Engineering for Scale
Building an enterprise-grade vector architecture.
Content sources for vectors can be extremely large. As you grow you should run your Vector workloads across several secondary databases (sometimes called "pods"), which allows each collection to scale independently.
Small workloads #
For small workloads, you can typically store your data in a single database.
If you've used Vecs to create 3 different collections, you can expose collections to your web or mobile application using views:
The diagram below shows a single database holding the three vector collections of docs, posts, and images. Each are exposed to your application through a view.
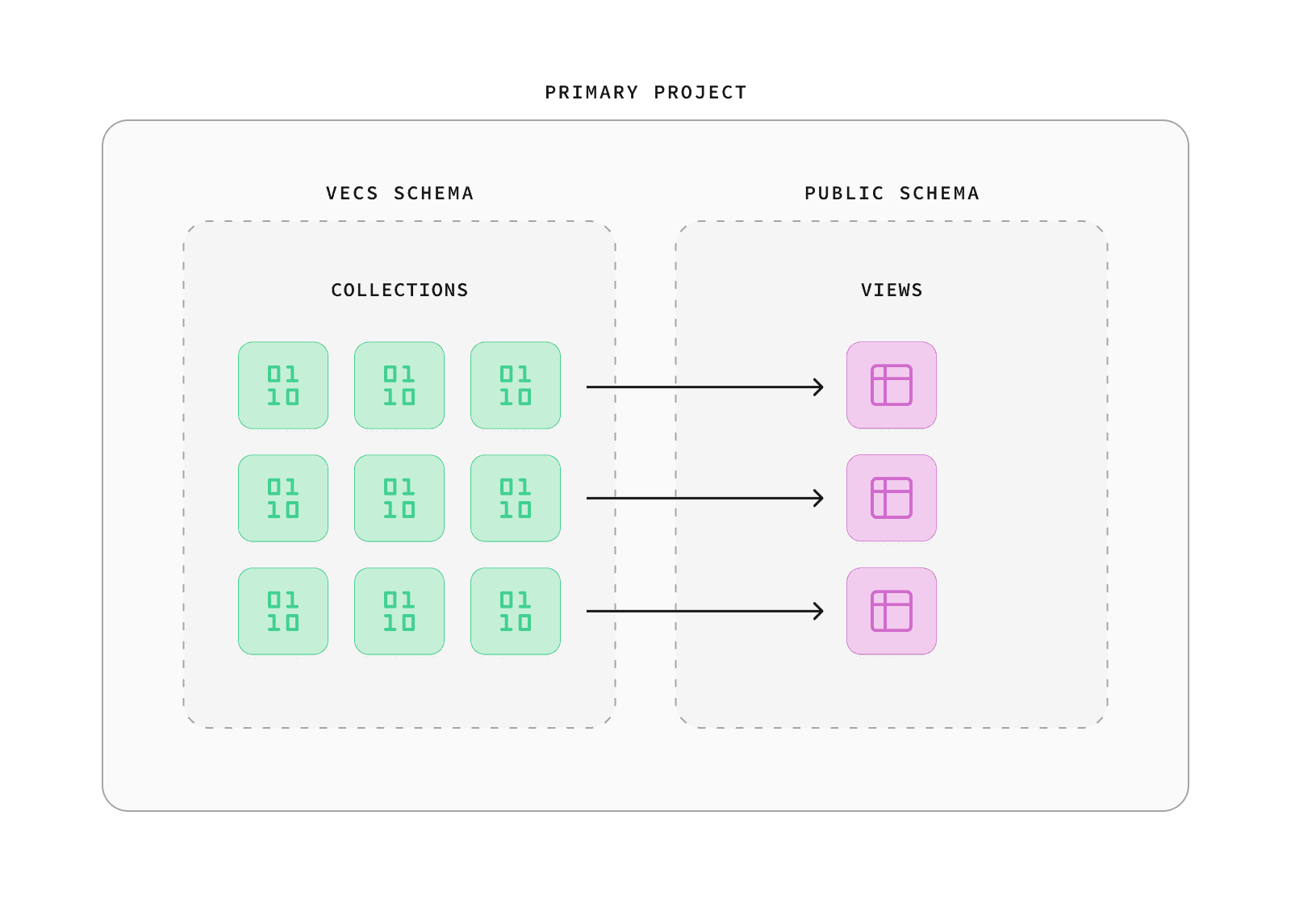
For example, with 3 collections, called docs, posts, and images, we could expose the "docs" inside the public schema like this:
1create view public.docs as2select3 id,4 embedding,5 metadata, # Expose the metadata as JSON6 (metadata->>'url')::text as url # Extract the URL as a string7from vectorYou can then use any of the client libraries to access your collections within your applications:
1const { data, error } = await supabase2 .from('docs')3 .select('id, embedding, metadata')4 .eq('url', '/hello-world')Enterprise workloads#
As you move into production, we recommend splitting your collections into separate projects. This is because it allows your vector stores to scale independently of your production data. Vectors typically grow faster than operational data, and they have different resource requirements. Running them on separate databases removes the single-point-of-failure.
The diagram below shows a primary database alongside separate secondary "pod" databases, each holding its own vector collection so they can scale independently.
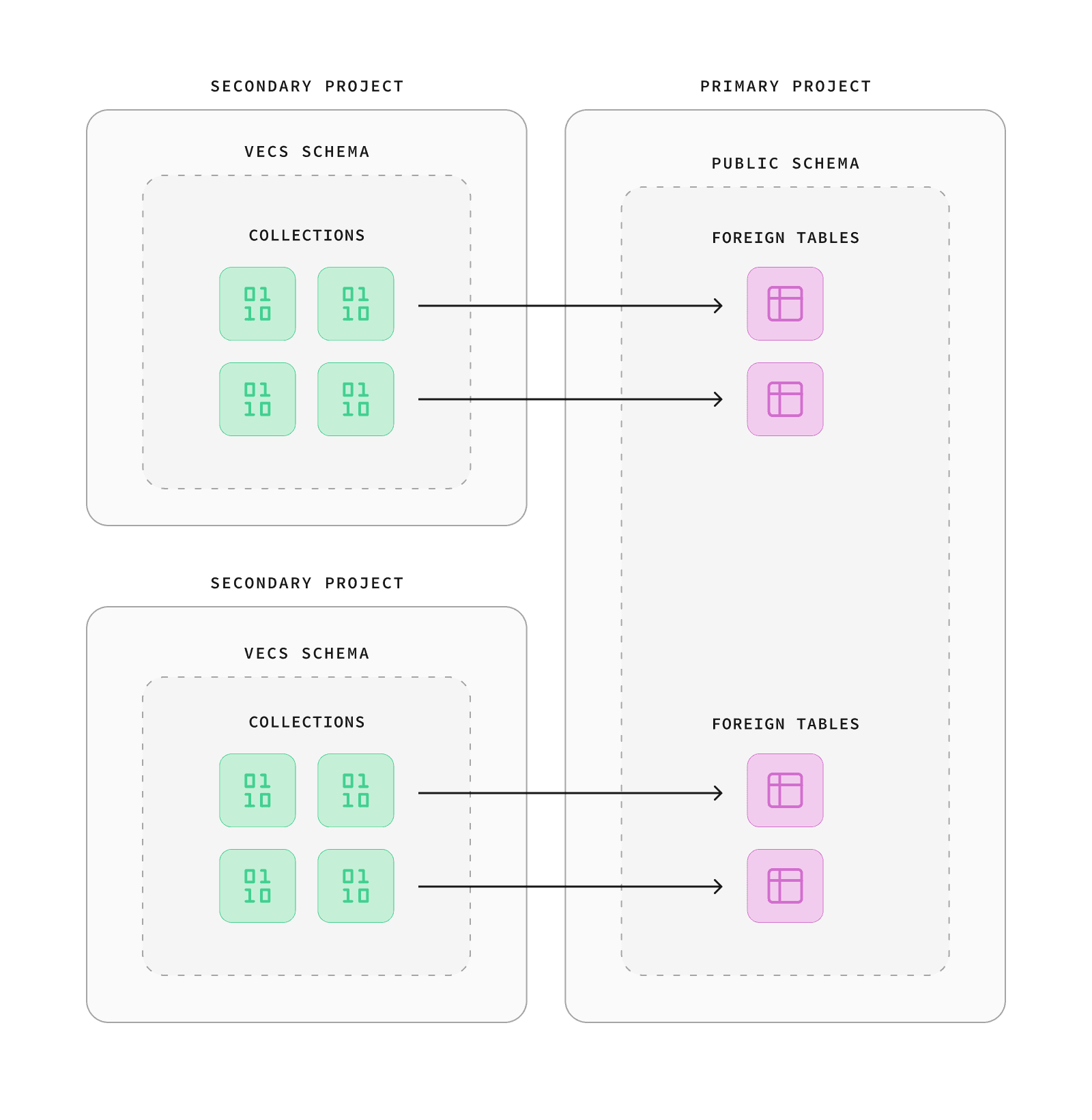
You can use as many secondary databases as you need to manage your collections. With this architecture, you have 2 options for accessing collections within your application:
- Query the collections directly using Vecs.
- Access the collections from your Primary database through a Wrapper.
You can use both of these in tandem to suit your use-case. We recommend option 1 wherever possible, as it offers the most scalability.
Query collections using Vecs#
Vecs provides methods for querying collections, either using a cosine similarity function or with metadata filtering.
1# cosine similarity2docs.query(query_vector=[0.4,0.5,0.6], limit=5)34# metadata filtering5docs.query(6 query_vector=[0.4,0.5,0.6],7 limit=5,8 filters={"year": {"$eq": 2012}}, # metadata filters9)Accessing external collections using Wrappers#
Supabase supports Foreign Data Wrappers. Wrappers allow you to connect two databases together so that you can query them over the network.
This involves 2 steps: connecting to your remote database from the primary and creating a Foreign Table.
Connecting your remote database#
Inside your Primary database we need to provide the credentials to access the secondary database:
1create extension postgres_fdw;23create server docs_server4foreign data wrapper postgres_fdw5options (host 'db.xxx.supabase.co', port '5432', dbname 'postgres');67create user mapping for docs_user8server docs_server9options (user 'postgres', password 'password');Create a foreign table#
We can now create a foreign table to access the data in our secondary project.
1create foreign table docs (2 id text not null,3 embedding extensions.vector(384),4 metadata jsonb,5 url text6)7server docs_server8options (schema_name 'public', table_name 'docs');This looks very similar to our View example above, and you can continue to use the client libraries to access your collections through the foreign table:
1const { data, error } = await supabase2 .from('docs')3 .select('id, embedding, metadata')4 .eq('url', '/hello-world')Enterprise architecture#
This diagram below provides an example architecture that allows you to access the collections either with our client libraries or using Vecs. You can add as many secondary databases as you need (in this example we only show one):
