Steps to improve query performance with indexes
Last edited: 6/29/2026
Optimizing your database#
This is an intermediate and actionable guide for Postgres optimization within the Supabase ecosystem.
Consider checking out Index_advisor and the performance advisor now available in the Dashboard!
Installing Supabase Grafana#
Supabase has an open-source Grafana Repo that displays real-time metrics of your database. Although the Observability Dashboard provides similar metrics, it averages the data by the hour or day. Having visibility over how your database responds to changes helps to ensure that the database is not stressed by the index-building process.
Visual of Grafana Dashboard
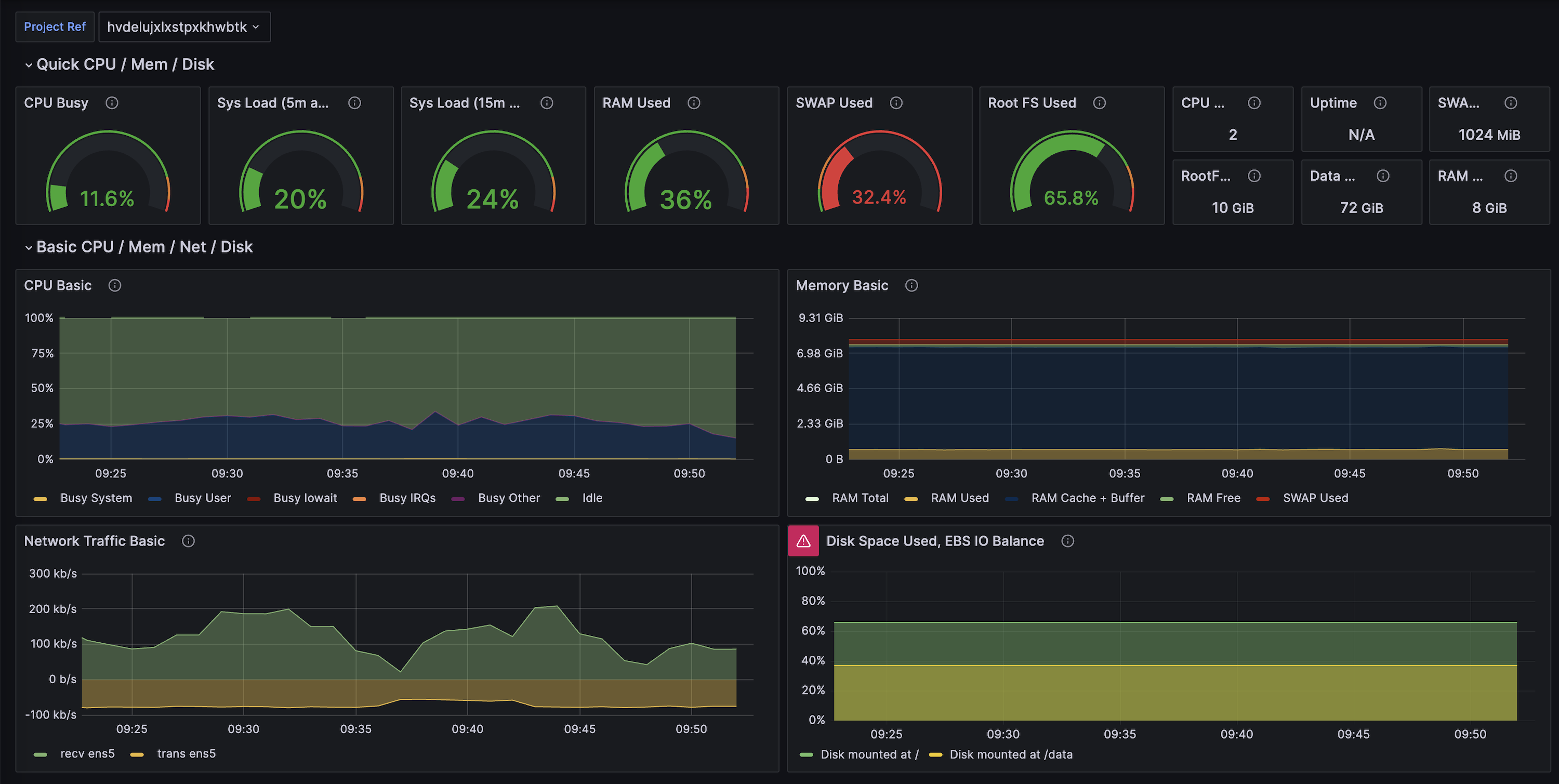
It can be run locally within Docker or can be deployed for free to fly.io. Installation instructions can be found in Supabase's metrics docs
Query optimization through indexes#
Disk (storage) is relatively slow compared to memory, so Postgres will take frequently accessed data and cache it in memory for fast access.
Ideally, you want the cache hit rate (cache-hits/total-hits) to be 99%. You should try to run the following query on your instance:
1select2 'index hit rate' as name,3 (sum(idx_blks_hit)) / nullif(sum(idx_blks_hit + idx_blks_read), 0) as ratio4from pg_statio_user_indexes5union all6select7 'table hit rate' as name,8 sum(heap_blks_hit) / nullif(sum(heap_blks_hit) + sum(heap_blks_read), 0) as ratio9from pg_statio_user_tables;If the cache hit rate is relatively low, it often means that you need to increase your memory capacity. The second metric that is often inspected is index usage. Indexes are data structures that allow Postgres to search for information efficiently - think of them like you would think of an index at the back of a book. Instead of scanning every page (or row), you can use an index to find the contents you need efficiently. For a better understanding of how Postgres decides on whether to use an index or not, check out this explainer.
The index hit rate (how often an index is used) can usually be improved moderately.
There's a query to find out how often an index is used when accessing a table:
1select2 relname,3 100 * idx_scan / (seq_scan + idx_scan) as percent_of_times_index_used,4 n_live_tup as rows_in_table5from pg_stat_user_tables6where seq_scan + idx_scan > 07order by n_live_tup desc;A lot of the queries for inspecting performance are pre-bundled as part of the Supabase CLI. For instance, there is a command for testing which indexes of yours are unnecessary and are needlessly taking up space:
1npx supabase login23npx supabase link45npx supabase inspect db unused-indexesThere is an extension called index_advisor that creates virtual indexes on your queries and then checks which ones increase performance the best. Unlike normal index creation, virtual indexes can be made rapidly, which makes uncovering the most performant solutions fast. The Query Performance Advisor in the Dashboard is configured to use index_advisor to make optimization suggestions and you should check it out to see where you can improve.
Index_advisor won't test indexes added through extensions nor will it test GIN/GIST indexes. For JSON or ARRAY columns, consider exploring GIN/GIST indexes separately from index_advisor. If you're using pg_vector, it's crucial to use an HSNW index.
Indexes can significantly speed up reads, sometimes boosting performance by 100 times. However, they come with a trade-off: they need to track all column changes, which can slow down data-modifying queries like UPDATEs, DELETEs, and INSERTs.
Generally, indexes offer more benefits. For example, primary key columns automatically have a B-Tree index, enhancing read and join operations without significantly affecting write queries. Nonetheless, it's wise to avoid carelessly adding indexes.
Some indexes may take a long time to build. A guide was written for applying HSNW indexes, but it can be generalized and referenced for applying others, too.
When building an index, the affected table is locked, preventing write operations. If this poses an issue, use the CONCURRENTLY modifier. However, reserve this for necessary cases only, as it entails building the index twice, prolonging the process and increasing computational costs.