🆕 Want to build your own Clippy based on your own content? Use our Next.js OpenAI Doc Search Template to deploy your own now!
We all know that Microsoft's real agenda for pouring billions into OpenAI is to revive their favorite friend Clippy. Today, we're doing our part to support the momentum by releasing “Supabase Clippy” for our docs (and we don't expect this name to last long before the lawyers catch on).
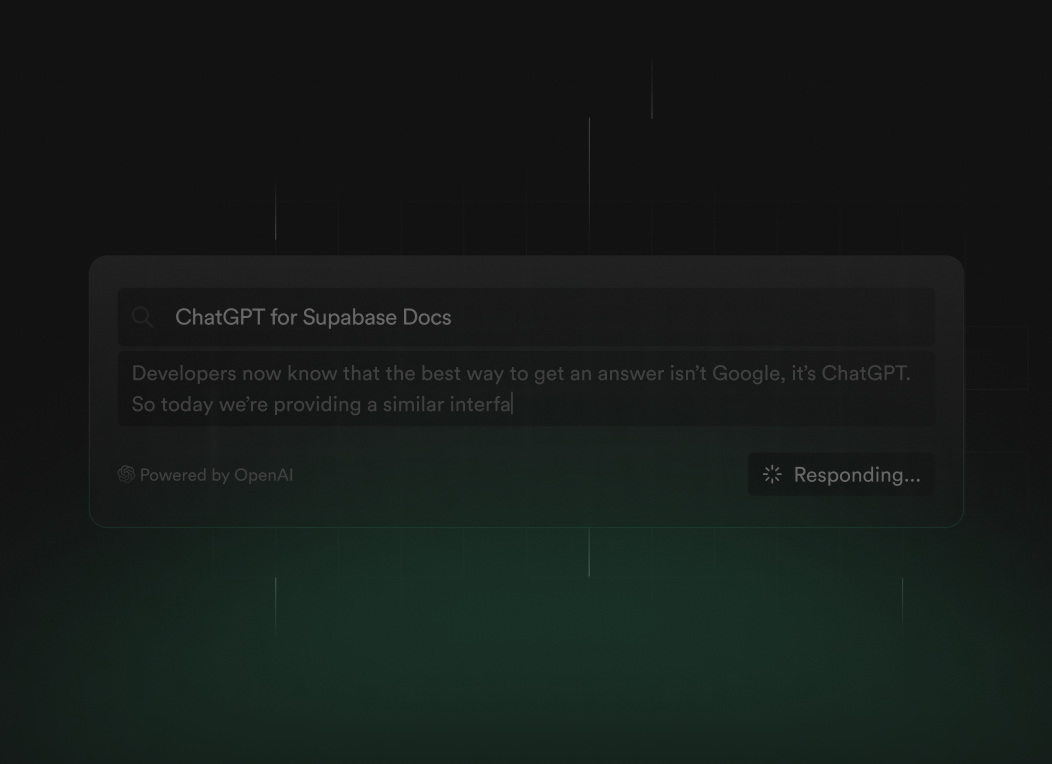
Want to try it out? It's a hidden feature while in MVP - visit supabase.com/docs and hit cmd + / to pull up the search box (sorry mobile users).
ChatGPT for Supabase Docs
Last launch week we released our new documentation site to improve the developer experience, especially for new users.
When we first started Supabase our docs were very concise. We deliberately withheld "non-critical information" so that developers could consume everything in one sitting.
Our product suite has grown in the past 2 years and our docs have grown as a result. There's a lot to read. We're also attracting developers who've never used Postgres before, and it's becoming incumbent on us to train these developers on best-practices.
The “ask” interface
Developers have recently gained the ability to trust a bot. Where Clippy failed, ChatGPT succeeded.
This is convenient timing for us, since our documentation content is more than the average developer wants to consume in one go. Today we're providing a similar interface to ChatGPT which is trained on our own docs.
To keep your expectations low, this implementation is a 1-week MVP. We're sharing this iteration to gather feedback and to teach you how to build something similar.
How it's built
It's built with Supabase/Postgres, and consists of several key parts:
- Parsing the Supabase docs into sections.
- Creating embeddings for each section using OpenAI's embeddings API.
- Storing the embeddings in Postgres using the pgvector extension.
- Getting a user's question.
- Query the Postgres database for the most relevant documents related to the question.
- Inject these documents as context for GPT-3 to reference in its answer.
- Streaming the results back to the user in realtime.
All the changes we made are in this Pull Request. Greg is here to explain every step in full detail:
You can find a full write up in our previous blog post: Storing OpenAI embeddings in Postgres with pgvector.
What's next
This current version is very basic, which makes it a good starting point if you want to build something similar.
- Expand the knowledge base: Create embeddings for our reference docs, GitHub Discussions, Discord discussions, etc. The current iteration is only using the Guides.
- Caching: Cache queries so that we can provide answers instantly to similar/matching questions.
- User-assisted improvements: Ability to thumbs-up responses for relevance.
- Beyond search: perhaps we can make this interface interactive, guiding users through instructions.
Bonus: The power of open source
One of the most interesting things about this feature was how it happened - almost completely from open source contributions. A short series of events:
A friendly email
A few weeks ago I received an email, drawing our attention to a Pull Request in our postgres GitHub repo:
A friendly chat
After we merged the PR, I reached out to see if Greg was interested in helping with some documentation or a blog post to help the community to use pgvector. On the call, Greg surprised me with an initial prototype where he had ingested the Supabase docs for a ChatGPT-like experience. I was suitably impressed and suggested that we could explore ways to work together to build it into the Supabase docs. He wasted no time:
A friendly collaboration
We sponsored Greg to work on an MVP with us, along with some guides to help developers do the same. He pushed all his changes to the Supabase Docs, and we wrote a blog post together to help developers build something similar.
If you re-read the events above and swap “Supabase” for any other big-tech company, you'll grasp how impossible this series of events is for any company that's not open source. All the code that was contributed is licensed liberally, so we didn't need to jump through IP checklists. Our docs are publicly available on GitHub, so Greg could build his prototype without being granted access.
We're incredibly grateful for Greg's work here, so if you like what he's done then consider supporting him by checking out prmpts.ai and following him on twitter: @ggrdson.
While you're at it, consider supporting @ankane's great work on pgvector by starring them on GitHub, and sending your thanks.
Try it out
Want to try Supabase Clippy? It's a hidden feature while in MVP - visit supabase.com/docs and hit cmd + / to pull up the search box (sorry mobile users).