Choosing your Compute Add-on
Choosing the right Compute Add-on for your vector workload.
You have two options for scaling your vector workload:
- Increase the size of your database. This guide will help you choose the right size for your workload.
- Spread your workload across multiple databases. You can find more details about this approach in Engineering for Scale.
Dimensionality#
The number of dimensions in your embeddings is the most important factor in choosing the right Compute Add-on. In general, the lower the dimensionality the better the performance. We've provided guidance for some of the more common embedding dimensions below. For each benchmark, we used Vecs to create a collection, upload the embeddings to a single table, and create both the IVFFlat and HNSW indexes for inner-product distance measure for the embedding column. We then ran a series of queries to measure the performance of different compute add-ons:
HNSW#
384 dimensions #
This benchmark uses the dbpedia-entities-openai-1M dataset containing 1,000,000 embeddings of text, regenerated for 384 dimension embeddings. Each embedding is generated using gte-small.
| Compute Size | Vectors | m | ef_construction | ef_search | QPS | Latency Mean | Latency p95 | RAM Usage | RAM |
|---|---|---|---|---|---|---|---|---|---|
| Micro | 100,000 | 16 | 64 | 60 | 580 | 0.017 sec | 0.024 sec | 1.2 (Swap) | 1 GB |
| Small | 250,000 | 24 | 64 | 60 | 440 | 0.022 sec | 0.033 sec | 2 GB | 2 GB |
| Medium | 500,000 | 24 | 64 | 80 | 350 | 0.028 sec | 0.045 sec | 4 GB | 4 GB |
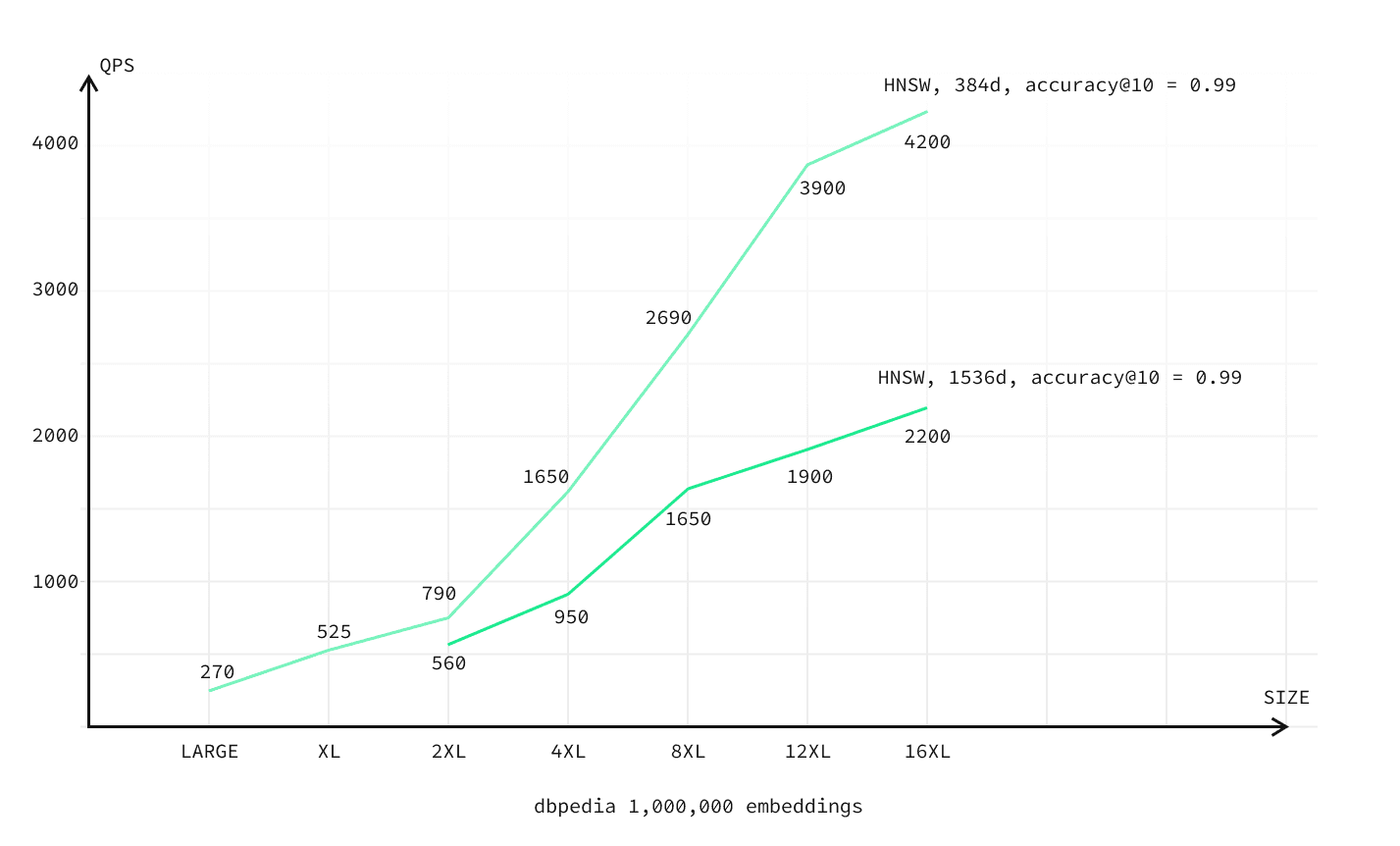
| Large | 1,000,000 | 32 | 80 | 100 | 270 | 0.073 sec | 0.108 sec | 7 GB | 8 GB |
| XL | 1,000,000 | 32 | 80 | 100 | 525 | 0.038 sec | 0.059 sec | 9 GB | 16 GB |
| 2XL | 1,000,000 | 32 | 80 | 100 | 790 | 0.025 sec | 0.037 sec | 9 GB | 32 GB |
| 4XL | 1,000,000 | 32 | 80 | 100 | 1650 | 0.015 sec | 0.018 sec | 11 GB | 64 GB |
| 8XL | 1,000,000 | 32 | 80 | 100 | 2690 | 0.015 sec | 0.016 sec | 13 GB | 128 GB |
| 12XL | 1,000,000 | 32 | 80 | 100 | 3900 | 0.014 sec | 0.016 sec | 13 GB | 192 GB |
| 16XL | 1,000,000 | 32 | 80 | 100 | 4200 | 0.014 sec | 0.016 sec | 20 GB | 256 GB |
Accuracy was 0.99 for benchmarks.
960 dimensions #
This benchmark uses the gist-960 dataset, which contains 1,000,000 embeddings of images. Each embedding is 960 dimensions.
| Compute Size | Vectors | m | ef_construction | ef_search | QPS | Latency Mean | Latency p95 | RAM Usage | RAM |
|---|---|---|---|---|---|---|---|---|---|
| Micro | 30,000 | 16 | 64 | 65 | 430 | 0.024 sec | 0.034 sec | 1.2 GB (Swap) | 1 GB |
| Small | 100,000 | 32 | 80 | 60 | 260 | 0.040 sec | 0.054 sec | 2.2 GB (Swap) | 2 GB |
| Medium | 250,000 | 32 | 80 | 90 | 120 | 0.083 sec | 0.106 sec | 4 GB | 4 GB |
| Large | 500,000 | 32 | 80 | 120 | 160 | 0.063 sec | 0.087 sec | 7 GB | 8 GB |
| XL | 1,000,000 | 32 | 80 | 200 | 200 | 0.049 sec | 0.072 sec | 13 GB | 16 GB |
| 2XL | 1,000,000 | 32 | 80 | 200 | 340 | 0.025 sec | 0.029 sec | 17 GB | 32 GB |
| 4XL | 1,000,000 | 32 | 80 | 200 | 630 | 0.031 sec | 0.050 sec | 18 GB | 64 GB |
| 8XL | 1,000,000 | 32 | 80 | 200 | 1100 | 0.034 sec | 0.048 sec | 19 GB | 128 GB |
| 12XL | 1,000,000 | 32 | 80 | 200 | 1420 | 0.041 sec | 0.095 sec | 21 GB | 192 GB |
| 16XL | 1,000,000 | 32 | 80 | 200 | 1650 | 0.037 sec | 0.081 sec | 23 GB | 256 GB |
Accuracy was 0.99 for benchmarks.
QPS can also be improved by increasing m and ef_construction. This will allow you to use a smaller value for ef_search and increase QPS.
1536 dimensions #
This benchmark uses the dbpedia-entities-openai-1M dataset, which contains 1,000,000 embeddings of text. And 224,482 embeddings from Wikipedia articles for compute add-ons large and below. Each embedding is 1536 dimensions created with the OpenAI Embeddings API.
| Compute Size | Vectors | m | ef_construction | ef_search | QPS | Latency Mean | Latency p95 | RAM Usage | RAM |
|---|---|---|---|---|---|---|---|---|---|
| Micro | 15,000 | 16 | 40 | 40 | 480 | 0.011 sec | 0.016 sec | 1.2 GB (Swap) | 1 GB |
| Small | 50,000 | 32 | 64 | 100 | 175 | 0.031 sec | 0.051 sec | 2.2 GB (Swap) | 2 GB |
| Medium | 100,000 | 32 | 64 | 100 | 240 | 0.083 sec | 0.126 sec | 4 GB | 4 GB |
| Large | 224,482 | 32 | 64 | 100 | 280 | 0.017 sec | 0.028 sec | 8 GB | 8 GB |
| XL | 500,000 | 24 | 56 | 100 | 360 | 0.055 sec | 0.135 sec | 13 GB | 16 GB |
| 2XL | 1,000,000 | 24 | 56 | 250 | 560 | 0.036 sec | 0.058 sec | 32 GB | 32 GB |
| 4XL | 1,000,000 | 24 | 56 | 250 | 950 | 0.021 sec | 0.033 sec | 39 GB | 64 GB |
| 8XL | 1,000,000 | 24 | 56 | 250 | 1650 | 0.016 sec | 0.023 sec | 40 GB | 128 GB |
| 12XL | 1,000,000 | 24 | 56 | 250 | 1900 | 0.015 sec | 0.021 sec | 38 GB | 192 GB |
| 16XL | 1,000,000 | 24 | 56 | 250 | 2200 | 0.015 sec | 0.020 sec | 40 GB | 256 GB |
Accuracy was 0.99 for benchmarks.
QPS can also be improved by increasing m and ef_construction. This will allow you to use a smaller value for ef_search and increase QPS. For example, increasing m to 32 and ef_construction to 80 for 4XL will increase QPS to 1280.
It is possible to upload more vectors to a single table if Memory allows it (for example, 4XL plan and higher for OpenAI embeddings). But it will affect the performance of the queries: QPS will be lower, and latency will be higher. Scaling should be almost linear, but it is recommended to benchmark your workload to find the optimal number of vectors per table and per database instance.
The chart below compares HNSW queries-per-second across compute sizes for different embedding dimensions.
IVFFlat#
384 dimensions #
This benchmark uses the dbpedia-entities-openai-1M dataset containing 1,000,000 embeddings of text, regenerated for 384 dimension embeddings. Each embedding is generated using gte-small.
| Compute Size | Vectors | Lists | Probes | QPS | Latency Mean | Latency p95 | RAM Usage | RAM |
|---|---|---|---|---|---|---|---|---|
| Micro | 100,000 | 500 | 50 | 205 | 0.048 sec | 0.066 sec | 1.2 GB (Swap) | 1 GB |
| Small | 250,000 | 1000 | 60 | 160 | 0.062 sec | 0.079 sec | 2 GB | 2 GB |
| Medium | 500,000 | 2000 | 80 | 120 | 0.082 sec | 0.104 sec | 3.2 GB | 4 GB |
| Large | 1,000,000 | 5000 | 150 | 75 | 0.269 sec | 0.375 sec | 6.5 GB | 8 GB |
| XL | 1,000,000 | 5000 | 150 | 150 | 0.131 sec | 0.178 sec | 9 GB | 16 GB |
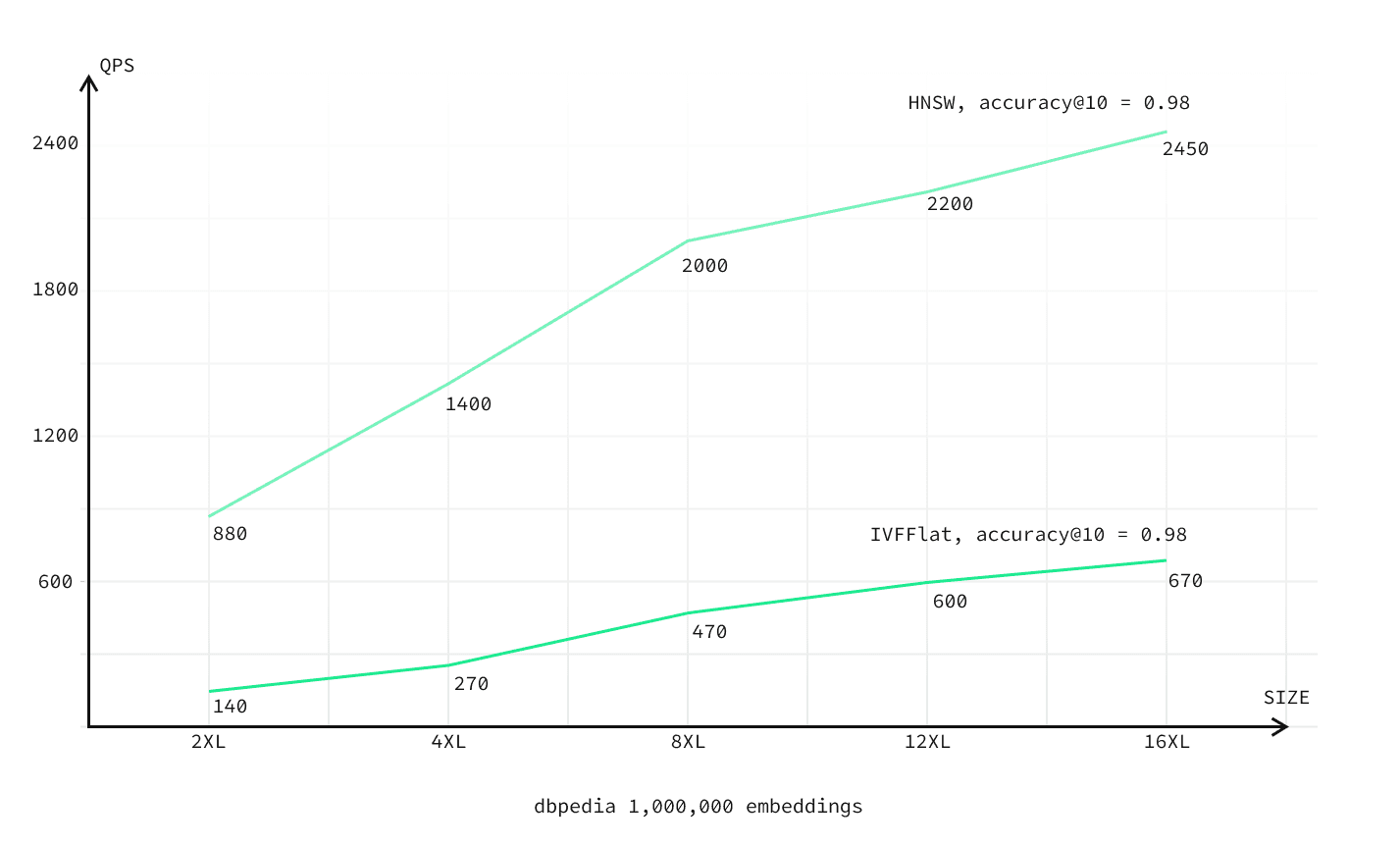
| 2XL | 1,000,000 | 5000 | 150 | 300 | 0.066 sec | 0.099 sec | 10 GB | 32 GB |
| 4XL | 1,000,000 | 5000 | 150 | 570 | 0.035 sec | 0.046 sec | 10 GB | 64 GB |
| 8XL | 1,000,000 | 5000 | 150 | 1400 | 0.023 sec | 0.028 sec | 12 GB | 128 GB |
| 12XL | 1,000,000 | 5000 | 150 | 1550 | 0.030 sec | 0.039 sec | 12 GB | 192 GB |
| 16XL | 1,000,000 | 5000 | 150 | 1800 | 0.030 sec | 0.039 sec | 16 GB | 256 GB |
960 dimensions #
This benchmark uses the gist-960 dataset, which contains 1,000,000 embeddings of images. Each embedding is 960 dimensions.
| Compute Size | Vectors | Lists | QPS | Latency Mean | Latency p95 | RAM Usage | RAM |
|---|---|---|---|---|---|---|---|
| Micro | 30,000 | 30 | 75 | 0.065 sec | 0.088 sec | 1.1 GB (Swap) | 1 GB |
| Small | 100,000 | 100 | 78 | 0.064 sec | 0.092 sec | 1.8 GB | 2 GB |
| Medium | 250,000 | 250 | 58 | 0.085 sec | 0.129 sec | 3.2 GB | 4 GB |
| Large | 500,000 | 500 | 55 | 0.088 sec | 0.140 sec | 5 GB | 8 GB |
| XL | 1,000,000 | 1000 | 110 | 0.046 sec | 0.070 sec | 14 GB | 16 GB |
| 2XL | 1,000,000 | 1000 | 235 | 0.083 sec | 0.136 sec | 10 GB | 32 GB |
| 4XL | 1,000,000 | 1000 | 420 | 0.071 sec | 0.106 sec | 11 GB | 64 GB |
| 8XL | 1,000,000 | 1000 | 815 | 0.072 sec | 0.106 sec | 13 GB | 128 GB |
| 12XL | 1,000,000 | 1000 | 1150 | 0.052 sec | 0.078 sec | 15.5 GB | 192 GB |
| 16XL | 1,000,000 | 1000 | 1345 | 0.072 sec | 0.106 sec | 17.5 GB | 256 GB |
1536 dimensions #
This benchmark uses the dbpedia-entities-openai-1M dataset, which contains 1,000,000 embeddings of text. Each embedding is 1536 dimensions created with the OpenAI Embeddings API.
| Compute Size | Vectors | Lists | QPS | Latency Mean | Latency p95 | RAM Usage | RAM |
|---|---|---|---|---|---|---|---|
| Micro | 20,000 | 40 | 135 | 0.372 sec | 0.412 sec | 1.2 GB (Swap) | 1 GB |
| Small | 50,000 | 100 | 140 | 0.357 sec | 0.398 sec | 1.8 GB | 2 GB |
| Medium | 100,000 | 200 | 130 | 0.383 sec | 0.446 sec | 3.7 GB | 4 GB |
| Large | 250,000 | 500 | 130 | 0.378 sec | 0.434 sec | 7 GB | 8 GB |
| XL | 500,000 | 1000 | 235 | 0.213 sec | 0.271 sec | 13.5 GB | 16 GB |
| 2XL | 1,000,000 | 2000 | 380 | 0.133 sec | 0.236 sec | 30 GB | 32 GB |
| 4XL | 1,000,000 | 2000 | 720 | 0.068 sec | 0.120 sec | 35 GB | 64 GB |
| 8XL | 1,000,000 | 2000 | 1250 | 0.039 sec | 0.066 sec | 38 GB | 128 GB |
| 12XL | 1,000,000 | 2000 | 1600 | 0.030 sec | 0.052 sec | 41 GB | 192 GB |
| 16XL | 1,000,000 | 2000 | 1790 | 0.029 sec | 0.051 sec | 45 GB | 256 GB |
For 1,000,000 vectors 10 probes results to accuracy of 0.91. And for 500,000 vectors and below 10 probes results to accuracy in the range of 0.95 - 0.99. To increase accuracy, you need to increase the number of probes.
The chart below plots requests-per-second against compute size.
It is possible to upload more vectors to a single table if Memory allows it (for example, 4XL plan and higher for OpenAI embeddings). But it will affect the performance of the queries: QPS will be lower, and latency will be higher. Scaling should be almost linear, but it is recommended to benchmark your workload to find the optimal number of vectors per table and per database instance.
Performance tips#
There are various ways to improve your pgvector performance. Here are some tips:
Pre-warming your database#
It's useful to execute a few thousand “warm-up” queries before going into production. This helps help with RAM utilization. This can also help to determine that you've selected the right compute size for your workload.
Fine-tune index parameters#
You can increase the Requests per Second by increasing m and ef_construction or lists. This also has an important caveat: building the index takes longer with higher values for these parameters.
The chart below shows how the HNSW build parameters m and ef_construction affect requests-per-second on the dbpedia dataset.

Check out more tips and the complete step-by-step guide in Going to Production for AI applications.
Benchmark methodology#
We follow techniques outlined in the ANN Benchmarks methodology. A Python test runner is responsible for uploading the data, creating the index, and running the queries. The pgvector engine is implemented using vecs, a Python client for pgvector.
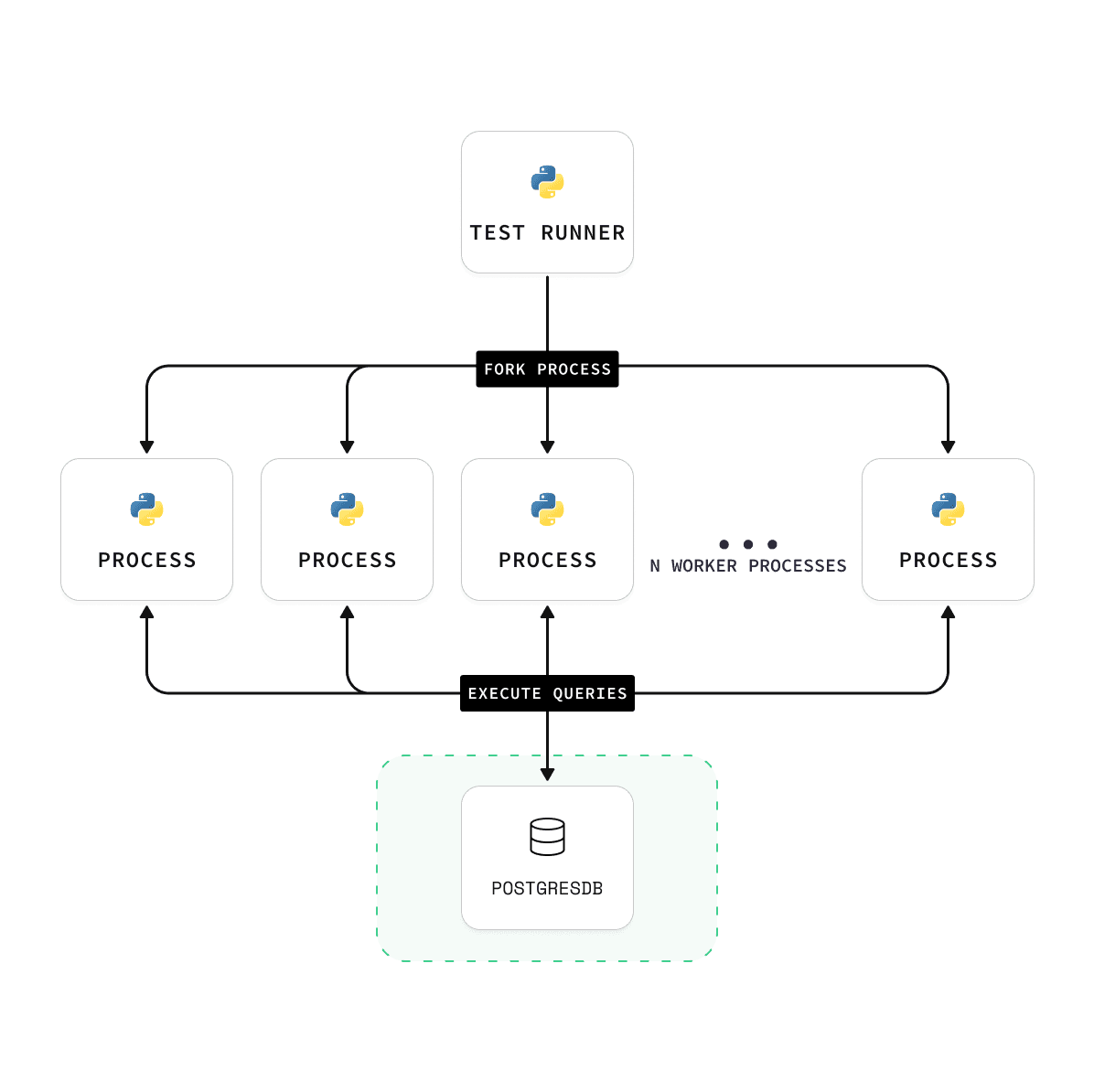
The diagram above shows the vecs benchmark setup: a Python test runner uploads data, builds the index, and runs queries against pgvector.
Each test is run for a minimum of 30-40 minutes. They include a series of experiments executed at different concurrency levels to measure the engine's performance under different load types. The results are then averaged.
As a general recommendation, we suggest using a concurrency level of 5 or more for most workloads and 30 or more for high-load workloads.