🆕 Storage has undergone significant enhancements with two major releases since its initial launch. Here is what is new:
Today, we are launching one of most requested features - Storage! When you sign up for Supabase, you get a Postgres database with realtime subscriptions, user management, auto-generated APIs and now a scalable object store. These services integrate very well with each other and you don't need to sign up for yet another service just for your storage requirements.
As with anything that we build in Supabase, Storage is fast, secure and scalable. You can use it to store terabytes of Machine Learning training data, your e-commerce product gallery or just your growing collection of JPEGs featuring cats playing synths in space.
This post outlines our design decisions while building Storage, and we'll show you how to use it in your own applications.
Architecture#
There are three key components to Supabase Storage:
- Backend (where the objects are actually stored).
- Middleware (access and permissions). This consists of an API Server and Postgres.
- Frontend (a nice UI).
The Storage API server sits behind Kong, an API Gateway. It talks to different storage backends like S3, Backblaze, etc to retrieve and store objects.
Object metadata and security rules are stored in your Postgres database.
We have built a powerful file explorer right into the dashboard, and using our Client libraries you can integrate Storage into your applications.
Frontend#
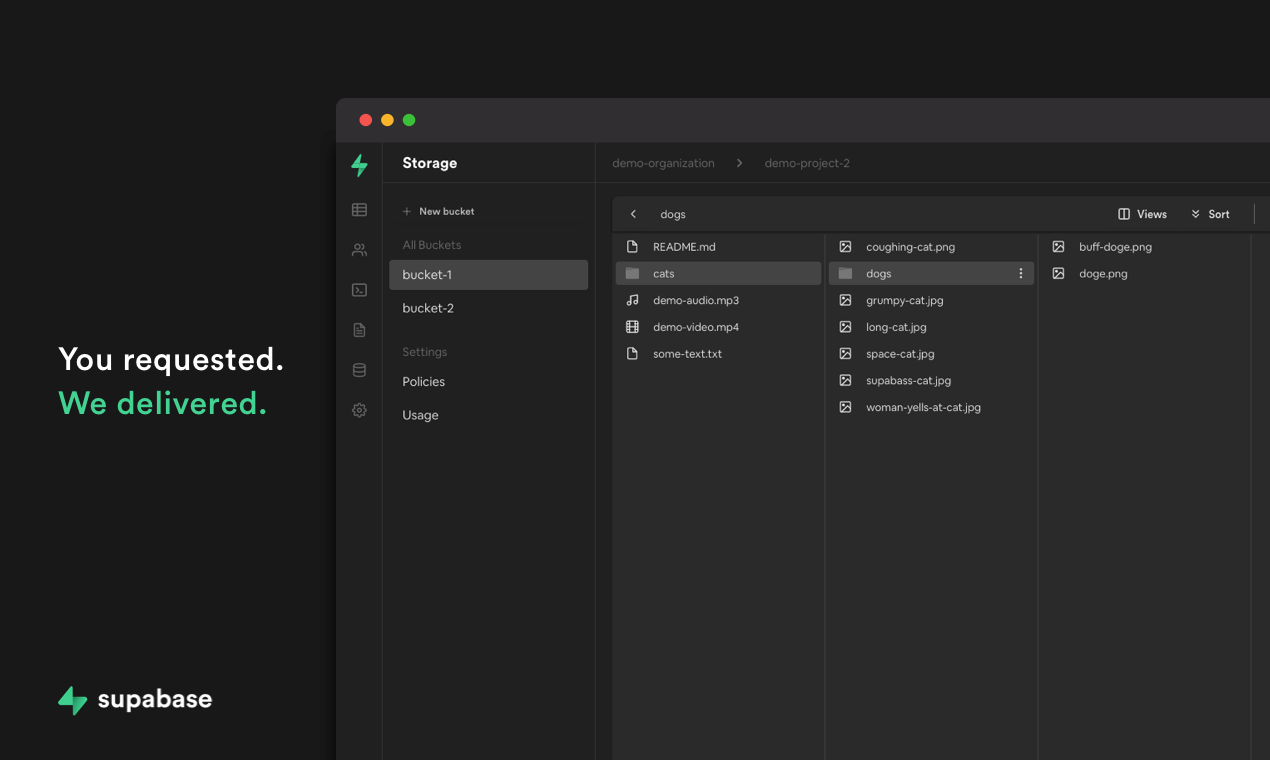
We set out to build the most usable front-end for storing content. Using Lists to display file hierarchies is a poor experience for exploring files - the most common use-case of a shared File system.
As avid Mac users, we've defaulted to using the column-based explorer in Finder as it allow us to quickly drill into nested folders and provides a clear birds eye view of file hierarchies at the same time.
We put in a lot of effort to make sure that the dashboard is fast and easy to navigate with our miller-based column view, allowing you to get to deeply nested folders quickly. If you're a fan of List Views though, don't worry! We have that option available too. The choice is yours.
Our File Browser also has a rich preview for a wide set of file types including images, audio, and videos.
And if you already know the location of a file but want to save a few clicks, you can paste the path into the location bar and navigate to it directly.
Designing the storage middleware#
We focused on performance, security and interoperability with the rest of the Supabase ecosystem.
Integration with the Supabase ecosystem#
Supabase is a collection of open source tools which integrate very well with each other. We evaluated open source object storage servers like Ceph, Swift, Minio and Zenko but none of these tools were a good fit for our existing ecosystem.
Postgres Compatibility
Each of these open source tools are amazing, but they all had a major drawback - we couldn't use Postgres as the server's datastore. If you haven't noticed yet, our team likes Postgres a lot 😉.
For example, Minio uses etcd (when used in multi-user gateway mode) and Zenko requires mongodb and Kafka. Every project on Supabase is a dedicated Postgres database, so leveraging it for object and user metadata is more efficient, reducing the number of dependencies for anyone using the Supabase ecosystem of tools.
Smaller footprint
We are using managed services like S3, Wasabi and Backblaze for our storage backend. We won't be managing our own hard disks and storage capacity, and so we don't require a lot of features offered by existing tools. For example, a large part of Minio's codebase is to offer erasure encoding and bitrot protection, automatically making use of new disks attached to the cluster.
Integration with Supabase Auth
Existing tools do not play well with our authentication system. For example, Minio is bundled with its own auth system and there is no easy way to map Minio users to Supabase users.
In the end, we opted to build our own Storage API server.
Security#
Authentication#
Our storage service sits behind Kong along with other services like PostgREST and Realtime. This allows us to reuse our existing Authentication system - any requests with a valid API key are authenticated and passed to the storage API.
Authorization#
For Authorization, we wanted to avoid creating a new DSL like Firebase. Instead, we created one where you can write policies in the One True Language - SQL!
To do this, we leverage Postgres' Row Level Security. We create a table for buckets and objects inside each Supabase project. These tables are namespaced in a separate schema called storage.
The idea is simple - if a user is able to select from the objects table, they can retrieve the object too. Using Postgres' Row Level Security, you can define fine-grained Policies to determine access levels for different users.
When a user makes a request for a file, the API detects the user in the Authorization header and tries to select from the objects table. If a valid row is returned, the Storage API pipes the object back from S3. Similarly if the user is able to delete the row from the objects table, they can delete the object from the storage backend too.
For example, if you want to give "read" access to a bucket called avatars you would use this policy:
_10create policy "Read access for avatars."_10on storage.objects for select using (_10 bucket_id = 'avatars'_10);
Extending this example, if you want to give access to a subfolder only (in this case called public):
_10create policy "Read access for public avatars."_10on storage.objects for select using (_10 bucket_id = 'avatars'_10 and (storage.foldername(name))[1] = 'public'_10);
We have created helper functions like foldername(), filename() and extension() in the storage schema to make Policies even simpler.
This system integrates with our User Management system. Here is an example policy which gives access to a particular file to a Supabase user:
_10create policy crud_uid_file_10on storage.objects for all using (_10 bucket_id = 'avatars'_10 and name = 'folder/only_uid.jpg'_10 and (select auth.uid()) = 'd8c7bce9-cfeb-497b-bd61-e66ce2cbdaa2'_10);
Using the power of Postgres' Row Level Security, you can create pretty much any policy imaginable.
Performance#
The storage server is built with Fastify and Typescript. Fastify is one of the fastest Node frameworks and our initial benchmark results look very promising.
We use Node streams everywhere. Objects are uploaded directly to S3 with minimal in-memory buffering. This minimizes RAM consumption even while uploading huge objects. The code does become a bit more complicated when using streams. For example, you can't figure out the size of the object being uploaded before streaming it to S3. But we believe this tradeoff is worth it.
Postgres is another hidden gem for our storage performance. For example, what if you had a bucket with thousands of objects, and you needed to find all objects which a user has access to? Without Postgres, you would retrieve all objects from that folder, evaluate each policy in the storage middleware and only return the objects which the user has access to. But we can avoid this completely with Postgres! We use Postgres to evaluate all the polices, and the storage middleware just returns the objects which the user has access to.
Supabase Storage has some opinionated defaults with respect to caching. Objects retrieved from S3 typically do not have a Cache-Control header. This isn't optimal for a Storage system since browsers don't cache objects completely without this header. Objects retrieved from Supabase Storage by default have a Cache-Control header of 1 hour. Of course, you can override this behaviour by specifying a different cache time when creating the object.
Storage Backend#
File objects are stored in an S3 bucket within the same region as your Supabase project. S3 has a high durability of 99.999999999% and is scalable as an object store.
While we started with S3, other storage backends like Wasabi, Backblaze and Openstack Swift expose an S3 compatible API. It will be simple to add more S3 compatible storage options in the future.
We have intentionally kept the API surface for the storage backend very small, in case the community also wants to add storage options which don't support the S3 API.
Client libraries#
You may be itching to get started tinkering around with our new Supabase storage - we have an example app prepared for you which simulates a simple context of setting an avatar image for a user. This will help you to get a high level overview of how to use your project's storage with our client library. For greater detail, refer to our storage API documentation here.
What's next#
- We currently support S3 and will be adding more storage backends. Vote for the storage backends you would like to see us implement here.
- We will integrate our storage service with a Content Delivery Network. With a CDN, objects are cached on a global network. This leads to faster access times for your users around the world. **SHIPPED: Supabase Storage v2: Image resizing and Smart CDN
- We are working on transformations like resizing of images and automatic optimization of different media types. This makes it easy to embed Supabase objects directly in your websites and mobile applications without additional processing. **SHIPPED: Supabase Storage v2: Image resizing and Smart CDN
- A better editor to make authoring policies easier and less error prone.
- Reach out to us if you would like to help out with adding storage support in one of the community maintained client libraries.
Take it for a spin on our dashboard and let us know what you think!