OrioleDB Overview
The OrioleDB Postgres extension provides a drop-in replacement storage engine for the default heap storage method. It is designed to improve Postgres' scalability and performance.
OrioleDB addresses Postgres's scalability limitations by removing bottlenecks in the shared memory cache under high concurrency. It also optimizes write-ahead-log (WAL) insertion through row-level WAL logging. These changes lead to significant improvements in the industry standard TPC-C benchmark, which approximates a real-world transactional workload. The following benchmark was performed on a c7g.metal instance and shows OrioleDB's performance outperforming the default Postgres heap method with a 3.3x speedup.
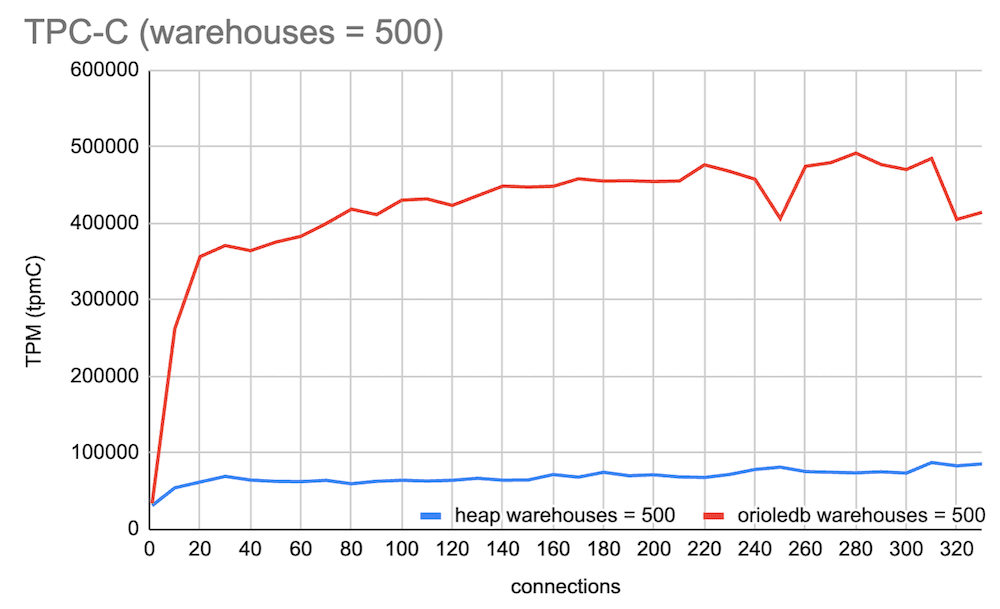
OrioleDB is in active development and currently has certain limitations. Currently, only B-tree indexes are supported, so features like pg_vector's HNSW indexes are not yet available. An Index Access Method bridge to unlock support for all index types used with heap storage is under active development. In the Supabase OrioleDB image the default storage method has been updated to use OrioleDB, granting better performance out of the box.
Concepts#
Index-organized tables#
OrioleDB uses index-organized tables, where table data is stored in the index structure. This design eliminates the need for separate heap storage, reduces overhead and improves lookup performance for primary key queries.
No buffer mapping#
In-memory pages are connected to the storage pages using direct links. This allows OrioleDB to bypass Postgres's shared buffer pool and eliminate the associated complexity and contention in buffer mapping.
Undo log#
Multi-Version Concurrency Control (MVCC) is implemented using an undo log. The undo log stores previous row versions and transaction information, which enables consistent reads while removing the need for table vacuuming completely.
Copy-on-write checkpoints#
OrioleDB implements copy-on-write checkpoints to persist data efficiently. This approach writes only modified data during a checkpoint, reducing the I/O overhead compared to traditional Postgres checkpointing and allowing row-level WAL logging.
Usage#
Creating OrioleDB project#
You can get started with OrioleDB by enabling the extension in your Supabase dashboard.
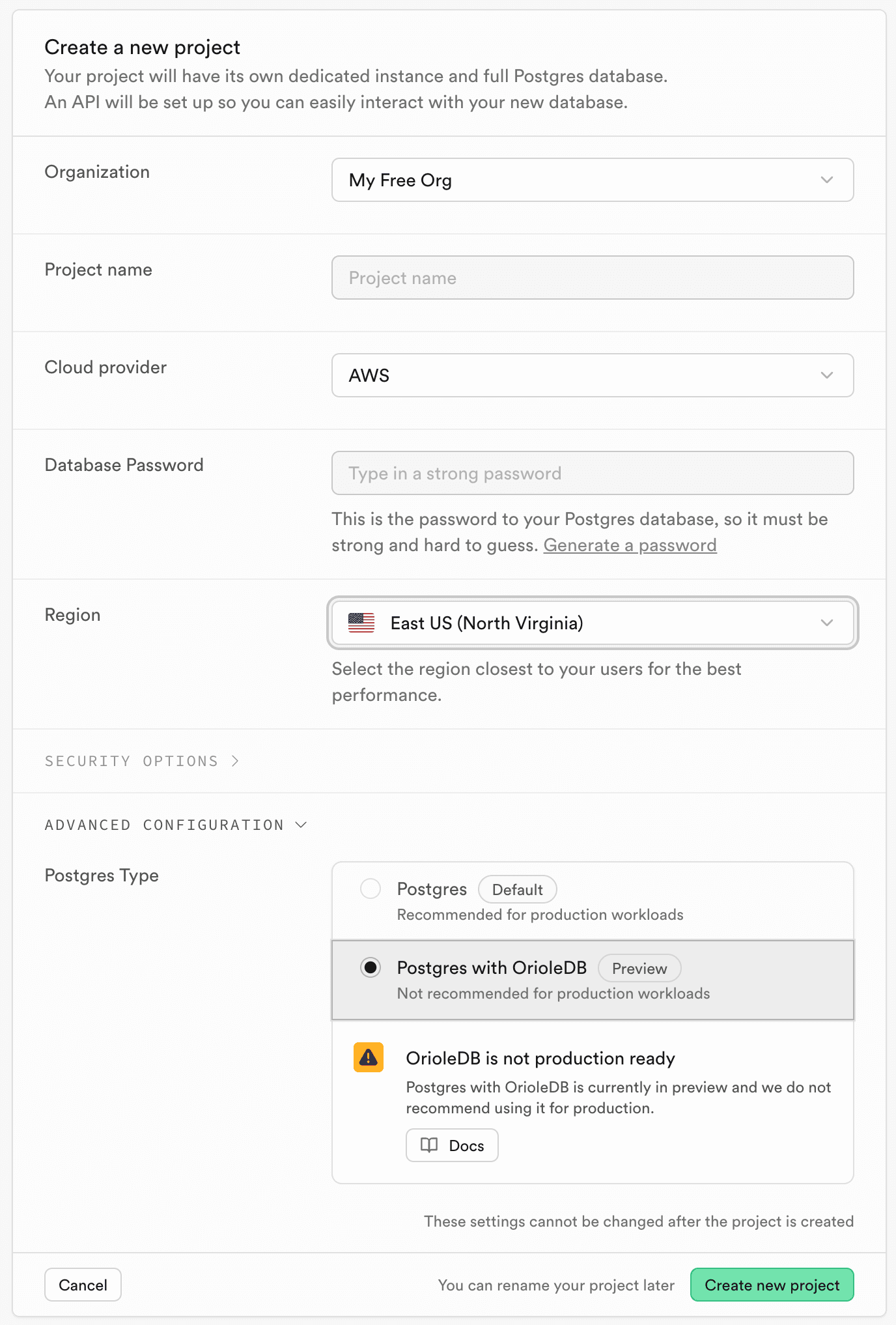
To get started with OrioleDB you need to create a new Supabase project and choose OrioleDB Public Alpha Postgres version.
Creating tables#
To create a table using the OrioleDB storage engine, execute the standard CREATE TABLE statement. By default it will create a table using OrioleDB storage engine. For example:
1-- Create a table2create table blog_post (3 id int8 not null,4 title text not null,5 body text not null,6 author text not null,7 published_at timestamptz not null default CURRENT_TIMESTAMP,8 views bigint not null,9 primary key (id)10);Creating indexes#
OrioleDB tables always have a primary key. If it wasn't defined explicitly, a hidden primary key is created using the ctid column.
Additionally you can create secondary indexes.
Currently, only B-tree indexes are supported, so features like pg_vector's HNSW indexes are not yet available.
1-- Create an index2create index blog_post_published_at on blog_post (published_at);34create index blog_post_views on blog_post (views) where (views > 1000);Data manipulation#
You can query and modify data in OrioleDB tables using standard SQL statements, including SELECT, INSERT, UPDATE, DELETE and INSERT ... ON CONFLICT.
1INSERT INTO blog_post (id, title, body, author, views)2VALUES (1, 'Hello, World!', 'This is my first blog post.', 'John Doe', 1000);34SELECT * FROM blog_post ORDER BY published_at DESC LIMIT 10;5 id │ title │ body │ author │ published_at │ views6────┼───────────────┼─────────────────────────────┼──────────┼───────────────────────────────┼───────7 1 │ Hello, World! │ This is my first blog post. │ John Doe │ 2024-11-15 12:04:18.756824+01 │ 1000Viewing query plans#
You can see the execution plan using standard EXPLAIN statement.
1EXPLAIN SELECT * FROM blog_post ORDER BY published_at DESC LIMIT 10;2 QUERY PLAN3────────────────────────────────────────────────────────────────────────────────────────────────────────────4 Limit (cost=0.15..1.67 rows=10 width=120)5 -> Index Scan Backward using blog_post_published_at on blog_post (cost=0.15..48.95 rows=320 width=120)67EXPLAIN SELECT * FROM blog_post WHERE id = 1;8 QUERY PLAN9──────────────────────────────────────────────────────────────────────────────────10 Index Scan using blog_post_pkey on blog_post (cost=0.15..8.17 rows=1 width=120)11 Index Cond: (id = 1)1213EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM blog_post ORDER BY published_at DESC LIMIT 10;14 QUERY PLAN15──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────16 Limit (cost=0.15..1.67 rows=10 width=120) (actual time=0.052..0.054 rows=1 loops=1)17 -> Index Scan Backward using blog_post_published_at on blog_post (cost=0.15..48.95 rows=320 width=120) (actual time=0.050..0.052 rows=1 loops=1)18 Planning Time: 0.186 ms19 Execution Time: 0.088 ms