Visit [Edge Function Secrets Management](/dashboard/project/_/functions/secrets) page in your Dashboard.
2. Add the Key and Value for your secret and press Save
Note that you can paste multiple secrets at a time.
**Using the CLI**
You can create a `.env` file to help deploy your secrets to production
```bash
# .env
STRIPE_SECRET_KEY=sk_live_...
```
Never check your `.env` files into Git! Instead, add the path to this file to your `.gitignore`.
You can push all the secrets from the `.env` file to your remote project using `supabase secrets set`. This makes the environment visible in the dashboard as well.
```bash
supabase secrets set --env-file .env
```
Alternatively, this command also allows you to set production secrets individually rather than storing them in a `.env` file.
```bash
supabase secrets set STRIPE_SECRET_KEY=sk_live_...
```
To see all the secrets which you have set remotely, you can use `supabase secrets list`
```bash
supabase secrets list
```
You don't need to re-deploy after setting your secrets. They're available immediately in your
functions.
# Status codes
Understand HTTP status codes returned by Edge Functions to properly debug issues and handle responses.
{/* supa-mdx-lint-disable Rule001HeadingCase */}
## Success Responses
### 2XX Success
Your Edge Function executed successfully and returned a valid response. This includes any status code in the 200-299 range that your function explicitly returns.
### 3XX Redirect
Your Edge Function used the `Response.redirect()` API to redirect the client to a different URL. This is a normal response when implementing authentication flows or URL forwarding.
***
## Client Errors
These errors indicate issues with the request itself, which typically require changing how the function is called.
### 401 Unauthorized
**Cause:** The Edge Function has JWT verification enabled, but the request was made with an invalid or missing JWT token.
**Solution:**
* Ensure you're passing a valid JWT token in the `Authorization` header
* Check that your token hasn't expired
* For webhooks or public endpoints, consider disabling JWT verification
### 404 Not Found
**Cause:** The requested Edge Function doesn't exist or the URL path is incorrect.
**Solution:**
* Verify the function name and project reference in your request URL
* Check that the function has been deployed successfully
### 405 Method Not Allowed
**Cause:** You're using an unsupported HTTP method. Edge Functions only support: `GET`, `POST`, `PUT`, `PATCH`, `DELETE`, and `OPTIONS`.
**Solution:** Update your request to use a supported HTTP method.
***
## Server Errors
These errors indicate issues with the function execution or underlying platform.
### 500 Internal Server Error
**Cause:** Your Edge Function threw an uncaught exception (`WORKER_ERROR`).
**Common causes:**
* Unhandled JavaScript errors in your function code
* Missing error handling for async operations
* Invalid JSON parsing
**Solution:** Check your Edge Function logs to identify the specific error and add proper error handling to your code.
```tsx
// ✅ Good error handling
try {
const result = await someAsyncOperation()
return new Response(JSON.stringify(result))
} catch (error) {
console.error('Function error:', error)
return new Response('Internal error', { status: 500 })
}
```
You can see the output in the [Edge Function Logs](/docs/guides/functions/logging).
### 503 Service Unavailable
**Cause:** Your Edge Function failed to start (`BOOT_ERROR`).
**Common causes:**
* Syntax errors preventing the function from loading
* Import errors or missing dependencies
* Invalid function configuration
**Solution:** Check your Edge Function logs and verify your function code can be executed locally with `supabase functions serve`.
### 504 Gateway Timeout
**Cause:** Your Edge Function didn't respond within the [request timeout limit](/docs/guides/functions/limits).
**Common causes:**
* Long-running database queries
* Slow external API calls
* Infinite loops or blocking operations
**Solution:**
* Optimize slow operations
* Add timeout handling to external requests
* Consider breaking large operations into smaller chunks
### 546 Resource Limit (Custom Error Code)
**Cause:** Your Edge Function execution was stopped due to exceeding resource limits (`WORKER_LIMIT`). Edge Function logs should provide which [resource limit](/docs/guides/functions/limits) was exceeded.
**Common causes:**
* Memory usage exceeded available limits
* CPU time exceeded execution quotas
* Too many concurrent operations
**Solution:** Check your Edge Function logs to see which resource limit was exceeded, then optimize your function accordingly.
# Integrating with Supabase Storage
Edge Functions work seamlessly with [Supabase Storage](/docs/guides/storage). This allows you to:
* Upload generated content directly from your functions
* Implement cache-first patterns for better performance
* Serve files with built-in CDN capabilities
***
## Basic file operations
Use the Supabase client to upload files directly from your Edge Functions. You'll need the secret key for server-side storage operations:
```typescript
import { createClient } from 'npm:@supabase/supabase-js@2'
const SUPABASE_SECRET_KEYS = JSON.parse(Deno.env.get('SUPABASE_SECRET_KEYS')!)
Deno.serve(async (req) => {
const supabaseAdmin = createClient(
Deno.env.get('SUPABASE_URL')!,
// If you want to use a different api key, change 'default' to your preferred key name
SUPABASE_SECRET_KEYS['default']
)
// Generate your content
const fileContent = await generateImage()
// Upload to storage
const { data, error } = await supabaseAdmin.storage
.from('images')
.upload(`generated/${filename}.png`, fileContent.body!, {
contentType: 'image/png',
cacheControl: '3600',
upsert: false,
})
if (error) {
throw error
}
return new Response(JSON.stringify({ path: data.path }))
})
```
Always use one of the `SUPABASE_SECRET_KEYS` for server-side operations. Never expose this key in client-side code!
***
## Cache-first pattern
Check storage before generating new content to improve performance:
```typescript
const STORAGE_URL = 'https://your-project.supabase.co/storage/v1/object/public/images'
Deno.serve(async (req) => {
const url = new URL(req.url)
const username = url.searchParams.get('username')
try {
// Try to get existing file from storage first
const storageResponse = await fetch(`${STORAGE_URL}/avatars/${username}.png`)
if (storageResponse.ok) {
// File exists in storage, return it directly
return storageResponse
}
// File doesn't exist, generate it
const generatedImage = await generateAvatar(username)
// Upload to storage for future requests
const { error } = await supabaseAdmin.storage
.from('images')
.upload(`avatars/${username}.png`, generatedImage.body!, {
contentType: 'image/png',
cacheControl: '86400', // Cache for 24 hours
})
if (error) {
console.error('Upload failed:', error)
}
return generatedImage
} catch (error) {
return new Response('Error processing request', { status: 500 })
}
})
```
# Testing your Edge Functions
Writing Unit Tests for Edge Functions using Deno Test
Testing is an essential step in the development process to ensure the correctness and performance of your Edge Functions.
***
## Testing in Deno
Deno has a built-in test runner that you can use for testing JavaScript or TypeScript code. You can read the [official documentation](https://docs.deno.com/runtime/manual/basics/testing/) for more information and details about the available testing functions.
***
## Folder structure
We recommend creating your testing in a `supabase/functions/tests` directory, using the same name as the Function followed by `-test.ts`:
```bash
└── supabase
├── functions
│ ├── function-one
│ │ └── index.ts
│ └── function-two
│ │ └── index.ts
│ └── tests
│ └── function-one-test.ts # Tests for function-one
│ └── function-two-test.ts # Tests for function-two
└── config.toml
```
***
## Example
The following script is a good example to get started with testing your Edge Functions:
```typescript function-one-test.ts
// Import required libraries and modules
import { assert, assertEquals } from 'jsr:@std/assert@1'
import { createClient, SupabaseClient } from 'npm:@supabase/supabase-js@2'
// Will load the .env file to Deno.env
import 'jsr:@std/dotenv/load'
// Set up the configuration for the Supabase client
const supabaseUrl = Deno.env.get('SUPABASE_URL') ?? ''
const supabaseKey = Deno.env.get('SUPABASE_PUBLISHABLE_KEY') ?? ''
const options = {
auth: {
autoRefreshToken: false,
persistSession: false,
detectSessionInUrl: false,
},
}
// Test the creation and functionality of the Supabase client
const testClientCreation = async () => {
var client: SupabaseClient = createClient(supabaseUrl, supabaseKey, options)
// Verify if the Supabase URL and key are provided
if (!supabaseUrl) throw new Error('supabaseUrl is required.')
if (!supabaseKey) throw new Error('supabaseKey is required.')
// Test a simple query to the database
const { data: table_data, error: table_error } = await client
.from('my_table')
.select('*')
.limit(1)
if (table_error) {
throw new Error('Invalid Supabase client: ' + table_error.message)
}
assert(table_data, 'Data should be returned from the query.')
}
// Test the 'hello-world' function
const testHelloWorld = async () => {
var client: SupabaseClient = createClient(supabaseUrl, supabaseKey, options)
// Invoke the 'hello-world' function with a parameter
const { data: func_data, error: func_error } = await client.functions.invoke('hello-world', {
body: { name: 'bar' },
})
// Check for errors from the function invocation
if (func_error) {
throw new Error('Invalid response: ' + func_error.message)
}
// Log the response from the function
console.log(JSON.stringify(func_data, null, 2))
// Assert that the function returned the expected result
assertEquals(func_data.message, 'Hello bar!')
}
// Register and run the tests
Deno.test('Client Creation Test', testClientCreation)
Deno.test('Hello-world Function Test', testHelloWorld)
```
This test case consists of two parts.
1. The first part tests the client library and verifies that the database can be connected to and returns values from a table (`my_table`).
2. The second part tests the edge function and checks if the received value matches the expected value. Here's a brief overview of the code:
* We import various testing functions from the Deno standard library, including `assert`, `assertExists`, and `assertEquals`.
* We import the `createClient` and `SupabaseClient` classes from the `@supabase/supabase-js` library to interact with the Supabase client.
* We define the necessary configuration for the Supabase client, including the Supabase URL, API key, and authentication options.
* The `testClientCreation` function tests the creation of a Supabase client instance and queries the database for data from a table. It verifies that data is returned from the query.
* The `testHelloWorld` function tests the "Hello-world" Edge Function by invoking it using the Supabase client's `functions.invoke` method. It checks if the response message matches the expected greeting.
* We run the tests using the `Deno.test` function, providing a descriptive name for each test case and the corresponding test function.
Make sure to replace the placeholders (`supabaseUrl`, `supabaseKey`, `my_table`) with the actual values relevant to your Supabase setup.
***
## Running Edge Functions locally
To locally test and debug Edge Functions, you can utilize the Supabase CLI. Let's explore how to run Edge Functions locally using the Supabase CLI:
1. Ensure that the Supabase server is running by executing the following command:
```bash
supabase start
```
2. In your terminal, use the following command to serve the Edge Functions locally:
```bash
supabase functions serve
```
This command starts a local server that runs your Edge Functions, enabling you to test and debug them in a development environment.
3. Create the environment variables file:
```bash
# creates the file
touch .env
# adds the SUPABASE_URL secret
echo "SUPABASE_URL=http://localhost:54321" >> .env
# adds the SUPABASE_PUBLISHABLE_KEY secret
echo "SUPABASE_PUBLISHABLE_KEY=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJzdXBhYmFzZS1kZW1vIiwicm9sZSI6ImFub24iLCJleHAiOjE5ODM4MTI5OTZ9.CRXP1A7WOeoJeXxjNni43kdQwgnWNReilDMblYTn_I0" >> .env
# Alternatively, you can open it in your editor:
open .env
```
4. To run the tests, use the following command in your terminal:
```bash
deno test --allow-all supabase/functions/tests/function-one-test.ts
```
***
## Resources
* Full guide on Testing Supabase Edge Functions on [Mansueli's tips](https://blog.mansueli.com/testing-supabase-edge-functions-with-deno-test)
# Using Wasm modules
Use WebAssembly in Edge Functions.
Edge Functions supports running [WebAssembly (Wasm)](https://developer.mozilla.org/en-US/docs/WebAssembly) modules. WebAssembly is useful if you want to optimize code that's slower to run in JavaScript or require low-level manipulation.
This allows you to:
* Optimize performance-critical code beyond JavaScript capabilities
* Port existing libraries from other languages (C, C++, Rust) to JavaScript
* Access low-level system operations not available in JavaScript
For example, libraries like [magick-wasm](/docs/guides/functions/examples/image-manipulation) port existing C libraries to WebAssembly for complex image processing.
***
### Writing a Wasm module
You can use different languages and SDKs to write Wasm modules. For this tutorial, we will write a simple Wasm module in Rust that adds two numbers.
Follow this [guide on writing Wasm modules in Rust](https://developer.mozilla.org/en-US/docs/WebAssembly/Rust_to_Wasm) to setup your dev environment.
Create a new Edge Function called `wasm-add`
```bash
supabase functions new wasm-add
```
Create a new Cargo project for the Wasm module inside the function's directory:
```bash
cd supabase/functions/wasm-add
cargo new --lib add-wasm
```
Add the following code to `add-wasm/src/lib.rs`.
```
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
pub fn add(a: u32, b: u32) -> u32 {
a + b
}
```
Update the `add-wasm/Cargo.toml` to include the `wasm-bindgen` dependency.
```
[package]
name = "add-wasm"
version = "0.1.0"
description = "A simple wasm module that adds two numbers"
license = "MIT/Apache-2.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]
[dependencies]
wasm-bindgen = "0.2"
```
Build the package by running:
```bash
wasm-pack build --target deno
```
This will produce a Wasm binary file inside `add-wasm/pkg` directory.
***
## Calling the Wasm module from the Edge Function
Update your Edge Function to call the add function from the Wasm module:
```typescript index.ts
import { add } from './add-wasm/pkg/add_wasm.js'
Deno.serve(async (req) => {
const { a, b } = await req.json()
return new Response(JSON.stringify({ result: add(a, b) }), {
headers: { 'Content-Type': 'application/json' },
})
})
```
Supabase Edge Functions currently use Deno 1.46. From [Deno 2.1, importing Wasm modules](https://deno.com/blog/v2.1) will require even less boilerplate code.
***
## Bundle and deploy
Before deploying, ensure the Wasm module is bundled with your function by defining it in `supabase/config.toml`:
* You will need update Supabase CLI to 2.7.0 or higher for the `static_files` support.
* Static files cannot be deployed using the `--use-api` API flag. You need to build them with [Docker on the CLI](/docs/guides/functions/quickstart#step-6-deploy-to-production).
```toml
[functions.wasm-add]
static_files = [ "./functions/wasm-add/add-wasm/pkg/*"]
```
Deploy the function by running:
```bash
supabase functions deploy wasm-add
```
# Handling WebSockets
Handle WebSocket connections in Edge Functions.
Edge Functions supports hosting WebSocket servers that can facilitate bi-directional communications with browser clients.
This allows you to:
* Build real-time applications like chat or live updates
* Create WebSocket relay servers for external APIs
* Establish both incoming and outgoing WebSocket connections
***
## Creating WebSocket servers
Here are some basic examples of setting up WebSocket servers using Deno and Node.js APIs.
```ts
Deno.serve((req) => {
const upgrade = req.headers.get('upgrade') || ''
if (upgrade.toLowerCase() != 'websocket') {
return new Response("request isn't trying to upgrade to WebSocket.", { status: 400 })
}
const { socket, response } = Deno.upgradeWebSocket(req)
socket.onopen = () => console.log('socket opened')
socket.onmessage = (e) => {
console.log('socket message:', e.data)
socket.send(new Date().toString())
}
socket.onerror = (e) => console.log('socket errored:', e.message)
socket.onclose = () => console.log('socket closed')
return response
})
```
```ts
import { createServer } from 'node:http'
import { WebSocketServer } from 'npm:ws'
const server = createServer()
// Since we manually created the HTTP server,
// turn on the noServer mode.
const wss = new WebSocketServer({ noServer: true })
wss.on('connection', (ws) => {
console.log('socket opened')
ws.on('message', (data /** Buffer \*/, isBinary /** bool \*/) => {
if (isBinary) {
console.log('socket message:', data)
} else {
console.log('socket message:', data.toString())
}
ws.send(new Date().toString())
})
ws.on('error', (err) => {
console.log('socket errored:', err.message)
})
ws.on('close', () => console.log('socket closed'))
})
server.on('upgrade', (req, socket, head) => {
wss.handleUpgrade(req, socket, head, (ws) => {
wss.emit('connection', ws, req)
})
})
server.listen(8080)
```
***
### Outbound WebSockets
You can also establish an outbound WebSocket connection to another server from an Edge Function.
Combining it with incoming WebSocket servers, it's possible to use Edge Functions as a WebSocket proxy, for example as a [relay server](https://github.com/supabase-community/openai-realtime-console?tab=readme-ov-file#using-supabase-edge-functions-as-a-relay-server) for the [OpenAI Realtime API](https://platform.openai.com/docs/guides/realtime/overview).
```typescript supabase/functions/relay/index.ts
import { createServer } from "node:http";
import { WebSocketServer } from "npm:ws";
import { RealtimeClient } from "https://raw.githubusercontent.com/openai/openai-realtime-api-beta/refs/heads/main/lib/client.js";
// ...
const OPENAI_API_KEY = Deno.env.get("OPENAI_API_KEY");
const server = createServer();
// Since we manually created the HTTP server,
// turn on the noServer mode.
const wss = new WebSocketServer({ noServer: true });
wss.on("connection", async (ws) => {
console.log("socket opened");
if (!OPENAI_API_KEY) {
throw new Error("OPENAI_API_KEY is not set");
}
// Instantiate new client
console.log(`Connecting with key "${OPENAI_API_KEY.slice(0, 3)}..."`);
const client = new RealtimeClient({ apiKey: OPENAI_API_KEY });
// Relay: OpenAI Realtime API Event -> Browser Event
client.realtime.on("server.*", (event) => {
console.log(`Relaying "${event.type}" to Client`);
ws.send(JSON.stringify(event));
});
client.realtime.on("close", () => ws.close());
// Relay: Browser Event -> OpenAI Realtime API Event
// We need to queue data waiting for the OpenAI connection
const messageQueue = [];
const messageHandler = (data) => {
try {
const event = JSON.parse(data);
console.log(`Relaying "${event.type}" to OpenAI`);
client.realtime.send(event.type, event);
} catch (e) {
console.error(e.message);
console.log(`Error parsing event from client: ${data}`);
}
};
ws.on("message", (data) => {
if (!client.isConnected()) {
messageQueue.push(data);
} else {
messageHandler(data);
}
});
ws.on("close", () => client.disconnect());
// Connect to OpenAI Realtime API
try {
console.log(`Connecting to OpenAI...`);
await client.connect();
} catch (e) {
console.log(`Error connecting to OpenAI: ${e.message}`);
ws.close();
return;
}
console.log(`Connected to OpenAI successfully!`);
while (messageQueue.length) {
messageHandler(messageQueue.shift());
}
});
server.on("upgrade", (req, socket, head) => {
wss.handleUpgrade(req, socket, head, (ws) => {
wss.emit("connection", ws, req);
});
});
server.listen(8080);
```
***
## Authentication
WebSocket browser clients don't have the option to send custom headers. Because of this, Edge Functions won't be able to perform the usual authorization header check to verify the JWT.
You can skip the default authorization header checks by explicitly providing `--no-verify-jwt` when serving and deploying functions.
To authenticate the user making WebSocket requests, you can pass the JWT in URL query params or via a custom protocol.
```ts
import { createClient } from 'npm:@supabase/supabase-js@2'
const SUPABASE_SECRET_KEYS = JSON.parse(Deno.env.get('SUPABASE_SECRET_KEYS')!)
const supabase = createClient(
Deno.env.get('SUPABASE_URL'),
// If you want to use a different api key, change 'default' to your preferred key name
SUPABASE_SECRET_KEYS['default']
)
Deno.serve((req) => {
const upgrade = req.headers.get('upgrade') || ''
if (upgrade.toLowerCase() != 'WebSocket') {
return new Response("request isn't trying to upgrade to WebSocket.", { status: 400 })
}
// Please be aware query params may be logged in some logging systems.
const url = new URL(req.url)
const jwt = url.searchParams.get('jwt')
if (!jwt) {
console.error('Auth token not provided')
return new Response('Auth token not provided', { status: 403 })
}
const { error, data } = await supabase.auth.getClaims()
if (error) {
console.error(error)
return new Response('Invalid token provided', { status: 403 })
}
if (!data.user) {
console.error('user is not authenticated')
return new Response('User is not authenticated', { status: 403 })
}
const { socket, response } = Deno.upgradeWebSocket(req)
socket.onopen = () => console.log('socket opened')
socket.onmessage = (e) => {
console.log('socket message:', e.data)
socket.send(new Date().toString())
}
socket.onerror = (e) => console.log('socket errored:', e.message)
socket.onclose = () => console.log('socket closed')
return response
})
```
```ts
import { createClient } from 'npm:@supabase/supabase-js@2'
const SUPABASE_SECRET_KEYS = JSON.parse(Deno.env.get('SUPABASE_SECRET_KEYS')!)
const supabase = createClient(
Deno.env.get('SUPABASE_URL'),
// If you want to use a different api key, change 'default' to your preferred key name
SUPABASE_SECRET_KEYS['default']
)
Deno.serve((req) => {
const upgrade = req.headers.get('upgrade') || ''
if (upgrade.toLowerCase() != 'WebSocket') {
return new Response("request isn't trying to upgrade to WebSocket.", { status: 400 })
}
// Sec-WebScoket-Protocol may return multiple protocol values `jwt-TOKEN, value1, value 2`
const customProtocols = (req.headers.get('Sec-WebSocket-Protocol') ?? '')
.split(',')
.map((p) => p.trim())
const jwt = customProtocols.find((p) => p.startsWith('jwt')).replace('jwt-', '')
if (!jwt) {
console.error('Auth token not provided')
return new Response('Auth token not provided', { status: 403 })
}
const { error, data } = await supabase.auth.getClaims()
if (error) {
console.error(error)
return new Response('Invalid token provided', { status: 403 })
}
if (!data.user) {
console.error('user is not authenticated')
return new Response('User is not authenticated', { status: 403 })
}
const { socket, response } = Deno.upgradeWebSocket(req)
socket.onopen = () => console.log('socket opened')
socket.onmessage = (e) => {
console.log('socket message:', e.data)
socket.send(new Date().toString())
}
socket.onerror = (e) => console.log('socket errored:', e.message)
socket.onclose = () => console.log('socket closed')
return response
})
```
The maximum duration is capped based on the wall-clock, CPU, and memory limits. The Function will shutdown when it reaches one of these [limits](/docs/guides/functions/limits).
***
## Testing WebSockets locally
When testing Edge Functions locally with Supabase CLI, the instances are terminated automatically after a request is completed. This will prevent keeping WebSocket connections open.
To prevent that, you can update the `supabase/config.toml` with the following settings:
```toml
[edge_runtime]
policy = "per_worker"
```
When running with `per_worker` policy, Function won't auto-reload on edits. You will need to manually restart it by running `supabase functions serve`.
# Generate Images with Amazon Bedrock
[Amazon Bedrock](https://aws.amazon.com/bedrock) is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon. Each model is accessible through a common API which implements a broad set of features to help build generative AI applications with security, privacy, and responsible AI in mind.
This guide will walk you through an example using the Amazon Bedrock JavaScript SDK in Supabase Edge Functions to generate images using the [Amazon Titan Image Generator G1](https://aws.amazon.com/blogs/machine-learning/use-amazon-titan-models-for-image-generation-editing-and-searching/) model.
## Setup
* In your AWS console, navigate to Amazon Bedrock and under "Request model access", select the Amazon Titan Image Generator G1 model.
* In your Supabase project, create a `.env` file in the `supabase` directory with the following contents:
```txt
AWS_DEFAULT_REGION=""
AWS_ACCESS_KEY_ID=""
AWS_SECRET_ACCESS_KEY=""
AWS_SESSION_TOKEN=""
# Mocked config files
AWS_SHARED_CREDENTIALS_FILE="./aws/credentials"
AWS_CONFIG_FILE="./aws/config"
```
### Configure Storage
* \[locally] Run `supabase start`
* Open Studio URL: [locally](http://127.0.0.1:54323/project/default/storage/buckets) | [hosted](https://app.supabase.com/project/_/storage/buckets)
* Navigate to Storage
* Click "New bucket"
* Create a new public bucket called "images"
## Code
Create a new function in your project:
```bash
supabase functions new amazon-bedrock
```
And add the code to the `index.ts` file:
```ts index.ts
// We need to mock the file system for the AWS SDK to work.
import { prepareVirtualFile } from 'https://deno.land/x/mock_file@v1.1.2/mod.ts'
import { BedrockRuntimeClient, InvokeModelCommand } from 'npm:@aws-sdk/client-bedrock-runtime'
import { createClient } from 'npm:@supabase/supabase-js'
import { decode } from 'npm:base64-arraybuffer'
console.log('Hello from Amazon Bedrock!')
const SUPABASE_PUBLISHABLE_KEYS = JSON.parse(Deno.env.get('SUPABASE_PUBLISHABLE_KEYS')!)
Deno.serve(async (req) => {
prepareVirtualFile('./aws/config')
prepareVirtualFile('./aws/credentials')
const client = new BedrockRuntimeClient({
region: Deno.env.get('AWS_DEFAULT_REGION') ?? 'us-west-2',
credentials: {
accessKeyId: Deno.env.get('AWS_ACCESS_KEY_ID') ?? '',
secretAccessKey: Deno.env.get('AWS_SECRET_ACCESS_KEY') ?? '',
sessionToken: Deno.env.get('AWS_SESSION_TOKEN') ?? '',
},
})
const { prompt, seed } = await req.json()
console.log(prompt)
const input = {
contentType: 'application/json',
accept: '*/*',
modelId: 'amazon.titan-image-generator-v1',
body: JSON.stringify({
taskType: 'TEXT_IMAGE',
textToImageParams: { text: prompt },
imageGenerationConfig: {
numberOfImages: 1,
quality: 'standard',
cfgScale: 8.0,
height: 512,
width: 512,
seed: seed ?? 0,
},
}),
}
const command = new InvokeModelCommand(input)
const response = await client.send(command)
console.log(response)
if (response.$metadata.httpStatusCode === 200) {
const { body, $metadata } = response
const textDecoder = new TextDecoder('utf-8')
const jsonString = textDecoder.decode(body.buffer)
const parsedData = JSON.parse(jsonString)
console.log(parsedData)
const image = parsedData.images[0]
const supabaseClient = createClient(
// Supabase API URL - env var exported by default.
Deno.env.get('SUPABASE_URL')!,
// Using the default Supabase API PUB KEY.
// If you want to use a different api key, change 'default' to your preferred key name
SUPABASE_PUBLISHABLE_KEYS['default']
)
const { data: upload, error: uploadError } = await supabaseClient.storage
.from('images')
.upload(`${$metadata.requestId ?? ''}.png`, decode(image), {
contentType: 'image/png',
cacheControl: '3600',
upsert: false,
})
if (!upload) {
return Response.json(uploadError)
}
const { data } = supabaseClient.storage.from('images').getPublicUrl(upload.path!)
return Response.json(data)
}
return Response.json(response)
})
```
## Run the function locally
1. Run `supabase start` (see: [https://supabase.com/docs/reference/cli/supabase-start](https://supabase.com/docs/reference/cli/supabase-start))
2. Start with env: `supabase functions serve --env-file supabase/.env`
3. Make an HTTP request:
```bash
curl -i --location --request POST 'http://127.0.0.1:54321/functions/v1/amazon-bedrock' \
--header 'apikey: ' \
--header 'Content-Type: application/json' \
--data '{"prompt":"A beautiful picture of a bird"}'
```
4. Navigate back to your storage bucket. You might have to hit the refresh button to see the uploaded image.
## Deploy to your hosted project
```bash
supabase link
supabase functions deploy amazon-bedrock
supabase secrets set --env-file supabase/.env
```
You've now deployed a serverless function that uses AI to generate and upload images to your Supabase storage bucket.
# Custom Auth Emails with React Email and Resend
Use the [send email hook](/docs/guides/auth/auth-hooks/send-email-hook?queryGroups=language\&language=http) to send custom auth emails with [React Email](https://react.email/) and [Resend](https://resend.com/) in Supabase Edge Functions.
Prefer to jump straight to the code? [Check out the example on GitHub](https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/auth-hook-react-email-resend).
### Prerequisites
To get the most out of this guide, you’ll need to:
* [Create a Resend API key](https://resend.com/api-keys)
* [Verify your domain](https://resend.com/domains)
Make sure you have the latest version of the [Supabase CLI](/docs/guides/cli#installation) installed.
### 1. Create Supabase function
Create a new function locally:
```bash
supabase functions new send-email
```
### 2. Edit the handler function
Paste the following code into the `index.ts` file:
```tsx supabase/functions/send-email/index.ts
import React from 'npm:react@18.3.1'
import { Webhook } from 'https://esm.sh/standardwebhooks@1.0.0'
import { Resend } from 'npm:resend@4.0.0'
import { renderAsync } from 'npm:@react-email/components@0.0.22'
import { MagicLinkEmail } from './_templates/magic-link.tsx'
const resend = new Resend(Deno.env.get('RESEND_API_KEY') as string)
const hookSecret = (Deno.env.get('SEND_EMAIL_HOOK_SECRET') as string).replace('v1,whsec_', '')
Deno.serve(async (req) => {
if (req.method !== 'POST') {
return new Response('not allowed', { status: 400 })
}
const payload = await req.text()
const headers = Object.fromEntries(req.headers)
const wh = new Webhook(hookSecret)
try {
const {
user,
email_data: { token, token_hash, redirect_to, email_action_type },
} = wh.verify(payload, headers) as {
user: {
email: string
}
email_data: {
token: string
token_hash: string
redirect_to: string
email_action_type: string
site_url: string
token_new: string
token_hash_new: string
}
}
const html = await renderAsync(
React.createElement(MagicLinkEmail, {
supabase_url: Deno.env.get('SUPABASE_URL') ?? '',
token,
token_hash,
redirect_to,
email_action_type,
})
)
const { error } = await resend.emails.send({
from: 'welcome ',
to: [user.email],
subject: 'Supa Custom MagicLink!',
html,
})
if (error) {
throw error
}
} catch (error) {
console.log(error)
return new Response(
JSON.stringify({
error: {
http_code: error.code,
message: error.message,
},
}),
{
status: 401,
headers: { 'Content-Type': 'application/json' },
}
)
}
const responseHeaders = new Headers()
responseHeaders.set('Content-Type', 'application/json')
return new Response(JSON.stringify({}), {
status: 200,
headers: responseHeaders,
})
})
```
### 3. Create React Email templates
Create a new folder `_templates` and create a new file `magic-link.tsx` with the following code:
```tsx supabase/functions/send-email/_templates/magic-link.tsx
import {
Body,
Container,
Head,
Heading,
Html,
Link,
Preview,
Text,
} from 'npm:@react-email/components@0.0.22'
import * as React from 'npm:react@18.3.1'
interface MagicLinkEmailProps {
supabase_url: string
email_action_type: string
redirect_to: string
token_hash: string
token: string
}
export const MagicLinkEmail = ({
token,
supabase_url,
email_action_type,
redirect_to,
token_hash,
}: MagicLinkEmailProps) => (
Log in with this magic link
Login
Click here to log in with this magic link
Or, copy and paste this temporary login code:
{token}
If you didn't try to login, you can safely ignore this email.
ACME Corp
, the famouse demo corp.
)
export default MagicLinkEmail
const main = {
backgroundColor: '#ffffff',
}
const container = {
paddingLeft: '12px',
paddingRight: '12px',
margin: '0 auto',
}
const h1 = {
color: '#333',
fontFamily:
"-apple-system, BlinkMacSystemFont, 'Segoe UI', 'Roboto', 'Oxygen', 'Ubuntu', 'Cantarell', 'Fira Sans', 'Droid Sans', 'Helvetica Neue', sans-serif",
fontSize: '24px',
fontWeight: 'bold',
margin: '40px 0',
padding: '0',
}
const link = {
color: '#2754C5',
fontFamily:
"-apple-system, BlinkMacSystemFont, 'Segoe UI', 'Roboto', 'Oxygen', 'Ubuntu', 'Cantarell', 'Fira Sans', 'Droid Sans', 'Helvetica Neue', sans-serif",
fontSize: '14px',
textDecoration: 'underline',
}
const text = {
color: '#333',
fontFamily:
"-apple-system, BlinkMacSystemFont, 'Segoe UI', 'Roboto', 'Oxygen', 'Ubuntu', 'Cantarell', 'Fira Sans', 'Droid Sans', 'Helvetica Neue', sans-serif",
fontSize: '14px',
margin: '24px 0',
}
const footer = {
color: '#898989',
fontFamily:
"-apple-system, BlinkMacSystemFont, 'Segoe UI', 'Roboto', 'Oxygen', 'Ubuntu', 'Cantarell', 'Fira Sans', 'Droid Sans', 'Helvetica Neue', sans-serif",
fontSize: '12px',
lineHeight: '22px',
marginTop: '12px',
marginBottom: '24px',
}
const code = {
display: 'inline-block',
padding: '16px 4.5%',
width: '90.5%',
backgroundColor: '#f4f4f4',
borderRadius: '5px',
border: '1px solid #eee',
color: '#333',
}
```
You can find a selection of React Email templates in the [React Email Examples](https://react.email/examples).
### 4. Deploy the Function
Deploy function to Supabase:
```bash
supabase functions deploy send-email --no-verify-jwt
```
Note down the function URL, you will need it in the next step!
### 5. Configure the Send Email Hook
* Go to the [Auth Hooks](/dashboard/project/_/auth/hooks) section of the Supabase dashboard and create a new "Send Email hook".
* Select HTTPS as the hook type.
* Paste the function URL in the "URL" field.
* Click "Generate Secret" to generate your webhook secret and note it down.
* Click "Create" to save the hook configuration.
Store these secrets in your `.env` file.
```bash supabase/functions/.env
RESEND_API_KEY=your_resend_api_key
SEND_EMAIL_HOOK_SECRET="v1,whsec_"
```
You can generate the secret in the [Auth Hooks](/dashboard/project/_/auth/hooks) section of the Supabase dashboard.
Set the secrets from the `.env` file:
```bash
supabase secrets set --env-file supabase/functions/.env
```
Now your Supabase Edge Function will be triggered anytime an Auth Email needs to be sent to the user!
## More resources
* [Send Email Hooks](/docs/guides/auth/auth-hooks/send-email-hook)
* [Auth Hooks](/docs/guides/auth/auth-hooks)
# CAPTCHA support with Cloudflare Turnstile
[Cloudflare Turnstile](https://www.cloudflare.com/application-services/products/turnstile/) is a friendly, free CAPTCHA replacement, and it works seamlessly with Supabase Edge Functions to protect your forms. [View on GitHub](https://github.com/supabase/supabase/tree/master/examples/edge-functions/supabase/functions/cloudflare-turnstile).
## Setup
* Follow these steps to set up a new site: [https://developers.cloudflare.com/turnstile/get-started/](https://developers.cloudflare.com/turnstile/get-started/)
* Add the Cloudflare Turnstile widget to your site: [https://developers.cloudflare.com/turnstile/get-started/client-side-rendering/](https://developers.cloudflare.com/turnstile/get-started/client-side-rendering/)
## Code
Create a new function in your project:
```bash
supabase functions new cloudflare-turnstile
```
And add the code to the `index.ts` file:
```ts index.ts
import { corsHeaders } from '@supabase/supabase-js/cors' // v2.95.0+
console.log('Hello from Cloudflare Trunstile!')
function ips(req: Request) {
return req.headers.get('x-forwarded-for')?.split(/\s*,\s*/)
}
Deno.serve(async (req) => {
// This is needed if you're planning to invoke your function from a browser.
if (req.method === 'OPTIONS') {
return new Response('ok', { headers: corsHeaders })
}
const { token } = await req.json()
const clientIps = ips(req) || ['']
const ip = clientIps[0]
// Validate the token by calling the
// "/siteverify" API endpoint.
let formData = new FormData()
formData.append('secret', Deno.env.get('CLOUDFLARE_SECRET_KEY') ?? '')
formData.append('response', token)
formData.append('remoteip', ip)
const url = 'https://challenges.cloudflare.com/turnstile/v0/siteverify'
const result = await fetch(url, {
body: formData,
method: 'POST',
})
const outcome = await result.json()
console.log(outcome)
if (outcome.success) {
return new Response('success', { headers: corsHeaders })
}
return new Response('failure', { headers: corsHeaders })
})
```
## Deploy the server-side validation Edge Functions
* [https://developers.cloudflare.com/turnstile/get-started/server-side-validation/](https://developers.cloudflare.com/turnstile/get-started/server-side-validation/)
```bash
supabase functions deploy cloudflare-turnstile
supabase secrets set CLOUDFLARE_SECRET_KEY=your_secret_key
```
## Invoke the function from your site
```js
const { data, error } = await supabase.functions.invoke('cloudflare-turnstile', {
body: { token },
})
```
# Building a Discord Bot
## Create an application on Discord Developer portal
1. Go to [https://discord.com/developers/applications](https://discord.com/developers/applications) (login using your discord account if required).
2. Click on **New Application** button available at left side of your profile picture.
3. Name your application and click on **Create**.
4. Go to **Bot** section, click on **Add Bot**, and finally on **Yes, do it!** to confirm.
A new application is created which will hold our Slash Command. Don't close the tab as we need information from this application page throughout our development.
Before we can write some code, we need to curl a discord endpoint to register a Slash Command in our app.
Fill `DISCORD_BOT_TOKEN` with the token available in the **Bot** section and `CLIENT_ID` with the ID available on the **General Information** section of the page and run the command on your terminal.
```bash
BOT_TOKEN='replace_me_with_bot_token'
CLIENT_ID='replace_me_with_client_id'
curl -X POST \
-H 'Content-Type: application/json' \
-H "Authorization: Bot $BOT_TOKEN" \
-d '{"name":"hello","description":"Greet a person","options":[{"name":"name","description":"The name of the person","type":3,"required":true}]}' \
"https://discord.com/api/v8/applications/$CLIENT_ID/commands"
```
This will register a Slash Command named `hello` that accepts a parameter named `name` of type string.
## Code
```ts index.ts
// Sift is a small routing library that abstracts away details like starting a
// listener on a port, and provides a simple function (serve) that has an API
// to invoke a function for a specific path.
import { json, serve, validateRequest } from 'https://deno.land/x/sift@0.6.0/mod.ts'
// TweetNaCl is a cryptography library that we use to verify requests
// from Discord.
import nacl from 'https://cdn.skypack.dev/tweetnacl@v1.0.3?dts'
enum DiscordCommandType {
Ping = 1,
ApplicationCommand = 2,
}
// For all requests to "/" endpoint, we want to invoke home() handler.
serve({
'/discord-bot': home,
})
// The main logic of the Discord Slash Command is defined in this function.
async function home(request: Request) {
// validateRequest() ensures that a request is of POST method and
// has the following headers.
const { error } = await validateRequest(request, {
POST: {
headers: ['X-Signature-Ed25519', 'X-Signature-Timestamp'],
},
})
if (error) {
return json({ error: error.message }, { status: error.status })
}
// verifySignature() verifies if the request is coming from Discord.
// When the request's signature is not valid, we return a 401 and this is
// important as Discord sends invalid requests to test our verification.
const { valid, body } = await verifySignature(request)
if (!valid) {
return json(
{ error: 'Invalid request' },
{
status: 401,
}
)
}
const { type = 0, data = { options: [] } } = JSON.parse(body)
// Discord performs Ping interactions to test our application.
// Type 1 in a request implies a Ping interaction.
if (type === DiscordCommandType.Ping) {
return json({
type: 1, // Type 1 in a response is a Pong interaction response type.
})
}
// Type 2 in a request is an ApplicationCommand interaction.
// It implies that a user has issued a command.
if (type === DiscordCommandType.ApplicationCommand) {
const { value } = data.options.find(
(option: { name: string; value: string }) => option.name === 'name'
)
return json({
// Type 4 responds with the below message retaining the user's
// input at the top.
type: 4,
data: {
content: `Hello, ${value}!`,
},
})
}
// We will return a bad request error as a valid Discord request
// shouldn't reach here.
return json({ error: 'bad request' }, { status: 400 })
}
/** Verify whether the request is coming from Discord. */
async function verifySignature(request: Request): Promise<{ valid: boolean; body: string }> {
const PUBLIC_KEY = Deno.env.get('DISCORD_PUBLIC_KEY')!
// Discord sends these headers with every request.
const signature = request.headers.get('X-Signature-Ed25519')!
const timestamp = request.headers.get('X-Signature-Timestamp')!
const body = await request.text()
const valid = nacl.sign.detached.verify(
new TextEncoder().encode(timestamp + body),
hexToUint8Array(signature),
hexToUint8Array(PUBLIC_KEY)
)
return { valid, body }
}
/** Converts a hexadecimal string to Uint8Array. */
function hexToUint8Array(hex: string) {
return new Uint8Array(hex.match(/.{1,2}/g)!.map((val) => parseInt(val, 16)))
}
```
## Deploy the slash command handler
```bash
supabase functions deploy discord-bot --no-verify-jwt
supabase secrets set DISCORD_PUBLIC_KEY=your_public_key
```
Navigate to your Function details in the Supabase Dashboard to get your Endpoint URL.
### Configure Discord application to use our URL as interactions endpoint URL
1. Go back to your application (Greeter) page on Discord Developer Portal
2. Fill **INTERACTIONS ENDPOINT URL** field with the URL and click on **Save Changes**.
The application is now ready. Let's proceed to the next section to install it.
## Install the slash command on your Discord server
So to use the `hello` Slash Command, we need to install our Greeter application on our Discord server. Here are the steps:
1. Go to **OAuth2** section of the Discord application page on Discord Developer Portal
2. Select `applications.commands` scope and click on the **Copy** button below.
3. Now paste and visit the URL on your browser. Select your server and click on **Authorize**.
Open Discord, type `/Promise` and press **Enter**.
## Run locally
```bash
supabase functions serve discord-bot --no-verify-jwt --env-file ./supabase/.env.local
ngrok http 54321
```
# Streaming Speech with ElevenLabs
Generate and stream speech through Supabase Edge Functions. Store speech in Supabase Storage and cache responses via built-in CDN.
## Introduction
In this tutorial you will learn how to build an edge API to generate, stream, store, and cache speech using Supabase Edge Functions, Supabase Storage, and [ElevenLabs text to speech API](https://elevenlabs.io/text-to-speech).
Find the [example project on GitHub](https://github.com/elevenlabs/elevenlabs-examples/tree/main/examples/text-to-speech/supabase/stream-and-cache-storage).
## Requirements
* An ElevenLabs account with an [API key](/app/settings/api-keys).
* A [Supabase](https://supabase.com) account (you can sign up for a free account via [database.new](https://database.new)).
* The [Supabase CLI](/docs/guides/local-development) installed on your machine.
* The [Deno runtime](https://docs.deno.com/runtime/getting_started/installation/) installed on your machine and optionally [setup in your favourite IDE](https://docs.deno.com/runtime/getting_started/setup_your_environment).
## Setup
### Create a Supabase project locally
After installing the [Supabase CLI](/docs/guides/local-development), run the following command to create a new Supabase project locally:
```bash
supabase init
```
### Configure the storage bucket
You can configure the Supabase CLI to automatically generate a storage bucket by adding this configuration in the `config.toml` file:
```toml ./supabase/config.toml
[storage.buckets.audio]
public = false
file_size_limit = "50MiB"
allowed_mime_types = ["audio/mp3"]
objects_path = "./audio"
```
Upon running `supabase start` this will create a new storage bucket in your local Supabase project. Should you want to push this to your hosted Supabase project, you can run `supabase seed buckets --linked`.
### Configure background tasks for Supabase Edge Functions
To use background tasks in Supabase Edge Functions when developing locally, you need to add the following configuration in the `config.toml` file:
```toml ./supabase/config.toml
[edge_runtime]
policy = "per_worker"
```
When running with `per_worker` policy, Function won't auto-reload on edits. You will need to manually restart it by running `supabase functions serve`.
### Create a Supabase Edge Function for speech generation
Create a new Edge Function by running the following command:
```bash
supabase functions new text-to-speech
```
If you're using VS Code or Cursor, select `y` when the CLI prompts "Generate VS Code settings for Deno? \[y/N]"!
### Set up the environment variables
Within the `supabase/functions` directory, create a new `.env` file and add the following variables:
```env supabase/functions/.env
# Find / create an API key at https://elevenlabs.io/app/settings/api-keys
ELEVENLABS_API_KEY=your_api_key
```
### Dependencies
The project uses a couple of dependencies:
* The [@supabase/supabase-js](/docs/reference/javascript) library to interact with the Supabase database.
* The ElevenLabs [JavaScript SDK](/docs/quickstart) to interact with the text-to-speech API.
* The open-source [object-hash](https://www.npmjs.com/package/object-hash) to generate a hash from the request parameters.
Since Supabase Edge Function uses the [Deno runtime](https://deno.land/), you don't need to install the dependencies, rather you can [import](https://docs.deno.com/examples/npm/) them via the `npm:` prefix.
## Code the Supabase Edge Function
In your newly created `supabase/functions/text-to-speech/index.ts` file, add the following code:
```ts supabase/functions/text-to-speech/index.ts
// Setup type definitions for built-in Supabase Runtime APIs
import 'jsr:@supabase/functions-js/edge-runtime.d.ts'
import { createClient } from 'npm:@supabase/supabase-js@2'
import { ElevenLabsClient } from 'npm:elevenlabs@1.52.0'
import * as hash from 'npm:object-hash'
const SUPABASE_SECRET_KEYS = JSON.parse(Deno.env.get('SUPABASE_SECRET_KEYS')!)
// If you want to use a different api key, change 'default' to your preferred key name
const supabase = createClient(Deno.env.get('SUPABASE_URL')!, SUPABASE_SECRET_KEYS['default'])
const client = new ElevenLabsClient({
apiKey: Deno.env.get('ELEVENLABS_API_KEY'),
})
// Upload audio to Supabase Storage in a background task
async function uploadAudioToStorage(stream: ReadableStream, requestHash: string) {
const { data, error } = await supabase.storage
.from('audio')
.upload(`${requestHash}.mp3`, stream, {
contentType: 'audio/mp3',
})
console.log('Storage upload result', { data, error })
}
Deno.serve(async (req) => {
// To secure your function for production, you can for example validate the request origin,
// or append a user access token and validate it with Supabase Auth.
console.log('Request origin', req.headers.get('host'))
const url = new URL(req.url)
const params = new URLSearchParams(url.search)
const text = params.get('text')
const voiceId = params.get('voiceId') ?? 'JBFqnCBsd6RMkjVDRZzb'
const requestHash = hash.MD5({ text, voiceId })
console.log('Request hash', requestHash)
// Check storage for existing audio file
const { data } = await supabase.storage.from('audio').createSignedUrl(`${requestHash}.mp3`, 60)
if (data) {
console.log('Audio file found in storage', data)
const storageRes = await fetch(data.signedUrl)
if (storageRes.ok) return storageRes
}
if (!text) {
return new Response(JSON.stringify({ error: 'Text parameter is required' }), {
status: 400,
headers: { 'Content-Type': 'application/json' },
})
}
try {
console.log('ElevenLabs API call')
const response = await client.textToSpeech.convertAsStream(voiceId, {
output_format: 'mp3_44100_128',
model_id: 'eleven_multilingual_v2',
text,
})
const stream = new ReadableStream({
async start(controller) {
for await (const chunk of response) {
controller.enqueue(chunk)
}
controller.close()
},
})
// Branch stream to Supabase Storage
const [browserStream, storageStream] = stream.tee()
// Upload to Supabase Storage in the background
EdgeRuntime.waitUntil(uploadAudioToStorage(storageStream, requestHash))
// Return the streaming response immediately
return new Response(browserStream, {
headers: {
'Content-Type': 'audio/mpeg',
},
})
} catch (error) {
console.log('error', { error })
return new Response(JSON.stringify({ error: error.message }), {
status: 500,
headers: { 'Content-Type': 'application/json' },
})
}
})
```
## Run locally
To run the function locally, run the following commands:
```bash
supabase start
```
Once the local Supabase stack is up and running, run the following command to start the function and observe the logs:
```bash
supabase functions serve
```
### Try it out
Navigate to `http://127.0.0.1:54321/functions/v1/text-to-speech?text=hello%20world` to hear the function in action.
Afterwards, navigate to `http://127.0.0.1:54323/project/default/storage/buckets/audio` to see the audio file in your local Supabase Storage bucket.
## Deploy to Supabase
If you haven't already, create a new Supabase account at [database.new](https://database.new) and link the local project to your Supabase account:
```bash
supabase link
```
Once done, run the following command to deploy the function:
```bash
supabase functions deploy
```
### Set the function secrets
Now that you have all your secrets set locally, you can run the following command to set the secrets in your Supabase project:
```bash
supabase secrets set --env-file supabase/functions/.env
```
## Test the function
The function is designed in a way that it can be used directly as a source for an `