Supabase offers a supercharged Postgres instance, along with a set of complementary services, making it easy to build mobile and web applications. Today, we're exposing a full set of metrics in your projects, so that you can build better (and faster) products for your users.
Reports page#
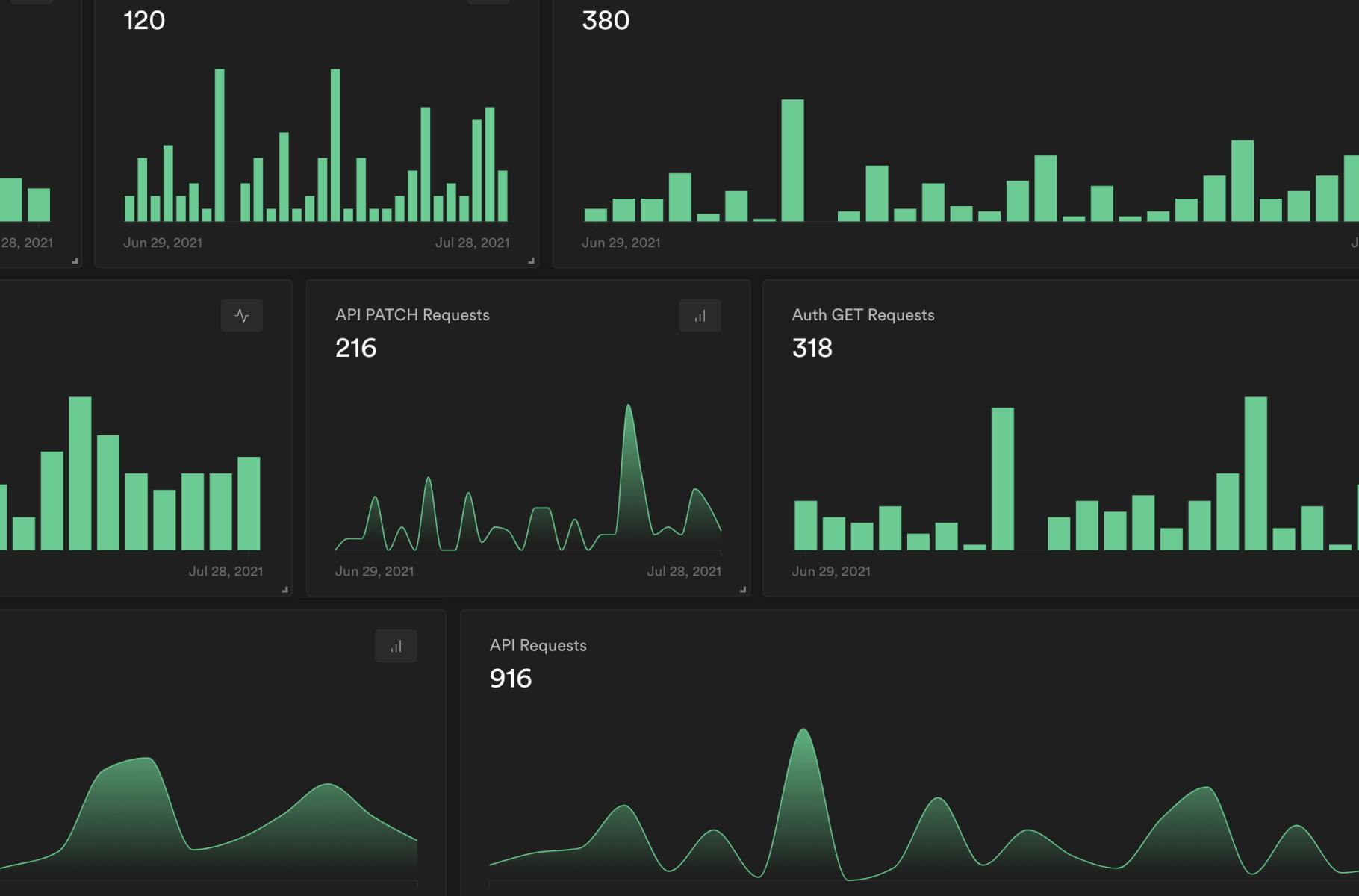
We've added a new "Reports" section to the Dashboard. You can view one month of data, including API requests across all of Supabase's core pillars: Database, Auth and Storage. We've included two instance health metrics, CPU usage and Memory usage, with a lot more on the way.
All charts are built with Recharts, an MIT-licensed React chart library chosen for its ease of use. We'll add customizable charts in the future, so we'd love to hear which libraries you'd like to see in Supabase.
We support one configurable report per project, accessible and editable by all team members. In the next few weeks, we'll expand to unlimited reports, with longer date range options, new layout configurations, report templates, stacked charts and private/public visibility across your project's members.
New project home page#
Every project has a new home page with a weekly overview of important metrics. We've included usage bars for Database storage, number of Auth users, and Storage space.
And we're just getting warmed up. Over the next few months you'll see more project information, notifications, and highlights to monitor your project health at a glance.
Observability metrics#
Backend as a Service? Infrastructure as a Service? We don't care about the label, but we do care about giving developers the relevant observability metrics. Supabase gives you a full Postgres cluster for every project, and now we give you the tools to diagnose and manage important infrastructure anomalies.
All databases are now launched with pg_stat_statements enabled, so you can expect some useful query statistics in the future too.
Building a metrics pipeline#
"If you can't measure it, you can't improve it."
Full control, full responsibility#
When developers build services and applications on top of Supabase, relying on the platform's reliability and performance. Product observability is critical, as it allows developers to make decisions on where to spend their optimization dollars, and to get ahead of possible issues before they become showstoppers.
At Supabase, each project is provisioned with a Postgres cluster, and a suite of associated services that add, ahem, supa-powers to the database.
Our users get liberal access to each of these services - you can use PostgREST for a RESTful API, Realtime to listen to changes in your Postgres instance, or even just open a raw connection to the database. While this makes for an extremely flexible offering, it presents a diverse cast of foot-guns. Want to mess with Realtime? Why not bulk-insert millions of records on tables you've configured it to watch? Feel like taking out your entire database? Just connect to it and run a wildly inefficient query!
We're continuously rolling out protections to mitigate failure scenarios and to minimize the blast radius. However, given the power and flexibility exposed via our services and the diverse workloads they support, our users remain best positioned to make the call on what's reasonable for their project. As such, we're also working on exposing as much data as possible to them.
Gathering relevant metrics#
Given the setup described above, there are two major categories of metrics that we care about. There are metrics pertinent to the services mentioned ("Project Metrics") that get spun up for each project (e.g. the number of active connections to the db), and there are metrics for the underlying infrastructure (e.g. system health). Most of the time, our users shouldn't have to care about the latter, though the nature of leaky abstractions dictates that sometimes they become relevant to Project Metrics as well.
In order to build a comprehensive view of the project's health, each service needs to be instrumented along with its underlying infrastructure. We're looking at hundreds of thousands of targets at our current scale (likely approaching millions in the near future) each of them presenting hundreds of metrics of interest (every minute!).
To buy ourselves some headroom, we built a federated approach: we run instances of our monitoring systems in each geographical region we operate in. This provides a natural dimension for sharding, while reducing the latency for everyone. We run Prometheus out of inertia, soon to be VictoriaMetrics. The monitoring instances scrape data from a number of exporters that are bundled into each of our projects. A small subset of the metrics collected gets aggregated to a centralized VictoriaMetrics instance for easier cohort analysis.
Available sources and metrics#
To start with, we're focusing on metrics a few of the most pertinent metrics:
- Database metrics: CPU and RAM usage
- API Requests: Ingress, Egress,
GET,POST,PATCH,PUT,OPTIONS, and all requests. - Storage Requests: Ingress, Egress,
GET,POST,PATCH,PUT,OPTIONS, and all requests. - Auth Requests: Ingress, Egress,
GET,POST,PATCH,PUT,OPTIONS, and all requests.
What's next?#
Where to begin?
- Multiple reports per project: we've started with just one report per project, but in the next few weeks we'll allow you to create as many as you want.
- More metrics: we're just getting started.
- Number of active connections to your database.
- Various detailed stats from
pg_stat_statements,pg_stat_bgwriter,pg_stat_database,pg_stat_database_conflicts. - System level metrics like CPU, memory and disk utilization.
- Granularity: project statistics will come down to hourly.
- Longer time periods: view historical data going back several months.
- Interactive widgets: view-only reports are fine, but we wouldn't be a Postgres company if we didn't allow you to write your own SQL queries.
Any other metrics you want to see in your projects? Reach out on our Discord channel and give Supabase a try by creating a project.